一種Redis中主從節點數據同步方法與流程
2023-06-25 09:48:21 2
本發明涉及電子計算機數據存儲領域,具體涉及一種Redis中主從節點數據同步方法。
背景技術:
近年來,計算機系統的發展日新月異,對數據存儲載體的要求也越來越高,特別是網際網路的興起,由於其服務的用戶眾多,對數據存儲性能的要求非常高,傳統的關係型資料庫很難滿足要求,因此,眾多的網際網路企業在面向最終用戶的服務上放棄使用傳統的關係型資料庫,而使用了性能更好的KV(鍵值)資料庫存儲,開源產品Redis(REmoteDIctionary Server)就是其中之一。
Redis是一個性能極高、數據類型豐富、功能全面的KV(鍵,值)資料庫。根據其官網描述在50個並發的情況下寫入速度是11萬次/秒,讀出速度8.1萬次/秒。數據類型除了基本的string數據類型外還有hash,list,set,sorted set等數據結構類型。Redis在集群部署中提供了數據的主從節點複製功能。
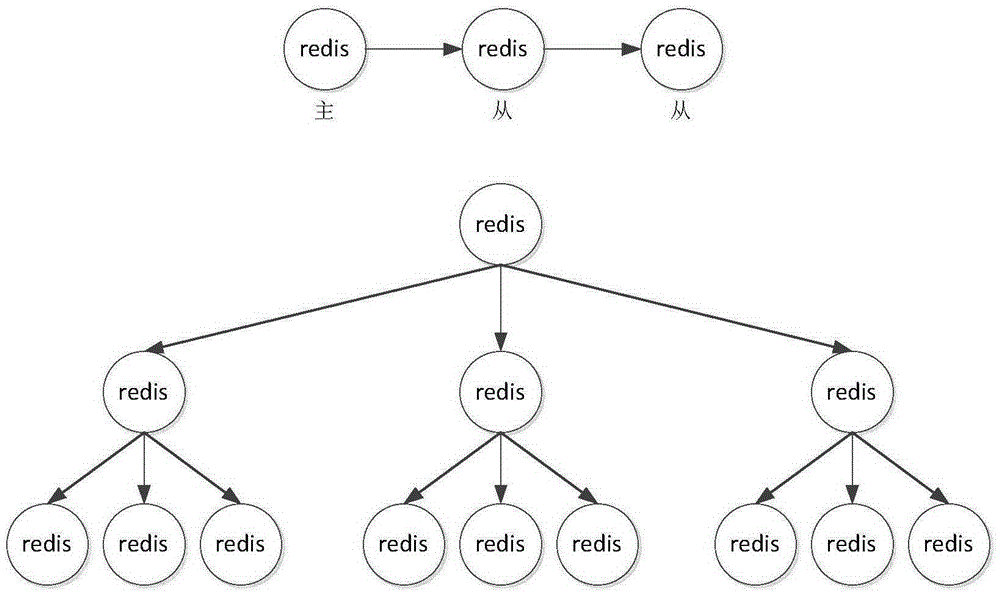
網際網路業務應用系統因其提供的服務在性能和實時性響應上的特殊要求大量使用Redis作為數據存儲載體,集群部署中也使用了Redis的主從複製功能,出現了主從複製鏈、主從複製樹形結構(複製鏈的增強版),如圖1所示,每個Redis節點都是數據的全量,使用上基本是Redis的「主」節點接受數據寫入,數據由「主」節點複製到「從」節點,應用程式在「從」節點讀取數據的方式。
在業務系統使用過程中,Redis的這種部署方式對數據一致性、實時性和擴展性上面都給了業務系統不錯的支撐。數據實時性、一致性在Redis高效的主從複製上的到了很好的保證。集群擴展性上,擴展集群只是意味著增加複製鏈(樹)型結構的節點即可,十分簡單。但是在使用Redis中 仍然碰到了一些問題。
首先,「主」節點存在「單點」問題,一旦「主」節點所在伺服器硬體故障或者網絡分區導致「主」節點相對「從」節點或應用伺服器不可訪問就會導致數據無法寫入問題,此時必須更換「主」節點進行數據寫入,並且「原主」節點所有的「從」節點也要進行主從節點的變更,使其從於「新主」節點接受數據更新,如圖2所示,換主期間左右兩個Redis子樹的數據會被「新主節點」全量覆蓋,在數據同步的過程中服務不可用。
其次,在使用過程中會有同城不同機房間的機器調整,此過程中會有手工的「摘掉」節點、「掛」新節點的動作,如圖3所示,整個過程數據全量複製一次時間比較長,期間數據全量複製,被調整節點的服務不可用。
再次,如果有異地機房之間的數據需要複製,問題將會更加嚴重,如圖4,一旦全量複製數據,數據同步期間服務不可用。
以上幾種情況將會出現一個共同的問題,主從節點之間數據全量複製,並且在全量複製期間不能提供服務,如果節點數據量比較大、複製時間長問題將會加劇。原生態的Redis在主從複製的實現上有全量複製和增量複製兩種方式,全量複製由於複製數據量大需要較長的時間才能完成,因此Redis2.8版本後出現了增量複製,但是增量複製只適用於主從節點短時間連結斷開,數據更新量不是很大(沒有超過主節點日誌範圍)的情況。全量複製由於其耗時較長(複製期間會出現服務不可用)應該被儘量的避免,而在上述示例的幾種情況下都會出的全量複製,如果網絡環境不好導致複製時間較長的話這一缺點將更加突出。實際上在「複製樹」結構中由於Redis的主從複製機制,各個節點數據更新相差不大,在調整結構過程中即便不是直接的主從節點關係,理論上也可以通過拷貝差異數據來實現增量複製。
技術實現要素:
(一)要解決的技術問題
鑑於上述問題,本發明的目的在於,提供一種Redis中主從節點數據同步方法,解決現有Redis主從節點之間所提供的數據同步方式的低效問題,最大限度的減少了服務不可用的時間和由此帶來的運維不便。
(二)技術方案
本發明提供一種Redis中主從節點數據同步方法,用於將Redis樹型結構中主節點和從節點的數據進行同步,同一樹型結構中的節點具有相同的基因ID,不同樹型結構間的節點具有不同的基因ID,方法包括:
S1,從節點向主節點發送數據同步請求,其中,該數據同步請求包含有從節點的基因ID;
S2,主節點接收到該數據同步請求後,判斷從節點的基因ID與主節點的基因ID是否一致,若一致,則通過增量複製的方式將主節點上的數據複製到所述從節點,否則,通過全量複製的方式將主節點上的數據複製到所述從節點。
(三)有益效果
本發明提供的Redis中主從節點數據同步方法,在同一顆樹中,將數據相差不大的主從節點進行增量同步,解決現有Redis主從節點之間所提供的數據同步方式的低效問題,使得業務應用客戶端在數據存儲故障或手工數據遷移過程中最大限度的減少了服務不可用的時間,帶來了較好的用戶體驗。
附圖說明
圖1-圖4是現有技術Redis中主從複製樹形結構的示意圖。
圖5是本發明實施例提供的Redis節點複製樹型結構。
圖6是本發明實施例提供的主從節點進行增量複製的判定示意圖。
圖7是現有技術和本發明實施例提供的主從節點斷開重連時進行數據同步的示意圖。
圖8是本發明實施例提供的主從節點斷開後命令執行的示意圖。
圖9是現有技術和本實施例的寫性能壓力測試的對比圖。
圖10是現有技術和本實施例的讀性能壓力測試的對比圖。
具體實施方式
本發明提供一種Redis中主從節點數據同步方法,通過主從節點基因ID,判斷其是否處於同一顆樹上,若是,則進行數據增量複製;另外,主 從節點建立連接並進行全量同步數據時,主節點將基準偏移量傳遞給從節點,保證主從節點斷開重連後對應的命令保持一致;再者,在從節點連接新主節點時,先斷開連接,再在從節點中增加標誌位,避免從節點自動重新跟原主節點建立連接,解決了主從日誌數據順序不一致的問題。
根據本發明的一種實施方式,Redis中主從節點數據同步方法包括:
S1,從節點向主節點發送數據同步請求,其中,該數據同步請求包含有從節點的基因ID,所述基因ID是標識不同Redis樹型結構的ID;
S2,主節點接收到該數據同步請求後,判斷從節點的基因ID與主節點的基因ID是否一致,若一致,則通過增量複製的方式將主節點上的數據複製到所述從節點,否則,通過全量複製的方式將主節點上的數據複製到所述從節點。
根據本發明的一種實施方式,主從節點採用環形隊列存儲日誌,並且,數據同步請求包括從節點的偏移量,其中,在步驟S2中,若從節點的基因ID與主節點的基因ID一致,則判斷偏移量是否存在於所述日誌,若是,則通過增量複製的方式將主節點上的數據複製到所述從節點,否則,通過全量複製的方式將主節點上的數據複製到從節點。
根據本發明的一種實施方式,通過全量複製的方式將主節點上的數據複製到從節點時,將主節點的基準偏移量傳遞給從節點,以使得主從節點中日誌對應的命令相同。
根據本發明的一種實施方式,在數據同步期間,禁止ping命令寫入日誌。
根據本發明的一種實施方式,當從節點欲與新主節點連接時,首先斷開從節點與原主節點的連接,然後在從節點中增加標誌位,以避免從節點自動重新與所述原主節點建立連接。
為使本發明的目的、技術方案和優點更加清楚明白,以下結合具體實施例,並參照附圖,對本發明進一步詳細說明。
圖5是本發明實施例提供的Redis節點複製樹型結構,如圖5所示,同一棵Redis複製樹型結構上的所有節點如同一個家族的成員,節點(父子節點,兄弟姐妹節點)之間是有血緣關係的或者說是有相同的「基因」的。具有相同「基因」的節點時能夠進行增量複製的前提,因此,在本實施例 中,每個節點都會繼承父節點的「基因ID」,凡是具有「血緣」關係或說有相同「基因ID」的節點之間原則上都可以做增量同步。因此在從節點通過psync(partial sync)命令向主節點進行數據同步時應先檢查是否有相同的「基因ID」,具有相同」基因ID「的節點可以接受增量複製的請求。
圖6是本發明實施例提供的主從節點進行增量複製的判定示意圖,如圖6所示,Redis數據存儲上使用了一種環形隊列的結構來存儲日誌(backlog),環形隊列大小可以通過配置項來定製,從節點向主節點請求同步數據的時候會傳入「基因ID」和偏移量(offset)。主節點接收到請求的時候會首先判斷是否來自相同複製樹型結構進而判斷是否支持增量同步方式。
圖7是現有技術和本發明實施例提供的主從節點斷開重連時進行數據同步的示意圖,Redis中的Backlog用來緩存主節點傳遞給從節點的Redis命令,如果主從節點之間出現斷開重連的情況,主節點通過傳遞給從節點缺少的命令來實現部分同步。而偏移量就是用來確定傳遞命令的範圍的。從節點在給主節點發送psync命令時傳遞的偏移量是從主節點接收到的最新命令對應在主節點Backlog的偏移量。由於Backlog的大小固定並且是滾動使用的,所以偏移量實際上是所有寫入過Backlog的命令的累加值。當從節點創建Backlog時,偏移量從0開始計算,如圖7中左圖所示,雖然數據Backlog最後一條命令是相同的,但是對應的偏移量不一致。為了支持同一複製樹內任意兩個節點的部分同步,需要通過傳遞基準偏移量(base offset)來保證相同的偏移量在複製樹內任意節點所對應的命令相同,如圖7中右圖所示。因此,本實施例主從節點建立連接首次全量同步數據時,將基準偏移量傳遞給從節點,這樣在複製樹內同一偏移量在任意兩個節點所對應的命令就能保持一致了。
此外,為了保持backlog數據的一致性,對一些Redis命令還需要做一些特殊處理。例如,Redis會根據配置文件周期性的向backlog內寫入ping命令並傳遞給所有從節點,為了保持數據一致性我們將禁止ping命令寫入backlog。
從節點連接新主節點的過程中應該避免接收到原主節點的數據。雖然Redis的slaveof no one可以實現類似的功能,但是如果從節點有當前包含 標記為expire但還沒有釋放的數據,一旦expire時間到達會在從節點觸發del命令同時將del命令寫入backlog。這種從節點自發修改(不是由主節點觸發)backlog的行為,會產生主從backlog數據順序不一致的問題。如圖8所示,主從斷開前有「EXPIRE a 60」執行,代表60秒後a將被清除(主節點60秒後自動調用DEL),如果清除前主從斷開(通過從節點執行slaveof no one命令),同時主節點有新數據寫入「SET b 2」,60秒後斷開的主從會分別執行DEL命令,這就導致主從相同的offset對應的命令不同。
為了避免這類問題,本實施例採用「暫停主從同步」的Redis命令,該命令首先斷開主從連接阻止主從數據複製,然後增加標誌位避免從節點自動重新跟主節點建立連接。
圖9是現有技術和本實施例的寫性能壓力測試的對比圖。相比現有技術,本實施例的Redis從節點在作為葉子時也需要創建並維護backlog,所以在寫入的最大TPS要低,但由於差異比例小,對實際性能影響不大。
圖10是現有技術和本實施例的讀性能壓力測試的對比圖。相比現有技術,本實施例的Redis從節點需要對一些影響backlog offset的命令進行過濾,所以最大TPS略低。但由於差異比例小,對性能影響不大。
綜上所述,本發明通過主從節點基因ID,判斷其是否處於同一顆樹上,若是,則進行數據增量複製;另外,主從節點建立連接並進行全量同步數據時,主節點將基準偏移量傳遞給從節點,保證主從節點斷開重連後對應的命令保持一致;再者,在從節點連接新主節點時,先斷開連接,再在從節點中增加標誌位,避免從節點自動重新跟原主節點建立連接,解決了主從日誌數據順序不一致的問題,提高了數據同步效率,基本消除了暫停服務,方便了對Redis集群的運維。
以上所述的具體實施例,對本發明的目的、技術方案和有益效果進行了進一步詳細說明,所應理解的是,以上所述僅為本發明的具體實施例而已,並不用於限制本發明,凡在本發明的精神和原則之內,所做的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。