一種圖像匹配點對篩選方法與流程
2023-05-13 01:58:01 3
本發明涉及計算機視覺技術領域,特別是指一種圖像匹配點對篩選方法。
背景技術:
在計算機視覺領域,對模型進行魯棒性估計有著十分重要的意義。模型的魯棒性估計是指在包含異常值的數據集中計算模型參數,主要應用於運動估計、三維重建、目標識別與跟蹤,以及圖像拼接等方面。例如,對於圖像拼接,一般是先找到兩個圖像之間的匹配點對,然後對由所有匹配點對所構成的數據集進行魯棒性估計,從而剔除偏差較大的外點,保留符合模型的內點。
在眾多模型估計算法中,fishler等在1981年引入的ransac(randomsampleconsensus,隨機抽樣一致)算法以其良好的操作性和強大的魯棒性,成為計算機領域應用最廣的模型估計方法。
ransac算法能夠在有大量外點(即不符合模型的點)的數據中找到正確模型,但是在外點數量較多或者模型複雜的情況下,會導致計算量非常大。近年來,為了提高ransac算法的效率及性能,研究人員在這方面做了很多工作。一種途徑是對採用預檢驗的方法,將得到的模型先在小部分數據上而不是所有數據上進行檢驗,只有當模型通過預檢驗時才進入下一步驟。比較經典有chumo提出的基於td,d測試的randomizedransac算法,該算法先對得到模型進行td,d測試,通過則計算所有數據點的誤差,否則重新採樣。陳付幸等在此基礎上進行改進並提出了tc,d測試算法,優化了預處理模型。但是,這類方法的優越性依賴於預判條件的設置,若正確模型通過預檢驗的概率較低,則會比ransac算法需要更多的迭代。另一種途徑是對數據採樣模式進行改進,根據先驗知識對樣本進行有區別的採樣,比較有代表性的是chumo提出的prosac(progressivesampleconsensus)算法,這種算法根據先驗概率對匹配點進行排序,抽取最高概率的最小子集,但是該方法過度依賴於先驗知識,在實際操作中,獲得完全正確的先驗知識往往非常困難,而且誤差的存在也會導致額外的運算。
技術實現要素:
有鑑於此,本發明的目的在於提出一種圖像匹配點對篩選方法,該方法能夠簡化模型構建的過程,提高匹配點對篩選的效率和精度。
基於上述目的,本發明提供的技術方案是:
一種圖像匹配點對篩選方法,其應用於由兩個圖像間的匹配點對所組成的樣本集,樣本集中的每一個樣本點表示一個匹配點對,該方法包括以下步驟:
(1)根據匹配點對的特徵距離為樣本集中的每一個樣本點賦予先驗概率;
(2)從樣本集中逐次獲取內點集,將當次所得內點集與前次所得的最大內點集相比較,直至某次所得內點集在緊隨其後的連續m次比較中均為最大內點集,以此內點集為第一極大內點集;
(3)再次從樣本集中逐次獲取內點集,將當次所得內點集與已有的最大內點集相比較,直至某次所得內點集在緊隨其後的連續n次比較中均為最大內點集,以此內點集為第二極大內點集;至此,第二極大內點集中的樣本點所表示的匹配點對即為兩個圖形間的有效匹配點對;
上述步驟中,所述最大內點集是指元素個數最多的內點集;
步驟(2)中每個內點集的獲取方式為:
(201)根據預設模型對樣本點個數的要求,依先驗概率從樣本集中抽取若干樣本點,構成一個用於求解預設模型具體參數的最小子集;
(202)由步驟(201)中的最小子集求解出預設模型的一組具體參數;
(203)用由步驟(202)中的具體參數所確定的預設模型對樣本集中的所有樣本點進行逐個校驗,得到符合模型的內點集;
步驟(3)中每個內點集的獲取方式為:
(301)根據預設模型對樣本點個數的要求,從當次已有的最大內點集中以等概率方式選取一個用於求解預設模型具體參數的最小子集;
(302)由步驟(301)中的最小子集求解出預設模型的一組具體參數;
(303)用由步驟(302)中的具體參數所確定的預設模型對樣本集中的所有樣本點進行逐個校驗,得到符合模型的內點集。
可選地,特徵距離為匹配點對中兩點的相關性係數,先驗概率為特徵距離的倒數的歸一化值。
可選地,m的取值範圍為28~32;n的取值範圍為57~63。
從上面的敘述可以看出,本發明的特點及有益效果在於:
1、現有技術通常是在得到樣本點的先驗概率之後直接選取先驗概率最高的若干樣本點構成最小子集,這樣,算法會過度依賴於先驗概率,即,對先驗知識準確性的要求極高。而在實際工作中,要獲得準確的先驗概率往往是困難的,因此,現有技術的做法很有可能會在最小子集中包含誤差較大的樣本點,這時,去除這些樣本點就需要更多的運算次數,使運算效率低於原始ransac算法的效率。有鑑於此,本發明方法不直接選取先驗概率最高的前幾個樣本點作為最小子集,而是從整個樣本集中進行多次隨機抽取,每次抽取中,每個樣本點被抽到的概率由其先驗概率決定,這樣,先驗概率高的點有較大的可能被抽取,先驗概率低的點則以較小的可能被抽取。可見,本發明方法降低了對先驗概率的依賴程度,平衡了錯誤的先驗概率對算法的影響,從而在提高算法的效率的同時,保證了算法的穩定性。
2、現有技術中的ransac算法認為每次採樣-檢驗之間是獨立的,上一次的計算結果對以後的檢驗沒有影響。事實上,在沒有任何誤差的情況下,樣本集中只有一個正確模型以及該模型所對應的內點集,所有用從該內點集中選擇的最小子集所估計得到的模型就是該模型。基於這一思想,發明人發現,即使在樣本集存在誤差的情況下,一旦找到正確模型,也可以讓新的採樣只在該正確模型所對應的內點集中進行,這樣可使找到正確模型的概率大大提高,從而使樣本採樣和模型更新進入一個良性循環,提高獲取正確模型概率,減少迭代次數,提前得到最優模型。
總之,本發明方法在考慮先驗知識對採樣模式的影響的同時,還引入了檢驗結果對採樣的約束,從而簡化了構建模型的迭代步驟,提高了獲取正確模型的效率。實驗證明,本發明方法的運行效率和精度相較於現有技術都有較大提高。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對於本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
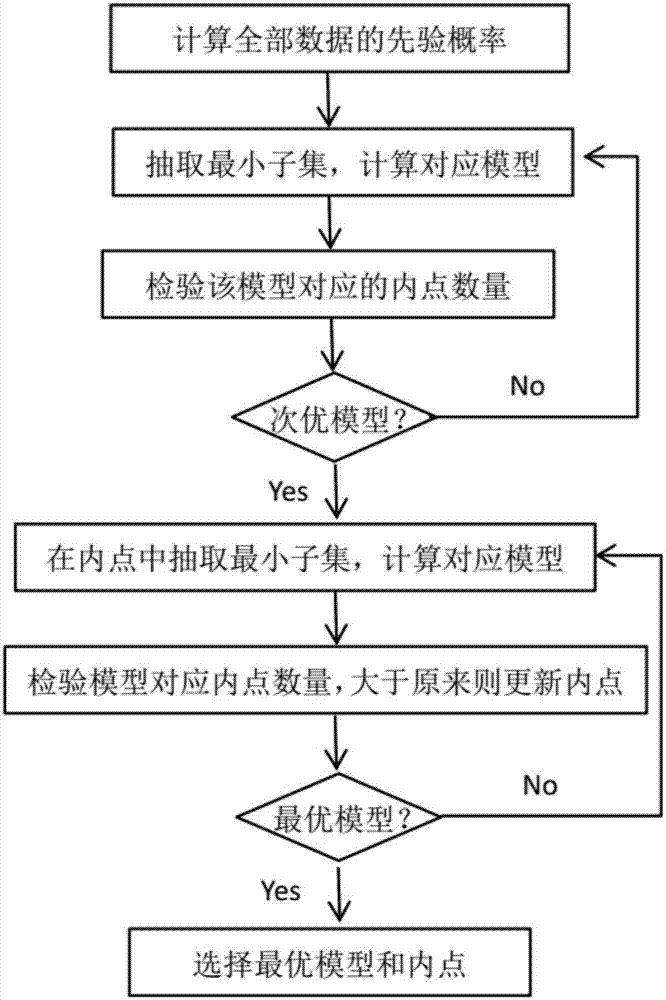
圖1為本發明實施例的一個方法流程圖。
具體實施方式
為使本發明的目的、技術方案和優點更加清楚明白,以下結合具體實施例,並參照附圖,對本發明做進一步的詳細說明。
一種圖像匹配點對篩選方法,其應用於由兩個圖像間的匹配點對所組成的樣本集,樣本集中的每一個樣本點表示一個匹配點對,該方法包括以下步驟:
(1)根據匹配點對的特徵距離為樣本集中的每一個樣本點賦予先驗概率;
(2)從樣本集中逐次獲取內點集,將當次所得內點集與前次所得的最大內點集相比較,直至某次所得內點集在緊隨其後的連續m次比較中均為最大內點集,以此內點集為第一極大內點集;
(3)再次從樣本集中逐次獲取內點集,將當次所得內點集與已有的最大內點集相比較,直至某次所得內點集在緊隨其後的連續n次比較中均為最大內點集,以此內點集為第二極大內點集;至此,第二極大內點集中的樣本點所表示的匹配點對即為兩個圖形間的有效匹配點對;
上述步驟中,最大內點集是指元素個數最多的內點集;
步驟(2)中每個內點集的獲取方式為:
(201)根據預設模型對樣本點個數的要求,依先驗概率從樣本集中抽取若干樣本點,構成一個用於求解預設模型具體參數的最小子集;
(202)由步驟(201)中的最小子集求解出預設模型的一組具體參數;
(203)用由步驟(202)中的具體參數所確定的預設模型對樣本集中的所有樣本點進行逐個校驗,得到符合模型的內點集;
步驟(3)中每個內點集的獲取方式為:
(301)根據預設模型對樣本點個數的要求,從當次已有的最大內點集中以等概率方式選取一個用於求解預設模型具體參數的最小子集;
(302)由步驟(301)中的最小子集求解出預設模型的一組具體參數;
(303)用由步驟(302)中的具體參數所確定的預設模型對樣本集中的所有樣本點進行逐個校驗,得到符合模型的內點集。
本實施例方法步驟(2)基於先驗概率得到一個次優模型,接下來步驟(3)所用最小子集的採樣不在整個樣本集中進行,而是在此次優模型對應的內點集(即第一極大內點集)中進行,並且,如果找到對應內點個數更多的模型,則更新之前得到的最大內點集,並在新的最大內點集中進行最小子集的採樣,否則仍在原內點集中採樣。如此直到最大內點集在指定次數內不再更新,則認為找到最優模型。
事實上,得到的次優模型只有兩種可能,即模型正確(即用於模型估計的最小子集中不含外點)或模型錯誤。假設次優模型是正確模型,那麼基於內點的採樣使迭代在正確樣本點和正確模型之間進行,在很多正確模型中可以很快找到最優模型;假設次優模型是錯誤模型,基於內點的採樣仍然會得到錯誤模型,但是基於全部數據的採樣和基於內點的採樣得到錯誤模型的概率是相同的,而迭代一旦開始找到正確模型後,就可以進入優化迭代。也就是說,即使在最壞的情況下,本算法也不會比ransac算法採樣次數多。
具體地,上述方法中的特徵距離可以採用匹配點對中兩點的相關性係數來表徵,這樣,每個樣本點的先驗概率則可採用特徵距離的倒數的歸一化值來表示。假設樣本集中共有n個樣本點,某一樣本點k所表示的匹配點對中兩點的相關性係數為d(k),則樣本點k的先驗概率為:
通過實驗,上述方法中的m取28~32,n取57~63時可以取得很好的執行效率。
圖1所示為一種迭代執行的圖像匹配點對篩選方法,其包含以下步驟:
(s001)計算樣本集中的每一個樣本點的先驗概率;
(s002)從樣本集中抽取一個最小子集,計算對應的模型;
(s003)以步驟(s002)所得的模型在樣本集中校驗內點,得到內點集及內點數量;
(s004)重複(s002)至(s003),直到第t次所得內點集在t+30次循環中均為最大內點集,以第t次所得內點集為第一極大內點集,至此得到次優模型;
(s005)在當前已有的最大內點集中抽取最小子集,計算對應的模型;
(s006)以步驟(s005)所得的模型在樣本集中校驗內點,得到內點集及內點數量;
(s007)重複(s005)至(s006),直到第k次所得內點集在k+60次循環中均為最大內點集,以第k次所得內點集為第二極大內點集,至此得到最優模型;
(s008)第二極大內點集中的樣本點所表示的匹配點對即為兩個圖形間的有效匹配點對。
需要說明的是,步驟(s007)中第一次循環所得到的內點集需要與第一極大內點集比較,即,第二極大內點集必定不小於第一極大內點集。
本領域的技術人員需要理解,本發明中所謂的內點集的大小是指兩個內點集所含元素個數的多少,並非是指集合間的包含關係。
針對牛津大學可視幾何圖形組中的graffiti和wall圖像(網址:http://www.robots.ox.ac.uk/~vgg/data/data-aff.html),使用本實施例方法及ransac算法分別進行內點選取,得到的對比實驗數據如下表1所示:
表1不同圖像ransac算法與本文算法對比
其中,針對wall圖像,不同內點比例下本實施例方法及ransac算法的實驗對比如下表2所示:
表2不同內點比例ransac算法與本文算法對比(wall)
可見,本實施例方法確實具有更好的精確度和運行效率。
總之,本發明方法按照抽取、估計、檢驗的思路進行內點篩選,著重對抽取方式進行優化改進。本發明方法在考慮先驗知識對採樣模式的影響的同時,還引入了檢驗結果對採樣的約束,從而簡化了構建模型的迭代步驟,提高了獲取正確模型的效率。實驗證明,本發明方法的運行效率和精度相較於現有技術都有較大提高。
所屬領域的普通技術人員應當理解:以上任何實施例的討論僅為示例性的,並非旨在暗示本公開的範圍(包括權利要求)被限於這些例子。凡在本發明的精神和原則之內,對以上實施例所做的任何省略、修改、等同替換、改進等,均應包含在本發明的保護範圍之內。