一種基於GRNN組合模型的城市日供水量預測方法與流程
2023-05-17 20:47:26 4
本發明涉及一種基於GRNN組合模型的城市日供水量預測方法,特別是一種基於混沌理論局域法—GRNN組合模型的城市日供水量預測方法,屬於預測、城市企業供水系統的優化調度領域。
背景技術:
城市供水系統是城市建設的重要組成部分之一,完善的供水系統對促進城市工農業生產、保障人民身體健康以及保護環境免遭汙染等都具有積極作用。近年來,隨著城市化進程的推進和社會經濟的快速發展,居民生活水平的提高,城市供水量大大增加。
由於城市供水系統範圍及規模的逐年擴大,供水複雜性在逐年提升,從而導致了與此相關的城市供水系統的調度篩選方案及調度複雜性的提高。而當前多數中小城市供水調度決策依舊停留在傳統經驗的基礎上,即根據日常經驗判斷、或根據流量表與壓力表數據判斷。前者盲目依靠經驗判斷,後者缺乏預知性(滯後性),容易造成①供水過度造成管網壓力偏高,增加水資源漏損或水管爆裂風險的機率;②供水富餘,消耗大量電能;③供水不足,影響用水等不良後果。所以,傳統供水系統調度方式面臨著巨大的挑戰,對城市供水系統的調度進行優化是必要的。而城市企業供水系統的優化調度主要包括三個環節:供水量預測、運行工況模擬和供水系統調度決策。在這三個環節中,供水量的預測工作是後兩個環節的基礎和前提,其準確度真接影響到供水系統工況模擬結果的合理性和調度決策模型的針對性和可靠性,所以預測環節的研究顯得尤為重要。
供水量預測一般分為傳統預測方法和基於新技術的方法。傳統預測方法是基於統計學理論發展而來的,主要建模方法有回歸分析法、指數平滑法、趨勢外推法、移動平均法等。此類方法使用時要對數據序列性質進行假設,若假設條件合理,得出的結果較為理想,反之,則預測模型將會嚴重失真。為克服傳統預測方法的缺點,基於新技術的預測方法主要選擇非線性的、自適應的學習方法來進行模型的構建,為非線性非平穩時間序列的預測研究提供了有力的工具。如混沌理論局域法的特點是可較好地辨識重構後相空間的系統運動規律,很好地追蹤供水系統的總體運動趨勢,且具有擬合速度快且精度較高等優點。而人工神經網絡則具有很強的信息綜合能力,能恰當地協調好歷史用水數據中的「偽數據」,對網絡進行動態的學習修正,能給出較準確的預測結果。但在實際工程中,當時間序列的非線性非平穩性特徵較強、噪聲較大時,即便是一種新技術預測模型也往往得不到滿意的結果,這就需要多種模型組合才可能收到較好的結果。鑑於此,學者們提出了許多組合模型來提高供水量預測效果,而混沌理論與人工神經網絡作為處理非線性系統問題的有效工具,二者的結合對尋求新的途徑和方法對城市供水量等預測研究,具有重要的意義。
技術實現要素:
本發明要解決的技術問題是提供一種基於GRNN組合模型的城市日供水量預測方法,可以利用歷史運動規律來推斷出系統總體運動趨勢的特點及GRNN在樣本數據較少的情況下對預測誤差修正效果依然很好的優勢,將混沌理論局域法與GRNN神經網絡有機結合,減少預測用時並解決神經網絡預測值隨機的固有缺點,提高時間序列預測的準確性。
本發明採用的技術方案是:一種基於GRNN組合模型的城市日供水量預測方法,包括如下步驟:
(1)重構相空間:設混沌時間序列{x1,x2,…,xN},則重構相空間為:
X(ti)=[x(ti),x(ti+2τ),…,x(ti+(m-1)τ)]
(i=1,2,…N-(m-1)τ) (1)
式中τ為時間延遲,m為嵌入維數,
(2)計算鄰近相點:設中心點XM的鄰近相點集為{XMi,i=1,2,…q},{XMi}中每個相點 到中心點XM的歐式距離為di,設di中的最小值為dmin,定義{XMi}的權值為Pi,則
di=‖XM-XMi‖2 (2)
(3)演化追蹤法選擇鄰近相點:
先根據歐氏距離法得XM的K(K≤N-(m+1)τ)個初始鄰近相點Xi0(i=1,2,…,K),再根據歐氏距離得XM的上一步演化點XM-1的K個初始鄰近相點Xi1(i=1,2,…,K);再根據歐氏距離得XM的上兩步演化點XM-2的K個初始鄰近相點Xi2(i=1,2,…,K);如果Xi0的上一步演化點在點集{Xi1,i=1,2,…,K}中,且Xi0的上兩步演化點在點集{Xi2,i=1,2,…,K}中,則點Xi是中心點XM的真鄰近相點(即Xi=Xi0∩Xi1∩Xi2),否則為偽鄰近相點,同理依次判斷剩餘的相點;
(4)參數計算:設{XMi}的S步演化相點集為{XMi+S},加權一階多步局域法線性擬合為:
XMi+S=aSe+bSXMi,i=1,2,…q (4)
式中aS和bS為待求的擬合參數,
設線性方程組(4)的矩陣表達式為:
Y=Ax (5)
式中Y=XMi+S,A=[eXMi],x=[aS bS]T;
定義目標函數為:
f(x)=(Ax-Y)TP(Ax-Y) (6)
其中P為權重係數矩陣;依據多元函數的極值理論,目標函數取得最小解的充要條件是:
則可得參數aS、bS的矩陣表達式:
(5)求解預測值:將aS、bS,帶入S步預測公式XMi+S=aSe+bSXMi,即可得到演化S步後的相點預測值XMi+S:
XMi+S=(xMi+S,xMi+S+τ,…xMi+S+(m-1)τ) (9)
這裡,XMi+S中的第m個元素xMi+S+(m-1)τ即為原序列的S步預測值xN+S;
(6)混沌理論局域法預測出的下一步相點XMi+S中前m-1個分量實際上是原時間序列中的點,將這m-1個點與原時間序列對應的點作差,得到誤差值;
(7)將這m-1個誤差數據作為GRNN神經網絡的訓練樣本,預測出第m個點的誤差值Em;
(8)用誤差值Em對預測得到的相點XMi+1的第m個分量xMi+S+(m-1)τ進行誤差修正,輸出預測值xN+S。
本發明具有的有益效果是:本發明採用一種新的組合模型預測方式來解決城市日供水量預測精度低,誤差波動大等缺點,本方法能夠準確預測出城市日供水量,模型收斂速度快、預測精度較高且解決了神經網絡預測值隨機的固有缺點,可行性強,通過本方法有助於提高城市日供水量的預測精度,可為運行工況模擬和供水系統調度決策提供依據與技術支持。
附圖說明
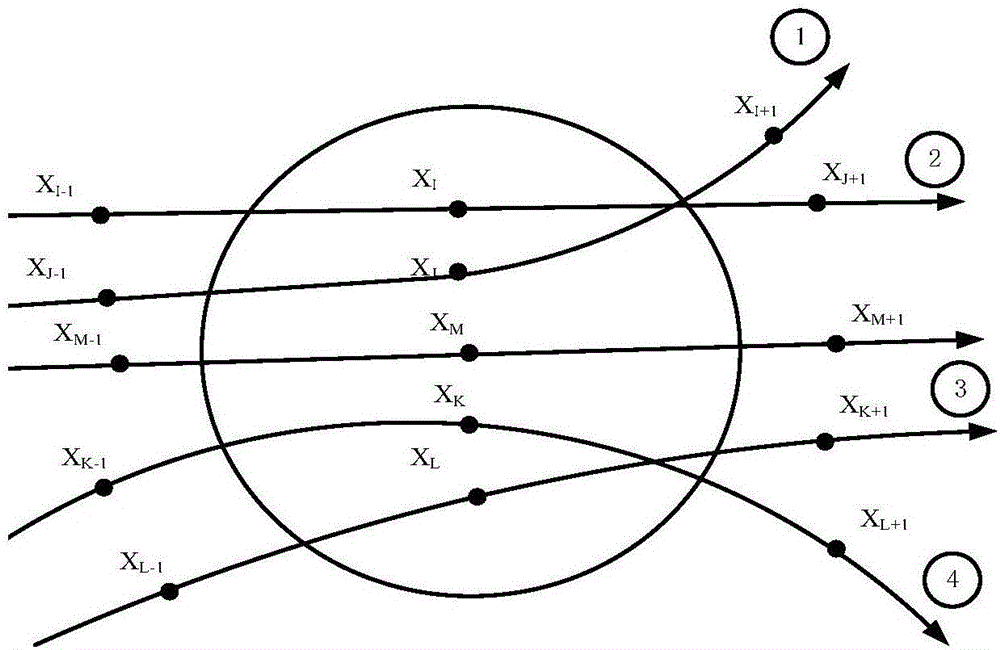
圖1為本發明預測中心點及其鄰近相點的演化示意圖;
圖2為混沌理論局域法—GRNN組合模型預測方法流程圖;
圖3為方法程序的構成文件圖;
圖4為A市1#水廠日供水量預測結果圖;
圖5為A市1#水廠日供水量局部預測細節對比圖;
具體實施方式
下面結合附圖和具體實施例對本發明作進一步說明。
實施例1:如圖1-5所示,一種基於GRNN組合模型的城市日供水量預測方法,其特徵
(1)重構相空間:設混沌時間序列{x1,x2,…,xN},則重構相空間為:
X(ti)=[x(ti),x(ti+2τ),…,x(ti+(m-1)τ)]
(i=1,2,…N-(m-1)τ) (1)
式中τ為時間延遲,m為嵌入維數,
(2)計算鄰近相點:設中心點XM的鄰近相點集為{XMi,i=1,2,…q},{XMi}中每個相點到中心點XM的歐式距離為di,設di中的最小值為dmin,定義{XMi}的權值為Pi,則
di=∥XM-XMi∥2 (2)
(3)演化追蹤法選擇鄰近相點:
在相空間重構中,鄰近的相點具有相似的演化行為,預測點的運動趨勢就是通過各鄰近相點的運動趨勢推斷而來,這是混沌局域法預測的基本前提和預測依據。如圖1所示,XI、XJ、XK、XL均是滿足歐式距離要求的XM的鄰近相點,XI-1、XJ-1、XK-1、XL-1分別是各自的上一步歷史相點,XI+1、XJ+1、XK+1、XL+1則是各自的下一步演化相點。圖1中①②③④四條軌線分別代表了鄰近相點的四類可能演化情況。XJ與XM的歷史相點XJ-1與XM-1很接近,但演化相點XJ+1與XM+1卻相距甚遠,說明兩個相點的演化趨勢差逐漸增大,鄰近相點XJ不能預示XM的發展方向,是偽鄰近相點;XI和XM對應的歷史相點、演化相點皆接近,是理想的參考鄰近相點;XL與XM的歷史相點XL-1與XM-1雖然距離較大,但演化相點XL+1卻趨近於XM+1,說明與目標相點的演化行為趨於一致,是較好的參考點;XK與XM的歷史相點XK-1與XM-1、演化相點XK+1與XM+1都相距較大,與預測相點XM+1的演化行為無關聯性,是偽鄰近相點。
若中心點XM及其歷史演化點XM-n與對應的鄰近相點「一直鄰近」,即說明在中心點與鄰近相點運動趨勢相同,進而推出預測點演化規律相同,而演化追蹤法就是為了找出這些「一直鄰近」的鄰近相點。
本發明先根據歐氏距離法得XM的K(K≤N-(m+1)τ)個初始鄰近相點Xi0(i=1,2,…,K),再根據歐氏距離得XM的上一步演化點XM-1的K個初始鄰近相點Xi1(i=1,2,…,K);再根據歐氏距離得XM的上兩步演化點XM-2的K個初始鄰近相點Xi2(i=1,2,…,K);如果Xi0的上一步演化點在點集{Xi1,i=1,2,…,K}中,且Xi0的上兩步演化點在點集{Xi2,i=1,2,…,K}中,則點Xi是中心點XM的真鄰近相點(即Xi=Xi0∩Xi1∩Xi2),否則為偽鄰近相點,同理依次判斷剩餘的相點;
(4)參數計算:設{XMi}的S步演化相點集為{XMi+S},加權一階多步局域法線性擬合為:
XMi+S=aSe+bSXMi,i=1,2,…q (4)
式中aS和bS為待求的擬合參數,
設線性方程組(4)的矩陣表達式為:
Y=Ax (5)
式中Y=XMi+S,A=[e XMi],x=[aS bS]T;
定義目標函數為:
f(x)=(Ax-Y)TP(Ax-Y) (6)
其中P為權重係數矩陣;依據多元函數的極值理論,目標函數取得最小解的充要條件是:
則可得參數aS、bS的矩陣表達式:
(5)求解預測值:將aS、bS,帶入S步預測公式XMi+S=aSe+bSXMi,即可得到演化S步後的相點預測值XMi+S:
XMi+S=(xMi+S,xMi+S+τ,…xMi+S+(m-1)τ) (9)
這裡,XMi+S中的第m個元素xMi+S+(m-1)τ即為原序列的S步預測值xN+S,
(6)混沌理論局域法預測出的下一步相點XMi+S中前m-1個分量實際上是原時間序列中的點,將這m-1個點與原時間序列對應的點作差,得到誤差值;
(7)將這m-1個誤差數據作為GRNN神經網絡的訓練樣本,預測出第m個點的誤差值Em;
(8)用誤差值Em對預測得到的相點XMi+1的第m個分量xMi+S+(m-1)τ進行誤差修正,輸出預測值xN+S。
現有技術中多數混沌理論和神經網絡組合的預測研究都只將相空間重構與神經網絡的結合,沒有充分利用不同的預測模型對不同時間序列的跟蹤特性,例如,傳統供水量預測組合模型利用相空間構造輸入樣本X為相空間前m-1個列向量,輸出樣本Y為相空間第m個列向量,最後輸入到RBF神經網絡中訓練,以獲得RBF預測模型。或將混沌時序的相空間嵌入維數m作為網絡的輸入層節點數,每個數據間相差τ個時間點,即x(ti),x(ti+2τ),…x(ti+(m-1)τ)作為神經網絡的輸入,輸出層節點為1,x(ti+(m-1)τ)為輸出預測值。而混沌理論的特點是可較好地辨識重構後相空間的系統運動規律,很好地追蹤供水系統的總體運動趨勢,人工神經網絡則具有很強的信息綜合能力,能恰當地協調好歷史用水數據中的「偽參考數據」,對網絡進行動態的學習修正,並給出較準確的預測結果。鑑於此,本發明充分利用混沌理論局域法可依據歷史運動規律來推斷出系統總體運動趨勢的特點及廣義回歸神經網絡(GRNN)在樣本數據較少的情況下對預測誤差修正效果依然很好的優勢,將混沌理論局域法與GRNN神經網絡有機結合,減少預測用時並解決神經網絡預測值隨機的固有缺點,提高時間序列預測的準確性。
如圖2所示,本方法在Matlab中編寫了混沌理論局域法—GRNN組合模型預測方法程序,與已有方法相比,本方法運用的混沌理論局域法可不必事先建立主觀模型,直接根據數據序列本身所計算出來的客觀規律進行預測,避免了預測的人為主觀性,而GRNN中由於只有一個閾值,人為調節參數很少,網絡的學習全部依賴數據樣本,也使得網絡最大可能地避免人為主觀假定對預測結果的影響,這就提高了本方法預測的精度和可信度。
本方法程序在MATLAB R2014a(32位)的環境下開發與運行,作業系統可為win7、win8、或win10。如圖3所示,本方法程序構成:(1)在Matlab裡編寫程序的原始碼(CLMGRNN.m);(2)示例數據(DATA.xlsx)。
將程序的原始碼與示例數據放在一個文件夾內,將該文件夾在Matlab中置於當前路徑,鍵入CLMGRNN。程序結束時,窗口界面會輸出預測結果和預測相對誤差,並輸出圖形。
舉例說明:A市1#水廠和B市2#水廠自2000年1月至2006年12月的日供水系統可看作 是混沌系統。為消除年供水量時間序列的季節性和趨勢性、減少噪聲影響,選取A市1#水廠和B市2#水廠的2000~2006年每年1月的日供水量數據作為單獨的時間序列進行預測,對於其它月份的預測可按此方法進行處理。本文用互信息法計算A市1#水廠和B市2#水廠日供水量的時間延遲分別為τA=7,τB=7。用GP法求A市1#水廠和B市2#水廠日供水量的嵌入維分別為mA=10,mB=12,用演化追蹤法選取A市1#水廠和B市2#水廠日供水量的鄰近相點分別為KA=7,KB=10。
通過混沌理論局域法—GRNN預測模型,A市1#水廠日供水量預測結果如圖4所示,A市1#水廠日供水量局部預測細節對比圖如圖5所示。
如圖4、5所示,7種方法都能較好預測日供水量總體趨勢,而對局部細節預測有一定差異。對預測結果按精度排序,將平均絕對誤差(MAPE)最小的置於首位,如表1所示。混沌局域法與GRNN組合模型預測精度最高,單一的RBF神經網絡預測精度最低。此外,組合預測模型的精度都高於相應的單一模型,由於採用小樣本訓練神經網絡,其運算時間僅為3s,達到了同時提高預測結果精度及計算效率的目的。
預測值精度檢驗公式為
其中:n為樣本數據的個數,Pi為相對百分比誤差。
表.1A市1#水廠預測相對誤差
表.2B市2#水廠預測相對誤差
以上實施例僅用以說明本發明的技術方案較一般日供水量預測模型預測精度更高且非個例,儘管參照較佳實施例對本發明進行了詳細說明,本領域的普通技術人員應當理解,可以對本發明的技術方案進行修改或者等同替換,而不脫離本發明技術方案的宗旨和範圍,其均應涵蓋在本發明的權利要求範圍當中。