視線校正方法、裝置、智能會議終端及存儲介質與流程
2023-05-23 00:56:46 4
本發明涉及圖像處理技術領域,尤其視線校正方法、裝置、智能會議終端及存儲介質。
背景技術:
隨著科技的發展,視頻會議也得到更廣泛的應用,調查顯示,視頻會議過程中如果視頻雙方能夠進行眼神交互,則更能給視頻參與者帶來良好的視頻會議體驗。一般而言,視頻會議時,只有雙方視頻者盯著攝像頭看時,另一方的視頻者才覺得畫面中的對方與自己存在眼神交互。然而,在視頻會議場景中,如果雙方視頻者均往視頻畫面看,則視頻畫面中顯示出的對方實則看向別處,此時雙方無法進行眼神交流,影響了用戶視頻會議的視覺體驗。
目前,技術人員提出了一些視線校正方案來保證視頻會議中視頻雙方的眼神交流,常見的視線校正方案有:對視頻設備中顯示設備的改進,如採用半透明鏡子或半透明顯示屏實現視線校正,或者採用特殊的攝像頭(如rgb-d攝像頭)結合相應的算法實現視線校正,上述方案儘管具有較好的視線校正性能,但卻需要依賴特殊硬體或特殊攝像頭,其均具有較高的成本消耗且可應用的範圍也存在限制。此外,技術人員也提出了一些採用普通單目攝像頭結合相應算法進行視線校正的方案,但該種方案大多數無法保證在實時性的前提下合成高質量的圖像,且該種方案主要依賴普通的單目攝像頭進行視線校正,相對上述方案,該方案的視線校正精確性不佳。
技術實現要素:
本發明實施例提供了視線校正方法、裝置、智能會議終端及存儲介質,能夠對視頻會議中的視頻者進行高精度的視線校正,解決了視線校正成本消耗過高,適用範圍過窄的問題。
一方面,本發明實施例提供了一種視線校正方法,包括:
獲取雙攝像頭同步捕獲的兩張當前畫面幀,確定所述兩張當前畫面幀中各重合被攝點的深度信息,並合併形成一幅當前實景畫面幀;
檢測所述當前實景畫面幀中構成人臉圖像的二維關鍵點,並確定所述二維關鍵點的坐標信息;
根據所述二維關鍵點對應的深度信息及所述坐標信息,在三維空間中校正所述人臉圖像獲得二維的人臉正視圖像。
另一方面,本發明實施例提供了一種視線校正裝置,包括:
深度信息確定模塊,用於獲取雙攝像頭同步捕獲的兩張當前畫面幀,確定所述兩張當前畫面幀中各重合被攝點的深度信息;
圖像拼接合成模塊,用於將所述兩張當前畫面幀合併形成一幅當前實景畫面幀;
關鍵點信息確定模塊,用於檢測所述當前實景畫面幀中構成人臉圖像的二維關鍵點,並確定所述二維關鍵點的坐標信息;
人物視線校正模塊,用於根據所述二維關鍵點對應的深度信息及所述坐標信息,在三維空間中校正所述人臉圖像獲得二維的人臉正視圖像。
又一方面,本發明實施例提供了一種智能會議終端,包括:
光軸平行的兩個攝像頭;
一個或多個處理器;
存儲裝置,用於存儲一個或多個程序;
所述一個或多個程序被所述一個或多個處理器執行,使得所述一個或多個處理器實現本發明實施例提供的視線校正方法。
再一方面,本發明實施例提供了一種計算機可讀存儲介質,其上存儲有電腦程式,該程序被處理器執行時實現本發明實施例提供的視線校正方法。
在上述視線校正方法、裝置、智能會議終端及存儲介質中,首先獲取雙攝像頭同步捕獲的兩張當前畫面幀,確定兩張當前畫面幀中各重合被攝點的深度信息,並合併形成一幅當前實景畫面幀;然後檢測當前實景畫面幀中構成人臉圖像的二維關鍵點並確定二維關鍵點的坐標信息;最終根據二維關鍵點對應的深度信息及坐標信息在三維空間中校正人臉圖像獲得二維的人臉正視圖像。上述視線校正方法、裝置、智能會議終端及存儲介質,與現有的視線校正方案相比,本發明的方案無需依賴特殊硬體或特殊攝像頭,僅需兩個普通的攝像頭就能高效地對所捕獲實景畫面幀中被攝人物的視線進行校正處理,其成本消耗低且適用範圍廣,同時通過雙攝像頭還能帶來更廣的捕獲視野,由此更好的增強了智能會議終端的實際使用體驗。
附圖說明
圖1為本發明實施例一提供的一種視線校正方法的流程示意圖;
圖2a為本發明實施例二提供的一種視線校正方法的流程示意圖;
圖2b~圖2c給出了基於本發明實施例二提供的視線校正方法進行視線校正的處理流程圖;
圖2d給出了一組存在一個被攝人物的待進行視線校正的第一實景畫面幀;
圖2e給出了對上述一組第一實景畫面幀進行視線校正處理後的校正效果圖;
圖2f給出了一組存在多個被攝人物的待進行視線校正的第二實景畫面幀;
圖2g給出了對上述一組第二實景畫面幀進行視線校正處理後的校正效果圖;
圖3為本發明實施例三提供的一種視線校正裝置的結構框圖;
圖4為本發明實施例四提供的一種智能會議終端的硬體結構示意圖。
具體實施方式
下面結合附圖和實施例對本發明作進一步的詳細說明。可以理解的是,此處所描述的具體實施例僅僅用於解釋本發明,而非對本發明的限定。另外還需要說明的是,為了便於描述,附圖中僅示出了與本發明相關的部分而非全部結構。
實施例一
圖1為本發明實施例一提供的一種視線校正方法的流程示意圖,該方法適用於視頻通話時對所捕獲畫面幀中的人物進行視線校正的情況,該方法可以由視線校正裝置執行,其中該裝置可由軟體和/或硬體實現,並一般集成在具有視頻通話功能的智能終端上。
在本實施例中,所述智能終端具體可以是手機、平板電腦、筆記本等智能移動終端,也可以是臺式計算機、智能會議終端等固定式的具有視頻通話功能的電子設備。本實施例優選的設定其應用場景為通過固定不動的智能終端進行視頻通話,且優選地認為進行視頻通話時視頻者雙方的實現均看向視頻畫面,此時基於本發明提供的視線校正方法,可以讓視頻者雙方自然地對視實現視頻通話時的視線交流。
如圖1所示,本發明實施例一提供的一種視線校正方法,包括如下操作:
s101、獲取雙攝像頭同步捕獲的兩張當前畫面幀,確定該兩張當前畫面幀中各重合被攝點的深度信息,並合併形成一幅當前實景畫面幀。
在本實施例中,在基於智能終端進行視頻通話時,主要通過智能終端的攝像頭捕獲視頻者當前所處場景的畫面信息,本實施例中的智能終端具有兩個光軸平行的攝像頭,即所述智能終端具有雙攝像頭。在視頻通話過程中,雙攝像頭可同步捕獲當前所在場景的當前畫面幀。
可以理解的是,由於雙攝像頭在智能終端上的安裝位置不同,同步捕獲的當前所在場景中的當前畫面幀也不完全重合,但所述兩張當前畫面幀中仍存在同時被捕獲的被攝點,本實施例將同時存在於所述兩張當前畫面幀中的被攝點稱為重合被攝點。
在本實施例中,可以根據設定的畫面幀立體匹配算法確定兩張當前畫面幀中各重合被攝點的視差值,之後,根據攝像頭具有的焦距、各重合被攝點到所在當前畫面幀中的視差值以及雙攝像頭光心連線的距離,可以確定各重合被攝點的深度信息。其中,所述深度信息具體可理解為重合被攝點到智能終端的深度值。此外,本實施例還可以對所捕獲的兩張畫面幀進行合併拼接處理,由此將兩張當前畫面幀合併形成一幅當前實景畫面幀。
s102、檢測當前實景畫面幀中構成人臉圖像的二維關鍵點,並確定二維關鍵點的坐標信息。
本步驟可以根據關鍵點檢測算法檢測當前實景畫面幀中的是否存在人臉圖像並可確定構成人臉圖像的二維關鍵點。具體地,可以根據人臉具有的特徵標識在所述當前實景畫面幀中檢測構成人臉圖像的二維關鍵點,同時可以確定各二維關鍵點在當前實景畫面幀中的具體坐標信息。一般地,可將人臉中的雙眼、鼻子以及兩嘴角作為人臉的最基本特徵標識,由此可以在當前畫面幀中檢測出構成人臉圖像的五個二維關鍵點。示例性的,所述二維關鍵點的個數不限於五個,還可以是8個、10個甚至63個,可以理解的是,所檢測的二維關鍵點個數越多,其在當前實景畫面幀中確定的人臉圖像的所在區域就越準確。本實施例為保證人臉圖像所在區域的準確性,優選的進行63個二維關鍵點的檢測,由此可在所述當前實景畫面幀中確定出63個二維關鍵點的坐標信息。
s103、根據二維關鍵點對應的深度信息及所述坐標信息,在三維空間中校正人臉圖像獲得二維的人臉正視圖像。
需要說明的是,本實施例認為智能終端上的雙攝像頭均可清晰的捕獲當前所處場景中的視頻者信息,即,可認為構成視頻者圖像(可以是人臉圖像)的被攝點屬於所述重合被攝點,因此,可從所獲取的各重合被攝點的深度信息中獲取構成人臉圖像的各二維關鍵點的深度信息。
本步驟可以根據所確定的各二維關鍵點的深度信息以及坐標信息,對人臉圖像的視線進行校正。需要說明的是,對人臉圖像的視線校正具體可相當於對人臉圖像的姿態進行校正,示例性的,當將人臉圖像由仰視、俯視以及側視等姿態校正為正視時,就相應的實現了人物視線的校正。
一般地,可以基於所確定二維關鍵點的坐標信息對當前的人臉圖像進行實際三角剖分,同樣可以根據預設的正視姿態下標準人臉圖像的關鍵點坐標信息進行標準三角剖分,之後可以根據各二維關鍵點與標準人臉圖像中各關鍵點的對應關係,建立各實際三角剖分與各標準三角剖分之間的紋理映射,最終根據其紋理映射將當前的人臉圖像校正為正視姿態下的標準人臉圖像。
上述操作可以實現人臉圖像的姿態校正,但其校正效果的精準度較低,本步驟可通過各二維關鍵點的深度信息及坐標信息在三維空間中形成三維的實際人臉圖像模型,之後可以根據幾何變換矩陣將三維的實際人臉圖像模型校正為正臉姿態的人臉圖像模型,最終對正臉姿態的人臉圖像模型進行投影映射形成二維的正臉姿態的人臉圖像模型,由此可將該正臉姿態的人臉圖像模型作為本實施例校正後的人臉正視圖像。
本發明實施例一提供的一種視線校正方法,與現有的視線校正方案相比,該視線校正方法無需依賴特殊硬體或特殊攝像頭,僅需兩個普通的攝像頭就能高效地對所捕獲實景畫面幀中被攝人物的視線進行校正處理,其成本消耗低且適用範圍廣,同時通過雙攝像頭還能帶來更廣的捕獲視野,由此更好的增強了智能會議終端的實際使用體驗。
實施例二
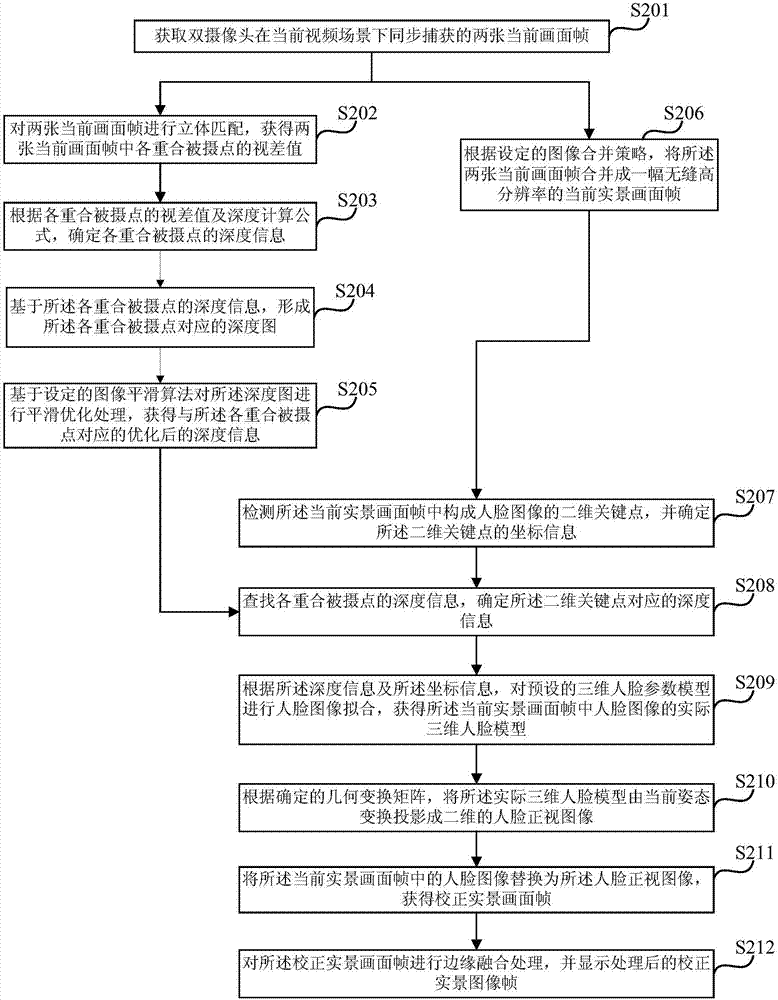
圖2a為本發明實施例二提供的一種視線校正方法的流程示意圖。本發明實施例二以上述實施例為基礎進行優化,在本實施例中,可以將獲取雙攝像頭同步捕獲的兩張當前畫面幀,確定所述兩張當前畫面幀中各重合被攝點的深度信息,並合併形成一幅當前實景畫面幀,進一步具體優化為:獲取雙攝像頭在當前視頻場景下同步捕獲的兩張當前畫面幀;對所述兩張當前畫面幀進行立體匹配,獲得所述兩張當前畫面幀中各重合被攝點的視差值;根據各重合被攝點的視差值及深度計算公式,確定各重合被攝點的深度信息;根據設定的圖像合併策略,將所述兩張當前畫面幀合併成一幅無縫高解析度的當前實景畫面幀。
進一步地,該視線校正方法所述確定所述兩張當前畫面幀中各重合被攝點的深度信息之後,還優化包括:基於所述各重合被攝點的深度信息,形成所述各重合被攝點對應的深度圖;基於設定的圖像平滑算法對所述深度圖進行平滑優化處理,獲得與所述各重合被攝點對應的優化後的深度信息。
在上述實施例的基礎上,該方法在根據所述二維關鍵點對應的深度信息及所述坐標信息,在三維空間中校正所述人臉圖像獲得二維的人臉正視圖像之後,還優化包括:將所述當前實景畫面幀中的人臉圖像替換為所述人臉正視圖像,獲得校正實景畫面幀;對所述校正實景畫面幀進行邊緣融合處理,並顯示處理後的校正實景圖像幀。
此外,本實施例還進一步將根據所述二維關鍵點對應的深度信息及所述坐標信息,在三維空間中校正所述人臉圖像獲得二維的人臉正視圖像,具體優化為:查找各重合被攝點的深度信息,確定所述二維關鍵點對應的深度信息;根據所述深度信息及所述坐標信息,對預設的三維人臉參數模型進行人臉圖像擬合,獲得所述當前實景畫面幀中人臉圖像的實際三維人臉模型;根據確定的幾何變換矩陣,將所述實際三維人臉模型由當前姿態變換投影成二維的人臉正視圖像。
如圖2a所示,本發明實施例二提供的一種視線校正方法,具體包括如下操作:
在本實施例中,s201~s204具體描述了重合被攝點深度信息的獲取過程。
s201、獲取雙攝像頭在當前視頻場景下同步捕獲的兩張當前畫面幀。
示例性的,在視頻通話時,可通過設置於智能終端上的光軸平行的雙攝像頭在當前視頻場景下同步進行畫面捕獲,相當於在兩個不同視角下獲得同一場景的兩張當前畫面幀。
s202、對兩張當前畫面幀進行立體匹配,獲得兩張當前畫面幀中各重合被攝點的視差值。
在本實施例中,所述對兩張當前畫面幀的立體匹配,具體可理解為從不同視角所捕獲的兩張或多張圖像中找點匹配的對應點,其中,所述對應點可理解為本實施例中的重合被攝點,本實施例對兩張當前畫面幀進行立體匹配後,可以確定各重合被攝點的視差值。
具體地,本實施例可以通過基於區域(窗口)的雙目匹配算法實現對應點的匹配,示例性的,將兩張當前畫面幀劃分為特定個數的區域,然後在每個區域中確定是否存在相匹配的對應點;本實施例還可以通過基於特徵的雙目匹配算法實現對應點的匹配,示例性的,在兩張當前畫面幀中劃分出包含真實世界中物體具有明顯特徵的各個區間,然後在各個區間中確定是否存在相匹配的對應點。
需要說明的是,實現上述立體匹配的方法有多種,每種方法都存在自身的優缺點,如基於區域(窗口)的雙目匹配算法,能夠很容易地恢復出高紋理區域的視差,但在低紋理區域會造成大量的誤匹配,從而導致邊界模糊,同時對遮擋的區域也很難進行處理;又如,基於特徵的雙目匹配方法提取的特徵點由於對噪聲不是太敏感,所以能得到一個比較精準的匹配,但由於圖像中的特徵點很稀疏,此種方法只能獲得一個稀疏的視差圖。本實施例並未對待使用的雙目匹配算法作進行具體限定,上述雙目匹配算法均可使用,且可根據具體應用場景進行具體選擇選擇。
s203、根據各重合被攝點的視差值及深度計算公式,確定各重合被攝點的深度信息。
在本實施例中,深度計算公式表示為:其中,z表示重合被攝點到智能終端的深度值,b表示雙攝像頭光心的連線距離,f表示雙攝像頭具有的焦距,d表示重合被攝點的視差值。基於上述公式以及確定的視差值,可以確定各重合被攝點的深度信息。
s204、基於所述各重合被攝點的深度信息,形成所述各重合被攝點對應的深度圖。
本步驟基於上述確定的各重合被攝點的深度信息以及各重合被攝點在當前實景畫面幀中的像素坐標信息,可以形成各重合被攝點對應的深度圖。
s205、基於設定的圖像平滑算法對所述深度圖進行平滑優化處理,獲得與所述各重合被攝點對應的優化後的深度信息。
在本實施例中,由於上述立體匹配算法的局限性,其確定出的深度信息具有的可靠性較低,而根據上述深度信息形成的深度圖中存在較多的空洞,由此需要對深度圖進行優化處理,以填補深度圖中的空洞,本實施例可以採用圖像平滑算法進行平滑優化處理,示例性的,所述圖像平滑算法可以是拉普拉斯平滑算法以及二維自適應濾波平滑算法等。此外,所獲得各重合被攝點對應的深度信息可以用於後續s208的操作。
需要說明的是,為加快本實施例中對深度信息的優化處理速度,可以僅考慮對當前實景畫面幀中包含人臉圖像的深度信息進行優化處理,但本步驟無需確定人臉圖像的具體區域,由於人臉圖像一般處於當前實景畫面幀中的前景區域,因此本實施例可以考慮僅對當前實景畫面幀中的前景區域進行處理。具體地,本實施例可以通過確定周圍平均深度值的方法判斷所述當前實景畫面幀中的前景區域。
s206、根據設定的圖像合併策略,將所述兩張當前畫面幀合併成一幅無縫高解析度的當前實景畫面幀。
本步驟具體實現兩張當前畫面幀的拼接處理,基於本步驟可以將兩張不同視角下拍攝的有重疊部分的圖像拼接成一幅視野範圍更廣的無縫高解析度圖像。示例性地,本步驟中的圖像合併策略可以是基於區域相關的拼接算法,也可以是基於特徵相關的拼接算法。
具體的,所述基於區域相關的拼接算法的一種實現方式可表述為:首先將兩張當前畫面幀中的一張圖像作為待配準圖像,另一張作為參考圖像,然後對待配準圖像中一塊區域與參考圖像中的相同尺寸的區域使用最小二乘法或者其它數學方法計算其灰度值的差異,進行差異比較後來判斷兩張待拼接圖像中重疊區域的相似程度,由此得到兩張當前畫面幀中重疊區域的範圍和位置,從而實現兩張當前畫面幀的圖像拼接。另一種實現方式可以通過fft變換將兩張當前畫面幀的圖像由時域變換到頻域,然後建立兩張當前畫面幀之間的映射關係,當以兩張當前畫面幀中各塊區域像素點灰度值的差別作為判別標準時,計算對應兩塊區域的像素點灰度值的相關係數,相關係數越大,則對應兩塊區域中圖像的匹配程度越高,由此將圖像匹配程度高的區域作為重疊區域,也可實現兩張當前畫面幀的拼接。
此外,基於特徵相關的拼接算法的實現方式可表述為:首先基於特徵進行重疊圖像的匹配,該匹配過程不是直接利用每個當前畫面幀中圖像的像素值,而是通過像素導出每個當前畫面幀中圖像的特徵,然後以圖像特徵為標準,通過搜索匹配確定圖像重疊部分的對應特徵區域,由此實現兩張當前畫面幀的拼接,其中,該類拼接算法有比較高的健壯性和魯棒性。
需要說明的是,基於特徵進行重疊圖像的匹配具有兩個過程:特徵抽取和特徵配準。首先從兩張當前畫面幀中提取灰度變化明顯的點、線、區域等特徵形成特徵集;然後在兩張當前畫面幀對應的特徵集中利用特徵匹配算法儘可能地將存在對應關係的特徵對選擇出來。在上述過程中,一系列的圖像分割技術都被用到特徵的抽取和邊界檢測上,如canny算子、拉普拉斯高斯算子、區域生長。此外,提取出的空間特徵包括有閉合的邊界、開邊界、交叉線以及其他特徵。同時,可通過交叉相關、距離變換、動態編程、結構匹配、鏈碼相關等算法實現上述過程中的特徵配準操作。
需要注意的是,本實施例並未對待使用的圖像拼接算法作進行具體限定,上述提出的圖像拼接算法均可使用,本實施例可根據具體應用場景進行具體選擇選擇。
s207、檢測所述當前實景畫面幀中構成人臉圖像的二維關鍵點,並確定所述二維關鍵點的坐標信息。
示例性的,本實施例優選的對當前實景畫面幀中構成人臉圖像的63個二維關鍵點進行檢測,並可獲取各二維關鍵點在所述當前實景畫面幀中的坐標信息。
s208、查找各重合被攝點的深度信息,確定所述二維關鍵點對應的深度信息。
需要說明的是,本步驟所採用的深度信息可以是基於s203獲得的初始深度信息,也可以是基於s205優化後的深度信息,本實施例優選的採用優化後的深度信息進行後續的操作,由此可以更好地提高視線校正的精確性。
本步驟具體通過已確定的各重合被攝點的深度信息,本實施例可認為構成人臉圖像的各二維關鍵點屬於所述重合被攝點集合,由此可查找獲得各二維關鍵點對應的深度信息。
在本實施例中,可通過下述s209和s210實現人臉圖像的視線校正。
s209、根據所述深度信息及所述坐標信息,對預設的三維人臉參數模型進行人臉圖像擬合,獲得所述當前實景畫面幀中人臉圖像的實際三維人臉模型。
具體地,根據已確定的各二維關鍵點的深度信息和坐標信息,可以在給定的三維人臉參數模型上進行立體的人臉圖像的擬合。所述三維人臉參數模型具體可理解為具有人臉輪廓的三維模型,其可根據所輸入參數的不同,擬合出具有不同特徵信息以及不同姿態的三維人臉模型。因此,本步驟可根據所輸入的二維關鍵點的深度信息和坐標信息,擬合確定出對應於當前實景畫面幀中人臉圖像的實際三維人臉模型。
s210、根據確定的幾何變換矩陣,將所述實際三維人臉模型由當前姿態變換投影成二維的人臉正視圖像。
在本實施例中,擬合出的世紀三維人臉模型其具有的姿態可看作當前實景畫面幀中人臉圖像所具有的姿態(如仰視或者俯視等),本步驟可通過對該實際三維人臉模型的幾何變換獲得人臉圖像的正視姿態。具體地,本步驟可以首先將實際三維人臉模型與第一幾何變換矩陣相乘,在三維空間中確定一個三維人臉正視模型,之後根據第二幾何變換矩陣與三維人臉正視模型相乘,將三維人臉正視模型的紋理投影到二維平面上,獲得二維的人臉正視圖像。此外,本步驟也可以首先將第一幾何變換矩陣和第二幾何變換矩陣相乘,獲得第三幾何變換矩陣,最終將實際三維人臉模型與第三幾何變化矩陣相乘,直接獲得二維的人臉正視圖像。
需要說明的是,本實施例中的第一幾何變換矩陣由當前實景畫面幀中所包含人物相對於智能終端屏幕的位置唯一確定,而所包含人物相對於智能終端屏幕的位置可通過上述深度信息獲得,由此可根據構成人臉圖像的深度信息唯一確定第一變換矩陣的具體值。本實施例中的第二幾何變換矩陣具體用於三維到二維的降維投影,可根據三維空間下正姿態的三維人臉模型確定。
s211、將所述當前實景畫面幀中的人臉圖像替換為所述人臉正視圖像,獲得校正實景畫面幀。
基於上述步驟獲得所述人臉正視圖像後,可基於本步驟進行人臉圖像的替換獲得校正實景畫面幀,可以知道的是,所述校正實景畫面幀中人臉圖像所處的姿態為正視姿態,由此實現了視頻通話時所捕獲畫面幀中人物視線的校正。
s212、對所述校正實景畫面幀進行邊緣融合處理,並顯示處理後的校正實景圖像幀。
需要說明的是,基於上述步驟形成的校正實景畫面幀僅獲得初步的校正效果,儘管視線得以校正,但替換合成的臉部邊緣與原實景畫面幀往往存在較大的不一致性,導致存在較明顯的圖像處理痕跡,因此,可基於本步驟對上述步驟的處理痕跡通過邊緣融合的方法進行修復。
實現本步驟邊緣融合的做法有多種,示例性的,可以將所形成校正實景圖像幀中的人臉圖像的輪廓外區域作為待切割區域,由此利用圖像分割技術獲得輪廓外區域的最佳切割邊緣,之後與校正實景圖像幀進行混合,最終獲得邊緣處理後的校正實景圖像幀,本實施例最終可以將處理後的校正實景圖像幀顯示到本端以及對端的屏幕上。
在上述實施例的基礎上,本實施例還進一步通過圖示描述了視線校正的實現過程,具體地,圖2b~圖2c給出了基於本發明實施例二提供的視線校正方法進行視線校正的處理流程圖。如圖2b所示,在智能終端的兩側分別設置了光軸平行的攝像頭20,攝像頭20可通過步驟s1同步捕獲兩張當前畫面幀21;然後可通過步驟s2對兩張當前畫面幀21進行立體匹配,獲得重合被攝點的深度信息22,並可通過步驟s3獲得優化後的深度信息23,同時還可通過步驟s4對兩張當前畫面幀21進行拼接獲得當前實景畫面幀24;之後,可根據步驟s5通過已確定的深度信息23以及檢測出的二維關鍵點對當前實景畫面幀24中的人臉圖像進行視線校正操作,獲得視線校正後的校正實景畫面幀25;可以發現,校正實景畫面幀25中人臉圖像的額頭部分26存在處理痕跡,由此可通過步驟s6對校正實景畫面幀25進行邊緣融合處理,獲得處理後的校正實景畫面幀27;還可以發現,處理後的校正實景畫面幀27中人臉圖像的額頭部分28平滑顯示,較好的修復了處理痕跡;最終通過步驟s7在對端的智能終端和/或本端的智能終端上實時顯示校正後的實景畫面幀29。
進一步地,本實施例還給出了基於所提供視線校正方法進行視線校正的效果圖,圖2d給出了一組存在一個被攝人物的待進行視線校正的第一實景畫面幀;圖2e給出了對一組第一實景畫面幀視角校正處理後的校正效果圖。通過圖2d和圖2e的比對,可以看出,視線校正處理後的被攝人物顯示為正視姿態,對端視頻者可與該姿態下的被攝人物進行視線交流。
此外,圖2f給出了一組存在多個被攝人物的待進行視線校正的第二實景畫面幀;圖2g給出了對上述一組第二實景畫面幀進行視線校正處理後的校正效果圖。通過圖2f和圖2g的比對,可以看出,視線校正處理後的兩個被攝人物均顯示為正視姿態,對端視頻者可與該姿態下的任一個被攝人物進行視線交流。
本發明實施例二提供的一種視線校正方法,具體描述了深度信息的確定過程,同時具體描述了畫面幀中人物視線的校正過程,此外還增加了深度信息的優化操作以及人物視線校正後所形成校正畫面幀的處理過程。利用該方法,能夠通過雙攝像頭捕獲的雙畫面幀確定各被攝點的深度信息,由此根據深度信息及檢測的人臉關鍵點信息實現被攝人物的視線校正,與現有方法相比,該方法無需依賴特殊硬體或特殊攝像頭,僅需兩個普通的攝像頭就能高效地對所捕獲實景畫面幀中被攝人物的視線進行校正處理,其成本消耗低且適用範圍廣,同時通過雙攝像頭還能帶來更廣的捕獲視野,由此更好的增強了智能會議終端的實際使用體驗。
實施例三
圖3為本發明實施例三提供的一種視線校正裝置的結構框圖,該裝置適用於視頻通話時對所捕獲畫面幀中的人物進行視線校正的情況,該裝置可由軟體和/或硬體實現,並一般集成在具有視頻通話功能的智能終端上。如圖3所示,該裝置包括:深度信息確定模塊31、圖像拼接合成模塊32、關鍵點信息確定模塊33以及人物視線校正模塊34。
其中,深度信息確定模塊31,用於獲取雙攝像頭同步捕獲的兩張當前畫面幀,確定所述兩張當前畫面幀中各重合被攝點的深度信息;
圖像拼接合成模塊32,用於將所述兩張當前畫面幀合併形成一幅當前實景畫面幀;
關鍵點信息確定模塊33,用於檢測所述當前實景畫面幀中構成人臉圖像的二維關鍵點,並確定所述二維關鍵點的坐標信息;
人物視線校正模塊34,用於根據所述二維關鍵點對應的深度信息及所述坐標信息,在三維空間中校正所述人臉圖像獲得二維的人臉正視圖像。
在本實施中,該視線校正裝置首先深度信息確定模塊31獲取雙攝像頭同步捕獲的兩張當前畫面幀,確定所述兩張當前畫面幀中各重合被攝點的深度信息;然後通過圖像拼接合成模塊32將所述兩張當前畫面幀合併形成一幅當前實景畫面幀;然後通過關鍵點信息確定模塊33檢測所述當前實景畫面幀中構成人臉圖像的二維關鍵點,並確定所述二維關鍵點的坐標信息,最終通過人物視線校正模塊34根據所述二維關鍵點對應的深度信息及所述坐標信息,在三維空間中校正所述人臉圖像獲得二維的人臉正視圖像。
本發明實施例三提供的一種視線校正裝置,與現有的視線校正裝置相比,該裝置無需依賴特殊硬體或特殊攝像頭,僅需兩個普通的攝像頭就能高效地對所捕獲實景畫面幀中被攝人物的視線進行校正處理,其成本消耗低且適用範圍廣,同時通過雙攝像頭還能帶來更廣的捕獲視野,由此更好的增強了智能會議終端的實際使用體驗。
進一步地,深度信息確定模塊31,具體用於:獲取雙攝像頭在當前視頻場景下同步捕獲的兩張當前畫面幀;對所述兩張當前畫面幀進行立體匹配,獲得所述兩張當前畫面幀中各重合被攝點的視差值;根據各重合被攝點的視差值及深度計算公式,確定各重合被攝點的深度信息。
相應的,圖像拼接合成模塊32,具體用於:根據設定的圖像合併策略,將所述兩張當前畫面幀合併成一幅無縫高解析度的當前實景畫面幀。
進一步地,該裝置還優化增加了:
深度圖確定模塊35,用於在所述確定所述兩張當前畫面幀中各重合被攝點的深度信息之後,基於所述各重合被攝點的深度信息,形成所述各重合被攝點對應的深度圖;
深度信息優化模塊36,用於基於設定的圖像平滑算法對所述深度圖進行平滑優化處理,獲得與所述各重合被攝點對應的優化後的深度信息。
進一步地,該裝置還優化包括:
人臉圖像替換模塊37,用於在根據所述二維關鍵點對應的深度信息及所述坐標信息,在三維空間中校正所述人臉圖像獲得二維的人臉正視圖像之後,將所述當前實景畫面幀中的人臉圖像替換為所述人臉正視圖像,獲得校正實景畫面幀;
校正圖像處理模塊38,用於對所述校正實景畫面幀進行邊緣融合處理,並顯示處理後的校正實景畫面幀。
在上述優化的基礎上,人物視線校正模塊34,具體用於:
查找各重合被攝點的深度信息,確定所述二維關鍵點對應的深度信息;根據所述深度信息及所述坐標信息,對預設的三維人臉參數模型進行人臉圖像擬合,獲得所述當前實景畫面幀中人臉圖像的實際三維人臉模型;根據確定的幾何變換矩陣,將所述實際三維人臉模型由當前姿態變換投影成二維的人臉正視圖像。
實施例四
圖4為本發明實施例四提供的一種智能會議終端的硬體結構示意圖,如圖4所示,本發明實施例四提供的智能會議終端,包括:光軸平行的兩個攝像頭41,處理器42和存儲裝置43。該智能會議終端中的處理器可以是一個或多個,圖4中以一個處理器42為例,所述智能會議終端中的兩個攝像頭41可以通過總線或其他方式分別與處理器42和存儲裝置43連接,且處理器42和存儲裝置43也通過總線或其他方式連接,圖4中以通過總線連接為例。
可以理解的是,智能會議終端屬於上述智能終端中的一種,可以進行遠程的視頻會議通話。在本實施例中,智能會議終端中的處理器42可以控制兩個攝像頭41進行圖像捕獲,處理器42還可以根據兩個攝像頭所捕獲的畫面幀進行所需的操作,此外,兩個攝像頭41所捕獲的畫面幀還可以存儲至存儲裝置43,以實現圖像數據的存儲。
該智能會議終端中的存儲裝置43作為一種計算機可讀存儲介質,可用於存儲一個或多個程序,所述程序可以是軟體程序、計算機可執行程序以及模塊,如本發明實施例中視線校正方法對應的程序指令/模塊(例如,附圖3所示的視線校正裝置中的模塊,包括:深度信息確定模塊31、圖像拼接合成模塊32、關鍵點信息確定模塊33以及人物視線校正模塊34)。處理器42通過運行存儲在存儲裝置43中的軟體程序、指令以及模塊,從而執行智能會議終端的各種功能應用以及數據處理,即實現上述方法實施例中視線校正方法。
存儲裝置43可包括存儲程序區和存儲數據區,其中,存儲程序區可存儲作業系統、至少一個功能所需的應用程式;存儲數據區可存儲根據設備的使用所創建的數據等。此外,存儲裝置43可以包括高速隨機存取存儲器,還可以包括非易失性存儲器,例如至少一個磁碟存儲器件、快閃記憶體器件、或其他非易失性固態存儲器件。在一些實例中,存儲裝置43可進一步包括相對於處理器42遠程設置的存儲器,這些遠程存儲器可以通過網絡連接至設備。上述網絡的實例包括但不限於網際網路、企業內部網、區域網、移動通信網及其組合。
並且,當上述智能會議終端所包括一個或者多個程序被所述一個或者多個處理器42執行時,程序進行如下操作:
獲取雙攝像頭同步捕獲的兩張當前畫面幀,確定所述兩張當前畫面幀中各重合被攝點的深度信息,並合併形成一幅當前實景畫面幀;檢測所述當前實景畫面幀中構成人臉圖像的二維關鍵點,並確定所述二維關鍵點的坐標信息;根據所述二維關鍵點對應的深度信息及所述坐標信息,在三維空間中校正所述人臉圖像獲得二維的人臉正視圖像。
此外,本發明實施例還提供一種計算機可讀存儲介質,其上存儲有電腦程式,該程序被控制裝置執行時實現本發明實施例一或實施例二提供的視線校正方法,該方法包括:獲取雙攝像頭同步捕獲的兩張當前畫面幀,確定所述兩張當前畫面幀中各重合被攝點的深度信息,並合併形成一幅當前實景畫面幀;檢測所述當前實景畫面幀中構成人臉圖像的二維關鍵點,並確定所述二維關鍵點的坐標信息;根據所述二維關鍵點對應的深度信息及所述坐標信息,在三維空間中校正所述人臉圖像獲得二維的人臉正視圖像。
通過以上關於實施方式的描述,所屬領域的技術人員可以清楚地了解到,本發明可藉助軟體及必需的通用硬體來實現,當然也可以通過硬體實現,但很多情況下前者是更佳的實施方式。基於這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分可以以軟體產品的形式體現出來,該計算機軟體產品可以存儲在計算機可讀存儲介質中,如計算機的軟盤、只讀存儲器(read-onlymemory,rom)、隨機存取存儲器(randomaccessmemory,ram)、快閃記憶體(flash)、硬碟或光碟等,包括若干指令用以使得一臺計算機設備(可以是個人計算機,伺服器,或者網絡設備等)執行本發明各個實施例所述的方法。
注意,上述僅為本發明的較佳實施例及所運用技術原理。本領域技術人員會理解,本發明不限於這裡所述的特定實施例,對本領域技術人員來說能夠進行各種明顯的變化、重新調整和替代而不會脫離本發明的保護範圍。因此,雖然通過以上實施例對本發明進行了較為詳細的說明,但是本發明不僅僅限於以上實施例,在不脫離本發明構思的情況下,還可以包括更多其他等效實施例,而本發明的範圍由所附的權利要求範圍決定。