分布式存儲冗餘數據壓縮方法和系統、客戶端以及伺服器與流程
2023-04-23 23:17:41 3
本發明涉及分布式計算領域,特別涉及一種分布式存儲冗餘數據壓縮技術。
背景技術:
隨著雲計算相關技術在國內的廣泛應用,基於廉價硬體的分布式存儲在企業內外部數據處理中得到了廣泛應用。
為保證分布式存儲系統的整體可靠性,目前典型的分布式存儲在底層普遍採用數據冗餘存儲的方式,例如將一份數據存儲保留多個副本,且存儲在不同的主機上,用空間置換安全性的提升。基於底層提供的數據安全保障,從應用層面就不再需要對數據做冗餘處理。由於同樣的文件存儲了多份,分布式存儲上應用層數據的冗餘不僅會浪費計算資源和網絡資源,也會增加整體維護成本,需要對應用層冗餘數據進行必要的壓縮處理。
目前分布式存儲在應用層數據壓縮,通常採用先上傳、後剔重的方案,這一方案雖然也可以釋放冗餘數據佔據的存儲空間,但需要佔用通信網絡資源、且剔重操作集中在伺服器端,會降低整體效能。對於大體積文件來說,這一缺陷尤其明顯。
技術實現要素:
本發明實施例所要解決的一個技術問題是:先上傳後剔重的應用層數據壓縮方法存在的通信網絡資源浪費以及整體效能比較低的問題。
根據本發明實施例的一個方面,提供了一種分布式存儲冗餘數據壓縮方法,包括:客戶端將上傳數據打包成數據塊;客戶端生成數據塊的數據塊ID;客戶端將數據塊ID發送至伺服器,使伺服器判斷該數 據塊ID對應的數據塊是否已經存在;客戶端接收伺服器返回的該數據塊ID對應的數據塊是否已經存在響應;根據響應,如果該數據塊ID對應的數據塊已存在於伺服器,客戶端開始下一個數據塊的傳輸;如果該數據塊ID對應的數據塊不存在於伺服器,客戶端將該數據塊ID對應的數據塊傳輸至伺服器。
根據本發明實施例的另一個方面,提供了一種分布式存儲冗餘數據壓縮方法,包括:伺服器端接收客戶端發送的數據塊ID;伺服器端判斷該數據塊ID對應的數據塊是否已經存在;如果數據塊ID對應的數據塊已經存在,則伺服器端將數據塊ID已存在的信息反饋給客戶端;如果數據塊ID對應的數據塊不存在,則伺服器端通知客戶端上傳數據塊ID對應的數據塊,並在接收到數據塊ID對應的數據塊後,將數據塊ID記錄到已上傳數據塊列表中。
根據本發明實施例的又一個方面,提供了一種用於分布式存儲冗餘數據壓縮的客戶端,包括:數據塊打包單元,用於將上傳數據打包成數據塊;數據塊ID生成單元,用於生成數據塊的數據塊ID;數據塊ID發送單元,用於將數據塊ID發送至伺服器,使伺服器判斷該數據塊ID對應的數據塊是否已經存在;響應接收單元,用於接收伺服器返回的該數據塊ID對應的數據塊是否已經存在響應;數據塊傳輸單元,用於根據響應,如果該數據塊ID對應的數據塊已存在於伺服器,則開始下一個數據塊的傳輸;如果該數據塊ID對應的數據塊不存在於伺服器,則將該數據塊ID對應的數據塊傳輸至伺服器。
根據本發明實施例的再一個方面,提供了一種用於分布式存儲冗餘數據壓縮的伺服器,包括:數據塊ID接收單元,用於接收客戶端發送的數據塊ID;數據塊判斷單元,用於判斷該數據塊ID對應的數據塊是否已經存在;信息反饋單元,用於如果數據塊ID對應的數據塊已經存在,則信息反饋單元將數據塊ID已存在的信息反饋給客戶端;如果數據塊ID對應的數據塊不存在,則信息反饋單元通知客戶端上傳數據塊ID對應的數據塊;數據塊接收單元,用於接收數據塊ID對應的數據塊;數據塊ID記錄單元,用於在接收到數據塊ID對 應的數據塊後,將數據塊ID記錄到已上傳數據塊列表中。
根據本發明實施例的另一個方面,提供了一種分布式存儲冗餘數據壓縮系統,包括前述的客戶端以及前述的伺服器。
本發明至少具有以下優點:
通過客戶端和伺服器端的協作,目標數據在上傳伺服器前先判斷是否在伺服器端已經存在,如果存在則進行「預壓縮」,從而實現了對應用層冗餘數據的壓縮,減少對通信網絡資源和伺服器端資源的佔用,提升分布式存儲的整體效能。
通過以下參照附圖對本發明的示例性實施例的詳細描述,本發明的其它特徵及其優點將會變得清楚。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對於本領域普通技術人員來講,在不付出創造性勞動性的前提下,還可以根據這些附圖獲得其他的附圖。
圖1示出根據本發明分布式存儲冗餘數據壓縮方法的一個實施例的流程示意圖。
圖2示出根據本發明分布式存儲冗餘數據壓縮方法的另一個實施例的流程示意圖。
圖3示出根據本發明分布式存儲冗餘數據壓縮方法的又一個實施例的流程示意圖。
圖4示出根據本發明分布式存儲冗餘數據壓縮客戶端的一個實施例的結構示意圖。
圖5示出根據本發明分布式存儲冗餘數據壓縮客戶端的另一個實施例的結構示意圖。
圖6示出根據本發明分布式存儲冗餘數據壓縮伺服器的一個實施例的結構示意圖。
圖7示出根據本發明分布式存儲冗餘數據壓縮伺服器的另一個實施例的結構示意圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。以下對至少一個示例性實施例的描述實際上僅僅是說明性的,決不作為對本發明及其應用或使用的任何限制。基於本發明中的實施例,本領域普通技術人員在沒有作出創造性勞動前提下所獲得的所有其他實施例,都屬於本發明保護的範圍。
下面參考圖1描述本發明一個實施例的分布式存儲冗餘數據壓縮方法。
圖1示出根據本發明分布式存儲冗餘數據壓縮方法的一個實施例的流程示意圖。如圖1所示,該實施例的方法包括:
步驟S102,客戶端將上傳數據打包成數據塊。
一種示例性的方法,客戶端根據數據打包策略將上傳數據打包成數據塊。以基於體積的策略為例,客戶端比較上傳數據的體積與數據打包策略中設定的數據塊閾值體積X;若上傳數據的體積小於或等於X,則將上傳數據打包成一個數據塊,並且打包數據塊體積等於上傳數據體積;若上傳數據的體積大於X,則以體積X為單位對上傳數據進行分割,分割後不足X的部分進行填充處理,分割後的各部分上傳數據分別打包成一個數據塊。
例如,客戶端預先設定數據塊閾值體積為100兆比特。客戶端比較上傳數據的體積與數據打包策略中設定的數據塊閾值體積:若上傳數據的體積小於或等於100兆比特,則將上傳數據打包成一個數據塊,並且打包數據塊體積等於上傳數據體積;若上傳數據的體積大於100兆比特,則以體積100兆比特為單位對上傳數據進行分割,分割後不足100兆比特的部分進行填充處理,分割後的各部分上傳數據分別打包成一個數據塊。此外,數據打包策略中,除了包括數據塊分割填充 機制之外,還可以包括數據塊完整性校驗機制,以保證上傳數據塊的完整性。
步驟S104,客戶端根據數據塊ID生成策略生成數據塊的數據塊ID。
一種示例性的方法,客戶端根據數據塊體積生成數據塊ID。客戶端比較數據塊的體積與數據塊ID生成策略中設定的數據塊閾值體積Y;若數據塊的體積小於Y,則根據數據塊所在的源文件名、文件後綴、文件大小以及文件修改時間中的至少一項信息生成數據塊ID;若數據塊的體積等於或大於Y,則對數據塊採用消息摘要算法計算生成數據塊ID。此外,若數據塊體積小於等於Y,且數據塊所在的源文件名、文件後綴、文件大小以及文件修改時間都相同,則也可以根據配置對數據塊採用消息摘要算法計算生成數據塊ID。
典型的數據塊ID生成策略包括基於文件特徵的數據塊ID生成策略和基於消息摘要算法數據塊ID生成策略。
基於文件特徵的數據塊ID生成策略計算簡單,耗費的系統資源較少,但存在文件唯一性識別錯誤的風險。例如,對於小體積數據塊,可以採用「文件名+文件後綴名+文件大小+修改時間」作為打包數據塊的數據塊ID。但是,如果有多個不同數據塊的文件名、文件後綴名、文件大小以及修改時間均相同,那麼依照基於文件特徵的數據塊ID生成策略所生成的數據塊ID相同。
基於消息摘要算法的數據塊ID生成策略可以避免文件唯一性識別錯誤的發生,但其計算複雜,耗費的系統資源較多,通常可以適用於大體積數據塊。常見的基於消息摘要算法包括CRC32、MD5以及SHA算法。例如,通過MD5算法,不同的數據塊可以生成唯一的數據塊ID。
為了更好的提高分布式存儲冗餘數據壓縮效率,可以將基於文件特徵的數據塊ID生成策略和基於消息摘要算法的數據塊ID生成策略結合使用。例如,客戶端預先設定數據塊閾值體積100兆比特。然後,客戶端比較數據塊的體積與數據塊ID生成策略中設定的數據塊閾值 體積:若數據塊體積小於100兆比特,則免去生成數據塊ID的過程,直接採用「文件名+文件後綴名+文件大小+修改時間」作為打包數據塊的數據塊ID,並進行數據塊上傳;若數據塊的體積大於100兆比特,則對數據塊採用MD5算法計算生成數據塊ID。
此外,若多個數據塊體積小於100兆比特,且多個數據塊所在的源文件名、文件後綴、文件大小以及文件修改時間都相同,則也對這些數據塊採用消息摘要算法計算生成數據塊ID。
步驟S106,客戶端將數據塊ID發送至伺服器,相應的,伺服器端接收客戶端發送的數據塊ID。
步驟S108,伺服器判斷該數據塊ID對應的數據塊是否已經存在。
一種示例性的判斷方法,伺服器可以根據已上傳數據塊列表記錄的信息,判斷列表中是否有請求上傳的數據塊ID,如果有,則說明該數據塊已經上傳過,可以執行步驟S110進行「預壓縮」,如果沒有,則說明該數據塊還沒有上傳過,可以執行步驟S112進行數據塊的上傳。
步驟S110,如果伺服器判斷數據塊ID對應的數據塊已經存在,則伺服器端將數據塊ID已存在的信息反饋給客戶端,客戶端開始下一個數據塊的傳輸;
步驟S112,如果伺服器判斷數據塊ID對應的數據塊不存在,則伺服器端通知客戶端上傳數據塊ID對應的數據塊,客戶端將該數據塊ID對應的數據塊傳輸至伺服器,伺服器在接收到數據塊ID對應的數據塊後,將數據塊ID記錄到已上傳數據塊列表中。
其中,已上傳數據塊列表中記錄有已上傳的數據塊ID,還可以包括已上傳數據塊的存儲位置信息等內容。
上述方法通過客戶端和伺服器端的協作,目標數據在上傳伺服器前先判斷是否在伺服器端已經存在,如果存在則進行「預壓縮」,從而實現了對應用層冗餘數據的壓縮,並且減少對通信網絡資源和伺服器端資源的佔用,提升分布式存儲的整體效能。
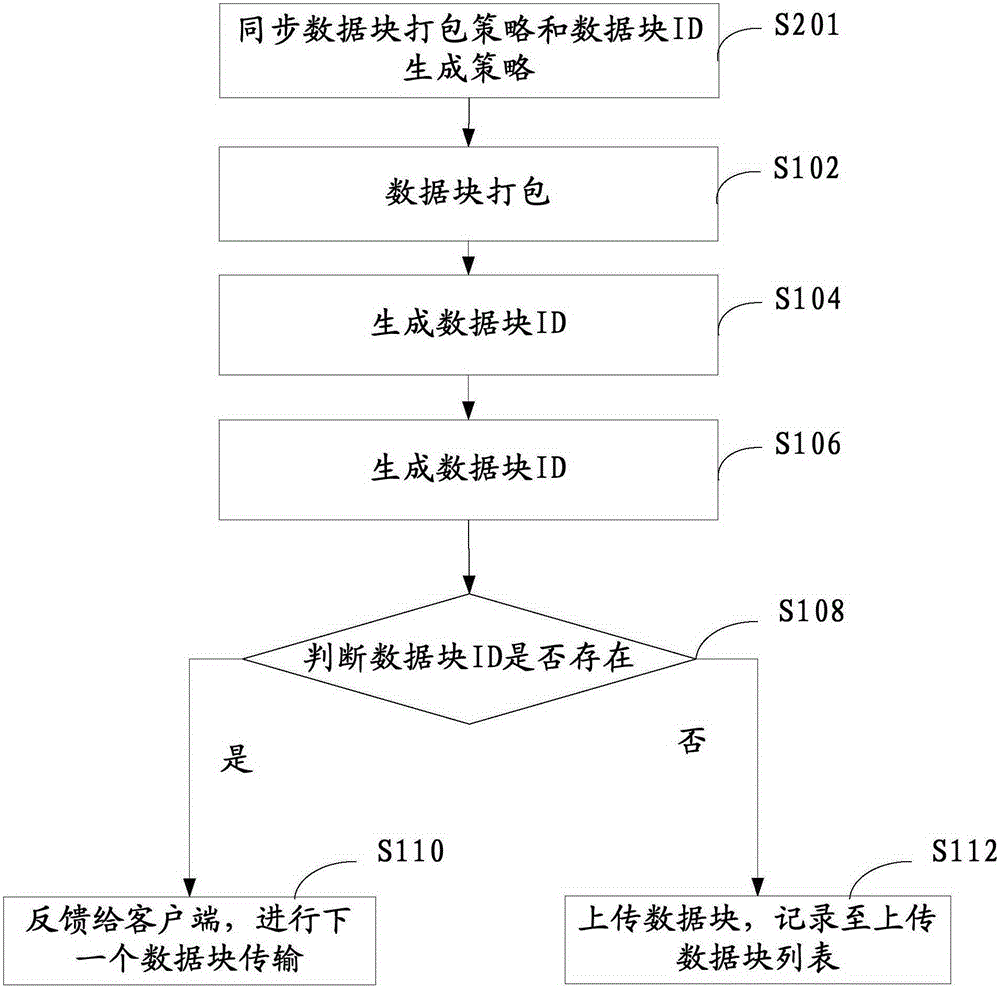
圖2示出根據本發明分布式存儲冗餘數據壓縮方法的又一個實施例的流程示意圖。如圖2所示,在圖1所示實施例的基礎上,本實 施例的方法還包括:
步驟S201,在伺服器配置數據塊打包策略和數據塊ID生成策略,客戶端在對數據塊進行打包之前,從伺服器同步數據打包策略和數據塊ID生成策略,由每個客戶端對本地數據分別進行數據塊打包和數據塊ID的生成。
影響數據打包策略的參數可以包括數據體積、數據所有者、數據文件類別。基於同步參數,可以確定數據塊的打包策略。伺服器可以根據安全、性能和其他個性化要求,制定數據塊ID計算算法,標識其唯一性。
通過客戶端與伺服器同步數據塊打包策略,伺服器可以處理具有統一規格的數據塊,進一步提高了分布式存儲的整體效能。此外,由於數據塊ID是上傳數據的唯一標識,伺服器依據數據塊ID對數據塊作出是否需要「預壓縮」的判斷。如果伺服器和客戶端的數據塊ID生成策略不同,那麼有可能出現以下兩種情形:不同客戶端根據不同數據塊生成策略生成相同數據塊ID,伺服器端會錯誤的執行預壓縮;不同客戶端根據相同數據塊生成不同數據塊ID,伺服器端會錯誤的遺漏預壓縮。因此,作為一個優選的方案,伺服器和各個客戶端的數據塊ID生成策略相同,可以保證不同的數據塊具有其對應的不同數據塊ID。從而可以避免上述情形的發生,有助於預壓縮高效地、準確地進行。
圖3示出根據本發明分布式存儲冗餘數據壓縮方法的又一個實施例的流程示意圖。如圖3所示,在圖1所示實施例的基礎上,本實施例的方法還包括:步驟S307,客戶端將上傳數據所屬文件的文件名稱發送至伺服器,相應的,伺服器接收客戶端發送的上傳數據塊所屬文件的文件名稱。步驟S307可以與步驟S106同時執行。
在步驟S110或S112伺服器接收到客戶端上傳的數據塊之後,執行步驟S314,伺服器建立文件名稱與其數據塊的連接。
在該實施例中,伺服器端維護「文件名-數據塊ID」的有序連接,一個文件名可以對應一個或更多個數據塊ID。如果有多個數據塊,需要按先後順序存放。一個數據塊ID可以對應一到多個文件名,當 數據塊ID沒有對應的文件名時,該數據塊ID和數據塊本身可以刪除。基於文件名,根據數據塊ID按次序組合其對應的數據塊,則可以得到文件本身。
下面參考圖4描述本發明一個實施例的分布式存儲冗餘數據壓縮客戶端的結構。
圖4示出根據本發明分布式存儲冗餘數據壓縮客戶端的一個實施例的結構示意圖。如圖4所示,該實施例的客戶端40包括:
數據塊打包單元402,用於將上傳數據打包成數據塊;
數據塊ID生成單元404,用於生成數據塊的數據塊ID;
數據塊ID發送單元406,用於將數據塊ID發送至伺服器,使伺服器判斷該數據塊ID對應的數據塊是否已經存在;
響應接收單元408,用於接收伺服器返回的該數據塊ID對應的數據塊是否已經存在響應;
數據塊傳輸單元410,用於根據所述響應,如果該數據塊ID對應的數據塊已存在於伺服器,則開始下一個數據塊的傳輸;如果該數據塊ID對應的數據塊不存在於伺服器,則將該數據塊ID對應的數據塊傳輸至伺服器。
其中,數據塊打包單元402用於根據數據打包策略配置將上傳數據打包成數據塊,例如,比較上傳數據的體積與數據打包策略中設定的數據塊閾值體積X;根據數據打包策略,若上傳數據的體積小於或等於X,則將上傳數據打包成一個數據塊,並且打包數據塊體積等於上傳數據體積;若上傳數據的體積大於X,則以體積X為單位對上傳數據進行分割,分割後不足X的部分進行填充處理,分割後的各部分上傳數據分別打包成一個數據塊。
其中,數據塊ID生成單元404用於根據數據塊ID生成策略配置生成數據塊的數據塊ID,比較數據塊的體積與數據塊ID生成策略中設定的數據塊閾值體積Y;根據數據塊ID生成策略,若數據塊的體積小於Y,則根據數據塊所在的源文件名、文件後綴、文件大小以及文件修改時間中的至少一項信息生成數據塊ID,或者對數據塊採用消 息摘要算法計算生成數據塊ID;若數據塊的體積等於或大於Y,則對數據塊採用消息摘要算法計算生成數據塊ID。
其中,數據塊ID生成單元404用於根據數據塊ID生成策略,在數據塊體積小於等於Y,且數據塊所在的源文件名、文件後綴、文件大小以及文件修改時間都相同的情況下,則對數據塊採用消息摘要算法計算生成數據塊ID,以便檢查其是否在伺服器端已經存在。
下面參考圖5描述本發明另一個實施例的分布式存儲冗餘數據壓縮客戶端的結構。
圖5示出根據本發明分布式存儲冗餘數據壓縮客戶端的另一個實施例的結構示意圖。如圖5所示,該實施例的客戶端50還包括:
包括策略同步單元501,用於從伺服器同步數據打包策略和數據塊ID生成策略。
文件名發送單元509,用於將上傳數據所屬文件的文件名稱發送至伺服器,以便伺服器建立文件名稱與其數據塊的連接。
優選的,數據塊ID發送單元406與文件名發送單元509可以同步執行。
下面參考圖6描述本發明一個實施例的分布式存儲冗餘數據壓縮伺服器的結構。
圖6示出根據本發明分布式存儲冗餘數據壓縮伺服器的一個實施例的結構示意圖。如圖6所示,該實施例的伺服器60包括:
數據塊ID接收單元602,用於接收客戶端發送的數據塊ID.
數據塊判斷單元604,用於判斷該數據塊ID對應的數據塊是否已經存在。
信息反饋單元606,用於如果數據塊ID對應的數據塊已經存在,則信息反饋單元將數據塊ID已存在的信息反饋給客戶端;如果數據塊ID對應的數據塊不存在,則信息反饋單元通知客戶端上傳數據塊ID對應的數據塊。
數據塊接收單元608,用於接收數據塊ID對應的數據塊。
數據塊ID記錄單元610,用於在接收到數據塊ID對應的數據塊 後,將數據塊ID記錄到已上傳數據塊列表中。
下面參考圖7描述本發明另一個實施例的分布式存儲冗餘數據壓縮伺服器的結構。
圖7示出根據本發明分布式存儲冗餘數據壓縮伺服器的另一個實施例的結構示意圖。如圖7所示,該實施例的伺服器70還包括:
策略同步單元701,用於將數據打包策略和數據塊ID生成策略同步到各客戶端。
文件名接收單元709,用於接收客戶端發送的上傳數據塊所屬文件的文件名稱,並建立文件名稱與其數據塊的連接。
優選的,數據塊ID接收單元602與文件名接收單元709可以同步執行。
本領域普通技術人員可以理解實現上述實施例的全部或部分步驟可以通過硬體來完成,也可以通過程序來指令相關的硬體完成,所述的程序可以存儲於一種計算機可讀存儲介質中,上述提到的存儲介質可以是只讀存儲器,磁碟或光碟等。
以上所述僅為本發明的較佳實施例,並不用以限制本發明,凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。