一種諾麗內生真菌的分離鑑定方法與流程
2023-05-17 14:37:36 6
本發明涉及微生物分離鑑定技術領域,具體涉及一種諾麗內生真菌的分離鑑定方法。
背景技術:
植物內生真菌(endophyticfungi)是指那些生活在地上部分且活的植物組織體內,但不引起宿主植物患病的一類有益真菌。因此,植物內生真菌是植物體內微生態系統中的天然組成成分,其長期生活在植物體內這種特殊環境中,不會導致植物患病,反而與宿主植物協同進化,並在演化過程中逐漸形成互惠共生的關係。藥用植物內生真菌的次生代謝產物十分豐富,具有抗菌、抗腫瘤、抗病毒、殺蟲、調節免疫及促進植物生長等生物活性,是篩選生物活性成分或先導化合物的有效途徑之一,在工業發酵、生物製藥、農業生產等領域具有潛在的應用價值。
諾麗(morindacitrifolialinn.)是茜草科巴戟天屬的植物,在熱帶地區有著悠久的食用歷史,最早可追溯到317世紀晚期。1943年,美國政府將諾麗果認定為可食用植物資源;2003年,歐盟委員會提名諾麗果汁為一種新資源食品;2010年5月,中國衛生部批准諾麗果漿為新資源食品。現代醫學和生物學研究證明,諾麗果和果汁對某些疾病具有一定的治療和輔助治療作用,如抗腫瘤、提高免疫力、抗氧化、護肝、抗菌消炎、改善糖尿病、抗血脂、降血壓、改善痛風等。近幾年來,隨著研究的不斷深入和新功能的不斷發現,諾麗果已經成為世界藥用植物和保健飲料的新寵。
諾麗因其卓有特效的抗癌效果而屢遭砍伐及毀滅性利用,加上種群分布的局限性,使得該植物種質資源並不豐富,甚至於處於瀕危滅絕的邊緣。由於內生真菌具有產生和寄主植物一樣的次生代謝產物和活性成分,且分離純化的內生真菌能通過發酵技術生產相應的活性物質,內生真菌的藥用價值已成為國際熱點,需最大可能地保留內生真菌不被殺滅。目前內生真菌常採用組織分離法分離,其缺陷有:(1)表面過分消毒,殺死部分內生真菌;(2)表面消毒不充分,表面菌汙染;(3)生長快的內生真菌覆蓋一些生長緩慢的真菌;(4)所用培養基不能確保所有內生真菌都生長。諾麗內生真菌的藥用潛力並沒有實現較大程度的挖掘。
技術實現要素:
本發明的目的在於提供一種諾麗內生真菌的分離鑑定方法。本發明提供的方法能夠實現諾麗內生真菌的有效分離和鑑定,為抗癌、抗炎藥物研發提供新思路。
本發明提供了一種諾麗內生真菌的分離鑑定方法,包括以下步驟:
1)對諾麗果和葉進行表面消毒;
2)將諾麗果和葉的內部組織置於馬鈴薯葡萄糖瓊脂培養基上,25±1℃黑暗條件下培養8~10天;
3)將步驟2)培養得到的菌株進行傳代培養,通過4~5次連續的菌絲尖端轉移進行純化,得到諾麗內生真菌;
4)對步驟3)得到的諾麗內生真菌進行its測序鑑定。
優選的是,所述步驟1)中的諾麗果和葉為八成熟。
優選的是,所述步驟1)的表面消毒包括次氯酸鈉溶液消毒和乙醇溶液消毒。
優選的是,所述次氯酸鈉溶液中次氯酸鈉的質量濃度為2.6~3.5%,所述乙醇溶液中乙醇的質量濃度為75%。
優選的是,次氯酸鈉溶液消毒的時間為60~300s,乙醇溶液消毒的時間為30~180s。
優選的是,所述步驟1)的表面消毒後還包括:採用無菌水對諾麗果和葉清洗2~4次。
優選的是,步驟2)得到的諾麗果和葉的邊緣部分採用組織印跡法進行無菌檢測。
優選的是,所述步驟3)得到的諾麗內生真菌後還包括:將諾麗內生真菌在馬鈴薯葡萄糖肉湯培養基中進行培養,所述培養條件為25±1℃,20rpm進行液體暗培養。
優選的是,所述步驟4)的its測序鑑定基於核糖體its區域的its1f和its4基因序列。
優選的是,所述its測序鑑定用引物如seqidno:1和seqidno:2所示。
本發明提供了一種諾麗內生真菌的分離鑑定方法,實現了內生真菌的有效分離、純化和鑑定。本發明提供的植物樣品表面消毒方法既能保證充分消毒,達到有效去除表面汙染菌的目的,又能避免過度的表面消毒,將部分內生真菌殺死,克服了現有植物內生真菌分離方法存在的某些菌種丟失的缺陷。通過多次試驗發現,25±1℃既有利於內生真菌的生長又抑制內生細菌的萌發,黑暗條件是模擬傳統發酵和植物自然生長的條件,有利於內生真菌的生長,本發明採用25±1℃黑暗條件下培養8~10天。核糖體itsrdna區域與rdna的其他基因區相比,具有最佳的變異度和解析度,能將諾麗內生真菌進行分子識別並鑑別到種的水平。我國許多珍稀植物資源不斷減少,甚至瀕臨滅絕。本發明提供的內生真菌分離方法,能夠有效分離植物內生真菌,通過發酵技術生產相應的活性物質,這對植物資源的保護和可持續利用具有重要的價值。
附圖說明
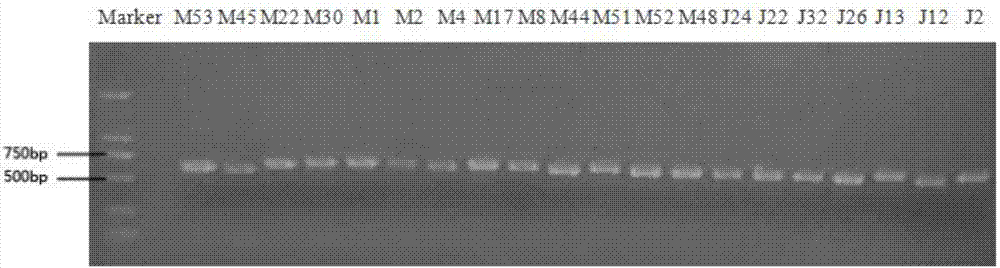
圖1為本發明實施例1提供的諾麗果和葉的內生真菌的itsrdnapcr擴增片段的瓊脂糖凝膠電泳結果圖;
圖2為本發明實施例1提供的諾麗果和葉中分離得到的內生真菌培養圖片。
具體實施方式
本發明提供了一種諾麗內生真菌的分離鑑定方法,包括以下步驟:
1)對諾麗果和葉進行表面消毒;
2)將諾麗果和葉的內部組織置於馬鈴薯葡萄糖瓊脂培養基上,25±1℃黑暗條件下培養8~10天;
3)將步驟2)培養得到的菌株進行傳代培養,通過4~5次連續的菌絲尖端轉移進行純化,得到諾麗內生真菌;
4)對步驟3)得到的諾麗內生真菌進行its測序鑑定。
本發明對諾麗果和葉進行表面消毒。在本發明中,優選選取健康、八成熟的諾麗果和葉。在本發明中,所述諾麗果和葉優選在用無菌水衝洗後進行保存備用,所述保存的溫度優選為4℃。
在本發明中,所述表面消毒包括次氯酸鈉溶液消毒和乙醇溶液消毒。在本發明中,所述次氯酸鈉溶液中次氯酸鈉的質量濃度為2.6~3.5%,所述乙醇溶液中乙醇的質量濃度為75%。
在本發明中,次氯酸鈉溶液消毒的時間為60~300s,乙醇溶液消毒的時間為30~180s。本發明優選採用次氯酸鈉溶液和乙醇溶液進行消毒,所述次氯酸鈉溶液的處理時間優選獨立地選自60s、120s、180s、240s或300s;所述乙醇溶液的處理時間優選獨立地選自30s、60s、90s、120s、150s或180s;即本發明優選從上述30個組合中選取任意一種組合進行諾麗果和葉的消毒,具體組合方式如下:次氯酸鈉溶液浸泡時間+乙醇溶液消毒時間:60s+30s、60s+60s、60s+90s、60s+120s、60s+150s、60s+180s;120s+30s、120s+60s、120s+90s、120s+120s、120s+150s、120s+180s;180s+30s、180s+60s、180s+90s、180s+120s、180s+150s、180s+180s;240s+30s、240s+60s、240s+90s、240s+120s、240s+150s、240s+180s;300s+30s、300s+60s、300s+90s、300s+120s、300s+150s、300s+180s。本發明優選選取次氯酸鈉溶液浸泡時間+乙醇溶液消毒時間120s+30s、120s+60s、180s+30s、180s+60s、240s+30s、240s+60s、300s+30s、300s+60s進行消毒,最優選採用次氯酸鈉溶液浸泡時間+乙醇溶液消毒時間80s+180s、240s+150s、240s+180s、300s+90s、300s+120s、300s+150s、300s+180s進行消毒。
在本發明中,所述表面消毒後,優選採用無菌水對諾麗果和葉清洗2~4次,更優選為3次。本發明在清洗後,優選吸乾水分,本發明對所述吸乾的方法沒有特殊的限定,採用本領域技術人員熟知的常規水分吸乾方法即可,如採用無菌濾紙吸乾水分。
得到表面消毒後的諾麗果和葉,本發明將諾麗果和葉的內部組織置於馬鈴薯葡萄糖瓊脂培養基上,25±1℃黑暗條件下培養8~10天。本發明優選通過去除諾麗果和葉的邊緣部分以獲得諾麗果和葉的內部組織,本發明對所述去除的方法沒有特殊的限定,具體的,本發明優選採用滅菌手術刀去除諾麗果和葉的邊緣部分0.5~0.8cm。本發明得到諾麗果和葉的邊緣部分後,優選對邊緣部分進行無菌檢測。在本發明中,所述無菌檢測的方法優選採用組織印跡法:將諾麗果和葉的邊緣部分置於馬鈴薯葡萄糖瓊脂(pda)固體培養基平板上,輕輕滾動或緊貼培養基放置2min,接著移去諾麗果和葉的邊緣部分,在25±1℃、黑暗條件下恆溫培養8~10天,無雜菌長出即說明消毒後的果塊或葉塊表面無菌,驗證表面無菌後,本發明將無菌的內部組織進行後續的處理。本發明採用組織塊印記法作對照,確保分離鑑定的是諾麗果和葉的內生真菌,具有操作簡單快捷、成本較低的優勢。
本發明得到諾麗果和葉的內部組織後,優選將果內部或中心部分切分成1cm×1cm大小的組織塊,葉內部或中心部分切分成0.5cm×0.5cm大小的組織塊,本發明將組織塊置於馬鈴薯葡萄糖瓊脂培養基上25℃黑暗條件下培養8~10天。本發明對所述pda培養基的製備方法沒有特殊的限定,採用本領域技術人員熟知的pda培養基即可,具體的,所述馬鈴薯葡萄糖瓊脂(pda)固體培養基的成分為:馬鈴薯浸粉3g、葡萄糖20g、瓊脂粉15g、氯黴素0.1g,每1000ml蒸餾水中加pda38g;使用前pda固體培養基在121℃、0.1mpa下滅菌20min。
本發明將上述培養得到的菌株分別傳代培養,通過4~5次連續的菌絲尖端轉移進行純化,得到諾麗內生真菌。在本發明中,所述諾麗內生真菌在馬鈴薯葡萄糖肉湯培養基(pdb)中進行傳代培養,所述傳代培養條件為25±1℃,20rpm進行液體暗培養。本發明對所述pdb培養基的製備方法沒有特殊的限定,採用本領域技術人員熟知的pdb培養基即可,具體的,所述馬鈴薯葡萄糖肉湯(pdb)液體培養基的成分為:馬鈴薯浸粉5g、葡萄糖15g、蛋白腖10g、氯化鈉5g,每1000ml蒸餾水中加pdb35g;使用前pdb液體培養基在121℃、0.1mpa下滅菌20min。
得到諾麗內生真菌後,本發明對諾麗內生真菌進行its測序鑑定。本發明的測序鑑定為對諾麗內生真菌進行進一步分類。在本發明中,所述its測序鑑定基於核糖體its區域的its1f和its4基因序列。在本發明中,所述its測序鑑定用引物如seqidno:1和seqidno:2所示。所述引物的具體序列為its4:5』-tcctccgcttattgatatgc-3』(seqidno:1);its1f:5』-cttggtcatttagaggaagtaa-3』(seqidno:2)。本發明所述引物擴增得到的序列片段大小分別為700bp和500~700bp,條帶需單一明亮。本發明引物擴增出的序列經測序後語ncbi資料庫進行blast比對,進行菌種的鑑定。本發明對所述pcr的擴增條件沒有特殊的限定,採用本領域技術人員熟知的基因擴增方法條件即可。本發明優選選取諾麗內生真菌的基因組dna為模板進行擴增,本發明對所述基因組的提取方法沒有特殊的限定,採用本領域技術人員熟知的市售真菌基因組dna提取試劑盒進行提取即可。
下面結合具體實施例對本發明所述的一種諾麗內生真菌的分離鑑定方法做進一步詳細的介紹,本發明的技術方案包括但不限於以下實施例。
實施例1
本發明在2016年3月至2016年12月從中國海南省海口市(北緯20°03′35",東經110°19′44",海拔9m)、萬寧市(北緯18°45′24",東經110°72′06",海拔33m)、瓊海市(北緯19°16′56",東經110°37′46",海拔10m)、三亞市(北緯18°20′38",東經109°34′41",海拔35m)、臨高市(北緯19°54′58",東經109°38′46",海拔76m)、儋州市(北緯19°30′38",東經109°34′21",海拔158m)六個市縣獲得。
本發明諾麗(morindacitrifolialinn.)內生真菌的具體分離純化操作步驟如下:
(1)諾麗果和葉的準備:採集諾麗健康、八成熟的果和葉,無菌水衝洗後,即得待分離內生真菌的植物樣品,將其存放無菌袋中於4℃保存。
(2)植物樣品的表面消毒與無菌檢測:將所述植物樣品用純淨水洗淨,分別依次以2.6%-3.5%次氯酸鈉+75%酒精按照不同的消毒時間做30個組合進行表面消毒,具體方案如下:次氯酸鈉浸泡時間+酒精消毒時間60s+30s、60s+60s、60s+90s、60s+120s、60s+150s、60s+180s;120s+30s、120s+60s、120s+90s、120s+120s、120s+150s、120s+180s;180s+30s、180s+60s、180s+90s、180s+120s、180s+150s、180s+180s;240s+30s、240s+60s、240s+90s、240s+120s、240s+150s、240s+180s;300s+30s、300s+60s、300s+90s、300s+120s、300s+150s、300s+180s。然後無菌水洗滌3次,無菌濾紙吸乾水分。用滅過菌的手術刀將果和葉邊緣部分去除,果內部或中心部分切分成1cm×1cm大小的組織塊,葉內部或中心部分切分成0.5cm×0.5cm大小的組織塊。部分果塊或葉塊放在滅過菌的馬鈴薯葡萄糖瓊脂(pda)固體培養基平板上,25±1℃、黑暗條件下恆溫培養8~10天。
將另一部分果塊和葉塊進行無菌檢測:採用組織印跡法,將果塊或葉塊置於馬鈴薯葡萄糖瓊脂(pda)固體培養基平板上,輕輕滾動或緊貼培養基放置2min,接著移去果塊或葉塊,在25±1℃、黑暗條件下恆溫培養8-10天,無雜菌長出即說明消毒後的果塊或葉塊表面無菌。
所述馬鈴薯葡萄糖瓊脂(pda)固體培養基的成分為:馬鈴薯浸粉3g、葡萄糖20g、瓊脂粉15g、氯黴素0.1g,每1000ml蒸餾水中加pda38g;使用前pda固體培養基在121℃、0.1mpa下滅菌20min。
(3)內生真菌的分離純化培養:當步驟(2)的馬鈴薯葡萄糖瓊脂(pda)固體培養基平板上的諾麗果塊或葉塊周圍長出菌絲時,採用尖端菌絲挑取法,把培養得到的菌絲尖端部分,移至新的pda平板培養基上,25±1℃黑暗條件下培養8-10天長出完整菌落;重複上述步驟4-5次直至得到純菌落,即得植物內生真菌,挑取純菌落內生真菌的尖端部分移至pda斜面培養基上,25±1℃、黑暗條件下培養8-10天,於4℃保存;
真菌基因組dna提取:將保存的諾麗果和葉內生真菌活化培養後,接種到馬鈴薯葡萄糖肉湯(pdb)液體培養基中,放入恆溫搖床在25±1℃、50rpm/min、黑暗條件下液體培養5天。根據其形態特徵將其初步分為酵母菌和黴菌,採用真菌基因組dna提取試劑盒的使用方法,提取內生真菌的dna。
具體步驟如下:1.對於酵母菌,取1~2ml培養好的菌液,離心收集,棄上液。加入200μl溶液a,加入20μlrnasea,再加入100mg玻璃珠,在高速振蕩器上振蕩,約5-10min。
1.黴菌(孢子也可相同處理):取1-2ml培養好的菌液,離心收集,棄上液加200μl溶液a,用玻璃研磨器適當研磨分散菌絲,加入200μl溶液a,再加入100mg玻璃珠,在高速振蕩器上振蕩約30min。
2.加入20μl的蛋白酶k(10mg/ml),充分混勻,55℃水浴消化30min,消化期間可顛倒離心管混勻數次。12000rpm離心2min。將上清液轉移到一個新的離心管中。如有沉澱,可再次離心。
3.在上清液中加入200μl溶液b,充分混勻。如出現白色沉澱,可放55℃水浴5min,沉澱即會消失,不影響後續實驗。如溶液未變清亮,說明樣品消化不徹底,可能導致提取的dna量少及不純,還可能導致上柱後堵塞柱子,增加消化時間。
4.再加入200μl無水乙醇,充分混勻,此時可能會出現絮狀沉澱,不影響dna的提取,將溶液和絮狀沉澱都加入吸附柱,放置2min。
5.12000rpm離心1min,棄廢液,將吸附柱放入收集管中。
6.向吸附柱中加入600μl漂洗液(使用前請先檢查是否已加入無水乙醇),12000rpm離心1min,棄廢液,將吸附柱放入收集管中,重複一次。
7.12000rpm離心2min,將吸附柱置於室溫或50℃恆溫箱放置數分鐘,目的是將吸附柱中殘餘的漂洗液去除,否則漂洗液中的乙醇會影響後續的實驗,如酶切、pcr擴增等。
8.將吸附柱放入一個乾淨的離心管中,向吸附膜中央懸空滴加50-200μl經65℃水浴預熱的洗脫液,室溫放置5min,12000rpm離心1min。
9.離心所得的洗脫液再加入吸附柱中,室溫放置2min,12000rpm離心2min,即可得到高質量的基因組dna。
以上真菌基因組dna的提取步驟均在室溫下進行。
所述馬鈴薯葡萄糖肉湯(pdb)液體培養基的成分為:馬鈴薯浸粉5g、葡萄糖15g、蛋白腖10g、氯化鈉5g,每1000ml蒸餾水中加pdb35g,使用前pdb液體培養基在121℃、0.1mpa下滅菌20min。
對上述提取的基因組dna,採用通用引物對its4和its1f進行pcr擴增。
pcr擴增體系:無菌水9.5μl、2·pcrmix12.5μl、引物ⅰ(its4)1.0μl,引物ⅱ(its1f)1.0μl,dna模板1.0μl,共25μl。(its4:5』-tcctccgcttattgatatgc-3』;its1f;5』-cttggtcatttagaggaagtaa-3』)。
pcr反應程序:94℃預變形5min,94℃變性40s,55℃退火40s,72℃延伸55s,共35個循環,最後72℃延伸10min,4℃保存,引物序列由海南光威科技有限公司合成。
對pcr產物進行檢測:擴增產物在1.2%瓊脂糖凝膠上電泳,並拍照保存。
序列測定:將pcr擴增產物送至北京六合華大基因科技有限公司廣州分公司進行測序,並將序列在ncbi資料庫中進行blast比對。
本發明在2016年3月-2016年12月採集海南省六個市(縣)的諾麗果和葉,在時間和地理位置上均豐富了內生真菌的種類。
本發明對諾麗果和葉採用不同的表面消毒處理,既能確保充分消毒,達到有效去除表面汙染菌的目的,又能避免過度的表面消毒,將部分內生真菌殺死,克服了現有植物內生真菌分離方法存在的某些菌種丟失的缺陷。試驗結果表明:1、2.6%次氯酸鈉+75%酒精在以下8組合消毒時間處理中除菌效果良好(120s+30s、120s+60s、180s+30s、180s+60s、240s+30s、240s+60s、300s+30s、300s+60s);2、2.6%次氯酸鈉+75%酒精在以下7組合消毒時間中沒有菌落長出(80s+180s、240s+150s、240s+180s、300s+90s、300s+120s、300s+150s、300s+180s)。
本發明所描述的分離得到諾麗內生真菌共有41株,經分子生物學its基因序列分析。pcr擴增得到itsrdna的序列片段條帶大小分別為700bp和500-700bp,條帶均單一明亮(圖1)。登錄ncbi資料庫將諾麗內生真菌已擴增的dna序列用blast進行序列比對,分別屬於擔子菌門(basidiomycota)、子囊菌門(ascomycota)兩個類群,包括刺盤孢屬(colletotrichum)、間座殼屬(diaporthe)、炭團菌屬(hypoxylon)、枝孢屬(cladosporium)、鐮刀菌屬(fusarium)、葉點黴屬(phyllosticta)、赤黴屬(gibberella)、金擔子菌屬(aureobasidium)、薔薇色酵母屬(rhodotorula)、隱球菌屬(cryptococcus)、麴黴屬(aspergillus)11個屬,26種(如表1所示)。上述26種諾麗內生真菌itsrrna測序結果序列如seqidno.3~seqidno.28所示。
本發明從諾麗(morindacitrifolialinn.)果和葉中分離得到的內生真菌特徵如下:
m22.菌體黑色,質地溼潤,有色素產生,滲透到培養基中,表面有突起,邊緣不整齊。
m30.菌體黑色,質地溼潤,表面平整,邊緣整齊。
m45.淡褐色菌絲,質地溼潤,產生褐色色素,表面平整,邊緣整齊。
m53.白色菌絲,質地溼潤,表面有液體生成,產生黑色色素,滲透到培養基中,邊緣呈羽毛狀。
m44.白色菌絲,質地乾燥,表面平整,邊緣不整齊。
m18.棕色孢子,質地乾燥,白色菌絲,表面平整,邊緣整齊。
m49.菌體褐色,質地溼潤,有色素產生,滲透到培養基中,表面有突起,邊緣不整齊。
m52.白色菌絲,質地溼潤,表面有液體生成,產生黑色色素,滲透到培養基中,邊緣不整齊。
m48.菌體黑色,質地乾燥,有色素產生,滲透到培養基中,表面有突起,邊緣不整齊。
m51.白色菌絲,質地溼潤,菌絲呈放射狀,滲透到培養基中,表面平整,邊緣不整齊。
m1.白色菌絲,質地乾燥,呈蓬鬆狀,表面有黑色孢子,表面凸起,邊緣不整齊。
m2.褐色孢子,質地乾燥,白色菌絲,背面有褶皺,表面凸起,邊緣不整齊。
m4.白色菌絲,質地乾燥,呈蓬鬆狀,表面有褐色孢子,表面凸起,邊緣不整齊。
m8.白色菌絲,質地乾燥,呈蓬鬆狀,表面有黑色孢子,背面有褶皺,邊緣不整齊。
m17.白色菌絲上,黑色孢子,質地乾燥,表面凸起,邊緣不整齊。
m12.褐色孢子,白色菌絲,質地乾燥,表面凸起,邊緣不整齊。
m15.棕色孢子,白色菌絲,質地乾燥,表面平整,邊緣整齊。
m16.黑色孢子,白色菌絲,質地乾燥,表面平整,邊緣不整齊,乾燥。
m40.黑色孢子,菌絲淡黃色,質地乾燥,表面平整,邊緣整齊。
m37.杆狀褐色孢子,白色菌絲,質地乾燥,背面有褶皺,邊緣不整齊。
j24.菌體透明色,質地溼潤,表面平整,邊緣整齊。
j22.菌體乳白色,質地粘稠,不透明,表面凸起,邊緣不整齊。
j12.菌體紅色,質地粘稠,不透明,表面凸起,邊緣整齊。
j13.菌體粉紅色,質地粘稠,不透明,表面平整,邊緣整齊。
j26.菌體粉紅色,質地粘稠,不透明,表面凸起,邊緣整齊。
j32.菌體淡黃色,質地溼潤,不透明,表面平整,邊緣整齊。
表1:諾麗(morindacitrifolialinn.)果和葉中分離得到的內生真菌
以上所述僅是本發明的優選實施方式,應當指出,對於本技術領域的普通技術人員來說,在不脫離本發明原理的前提下,還可以做出若干改進和潤飾,這些改進和潤飾也應視為本發明的保護範圍。
sequencelisting
2017
海南大學
一種諾麗內生真菌的分離鑑定方法
2017
28
patentinversion3.3
1
20
dna
人工序列
1
tcctccgcttattgatatgc20
2
22
dna
人工序列
2
cttggtcatttagaggaagtaa22
3
552
dna
人工序列
3
gggggtttcgagtaccgctcttataccctttgtgacataccccaaacgttgcctcggcgg60
gcagccggagcccagctccgtcgcccggagccgccgtctcggcgcgccccacccgccggc120
ggaccaccaaactctatttaaacgacgtctcttctgagtggcacaagcaaataatcaaaa180
cttttaacaacggatctcttggttctggcatcgatgaagaacgcagcgaaatgcgataag240
taatgtgaattgcagaattcagtgaatcatcgaatctttgaacgcacattgcgcccgcca300
gcattctggcgggcatgcctgttcgagcgtcatttcaaccctcaagcaccgcttggcgtt360
ggggccctacggcttccgtaggccccgaaatacagtggcggaccctcccggagcctcctt420
tgcgtagtaacataccacctcgcactgggatccggagggactcctgccgtaaaacccccc480
aattttccaaaggttgacctcggatcaggtaggaatacccgctgaacttaagcatatcaa540
taagcggaggaa552
4
595
dna
人工序列
4
ttattaattgggtaccgctccttataaccctttgtgacataccccaaacgttgcctcggc60
gggcagccggagcccagctccgtcgcccggagccgccgtctcggcgcgccccacccgccg120
gcggaccaccaaactctatttaaacgacgtctcttctgagtggcacaagcaaataatcaa180
aacttttaacaacggatctcttggttctggcatcgatgaagaacgcagcgaaatgcgata240
agtaatgtgaattgcagaattcagtgaatcatcgaatctttgaacgcacattgcgcccgc300
cagcattctggcgggcatgcctgttcgagcgtcatttcaaccctcaagcaccgcttggcg360
ttggggccctacggcttccgtaggccccgaaattcagtggcggaccctcccggatcctcc420
tttgcgtagaaacatagcacctcgcactgggatccggatggactcctgccgtaaaaccct480
ccaattgggcaaaggaagaactcgtatcaggtagcaatacccgttgaacttagccttacc540
tcggaaccggaagaaaaacccggttaaattttttctttcttttaagtggaggaag595
5
592
dna
人工序列
5
gaattggcatctacctgatccgaggtcaattttcagaagttgggggtttaacggcagggc60
accgccagggccttccagaacgagatataactactacgctcggggtcctagcgagctcgc120
cactagatttcagggcctgccctcgctagaaggcagtgccccatcaccaagccaggcttg180
agggttgaaatgacgctcgaacaggcatgccctccggaataccagagggcgcaatgtgcg240
ttcaaagattcgatgattcactgaattctgcaattcacattacttatcgcatttcgctgc300
gttcttcatcgatgccagaaccaagagatccgttgttgaaagttttgattcatttatgtt360
ttttactccaagattcactaaagaaacgagatgttaattggccactggcttcctgctccc420
tgtttcccggaaatctttgggccagatcgctaggacgccgagagtaaaaataatatctcg480
atctggaaggcggtgtcggggccctgccgataaacctccaacttctgaaactttgaccgc540
tgatcaagtgggaaccccggcgaactttaacttctccatatggaggaggaaa592
6
604
dna
人工序列
6
agaggaagtaaaagtcgtaacaaggtctccgttggtgaaccagcggagggatcattgctg60
gaacgcgcttcggcgcacccagaaaccctttgtgaacttatacctattgttgcctcggcg120
caggccggcctcttcactgaggccccctggaaacagggagcagcccgccggcggccaacc180
aaactcttgtttctatagtgaatctctgagtaaaaaaacataaatgaatcaaaactttca240
acaacggatctcttggttctggcatcgatgaagaacgcagcgaaatgcgataagtaatgt300
gaattgcagaattcagtgaatcatcgaatctttgaacgcacattgcgccctctggtattc360
cggagggcatgcctgttcgagcgtcatttcaaccctcaagcctggcttggtgatggggca420
ctgcctgtaatagggcaggccctgaaatctagtggcgagctcgccaggaccccgagcgta480
gtagttatatctcgctctggaaggccctggcggtgccctgccgttaaacccccaacttct540
gaaaatttgacctcggatcaggtaggaatacccgctgaacttaagcatatcaataagcgg600
agga604
7
591
dna
人工序列
7
tgaccggcatgctacctaatccgaggtcaccattaaaatagggggtgttttatggctagc60
aactataaccactacaagaagcgagagagagttactacgcttagagtgtgctataactcc120
gccactaactttaaggaactacgctataataggtcgtagagtcccaacgctaaacaaccg180
aggcttaagggttgaaatgacgctcgaataggcatgcccactagaatactaatgggcgca240
atgtgcgttcaaagattcgatgattcactgaattctgcaattcacattacttatcgcatt300
tcgctgcgttcttcatcgatgccagaaccaagagatccgttgttgaaagttttaacttat360
ttagttataaagttcagagatacagtataaaacagagttggtaggtcctctggcgagctt420
ggaatgtgttcccgggtagctacagggtagctatagggtagcataactcgccgaggcaac480
agtggtaagttcacaaagggttgggagttttggataactcagtaatgatccctccgctgg540
ttcaccaacggagaccttgttacgacttttacttcctctaaatgaccaaga591
8
531
dna
人工序列
8
agtcagcgacccgtagtgaccggtttcaccgggatgttctaaccctttgttgtccgactc60
tgttgcctccggggcgaccctgccttcgggcgggggctccgggtggacacttcaaactct120
tgcgtaactttgcagtctgagtaaacttaattaataaattaaaacttttaacaacggatc180
tcttggttctggcatcgatgaagaacgcagcgaaatgcgataagtaatgtgaattgcaga240
attcagtgaatcatcgaatctttgaacgcacattgcgccccctggtattccggggggcat300
gcctgttcgagcgtcatttcaccactcaagcctcgcttggtattgggcaacgcggtccgc360
cgcgtgcctcaaatcgaccggctgggtcttctgtcccctaagcgttgtggaaactattcg420
ctaaagggtgctcgggaggctacgccgtaaaacaaccccatttctaaggttgacctcgga480
tcaggtagggatacccgctgaacttaagcatatcataaggggggaagaact531
9
561
dna
人工序列
9
aaccgggctcctacctgatccgaggtcaccttagaaatggggttgttttacggcgtagcc60
tcccgagcaccctttagcgaatagtttccacaacgcttaggggacagaagacccagccgg120
tcgatttgaggcacgcggcggaccgcgttgcccaataccaagcgaggcttgagtggtgaa180
atgacgctcgaacaggcatgccccccggaataccagggggcgcaatgtgcgttcaaagat240
tcgatgattcactgaattctgcaattcacattacttatcgcatttcgctgcgttcttcat300
cgatgccagaaccaagagatccgttgttaaaagttttaatttattaattaagtttactca360
gactgcaaagttacgcaagagtttgaagtgtccacccggagcccccgcccgaaggcaggg420
tcgccccggaggcaacagagtcggacaacaaagggttatgaacatcccggtggtaaaccg480
gggtcacttgtaatgatccctccgcaggttcacctacggagaccttgttacgacttttac540
ttcctctaatttgacccaaga561
10
550
dna
人工序列
10
gcggggatttctactgatccgaggtcacattcagaagttgggggtttaacggcttggccg60
cgccgcgtaccagttgcgagggttttactactacgcaatggaagctgcagcgagaccgcc120
actagatttcggggccggcttgccgcaagggctcgccgatccccaacaccaaacccgagg180
gcttgagggttgaaatgacgctcgaacaggcatgcccgccagaatactggcgggcgcaat240
gtgcgttcaaagattcgatgattcactgaattctgcaattcacattacttatcgaatttt300
gctgcgttcttcatcaatgccagaaccaaaagatccgttgttgaaaggtttaatttattt360
atggttttactcagaagatacatatagaaaccgagtgaagggggcctctggctgcttatt420
ccgttccccgggagcgggatgctttcccaagcccttttttgccactttccctcgcaccct480
gccttggggggtctgcacagggagcatacagtgggctttggagtcggatggattgttcga540
ttttaacttt550
11
635
dna
人工序列
11
agtgggcttctacctgatccgaggtcaccttggaaaatagaccgaaggtcgattgtccgg60
cggccgtcgcccagcactccaaagcgagatattttactactacgctcgaggctaggacgc120
cgtcgccgaggtcttcaaggcacgtccggcagcggacgttgcccaataccaagcagagct180
tgagggttgaaatgacgctcgaacaggcatgccctccggaataccagagggcgcaatgtg240
cgttcaaagattcgatgattcactgaattctgcaattcacattacttatcgcatttcgct300
gcgttcttcatcgatgccagaaccaagagatccgttgttgaaagttttaatcaattaaat360
gatatatcaggacttcacaaaatgaattcttgagttttgtatactggcgggcacttagcc420
aggcgtcctggccagttaaggctgggggcgccggccgcctgggtcggaaccaggtcgacc480
cgccaaagcaacatagtgagtacacaagggtgagaaggtcatttcggcgttgtagcgcct540
actctggaacctttcaatagaagttattacatttcagtaatgatccttccgcaggttcac600
ctacggaaaccttgttacgacttttacttcctcaa635
12
568
dna
人工序列
12
gcccgggctttctacctgatccgaggtcacattcagaagttgggggtttaacggcttggc60
cgcgccgcgtaccagttgcgagggttttactactacgcaatggaagctgcagcgagaccg120
ccactagatttcggggccggcttgccgcaagggctcgccgatccccaacaccaaacccga180
gggcttgagggttgaaatgacgctcgaacaggcatgcccgccagaatactggcgggcgca240
atgtgcgttcaaagattcgatgattcactgaattctgcaattcacattacttatcgcatt300
ttgctgcgttcttcatcgatgccagaaccaagagatccgttgttgaaagttttgatttat360
ttatggttttactcagaagttacatatagaaacagagtttaggggtcctctggcgggccg420
tcccgttttaccgggagcgggctgatccgccgaggcaacaattggtatgttcacaggggt480
ttgggagttgtaaactcggtaatgatccctccgctggttcaccaacggagaccttgttac540
gacttttacttcctctaaatgaccaaga568
13
575
dna
人工序列
13
cggctacgagtcggggtctttgggccaacctcccatccgtgtctattataccctgttgct60
tcggcgggcccgccgcttgtcggccgccgggggggcgcctttgccccccgggcccgtgcc120
cgccggagaccccaacacgaacactgtctgaaagcgtgcagtctgagttgattgaatgca180
atcagttaaaactttcaacaatggatctcttggttccggcatcgatgaagaacgcagcga240
aatgcgataactaatgtgaattgcagaattcagtgaatcatcgagtctttgaacgcacat300
tgcgccccctggtattccggggggcatgcctgtccgagcgtcattgctgccctcaagccc360
ggcttgtgtgttgggtcgccgtccccctctccggggggacgggcccgaaaggcagcggcg420
gcaccgcgtccgatcctcgagcgtatggggctttgtcacatgctctgtaagattggccgg480
cgcctgccgacgttttccaaccattttttccaggttgacctcggatcaggtagggatacc540
cgctgaacttaagcatatcaataagcggaggaatc575
14
590
dna
人工序列
14
ggaagtaaaagtcgtaacaaggtttccgtaggtgaacctgcggaaggatcattaccgagt60
gctgggtccttcggggcccaacctcccacccgtgcttaccgtaccctgttgcttcggcgg120
gcccgccttcgggcggcccggggcctgcccccgggaccgcgcccgccggagaccccaatg180
gaacactgtctgaaagcgtgcagtctgagtcgattgataccaatcagtcaaaactttcaa240
caatggatctcttggttccggcatcgatgaagaacgcagcgaaatgcgataactaatgtg300
aattgcagaattcagtgaatcatcgagtctttgaacgcacattgcgccccctggtattcc360
ggggggcatgcctgtccgagcgtcatttctcccctccagccccgctggttgttgggccgc420
gcccccccgggggcgggcctcgagagaaacggcggcaccgtccggtcctcgagcgtatgg480
ggctctgtcacccgctctatgggcccggccggggcttgcctcgacccccaatcttctcag540
attgacctcggatcaggtagggatacccgctgaacttaagcatatcaata590
15
618
dna
人工序列
15
tagaggaagtaaaagtcgtaacaaggtttccgtaggtgaacctgcggaaggatcattacc60
gagtgcgggtcctttgggcccaacctcccatccgtgtctattataccctgttgcttcggc120
gggcccgccgcttgtcggccgccgggggggcgcctttgccccccgggcccgtgcccgccg180
gagaccccaacacgaacactgtctgaaagcgtgcagtctgagttgattgaatgcaatcag240
ttaaaactttcaacaatggatctcttggttccggcatcgatgaagaacgcagcgaaatgc300
gataactaatgtgaattgcagaattcagtgaatcatcgagtctttgaacgcacattgcgc360
cccctggtattccggggggcatgcctgtccgagcgtcattgctgccctcaagcccggctt420
gtgtgttgggtcgccgtccccctctccggggggacgggcccgaaaggcagcggcggcacc480
gcgtccgatcctcgagcgtatggggctttgtcacatgctctgtaggattggccggcgcct540
gccgacgttttccaaccattttttccaggttgacctcggatcaggtagggatacccgctg600
aacttaagcatatcaata618
16
626
dna
人工序列
16
gaggaagtaaaagtcgtaacaaggtttccgtaggtgaacctgcggaaggatcattaccga60
gtgcgggtcctttgggcccaacctcccatccgtgtctattgtaccctgttgcttcggcgg120
gcccgccgcttgtcggccgccgggggggcgcctctgccccccgggcccgtgcccgccgga180
gaccccaacacgaacactgtctgaaagcgtgcagtctgagttgattgaatgcaatcagtt240
aaaactttcaacaatggatctcttggttccggcatcgatgaagaacgcagcgaaatgcga300
taactaatgtgaattgcagaattcagtgaatcatcgagtctttgaacgcacattgcgccc360
cctggtattccggggggcatgcctgtccgagcgtcattgctgccctcaagcccggcttgt420
gtgttgggtcgccgtccccctctccggggggacgggcccgaaaggcagcggcggcaccgc480
gtccgatcctcgagcgtatggggctttgtcacatgctctgtaggattggccggcgcctgc540
cgacgttttccaaccattctttccaggttgacctcggatcaggtagggatacccgctgaa600
cttaagcatatcaataaggcggagga626
17
624
dna
人工序列
17
ggaagtaaaagtcgtaacaaggtttccgtaggtgaacctgcggaaggatcattaccgagt60
gcgggtcctttgggcccaacctcccatccgtgtctattataccctgttgcttcggcgggc120
ccgccgcttgtcggccgccgggggggcgcctttgccccccgggcccgtgcccgccggaga180
ccccaacacgaacactgtctgaaagcgtgcagtctgagttgattgaatgcaatcagttaa240
aactttcaacaatggatctcttggttccggcatcgatgaagaacgcagcgaaatgcgata300
actaatgtgaattgcagaattcagtgaatcatcgagtctttgaacgcacattgcgccccc360
tggtattccggggggcatgcctgtccgagcgtcattgctgccctcaagcccggcttgtgt420
gttgggtcgccgtccccctctccggggggacgggcccgaaaggcagcggcggcaccgcgt480
ccgatcctcgagcgtatggggctttgtcacatgctctgtaggattggccggcgcctgccg540
acgttttccaaccattttttccaggttgacctcggatcaggtagggatacccgctgaact600
taagcatatcaataaggcggagga624
18
584
dna
人工序列
18
aatgggcagctacctgatccgaggtcatctgagaagattgggggtcgaggcaagccccgg60
ccgggcccatagagcgggtgacagagccccatacgctcgaggaccggacggtgccgccgt120
ttctctcgaggcccgcccccgggggggcgcggcccaacaaccagcggggctggaggggag180
aaatgacgctcggacaggcatgccccccggaataccagggggcgcaatgtgcgttcaaag240
actcgatgattcactgaattctgcaattcacattagttatcgcatttcgctgcgttcttc300
atcgatgccggaaccaagagatccattgttgaaagttttgactgattggtatcaatcgac360
tcagactgcacgctttcagacagtgttccattggggtctccggcgggcgcggtcccgggg420
gcaggccccgggccgcccgaaggcgggcccgccgaagcaacagggtacggtaagcacggg480
tgggaggttgggccccgaaggacccagcactcggtaatgatccttccgcaggttcaccta540
cggaaaccttgttacgacttttacttcctctaaaatgaccaaga584
19
557
dna
人工序列
19
gggatttcttgtgctgtacgatctggtcttcggggccacctcccacccgtgcttaccgta60
ccctgttgcttcggcgggcccgccttcgggcggcccggggcctgcccccgggaccgcgcc120
cgccggagaccccaatggaacactgtctgaaagcgtgcagtctgagtcgattgataccaa180
tcagtcaaaactttcaacaatggatctcttggttccggcatcgatgaagaacgcagcgaa240
atgcgataactaatgtgaattgcagaattcagtgaatcatcgagtctttgaacgcacatt300
gcgccccctggtattccggggggcatgcctgtccgagcgtcatttctcccctccagcccc360
gctggttgttgggccgcgcccccccgggggcgggcctcgagagaaacggcggcaccgtcc420
ggtcctcgagcgtatggggctctgtcacccgctctatgggcccggccggggcttgcctcg480
acccccaatcttctcagattgacctcggatcaggtagggatacccgctgaacttaagcat540
atcaataagcggaggaa557
20
573
dna
人工序列
20
gggggtacgattgcggtctttgggccacctcccatccgtgtctattataccctgttgctt60
cggcgggcccgccgcttgtcggccgccgggggggcgcctttgccccccgggcccgtgccc120
gccggagaccccaacacgaacactgtctgaaagcgtgcagtctgagttgattgaatgcaa180
tcagttaaaactttcaacaatggatctcttggttccggcatcgatgaagaacgcagcgaa240
atgcgataactaatgtgaattgcagaattcagtgaatcatcgagtctttgaacgcacatt300
gcgccccctggtattccggggggcatgcctgtccgagcgtcattgctgccctcaagcccg360
gcttgtgtgttgggtcgccgtccccctctccggggggacgggcccgaaaggcagcggcgg420
caccgcgtccgatcctcgagcgtatggggctttgtcacatgctctgtaggattggccggc480
gcctgccgacgttttccaaccattttttccaggttgacctcggatcaggtagggataccc540
gctgaacttaagcatatcaataagccggaggaa573
21
549
dna
人工序列
21
ctgcggcgagtgctggtcttcggggccaacctcccacccgtgcttaccgtaccctgttgc60
ttcggcgggcccgccttcgggcggcccggggcctgcccccgggaccgcgcccgccggaga120
ccccaatggaacactgtctgaaagcgtgcagtctgagtcgattgataccaatcagtcaaa180
actttcaacaatggatctcttggttccggcatcgatgaagaacgcagcgaaatgcgataa240
ctaatgtgaattgcagaattcagtgaatcatcgagtctttgaacgcacattgcgccccct300
ggtattccggggggcatgcctgtccgagcgtcatttctcccctccagccccgctggttgt360
tgggccgcgcccccccgggggcgggcctcgagagaaacggcggcaccgtccggtcctcga420
gcgtatggggctctgtcacccgctctatgggcccggccggggcttgcctcgacccccaat480
cttctcagattgacctcggatcaggtagggatacccgctgaacttaagcatatcaataag540
cgggaggaa549
22
582
dna
人工序列
22
gcgaatgcgagtgcggttgatcggtctttgggcccacctcccatccgtgtctattatacc60
ctgttgcttcggcgggcccgccgcttgtcggccgccgggggggcgcctttgccccccggg120
cccgtgcccgccggagaccccaacacgaacactgtctgaaagcgtgcagtctgagttgat180
tgaatgcaatcagttaaaactttcaacaatggatctcttggttccggcatcgatgaagaa240
cgcagcgaaatgcgataactaatgtgaattgcagaattcagtgaatcatcgagtctttga300
acgcacattgcgccccctggtattccggggggcatgcctgtccgagcgtcattgctgccc360
tcaagcccggcttgtgtgttgggtcgccgtccccctctccggggggacgggcccgaaagg420
cagcggcggcaccgcgtccgatcctcgagcgtatggggctttgtcacatgctctgtagga480
ttggccggcgcctgccgacgttttccaaccattttttccaggttgacctcggatcaggta540
gggatacccgctgaacttaagcatatcataagccggaagaaa582
23
588
dna
人工序列
23
cggggatctacctgatccgaggtcacctagaaaaataaaggtttcagtcggcagaagtcc60
tctcctttgacagacgttcgaataaattctactacgcctaaagccggtgaggcctcgccg120
aggtctttaaggcgcgcccaactaaggacggcacccaataccaagcatagcttgagtggt180
gtaatgacgctcgaacaggcatgcccctcggaataccaaggggcgcaatgtgcgttcaaa240
gattcgatgattcactgaattctgcaattcacattacttatcgcatttcgctgcgttctt300
catcgatgcgagaaccaagagatccgttgttgaaagttttgatttattcaaaattttaac360
tcagacgaccggtttaataacaagagtttggtttaactctggcgggcgctcgcctgggac420
gaatccccagcggctcgagaccgagcggtcccgccaaagcaacaaggtagttttaacaac480
aaagggttggaggtcgggcgctgagcacccttactctttaatgatccttccgcaggttca540
cctacggaaaccttgttacgacttttacttcctcaatttgacccaaga588
24
567
dna
人工序列
24
tcttggtcatttagaggaagtaaaagtcgtaacaaggtttccgtaggtgaacctgcggaa60
ggatcattattgattggtcgaaagaccttatcagattctaccacctctgtgaaccgttga120
cctccgggttaataatcaaacatcagtgtaacgaacgtaagagtatcttaacgaaacaaa180
actttcaacaacggatctcttggctctcgcatcgatgaagaacgcagcgaaatgcgataa240
gtaatgtgaattgcagaattcagtgaatcatcgaatctttgaacgcaccttgcgcctttt300
ggtattccgaaaggcatgcctgtttcagtgtcatgaaatctcaatctaatatgttttctg360
aacatgttaggcttggacttgggcgtctgccagtgatggctcgcctcaaatgacttagtg420
gaacatcccacatcagtgttagacgtaataagtttcgtctctccttgtggtgatgactgc480
tcagaacctgccatcgcgcatcttttgactttgacctgaaatcaggtagggctacccgct540
gaacttaagcatatcaataagcggagg567
25
627
dna
人工序列
25
ccggacctcctggatttgaggtcaaatcttaaatgtggacttctgattagaaacttcctt60
taacctaacccggatctagtccgaagactagaattcctcaacgaatagactattacgcca120
agtcaatcctaaagttcgattgcggatgctaatgcattacgaacgagctagaacgtaaag180
gccagcagcgctcacaatccaaacacctcttcgatcactaagaaagaggagggttgaagt240
attcctgacactcacacaggcatgctccacggaataccatggagcgcaaggtgcgttcaa300
agattcgatgattcactgaattctgcaattcacattacttatcgcatttcgctgcgttct360
tcatcgatgcgagagccaagagatccgttgttgaaagttttgttttgttataaaattaaa420
tacattcatagactttgtgtttataagtgaataggaattcgctcttgcgagctactatcc480
caaacaaatgcacaggggtagaaagtgagagttcggactccaagttaaattggacgccct540
atgttctctaatgatgcttatgaaggttgagctacccataccatgttacgactattactt600
gctctcattgatcaagaggaggatggt627
26
632
dna
人工序列
26
cacggtgtccttcctggattttaagatctaatcttaaatgtagacattctgattagaagc60
ttcctttaacctaacccggctctaatccgaagactagaattcctcagcgaatagtctatt120
acgccaagtcaatccgaaagttcgattgcggatgctaatgcattacgaacgagctagacc180
gtaaaggccagcagcgctcagaatccaaacacctcttcgatcactaagaaagaggagggt240
tgaagtattcatgacactcaaacaggcatgctccacggaataccatggagcgcaaggtgc300
gttcaaagattcgatgattcactgaattctgcaattcacattacttatcgcatttcgctg360
cgttcttcatcgatgcgagagccaagagatccgttgttgaaagttttgttttgttataaa420
attaaatacattcatagactttgtgtttataagtgaataggaattcgctcttgcgagcta480
ctatcccaaacaaatgcacagggttagaaagtgagagttcggactccaagttaaattgga540
cgtcctatgttcactaatgatccttccgcaggttcacctacggagaccttgttacgactt600
ttacttcctcctaatgacgagggggagggaaa632
27
632
dna
人工序列
27
tactggctcccctacctgatcctgaggtctactcttaaatgtggacgatgactagattgg60
aagcttcctttagtccgacccggctctagtaatagtactagcaattcctcaaccgaatag120
actattagccctgattttccgaaagttcgattgcggatgctaatgcattacgaacgagct180
aatagaggaacggccgacagcgctcaaaatccgcacacctcttcactcaagggaaagagg240
agggttgaagattcatgacactctgaaggcatgctccacggaataccatggatttcaagg300
tgcgttcaaagattcgatgattcactgaattctgctgttcacattacttatcgcatttcg360
ctgcgttcttcatcaatgcgagagccaagagatccgttgttgaaagttttattttgttat420
aaaattaaatacattcatagactttgtgtttataagtgaataggagttcgacgactaggt480
cgactactatcccaaacgagtgcacagggttagaaagtgagagttcggactccaagttaa540
gttggacgtcctatgttcactaatgatccttccgcaggttcacctacggaaaccttgtta600
cgacttttacttcctctaaatgaccaagaggg632
28
621
dna
人工序列
28
gatgggttctactgatttgaggtctaatcgtaaatgtggacttctgattagaacttcctt60
tacctaacccggctctagtccgaagactagaattcctcaacgaatagactattacgccca120
gtcaatccgaaagttcgattgcggatgctaatgcattacgaacgagctagaacgtatagg180
cggacggcgctctcaaaccccacacctctctgctccctagaataaagagggggggaaaga240
ttcttgacacactcaaagatgcgcgcacctcggaacctcgtgtagcgcggggcgcgttca300
tacattctgatactctgtgatctccgctacacattttgtttatcgtttttctgtgttctc360
ttcctccacgccagaccgcagatatcctgttgagagttttgttttgtgatataattatat420
atattctcagactttgtgtgtatatatgtgaaggaaatctctcttgcgagctacactact480
atcccaatgcactgggttaggttataaggtgacagactccactccaaattggacggcaca540
tgttatgtactgatccttcccttcgttcagctacggaaaccttgttacgacttttacttc600
ctctcatcgaactgaccaaga621