一種語音交互方法及裝置與流程
2023-05-14 21:42:21 4
本申請涉及智能信息交互技術領域,特別是涉及一種語音交互方法及裝置。
背景技術:
目前,隨著智能技術的不斷發展,出現了很多智能設備,常見的有智慧型手機、機器人、智能音箱、智能電視等設備。
為了方便用戶使用,很多智能設備設置了語音輸入和語音應答的功能。智能設備可以通過語音與用戶進行交互。具體的,智能設備可以從接收的語音信號中檢測出用戶語音,根據檢測出的用戶語音確定對應的交互指令,並響應該交互指令,以實現與用戶的語音交互。例如,當用戶語音為「給我放一首《漂洋過海來看你》吧」時,智能設備確定的交互指令可以為「向用戶播放歌曲《漂洋過海來看你》」,響應該交互指令的過程包括:獲得上述歌曲的音頻資源,播放該音頻資源。又如,當用戶語音為「你今天吃飯了嗎」時,智能設備確定的交互指令可以為「對用戶的問題做出回答」,響應該交互指令的過程包括:獲得針對上述問題的應答內容,播放該應答內容。
但是,當智能設備所應用的環境中噪聲比較大時,智能設備與用戶的語音交互過程可能受影響,導致語音交互過程流暢性差,用戶體驗不好。
技術實現要素:
本申請實施例的目的在於提供了一種語音交互方法及裝置,以提高語音交互過程的流暢性,提高用戶體驗。具體的技術方案如下。
為了達到上述目的,本申請公開了一種語音交互方法,所述方法包括:
接收語音信號,作為目標語音信號;
檢測所述目標語音信號中是否包含用戶語音;
如果是,則確定環境中的噪聲音量;
根據所述噪聲音量,響應目標用戶語音對應的交互指令,所述目標用戶語音為所述目標語音信號中包含的用戶語音。
可選的,所述根據所述噪聲音量,響應目標用戶語音對應的交互指令的步驟,包括:
判斷所述噪聲音量是否滿足基於噪聲的交互控制條件;
如果滿足,則根據預設的噪聲提示信息,確定針對所述交互指令的響應內容,並以所述響應內容響應所述交互指令。
可選的,所述判斷所述噪聲音量是否滿足基於噪聲的交互控制條件的步驟,包括:
判斷所述噪聲音量是否大於預設音量閾值,若為是,則確定所述噪聲音量滿足基於噪聲的交互控制條件;或者,
判斷所述噪聲音量與所述目標用戶語音音量的差值否大於預設差值閾值,若為是,則確定所述噪聲音量滿足基於噪聲的交互控制條件。
可選的,所述根據所述噪聲音量,響應目標用戶語音對應的交互指令的步驟,包括:
判斷所述噪聲音量是否滿足基於噪聲的交互控制條件;
如果滿足,則調大播放音量,響應目標用戶語音對應的交互指令。
可選的,所述調大播放音量的步驟,包括:
將播放音量調整為:所述噪聲音量與預設第一音量的和值;或者,
將播放音量調整為:所述噪聲音量與預設第一係數之積;所述預設第一係數大於1。
可選的,在調大播放音量之後,所述方法還包括:
判斷所述噪聲音量是否滿足基於噪聲的交互控制條件;
如果不滿足,則調小播放音量,響應目標用戶語音對應的交互指令。
可選的,所述調小播放音量的步驟,包括:
將播放音量調整為:上一次音量調整前的播放音量;或者,
將播放音量調整為:當前播放音量與預設第二音量的差值;或者,
將播放音量調整為:當前播放音量與預設第二係數之積,所述預設第二係數大於0且小於1。
可選的,所述確定環境中的噪聲音量的步驟,包括:
將目標噪聲信號的音量確定為環境中的噪聲音量,其中,所述目標噪聲信號為:所述目標語音信號中除所述目標用戶語音以外的信號;或者,
根據目標時間段內接收的語音信號中噪聲信號的音量,確定環境中的噪聲音量,其中,所述目標時間段為:[t-x,t];所述x為預設時長,所述t為接收到所述目標語音信號的時刻。
可選的,所述檢測所述目標語音信號中是否包含用戶語音的步驟,包括:
檢測所述目標語音信號中是否包含來自目標方位的語音信號,如果是,則確定所述目標語音信號中包含用戶語音;其中,所述目標方位為接收到喚醒指令的方位。
為了達到上述目的,本申請公開了一種語音交互裝置,所述裝置包括:
接收模塊,用於接收語音信號,作為目標語音信號;
檢測模塊,用於檢測所述目標語音信號中是否包含用戶語音;
確定模塊,用於當檢測到所述目標語音信號中包含用戶語音時,確定環境中的噪聲音量;
響應模塊,用於根據所述噪聲音量,響應目標用戶語音對應的交互指令,所述目標用戶語音為所述目標語音信號中包含的用戶語音。
可選的,所述響應模塊,包括:
第一判斷子模塊,用於判斷所述噪聲音量是否滿足基於噪聲的交互控制條件;
第一響應子模塊,用於當所述噪聲音量滿足基於噪聲的交互控制條件時,根據預設的噪聲提示信息,確定針對所述交互指令的響應內容,並以所述響應內容響應所述交互指令。
可選的,所述第一判斷子模塊,具體用於:判斷所述噪聲音量是否大於預設音量閾值,若為是,則確定所述噪聲音量滿足基於噪聲的交互控制條件;或者,
所述第一判斷子模塊,具體用於:判斷所述噪聲音量與所述目標用戶語音音量的差值否大於預設差值閾值,若為是,則確定所述噪聲音量滿足基於噪聲的交互控制條件。
可選的,所述響應模塊,包括:
第二判斷子模塊,用於判斷所述噪聲音量是否滿足基於噪聲的交互控制條件;
第二響應子模塊,用於當所述噪聲音量滿足基於噪聲的交互控制條件時,調大播放音量,響應目標用戶語音對應的交互指令。
可選的,所述第二響應子模塊,包括:
調大單元,用於當所述噪聲音量滿足基於噪聲的交互控制條件時,調大播放音量;
第一響應單元,用於在調大播放音量之後,響應目標用戶語音對應的交互指令;
其中,所述調大單元,具體用於:
將播放音量調整為:所述噪聲音量與預設第一音量的和值;或者,
所述調大單元,具體用於:
將播放音量調整為:所述噪聲音量與預設第一係數之積;所述預設第一係數大於1。
可選的,所述響應模塊還包括:
第三判斷子模塊,用於在調大播放音量之後,判斷所述噪聲音量是否滿足基於噪聲的交互控制條件;
第三響應子模塊,用於當所述噪聲音量不滿足基於噪聲的交互控制條件時,調小播放音量,響應目標用戶語音對應的交互指令。
可選的,所述第三響應子模塊,具體包括:
調小單元,用於當所述噪聲音量不滿足基於噪聲的交互控制條件時,調小播放音量;
第二響應單元,用於在調小播放音量之後,響應目標用戶語音對應的交互指令;
其中,所述調小單元,具體用於:將播放音量調整為:上一次音量調整前的播放音量;或者,
所述調小單元,具體用於:將播放音量調整為:當前播放音量與預設第二音量的差值;或者,
所述調小單元,具體用於:將播放音量調整為:當前播放音量與預設第二係數之積,所述預設第二係數大於0且小於1。
可選的,所述確定模塊,具體用於:
將目標噪聲信號的音量確定為環境中的噪聲音量,其中,所述目標噪聲信號為:所述目標語音信號中除所述目標用戶語音以外的信號;或者,
所述確定模塊,具體用於:
根據目標時間段內接收的語音信號中噪聲信號的音量,確定環境中的噪聲音量,其中,所述目標時間段為:[t-x,t];所述x為預設時長,所述t為接收到所述目標語音信號的時刻。
可選的,所述檢測模塊,具體用於:
檢測所述目標語音信號中是否包含來自目標方位的語音信號,如果是,則確定所述目標語音信號中包含用戶語音;其中,所述目標方位為接收到喚醒指令的方位。
本申請實施例提供的語音交互方法及裝置,可以將接收的語音信號作為目標語音信號,檢測目標語音信號中是否包含用戶語音,如果是,則確定環境中的噪聲音量,根據所確定的噪聲音量,響應目標用戶語音對應的交互指令,其中,目標用戶語音為目標語音信號中包含的用戶語音。也就是說,本實施例可以在檢測到用戶語音時,確定噪聲音量,根據噪聲音量對語音交互過程進行相應的調整。因此,應用本申請實施例提供的方案,能夠提高語音交互過程的流暢性,提高用戶體驗。
附圖說明
為了更清楚地說明本申請實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單的介紹。顯而易見地,下面描述中的附圖僅僅是本申請的一些實施例,對於本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1為本申請實施例提供的語音交互方法的一種流程示意圖;
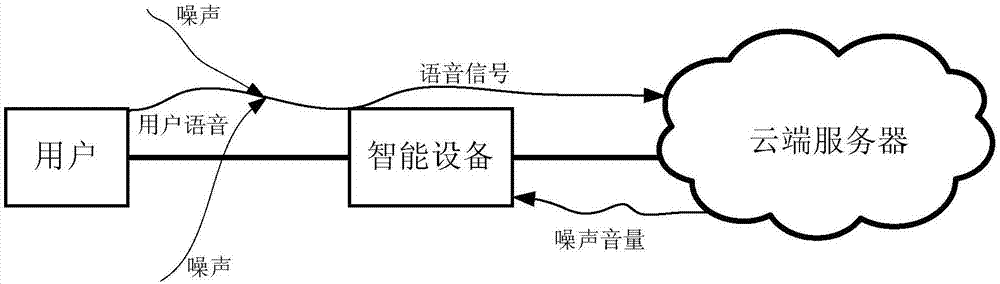
圖2為用戶、智能設備、雲端伺服器之間交互的示意圖;
圖3為圖1中步驟s104的一種流程示意圖;
圖4為圖1中步驟s104的另一種流程示意圖;
圖5為本申請實施例提供的語音交互裝置的一種結構示意圖。
具體實施方式
下面將結合本申請實施例中的附圖,對本申請實施例中的技術方案進行清楚、完整的描述。顯然,所描述的實施例僅僅是本申請的一部分實施例,而不是全部的實施例。基於本申請中的實施例,本領域普通技術人員在沒有做出創造性勞動的前提下所獲得的所有其他實施例,都屬於本申請保護的範圍。
本申請實施例提供了一種語音交互方法及裝置,應用於智能設備,該智能設備可以包括智慧型手機、機器人、智能音箱、智能電視等設備。本申請實施例的方案能夠提高語音交互過程的流暢性,提高用戶體驗。下面通過具體實施例,對本申請進行詳細說明。
圖1為本申請實施例提供的語音交互方法的一種流程示意圖,應用於智能設備。該方法包括如下步驟s101~步驟s104:
步驟s101:接收語音信號,作為目標語音信號。
具體的,智能設備可以通過自身設置的收音器件接收語音信號,其中,為了提高收音的準確性,該收音器件可以是麥克風陣列。麥克風陣列是將多個麥克風以預設的空間分布特徵設置在設備上的一種收音器件。
在接收語音信號時,可以實時地接收語音信號。其中,該語音信號可以包含多種聲源發出的信號,這些聲源可能只是噪聲聲源,也可能包含噪聲聲源和用戶聲源。
可以理解的是,所接收的語音信號可以是一段時間內的語音信號,這段時間的時長可以是預先設定的,例如,該時長可以是5秒或10秒等。
步驟s102:檢測上述目標語音信號中是否包含用戶語音,如果是,則執行步驟s103。如果否,則可以不做處理,也可以記錄目標語音信號的語音參數,該語音參數可以包括音量、時間等。
可以理解的是,智能設備在與用戶進行語音交互時,首先需要判斷是否接收到喚醒指令,如果接收到,則智能設備可以與用戶進行其他的語音交互;如果沒有接收到,則智能設備無法與用戶進行其他的語音交互。其中,喚醒指令可以與預先設定的喚醒詞對應,例如,當用戶輸入預設的喚醒詞後,智能設備即接收到喚醒指令。其他的語音交互是指除喚醒時交互之外的語音交互。
具體的,在對目標語音信號進行檢測時,如果檢測出該目標語音信號中包含喚醒指令,則將喚醒指令對應的語音信號確定為用戶語音,並可以將喚醒指令對應的方位確定為用戶當前的方位。
在喚醒智能設備之後,智能設備可以繼續接收該方位上用戶輸入的其他語音;因此,在另一種實施方式中,檢測目標語音信號中是否包含用戶語音時,可以包括:
檢測目標語音信號中是否包含來自目標方位的語音信號,如果是,則確定目標語音信號中包含用戶語音,並將目標語音信號中包含的來自目標方位的語音信號確定為目標用戶語音。其中,目標方位為接收到喚醒指令的方位。
另外,由於噪聲是聲源做無規則振動時發出的聲音,其音頻和音強等特徵變化混亂,沒有規律;而相對於噪聲,用戶發出的聲音的音頻和音強等特徵變化不大,比較有規律性。
因此,可以根據用戶的聲音特徵,檢測目標語音信號中是否包含用戶語音。
步驟s103:確定環境中的噪聲音量。其中,音量也可以稱為聲壓,單位為分貝(db)。
具體的,確定環境中的噪聲音量時,具體可以包括以下幾種實施方式:
方式一,將目標噪聲信號的音量確定為環境中的噪聲音量。其中,目標噪聲信號為:目標語音信號中除目標用戶語音以外的信號。
可以理解的是,環境中的噪聲是時刻存在的,只是有時噪聲音量較大,有時噪聲音量較小。因此,智能設備接收到的目標語音信號中包含噪聲信號。當目標語音信號中既包含噪聲信號,又包含用戶語音時,可以將除用戶語音之外的語音信號的音量作為噪聲音量。
方式二,根據目標時間段內接收的語音信號中噪聲信號的音量,確定環境中的噪聲音量。其中,目標時間段為:[t-x,t];x為預設時長,t為接收到目標語音信號的時刻。
需要說明的是,接收到目標語音信號的時刻為接收完目標語音信號的時刻,而非開始接收目標語音信號的時刻。
例如,目標語音信號持續時長為5s,接收到目標語音信號的時刻為第50s時,預設時長為20s,那麼目標時間段可以為第30秒~第50s。也就是說,目標時間段內接收的語音信號中包含目標語音信號。
可以理解的是,噪聲信號的音量可能是不斷變化的,根據目標時間段內接收的語音信號中噪聲信號的音量確定環境噪聲音量,能夠使確定的噪聲音量更準確。
步驟s104:根據上述噪聲音量,響應目標用戶語音對應的交互指令,目標用戶語音為目標語音信號中包含的用戶語音。
具體的,在確定目標用戶語音對應的交互指令時,可以包括:在獲得目標用戶語音之後,智能設備可以對該目標用戶語音進行語音識別,獲得語音識別結果,確定與該語音識別結果對應的交互指令,該交互指令即為與目標用戶語音對應的交互指令。
上述交互指令可以為多種類型的指令,例如喚醒後的回應指令、點播指令、聊天指令、信息查詢指令等。舉例來說,當目標用戶語音為「小雅小雅」時(小雅小雅為喚醒詞),對應的交互指令為喚醒後的回應指令;當目標用戶語音為「請為我播放一首《忘情水》」時,對應的交互指令為點播指令;當目標用戶語音為「你今天吃飯了嗎」時,對應的交互指令為聊天指令;當目標用戶語音為「今天天氣怎麼樣」或者「明天下午有會議嗎」時,對應的交互指令為信息查詢指令。需要說明的是,上述舉例只是部分交互指令,並不是全部,本領域技術人員還可以據此獲得更多類型的交互指令。本申請對交互指令的具體內容不做限定。
具體的,根據上述噪聲音量,響應目標用戶語音對應的交互指令,可以包括多種實施方式,例如,當噪聲音量比較大時,可以將智能設備的播放音量調大,或向用戶播放一些提示信息,這些都是可行的。
可以理解的是,在根據上述噪聲音量響應目標用戶語音對應的交互指令之後,能夠使智能設備調整本身輸出的音量,或者根據智能設備的提示,可以使用戶向智能設備輸入的語音發生相應的變化。這些調整或變化都能使智能設備與用戶後續的語音交互過程更加流暢,準確性更高。
由上述內容可知,本實施例提供的語音交互方法及裝置,可以將接收的語音信號作為目標語音信號,檢測目標語音信號中是否包含用戶語音,如果是,則確定環境中的噪聲音量,根據所確定的噪聲音量,響應目標用戶語音對應的交互指令,其中,目標用戶語音為目標語音信號中包含的用戶語音。也就是說,本實施例可以在檢測到用戶語音時,確定噪聲音量,根據噪聲音量對語音交互過程進行相應的調整。因此,應用本實施例提供的方案,能夠提高語音交互過程的流暢性,提高用戶體驗。
另外,由於智能設備的性能限制,上述步驟s102~步驟s103具體可以是在與智能設備通信相連的雲端伺服器上執行的。也就是說,在這種實施方式中,智能設備在接收到語音信號並作為目標語音信號之後,將目標語音信號發送至雲端伺服器,雲端伺服器檢測目標語音信號中是否包含用戶語音,如果是,則確定環境中的噪聲音量,將確定的噪聲音量發送至智能設備。由於雲端伺服器可以具有更強的處理能力,因此本實施例的方案可以在智能設備性能受限時提高語音交互過程的效率,同時無需提高智能設備的性能。
作為一個例子,圖2為用戶、智能設備和雲端伺服器之間交互的流程示意圖。其中,智能設備接收周圍的語音信號,並發送至雲端伺服器,雲端伺服器將噪聲音量發送至智能設備。
在圖1所示實施例的一種實施方式中,步驟s104,即根據所述噪聲音量,響應目標用戶語音對應的交互指令的步驟,可以按照圖3所示流程示意圖進行,具體包括以下步驟s104a和步驟s104b:
步驟s104a:判斷上述噪聲音量是否滿足基於噪聲的交互控制條件,如果滿足,則執行步驟s104b。
需要說明的是,當噪聲音量滿足基於噪聲的交互控制條件時,說明當前的噪聲音量已經比較大了,即當前的環境為較差的交互環境,這種環境會影響智能設備與用戶之間正常的語音交互過程。
具體的,在判斷噪聲音量是否滿足基於噪聲的交互控制條件時,可以包括以下幾種實施方式:
方式一,判斷該噪聲音量是否大於預設音量閾值,若為是,則確定所述噪聲音量滿足基於噪聲的交互控制條件。
其中,預設音量閾值可以取得較大一些,例如75db、80db、85db等音量。當該預設音量閾值的取值較大一些時,確定當前環境為較差的交互環境的準確性會更高。
方式二,判斷該噪聲音量與目標用戶語音音量的差值否大於預設差值閾值,若為是,則確定所述噪聲音量滿足基於噪聲的交互控制條件。
其中,預設差值閾值可以根據經驗獲得,即當噪聲音量與目標用戶語音音量的差值不大於預設差值閾值時,智能設備與用戶之間的交互過程受環境噪聲的影響較小,不認為當前環境為較差的交互環境。
預設差值閾值可以取得較大一些,例如20db、25db等音量。當該預設差值閾值的取值較大一些時,確定當前環境為較差的交互環境的準確性會更高。
步驟s104b:根據預設的噪聲提示信息,確定針對所述交互指令的響應內容,並以該響應內容響應上述交互指令。
其中,預設的噪聲提示信息可以為音量調整提示信息、設備與用戶之間距離的調整提示信息、降低噪聲提示信息或調整交互環境提示信息等類型。
例如,音量調整提示信息可以包括:請調大音量、請大點聲、請大點聲再說一次等;
設備與用戶之間距離的調整提示信息可以包括:請離我近一些說、請靠近一點說、請再過來一些說等;
降低噪聲提示信息可以包括:請把周圍的聲音關小一點、請關閉周圍的發聲設備等
調整交互環境提示信息可以包括:請換一個安靜點的環境、請換個環境、請把我移到另一個環境、請把我移到安靜點的環境等。
具體的,步驟s104b可以包括:將預設的噪聲提示信息直接確定為針對上述交互指令的響應內容。
需要說明的是,當噪聲音量很大,周圍環境很嘈雜時,智能設備可能無法對目標用戶語音進行準確識別。這時,可以直接將預設的噪聲提示信息直接確定為針對上述交互指令的響應內容。
具體的,步驟s104b可以包括:對目標用戶語音進行語音識別,獲得語音識別結果,根據預設的噪聲提示信息和該語音識別結果,確定針對上述交互指令的響應內容。
需要說明的是,當周圍環境存在較大噪聲時,但是還可以從目標用戶語音中識別出較準確的結果時,可以將預設的噪聲提示信息和該語音識別結果結合起來,確定針對上述交互指令的響應內容。
例如,語音識別結果為「今天天氣怎麼樣」,確定的響應內容可以是「您說的是今天天氣怎麼樣嗎?對不起,周圍環境太吵,請把我移到安靜點的環境」,或者也可以是「您說的是今天天氣怎麼樣嗎?對不起,周圍環境太吵,請把周圍的聲音關小一點」。
具體的,以該響應內容響應上述交互指令,具體可以包括:播放該響應內容。另外,在播放該響應內容之前,還可以調大播放音量。
在調大播放音量時,可以包括以下多種方式:
方式一,將播放音量調整為:該噪聲音量與預設第一音量的和值。其中,預設第一音量可以為5db、10db或15db等。
方式二,將播放音量調整為:該噪聲音量與預設第一係數之積;該預設第一係數大於1。其中,預設第一係數可以為1.1、1.2、1.3等。
這樣,在嘈雜環境下,由於調大了播放音量,播放出的響應內容可以讓用戶聽得更清楚,語音交互過程也會更流程,能夠提高用戶體驗。
在圖1所示實施例的一種實施方式中,步驟s104,即根據所述噪聲音量,響應目標用戶語音對應的交互指令的步驟,可以按照圖4所示流程示意圖進行,具體包括步驟s104a和步驟s104b:
步驟s104a:判斷所述噪聲音量是否滿足基於噪聲的交互控制條件,如果滿足,則執行步驟s104b。
本步驟與步驟s104a相同,具體內容可以參考步驟s104a的相關描述。
步驟s104b:調大播放音量,響應目標用戶語音對應的交互指令。
需要說明的是,調大播放音量的過程已經在步驟s104b的對應描述中說明,詳細內容可以參見步驟s104b的相關描述。
在調大播放音量之後,響應目標用戶語音對應的交互指令時,可以包括:確定針對該交互指令的響應內容,播放該響應內容。
由於上述交互指令可以為多種類型的指令,例如喚醒後的回應指令、點播指令、聊天指令、信息查詢指令等。對應的,針對該交互指令的響應內容也可以包括多種類型,例如喚醒後的回應類、點播回復類、聊天應答類、信息反饋類等。
舉例來說,當目標用戶語音為「小雅小雅」時(小雅小雅為喚醒詞),對應的交互指令為喚醒後的回應指令,這時響應內容可以為「哎」或「我在」「here(這兒)」等;當目標用戶語音為「請為我播放一首《忘情水》」時,對應的交互指令為點播指令,這時響應內容可以為「為您播放《忘情水》」語音提示以及歌曲資源;當目標用戶語音為「你今天吃飯了嗎」時,對應的交互指令為聊天指令,這時響應內容可以為「沒有呢,你想請我吃飯嗎」;當目標用戶語音為「今天天氣怎麼樣」或者「明天下午有會議嗎」時,對應的交互指令為信息查詢指令,這時響應內容可以分別為「今天天氣晴朗,微風」和「明天下午沒有會議」。需要說明的是,上述舉例只是部分交互指令,並不是全部,本領域技術人員還可以據此獲得更多類型的交互指令。本申請對交互指令的具體內容不做限定。
可以理解的是,當周圍環境噪聲較大時,智能設備相應地提高播放音量,這樣可以讓用戶更清楚地聽到智能設備的響應內容。
需要說明的是,本實施方式中,雖然周圍存在較大的噪聲,但是智能設備還是能夠比較準確地對目標用戶語音進行識別,進而比較準確地確定對應的交互指令,因此可以直接在調大播放音量的情況下響應交互指令,這樣能使語音交互過程在嘈雜的環境下流程地進行。
在圖1所示實施例的一種實施方式中,在調大播放音量之後,該方法還可以包括以下步驟1~步驟2:
步驟1:判斷該噪聲音量是否滿足基於噪聲的交互控制條件,如果不滿足,則執行步驟2;如果滿足,則不予處理。
步驟2:調小播放音量,響應目標用戶語音對應的交互指令。
可以理解的是,當噪聲音量不滿足基於噪聲的交互控制條件時,說明當前的噪聲音量比較小了,即當前的環境為較好的交互環境。在這種環境下,如果還是保持較大的播放音量,則用戶體驗不好。這時,調小播放音量,能夠提高用戶體驗。
具體的,調小播放音量時,具體可以包括以下幾種實施方式:
方式一,將播放音量調整為:上一次音量調整前的播放音量。其中,上一次音量調整,為將音量調大的那次音量調整。
方式二,將播放音量調整為:當前播放音量與預設第二音量的差值。其中,預設第二音量可以與預設第一音量相同,也可以不相同。
方式三,將播放音量調整為:當前播放音量與預設第二係數之積,所述預設第二係數大於0且小於1。其中,預設第二係數可以與預設第一係數相同,也可以不相同。
作為一種應用場景的例子,當用戶與智能設備的交互環境中存在較大的噪聲時,智能設備播放的語音可能淹沒在噪聲中,無法使用戶聽到,這時智能設備可以調大播放音量,使用戶能夠聽得更清楚。當周圍的噪聲又變小時,智能設備可以調小播放音量,這樣用戶不會因為周圍噪聲變小而感覺智能設備播放的聲音過大。也就是說,智能設備可以根據環境噪聲音量,智慧地調節播放音量,使用戶體驗更高。
圖5為本申請實施例提供的一種語音交互裝置的一種流程示意圖,應用於智能設備,該實施例與圖1所示方法實施例相對應,該裝置包括:
接收模塊501,用於接收語音信號,作為目標語音信號;
檢測模塊502,用於檢測所述目標語音信號中是否包含用戶語音;
確定模塊503,用於當檢測到所述目標語音信號中包含用戶語音時,確定環境中的噪聲音量;
響應模塊504,用於根據所述噪聲音量,響應目標用戶語音對應的交互指令,所述目標用戶語音為所述目標語音信號中包含的用戶語音。
在圖5所示實施例的一種實施方式中,響應模塊504具體可以包括:
第一判斷子模塊(圖中未示出),用於判斷所述噪聲音量是否滿足基於噪聲的交互控制條件;
第一響應子模塊(圖中未示出),用於當所述噪聲音量滿足基於噪聲的交互控制條件時,根據預設的噪聲提示信息,確定針對所述交互指令的響應內容,並以所述響應內容響應所述交互指令。
在圖5所示實施例的一種實施方式中,第一判斷子模塊具體可以用於:判斷所述噪聲音量是否大於預設音量閾值,若為是,則確定所述噪聲音量滿足基於噪聲的交互控制條件;或者,
第一判斷子模塊具體可以用於:判斷所述噪聲音量與所述目標用戶語音音量的差值否大於預設差值閾值,若為是,則確定所述噪聲音量滿足基於噪聲的交互控制條件。
在圖5所示實施例的一種實施方式中,響應模塊504具體可以包括:
第二判斷子模塊(圖中未示出),用於判斷所述噪聲音量是否滿足基於噪聲的交互控制條件;
第二響應子模塊(圖中未示出),用於當所述噪聲音量滿足基於噪聲的交互控制條件時,調大播放音量,響應目標用戶語音對應的交互指令。
在圖5所示實施例的一種實施方式中,第二響應子模塊可以包括:
調整單元(圖中未示出),用於當所述噪聲音量滿足基於噪聲的交互控制條件時,調大播放音量;
響應單元(圖中未示出),用於在調大播放音量之後,響應目標用戶語音對應的交互指令;
其中,調整單元具體可以用於:
將播放音量調整為:所述噪聲音量與預設第一音量的和值;或者,
調整單元具體可以用於:
將播放音量調整為:所述噪聲音量與預設第一係數之積;所述預設第一係數大於1。
在圖5所示實施例的一種實施方式中,響應模塊504還可以包括:
第三判斷子模塊(圖中未示出),用於在調大播放音量之後,判斷所述噪聲音量是否滿足基於噪聲的交互控制條件;
第三響應子模塊(圖中未示出),用於當所述噪聲音量不滿足基於噪聲的交互控制條件時,調小播放音量,響應目標用戶語音對應的交互指令。
在圖5所示實施例的一種實施方式中,第三響應子模塊具體可以包括:
調小單元(圖中未示出),用於當所述噪聲音量不滿足基於噪聲的交互控制條件時,調小播放音量;
第二響應單元(圖中未示出),用於在調小播放音量之後,響應目標用戶語音對應的交互指令;
其中,調小單元,具體用於:將播放音量調整為:上一次音量調整前的播放音量;或者,
調小單元,具體用於:將播放音量調整為:當前播放音量與預設第二音量的差值;或者,
調小單元,具體用於:將播放音量調整為:當前播放音量與預設第二係數之積,所述預設第二係數大於0且小於1。
在圖5所示實施例的一種實施方式中,確定模塊503具體可以用於:
將目標噪聲信號的音量確定為環境中的噪聲音量,其中,所述目標噪聲信號為:所述目標語音信號中除所述目標用戶語音以外的信號;或者,
所述確定模塊503具體可以用於:
根據目標時間段內接收的語音信號中噪聲信號的音量,確定環境中的噪聲音量,其中,所述目標時間段為:[t-x,t];所述x為預設時長,所述t為接收到所述目標語音信號的時刻。
在圖5所示實施例的一種實施方式中,檢測模塊102具體可以用於:
檢測所述目標語音信號中是否包含來自目標方位的語音信號,如果是,則確定所述目標語音信號中包含用戶語音;其中,所述目標方位為接收到喚醒指令的方位。
由於上述裝置實施例是基於方法實施例得到的,與該方法具有相同的技術效果,因此裝置實施例的技術效果在此不再贅述。對於裝置實施例而言,由於其基本相似於方法實施例,所以描述得比較簡單,相關之處參見方法實施例的部分說明即可。
需要說明的是,在本文中,諸如第一和第二等之類的關係術語僅僅用來將一個實體或者操作與另一個實體或操作區分開來,而不一定要求或者暗示這些實體或操作之間存在任何這種實際的關係或者順序。而且,術語「包括」、「包含」或者任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者設備所固有的要素。在沒有更多限制的情況下,由語句「包括一個……」限定的要素,並不排除在包括所述要素的過程、方法、物品或者設備中還存在另外的相同要素。
本說明書中的各個實施例均採用相關的方式描述,各個實施例之間相同相似的部分互相參見即可,每個實施例重點說明的都是與其他實施例的不同之處。
以上所述僅為本申請的較佳實施例而已,並非用於限定本申請的保護範圍。凡在本申請的精神和原則之內所做的任何修改、等同替換、改進等,均包含在本申請的保護範圍內。