一種基於改進ELM算法的毛管質量預報方法與流程
2023-10-08 12:55:54 3
本發明屬於回歸技術領域的質量預報技術,具體涉及一種基於改進elm算法的毛管質量預報方法。
背景技術:
穿孔作為無縫鋼管生產的第一道工序,對鋼管的質量有著十分重要的影響;穿孔過程產生的質量問題在後續過程中不但得不到緩解,而且會使鋼管產生更嚴重的質量問題;所以,建立利用採集的穿孔過程數據建立毛管質量預報模型對軋鋼工藝有著很重要的指導意義;常見的預測方法主要是基於時間序列法、卡爾曼濾波法、神經網絡、支持向量機(svm)等;時間序列方法預報的結果不穩定,其模型參數難以確定;神經網絡收斂速度慢,已陷入局部最優等缺陷;卡爾曼濾波法的狀態方程的建立需要對機理知識有一定的理解,對一般的建模者來說是一個挑戰;支持向量機的預報結果雖然精度能達到要求,但是耗時長。
elm算法2006年由huangg.b.第一次提出,是在單隱含層神經網絡(slfns)基礎上的延伸。與slfns不同的是,其隱含層節點數、隱含層參數與訓練數據無關,大大加快了elm的訓練速度,且泛化能力較優良。elm算法隨機生成隱含層參數,避免了梯度下降法調整參數,大大加快了運行速度;不會產生過擬合,避免陷入局部最優;理論證明elm算法具有訓練誤差越小,權重範數越小的性質,根據巴特利特理論知極限學習算法具有很好的泛化能力。對elm算法的研究和應用掀起了熱潮,增量式極限學習機、誤差最小極限學習機、l1/2正則化方法修剪極限學習機、op-elm等實現對elm算法的不斷改進和發展,elm算法成功的應用到分類、回歸、模式識別等領域;
通過查閱文獻對比知道,elm算法學習速度、泛化能力和可擴展性方面均有優勢;但是,當樣本數據存在噪聲幹擾時,elm模型的預報結果不穩定。
技術實現要素:
針對現有技術中毛管質量預報方法在樣本數據存在噪聲幹擾elm模型的預報結果不穩定等不足,本發明提出一種基於改進elm算法的毛管質量預報方法,以達到提高毛管預測準確性的目的。
為解決上述技術問題,本發明採用的技術方案是:
一種基於改進elm算法的毛管質量預報方法,包括以下步驟:
步驟1、採集毛管穿孔過程的多組歷史現場數據,構建訓練集;
步驟2、根據所採集的現場數據,確定集成elm網絡的輸入層、輸出層和隱含層;
步驟3、結合多個常用激勵函數,通過設置權重的方式,確定集成elm網絡的激勵函數;
步驟4、採用遺傳算法對集成elm網絡的激勵函數中每個權值進行優化,獲得最優激勵函數;
步驟5、採用訓練集對集成elm網絡進行訓練,完成集成elm網絡的構建,具體如下:
步驟5-1、利用交叉檢驗的方法確定集成elm網絡的子網絡個數;
步驟5-2、對訓練集中所有組數據進行訓練,每組數據分別在每個子網絡中進行訓練,完成集成elm網絡搭建;
步驟6、將實際生產中的數據輸入至集成elm網絡的每個子網絡中,獲得每個子網絡的輸出結果,進而獲得集成elm網絡的輸出預報結果,即獲得毛管質量的預報結果。
步驟1所述的現場數據,包括:上輥轉速實際值、下輥轉速實際值、上輥電流、下輥電流、上輥磁場、下輥磁場、上輥電機感應電動勢、下輥電機感應電動勢、止推小車的實際位置、上輥壓下實際值、下輥壓上實際值、上輥傾角實際值、下輥傾角實際值、右導盤位置實際值、左導盤位置實際值、推鋼機位置、上輥轉速實際值、下輥轉速實際值、上輥入口側溫度、上輥出口側溫度、下輥入口側溫度、下輥出口側溫度、右導盤電流和左導盤電流和縱向壁厚。
步驟2所述的根據所採集的現場數據,確定集成elm網絡的輸入層、輸出層和隱含層;具體為:將所採集的前24個數據作為集成elm網絡的輸入,將縱向壁厚作為集成elm網絡輸出,採用交叉檢驗的方法確定隱含層的個數。
步驟3所述的結合多個常用激勵函數,通過設置權重的方式,確定集成elm網絡的激勵函數;具體公式如下:
激勵函數具體公式如下:
g(x)=λ1·log(x)+λ2·hardlim(x)+λ3·satlin(x)(1)
其中,g(x)表示激勵函數,λ1表示log(x)函數的權值,λ2表示hardlim(x)函數的權值,λ3表示satlin(x)函數的權值,0≤λi≤1,i=1,2,3。
步驟4所述的採用遺傳算法對集成elm網絡的激勵函數中每個權值進行優化,獲得最優激勵函數;
步驟4-1、確定目標函數;
目標函數如下:
其中,f為目標函數,yi為採集的質量指標,為預報的質量指標,m為訓練集中數據的組數;
步驟4-2、確定待優化參數為激勵函數中權重值;
步驟4-3、確定染色體的個數為變量個數;
步驟4-4、根據目標函數確定適應度函數;
步驟4-5、確定遺傳算法的參數,包括:種群大小,迭代次數,染色體個數;
步驟4-6、運行遺傳算法,求取最優權值。
本發明優點:
本發明提出一種基於改進elm算法的毛管質量預報方法,主要以改進elm算法為核心,建立毛管穿孔過程質量預報模型,為提高elm預報模型的魯棒性及精度,進一步利用集成學習的elm模型算法搭建預報模型;主要利用取平均值、隨機優化取均值、ga優化權值的方法建立集成的elm算法;通過比較發現,單個elm模型的預報效果遠沒有集成網絡的效果準確;即集成的elm預報模型繼承了elm模型的快速的性能和集成方法的魯棒性,使得預報更加可靠準確;對於集成網絡,相對於均值集成,選擇後優化的效果很好,優化權值產生新的激勵函數的預報效果更佳,能更準確的預報毛管的質量。
附圖說明
圖1為本發明基於改進elm算法的毛管質量預報方法流程圖;
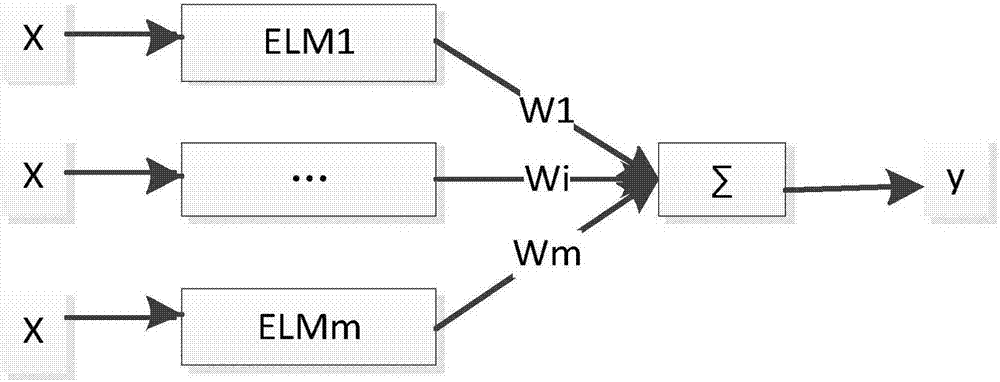
圖2為本發明中毛管質量的集成elm預報模型示意圖;
圖3(a)為本發明中多個elm網絡集成測試結果示意圖;
圖3(b)為多個elm網絡集成測試誤差示意圖;
圖4(a)為本發明中選擇集成的elm網絡集成測試結果示意圖;
圖4(b)為選擇集成的elm網絡集成測試結果示意圖;
圖5(a)為本發明中基於優化激活函數的穿孔過程集成elm網絡的預報結果示意圖
圖5(b)為集成的elm網絡預報誤差示意圖。
具體實施方式
下面結合附圖對本發明一種實施例做進一步說明。
本發明實施例中,基於改進elm算法的毛管質量預報方法,方法流程圖如圖1所示,包括以下步驟:
步驟1、採集毛管穿孔過程的40組歷史現場數據,構建訓練集;
本發明實施例中,採用寶鋼鋼管分公司sww斜軋穿孔機的實際測量歷史數據為樣本,共40組數據作為訓練數據,所述的現場數據,包括:上輥轉速實際值、下輥轉速實際值、上輥電流、下輥電流、上輥磁場、下輥磁場、上輥電機感應電動勢、下輥電機感應電動勢、止推小車的實際位置、上輥壓下實際值、下輥壓上實際值、上輥傾角實際值、下輥傾角實際值、右導盤位置實際值、左導盤位置實際值、推鋼機位置、上輥轉速實際值、下輥轉速實際值、上輥入口側溫度、上輥出口側溫度、下輥入口側溫度、下輥出口側溫度、右導盤電流和左導盤電流和縱向壁厚;
步驟2、根據所採集的現場數據,確定集成elm網絡的輸入層、輸出層和隱含層;
本發明實施例中,如圖2所示,將所採集的前24個數據作為集成elm網絡的輸入,將縱向壁厚作為集成elm網絡輸出,採用交叉檢驗的方法確定隱含層的個數,具體如下:
步驟2-1、初始化神經網絡結構:輸入變量24,輸出變量為1,採用交叉檢驗的方法確定隱含層為35個;確定神經網絡結構為24-35-1的連接方式,即輸入層神經元為24個,在網絡開始訓練的時刻,隱含層的神經元為35個,輸出層神經元1個;
步驟2-2、對神經網絡的權值進行隨機賦值;
本發明實施例中,對神經網絡的權值進行隨機賦值,其值為0到1的隨機數;
步驟3-3、定義誤差函數為:
其中,m為訓練集中數據的組數,和yi分別表示i時刻神經網絡的實際輸出和期望輸出;訓練動態前饋神經網絡的目的就是使得式(3)定義的誤差函數達到期望值。
附圖2中,x為elm網絡的輸入、wi為集成的m個elm網絡每一個網絡所佔有的權重。
步驟3、結合多個常用激勵函數,通過設置權重的方式,確定集成elm網絡的激勵函數;具體公式如下:
激勵函數具體公式如下:
g(x)=λ1·log(x)+λ2·hardlim(x)+λ3·satlin(x)(1)
其中,g(x)表示激勵函數,λ1表示log(x)函數的權值,λ2表示hardlim(x)函數的權值,λ3表示satlin(x)函數的權值,0≤λi≤1,i=1,2,3。
步驟4、採用遺傳算法對集成elm網絡的激勵函數中每個權值進行優化,獲得最優激勵函數;
步驟4-1、確定目標函數;
目標函數如下:
其中,f為目標函數,yi為採集的質量指標,為預報的質量指標,m為訓練集中數據的組數;
步驟4-2、確定待優化參數為激勵函數中權重值,選擇編碼類型為十進位;
步驟4-3、確定染色體的個數為變量個數,本發明實施例中,取值為3;
步驟4-4、根據目標函數確定適應度函數,本發明實施例中,適應度函數為fitness=-f;
步驟4-5、確定遺傳算法的參數,包括:種群大小30,迭代100次,染色體為3;
步驟4-6、運行遺傳算法,求取最優權值;
步驟5、採用訓練集對集成elm網絡進行訓練,完成集成elm網絡的構建,具體如下:
步驟5-1、利用交叉檢驗的方法確定集成elm網絡的子網絡個數,本發明實施例中,子網絡個數為11;
步驟5-2、對訓練集中40組數據進行訓練,每組數據分別在每個子網絡中進行訓練,完成集成elm網絡搭建;
步驟6、將實際生產中的數據輸入至集成elm網絡的每個子網絡中,獲得每個子網絡的輸出結果,進而獲得集成elm網絡的輸出預報結果,即獲得毛管質量的預報結果;
11個elm子網絡的輸出f1,f2,...f11,則集成的結果為:
最終,將作為這組數據最終的預報結果。
本發明實施例中,圖3(a)~3(b)、圖4(a)~4(b)、圖5(a)~5(b)所示,其測試誤差分別為0.0115,0.0078,0.0036,由數據分析知:對於集成網絡,相對於均值集成,選擇後優化的效果很好,優化權值產生新的激勵函數的預報效果更佳,能更準確的預報毛管的質量。