一種模糊粗糙集中基於信息增益率的屬性選擇方法與流程
2023-06-12 13:59:37 7
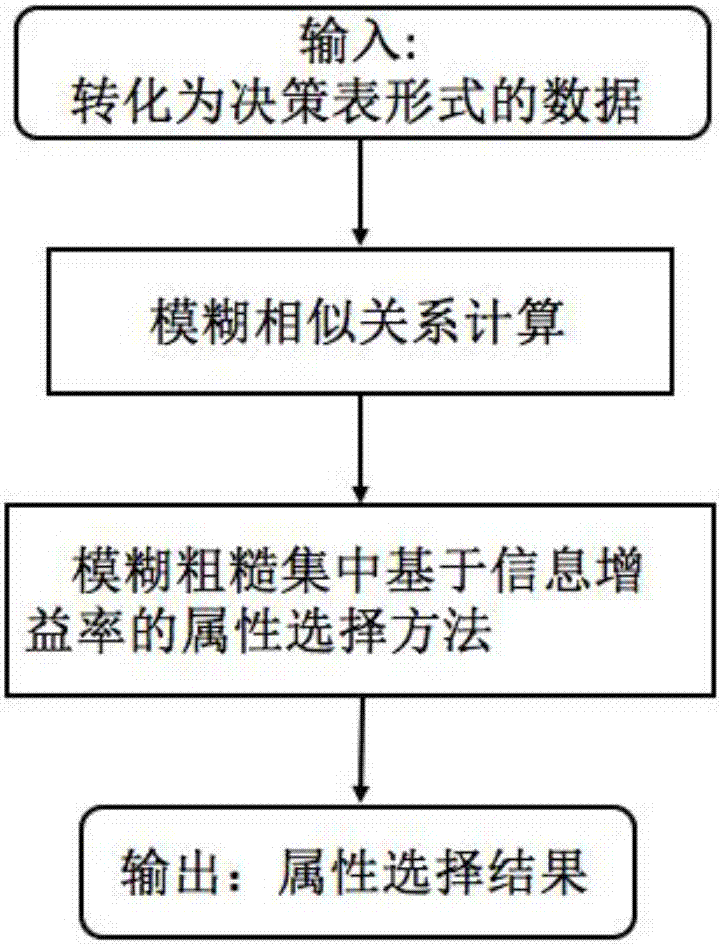
本發明涉及屬性選擇方法,具體是指一種模糊粗糙集中基於信息增益率的屬性選擇方法。
背景技術:
:現實中由於數據採集的結果往往伴隨著噪聲數據,這使得不確定數學工具顯得尤為重要。粗糙集理論與其他處理不確定和不精確問題理論相比,無需提供問題所需處理的數據集合之外的任何先驗知識。由於粗糙集處理不確定數據的優越性,目前已經在分類、聚類等多個領域得到廣泛應用,其中,屬性選擇是最為重要的應用之一。屬性選擇可以從大量的屬性中消除冗餘、無關的屬性,從而提高數據質量、加速數據處理速度和改善分類器的泛化能力。經典的粗糙集理論只能夠處理符號屬性,對於數值屬性必須提前進行離散化處理。d.dubios和h.prad在1992年提出了模糊粗糙集,模糊粗糙集將模糊集和離散集結合,用模糊集和隸屬度來描述一個對象和集合間的關係,可以直接處理數值屬性。相比離散化,模糊化能較好的保留數值屬性的信息。信息增益率是一種選擇屬性的有效方法,可以懲罰值較多的屬性,在實際使用中往往具有較好的效果。但目前模糊粗糙集中存在的基於信息增益率的屬性選擇方法(daij,xuq.attributeselectionbasedoninformationgainratioinfuzzyroughsettheorywithapplicationtotumorclassification[j].appliedsoftcomputing,2013,13(1):211-221.):(1)沒有去除相關性較低的屬性,相關性較低的屬性可能會被選擇到結果中。(2)屬性選擇的結果中,可能存在冗餘。為了解決上述問題,提升模糊粗糙集中屬性選擇方法,本發明將提出一種新的模糊粗糙集中基於信息增益率的屬性選擇方法。相比目前模糊粗糙集中存在的基於信息增益率的屬性選擇方法,可以進一步從大量的屬性中消除無關、冗餘的屬性,從而提高數據質量、加速數據處理速度和改善分類器的泛化能力。技術實現要素:本發明的目的是為了提升模糊粗糙集中屬性選擇方法,而提出一種新的模糊粗糙集中基於信息增益率的屬性選擇方法。為了實現以上發明的目的,本發明採用的技術方案如下:本發明方法是在模糊粗糙集下,計算各屬性的信息增益率,去除信息增益率小於給定閾值的屬性;計算各個未被選擇的屬性的信息增益率,選擇信息增益率最大的屬性,並加入到屬性選擇結果中;重複上面的選擇過程,直到信息增益率的最大值為0或未被選擇的屬性集為空集,去除選擇結果中的冗餘屬性。這裡的各個未被選擇的屬性是指代刪除信息增益率小於給定閾值的屬性後的模糊粗糙集下的屬性。上述基於模糊粗糙集信息增益率的屬性選擇方法的具體描述如下:輸入:一個決策表dt=(u,a=c∪d,v,f),其中u是論域,c是條件屬性集,d是決策屬性集,v是值域,f是u和a到v的映射。論域中對象間的模糊相似關係。閾值δ(可根據實際情況調節,默認為一個較小的值:0.000001)。輸出:屬性選擇結果b第1步:令屬性選擇結果b的初始值為空集,未被選擇的屬性集m的初始值為c第2步:對於未選擇屬性集m中的每個屬性a,如果信息增益率gr(a,b,d)0,並且繼續執行第3步和第4步;否則,進入下一步。第6步:對於屬性選擇結果b中的每個屬性a,如果信息增益率gr(a,b–{a},d)=0,則b=b–{a}。遍歷屬性選擇結果b中所有屬性,最終得到所需的結果集。(先選擇的屬性往往更重要,因此優先去除後選擇的屬性,即在本步中反向遍歷b)本發明方法具有模糊粗糙集的優點,可以直接處理數值屬性,而且使用信息增益率選擇屬性;提前去除相關性較低的屬性,防止相關性較低的屬性被選擇到結果中;屬性選擇後,去除結果中的冗餘屬性。相比目前模糊粗糙集中存在的基於信息增益率的屬性選擇方法,可以進一步的從大量的屬性中消除無關、冗餘的屬性,從而提高數據質量、加速數據處理速度和改善分類器的泛化能力。附圖說明圖1為本發明的方法流程圖;圖2為本發明的實施流程圖。具體實施方式下面結合具體實施例對本發明做進一步的分析。本發明包括以下4個步驟,圖1為本發明的方法流程圖;圖2為本發明的實施流程圖。(1)將數據轉化為粗糙集中使用的決策表格式(2)計算決策表中對象的模糊相似關係,常用的數值屬性的模糊相似關係如下其中:xi和xj表示論域u中的2個對象,amax表示屬性a的最大值,amin表示屬性a的最小值。(3)通過本發明的基於模糊粗糙集信息增益率的屬性選擇方法,得到屬性選擇結果(4)輸出屬性選擇結果實驗例:在醫療領域,用機器學習算法診斷疾病已經成為一種新的趨勢。相比於傳統的人工診斷,使用機器學習算法診斷,效率更高,準確率更好。然而,現實生活中採集的數據往往包含大量的噪聲和冗餘屬性。使用這種數據訓練模型,效率低下,準確率低。因此,去除冗餘屬性和噪聲的預處理技術是必不可少的步驟。在本發明中,使用本專利提出的方法對uci(http://archive.ics.uci.edu/ml)數據倉庫中的breastcancerwisconsin(diagnostic)進行屬性約減,並驗證結果的有效性。breastcancerwisconsin(diagnostic)數據集的特徵是從乳腺腫塊的細針穿刺(fna)圖像提取的。這些特徵描述了圖像中細胞核的特性。數據集的類別只有兩種:良性(benign)和惡性(malignant)。數據集的信息如表1所示。運行的結果如表2所示:消除無關、冗餘的屬性,從而提高數據質量和改善分類器的泛化能力。屬性選擇後的數據集為原始數據集去除未在屬性選擇中的屬性;分類準確率為十者交叉驗證的平均值,採用的分類器為邏輯回歸。表1數據集信息#dataset#instances#attributes#classbcw569322表2屬性選擇後的數據集與原始數據集對比上述實施例並非是對於本發明的限制,本發明並非僅限於上述實施例,只要符合本發明要求,均屬於本發明的保護範圍。當前第1頁12