基於卷積神經網絡的監控視頻中人車目標分類方法與流程
2023-08-22 10:24:16 2
本發明涉及一種基於卷積神經網絡的監控視頻中人車目標分類方法,屬於模式識別技術領域。
背景技術:
隨著社會的不斷發展,公共安全防範已經成為城市現代化的重要基礎,視頻監控系統作為安全防範系統的重要組成部分,發揮著重要的作用,在城市道路交通領域,廣泛使用視頻監控系統實時記錄人、車的交通行為,利用卷積神經網絡識別監控視頻中的人、車等目標,能夠極大的提高各類交通案件的處置效率。現有的監控視頻中人車分類方法,分類精度不高,且實時性不夠強。
技術實現要素:
鑑於上述原因,本發明的目的在於提供一種基於卷積神經網絡的監控視頻中人車目標分類方法,利用多角度的樣本圖片對卷積神經網絡進行有針對性的訓練、調整,能夠達到較高的人車分類準確率。
為實現上述目的,本發明採用以下技術方案:
一種基於卷積神經網絡的監控視頻中人車目標分類方法,包括:
s1:獲取多角度性的樣本集,並將樣本集劃分為訓練樣本集、驗證樣本集和測試樣本集;
s2:建立卷積神經網絡;
s3:將訓練樣本集中的樣本圖片先減去每個像素點對應的均值,然後作為訓練數據輸入該卷積神經網絡,進行有監督的學習,得到訓練後的卷積神經網絡的各層的參數;
s4:利用訓練後的卷積神經網絡的各層的參數,初始化與步驟s2中所述卷積神經網絡結構相同的卷積神經網絡,得到具有監控視頻中人車目標分類功能的圖像識別網絡。
所述步驟s1中,所述多角度性的樣本集的獲取方法是:
採集大量的監控視頻中的人、車、非人非車的圖片,將所有圖片縮放到同等像素大小的圖片,在所有圖片中添加用於區別人、車、非人非車圖片的標籤,對所有圖片進行鏡像、旋轉處理。
所述步驟s2中的卷積神經網絡包括兩個卷積層、兩個下採樣層,一個全 連接層,及softmax分類器,第一卷積層濾波器的大小為5×5像素,特徵圖為6個,第一下採樣層濾波器的大小為2×2像素,特徵圖為6個,第二卷積層濾波器的大小為5×5像素,特徵圖為16個,第二下採樣層濾波器的大小為2×2像素,特徵圖為16個,全連接層的特徵圖為120個,softmax分類器輸出三種類型的目標:人、車、其他。
對所有圖片進行水平鏡像處理,然後沿水平方向旋轉10度。
本發明的優點是:
1、採集大量的監控視頻中的圖片,並對圖片進行預處理,增加了不同樣本圖片之間的差異性,在此基礎上對卷積神經網絡進行有針對性的訓練、調整,能夠達到較高的分類準確率,保證了分類過程的實時性;
2、採用機器自學習的方法,減少了人為幹預,使卷積神經網絡能夠學習到全面的人車特徵,網絡的泛化能力強。
附圖說明
圖1是本發明的卷積神經網絡的結構示意圖。
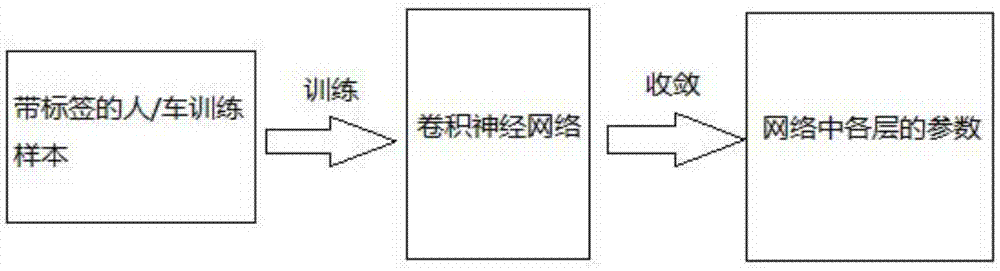
圖2是本發明的卷積神經網絡的訓練過程圖。
圖3是利用本發明的卷積神經網絡進行分類的過程圖。
具體實施方式
如圖1至3所示,本發明公開的基於卷積神經網絡的監控視頻中人車目標分類方法,包括以下步驟:
s1:獲取樣本集,並將樣本集劃分為訓練樣本集、驗證樣本集和測試樣本集;
採集大量的監控視頻中的人、車、非人非車的圖片,將所有圖片縮放到32×32像素大小,對所有圖片於每個像素點進行平均值計算,並在所有圖片中添加標籤,例如,在有人的圖片中添加0,在有車的圖片中添加1,在非人非車的圖片中添加2;
之後,對所有圖片進行預處理後作為樣本圖片,預處理包括圖片的鏡像、旋轉處理,鏡像方式為水平鏡像,旋轉角度為沿水平方向旋轉10度;預處理後得到的樣本圖片具有全面、豐富的多角度特徵,且增大了不同樣本圖片(人、車、其他)之間的差異性。
將所有樣本圖片分成訓練樣本集(佔總樣本的85%)、驗證樣本集(佔總樣本的10%)和測試樣本集(佔總樣本的5%)。
s2:建立卷積神經網絡;
如圖1所示,本發明建立的卷積神經網絡包括兩個卷積層、兩個下採樣層,一個全連接層,及softmax分類器。第一卷積層濾波器的大小為5×5像素,特徵圖為6個,第一下採樣層濾波器的大小為2×2像素,特徵圖為6個,第二卷積層濾波器的大小為5×5像素,特徵圖為16個,第二下採樣層濾波器的大小為2×2像素,特徵圖為16個,全連接層的特徵圖為120個,softmax分類器輸出三種類型的目標:人、車、其他。
s3:將訓練樣本集中的樣本圖片先減去每個像素點對應的均值,然後作為訓練數據輸入卷積神經網絡,進行帶標籤的有監督的學習,得到訓練後的卷積神經網絡的各層的參數;
訓練過程中,採用隨機梯度下降法調整卷積神經網絡中各層的參數,觀察卷積神經網絡在驗證樣本集上的準確率變化,並調整卷積神經網絡的學習率,確保卷積神經網絡在訓練樣本集上收斂並在驗證樣本集上達到較高的分類準確率,當卷積神經網絡收斂後(準確率達到設定的閾值),保存卷積神經網絡中各層的參數。
s4:利用訓練後的卷積神經網絡的各層的參數,初始化同樣結構的卷積神經網絡,得到具有監控視頻中人車目標分類功能的圖像識別網絡。
後續即可利用該圖像識別網絡對測試樣本集進行測試、分類。
於一具體實施例中,使用的訓練樣本集大小為24000張身份證照片,驗證樣本集的大小為2823張身份證照片,測試樣本集的大小為1411張監控視頻中的人、車、非人非車的圖片,測試前,先將測試樣本集的樣本圖片減去每個像素對應的均值,然後輸入圖像識別網絡,最終該圖像識別網絡在測試樣本集上的分類準確率達到了86%,由於樣本圖片具有多角度性,因而分類準確率較高。
以上所述是本發明的較佳實施例及其所運用的技術原理,對於本領域的技術人員來說,在不背離本發明的精神和範圍的情況下,任何基於本發明技術方案基礎上的等效變換、簡單替換等顯而易見的改變,均屬於本發明保護範圍之內。
技術特徵:
技術總結
本發明公開一種基於卷積神經網絡的監控視頻中人車目標分類方法,包括:獲取多角度性的樣本集,並將樣本集劃分為訓練樣本集、驗證樣本集和測試樣本集;建立卷積神經網絡;將訓練樣本集中的樣本圖片先減去每個像素點對應的均值,然後作為訓練數據輸入該卷積神經網絡,進行有監督的學習,得到訓練後的卷積神經網絡的各層的參數;利用訓練後的卷積神經網絡的各層的參數,初始化相同結構的卷積神經網絡,得到具有監控視頻中人車目標分類功能的圖像識別網絡。本發明利用多角度的樣本圖片對卷積神經網絡進行有針對性的訓練、調整,能夠達到較高的人車分類準確率。
技術研發人員:付景林;孟漢峰;侯玉成;張新中;王芊;丁明鋒;鞠秀芳;柳炯;李永豐;王允升;楊永強;姜曉偉
受保護的技術使用者:北京大唐高鴻軟體技術有限公司
技術研發日:2015.12.29
技術公布日:2017.07.07