基於馬爾科夫鏈進化的汽車運行工況設計方法與流程
2023-04-29 04:24:41 4
本發明涉及汽車運行工況設計方法,特別是一種基於馬爾科夫鏈進化的汽車運行工況設計方法。
背景技術:
汽車的排放和能源消耗是汽車領域內備受關注的兩個方面。而在尋找降低排放和提高燃油消耗使用率的新技術時,例如在考察某類車輛在某一地區排放水平或者能量消耗量時,確定當地的汽車運行工況,才能夠提供可靠的檢測依據;在設計開發新車型的動力系統時,汽車運行工況是重要的評價依據。汽車運行工況作為汽車正向開發過程中的一項核心技術,其中合理的設計方法是能夠高效率得到代表性工況的關鍵。
在汽車運行工況設計方法中,基於馬爾科夫鏈的設計方法已成為工況設計的主流方法。它依據工況是馬爾科夫鏈的本質的特點,運用馬爾科夫鏈隨機模擬生成的工況序列。2001年,linjie在博士論文中提到汽車運行工況是一個隨機過程,首次利用馬爾科夫的方法設計工況。shishuming等人證明在小尺度範圍內(如1s),運行工況具有強馬爾科夫性,即當前狀態到下一時刻的狀態存在確定的狀態轉移概率。研究學者又對工況的馬爾科夫性進行了深入的拓展研究,yuebingjian等人通過試驗數據驗證了道路坡度具有馬爾科夫性,設計了三參數的運行工況。馬爾科夫鏈方法從符合工況動力學本質特徵的客觀事實出發,合理性強,富有科學依據。儘管馬爾科夫模型在汽車運行工況中使用成熟,但是更多研究學者們關注的是馬爾科夫鏈設計工況的應用以及拓展,並未注意到基於馬爾科夫鏈設計汽車運行工況時,尤其設計多參數的高速工況時,存在設計效率極低的問題。因此,針對此問題提出本發明方法。
技術實現要素:
本發明的目的是提供一種基於馬爾科夫鏈進化的汽車運行工況設計方法,以提高基於馬爾科夫鏈方法設計多參數的高速工況的設計效率。
本發明基於馬爾科夫鏈進化的汽車運行工況設計方法,包括以下五個階段:
一、初始種群構建
通過汽車運行工況的馬爾科夫鏈隨機模擬生成多條滿足一定長度的起止為怠速狀態條件的工況狀態序列,以此組成一個初始種群;具體步驟如下:
1)統計三參數(速度,加速度和坡度)工況原始資料庫的狀態轉移矩陣:
首先,確定速度,加速度和坡度的劃分步長以及範圍,採用下式
st=mt+(nt-1)×m+(pt-1)×m×h,t=1,2,…
將三維空間狀態mt,nt,pt轉化為一維空間狀態st,其中,mt為速度的狀態,nt為加速度的狀態,pt為坡度的狀態,m為速度最大維數,h為加速度最大維數;
然後,採用最大似然估計方法,統計狀態轉移概率矩陣p,
其中,pij為一維空間狀態si到一維空間狀態sj的轉移概率,nij為一維空間狀態si到一維空間狀態sj的轉移頻數,ni為一維空間狀態si到一維空間的其他狀態的轉移頻數之和,s為一維空間狀態集合;
2)模擬馬爾科夫鏈隨機狀態序列x=(k0,k1,…,ki,…),i=n,其中n為序列長度,
選取怠速狀態作為馬爾科夫鏈的初始狀態x(1)=k0,利用偽隨機數原則,在0和1之間取隨機數r1,選擇滿足
的狀態k1作為馬爾科夫鏈的下一狀態x(2)=k1,按照此模擬方法不斷重複,生成長度為n的工況狀態序列;選取終止狀態仍為怠速狀態的序列作為工況狀態序列,依次生成多條起止為怠速狀態的工況狀態序列;
3)生成工況的初始種群
採用遺傳算法中的整數編碼方式,將馬爾科夫鏈隨機生成的狀態編碼為基因,將長度為n的工況狀態序列編碼為一條染色體,則多條染色體即多條工況狀態序列組成一個初始種群;
二、目標函數設計
計算設計工況與參考資料庫的所有指標的相對偏差,採用滿意準則模型,將多目標轉化為單目標的目標函數;具體步驟如下:
1)選取工況中常用的特徵參數並設定允許偏差
選取汽車運行工況設計中常用的特徵參數作為評價設計工況與原始資料庫一致性的評價指標,允許偏差根據工程應用需求設定;
2)設計工況與原始資料庫的指標函數一致性表達
x為生成的設計工況,io為原始資料庫的特徵參數,id為設計工況的特徵參數,e為允許偏差,用公式(2)表達設計工況與原始資料庫的一致性
|ioi-idi|≤ei,(i=1,2,…,n),n=11(2)
3)利用公式(3)滿意準則模型的廣義形式
將公式(2)轉化為公式(4)
4)通過構造公式(5)輔助函數ti
把公式(4)多目標轉化為公式(6)單目標函數f
三、交叉算子設計
利用汽車運行工況統計的狀態轉移矩陣,在任意兩個個體序列中,判斷與等長交叉段相關的四個基因轉移概率是否非零,選擇滿足馬爾科夫鏈狀態轉移關係的基因並進行等交叉段交叉,最終得到符合馬爾科夫鏈的交叉個體;具體步驟如下:
下述中,x(1)和x(2)為兩條時間序列的個體,n為個體的長度,p為公式(1)計算得到的工況狀態轉移概率矩陣,
1)確定交叉位置
x(1)的兩個相鄰基因和與x(2)的兩個相鄰基因和滿足
時,i為x(1)的交叉位置,j為x(2)的交叉位置,且i不一定等於j;為到的轉移概率,為到的轉移概率;
2)確定交叉段
為保證x(1)和x(2)發生交叉後,生成的子代個體仍然滿足長度為n,兩個個體各自交叉位置之間的部分染色體長度必須相同;按照上述1)確定另一組交叉位置i′和j′,其滿足
其中i′-i=j′-j,為到的轉移概率,為到的轉移概率;
3)實施交叉,生成子代個體
確定交叉位置以及交叉段後,交換x(1)中位置i到i′和x(2)中j到j′之間的部分染色體,最終生成兩個子代染色體;
四、變異算子設計
應用汽車運行工況的馬爾科夫鏈隨機模擬,滿足一定長度且起止為怠速狀態條件下,生成任意一條工況狀態序列作為子代序列個體;
變異算子採用上述階段一2)中的馬爾科夫鏈隨機模擬方法進行設計,即滿足一定長度且起止為怠速狀態條件下,生成一定長度的工況狀態序列,並對其整數編碼,最後得到一條基因染色體作為變異個體;
五、代表性工況進化過程
設定迭代次數,進化初始種群至輸出最佳目標函數值的工況狀態序列;然後經過解碼,生成三參數的時間序列,即代表性工況。
本發明設計方法,是通過馬爾科夫鏈與遺傳算法結合的思想,利用汽車運行工況的本質特徵(馬爾科夫鏈)去重新構建新的遺傳算法,最後進化出代表性工況。該方法顯著地提高了馬爾科夫鏈方法設計多參數(速度、加速度和坡度)高速工況的效率。
在給定相同的三參數高速資料庫下設計1800s長度的代表性工況,與基於傳統馬爾科夫鏈方法設計工況相比,平均用時減少了23.24小時,平均效率顯著提高。在設計相同精度的代表性工況要求下,與基於傳統馬爾科夫鏈設計方法長時間仍未達精度要求相比,本發明方法得到更優的設計工況。該方法可以直接應用於處理馬爾科夫鏈的實際問題中,改善馬爾科夫鏈隨機模擬的收斂慢的現象,具有更廣泛的適用性。
附圖說明
圖1是本發明設計方法流程示意圖;
圖2是本發明設計方法所述的狀態轉移概率矩陣二維投影圖;
圖3本發明設計方法所述的隨機搜索交叉算法中循環次數k與發生交叉的概率的關係圖;
圖4本發明設計方法所述的隨機搜索交叉算法中循環次數k與平均用時的關係圖;
圖5本發明設計方法所述的速度時間序列圖;
圖6本發明設計方法所述的加速度時間序列圖;
圖7本發明設計方法所述的坡度時間序列圖。
具體實施方式
通過以下實施例及附圖對本發明設計方法作進一步詳細說明。
參照圖1,本發明一種基於馬爾科夫鏈進化的汽車運行工況設計方法,包括以下五個階段,具體實施方式詳述如下:
階段一:初始種群構建
初始種群構建主要包括以下三個步驟:
1)統計三參數(速度,加速度和坡度)工況原始資料庫的狀態轉移矩陣:
確定速度、加速度和坡度的劃分步長以及範圍。採用下式
st=mt+(nt-1)×m+(pt-1)×m×h
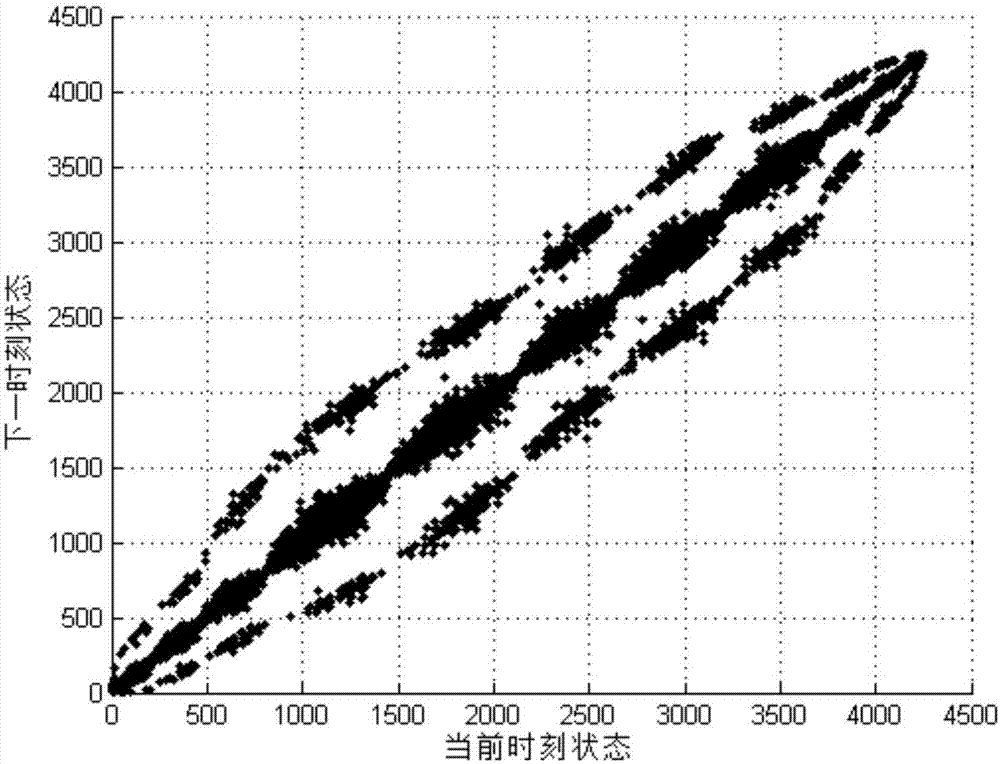
將三維空間狀態(mt,nt,pt)轉化為一維空間狀態st。其中,mt為速度的狀態,nt為加速度的狀態,pt為坡度的狀態,m為速度最大維數,h為加速度最大維數。然後,採用最大似然估計方法,統計三參數工況的狀態轉移概率矩陣p,參見圖2所示;
其中,pij為一維空間狀態si到一維空間狀態sj的轉移概率,nij為一維空間狀態si到一維空間狀態sj的轉移頻數,ni為一維空間狀態si到一維空間其他狀態的轉移頻數之和,s為一維空間狀態集合。
2)模擬馬爾科夫鏈隨機狀態序列x=(k0,k1,…,ki,…),i=n,其中n=1800
選取怠速狀態作為馬爾科夫鏈的初始狀態x(1)=k0,利用偽隨機數原則,在0和1之間取隨機數r1,選擇滿足
的狀態k1作為馬爾科夫鏈的下一狀態x(2)=k1,按照此模擬方法不斷重複,生成長度為1800s的工況狀態序列。選取終止狀態為怠速狀態的長度為1800s的序列作為工況狀態序列;依次生成多條起止為怠速狀態的工況狀態序列。
3)生成工況的初始種群
採用遺傳算法中的整數編碼方式,將馬爾科夫鏈隨機生成的狀態編碼為基因。將長度為1800s的工況狀態序列編碼為一條染色體,則多條染色體即多條工況狀態序列組成一個初始種群。初始種群大小設定為100。
階段二:目標函數設計
目標函數設計主要包括以下4個步驟:
1)選取工況中常用的特徵參數並設定允許偏差
選擇和速度、加速度和坡度有關的11個特徵參數,分別為怠速時間比例(%)、加速時間比例(%)、勻速行駛時間比例(%)、減速時間比例(%)、平均速度(km/h)、平均行駛速度(km/h)、行駛速度標準差(km/h)、pke(m/s3)、平均爬坡(%)、平均下坡(%)和va分布(velocityandaccelerationprobabilitydistribution)相關係數。允許偏差設定10%。
2)設計工況與原始資料庫的指標函數一致性表達
x為生成的設計工況,io為原始資料庫的特徵參數,id為設計工況的特徵參數,e為允許偏差。用公式(2)表達設計工況與原始資料庫的一致性
|ioi-idi|≤ei,(i=1,2,…,n),n=11(2)
3)利用公式(3)滿意準則模型的廣義形式
將公式(2)轉化為公式(4)
4)通過構造公式(5)輔助函數ti
把公式(4)多目標轉化為公式(6)單目標函數f
階段三:交叉算子設計
交叉算子設計主要包括以下三個步驟:
x(1)和x(2)為兩條時間序列的個體,n為個體的長度,p為由公式(7)計算得到的工況狀態轉移概率矩陣。
1)確定交叉位置
x(1)的兩個相鄰基因和與x(2)的兩個相鄰基因和滿足
時,i為x(1)的交叉位置,j為x(2)的交叉位置,且i不一定等於j。為到的轉移概率,為到的轉移概率。
2)確定交叉段
為保證x(1)和x(2)發生交叉後,生成的子代個體仍然滿足長度為n。兩個個體各自交叉位置之間的部分染色體長度必須相同。按照①確定另一組交叉位置i′和j′。其滿足
其中i′-i=j′-j,為到的轉移概率,為到的轉移概率。
3)實施交叉,生成子代個體
確定交叉位置以及交叉段後,交換x(1)中位置i到i』和x(2)中j到j』之間的部分染色體,最終生成兩個子代染色體。
每次執行隨機搜索交叉算子,需要設定循環次數k以得到較高的發生交叉的概率。其中循環次數k與發生交叉的概率的關係見圖3,循環次數k與平均用時的關係見圖4,並設定k為200。
階段四:變異算子設計
變異算子採用上述階段一2)中馬爾科夫鏈隨機模擬生成起止為怠速的長度為1800的工況狀態序列,並將其整數編碼為一條基因染色體作為變異個體。
階段五:代表性工況進化過程
設定迭代次數為100,進化初始種群至輸出最佳目標函數值0.1的工況狀態序列;然後經過解碼,生成三參數的時間序列,即代表性工況,包括速度、加速度和坡度時間序列,分別見圖5,圖6和圖7。