一種基於信息熵的超高維數據降維算法的製作方法
2023-05-31 10:30:41 3
本發明屬於高維數據預處理領域,更為具體地講,是一種基於信息熵改進的超高維數據降維算法。
背景技術:
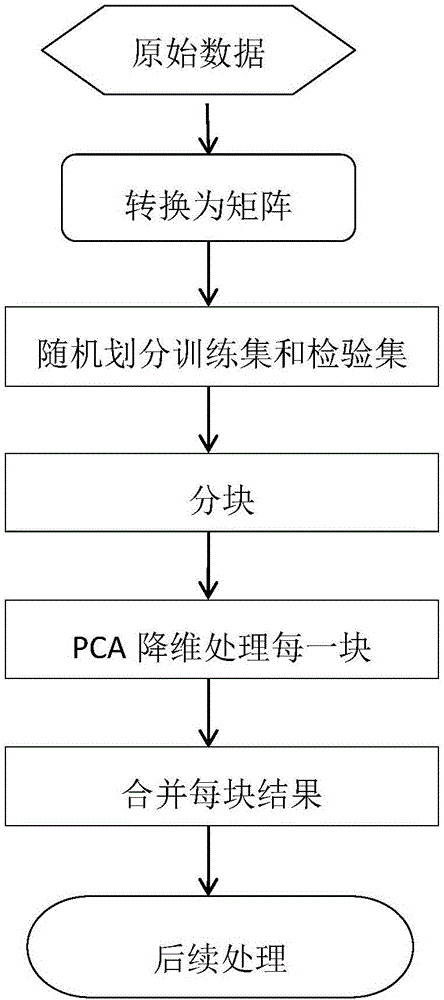
隨著信息科學技術的飛速發展,信息的表示越來越全面,人們獲取數據越來越容易、關注的數據對象日漸複雜,業界對數據分析、處理技術的需求最為迫切,特別是對高維數據的分析與處理技術。直接處理高維數據會面臨以下困難:維數災難、空空間、不適定、算法失效。本發明針對數據特徵維太高,內存受限,不能一次性讀入內存分析計算的問題,採用分塊處理方法,處理流程如圖1所示。但結果顯示,運行耗時太長,不能滿足應用需求,在此基礎上,引入信息熵,首先做特徵篩選,大大降低了特徵數量,再做降維處理,具體流程如圖2所示,具體算法如圖3所示,整個過程運行耗時減少數倍,降維結果保留了大部分主成分,依然能滿足應用需求。
技術實現要素:
本發明的最終目的是對原始超高維數據進行降維處理,使得降維後的數據可以在較低內存,用時較少的情況下得以繼續分析處理。本發明對主要利用了信息熵在信息處理上的意義,對PCA算法進行了改進。所謂的數據維數就是每條記錄數據的屬性個數。
為實現上述目的,本發明基於信息熵對PCA算法做了改進, 其算法構成如下:
1)Matrix=getMatrix(rdata)
2)計算信息熵,做篩選
3)分割數據矩陣
[B,C]=randomSplit(Matrix)//B為訓練集,C為檢驗集
4)樣本B矩陣中心化:即每一維度減去該維度的均值
X=B–repmat(mean(B,2),1,m1)
5)計算不同維度之間的協方差,構成協方差矩陣:
C=(X*XT)/size(X,2)
6)計算協方差矩陣的特徵向量eigenVector和特徵值eigenValue
[eigenVector,eigenValue]=eig(Cov)
7)選擇最大的k個特徵值對應的k特徵向量分別作為列向量組成特徵向量矩陣Vn×k,k由f計算。
8)計算降維結果:Y=VT*X
9)對矩陣C中心化,得X0
10)計算結果:Y0=VT*X0
11)後續對比,如分類。
附圖說明
圖1是基於分塊的PCA處理高維數據的流程(應用PCA的處理流程),圖2是本發明基於信息熵的PCA降維處理流程(基於信息熵的降維處理流程),圖3是本發明算法E-PCA的步驟(基於信息熵的PCA(E-PCA)算法過程)。
具體實施方式
下面結合附圖對本發明的具體實施方式進行描述,以便本領域的技術人員更好的理解本發明。需要特別提醒注意的是,在以下的描述中,當已知功能和設計的詳細描述也許會淡化本發明的主要內容時,這些描述在這裡將被忽略。
圖1是本發明基於信息熵的超高維數據降維處理的流程。在本實施例中,如圖2所示,原始數據作為輸入,如果原始數據本來就是屬性和記錄組成的矩陣,可以省略轉換為矩陣的步驟。
生成矩陣的下一步為對每個屬性計算信息熵H(i),並和閾值et(et根據具體的應用取值)比較,大於閾值的屬性保留,處理之後的矩陣A作為下一步處理的輸入。
信息熵處理之後的數據進入PCA處理流程,首先樣本中心化,在計算不同屬性之間的協方差,形成協方差矩陣,再計算協方差矩陣的特徵值和特徵向量,計算貢特徵值獻率(表徵獲取的主成分佔原始數據信息的比例)f確定k值,進而確定主成分個數,抽取最大的k個特徵值對應的k個特徵向量作為變換基,將原始數據降維得結果Yk×m,以便後續分析計算。
儘管上面對本發明說明性的具體實施方式進行了描述,以便於本技術領域的技術人員理解本發明,但應該清楚,本發明不限於具體實施方式的範圍,對本技術領域的普通技術人員來講,只要各種變化再所附的權利要求限定和確定的本發明的精神和範圍內,這些變化是顯而易見的,一切利用本發明構思的發明創造均在保護之列。