一種NtHMA2基因突變體與應用的製作方法
2023-07-07 17:52:07 4
本發明屬於遺傳工程技術領域,具體涉及一種NtHMA2基因突變體與應用。
背景技術:
鎘( Cd)、砷( As) 、鉻( Cr) 、汞( Hg)和鉛( Pb) 等是公認的對植物和人體危害比較大的重金屬元素,植物必需微量元素鋅( Zn) 、鎳( Ni) 、銅( Cu)等如果過量也會產生危害。所以,關於作物重金屬汙染及其降低方法的研究越來越引起科研人員的重視。菸草(Nicotiana tabacum)是重要的經濟作物,是茄科一年生草本植物。近年來關於菸草中重金屬的研究也逐漸成為菸草減害研究的一個熱點。
重金屬對菸草品質會產生不利影響。菸鹼含量是衡量菸葉品質的一個重要指標,在一定範圍內提高菸鹼有利於菸葉品質的提高,Cd 汙染會降低菸葉菸鹼含量,可能原因是根合成菸鹼途徑或者菸鹼向上部轉運過程受阻。另外,菸葉中可溶性糖對Cd、Pb極為敏感,輕度汙染就會導致其含量明顯下降,這可能是由於重金屬破壞了菸草葉綠體,光合作用受阻引起的。重金屬會導致菸葉糖鹼比和氮鹼比升高,化學成分組成失衡,品質受到影響。
重金屬對人體的危害巨大,如過量的鎘進入人體內可能對血管造成損害;另外鎘元素對腸道吸收鐵具有抑制作用,還會干擾鈷、銅、鋅等微量元素的代謝過程,引起肺、腎、肝等人體臟器損害,最終可能導致致癌、致畸和致突變等作用。砷可以誘發許多疾病,如急性砷中毒可造成中樞神經系統障礙導致全身麻木、呼吸道和消化道病變甚至快速死亡;慢性砷中毒導致神經系統紊亂、全身乏力、食慾減退、噁心以及皮膚色素沉著和角化病等皮膚病變等,而且可以引起肺癌、皮膚癌和膀胱癌等疾病。鋅元素是人體的重要的微量元素之一,對人體的生長發育、智力、免疫功能甚至是視力都有至關重要的作用。但是人體中的鋅不是越多越好。人體攝入過量的鋅,在胃液中易轉化成氯化鋅,對胃黏膜有較強的腐蝕性,可致胃黏膜充血、水腫、甚至出血。過量的血鋅會抑制白細胞的吞噬功能,是人體抵抗力下降,易受病菌感染。過量的鋅還會影響人體其他無機鹽的吸收與代謝,如影響鐵的吸收,使肝臟中鐵代謝受損成銅/鋅比值過高;影響膽固醇代謝,形成高膽固醇血症等。鎳及其鹽類的毒性較低,但由於它本身具有生物化學活性,故能激活或抑制一系列的酶(精氨酸酶、羧化酶、酸性磷酸酶和拓脫羧酶)而發揮其毒性。鎳可引起接觸性皮炎。直接進入血液的鎳鹽毒性較高,膠體鎳或氯化鎳毒性較大,可引起中樞性循環和呼吸紊亂,使心肌、腦、肺和腎出現水腫、出血和變性。
菸草是我國重要的經濟作物, 重金屬汙染不僅影響菸草本身生長發育,對吸食者的的健康也具有嚴重的威脅。減害一直是菸草科研工作的一個重要方向,其中降低重金屬含量是一個重要的公關目標。
技術實現要素:
本發明的第一目的在於提供一種NtHMA2基因的EMS突變體;第二目的在於提供所述的NtHMA2基因突變體的應用。
本發明的第一目的是這樣實現的,與野生型菸草的NtHMA2基因具有如序列表中SEQ ID No:1所示的核苷酸序列相比,突變體含有的NtHMA2基因序列520位的C突變為T,形成終止密碼子,使該基因提前終止。
所述的NtHMA2基因的EMS突變體的製備方法包括EMS誘變和TILLING篩選突變體。
EMS誘變菸草種子:
A :利用漂白水處理菸草種子,然後旋轉離心並濾幹;
B :對種子進行漂洗,清除漂白水,使種子不受漂白劑化學成分影響,然後進行旋轉離心濾幹;
C :將種子放在10℃ ~30℃溫度下的去離子水中浸泡10~15小時,菸草種子催芽萌發,以利種子均勻誘變處理,然後進行旋轉離心濾幹;
D :將種子放在0.5%的EMS (甲基磺酸乙酯)誘變劑溶液中浸泡處理10~15個小時,然後進行旋轉離心濾幹;
E :將種子放在漂洗劑溶液中漂洗,再用去離子水衝洗,反覆進行5~8 次此過程,然後布氏漏鬥濾紙過濾乾燥。
TILLING篩選核苷酸變化的突變體
A :誘變處理後的種子(M1代)播種與大田,單株套袋自交收種獲得M2代,每個M1代單株收穫的M2代種子播種1粒種子。
B:取M2代突變體單株葉片利用QIAGEN DNA提取試劑盒提取突變體材料葉片DNA。
C:樣品濃度測定及建池
將樣品按照順序大小排列。分別取2ul DNA樣品16通道 Tecan infinite M200儀器上進行濃度測定。將所有的樣品濃度稀釋至40ng/ul,製作8倍DNA池用於TILLING分析。
D: 利用Primer3設計NtHMA2基因TILLING分析引物,HMA2-F:
AATATAGAGATGGCCAATGAAGGT和HMA2-R: CTAAAATTTATATGACCAAGTACTT,擴增長度為1400bp左右。
E:TILLING分析 M2代突變體,篩選核苷酸突變的單株,並進行測序驗證,獲得一個突變體,其CDS的520位的C突變為T,形成終止密碼子,使該基因提前終止。
F:在M3代突變體篩選突變位點純合的植株,自交收種。
G:對純合突變體進行鎘吸收試驗,具體為在煙株現蕾期,將100µmol CdCL2溶液500mL澆於煙株根部。5天後取葉片,殺青烘乾,檢測重金屬含量。
H: 含有突變序列的菸草相比含有SEQ ID NO:1序列的菸草葉片鎘含量降低40%左右,鋅、鐵、鉛、鉻、鎳等含量降低30%左右,砷含量降低10%左右。
本發明的第二目的是這樣實現的,NtHMA2基因突變體可以使菸葉鎘含量降低30~50%,鋅、鐵、鉛、鉻、鎳等含量降低20~40%左右,砷含量降低5~15%左右。即以所述的NtHMA2基因突變體獲得低重金屬含量的菸草。
附圖說明
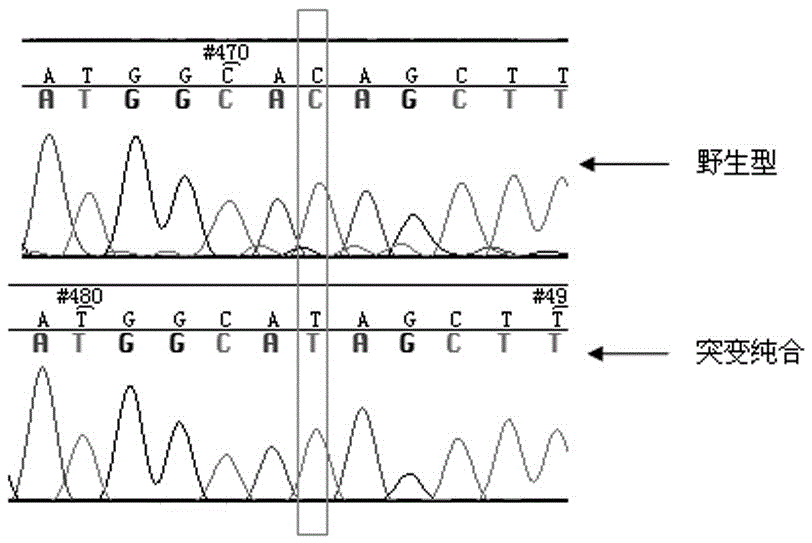
圖1 為突變體突變位點測序峰圖;
圖2為本發明NtHMA2突變體與雲煙87葉片鎘含量對比示意圖;
圖3為本發明NtHMA2突變體與雲煙87葉片鋅含量對比示意圖;
圖4為本發明NtHMA2突變體與雲煙87葉片鐵含量對比示意圖;
圖5為本發明NtHMA2突變體與雲煙87葉片砷含量對比示意圖;
圖6為本發明NtHMA2突變體與雲煙87葉片鉻含量對比示意圖;
圖7為本發明NtHMA2突變體與雲煙87葉片鎳含量對比示意圖。
具體實施方式
下面結合實施例和附圖對本發明作進一步的說明,但不以任何方式對本發明加以限制,基於本發明教導所作的任何變換或替換,均屬於本發明的保護範圍。
本發明所述的NtHMA2基因突變體,與野生型菸草的NtHMA2基因具有如序列表中SEQ ID No:1所示的核苷酸序列相比,突變體含有的NtHMA2基因序列520位的C突變為T,形成終止密碼子,使該基因提前終止。
NtHMA2基因編碼的胺基酸序列如SEQ ID No:2所示;
NtHMA2基因突變體的核苷酸序列如SEQ ID No:3所示;
NtHMA2基因突變體編碼的胺基酸序列如SEQ ID No:4所示;
所述的NtHMA2基因的EMS突變體的製備方法包括EMS誘變和TILLING篩選突變體。
EMS誘變菸草種子:
A :利用漂白水處理菸草種子,然後旋轉離心並濾幹;
B :對種子進行漂洗,清除漂白水,使種子不受漂白劑化學成分影響,然後進行旋轉離心濾幹;
C :將種子放在10℃ ~30℃溫度下的去離子水中浸泡10~15小時,菸草種子催芽萌發,以利種子均勻誘變處理,然後進行旋轉離心濾幹;
D :將種子放在0.5%的EMS (甲基磺酸乙酯)誘變劑溶液中浸泡處理10~15個小時,然後進行旋轉離心濾幹;
E :將種子放在漂洗劑溶液中漂洗,再用去離子水衝洗,反覆進行5~8 次此過程,然後布氏漏鬥濾紙過濾乾燥。
TILLING篩選核苷酸變化的突變體
A :誘變處理後的種子(M1代)播種與大田,單株套袋自交收種獲得M2代,每個M1代單株收穫的M2代種子播種1粒種子。
B:取M2代突變體單株葉片利用QIAGEN DNA提取試劑盒提取突變體材料葉片DNA。
C:樣品濃度測定及建池
將樣品按照順序大小排列。分別取2ul DNA樣品16通道 Tecan infinite M200儀器上進行濃度測定。將所有的樣品濃度稀釋至40ng/ul,製作8倍DNA池用於TILLING分析。
D: 利用Primer3設計NtHMA2基因TILLING分析引物,
HMA2-F:AATATAGAGATGGCCAATGAAGGT和
HMA2-R: CTAAAATTTATATGACCAAGTACTT,擴增長度為1400bp左右。
E:TILLING分析 M2代突變體,篩選核苷酸突變的單株,並進行測序驗證,獲得一個突變體,其CDS的520位的C突變為T,形成終止密碼子,使該基因提前終止。
F:在M3代突變體篩選突變位點純合的植株,自交收種。
G:對純合突變體進行鎘吸收試驗,具體為在煙株現蕾期,將100µmol CdCL2溶液500mL澆於煙株根部。5天後取葉片,殺青烘乾,檢測重金屬含量。
H: 含有突變序列的菸草相比含有SEQ ID NO:1序列的菸草葉片鎘含量降低40%左右,鋅、鐵、鉛、鉻、鎳等含量降低30%左右,砷含量降低10%左右。
本發明所述的應用為NtHMA2基因突變體可以使菸葉鎘含量降低30~50%左右,鋅、鐵、鉛、鉻、鎳等含量降低20~40%左右,砷含量降低5~15%左右。即以所述的NtHMA2基因突變體獲得低重金屬含量的菸草。
下面以具體實施案例對本發明做作進一步說明:
所述的NtHMA2突變體的製備方法, 未突變NtHMA2突變體的核苷酸序列如序列表中SEQ ID No:1所示,突變體的核苷酸序列520位的C突變為T,具體製備方法包括以下步驟:
(1)選用50% 漂白水處理雲煙87種子6 分鐘,離心濾幹;
(2)利用去離子對種子進行漂洗1 分鐘,離心濾幹去除漂白水成分;
(3)室溫條件,去離子水浸泡菸草種子10-12 小時,離心濾幹;
(4)室溫條件,0.50%EMS 甲基磺酸乙酯處理菸草種子12 小時,離心濾幹;
(5)加入去離子水漂洗1 分鐘,離心濾幹,共重複漂洗8次。然後布氏漏鬥濾紙過濾乾燥。
(6)誘變處理後的種子(M1代)播種與大田,單株套袋自交收種獲得M2代,每個M1代單株收穫的M2代種子播種1粒種子,共獲得1842個M2代單株。
(7) 取M2代突變體單株葉片利用QIAGEN DNA提取試劑盒提取突變體材料葉片DNA。具體步驟如下:將樣品液氮研磨,並用1.5ml離心管收取;加入400ul的AP1溶液,4ul的RNA酶混勻 ;把樣品放入65℃水浴鍋水浴10min,期間搖勻3次;往樣品中加入130ul P3溶液,冰浴5mim;高速離心,13200rpm,5min;取上層液倒入紫色過濾柱,13200rpm,2min離心;將濾液轉入新的1.5mL離心管並加入675ul的AW1溶液混勻;把混勻樣品溶液分2次轉入淡黃色過濾柱並進行10000rpm,1min離心,棄除濾液;把淡黃色過濾柱放入新的2ml離心管中並加入500ul的AW2溶液,進行10000rpm,1min離心,棄濾液 (此步驟重複兩次);再把棄除濾液的淡黃色過濾柱進行空轉(10000rpm,1min),將空轉好的淡黃色過濾柱放入新的1.5ml離心管中加入50ul AE溶液後靜置5min,放入離心機進行10000rpm,1min離心,去除淡黃色過濾柱,放入4℃冰箱保存。
(8)樣品濃度測定及建池
將樣品按照順序大小排列。分別取2ul DNA樣品16通道 Tecan infinite M200儀器上進行濃度測定。將所有的樣品濃度稀釋至40ng/ul,製作8倍DNA池用於TILLING分析。
(9)利用Primer3設計NtHMA2基因TILLING分析引物,
HMA2-F:AATATAGAGATGGCCAATGAAGGT和
HMA2-R:CTAAAATTTATATGACCAAGTACTT,擴增長度為1400bp左右。
(10)TILLING分析 M2代突變體,擴增體系為:1.0µl 10×buffer,0.8µl dNTP(2.5mM),0.16 µl HMA2-F primer(10µM) ,0.16µl HMA2-R primer (10uM), 6.78 µl H2O,1.0 µl DNA模板 (20ng/ul) 。反應程序為95℃ 3min,94℃ 30s,62℃ 30s,-1℃/循環,72℃ 1min,7個循環;94℃30s,58℃30s,72℃1min,40個循環,72℃5min;99℃ 10min;70℃20s, -0.3℃/循環, 70個循環,4℃保存。擴增產物通過毛細管電泳進行分析。
(11)篩選出的核苷酸突變的單株,進行測序驗證,獲得一個突變體,其NtHMA2基因CDS的520位的C突變為T,形成終止密碼子,使該基因提前終止。
(12)在M3代突變體中經過測序篩選突變位點純合的植株(圖1),自交收種。
NtHMA2突變體降低菸葉重金屬含量的方法包括以下步驟:
(1)對純合突變體進行鎘吸收試驗,具體為在溫室種植純合突變體及野生型對照,煙株現蕾期,將100µmol CdCL2溶液500mL澆於煙株根部,5天後取葉片,殺青烘乾。利用菸草行業標準YC/T380-2010的方法檢測菸葉重金屬含量。
(2)含有突變序列的菸草相比含有SEQ ID NO:1序列的菸草葉片鎘含量降低40%左右,鋅、鐵、鉛、鉻、鎳等含量降低30%左右,砷含量降低10%左右(表1,圖2~圖7)。
表1 菸葉重金屬含量
SEQUENCE LISTING
雲南省菸草農業科學研究院
一種NtHMA2突變體與應用
2017
6
PatentIn version 3.3
1
4212
DNA
NtHMA2基因核苷酸
1
atggtggaaa gtgaaaaaat gaatgaaaca aagaagttga gcaagagcta ttttgatgtt 60
ttgggaattt gctgtacttc agaagttgtt ctagttgaaa aaattctcaa gaatcttgaa 120
ggggttaaag aggtttcagt aattgtcaca acaaagactg tcattgttat tcatgattct 180
cttctcattt ctccgcaaca aattgttaaa gcattgaatc aagcaagatt agaagcaagc 240
ataagagtga aaggagagaa aaactaccaa aagaaatggc caagtccatt tgcaattggc 300
agtggaatat tgcttggact ctcatttttg aagtactttt ttgcaccttt ccaatggtta 360
gcacttgcag ctgttgcagt tgggattcct ccaattattt ttagaggtgt ggctgccgtg 420
cgaaacctca ctcttgacat caacattctt gttttaatag cagtggctgg atcaattgtt 480
ttacacgatt attgggaagc tggtactatt gtcttcttat tcgccattgc agaatggcta 540
gagtcaaggg caagtcacaa ggctaccgct gctatgtcat cactggtcaa tatagtccct 600
ccaacagcag ttttagctga aagcggagaa gtcgtaaatg ttgatgaagt caaggtgaat 660
agcattcttg ctgtgaaagc tggtgaaact atacctattg atggagttgt agtggaaggg 720
gaatgtgacg tggacgagaa aacactgaca ggcgagtcgt ttccagtttc taagcaaaga 780
gattcaacgg tctgggctgg cactacaaat ctaaatggct atatcagtgt taagactacg 840
gctttggctg aagattgtgc ggtggctagg atggcacagc ttgtcgaaga tgctcagaac 900
aagaaatcaa aaacccaaag atacatcgac aagtgtgcta aatattatac accagcaatt 960
gtggctatat cagcttcttt ggcaattgtt cctactgcat taagagttca caatcgaaat 1020
gaatggtatc gcttggcttt ggtcacattg gtgagtgcat gtccgtgtgc acttgttcta 1080
tctacaccag ttgccatgtg ttgcgcactt tcaaaagcag caacgtccgg tcttctgttt 1140
aaaggagcag agtaccttga gactctagct aaaatcaaaa tcatggcttt tgacaaaaca 1200
gggactataa ctaaaggaga atttatggtg accgagttca agtctctgat tgatggtttt 1260
agtctcaata cactgcttta ctgggtttca agcattgaga gcaagtcagg tcatccgatg 1320
gcagccgctc tggtggacta tgcacaatca aattccgttg agccaaagcc tgatagagtt 1380
gagcagtttc aaaattttcc tggtgaaggg atatttggaa gaattgatgg aatggaaatc 1440
tatgtcggga ataggaaaat ttcttcaaga gctggatgta ccacagtacc agaaatagag 1500
ggtgatagtt tcaaaggaaa gtctgttgga tacatatttt tgggatcatc tccagctgga 1560
attttcagtc tttccgatgt ttgtcgaatt ggtgtaaaag aagcaatgag agaactgaag 1620
cagatgggta tcaaaaccgc gatgcttact ggtgattgtt atgcagctgc caaccatgtg 1680
caggatcagt taggtggagc tttggatgaa tttcaagcag aactcctacc agaggacaag 1740
gcaacaatca tcaagggttt tcagaaggaa gctccaacag cgatgatagg cgacggcctt 1800
aatgatgctc ctgcattagc aacagctgac attggcatct caatgggcat ctctgggtca 1860
gctctcgcta aagaaacagg ccatgttata ctaatgacaa atgacatcgg aagaataccg 1920
aaagctgcac gtcttgctag aagagttcga aggaagattg ttgagaatat gattatatca 1980
gtcgttacaa aggctgccat agttgcattg gcaatagcag gttatccatt ggtttgggct 2040
gctgtcctcg cagatactgg gacatgcttg ctagtgattt tgaacagcat gctacttcta 2100
cgaggaggca cacgcagaca tgggaaaaaa tgttggagat cttctactcc ttcgcatgct 2160
ccccaccaca aagacaaagc ttcatgttgc aagtcggaaa atgctcccca gctgtgttgc 2220
tctgatattg agtcacaaaa gaaatgtaca agtcaatcat gctcgtccga ggtgtgtgtt 2280
ccaagatgtc aacctgtctc ctcaggatca aagtcatgtg gaaataatca gtgcccagac 2340
tccattgaaa atagtggttt tcattctcat ccccgtcctc aatgctgctc gtcgaagatg 2400
gctgctaaag catgccaatc tgcagtttca gaatcaaagt catgcggaaa taatcagtgc 2460
ccagactccg ttgaaaatag tggttttcat tctcatcccc gtcctgaatg ctgctcgtcg 2520
aagatggctg ctaaagcgtg ccaatctgca gtttcagaat caaagtcatg tggaaataat 2580
cagtgcccag actccgttga aaatagtggt tttcattctc atccccgtcc tcaatgctgt 2640
tcatcgaaga tggctgctaa agcaggccaa tctgcacttt cagaatcaaa gtcatgtgga 2700
aataacaatt gctcagactc cattcacaag agtaattgtc attctttaac taactctcta 2760
gtatgttctt ccaagatgtc tgctccacaa tgtcattctg ctacttcaag caacaaatca 2820
tgtggaagta ccaagtgctc cgacttcagt gacaaaaaat gttgtcaatc cgacaaaatt 2880
cctcaaacgt gctctaccaa gaagtctgct ccaggatgtc aatctgcagt ttctgggtct 2940
aaatcatgtg gaaatagcaa gtgttcagac tcaaaagaca atagtagcca tccttcacat 3000
cccgatcatc aaacatgcat gtctaagttg tgtgctccac aaagccaatc tgcaacttca 3060
agctccagga catgtggaaa tacaaagtgc tcggacacca atagcaagaa ttcttgttat 3120
tcacaaacca actctgaatc atgctcttca aagatgtctg gtccatcatg caaaactgct 3180
aattcaggtt caaggtcatg cagaaataag aagtgccagg actctgcaac cgagaacagt 3240
tttcattcac cacttactaa tccactcagt ggggaaaagc tttcggagca gaaaagcttg 3300
gatttagtcc gaaaagataa ggaatcaagt catgatcttc gtcatggctg ctctgacgag 3360
gaacatgatc atacaaattt agacaaggca tatgacagtt gtgccttaca agaatgttgt 3420
tattcggttc aaggcaataa aactgatgta tcagaaactg gaatccagga aactgctcat 3480
tgtgacagca ccaatcaaac atgccaaact gcaagttcag gatcgatgac atgcggaaat 3540
gataagatcc tggactctct aagcatccat ggttgtcatt cgcatgataa tccactccac 3600
gaggagaaca acttggagca gaaaatcttg gatgttgttg gagaaggtat aaaatcacct 3660
catgctgtcg gtcatggctg ttcggacaag gaacacgatc actcacatcc agaaaaggca 3720
tatgacagtt gtgcaacaga tgattgttgt ttttcagttc aagtccatgg cattgacgac 3780
gtatcaaaaa gtgaaattca agaaactgct cattgtgaca gcacaaagca gagcatggtc 3840
atctccagca gctgcaaaca tgaaccaaaa gatcaggtaa atcactgtgg acttcactct 3900
aaaactactc caactgatga agaactagcc aagctggtta gaagatgctg caaatacaaa 3960
ccatgccacg acgtccgttc tggctgcagg aagcatgctg cagaatgtgg tccaaccgtt 4020
cgatcaacca tcaatatctt acgggacaac catcatcatt acctagactg cagtggtcgt 4080
aaggtttgtt cgctgttgga gaagagacac atcggtggat gctgtgacag cttcagaaaa 4140
gaatgttgtg ccaagaaaaa acaccttgga gcaagttttg gaggaggttt atcagaaatt 4200
gtcatagagt ag 4212
2
1403
PRT
NtHMA2基因胺基酸
2
Met Val Glu Ser Glu Lys Met Asn Glu Thr Lys Lys Leu Ser Lys Ser
1 5 10 15
Tyr Phe Asp Val Leu Gly Ile Cys Cys Thr Ser Glu Val Val Leu Val
20 25 30
Glu Lys Ile Leu Lys Asn Leu Glu Gly Val Lys Glu Val Ser Val Ile
35 40 45
Val Thr Thr Lys Thr Val Ile Val Ile His Asp Ser Leu Leu Ile Ser
50 55 60
Pro Gln Gln Ile Val Lys Ala Leu Asn Gln Ala Arg Leu Glu Ala Ser
65 70 75 80
Ile Arg Val Lys Gly Glu Lys Asn Tyr Gln Lys Lys Trp Pro Ser Pro
85 90 95
Phe Ala Ile Gly Ser Gly Ile Leu Leu Gly Leu Ser Phe Leu Lys Tyr
100 105 110
Phe Phe Ala Pro Phe Gln Trp Leu Ala Leu Ala Ala Val Ala Val Gly
115 120 125
Ile Pro Pro Ile Ile Phe Arg Gly Val Ala Ala Val Arg Asn Leu Thr
130 135 140
Leu Asp Ile Asn Ile Leu Val Leu Ile Ala Val Ala Gly Ser Ile Val
145 150 155 160
Leu His Asp Tyr Trp Glu Ala Gly Thr Ile Val Phe Leu Phe Ala Ile
165 170 175
Ala Glu Trp Leu Glu Ser Arg Ala Ser His Lys Ala Thr Ala Ala Met
180 185 190
Ser Ser Leu Val Asn Ile Val Pro Pro Thr Ala Val Leu Ala Glu Ser
195 200 205
Gly Glu Val Val Asn Val Asp Glu Val Lys Val Asn Ser Ile Leu Ala
210 215 220
Val Lys Ala Gly Glu Thr Ile Pro Ile Asp Gly Val Val Val Glu Gly
225 230 235 240
Glu Cys Asp Val Asp Glu Lys Thr Leu Thr Gly Glu Ser Phe Pro Val
245 250 255
Ser Lys Gln Arg Asp Ser Thr Val Trp Ala Gly Thr Thr Asn Leu Asn
260 265 270
Gly Tyr Ile Ser Val Lys Thr Thr Ala Leu Ala Glu Asp Cys Ala Val
275 280 285
Ala Arg Met Ala Gln Leu Val Glu Asp Ala Gln Asn Lys Lys Ser Lys
290 295 300
Thr Gln Arg Tyr Ile Asp Lys Cys Ala Lys Tyr Tyr Thr Pro Ala Ile
305 310 315 320
Val Ala Ile Ser Ala Ser Leu Ala Ile Val Pro Thr Ala Leu Arg Val
325 330 335
His Asn Arg Asn Glu Trp Tyr Arg Leu Ala Leu Val Thr Leu Val Ser
340 345 350
Ala Cys Pro Cys Ala Leu Val Leu Ser Thr Pro Val Ala Met Cys Cys
355 360 365
Ala Leu Ser Lys Ala Ala Thr Ser Gly Leu Leu Phe Lys Gly Ala Glu
370 375 380
Tyr Leu Glu Thr Leu Ala Lys Ile Lys Ile Met Ala Phe Asp Lys Thr
385 390 395 400
Gly Thr Ile Thr Lys Gly Glu Phe Met Val Thr Glu Phe Lys Ser Leu
405 410 415
Ile Asp Gly Phe Ser Leu Asn Thr Leu Leu Tyr Trp Val Ser Ser Ile
420 425 430
Glu Ser Lys Ser Gly His Pro Met Ala Ala Ala Leu Val Asp Tyr Ala
435 440 445
Gln Ser Asn Ser Val Glu Pro Lys Pro Asp Arg Val Glu Gln Phe Gln
450 455 460
Asn Phe Pro Gly Glu Gly Ile Phe Gly Arg Ile Asp Gly Met Glu Ile
465 470 475 480
Tyr Val Gly Asn Arg Lys Ile Ser Ser Arg Ala Gly Cys Thr Thr Val
485 490 495
Pro Glu Ile Glu Gly Asp Ser Phe Lys Gly Lys Ser Val Gly Tyr Ile
500 505 510
Phe Leu Gly Ser Ser Pro Ala Gly Ile Phe Ser Leu Ser Asp Val Cys
515 520 525
Arg Ile Gly Val Lys Glu Ala Met Arg Glu Leu Lys Gln Met Gly Ile
530 535 540
Lys Thr Ala Met Leu Thr Gly Asp Cys Tyr Ala Ala Ala Asn His Val
545 550 555 560
Gln Asp Gln Leu Gly Gly Ala Leu Asp Glu Phe Gln Ala Glu Leu Leu
565 570 575
Pro Glu Asp Lys Ala Thr Ile Ile Lys Gly Phe Gln Lys Glu Ala Pro
580 585 590
Thr Ala Met Ile Gly Asp Gly Leu Asn Asp Ala Pro Ala Leu Ala Thr
595 600 605
Ala Asp Ile Gly Ile Ser Met Gly Ile Ser Gly Ser Ala Leu Ala Lys
610 615 620
Glu Thr Gly His Val Ile Leu Met Thr Asn Asp Ile Gly Arg Ile Pro
625 630 635 640
Lys Ala Ala Arg Leu Ala Arg Arg Val Arg Arg Lys Ile Val Glu Asn
645 650 655
Met Ile Ile Ser Val Val Thr Lys Ala Ala Ile Val Ala Leu Ala Ile
660 665 670
Ala Gly Tyr Pro Leu Val Trp Ala Ala Val Leu Ala Asp Thr Gly Thr
675 680 685
Cys Leu Leu Val Ile Leu Asn Ser Met Leu Leu Leu Arg Gly Gly Thr
690 695 700
Arg Arg His Gly Lys Lys Cys Trp Arg Ser Ser Thr Pro Ser His Ala
705 710 715 720
Pro His His Lys Asp Lys Ala Ser Cys Cys Lys Ser Glu Asn Ala Pro
725 730 735
Gln Leu Cys Cys Ser Asp Ile Glu Ser Gln Lys Lys Cys Thr Ser Gln
740 745 750
Ser Cys Ser Ser Glu Val Cys Val Pro Arg Cys Gln Pro Val Ser Ser
755 760 765
Gly Ser Lys Ser Cys Gly Asn Asn Gln Cys Pro Asp Ser Ile Glu Asn
770 775 780
Ser Gly Phe His Ser His Pro Arg Pro Gln Cys Cys Ser Ser Lys Met
785 790 795 800
Ala Ala Lys Ala Cys Gln Ser Ala Val Ser Glu Ser Lys Ser Cys Gly
805 810 815
Asn Asn Gln Cys Pro Asp Ser Val Glu Asn Ser Gly Phe His Ser His
820 825 830
Pro Arg Pro Glu Cys Cys Ser Ser Lys Met Ala Ala Lys Ala Cys Gln
835 840 845
Ser Ala Val Ser Glu Ser Lys Ser Cys Gly Asn Asn Gln Cys Pro Asp
850 855 860
Ser Val Glu Asn Ser Gly Phe His Ser His Pro Arg Pro Gln Cys Cys
865 870 875 880
Ser Ser Lys Met Ala Ala Lys Ala Gly Gln Ser Ala Leu Ser Glu Ser
885 890 895
Lys Ser Cys Gly Asn Asn Asn Cys Ser Asp Ser Ile His Lys Ser Asn
900 905 910
Cys His Ser Leu Thr Asn Ser Leu Val Cys Ser Ser Lys Met Ser Ala
915 920 925
Pro Gln Cys His Ser Ala Thr Ser Ser Asn Lys Ser Cys Gly Ser Thr
930 935 940
Lys Cys Ser Asp Phe Ser Asp Lys Lys Cys Cys Gln Ser Asp Lys Ile
945 950 955 960
Pro Gln Thr Cys Ser Thr Lys Lys Ser Ala Pro Gly Cys Gln Ser Ala
965 970 975
Val Ser Gly Ser Lys Ser Cys Gly Asn Ser Lys Cys Ser Asp Ser Lys
980 985 990
Asp Asn Ser Ser His Pro Ser His Pro Asp His Gln Thr Cys Met Ser
995 1000 1005
Lys Leu Cys Ala Pro Gln Ser Gln Ser Ala Thr Ser Ser Ser Arg
1010 1015 1020
Thr Cys Gly Asn Thr Lys Cys Ser Asp Thr Asn Ser Lys Asn Ser
1025 1030 1035
Cys Tyr Ser Gln Thr Asn Ser Glu Ser Cys Ser Ser Lys Met Ser
1040 1045 1050
Gly Pro Ser Cys Lys Thr Ala Asn Ser Gly Ser Arg Ser Cys Arg
1055 1060 1065
Asn Lys Lys Cys Gln Asp Ser Ala Thr Glu Asn Ser Phe His Ser
1070 1075 1080
Pro Leu Thr Asn Pro Leu Ser Gly Glu Lys Leu Ser Glu Gln Lys
1085 1090 1095
Ser Leu Asp Leu Val Arg Lys Asp Lys Glu Ser Ser His Asp Leu
1100 1105 1110
Arg His Gly Cys Ser Asp Glu Glu His Asp His Thr Asn Leu Asp
1115 1120 1125
Lys Ala Tyr Asp Ser Cys Ala Leu Gln Glu Cys Cys Tyr Ser Val
1130 1135 1140
Gln Gly Asn Lys Thr Asp Val Ser Glu Thr Gly Ile Gln Glu Thr
1145 1150 1155
Ala His Cys Asp Ser Thr Asn Gln Thr Cys Gln Thr Ala Ser Ser
1160 1165 1170
Gly Ser Met Thr Cys Gly Asn Asp Lys Ile Leu Asp Ser Leu Ser
1175 1180 1185
Ile His Gly Cys His Ser His Asp Asn Pro Leu His Glu Glu Asn
1190 1195 1200
Asn Leu Glu Gln Lys Ile Leu Asp Val Val Gly Glu Gly Ile Lys
1205 1210 1215
Ser Pro His Ala Val Gly His Gly Cys Ser Asp Lys Glu His Asp
1220 1225 1230
His Ser His Pro Glu Lys Ala Tyr Asp Ser Cys Ala Thr Asp Asp
1235 1240 1245
Cys Cys Phe Ser Val Gln Val His Gly Ile Asp Asp Val Ser Lys
1250 1255 1260
Ser Glu Ile Gln Glu Thr Ala His Cys Asp Ser Thr Lys Gln Ser
1265 1270 1275
Met Val Ile Ser Ser Ser Cys Lys His Glu Pro Lys Asp Gln Val
1280 1285 1290
Asn His Cys Gly Leu His Ser Lys Thr Thr Pro Thr Asp Glu Glu
1295 1300 1305
Leu Ala Lys Leu Val Arg Arg Cys Cys Lys Tyr Lys Pro Cys His
1310 1315 1320
Asp Val Arg Ser Gly Cys Arg Lys His Ala Ala Glu Cys Gly Pro
1325 1330 1335
Thr Val Arg Ser Thr Ile Asn Ile Leu Arg Asp Asn His His His
1340 1345 1350
Tyr Leu Asp Cys Ser Gly Arg Lys Val Cys Ser Leu Leu Glu Lys
1355 1360 1365
Arg His Ile Gly Gly Cys Cys Asp Ser Phe Arg Lys Glu Cys Cys
1370 1375 1380
Ala Lys Lys Lys His Leu Gly Ala Ser Phe Gly Gly Gly Leu Ser
1385 1390 1395
Glu Ile Val Ile Glu
1400
3
4212
DNA
NtHMA2基因突變體核苷酸
3
atggtggaaa gtgaaaaaat gaatgaaaca aagaagttga gcaagagcta ttttgatgtt 60
ttgggaattt gctgtacttc agaagttgtt ctagttgaaa aaattctcaa gaatcttgaa 120
ggggttaaag aggtttcagt aattgtcaca acaaagactg tcattgttat tcatgattct 180
cttctcattt ctccgcaaca aattgttaaa gcattgaatc aagcaagatt agaagcaagc 240
ataagagtga aaggagagaa aaactaccaa aagaaatggc caagtccatt tgcaattggc 300
agtggaatat tgcttggact ctcatttttg aagtactttt ttgcaccttt ccaatggtta 360
gcacttgcag ctgttgcagt tgggattcct ccaattattt ttagaggtgt ggctgccgtg 420
cgaaacctca ctcttgacat caacattctt gttttaatag cagtggctgg atcaattgtt 480
ttacacgatt attgggaagc tggtactatt gtcttcttat tcgccattgc agaatggcta 540
gagtcaaggg caagtcacaa ggctaccgct gctatgtcat cactggtcaa tatagtccct 600
ccaacagcag ttttagctga aagcggagaa gtcgtaaatg ttgatgaagt caaggtgaat 660
agcattcttg ctgtgaaagc tggtgaaact atacctattg atggagttgt agtggaaggg 720
gaatgtgacg tggacgagaa aacactgaca ggcgagtcgt ttccagtttc taagcaaaga 780
gattcaacgg tctgggctgg cactacaaat ctaaatggct atatcagtgt taagactacg 840
gctttggctg aagattgtgc ggtggctagg atggcatagc ttgtcgaaga tgctcagaac 900
aagaaatcaa aaacccaaag atacatcgac aagtgtgcta aatattatac accagcaatt 960
gtggctatat cagcttcttt ggcaattgtt cctactgcat taagagttca caatcgaaat 1020
gaatggtatc gcttggcttt ggtcacattg gtgagtgcat gtccgtgtgc acttgttcta 1080
tctacaccag ttgccatgtg ttgcgcactt tcaaaagcag caacgtccgg tcttctgttt 1140
aaaggagcag agtaccttga gactctagct aaaatcaaaa tcatggcttt tgacaaaaca 1200
gggactataa ctaaaggaga atttatggtg accgagttca agtctctgat tgatggtttt 1260
agtctcaata cactgcttta ctgggtttca agcattgaga gcaagtcagg tcatccgatg 1320
gcagccgctc tggtggacta tgcacaatca aattccgttg agccaaagcc tgatagagtt 1380
gagcagtttc aaaattttcc tggtgaaggg atatttggaa gaattgatgg aatggaaatc 1440
tatgtcggga ataggaaaat ttcttcaaga gctggatgta ccacagtacc agaaatagag 1500
ggtgatagtt tcaaaggaaa gtctgttgga tacatatttt tgggatcatc tccagctgga 1560
attttcagtc tttccgatgt ttgtcgaatt ggtgtaaaag aagcaatgag agaactgaag 1620
cagatgggta tcaaaaccgc gatgcttact ggtgattgtt atgcagctgc caaccatgtg 1680
caggatcagt taggtggagc tttggatgaa tttcaagcag aactcctacc agaggacaag 1740
gcaacaatca tcaagggttt tcagaaggaa gctccaacag cgatgatagg cgacggcctt 1800
aatgatgctc ctgcattagc aacagctgac attggcatct caatgggcat ctctgggtca 1860
gctctcgcta aagaaacagg ccatgttata ctaatgacaa atgacatcgg aagaataccg 1920
aaagctgcac gtcttgctag aagagttcga aggaagattg ttgagaatat gattatatca 1980
gtcgttacaa aggctgccat agttgcattg gcaatagcag gttatccatt ggtttgggct 2040
gctgtcctcg cagatactgg gacatgcttg ctagtgattt tgaacagcat gctacttcta 2100
cgaggaggca cacgcagaca tgggaaaaaa tgttggagat cttctactcc ttcgcatgct 2160
ccccaccaca aagacaaagc ttcatgttgc aagtcggaaa atgctcccca gctgtgttgc 2220
tctgatattg agtcacaaaa gaaatgtaca agtcaatcat gctcgtccga ggtgtgtgtt 2280
ccaagatgtc aacctgtctc ctcaggatca aagtcatgtg gaaataatca gtgcccagac 2340
tccattgaaa atagtggttt tcattctcat ccccgtcctc aatgctgctc gtcgaagatg 2400
gctgctaaag catgccaatc tgcagtttca gaatcaaagt catgcggaaa taatcagtgc 2460
ccagactccg ttgaaaatag tggttttcat tctcatcccc gtcctgaatg ctgctcgtcg 2520
aagatggctg ctaaagcgtg ccaatctgca gtttcagaat caaagtcatg tggaaataat 2580
cagtgcccag actccgttga aaatagtggt tttcattctc atccccgtcc tcaatgctgt 2640
tcatcgaaga tggctgctaa agcaggccaa tctgcacttt cagaatcaaa gtcatgtgga 2700
aataacaatt gctcagactc cattcacaag agtaattgtc attctttaac taactctcta 2760
gtatgttctt ccaagatgtc tgctccacaa tgtcattctg ctacttcaag caacaaatca 2820
tgtggaagta ccaagtgctc cgacttcagt gacaaaaaat gttgtcaatc cgacaaaatt 2880
cctcaaacgt gctctaccaa gaagtctgct ccaggatgtc aatctgcagt ttctgggtct 2940
aaatcatgtg gaaatagcaa gtgttcagac tcaaaagaca atagtagcca tccttcacat 3000
cccgatcatc aaacatgcat gtctaagttg tgtgctccac aaagccaatc tgcaacttca 3060
agctccagga catgtggaaa tacaaagtgc tcggacacca atagcaagaa ttcttgttat 3120
tcacaaacca actctgaatc atgctcttca aagatgtctg gtccatcatg caaaactgct 3180
aattcaggtt caaggtcatg cagaaataag aagtgccagg actctgcaac cgagaacagt 3240
tttcattcac cacttactaa tccactcagt ggggaaaagc tttcggagca gaaaagcttg 3300
gatttagtcc gaaaagataa ggaatcaagt catgatcttc gtcatggctg ctctgacgag 3360
gaacatgatc atacaaattt agacaaggca tatgacagtt gtgccttaca agaatgttgt 3420
tattcggttc aaggcaataa aactgatgta tcagaaactg gaatccagga aactgctcat 3480
tgtgacagca ccaatcaaac atgccaaact gcaagttcag gatcgatgac atgcggaaat 3540
gataagatcc tggactctct aagcatccat ggttgtcatt cgcatgataa tccactccac 3600
gaggagaaca acttggagca gaaaatcttg gatgttgttg gagaaggtat aaaatcacct 3660
catgctgtcg gtcatggctg ttcggacaag gaacacgatc actcacatcc agaaaaggca 3720
tatgacagtt gtgcaacaga tgattgttgt ttttcagttc aagtccatgg cattgacgac 3780
gtatcaaaaa gtgaaattca agaaactgct cattgtgaca gcacaaagca gagcatggtc 3840
atctccagca gctgcaaaca tgaaccaaaa gatcaggtaa atcactgtgg acttcactct 3900
aaaactactc caactgatga agaactagcc aagctggtta gaagatgctg caaatacaaa 3960
ccatgccacg acgtccgttc tggctgcagg aagcatgctg cagaatgtgg tccaaccgtt 4020
cgatcaacca tcaatatctt acgggacaac catcatcatt acctagactg cagtggtcgt 4080
aaggtttgtt cgctgttgga gaagagacac atcggtggat gctgtgacag cttcagaaaa 4140
gaatgttgtg ccaagaaaaa acaccttgga gcaagttttg gaggaggttt atcagaaatt 4200
gtcatagagt ag 4212
4
292
PRT
NtHMA2基因突變體胺基酸
4
Met Val Glu Ser Glu Lys Met Asn Glu Thr Lys Lys Leu Ser Lys Ser
1 5 10 15
Tyr Phe Asp Val Leu Gly Ile Cys Cys Thr Ser Glu Val Val Leu Val
20 25 30
Glu Lys Ile Leu Lys Asn Leu Glu Gly Val Lys Glu Val Ser Val Ile
35 40 45
Val Thr Thr Lys Thr Val Ile Val Ile His Asp Ser Leu Leu Ile Ser
50 55 60
Pro Gln Gln Ile Val Lys Ala Leu Asn Gln Ala Arg Leu Glu Ala Ser
65 70 75 80
Ile Arg Val Lys Gly Glu Lys Asn Tyr Gln Lys Lys Trp Pro Ser Pro
85 90 95
Phe Ala Ile Gly Ser Gly Ile Leu Leu Gly Leu Ser Phe Leu Lys Tyr
100 105 110
Phe Phe Ala Pro Phe Gln Trp Leu Ala Leu Ala Ala Val Ala Val Gly
115 120 125
Ile Pro Pro Ile Ile Phe Arg Gly Val Ala Ala Val Arg Asn Leu Thr
130 135 140
Leu Asp Ile Asn Ile Leu Val Leu Ile Ala Val Ala Gly Ser Ile Val
145 150 155 160
Leu His Asp Tyr Trp Glu Ala Gly Thr Ile Val Phe Leu Phe Ala Ile
165 170 175
Ala Glu Trp Leu Glu Ser Arg Ala Ser His Lys Ala Thr Ala Ala Met
180 185 190
Ser Ser Leu Val Asn Ile Val Pro Pro Thr Ala Val Leu Ala Glu Ser
195 200 205
Gly Glu Val Val Asn Val Asp Glu Val Lys Val Asn Ser Ile Leu Ala
210 215 220
Val Lys Ala Gly Glu Thr Ile Pro Ile Asp Gly Val Val Val Glu Gly
225 230 235 240
Glu Cys Asp Val Asp Glu Lys Thr Leu Thr Gly Glu Ser Phe Pro Val
245 250 255
Ser Lys Gln Arg Asp Ser Thr Val Trp Ala Gly Thr Thr Asn Leu Asn
260 265 270
Gly Tyr Ile Ser Val Lys Thr Thr Ala Leu Ala Glu Asp Cys Ala Val
275 280 285
Ala Arg Met Ala
290
5
24
DNA
HMA2-F
5
aatatagaga tggccaatga aggt 24
6
25
DNA
HMA2-R
6
ctaaaattta tatgaccaag tactt 25