一種基於TegraX1雷達數據的無人車障礙物檢測方法與流程
2023-05-01 22:48:56 2
本發明屬於無人駕駛領域,尤其涉及一種基於Tegra X1雷達數據的無人車障礙物檢測方法。
背景技術:
近年來,隨著傳感器技術、控制系統、人工智慧的不斷發展,地面移動機器人取得了很大的進步。在現實動態環境中,自主機器人在環境感知中能夠穩定準確的檢測障礙物和識別障礙物類型,對於路徑規劃建立運動模型可以起到很大幫助,從而做出智能決策行為。通常自主機器人在環境中主要有兩大類動態物體:車輛和行人。對於車輛,在交通中是主要的交互對象,速度比較快,需要保持一定的安全距離,在交通規則允許的情況下需要選擇是跟車還是超車.對於行人,由於行人的運動具有很大的隨意性,需要保持較大的橫向距離,以確保行人安全。
利用安裝在智能車上的多傳感器系統,比如攝像機、雷射、毫米波雷達、GPS、慣導等獲取車輛前方的障礙物信息及本車的位置和姿態信息,然後在車載計算機上根據己建立的駕駛行為專家系統對這些信息進行處理,當本車與前方障礙物的相對距離小於安全距離時,有碰撞危險發生,則計算機會直接發出相應指令控制汽車減速甚至是剎車等動作。同時,通過傳感器系統,智能車也能夠識別道路中的各種交通標誌牌,車道邊緣線等,並利用決策層的指令實現超車,匯入車流等本車動作。因此,智能車大大提高了交通系統的安全性和效率。在可使用的傳感器中,Velodyne雷射雷達由於其高精度測距、探測範圍大、抗幹擾能力強等優點,近年來在移動機器人上的應用越來越廣泛。但由於該雷達數據過大,處理算法的運算量極大,所以實時性較差,因此在複雜環境下,並不能及時將障礙物信息發送到決策。
技術實現要素:
針對雷射雷達工程應用中實時性需求問題,本發明提供一種基於Tegra X1雷達數據的無人車障礙物檢測加速方法。
本發明的基本思想為根據Tegra X1計算平臺的特點,採用CPU+GPU協調工作的方法來進行雷達數據的加速處理。本發明結合雷射雷達在智能車實際應用情況,將道路環境分為簡單道路環境和複雜道路環境。並在此基礎上,針對不同情況,對相應的算法進行優化,實現雷達數據處理加速,提高了智能車雷達數據處理的實時性。
為現實上述目的,本發明採用如下的技術方案:
一種基於Tegra X1雷達數據的無人車障礙物檢測方法,包括以下步驟:
步驟1、採用velodyne雷射雷達作為傳感器採集環境信息,通過NVIDIA Tegra X1移動處理器進行三維雷達數據轉換;
步驟2、基於柵格的障礙物檢測,採用GPU處理柵格數據,包括三個步驟:
將三維數據點投影到柵格地圖上;
將所有柵格相對高度大於某個閾值的柵格設定為障礙物點;
濾去所有因柵格內存在懸空點而導致屬性為障礙物的柵格。
作為優選,採用向量化的方法將雷達點雲數據投影到柵格地圖上,通過三維雷達數據轉換過程中,將轉換後的點雲數據以float4的數據格式保存,以warp為處理單位並行獲取障礙信息。
本發明的方法與現有技術相比,有效的提高無人車障礙物檢測的實時性,有如下特點:
1、根據Tegra X1 arm和GPU之間訪存帶寬,我們利用pinned memory來降低了CPU與GPU之間的傳輸消耗。
2、在簡單道路環境的障礙物檢測上,我們採用一個線程處理一個柵格的方法來處理雷達數據,對比工控機的雷達處理性能有了6~7倍的提升。
3、在複雜道路環境的障礙物檢測上,我們採用一個線程束處理一個柵格的方法來處理雷達數據,對比工控機的雷達處理性能有了5~6倍的提升。
附圖說明
圖1為本發明無人車障礙物檢測方法的流程圖;
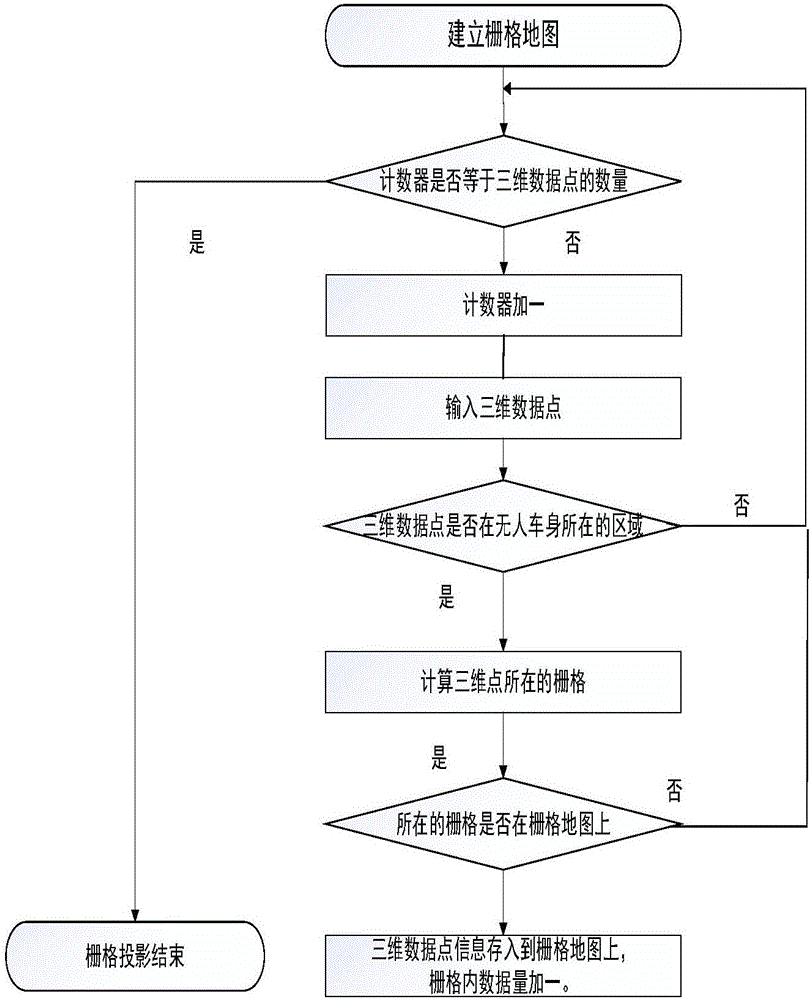
圖2為柵格投影流程圖;
圖3為pinned memory和pageable memory帶寬對比圖;
圖4為柵格屬性判斷流程圖;
圖5為thread處理柵格流程圖;
圖6為warp處理柵格流程圖。
具體實施方式
本發明提供一種基於Tegra X1雷達數據的無人車障礙物檢測方法,採用velodyne雷射雷達作為傳感器採集環境信息,搭載NVIDIA Tegra X1移動處理器,實現無人車障礙物檢測。為更進一步說明本發明在技術內容,創新點效果好,以下結合實施方式並配合附圖詳細說明。
如圖1所示,本發明方法分為兩個步驟:1、三維雷達數據轉換2、障礙物檢測
由於三維雷達數據轉換過程中,擁有著較多的複雜邏輯處理和事務管理,因此該過程不適合放入GPU中進行運算。因此本發明通過使用NVIDIA Tegra X1 arm處理器來處理該過程。
由於雷達點雲數據量非常大(約130萬個點/秒),不太適合直接在原始數據上進行處理。因此採用在國內外無人自主車系統中廣泛採用的柵格處理方法來處理雷達點雲數據。
基於柵格的障礙物檢測分為三個步驟:
1、柵格投影
2、柵格屬性判斷
3、柵格濾波
柵格投影是將三維數據點投影到柵格地圖上,其具體算法流程如圖2所示。本發明採用向量化的方法將雷達點雲數據投影到柵格地圖上。通過三維雷達數據轉換過程中,將轉換後的點雲數據以float4的數據格式保存。從而可以通過單指令多數據的方法將雷達點雲數據投影到柵格地圖上,提高arm處理器的處理性能。通過分析柵格數據,可知柵格之間毫無依賴關係,即有良好的並行性,因此採用GPU處理柵格數據。
在寫內核函數之前,需要考慮GPU與CPU之間的傳輸效率的問題。host內存分為pageable memory和pinned memory兩種。pageable memory是通過作業系統API(malloc,new)分配的存儲器空間;pinned memory始終存在於物理內存中,不會被分配到低速的虛擬內存中,能夠通過DMA加速與設備端進行通信。相比於pageable memory,在pinned memory上主機端-設備端的數據傳輸帶寬高。如圖3所示,在Tegra X1上,傳輸32MB的數據,在pinned memory上GPU與CPU的傳輸是pageable memory上GPU與CPU的傳輸的5~6倍。而且Tegra X1還支持zero-copy功能,通過該方法將主機端內存映射到設備地址空間,從GPU直接訪問,省掉主存與顯存間進行數據拷貝的工作。因此,本發明與傳統的方法所不同的是,我們結合Tegra X1的特性,將柵格地圖建立在pinned memory上,來降低傳輸消耗。
在完成柵格投影之後,需要進行的是柵格屬性判斷、柵格濾波兩個步驟。柵格屬性判斷是將所有柵格現對高度(柵格最高點減去最低點)大於某個閾值的柵格設定為障礙物點。其具體算法流程如圖4所示。柵格濾波是濾去所有因柵格內存在懸空點而導致屬性為障礙物的柵格。傳統的方法是先完成所有柵格完成屬性判斷後,再進行柵格濾波的任務。本發明對其進行了改進,去掉了傳統方法中存在的排序過程,將其改為求極值的問題。其次本發明將採用的是將柵格判斷和柵格濾波合併為一項任務,在結合GPU運算的特點,使得柵格不需要等待所以柵格都完成柵格判斷後再進行柵格濾波,從而提高處理性能。
GPU採用SIMT(Signal Instruction Multiple Thread,單指令多數據)編程模型,其調度和執行的基本單位是warp。其最終執行時間由執行時間最長的線程決定。因此本發明將道路環境分為兩種即簡單道路環境和複雜道路環境。
在簡單的道路環境中,由於道路障礙物數量少,所以三維點投影在柵格地圖的個數比較均衡。所以當採用一個線程處理一個柵格的方法來處理柵格數據,warp內線程的負載較為均衡,處理性能較高。其次本發明在求極值的過程中,通過減少條件分支,來減少動態指令,從而提高處理性能。使用?:語句代替if...else...語句是減少動態指令的主要方式。其具體算法流程如圖5所示。在該道路環境上,本發明的處理方法對比工控機的雷達處理方法的性能有了6~7倍的提升。
在複雜的道路環境中,由於障礙物數量多,所以三維點投影在柵格地圖的個數極度不均衡,因此當採用一個線程處理一個柵格的方法來處理柵格數據,warp內線程的負載極度不均衡,處理性能不高。針對這種情況,本發明採用了粗粒度並行的方法,選擇warp作為基本並行執行單元和任務分配單位即一個warp處理一個柵格。warp內的所有線程將協同完成分配給warp的計算任務。在求柵格的極值時,本發明通過使用Shuffle技術,取代一個線程處理一個柵格所需的單指令序列,增加有效帶寬和減少延遲。其次將處理完的數據放入共享內存中,用一個warp來存放結果,能有效的減少對全局內存的訪問。其具體算法流程如圖6所示。在該道路環境上,本發明的處理方法對比工控機的雷達處理方法的性能有了6~7倍的提升。
本發明通過CPU與GPU的協同工作實現了雷達數據在NVIDIA Tegra TX1移動處理器上的加速處理。算法加速的過程需要根據算法特點,設計實現到底層硬體架構特徵的高效映射。Tegra X1整合了四顆Cortex-A57核心和四顆Cortex-A53核心,同時Tegra X1擁有256採用Maxwell架構的GPU,這就需要在程序優化過程中,不僅要考慮算法特性,而且還要考慮底層硬體架構的特徵,最終還需要完成這兩種特徵的高效映射,才能實現基於Tegra X1雷達數據處理的加速。