可加載個性化特徵模型的語音識別系統及方法與流程
2023-12-08 23:13:26 2
本發明涉及嵌入式語音識別技術領域,具體地,涉及一種可加載個性化特徵模型的語音識別系統及方法。
背景技術:
基於按鍵及觸控螢幕的人機接口技術已經非常成熟,並且大大提高了人們操作設備便利性,而語音作為人類的自然界面,利用語音識別來控制操作設備的技術才開始起步,一方面是因為語音識別技術非常複雜,另一方面是嵌入式計算能力不足,即使在pc機上驗證的算法很難移植到嵌入式系統中。
技術實現要素:
針對現有技術中的缺陷,本發明的目的是提供一種可加載個性化特徵模型的語音識別系統及方法,其可以用於語音控制ui的技術,且可以加載個性化特徵模型,大大提高識別率及識別的可靠性。
根據本發明的一個方面,提供一種可加載個性化特徵模型的語音識別系統,所述可加載個性化特徵模型的語音識別系統包括:
語音編解碼晶片,用於將接收到的模擬語音信號進行a/d轉換得到數字音頻信號,及將數位訊號處理器後的數字音頻信號進行d/a轉換為模擬語音信號;
數位訊號處理器,用於對輸入的數字音頻信號進行語音識別算法處理,識別完成後將識別的結果語音合成為輸出數字音頻信號,發送給語音編解碼晶片進行語音輸出;
flash晶片,用於存儲數位訊號處理器的語音識別程序及通用語音模型數據,上電啟動後,程序及通用語音模型數據從flash晶片加載到ddrram晶片中;
ddrram晶片,用於運行語音識別程序,存儲通用語音模型數據及個性化特徵模型數據;
串口晶片,數位訊號處理器通過串口晶片和外部通信,數位訊號處理器通過串口晶片和外部通信,通過串口給出識別出的詞彙對應的漢字碼;
網絡晶片,當某人口音特別嚴重時,利用通用語音模型識別時識別率小於95%,用於加載個性化特徵模型數據,以提高其識別率。
優選地,所述數位訊號處理器選用高性能低功耗的浮點型tms320c6748數位訊號處理器。
優選地,所述語音編解碼晶片需要支持多種採樣率。
優選地,所述網絡晶片選擇lan8710a型晶片。
優選地,所述數位訊號處理器的通信和語音編解碼晶片的通信都採取dma方式通信。
本發明提供一種可加載個性化特徵模型的語音識別方法,其包括如下步驟:
步驟一,系統上電後,首先將語音識別程序從flash晶片加載到ddrram晶片中,然後將通用語音模型數據加載到ddrram晶片中,開始運行準備語音識別;
步驟二,語音識別模塊上電程序運行後,系統進行識別按鍵檢測,檢測到識別按鍵按下後,開始控制音頻編解碼晶片,進行ad轉換接收語音信號,然後通過語音識別算法進行語音識別,同時系統檢測到識別按鍵抬起後,通過串口給出識別出的詞彙對應的漢字碼,同時將識別的詞彙進行語音合成,控制音頻編解碼晶片將合成的結果da轉換為模擬語音信號進行輸出;
步驟三,語音識別模塊運行中,如果檢測到模型切換按鍵按下,加載下一條個性化語音模型數據到ddrram晶片,如果沒有下一條個性化語音模型數據,加載通用語音模型數據到ddrram晶片中,後續語音識別將會使用新加載的模型進行語音識別;
步驟四,語音識別模塊運行中,如果接收到網絡加載的個性化語音模型數據,則將收到的個性化語音模型數據存儲到flash晶片中及ddrram晶片中,後續語音識別將會使用新加載的模型進行語音識別。
與現有技術相比,本發明具有如下的有益效果:本發明可以用於語音控制ui的技術,且可以加載個性化特徵模型,大大提高識別率及識別的可靠 性。
附圖說明
通過閱讀參照以下附圖對非限制性實施例所作的詳細描述,本發明的其它特徵、目的和優點將會變得更明顯:
圖1為本發明可加載個性化特徵模型的語音識別系統的原理框圖。
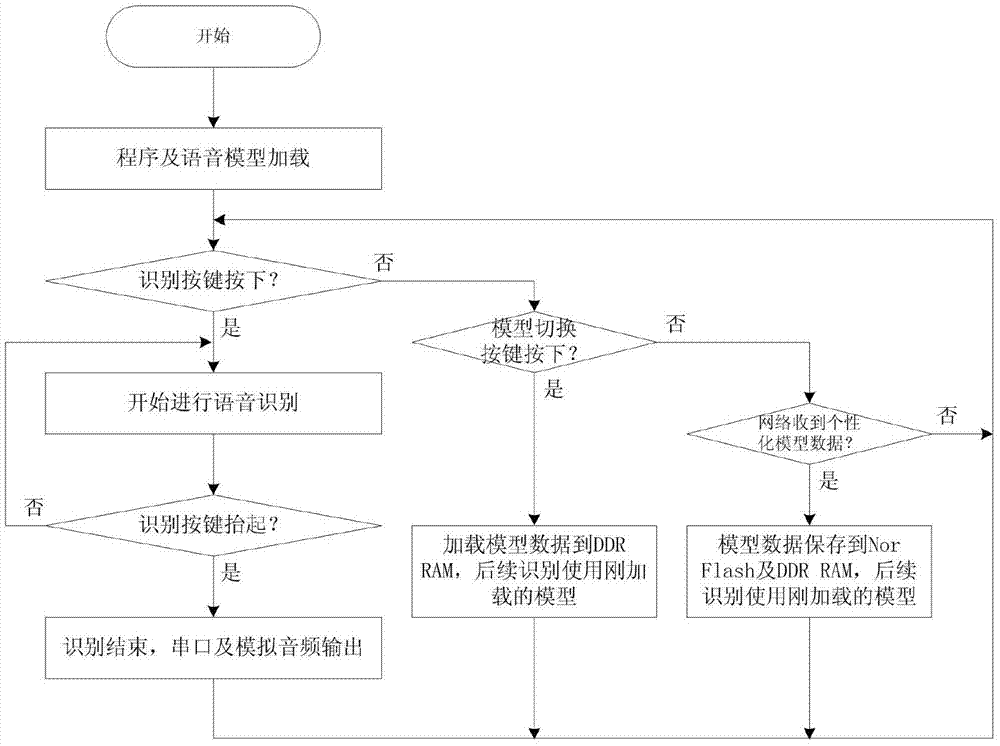
圖2為本發明可加載個性化特徵模型的語音識別方法的流程圖。
具體實施方式
下面結合具體實施例對本發明進行詳細說明。以下實施例將有助於本領域的技術人員進一步理解本發明,但不以任何形式限制本發明。應當指出的是,對本領域的普通技術人員來說,在不脫離本發明構思的前提下,還可以做出若干變形和改進。這些都屬於本發明的保護範圍。
如圖1所示,本發明可加載個性化特徵模型的語音識別系統包括:
語音編解碼晶片104,用於將接收到的模擬語音信號進行a/d轉換得到數字音頻信號,及將數位訊號處理器後的數字音頻信號進行d/a轉換為模擬語音信號;
數位訊號處理器(digitalsignalprocessor,dsp)101,用於對輸入的數字音頻信號進行語音識別算法處理,識別完成後將識別的結果語音合成為輸出數字音頻信號,發送給語音編解碼晶片進行語音輸出;
flash晶片102,用於存儲數位訊號處理器的語音識別程序及通用語音模型數據,上電啟動後,程序及通用語音模型數據從flash晶片加載到ddrram晶片中;
ddrram晶片103,用於運行語音識別程序,存儲通用語音模型數據及個性化特徵模型數據;
串口晶片105,dsp通過串口晶片和外部通信,,數位訊號處理器通過串口晶片和外部通信,通過串口給出識別出的詞彙對應的漢字碼;
網絡晶片106,當某人口音特別嚴重時,利用通用語音模型識別時識別率小於95%,用於加載個性化特徵模型數據,以提高其識別率。
本發明可加載個性化特徵模型的語音識別系統還可以包括鋰電池107,鋰電池用於給本發明可加載個性化特徵模型的語音識別系統供電。
作為一種實施方式,數位訊號處理器101可以選用高性能低功耗的浮點型tms320c6748dsp,同時,為了降低功耗,儘量減少處理器各接口的使用,在滿足算法處理的情況下,儘量降低處理器工作頻率。flash晶片102及ddrram晶片103選用市場上通用的並且本款數位訊號處理器能夠支持的晶片即可。串口晶片105可以選擇rs232、rs422、rs485任意一種標準的晶片。語音編解碼晶片104需要支持多種採樣率,如8khz、16khz、44.1khz等,採樣精度支持16bit、24bit。網絡晶片106可以選擇lan8710a型晶片。
作為一種實施方式,語音編解碼晶片被配置為16khz的採樣率,採樣精度為24bit。數位訊號處理器和語音編解碼晶片之間可以採用iis方式通信,每秒傳輸字節數位48k字節,為了降低數位訊號處理器的負擔,使數位訊號處理器主要運行識別程序,數位訊號處理器的通信和語音編解碼晶片的通信都採取dma(directmemoryaccess,直接內存存取)方式通信。
如圖2所示,本發明可加載個性化特徵模型的語音識別方法,包括如下步驟:
步驟一,系統上電後,首先將語音識別程序從flash晶片加載到ddrram晶片中,然後將通用語音模型數據加載到ddrram晶片中(如果有個性化語音模型數據,將個性化語音模型數據加載到ddrram晶片中),開始運行準備語音識別;
步驟二,語音識別模塊上電程序運行後,系統進行識別按鍵檢測,檢測到識別按鍵按下後,開始控制音頻編解碼晶片,進行ad轉換接收語音信號,然後通過語音識別算法進行語音識別,同時系統檢測到識別按鍵抬起後,通過串口給出識別出的詞彙對應的漢字碼,同時將識別的詞彙進行語音合成,控制音頻編解碼晶片將合成的結果da轉換為模擬語音信號進行輸出;
步驟三,語音識別模塊運行中,如果檢測到模型切換按鍵按下,加載下一條個性化語音模型數據到ddrram晶片,如果沒有下一條個性化語音模型數據,加載通用語音模型數據到ddrram晶片中,後續語音識別將會使用新加載的模型進行語音識別;
步驟四,語音識別模塊運行中,如果接收到網絡加載的個性化語音模型數據,則將收到的個性化語音模型數據存儲到flash晶片中及ddrram晶片中,後續語音識別將會使用新加載的模型進行語音識別。
以上對本發明的具體實施例進行了描述。需要理解的是,本發明並不局限於上述特定實施方式,本領域技術人員可以在權利要求的範圍內做出各種變形或修改,這並不影響本發明的實質內容。