一種基於流量統計數據的訪問告警方法與流程
2023-09-22 21:40:55 2
本發明涉及一種基於流量統計數據的訪問告警方法,特別是涉及一種適用於大流量環境和複雜告警規則的,基於流量統計數據的訪問告警方法。
背景技術:
流量統計是指分析網絡中的原始數據包數據,計算各種網絡指標,並按照一定規則(ip,埠、會話等等)將結果分類並合併在一起,以便後續分析。
時間桶統計是指按時間桶:持續時長為n秒,並且開始時間戳為n的整數倍的時間段稱為時間桶。常用時間桶有1秒桶、1分鐘桶、1小時桶、1天桶等。如1秒桶是指任意一個時長為1秒的時間段;1分鐘桶是指開始時間戳為60的整數倍,並且時長為60秒的時間段;10分鐘桶是指開始時間戳為600的整數倍,並且時長為600秒的時間段;其他時間桶類推。
告警規則是指網絡元數據組合在一起形成的規則如:ip、埠、應用、協議等等。
黑名單為網絡流量與告警規則匹配時進行告警;白名單為網絡流量與告警規則不匹配進行告警。
維度是指規則中支持的網絡元數據的數量,如規則中只有ip,表示為一維、規則中包括ip和埠為二維;依次類推,維度越高實現的複雜度越高、性能越低。
隨著網絡流量環境的迅猛增長,針對大流量的高性能的分析解決方案需求越來越迫切。當前很多號稱支持大流量分析的系統都只能做一些基礎的流量分析功能,對用戶的作用有限。
本技術源於網絡數據分析領域,在網絡數據分析領域中經常需要對網絡中的異常數據流量、異常統計指標進行告警。如:某ip訪問某臺伺服器;某時間字節數大於特定閾值或者某ip發送數據包數大於特定閾值等等。但是受限於性能和複雜度這類告警在大流量環境中很少使用,即使使用也只能支持少量的簡單規則,且有諸多限制。
逐條匹配:循環對規則進行一一比對,這種方式實現最簡單,對規則沒有過多要求,可以支持一些較為複雜的規則,但是性能極低,數量有限,對於小流量環境還勉強適用。假設有m條規則,每秒鐘存在n條會話,那麼需要匹配的次數就是m*n次,其時間複雜度為o(m*n)。
哈希表匹配:哈希查表操作勝在速度極高,且不受規則數量的影響(可以達到百萬級規模),基本上接近到o(1)的性能,是一種在網絡分析領域使用極廣的算法;遺憾的是哈希表要求規則唯一,很多網絡分析領域的告警規則都需要考慮範圍,無法滿足唯一性要求(特定情形下可以將1個範圍轉換為n個非範圍規則,但會導致規則的規模急速上漲,內存資源無法滿足)。
不少流量統計軟體都有類似的訪問告警功能,但其在大流量環境下表現一般都不如人意;要麼是性能不足,難以支撐大流量的分析要求,要麼是告警規則簡單、支持數量有限,難以滿足用戶的使用需要。
技術實現要素:
本發明要解決的技術問題是提供一種基於流量統計數據的訪問告警方法,該方法能夠適用於大流量環境下,支持大量複雜規則的,高性能訪問告警功能。
本發明採用的技術方案如下:一種基於流量統計數據的訪問告警方法,具體方法為:網絡中的數據包經過分析,按照時間桶生成各種統計數據;生成的統計數據傳遞給存儲模塊進行存儲;警報模塊通過存儲模塊獲取統計數據,按照設定規則進行告警。
所述方法還包括,對設定規則進行預處理,形成一種樹形結構,通過對樹形結構的遍歷,完成對設定規則的匹配。
對設定規則進行預處理的具體方法為:將設定規則中每一個存在交叉的維度拆分為不同的樹節點,保證能夠在一次遍歷中得到正確的識別結果。
在系統中我們需要對「客戶端ip」、「服務端ip」、「服務端port」、「應用」和「協議」等5個維度組成的規則進行流量訪問告警;為了簡化規則配置,可能每個維度都需要支持範圍和*(地址需要支持ipv6);假定有如下規則:
如果網絡中出現了規則表示的流量則進行告警。可以看出規則的構成非常複雜,在規則數量巨大的情況下,採用常規的算法進行處理,基本不現實。
充分研究了規則構成後,我們對規則進行一些預處理,形成一種簡單的樹形結構,這樣對規則的匹配就變成了對這顆樹的遍歷;我們知道樹的深度是有限的,就是規則的維度。
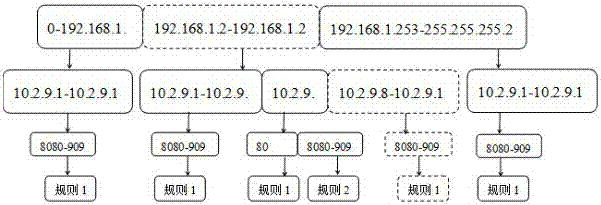
如圖1所示,為第一條設定規則預處理後的結果,圖2為第二條設定規則預處理後的結果。可以看到經過預處理後2條規則形成了複雜的樹形結構;規則中的每一個存在交叉的維度都會被拆分成不同的樹節點,保證能夠在一次遍歷中得到正確的識別結果。從2條規則的預處理我們可以發現規則中的維度交叉越厲害,被切分的樹節點會越多,樹的結構越複雜,消耗的內存也會越大,構建的時間也越長;但是無論多複雜的樹,一旦構建完成,其識別的效率只與樹的高度相關(維度),與樹的複雜度無關。
假如有如下待匹配流量:192.168.1.3,10.2.9.9,8189,http,tcp
通過對樹的遍歷我們可以得上圖中的虛線所示路徑,最終識別出規則1匹配即說明待匹配的流量會產生訪問告警。
隨著現在網絡中越來越多的使用ipv6協議,產生了對ipv6流量的分析處理的強列需求;我們知道ipv4可以由32位的整數表示;為了支持ipv6的規則在ipv6中以128位整數實現,以此表示ipv6。
所述方法還包括,採用雙緩存機制,對於需要重新修改並進行配置的設定規則,修改後放在一個地方進行預處理,與觸發任務中獲取到的設定規則互不幹擾;在預處理修改後的設定規則時,觸發任務依然使用本地存儲的配置好的內容進行告警,一旦預處理完成,觸發任務獲取新的配置好的設定規則,完成告警。由於所述設定規則越複雜,數量越大,則設定跪著預處理的時間也就越長,如果每次在獲取配置後才進行預處理,顯然會嚴重影響系統的性能。
所述方法還包括,設置一個定時器來定時產生觸發告警任務。採用定時器來觸發告警任務,以適應統計數據產生規律和降低系統的耦合性。如果在時間桶數據產生後直接觸發告警任務,則源於統計數據的產生規律,系統的耦合性會比較高。在本發明中,設置一個定時器去觸發,儘量和統計數據的生成分離,通過統一的查詢接口獲取統計數據,這樣一旦需要在觸發警報前對統計數據進行一些特殊處理就很方便。另外,直接觸發警報這樣的流程屬於串行的方式,不利於性能控制,一旦觸發性能不足會引起統計數據生成的性能下降,反之也是一樣的。分離雖然增加了額外的統計數據獲取的流程,但由於是分離的,可以獨立控制,互不幹擾。
所述定時器定時檢查時間桶統計數據是否已經產生,如果是,則觸發告警任務。
所述方法還包括,設定告警任務觸發統計數據在內存中存儲的最大時間或最大數據量;告警任務觸發後,檢查觸發告警任務的統計數據是否還在內存中,如果否,則丟棄這些數據不再觸發告警任務,避免性能進一步惡化(時間越久說明性能越低)。完成這一步後,緊接著需要獲取告警規則的「配置」和該觸發點的統計數據。
所述方法還包括,從緩存中獲取對告警需要的來自於查詢接口的統計數據,而非從磁碟中讀取,從而進一步提高系統的處理能力。
與現有技術相比,本發明的有益效果是:能夠適用於大流量環境下,支持大量複雜規則的,高性能訪問告警功能。
附圖說明
圖1為本發明其中一設定規則預處理的原理示意圖。
圖2為本發明其中一設定規則預處理的原理示意圖。
圖3為本發明其中一實施例的流量告警功能流程圖。
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,以下結合附圖及實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅用以解釋本發明,並不用於限定本發明。
本說明書(包括摘要和附圖)中公開的任一特徵,除非特別敘述,均可被其他等效或者具有類似目的的替代特徵加以替換。即,除非特別敘述,每個特徵只是一系列等效或類似特徵中的一個例子而已。
具體實施例1
如圖3所示,一種基於流量統計數據的訪問告警方法,具體方法為:網絡中的數據包經過分析,按照時間桶生成各種統計數據;生成的統計數據傳遞給存儲模塊進行存儲;警報模塊通過存儲模塊獲取統計數據,按照設定規則進行告警。
具體實施例2
在具體實施例1的基礎上,所述方法還包括,對設定規則進行預處理,形成一種樹形結構,通過對樹形結構的遍歷,完成對設定規則的匹配。
具體實施例3
在具體實施例2的基礎上,對設定規則進行預處理的具體方法為:將設定規則中每一個存在交叉的維度拆分為不同的樹節點,保證能夠在一次遍歷中得到正確的識別結果。
具體實施例4
在具體實施例1到3之一的基礎上,所述方法還包括,採用雙緩存機制,對於需要重新修改並進行配置的設定規則,修改後放在一個地方進行預處理,與觸發任務中獲取到的設定規則互不幹擾;在預處理修改後的設定規則時,觸發任務依然使用本地存儲的配置好的內容進行告警,一旦預處理完成,觸發任務獲取新的配置好的設定規則,完成告警。
具體實施例5
在具體實施例1到4之一的基礎上,所述方法還包括,設置一個定時器來定時產生觸發告警任務。不同的時間桶的產生具有很強的時間規律,如1秒、1分、1小時(時間桶);根據需要我們可以選則一個時間桶作為警報觸發的數據源(在本具體實施例中,採用分鐘桶。
具體實施例6
在具體實施例5的基礎上,所述定時器定時檢查時間桶統計數據是否已經產生,如果是,則觸發告警任務。在本具體實施例中,由於採用的分鐘桶,考慮到統計數據生成的延時性,定時器每數秒(如每5秒)運行一次。
具體實施例7
在具體實施例1到6之一的基礎上,所述方法還包括,設定告警任務觸發統計數據在內存中存儲的最大時間或最大數據量;告警任務觸發後,檢查觸發告警任務的統計數據是否還在內存中,如果否,則丟棄這些數據不再觸發告警任務。
具體實施例8
在具體實施例1到7之一的基礎上,所述方法還包括,從緩存中獲取對告警需要的來自於查詢接口的統計數據,而非從磁碟中讀取。
每一個時間桶產生的統計數據有很多條,需要對這些數據進行逐條告警,並產生告警日誌。依賴於前面提到的高性能告警算法,本發明申請方案可以達到30萬數據10萬規模的規則的秒內告警性能。