基於HDFS的節點失效的快速檢測與恢復方法及系統與流程
2023-05-18 20:40:37 2
本發明涉及存儲集群的技術領域,特別是涉及一種基於HDFS的節點失效的快速檢測與恢復方法及系統。
背景技術:
隨著整個社會的信息化程度不斷提高,社會生活逐漸與計算機系統密不可分。目前,計算機系統已全面進入「雲計算」、「大數據」時代,由大規模伺服器集群響應海量請求和處理海量數據已經成為必然趨勢。將相互獨立的、分散的計算機通過網絡互聯,使它們成為一個集群,宏觀上以單一系統的模式對其進行管理。對用戶而言,集群像是一個獨立的伺服器。
然而,僅僅具有高性能計算能力的集群系統還遠遠不能滿足這種大規模應用的需要,必須還能夠提供持久高效穩定的服務,即提供一定的可用性。所謂計算機系統的可用性,一般定義為計算機系統正常工作時間與計算機系統總運行時間之比。對於某些執行關鍵使命的計算機系統,要求系統能夠長時間穩定運行,即具備365x24小時不停頓運行的能力。對於這類系統,暫時的宕機都會導致數據的丟失繼而引發災難性的後果。
分布式系統特別是集群的容錯機制現已成為當今國際學術界研究的熱點,吸引了眾多的研究人員。眾多研究機構和開源組織在系統容錯和檢查點技術方面做了大量的工作。典型的系統包括Linux-HA(High Available,高可用)的Heartbeat、openssl、Amoeba等。
Linux-HA開源項目提供的Heartbeat軟體是基於Linux平臺的高可用軟體。該項目於1999年開始啟動,現已發展到2.0版本,並隨大多數Linux版本一起發行,應用廣泛。Heartbeat是運行在作業系統之上的用戶級軟體,可以在多種類Unix平臺上運行,具有較好的可移植性,可以在毫秒級發現節點失效。Heartbeat具有易用性、安全性、簡單性和低成本等優點,支持串口通訊,即節點間可通過串口傳遞心跳消息。Heartbeat通過冗餘來消除單點故障。當發生節點失效時,自動進行故障恢復並由備份系統接管工作。最初的Heartbeat軟體僅支持兩個節點,即雙機熱備份的工作模式。即在主機工作時,備份機通過心跳消息來監控主機的工作狀態。一旦發現主機失效,立即接管主機的工作,從而實現主機故障對用戶透明。
目前集群的文件系統常用GFS(Google File System,Google文件系統),其衍生的HDFS(Hadoop Distributed File System,Hadoop分布式文件系統)由於易於布置在常用設備上而廣受歡迎。在HDFS中保障數據安全所採用的機制主要包括冗餘備份、心跳檢測以及安全模型等。其中,心跳檢測是失效檢測中最常採用的技術之一,通過周期性的檢查各個節點的工作狀態,來便於系統對各個節點進行檢測與管理。然而,現有的HDFS檢測和恢復機制依然不能滿足系統安全的需求。
容災系統只有擁有快速而準確的失效檢測技術,才能在正常時期避免網絡信息延遲事件或網絡丟包事件帶來的幹擾,並且在災難發生後最短的時間內檢測到失效,提高系統的效率。因此,如何快速檢測和恢復失效節點,提高集群系統的可用性,盡最大可能避免因節點失效而導致的嚴重後果,成為當前集群系統研究的熱點問題之一。
技術實現要素:
鑑於以上所述現有技術的缺點,本發明的目的在於提供一種基於HDFS的節點失效的快速檢測與恢復方法及系統,在HDFS原有檢測機制上維護一個危險數據節點隊列,並對該危險數據節點隊列中各數據節點的數據塊進行比對以找出相同數據塊,並將相同數據塊提前加入待恢復隊列,優先進行相同數據塊的恢復,從而在保證各數據節點的數據塊可用,基本不增加網絡帶寬的前提下,提前恢復了危險數據塊,降低了系統風險。
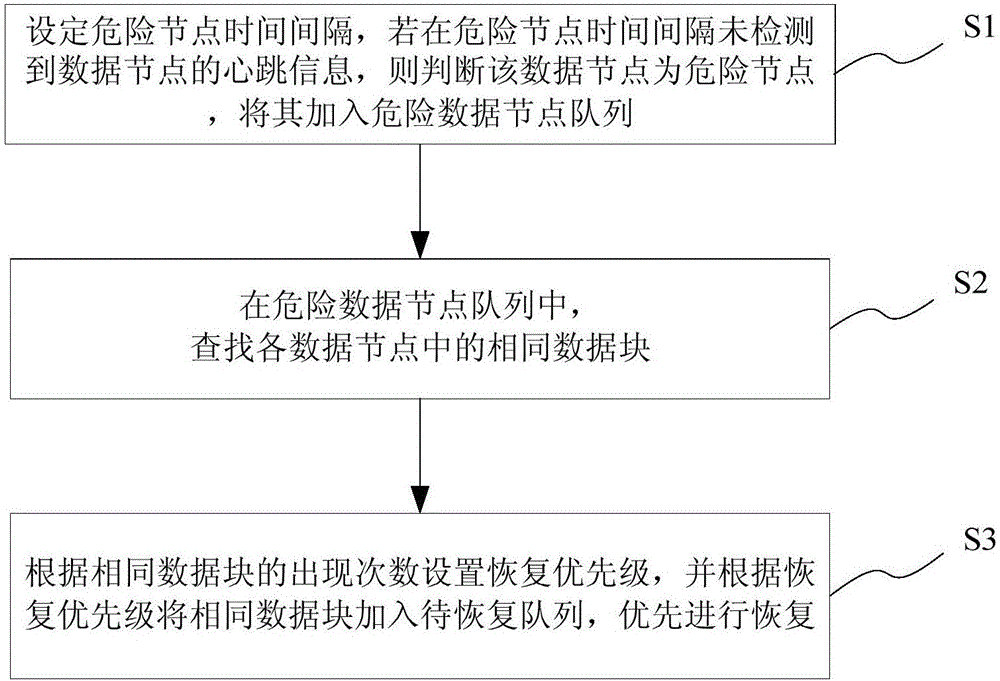
為實現上述目的及其他相關目的,本發明提供一種基於HDFS的節點失效的快速檢測與恢復方法,包括以下步驟:設定危險節點時間間隔,若在危險節點時間間隔未檢測到數據節點的心跳信息,則判斷該數據節點為危險節點,將其加入危險數據節點隊列;所述危險節點時間間隔須小於判斷數據節點宕機所需時間;在危險數據節點隊列中,查找各數據節點中的相同數據塊;根據相同數據塊的出現次數設置恢復優先級,並根據恢復優先級將相同數據塊加入待恢復隊列,優先進行恢復。
根據上述的基於HDFS的節點失效的快速檢測與恢復方法,其中:若數據節點在加入危險數據節點隊列後,被判斷處於宕機狀態,則將所述數據節點從危險數據節點列表中移除,並加入到待恢復隊列依次進行恢復。
根據上述的基於HDFS的節點失效的快速檢測與恢復方法,其中:在待恢復隊列中,對於不同優先級的數據塊,根據恢復優先級先後對不同的數據塊進行恢復。
根據上述的基於HDFS的節點失效的快速檢測與恢復方法,其中:在待恢復隊列中,對於相同恢復優先級的不同數據塊,按照加入恢復隊列的先後依次進行恢復。
根據上述的基於HDFS的節點失效的快速檢測與恢復方法,其中:對於相同數據塊,存活副本數越多,優先級越低;存活副本數越少,優先級越高;所述存活副本數等於所有副本數減去宕機副本數和相同數據塊的出現次數。
同時,本發明還提供一種基於HDFS的節點失效的快速檢測與恢復系統,包括檢測判斷模塊、查找模塊和恢復模塊;
所述檢測判斷模塊用於設定危險節點時間間隔,並在危險節點時間間隔未檢測到數據節點的心跳信息時,判斷該數據節點為危險節點,將其加入危險數據節點隊列;所述危險節點時間間隔須小於判斷數據節點宕機所需時間;
所述查找模塊用於在危險數據節點隊列中,查找各數據節點中的相同數據塊;
所述恢復模塊用於根據相同數據塊的出現次數設置恢復優先級,並根據恢復優先級將相同數據塊加入待恢復隊列,優先進行恢復。
根據上述的基於HDFS的節點失效的快速檢測與恢復系統,其中:所述檢測判斷模塊中,若數據節點在加入危險數據節點隊列後,被判斷處於宕機狀態,則將所述數據節點從危險數據節點列表中移除,並加入到待恢復隊列依次進行恢復。
根據上述的基於HDFS的節點失效的快速檢測與恢復系統,其中:在待恢復隊列中,對於不同優先級的數據塊,根據恢復優先級先後對不同的數據塊進行恢復。
根據上述的基於HDFS的節點失效的快速檢測與恢復系統,其中:在待恢復隊列中,對於相同恢復優先級的不同數據塊,按照加入恢復隊列的先後依次進行恢復。
根據上述的基於HDFS的節點失效的快速檢測與恢復系統,其中:所述恢復模塊中,對於相同數據塊,存活副本數越多,優先級越低;存活副本數越少,優先級越高;所述存活副本數等於所有副本數減去宕機副本數和相同數據塊的出現次數。
如上所述,本發明的基於HDFS的節點失效的快速檢測與恢復方法及系統,具有以下有益效果:
(1)在HDFS原有檢測機制上維護一個危險數據節點隊列,並對該危險數據節點隊列中各數據節點的數據塊進行比對以找出相同數據塊,並將相同數據塊提前加入待恢復隊列,優先進行相同數據塊的恢復;
(2)保證各數據節點的數據塊可用,基本不增加網絡帶寬;
(3)提前恢復了危險數據塊,降低了系統風險。
附圖說明
圖1顯示為現有技術中不同數據節點中相同數據塊宕機檢測恢復示意圖;
圖2顯示為本發明的基於HDFS的節點失效的快速檢測與恢復方法的流程圖;
圖3顯示為本發明中不同數據節點中相同數據塊宕機檢測恢復示意圖;
圖4顯示為本發明的基於HDFS的節點失效的快速檢測與恢復系統的結構示意圖。
元件標號說明
1 檢測判斷模塊
2 查找模塊
3 恢復模塊
具體實施方式
以下通過特定的具體實例說明本發明的實施方式,本領域技術人員可由本說明書所揭露的內容輕易地了解本發明的其他優點與功效。本發明還可以通過另外不同的具體實施方式加以實施或應用,本說明書中的各項細節也可以基於不同觀點與應用,在沒有背離本發明的精神下進行各種修飾或改變。需說明的是,在不衝突的情況下,以下實施例及實施例中的特徵可以相互組合。
需要說明的是,以下實施例中所提供的圖示僅以示意方式說明本發明的基本構想,遂圖式中僅顯示與本發明中有關的組件而非按照實際實施時的組件數目、形狀及尺寸繪製,其實際實施時各組件的型態、數量及比例可為一種隨意的改變,且其組件布局型態也可能更為複雜。
HDFS中包含兩種節點,分別以管理者-工作者的模式運行,即一個名字節點(管理者)和多個數據節點(工作者)。名字節點管理文件系統的命名空間,維護著這個文件系統樹及這個樹內所有的文件和索引目錄,也記錄著每個文件的每個塊所在的數據節點。數據節點是文件系統的工作者,存儲並提供定位塊的服務,並且定時的向名字節點發送它們存儲的塊的列表。
在HDFS中,採用主從形式管理名字節點和數據節點。其中數據節點採用三備份策略,當其中一份對應節點宕機的備份失效後可以從其他節點快速恢復。數據節點定期向名字節點發送心跳信息,名字節點通過心跳判斷數據節點狀態。名字節點對心跳信息進行定期檢查,如果名字節點在2次檢查間隔和10次心跳間隔中未收到數據節點的心跳信息,則判定該數據節點宕機。若連續兩次判斷該數據節點宕機,則從名字節點中移除該數據節點信息,然後調用恢復機制對其進行恢復。其中,兩次判斷節點是否宕機是考慮到故障處理需要對heartbeats和datanodeMap等同步操作,心跳處理函數就不能對他們更新,容易在系統超負載、機架故障造成大量數據節點故障時誤判。
具體地,判斷數據節點宕機所需時間的計算公式為:
timeout=2*heartbeat.recheck.interval+10*dfs.heartbeat.interval
其中,heartbeat.recheck.interval表示心跳檢查間隔,dfs.heartbeat.interval表示心跳間隔。通常默認heartbeat.recheck.interval為5分鐘,默認dfs.heartbeat.interval為3秒。因此,名字節點如果在10分鐘+30秒後,仍然沒有收到數據節點的心跳,就認為該數據節點已經宕機,並標記為宕機(dead)。
圖1所示為現有技術中不同數據節點中相同數據塊宕機檢測恢復示意圖,其顯示了數據節點宕機可能造成的數據塊危險係數提高的情況。其中,數據節點B和數據節點A有相同的數據塊b1。數據節點A和B向名字節點持續發送心跳信息,名字節點檢測心跳信息。圖中縱向虛線表示檢測時間點,上次檢測時間是5min時刻,顯示數據節點A和B都處於運行正常狀態。在檢測後某時刻數據節點B失效,則其中數據塊b1也失效。在接下來的一次檢測也就是10min時刻,檢測到數據節點B失效。之後要再做一次確認,也就是在15min時刻(忽略30s的心跳發送時間間隔)再次確認,發現數據節點B的確失效,故在15min時將數據節點B加入待恢復隊列,也就是將數據塊b1加入待恢復隊列。由於待恢復隊列中可能還有之前未恢復的數據塊,故並不是立刻恢復該數據塊。再過一段時間,即在圖中t2時刻數據節點B中數據塊b1被恢復,其副本數滿足系統需求。
如果在數據節點B出現問題後與其有共同數據塊b1的數據節點A在t1時刻也發生故障,在10min時刻未檢測到其心跳,則在15min時刻要再確認一次。但是,在此次確認中因為先發現了第二次確認的已失效的數據節點B,那麼對應的數據節點A的失效就會被忽視,並在之後的20min時刻才會被發現。此時,再將數據節點A加入到待恢復隊列,過段時間其中塊b1恢復後其副本數滿足系統需求。因此,在t1到t2這段時間裡對於塊b1來說,其數據節點危險係數增大,因為可用副本數為1。而系統發現這種情況並恢復第一個數據塊的時刻也在10分30秒之後。由上可知,現有技術中的數據節點的檢測恢復機制中,故障處理前需要再次確認故障狀態,再進行故障檢測和故障恢復。由於在故障檢測時間點和故障恢復之間存在較長時間差,忽視這段時間內故障節點的檢測,擁有相同數據塊的數據節點可能出問題,導致該數據塊的備份數降為1或0,存在數據丟失風險。
本發明的基於HDFS的節點失效的快速檢測與恢復方法在判斷數據節點宕機狀態前,加入一種危險(danger)狀態判斷。若在T時間(T<10min)未檢測到數據節點的心跳信息,則認為該數據節點處於危險狀態,將該數據節點加入到危險數據節點隊列中,並對危險數據節點隊列中各數據節點的數據塊進行比對以找出相同數據塊,該相同數據塊即為危險數據塊。系統為相同數據塊設置恢復優先級,將該相同數據塊提前加入到待恢復隊列進行恢復,從而將宕機數據節點中的危險數據塊提前進行恢復,降低了危險數據塊的風險。
參照圖2,本發明的基於HDFS的節點失效的快速檢測與恢復方法包括以下步驟:
步驟S1、設定危險節點時間間隔,若在危險節點時間間隔未檢測到數據節點的心跳信息,則判斷該數據節點為危險節點,將其加入危險數據節點隊列;其中,危險節點時間間隔須小於判斷數據節點宕機所需時間。
其中,判斷數據節點宕機所需時間通常為10min+30s。優選地,危險節點時間間隔設置為5min。
具體地,遍歷心跳信息表中每條心跳信息。心跳信息表用於記錄每次心跳時各個數據節點的心跳信息。因此,遍歷心跳信息表,也就是檢測對應的每個數據節點,判斷其所處的狀態。如果在危險節點時間間隔,未檢測到數據節點的心跳信息,則判定該數據節點處於危險狀態。如果數據節點處於非危險狀態卻被加入了危險數據節點隊列,則需要將其從危險數據節點隊列中移除。這是因為部分數據節點可能是短期內由於網絡狀況與名字節點失去連接,之後又恢復連接。因此,將此類數據節點從危險數據節點列表中移除,能夠減少不必要的系統負擔。
若數據節點在加入危險數據節點隊列後,被判斷處於宕機狀態,也就是說在10min30s後被判斷為處於宕機狀態,則將其從危險數據節點列表中移除,並根據現有機制,將該數據節點加入到待恢復隊列依次進行恢復。
步驟S2、在危險數據節點隊列中,查找各數據節點中的相同數據塊。
具體地,在危險數據節點隊列中的數據節點中,出現兩次及以上的數據塊即為所要查找的相同數據塊。
步驟S3、根據相同數據塊的出現次數設置恢復優先級,並根據恢復優先級將相同數據塊加入待恢復隊列,優先進行恢復。
其中,相同數據塊出現的次數越多,表明其存活的副本數越少,則恢復優先級越高;相同數據塊出現的次數越少,表明其存活的副本數越多,則恢復優先級越低。
設定相同數據塊的出現次數為該數據塊的危險係數。其中,危險係數越大,表明該數據塊的存活副本數越少,危險程度越高。反之,危險係數越小,表明該數據塊的存活副本數越多,危險程度越低。危險係數通常取值為0、1和2。
具體地,在數據塊block的定義中加入danger標記,danger=0,1,2。通過定義countDangerNodes(Block b)函數判斷數據塊b在危險節點隊列中出現的次數。通過blocksMaps查詢存儲該數據塊副本的其他數據節點信息,因此查詢相同的數據塊也就轉化為查詢存儲該數據塊副本的其他數據節點在危險數據節點隊列中出現的次數。在危險數據節點隊列中每出現一個存儲該數據塊副本的數據節點,則該數據塊的危險係數danger加1。遍歷完危險數據節點隊列後,即可返回得到該數據塊block對應的危險係數。當引入危險係數danger後,存活副本數為原存活副本數減去危險係數後的值。採用現有機制中恢復數據塊時要檢測該數據塊的存活副本數countNodes,只需將存活副本數修改為原存活副本數減去危險係數後的值。這樣不對現有機製做過多修改,現有機制也可以正常運行。其中,原存活副本數等於所有副本數減去處於宕機狀態的副本數。
具體地,對於相同數據塊,存活副本數越多,優先級越低;存活副本數越少,優先級越高;所述存活副本數等於所有副本數減去宕機副本數和相同數據塊的出現次數。即存活副本數等於所有副本數減去宕機副本數和危險係數。
在待恢復隊列中,根據恢復優先級先後對不同的數據塊進行恢復;對於相同恢復優先級的不同數據塊,則按照加入恢復隊列的先後依次進行恢復。
圖3所示為本發明中不同數據節點中相同數據塊宕機檢測恢復示意圖。由圖可知,數據節點A、B有著相同的數據塊b1。在第二次確認數據節點失效之前,也就是t1時刻檢測該數據節點是否屬於危險節點。其中,判斷該數據節點上次檢測時間與此次檢測的時間間隔是否超過設置的危險節點時間間隔,如果是,則將該數據節點加入危險數據節點隊列。若設置的危險檢測點是t1時刻,即t1時刻與10min時刻間的時間間隔等於危險節點時間間隔,那麼數據節點A和B將在此刻加入到危險數據節點隊列中;同時,遍歷危險數據節點隊列中的數據塊,將相同的數據塊根據出現次數設置恢復優先級,並根據恢復優先級優先進行恢復。也就是說,此處的數據塊b1被加入待恢復隊列,其加入隊列的時刻是t1時刻,過一段時間後被恢復,這時b1副本數符合系統要求。
下面結合具體實施例來進一步說明本發明的基於HDFS的節點失效的快速檢測與恢復方法。
1、修改代碼重新編譯
對HDFS對應代碼進行修改,並將做過修改的代碼文件重新編譯,導出相應的jar文件,替換原有文件。在數據節點和名字節點上用的的源碼都是修改編譯後的源碼。
2、環境部署:
以四臺計算機為例搭建,其中包括
一個master節點(名字節點),為master 192.168.0.136
三個slave節點(數據節點),分別為slave 192.168.0.137、slave 192.168.0.138和slave192.168.0.139。
首先,修改master節點上的配置文件,需要修改的文件有:
/etc/hostname,/etc/hosts,/home/hadoop/hadoop/conf/masters,/home/hadoop/hadoop/conf/slaves,/home/hadoop/hadoop/conf/core-site.xml,/home/hadoop/hadoop/conf/hdfs-site.xml,/home/hadoop/hadoop/conf/mapred-site.xml
接著,修改每臺計算機的/etc/hostname,以便於進行網絡配置。以192.168.0.136為例,修改/etc/hostname,將原來的localhost改成n136。其他機器也如此。
然後,修改master(即n136)上的/etc/hosts,將裡面所有的內容都注釋掉,添加以下信息:
該步驟是將每個節點的ip和計算機名聯繫起來,因為在hadoop中,防止出現找不到計算機名而報錯的情況。
接著,修改master上的/home/hadoop/hadoop/conf/masters文件,把裡面原來的localhost修改成n136,將計算機名與hadoop配置文件中的節點角色聯繫起來。
再修改master上的/home/hadoop/hadoop/conf/slaves文件,把裡面的localhost清除,添加以下信息:d137 d138 d139
接著,修改master節點上的/home/hadoop/hadoop/conf/core-site.xml文件,只需修改fs.default.name項為:
這裡指明文件系統的入口是master(即n136)的9000號埠。
接著,修改master上的/home/hadoop/hadoop/conf/hdfs-site.xml文件,把dfs.replication改成默認的3(採用默認值3)。
最後,修改master上的/home/hadoop/hadoop/conf/mapred-site.xml文件,修改mapred.job.tracker:
這裡將MapReduce中的jobtracker放在了master上,其實也可以放在其他節點上,這根據具體情況而定,與對HDFS修改做測試無關。
3、測試
在master為1、slaver為3的集群中,通過客戶端向集群數據節點寫入文件,使其中兩個數據節點宕機,等待系統信息輸出。在檢測到數據節點失效及進行數據節點恢復時系統會輸出相應時間信息,過段時間後查看加入待恢復隊列時系統列印出的數據節點開始恢復的時間信息。根據返回時間信息調整危險節點時間間隔(heartbeatDangerInterval)參數,使其系統在固定數據量範圍內達到性能最優。
參照圖4,本發明的基於HDFS的節點失效的快速檢測與恢復系統包括檢測判斷模塊1、查找模塊2和恢復模塊3。
檢測判斷模塊1用於設定危險節點時間間隔,並在危險節點時間間隔未檢測到數據節點的心跳信息時,判斷該數據節點為危險節點,將其加入危險數據節點隊列;其中,危險節點時間間隔須小於判斷數據節點宕機所需時間。
其中,判斷數據節點宕機所需時間通常為10min+30s。優選地,危險節點時間間隔設置為5min。
具體地,遍歷心跳信息表中每條心跳信息。心跳信息表用於記錄每次心跳時各個數據節點的心跳信息。因此,遍歷心跳信息表,也就是檢測對應的每個數據節點,判斷其所處的狀態。如果在危險節點時間間隔,未檢測到數據節點的心跳信息,則判定該數據節點處於危險狀態。如果數據節點處於非危險狀態卻被加入了危險數據節點隊列,則需要將其從危險數據節點隊列中移除。這是因為部分數據節點可能是短期內由於網絡狀況與名字節點失去連接,之後又恢復連接。因此,將此類數據節點從危險數據節點列表中移除,能夠減少不必要的系統負擔。
若數據節點在加入危險數據節點隊列後,被判斷處於宕機狀態,也就是說在10min30s後被判斷為處於宕機狀態,則將其從危險數據節點列表中移除,並根據現有機制,將該數據節點加入到待恢復隊列依次進行恢復。
查找模塊2與檢測判斷模塊1相連,用於在危險數據節點隊列中,查找各數據節點中的相同數據塊。
具體地,在危險數據節點隊列中的數據節點中,出現兩次及以上的數據塊即為所要查找的相同數據塊。
恢復模塊3與查找模塊2相連,用於根據相同數據塊的出現次數設置恢復優先級,並根據恢復優先級將相同數據塊加入待恢復隊列,優先進行恢復。
其中,相同數據塊出現的次數越多,表明其存活的副本數越少,則恢復優先級越高;相同數據塊出現的次數越少,表明其存活的副本數越多,則恢復優先級越低。
設定相同數據塊的出現次數為該數據塊的危險係數。其中,危險係數越大,表明該數據塊的存活副本數越少,危險程度越高。反之,危險係數越小,表明該數據塊的存活副本數越多,危險程度越低。危險係數通常取值為0、1和2。
具體地,在數據塊block的定義中加入danger標記,danger=0,1,2。通過定義countDangerNodes(Block b)函數判斷數據塊b在危險節點隊列中出現的次數。通過blocksMaps查詢存儲該數據塊副本的其他數據節點信息,因此查詢相同的數據塊也就轉化為查詢存儲該數據塊副本的其他數據節點在危險數據節點隊列中出現的次數。在危險數據節點隊列中每出現一個存儲該數據塊副本的數據節點,則該數據塊的危險係數danger加1。遍歷完危險數據節點隊列後,即可返回得到該數據塊block對應的危險係數。當引入危險係數danger後,存活副本數為原存活副本數減去危險係數後的值。採用現有機制中恢復數據塊時要檢測該數據塊的存活副本數countNodes,只需將存活副本數修改為原存活副本數減去危險係數後的值。這樣不對現有機製做過多修改,現有機制也可以正常運行。其中,原存活副本數等於所有副本數減去處於宕機狀態的副本數。
具體地,對於相同數據塊,存活副本數越多,優先級越低;存活副本數越少,優先級越高;所述存活副本數等於所有副本數減去宕機副本數和相同數據塊的出現次數。即存活副本數等於所有副本數減去宕機副本數和危險係數。
在待恢復隊列中,根據恢復優先級先後對不同的數據塊進行恢復;對於相同恢復優先級的不同數據塊,則按照加入恢復隊列的先後依次進行恢復。
綜上所述,本發明的基於HDFS的節點失效的快速檢測與恢復方法及系統在HDFS原有檢測機制上維護一個危險數據節點隊列,並對該危險數據節點隊列中各數據節點的數據塊進行比對以找出相同數據塊,並將相同數據塊提前加入待恢復隊列,優先進行相同數據塊的恢復;保證各數據節點的數據塊可用,基本不增加網絡帶寬;提前恢復了危險數據塊,降低了系統風險。所以,本發明有效克服了現有技術中的種種缺點而具高度產業利用價值。
上述實施例僅例示性說明本發明的原理及其功效,而非用於限制本發明。任何熟悉此技術的人士皆可在不違背本發明的精神及範疇下,對上述實施例進行修飾或改變。因此,舉凡所屬技術領域中具有通常知識者在未脫離本發明所揭示的精神與技術思想下所完成的一切等效修飾或改變,仍應由本發明的權利要求所涵蓋。