一種具有聽力保護功能的音效定製方法及系統與流程
2023-10-26 16:51:27 2
本發明涉及音頻調節領域、計算機軟體領域,特別涉及一種具有聽力保護功能的音效定製方法及系統。
背景技術:
智能設備(intelligentdevice)是指任何一種具有計算處理能力的設備、器械或者機器。功能完備的智能設備必須具備靈敏準確的感知功能、正確的思維與判斷功能以及行之有效的執行功能。
在聽力醫療行業中,有如下的幾種應用場景:
1、放大聲音。最常見的是助聽器,是通過一個線性放大電路,把聲音放大。相比用戶原先的聽力放大了聲音。
2、非線性放大。由於發現用戶的聽力損失不同頻率損失不一樣,模擬電路線性放大並不好,所以有人採用了基於dsp晶片的數字助聽器,經過嚴格的聽力測試之後,根據不同頻率給不同的補償量,使得助聽器非線性放大的聲音更適合用戶。
3、降噪與場景識別。由於戴助聽器總覺得有噪聲,雖然通過聲音數據模型的建立,通過對環境噪聲的識別,可以採用「降噪」的程序,但是用戶在不同場景下對有效聲音的需求並不一致。於是出現了通過智慧型手機的位置來判斷場景,進而使助聽器聲音處理程序自動切換不同的場景處理程序。
4、智能設備的使用。對聽障或困難人士來說同樣很重要,而佩戴助聽器打電話,總是有些不便。因此在最新的助聽器裡,已經有了與電話之間進行2.4ghz藍牙連接的助聽器。
智能設備能夠完成的功能越來越多,人們對智能設備的依賴也越來越強。隨著智能智能設備的發展,人們可以通過智能設備的麥克風和接入網絡的方式進行音頻傳送和音頻控制,常見的包括:微信、靈犀語音助手等等,從而極大的方便了社交和智能設備控制。
現有的智能設備由於型號不同,配置了不同的音頻晶片和麥克風,所以對聲音表現出不同的頻段和音量。經過研究發現,老人和小孩對某些頻段接受的範圍不一樣,而且不同頻段對老人和小孩的身體健康(主要是耳朵)會造成不同程度的傷害。
技術實現要素:
本發明要解決的技術問題是,有效地保護用戶聽力的具有聽力保護功能的音效定製方法。
解決上述技術問題,本發明提供了一種具有聽力保護功能的音效定製方法,包括如下步驟:
s1初始化音效包,
s2提交至後臺伺服器,
s3在所述後臺伺服器進行加密後儲存,
s4通過應用程式伺服器定義不同類型的音效包,
s5通過所述後臺伺服器下發音效包,
s6在設備上解析並播放所述音效包。
更進一步,所述s1中的初始化包括:
設置音效參數,上述每個聲道的音效參數為:125hz、250hz、500hz、700hz、1000hz1400hz、2000hz、4000hz、8000hz或者16000hz,
設置聲道,上述聲道至少包括:左聲道、右聲道、中置聲道、低音聲道、左環繞聲道或者右環繞聲道。
更進一步,所述s3中採用md5加密算法進行加密。
更進一步,所述後臺伺服器還包括:音效榜單模塊,用以建立一音效榜單,並根據不同音效分貝選取所述音效榜單上的音效包。
更進一步,所述後臺伺服器還包括:自適應調節模塊,用以記錄在設備中最近時間段內設置的音效參數。
更進一步,所述後臺伺服器還包括:第三方api接口模塊,用以作為社交伺服器的調用接口。
更進一步,所述s6設備包括:智能音箱、智慧型手機、智能盒子、智能tv、智能穿戴設備或者智能聽力輔助設備。
更進一步,方法還包括s7,在設備中播放模式包括:第一播放模式、第二播放模式或預設模式,
所述第一播放模式,用以作為為兒童播放模式,
所述第二播放模式,用以作為為老人播放模式,
所述預設模式,用以作為正常播放模式。
更進一步,所述s6中的設備上安裝:pc、安卓、iphone、wp、ipad或mac的客戶端。
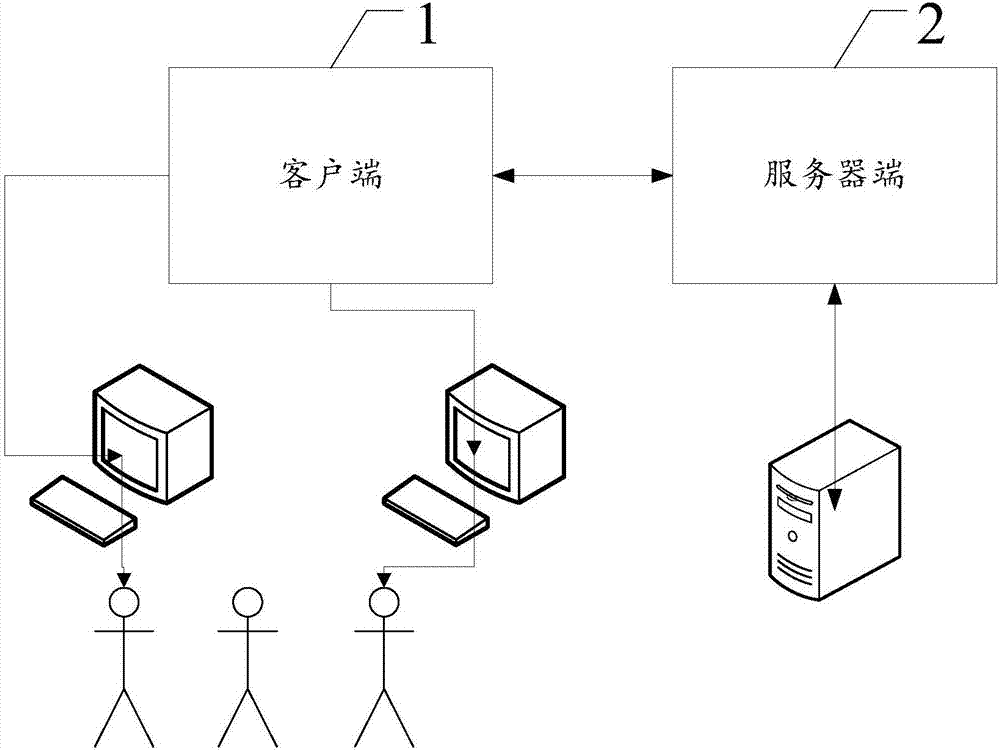
基於上述,本發明還提供了一種具有聽力保護功能的音效定製系統,包括:客戶端和伺服器端,
所述客戶端,用以初始化音效包,解析並播放從伺服器端下發的音效包,
所述伺服器端,用以進行加密後儲存,再通過應用程式伺服器定義不同類型的音效包後下發。
本發明的有益效果:
本發明中的具有聽力保護功能的音效定製方法,由於包括:初始化音效包,能夠對音效包實現預先設定和單獨的命名保存,提交至後臺伺服器,在所述後臺伺服器進行加密後儲存,通過應用程式伺服器定義不同類型的音效包,由於asp,asp.net、php,jsp都提供在html代碼中混合某種程序代碼,用戶通過瀏覽器瀏覽網頁時,web伺服器會調用對應的應用程式伺服器執行其中的程序代碼。通過所述後臺伺服器下發音效包,在設備上解析並播放所述音效包。
當在智能設備上進行播放時,本發明能夠保護聽力障礙或弱者的聽力,整理架構簡單,運維成本較低。
附圖說明
圖1是本發明一實施例中的方法流程示意圖;
圖2是本發明一實施例中的系統結構示意圖;
圖3是本發明一優選實施例中的系統結構示意圖;
圖4是本發明中的時序圖。
具體實施方式
現在將參考一些示例實施例描述本公開的原理。可以理解,這些實施例僅出於說明並且幫助本領域的技術人員理解和實施例本公開的目的而描述,而非建議對本公開的範圍的任何限制。在此描述的本公開的內容可以以下文描述的方式之外的各種方式實施。
如本文中所述,術語「包括」及其各種變體可以被理解為開放式術語,其意味著「包括但不限於」。術語「基於」可以被理解為「至少部分地基於」。術語「一個實施例」可以被理解為「至少一個實施例」。術語「另一實施例」可以被理解為「至少一個其它實施例」。
圖1是本發明一實施例中的方法流程示意圖,本實施例中的一種具有聽力保護功能的音效定製方法,包括如下步驟:
步驟s1初始化音效包,初始化時即將預先設定音效包進行命名並進行保存,
步驟s2提交至後臺伺服器,
步驟s3在所述後臺伺服器進行加密後儲存,
步驟s4通過應用程式伺服器定義不同類型的音效包,
步驟s5通過所述後臺伺服器下發音效包,
步驟s6在設備上解析並播放所述音效包。在具體實施例中,設備包括但不限於:移動終端,移動終端可以是智慧型手機、平板電腦及其他電子設備。
作為本實施例中的優選,在所述s1中的初始化包括:設置音效參數,上述每個聲道的音效參數為:125hz、250hz、500hz、700hz、1000hz1400hz、2000hz、4000hz、8000hz或者16000hz,設置聲道,上述聲道至少包括:左聲道、右聲道、中置聲道、低音聲道、左環繞聲道或者右環繞聲道。
作為本實施例中的優選,所述s3中採用md5加密算法進行加密。
作為本實施例中的優選,上述方法中的所述後臺伺服器還包括:音效榜單模塊,用以建立一音效榜單,並根據不同音效分貝選取所述音效榜單上的音效包。
作為本實施例中的優選,上述方法中的所述後臺伺服器還包括:自適應調節模塊,用以記錄在設備中最近時間段內設置的音效參數。
作為本實施例中的優選,上述方法中的所述後臺伺服器還包括:第三方api接口模塊,用以作為社交伺服器的調用接口。
作為本實施例中的優選,所述方法中的s6的設備包括:智能音箱、智慧型手機、智能盒子、智能tv、智能穿戴設備或者智能聽力輔助設備。
作為本實施例中的優選,上述方法中還包括s7,在設備中播放模式包括:第一播放模式、第二播放模式或預設模式,
所述第一播放模式,用以作為為兒童播放模式,
所述第二播放模式,用以作為為老人播放模式,
所述預設模式,用以作為正常播放模式。
作為本實施例中的優選,上述方法中的所述s6中的設備上安裝:pc、安卓、iphone、wp、ipad或mac的客戶端。
對於老人來說,低音會相對減小4db-8db,總音量增加5%-10%。對於小孩來說,低音會相對減小4db-8db,高音(2khz-20khz,減少3db-5db),總音量減少5%-10%。本發明保護聽力的目的是,預先設定音效包參數,可供老人、小孩選擇,音效包可根據智能設備或tv端進行自適應優化、調整。
如圖2是本發明一實施例中的系統結構示意圖,本實施例中的一種具有聽力保護功能的音效定製系統,包括:客戶端1和伺服器端2,所述客戶端1,用以初始化音效包,解析並播放從伺服器端下發的音效包,所述伺服器端2,用以進行加密後儲存,再通過應用程式伺服器定義不同類型的音效包後下發。
作為本實施例中的優選,上述初始化包括:
設置音效參數,上述每個聲道的音效參數為:125hz、250hz、500hz、700hz、1000hz1400hz、2000hz、4000hz、8000hz或者16000hz,
設置聲道,上述聲道至少包括:左聲道、右聲道、中置聲道、低音聲道、左環繞聲道或者右環繞聲道。
作為本實施例中的優選,伺服器端2中採用md5加密算法進行加密。
圖3是本發明一優選實施例中的系統結構示意圖,作為本實施例中的優選,所述後臺伺服器還包括:音效榜單模塊21,用以建立一音效榜單,並根據不同音效分貝選取所述音效榜單上的音效包。
圖3是本發明一優選實施例中的系統結構示意圖,作為本實施例中的優選,所述後臺伺服器還包括:自適應調節模塊23,用以記錄在設備中最近時間段內設置的音效參數。
圖3是本發明一優選實施例中的系統結構示意圖,作為本實施例中的優選,所述後臺伺服器還包括:第三方api接口模塊22,用以作為社交伺服器的調用接口。
作為本實施例中的優選,客戶端1安裝的設備包括:智能音箱、智慧型手機、智能盒子、智能tv、智能穿戴設備或者智能聽力輔助設備。
圖3是本發明一優選實施例中的系統結構示意圖,作為本實施例中的優選,在設備中上客戶端1播放模式包括:第一播放模式、第二播放模式或預設模式,
所述第一播放模式11,用以作為為兒童播放模式,
所述第二播放模式12,用以作為為老人播放模式,
所述預設模式13,用以作為正常播放模式。
設備上安裝:pc、安卓、iphone、wp、ipad或mac的客戶端。
對於老人來說,低音會相對減小4db-8db,總音量增加5%-10%。對於小孩來說,低音會相對減小4db-8db,高音(2khz-20khz,減少3db-5db),總音量減少5%-10%。本發明保護聽力的目的是,預先設定音效包參數,可供老人、小孩選擇,音效包可根據智能設備或tv端進行自適應優化、調整
請參考圖4是本發明中的時序圖,包括客戶端1和伺服器端2,
在所述客戶端1初始化音效包,並提交至後臺伺服器,
在所述伺服器端2進行加密後儲存,再通過應用程式伺服器定義不同類型的音效包,
在所述客戶端1向伺服器端2發出播放請求/調用,
在所述伺服器端2下發音效包,
在所述客戶端1所配置的設備上解析並播放所述音效包。
當在設備上進行播放時,本發明能夠保護聽力障礙或弱者的聽力,整理架構簡單,運維成本較低。
應當理解,本發明的各部分可以用硬體、軟體、固件或它們的組合來實現。在上述實施方式中,多個步驟或方法可以用存儲在存儲器中且由合適的指令執行系統執行的軟體或固件來實現。例如,如果用硬體來實現,和在另一實施方式中一樣,可用本領域公知的下列技術中的任一項或他們的組合來實現:具有用於對數據信號實現邏輯功能的邏輯門電路的離散邏輯電路,具有合適的組合邏輯門電路的專用集成電路,可編程門陣列(pga),現場可編程門陣列(fpga)等。
在本說明書的描述中,參考術語「一個實施例」、「一些實施例」、「示例」、「具體示例」、或「一些示例」等的描述意指結合該實施例或示例描述的具體特徵、結構、材料或者特點包含於本發明的至少一個實施例或示例中。在本說明書中,對上述術語的示意性表述不一定指的是相同的實施例或示例。而且,描述的具體特徵、結構、材料或者特點可以在任何的一個或多個實施例或示例中以合適的方式結合。
總體而言,本公開的各種實施例可以以硬體或專用電路、軟體、邏輯或其任意組合實施。一些方面可以以硬體實施,而其它一些方面可以以固件或軟體實施,該固件或軟體可以由控制器、微處理器或其它計算設備執行。雖然本公開的各種方面被示出和描述為框圖、流程圖或使用其它一些繪圖表示,但是可以理解本文描述的框、設備、系統、技術或方法可以以非限制性的方式以硬體、軟體、固件、專用電路或邏輯、通用硬體或控制器或其它計算設備或其一些組合實施。
此外,雖然操作以特定順序描述,但是這不應被理解為要求這類操作以所示的順序執行或是以順序序列執行,或是要求所有所示的操作被執行以實現期望結果。在一些情形下,多任務或並行處理可以是有利的。類似地,雖然若干具體實現方式的細節在上面的討論中被包含,但是這些不應被解釋為對本公開的範圍的任何限制,而是特徵的描述僅是針對具體實施例。在分離的一些實施例中描述的某些特徵也可以在單個實施例中組合地執行。相反對,在單個實施例中描述的各種特徵也可以在多個實施例中分離地實施或是以任何合適的子組合的方式實施。