基於密度峰值聚類的交通流量序列劃分方法與流程
2023-11-10 11:36:17 4
本發明涉及一種交通流量序列的劃分方法,具體是一種基於密度峰值聚類的交通流量序列劃分方法,屬於交通控制研究領域。
背景技術:
現有信號控制系統多具備自適應功能,主要依靠線圈檢測設備的檢測信息實時優化信號控制方案。而在實際應用中,線圈檢測器損壞和故障的發生率很高,且其它類型的檢測器數據,包括視頻、微波、地磁等均很難直接接入現有信號控制系統,致使很多信號控制系統和信號控制器只能被動採用固定式的配時方案。為了儘量提升交叉口的交通流運行效率,定時控制策略下的信號配時方案也必須根據交通流的時變特性進行相應的動態調整,通常以天為基本單元將整個時間長度劃分為若干單元,利用每個單元的平均交通流數據優化相應的信號控制方案,即多時段信號控制方案。
目前,信號控制的時段劃分多採用傳統的聚類方法,即將一天中所有時間區段的流量值看做樣本,根據樣本自身的屬性,用數學方法按照某種相似性或差異性指標,定量地確定樣本之間的親疏關係,並按這種親疏關係程度對樣本進行聚類,存在如下三點問題:1.多數方法不能自動優化合理的聚類數目,需要多次對比實驗數據得到最佳結果;2.具備自動輸出聚類數目和結果的方法多通過枚舉的方式,其計算時間複雜度較大;3.所有方法都僅局限於針對特定天的流量數據確定時段劃分方案,而沒有考慮不同天之間的流量變化規律亦有相似性,具有相似變化規律的若干天可以採用相同的時段劃分方案。因此,如果能夠針對較長時間範圍內的流量數據,以天為基本單元,首先通過密度峰值聚類的方法實現流量序列分類劃分,可以大大節約時段劃分的工作量。同時,一種時間複雜度小且能自動輸出聚類數目和方案的劃分方法必然可以大大提升結果的可靠度。
技術實現要素:
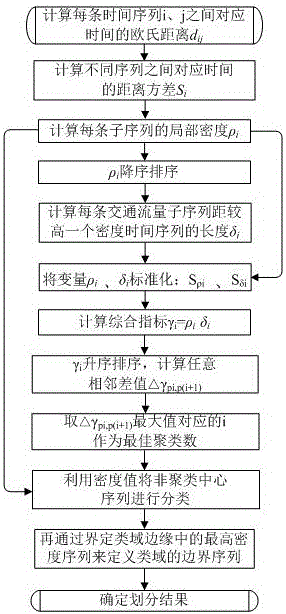
本發明的目的在於針對較長時間範圍內的流量數據(一般應包括15天以上的數據),以天為基本單元,將一個長時間序列的流量切片成若干子序列,實現子序列聚類數目和聚類結果的自動優化。
本發明的基本思想主要體現為以下兩點:1.每一類的聚類中心其密度值最大;2.聚類中心與其它具有較高密度數據的距離值較大。該方法的核心思想為利用距離方差衡量子序列的相似程度:計算每條子序列的局部密度衡量序列間相互聚集程度,序列間距離用于衡量類分離程度,結合局部密度和序列間距尋求聚類中心;利用密度值將非聚類中心序列進行分類,從而得到交通流量序列的合理分組,最終輸出聚類結果。
本發明的基本步驟如下:
c1、計算每條交通流量子序列的局部密度;
c2、按照局部密度對子序列進行排序,計算每條交通流量子序列距離一個較高密度的交通流量子序列的長度;
c3、定義一個綜合考慮密度值和距離值的指標,並計算每一個流量子序列下該指標的取值,根據綜合指標變化率趨勢圖得到最佳聚類數和聚類中心;
c4、利用密度值將非聚類中心序列進行分類,再通過界定類域邊緣中的最高密度序列來定義類域的邊界序列,確定劃分結果。
步驟c1的過程包括:
c11、以相等長度為時間間隔(一般取一天,即24小時),將交通流量序列劃分為n個子序列,子序列記為X=x1,x2,…,xn;
c12、針對任意一個子序列i,以固定時段為時間間隔將子序列劃分成若干區段,通常情況該固定時段取為5分鐘、10分鐘或者15分鐘;區段序列為xi=xi(1),xi(2),…,xi(N).
c13、計算每條子序列的局部密度ρi;
①假設i,j表示任意兩條子序列,則子序列i和j之間的歐氏距離dij:
式中:dij為第i、j序列之間對應時間的歐氏距離;r為時段序號;xi(k)為第i個子序列中第r個區段的流量值,N為每個子序列所包含的區段數。歐氏距離時間複雜度相對小,但對噪聲數據敏感。如果只需要知道相似程度或排序,無需單調函數平方根。
②計算不同子序列之間的距離方差:
式中:Si為i子序列與其它子序列之間所對應距離的方差;m為距離數,其值為n*(n-1)/2;為所有子序列距離的平均值,表達式為:
③計算每條子序列的局部密度:
式中:ρi為第i個子序列的局部密度;dc為截斷距離參數,其取值應使得序列的平均鄰居數是數據集中序列總數的1-2%。將計算得到m個距離數據dij,按大小進行排序;假設得到db1≤db2≤…≤dbm,取dc=df(mt),其中f(mt)表示對mt四捨五入得到的整數,t是數據集中序列總數的百分比,一般取1-2%;距離dij小於截斷距離dc的數值越多,密度值ρi越大,則子序列i周圍所聚集的子序列越多,以此衡量序列間相互聚集程度。
步驟c2的過程包括:
c21、將子序列的局部密度ρi按照大小進行排序ρq1≥ρq2≥,…,≥ρqi≥ρq(i+1)≥,…,≥ρqn,計算每條子序列距離一個較高密度子序列的長度:
式中:δqi為ρi按大小排序後,第qi個區段流量距離一個較高密度子序列的長度;dqiqj為ρi按大小排序後,第qi與qj個子序列之間的距離。當子序列xqi具有最大密度時,δqi表示所有子序列中與xqi的最大距離值;當子序列xqi的最大密度值小於最大密度時,δqi表示在所有局部密度大於xqi的子序列中,所有子序列與xqi之間的最小距離。
步驟c3的過程包括:
c31、將變量ρqi和δqi標準化:
式中:和分別表示變量ρqi和δqi標準化後結果;分別表示變量ρqi和δqi的平均值;σρ和σδ分別表示變量ρqi和δqi的標準差。
c32、引入一個將密度值和距離值綜合考慮的指標,其計算方法為:
式中:γqi為綜合考慮ρqi和δqi值的指標。
c33、將γqi按升序排序,令其排序為γp1≤γp2≤,…,≤γpi≤γp(i+1)≤,…,≤γpn,計算隨著數據不斷增大時數值任意相鄰γpi的差值,其計算方法為:
△γpi,p(i+1)=γp(i+1)-γpi (1-i)
式中,△γpi,p(i+1)為升序排序後第pi和p(i+1)個子序列的綜合指標差值;γp(i+1)和γpi分別表示升序排序後第p(i+1)和pi個子序列的綜合指標值。
c34、針對第pi個升序排序的綜合指標,可用pi與p(i-1)和p(i+1)之間的變化率比值作為衡量γpi穩定性的指標,即:
式中,ηpi為按照綜合指標升序排序後,第pi個子序列的穩定性係數。
c35、用ηpi衡量綜合指標的穩定性,並取穩定性係數最大值所對應的pi作為最佳聚類數kop。
c36、選取前kop個綜合指標最大的子序列作為聚類中心。
步驟c4的過程包括:
c41、利用密度值將非聚類中心序列進行分類:將每個非聚類中心子序列的密度值ρqi按照從大到小的順序進行排序,每個子序列被分到一個具有較高密度值的最近相鄰子序列所在的類當中。
c42、通過界定類域邊緣中的最高密度子序列來定義類域的邊界子序列:分配到該類中但與其他類中序列的距離小於dc的序列,計算兩者的密度平均值,取平均值中最高密度定義為ρz,類中密度高於ρz的序列作為類的核心部分,其餘作為類邊緣部分,也稱作噪聲。
本發明的有益效果:本發明提出了一種基於密度峰值聚類的交通流量序列分類方法,以天為基本時間單元,將一個長時間的交通流量切割成若干子序列,並實現子序列的自動、高效分類。同一類中的子序列均可採用相同的時段劃分方案和信號控制方案,在確保交通流運行效率的前提下,減少了定時控制策略下時段劃分和信號優化的工作量。
附圖說明
圖1算法實現過程流程圖;
圖2綜合指標γpi趨勢圖;
圖3γpi突變點判斷圖;
圖4聚類數決策圖;
圖5數據聚類決策結果圖;
圖6序列數據聚類轉化為2D平面結果圖;
圖7序列數據聚類結果圖。
具體實施方式
以某城市某交叉口24天的流量序列為例,對這24天的數據進行分類,具體實現流程見圖1。
1、將總流量序列以天為單元劃分成24個子序列,並計算每條子序列的局部密度:
(1)在24條子序列中,計算每兩條子序列之間的相似度,記24個子序列為X=x1,x2,…xn;
(2)針對任意一個子序列i,以固定時段為間隔將子序列劃分成若干區段,區段序列為xi=xi(1),xi(2),…,xi(N);通常情況下該固定時段取為5分鐘、10分鐘或者15分鐘。
①計算子序列i、j之間對應的歐氏距離dij:
②計算所有子序列距離的平均值:
③計算子序列i與其它子序列之間歐氏距離的方差:
(3)計算每條時間序列的局部密度
①計算截斷距離參數dc,將距離dij排序db1≤db2≤…≤dbm,f(mt)表示對mt四捨五入得到的整數:
dc=df(mt) (1-3)
②計算每條子序列的局部密度:
2、計算每條子序列距離一個較高密度子序列的長度,利用局部密度與距離值畫出決策圖,如附圖4所示。
(1)將ρi進行大小排序ρq1≥ρq2≥,…,≥ρqi≥ρq(i+1)≥,…,≥ρqn,當子序列xqi具有最大密度時,δqi表示所有子序列中與xqi之間的最大距離值:
(2)當子序列xqi沒有最大密度時,δqi表示在所有局部密度大於xqi的子序列中,所有子序列與xqi之間的最小距離值,即:
3、計算綜合指標值
(1)將變量ρqi、δqi標準化
①分別計算變量ρqi、δqi的平均值以及標準差σρ和σδ:
②分別計算ρqi、δqi的標準化結果和
③計算綜合指標大小:
(2)將γqi按升序排序,令其排序為γp1≤γp2≤,…,≤γpi≤γp(i+1)≤,…,≤γpn,計算隨著數據不斷增大時數值任意相鄰γpi的差值,其變化規律如圖3所示。
△γpi,p(i+1)=γp(i+1)-γpi (3-8)
(3)計算第pi個子序列的穩定性係數ηpi:
令第pi個子序列的穩定性係數最大,則最佳聚類數目kop為(n-pi+1),如附圖3所示;
(4)利用得到的最佳分類數kop在圖4中以右上角為起點向左下方向畫正方形,直到選擇前kop個點為止,所圈出來的點即為ρpi、δpi都明顯較大的點,所選擇的點如圖5,作為聚類中心得到序列數據分類轉化為2D平面結果圖,見圖6。
4、利用密度值將非聚類中心序列進行分類,再通過界定類域邊緣中的最高密度序列來定義類域的邊界序列。
(1)利用密度值將非聚類中心序列進行分類:將每個非聚類中心序列的密度值ρqi按照從大到小的順序進行排序,每個序列被分到一個具有較高密度值的最近相鄰子序列的類當中;
(2)通過界定類域邊緣中的最高密度序列來定義類域的邊界序列:分配到該類中但與其他類中序列的距離小於dc的序列,計算兩者的密度平均值,取平均值中最高密度定義為ρz,類中密度高於ρz的子序列作為類的核心部分,其餘作為類邊緣部分,也稱作噪聲。最終得到最後序列的分類結果,如圖7所示。
綜上,本發明涉及一種交通流量序列的劃分方法,具備劃分數目自動優化、計算複雜度較低的特點。本發明可將交叉口長時間的流量序列(連續若干天)以天為基本單位劃分成若干類,每一類的不同子序列之間具有相似的流量變化特性,在定時控制策略下可採用相同的時段劃分方案,為提高時段劃分的智能性與科學性、提升交叉口交通流的運行效率提供技術支持,屬於交通控制研究領域。