基於深度學習的人臉識別和年齡合成聯合模型的構建方法與流程
2023-08-06 18:30:21 4
本發明涉及計算機視覺領域,更具體地,涉及一種基於深度學習的人臉識別和年齡合成聯合模型的構建方法。
背景技術:
人臉識別,是基於人的臉部特徵信息進行身份識別的一種生物識別技術。用攝像機或攝像頭採集含有人臉的圖像或視頻流,並自動在圖像中檢測和跟蹤人臉,進而對檢測到的人臉進行臉部的一系列相關技術,通常也叫做人像識別、面部識別。
由於人臉識別分類與驗證均有很大的實際應用價值,所以此課題作為一個研究熱點已經持續了多年時間。人臉識別在現實生活中有很廣的應用前景。如安保門禁系統、公安刑偵破案、攝像監視系統、網絡應用,身份辨識、支付系統中均需用到人臉識別。
然而人臉識別並不是個簡單的任務。人臉的外形很不穩定,人可以通過臉部的變化產生很多表情,而在不同觀察角度,人臉的視覺圖像也相差很大,另外,人臉識別還受光照條件(例如白天和夜晚,室內和室外等)、人臉的很多遮蓋物(例如口罩、墨鏡、頭髮、鬍鬚等)、年齡等多方面因素的影響。這些問題給人臉識別帶來了莫大的挑戰。
因此近來許多關於人臉識別研究熱烈開展起來。因為一幅人臉圖像的維度太大,首要任務是對人臉圖像的一系列處理。如經典的主成分分析方法(PCA),通過線性變換原理將原始數據變換為一組各維度線性無關的表示,可用於提取數據的主要特徵分量;還有線性判別分析(LDA),將帶上標籤的數據(點),通過投影的方法,投影到維度更低的空間中,使得投影后的點,會形成按類別區分,一簇一簇的情況,相同類別的點,將會在投影后的空間中更接近。這樣將使不同類的數據更易於分類。在本發明中,將這兩種算法都作為預處理的方法。
近年基於深度學習的人臉識別方法取得了很大進展。深度學習的概念源於人工神經網絡的研究。含多隱層的多層感知器就是一種深度學習結構。深度學習通過組合低層特徵形成更加抽象的高層表示屬性類別或特徵,以發現數據的分布式特徵表示。
深度學習的概念由Hinton等人於2006年提出。基於深信度網(DBN)提出非監督貪心逐層訓練算法,為解決深層結構相關的優化難題帶來希望,隨後提出多層自動編碼器深層結構。此外Lecun等人提出的卷積神經網絡(CNN)是第一個真正多層結構學習算法,它利用空間相對關係減少參數數目以提高訓練性能,基於CNN的方法的主要思想是:首先,對輸入圖像利用的CNN進行卷積提取局部特徵,然後在全連結層通過矩陣相乘減少維數,同時通過反向傳導的梯度下降法調整參數使得整個網絡結構能輸出與訓練集結果相差最小的分類結果。網絡中倒數第二,第三層的特徵可被視為原圖像的全局特徵,在人臉驗證模型中,這些特徵將會使用各種方法組合計算出兩張人臉圖像屬於同一個人的概率,通過與參考集一一比對以完成最終的識別過程。本發明將CNN方法用於身份識別過程。
雖然上述方法都取得了很大的進展,但在處理跨年齡的人臉識別方向還有待探索。年齡增長給人臉帶來的巨大變化大大影響了人臉識別算法的精度。所以跨年齡的人臉識別仍需更有效的算法來解決。
技術實現要素:
本發明提供一種基於深度學習的人臉識別和年齡合成聯合模型的構建方法,該方法構建的模型可同時抑制身份表達和年齡表達的相關度,來達到年齡不變的人臉識別的目的。
為了達到上述技術效果,本發明的技術方案如下:
一種基於深度學習的人臉識別和年齡合成聯合模型的構建方法,包括以下步驟:
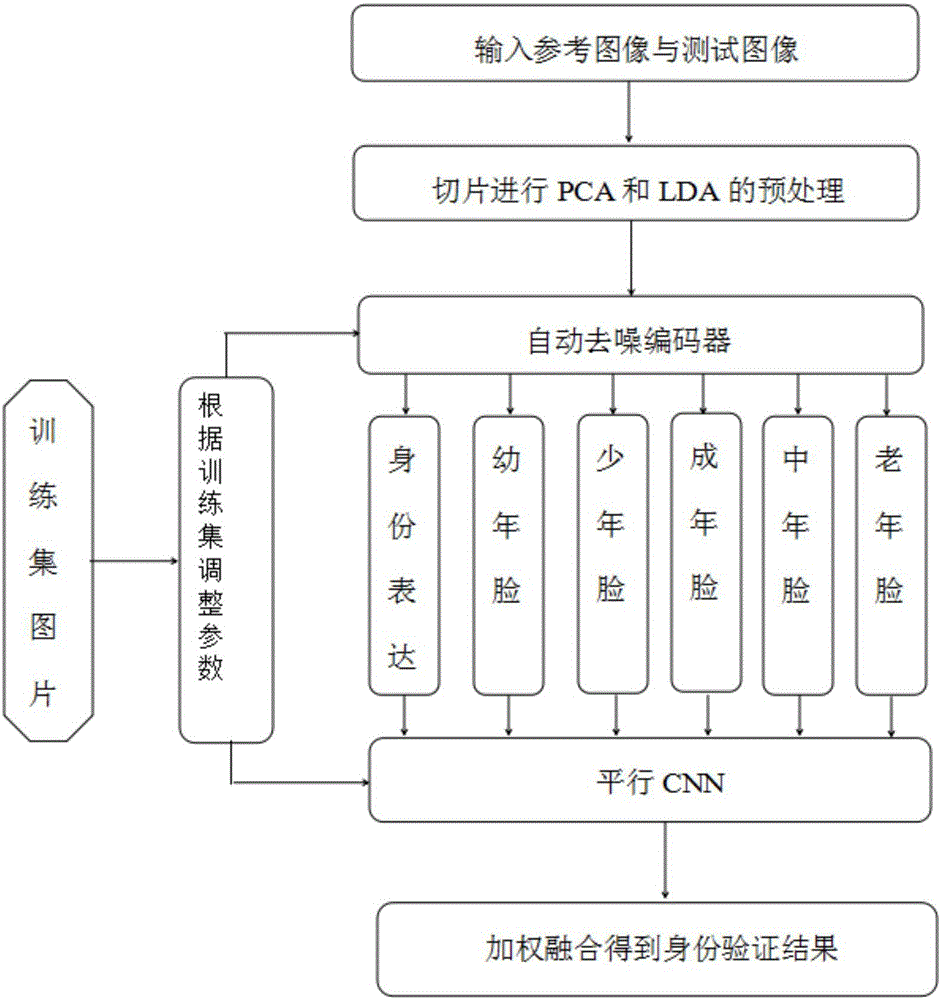
S1:對圖像進行切片預處理:根據雙眼中心進行對齊,採用PCA和LDA的方式進行降維,以及達到增大類間差距的目的;
S2:編碼:通過訓練數據得到的一個自動編碼器對輸入特徵向量進行編碼。該編碼器的目的是將原圖特徵通過某種編碼方式合成新的特徵,用於表達身份或者年齡的相關信息,對任何輸入的圖片,該編碼器將生成六組不同的表達:
第一組為身份表達,對原特徵減去平均臉後的映射編碼,反映個體的身份的穩定信息;
第二組至第六組分別為幼年、少年、成年、中年、老年五個年齡段下原圖像的合成圖像的表達,這一部分的編碼過程與上述相似,不同的是輸入是原圖信息,這五組編碼器的作用是模擬老化過程來合成特定年齡組的圖片,
然後通過損失函數和一定的約束規則來控制消除年齡對身份表達的影響,即在年齡合成中起到重要作用的特徵,降低它在身份表達中起的作用;
S3:對每對圖像進行身份匹配驗證:測試圖像與一幅訓練圖像作為一對,由編碼器得到的六對特徵分別通過平行CNN,Softmax層將給出輸入的一對特徵的相似度的大小;
令Ia,Ib為一對輸入圖像,則相似得分表示為:
s(Ia,Ib)=soft max(Ws|o(Ia)-o(Ib)|+bs)
其中,o表示CNN中全連接層的輸出,Ws和bs為softmax層的參數;
對這六個結果進行加權平均即可得到驗證結果,其中身份表達佔的比重較大;五對年齡合成的相似度表示在五個年齡段裡的相似度,作為參考因素,佔的比重比身份表達要小,由此將得到兩幅圖像匹配的概率:
score=as1+(1-a)(s2+s3+s4+s5+s6);
S4:對所有特徵得到的相似得分結果進行餘弦相似度融合,即可得到最終的結果。
進一步地,所述步驟S2中,使用的編碼器由訓練庫中的數據訓練得出,該編碼器將生成6組不同的表達:
S21:第一組為身份表達,是對原特徵減去平均臉後的映射編碼,假設輸入的第i個人的人臉圖片表示為Xi訓練庫中所有人臉圖像的均值為M,則Yi=Xi-M反映的是該臉的獨特信息,然後對Yi進行編碼:
假設編碼由3層結構組成,每一層以上一層的輸出作為輸入,層數為j的輸出表示為hj則編碼過程可表示為hj=Wjσ(hj-1)+bj,第一層的輸入為Yi,
則編碼過程的映射表示為:
h=Wσ(Y+b)
同時,編碼後的圖像重構可表示為Y'=W'σ(h'+b')
這一部分參數W,b由最小化一個損失函數來獲得,該損失函數表示原圖減去平均臉的信息與由編碼後重構的信息的距離的平方損失,該過程的損失函數表示為:
S22:第二組至第六組分別為幼年、少年、成年、中年、老年等5個年齡段下原圖像的合成圖像的表達,這一部分的編碼過程與上述相似,不同的是輸入是原圖信息Xi,這一部分損失函數由每一組與庫內同類同年齡組的原圖的平方損失來表示,因此這裡有5個不同的年齡合成的編碼器,每一個編碼器有不同的編碼參數,因此損失函數為這5個編碼器的生成的結果重構與原圖的距離平方損失:
於是聯合損失函數L=L1+L2,表示兩個不同的編碼過程中原特徵與重構特徵的損失,這一部分是表示對原圖特徵的共享;
S23:要抑制年齡對身份表達的影響,即對年齡合成很重要的那部分特徵,應該削弱其在身份表達中的作用,用一個矩陣Φ來表示在編碼過程中反映的原圖特徵的重要程度,可表示為其中令s(j)為Wj作用的特徵,mkj=δ(s(j)-k)=1若且唯若s(j)=k,即,M為將編碼參數映射為特徵重要程度的矩陣;
表示身份表達過程中反映的特徵重要性矩陣;表示年齡合成表現出來的特徵重要性矩陣,然後對聯合損失函數加入了一個約束:目的是減小身份表達和年齡表達之間的相關度;
S24:編碼器的參數表示為θ={W,b},總損失函數L(θ)=L1+L2+L3通過最小化總損失函數來訓練整個編碼部分:W,b=arg minL(θ)對該式求解利用交替貪婪聯合下降算法,先固定b,對W求梯度下降的最優解;再固定W,對b求梯度下降的最優解,直到迭代收斂。
進一步地,所述步驟S3中,平行CNN的訓練步驟如下:
用訓練庫中人臉圖像,分別以多尺度矩形框截取人臉圖像的多個部分的圖像,成對作為CNN的輸入進行預訓練,平行CNN的結構有九個層次,是由隨機梯度下降來訓練,輸入層需要一對圖像作為輸入,接下來的三個卷積層通過最大池層提取判別圖像分層的功能,然後用一個非線性激活函數用於對輸入進行卷積運算後的數據,在這用修正的線性函數Relu為激活函數,完全連接層通過學習一個語義空間,使同一個人的一對圖像的相似性得分被放大,而來自不同的人的圖像對的相似度減小,除了卷積特徵從輸入的人臉紋理中提取,歸一化的坐標的68個地標相結合,作為一個132維向量,也被納入學習的歧視性空間,最後一層是一個softmax層產生的相似性輸入圖像對的分數,在輸入的圖像對之間,輸入端到完全連接層的參數共享。
與現有技術相比,本發明技術方案的有益效果是:
本發明通過對輸入的一對圖像進行對齊和PCA和LDA降維的預處理;並通過一個經過訓練得到的自動編碼器,得到用於身份表示的特徵和不同年齡段表示的特徵共6組,然後對6對結果經過平行CNN,輸出圖像相似度,之後加權融合得到匹配結果;該發明對單獨的人臉識別或者年齡檢測以及共同任務均能得到很好的效果,對光照、姿勢影響下的人臉識別也額能取得很好的效果;由於區分開了年齡與人臉身份的特徵,因此對跨年齡的人臉識別也具有魯棒性。並且,可視要求而定調整一些參數和權值,因此非常有靈活性。
附圖說明
圖1為本發明方法流程圖。
具體實施方式
附圖僅用於示例性說明,不能理解為對本專利的限制;
為了更好說明本實施例,附圖某些部件會有省略、放大或縮小,並不代表實際產品的尺寸;
對於本領域技術人員來說,附圖中某些公知結構及其說明可能省略是可以理解的。
下面結合附圖和實施例對本發明的技術方案做進一步的說明。
實施例1
如圖1所示,一種基於深度學習的人臉識別和年齡合成聯合模型的構建方法,包括以下步驟:
S1:對圖像進行切片預處理:根據雙眼中心進行對齊,採用PCA和LDA的方式進行降維,以及達到增大類間差距的目的;
S2:編碼:通過訓練數據得到的一個自動編碼器對輸入特徵向量進行編碼。該編碼器的目的是將原圖特徵通過某種編碼方式合成新的特徵,用於表達身份或者年齡的相關信息,對任何輸入的圖片,該編碼器將生成六組不同的表達:
第一組為身份表達,對原特徵減去平均臉後的映射編碼,反映個體的身份的穩定信息;
第二組至第六組分別為幼年、少年、成年、中年、老年五個年齡段下原圖像的合成圖像的表達,這一部分的編碼過程與上述相似,不同的是輸入是原圖信息,這五組編碼器的作用是模擬老化過程來合成特定年齡組的圖片,
然後通過損失函數和一定的約束規則來控制消除年齡對身份表達的影響,即在年齡合成中起到重要作用的特徵,降低它在身份表達中起的作用;
S3:對每對圖像進行身份匹配驗證:測試圖像與一幅訓練圖像作為一對,由編碼器得到的六對特徵分別通過平行CNN,Softmax層將給出輸入的一對特徵的相似度的大小;
令Ia,Ib為一對輸入圖像,則相似得分表示為:
s(Ia,Ib)=soft max(Ws|o(Ia)-o(Ib)|+bs)
其中,o表示CNN中全連接層的輸出,Ws和bs為softmax層的參數;
對這六個結果進行加權平均即可得到驗證結果,其中身份表達佔的比重較大;五對年齡合成的相似度表示在五個年齡段裡的相似度,作為參考因素,佔的比重比身份表達要小,由此將得到兩幅圖像匹配的概率:
score=as1+(1-a)(s2+s3+s4+s5+s6);
S4:對所有特徵得到的相似得分結果進行餘弦相似度融合,即可得到最終的結果。
步驟S2中,使用的編碼器由訓練庫中的數據訓練得出,該編碼器將生成6組不同的表達:
S21:第一組為身份表達,是對原特徵減去平均臉後的映射編碼,假設輸入的第i個人的人臉圖片表示為Xi訓練庫中所有人臉圖像的均值為M,則Yi=Xi-M反映的是該臉的獨特信息,然後對Yi進行編碼:
假設編碼由3層結構組成,每一層以上一層的輸出作為輸入,層數為j的輸出表示為hj則編碼過程可表示為hj=Wjσ(hj-1)+bj,第一層的輸入為Yi,
則編碼過程的映射表示為:
h=Wσ(Y+b)
同時,編碼後的圖像重構可表示為Y'=W'σ(h'+b')
這一部分參數W,b由最小化一個損失函數來獲得,該損失函數表示原圖減去平均臉的信息與由編碼後重構的信息的距離的平方損失,該過程的損失函數表示為:
S22:第二組至第六組分別為幼年、少年、成年、中年、老年等5個年齡段下原圖像的合成圖像的表達,這一部分的編碼過程與上述相似,不同的是輸入是原圖信息Xi,這一部分損失函數由每一組與庫內同類同年齡組的原圖的平方損失來表示,因此這裡有5個不同的年齡合成的編碼器,每一個編碼器有不同的編碼參數,因此損失函數為這5個編碼器的生成的結果重構與原圖的距離平方損失:
於是聯合損失函數L=L1+L2,表示兩個不同的編碼過程中原特徵與重構特徵的損失,這一部分是表示對原圖特徵的共享;
S23:要抑制年齡對身份表達的影響,即對年齡合成很重要的那部分特徵,應該削弱其在身份表達中的作用,用一個矩陣Φ來表示在編碼過程中反映的原圖特徵的重要程度,可表示為其中令s(j)為Wj作用的特徵,mkj=δ(s(j)-k)=1若且唯若s(j)=k,即,M為將編碼參數映射為特徵重要程度的矩陣;
表示身份表達過程中反映的特徵重要性矩陣;表示年齡合成表現出來的特徵重要性矩陣,然後對聯合損失函數加入了一個約束:目的是減小身份表達和年齡表達之間的相關度;
S24:編碼器的參數表示為θ={W,b},總損失函數L(θ)=L1+L2+L3通過最小化總損失函數來訓練整個編碼部分:W,b=arg min L(θ)對該式求解利用交替貪婪聯合下降算法,先固定b,對W求梯度下降的最優解;再固定W,對b求梯度下降的最優解,直到迭代收斂。
步驟S3中,平行CNN的訓練步驟如下:
用訓練庫中人臉圖像,分別以多尺度矩形框截取人臉圖像的多個部分的圖像,成對作為CNN的輸入進行預訓練,平行CNN的結構有九個層次,是由隨機梯度下降來訓練,輸入層需要一對圖像作為輸入,接下來的三個卷積層通過最大池層提取判別圖像分層的功能,然後用一個非線性激活函數用於對輸入進行卷積運算後的數據,在這用修正的線性函數Relu為激活函數,完全連接層通過學習一個語義空間,使同一個人的一對圖像的相似性得分被放大,而來自不同的人的圖像對的相似度減小,除了卷積特徵從輸入的人臉紋理中提取,歸一化的坐標的68個地標相結合,作為一個132維向量,也被納入學習的歧視性空間,最後一層是一個softmax層產生的相似性輸入圖像對的分數,在輸入的圖像對之間,輸入端到完全連接層的參數共享。
相同或相似的標號對應相同或相似的部件;
附圖中描述位置關係的用於僅用於示例性說明,不能理解為對本專利的限制;
顯然,本發明的上述實施例僅僅是為清楚地說明本發明所作的舉例,而並非是對本發明的實施方式的限定。對於所屬領域的普通技術人員來說,在上述說明的基礎上還可以做出其它不同形式的變化或變動。這裡無需也無法對所有的實施方式予以窮舉。凡在本發明的精神和原則之內所作的任何修改、等同替換和改進等,均應包含在本發明權利要求的保護範圍之內。