離群點的挖掘方法及挖掘裝置與流程
2023-05-16 00:24:06 3
本發明涉及數據處理技術領域,具體而言,涉及一種離群點的挖掘方法和一種離群點的挖掘裝置。
背景技術:
例外數據挖掘是數據挖掘中的一個重要研究內容,其目的是發現數據集中行為異常的少量數據對象。其中的例外即為離群點,所謂離群點是指在數據集中,常常存在一些數據對象,它們不符合數據的一般模型,因此稱這樣的數據對象為離群點。例外數據挖掘技術都需要對於異常情況做出快速而敏感的檢測,這些都為離群點的挖掘提供了潛在的應用背景。
離群點挖掘可以描述如下:對於給定的N個數據點或對象的集合,及預期的離群點的數目k,是指發現與剩餘的數據相比是有顯著異常的或不一致的前k個對象。近年來,基於數據挖掘思想的離群點挖掘研究取得了一系列重要的成果和挖掘方法,例如基於深度的方法、基於距離的方法和基於密度的方法。但是,現有的離群點挖掘算法均是對點集中的所有點進行檢測,以選擇出符合條件的點作為挖掘結果。
由於點集中點的數量較多,若對點集中的所有點均進行檢測以確定離群點,無疑會增加數量繁多的計算量,同時也會增加算法的運行時長。
因此,如何能夠在進行離群點的挖掘時,減少挖掘算法的計算量,以降低挖掘算法的運行時長成為亟待解決的技術問題。
技術實現要素:
本發明正是基於上述技術問題至少之一,提出了一種新的離群點的挖掘方案,可以有效減少在進行離群點挖掘時需要檢測的數據量,從而減少了挖掘算法的計算量,降低了挖掘算法的運行時長。
有鑑於此,本發明提出了一種離群點的挖掘方法,包括:將多維數據集劃分為多個網格單元,並確定所述多維數據集中的每個數據點所在的網格單元;根據所述多個網格單元中的每個網格單元內的數據點的個數,確定所述多個網格單元中的邊界單元;基於LOF(Local Outlier Factor,局部異常因子)算法對所述邊界單元中的數據點進行離群點的挖掘。
在該技術方案中,由於聚類的點集都有一定的邊界點,邊界點所處的範圍即邊界單元,而聚類的點通常是不可能成為離群點的,因此通過將多維數據集劃分為多個網格單元,以根據每個網格單元內的數據點的個數,確定多個網格單元中的邊界單元,進而採用LOF算法對所述邊界單元中的數據點進行離群點的挖掘,使得能夠在進行離群點挖掘時,先排除掉不可能成為離群點的範圍,即非邊界單元,然後僅對可能出現離群點的邊界單元進行離群點的挖掘,有效減少了在進行離群點挖掘時需要檢測的數據量,從而減少了挖掘算法的計算量,降低了挖掘算法的運行時長。
在上述技術方案中,優選地,所述將多維數據集劃分為多個網格單元的步驟具體包括:根據所述多維數據集中每一維數據集的相鄰數據點之間的平均距離,計算所述每一維數據集的劃分間隔值;基於所述每一維數據集的劃分間隔值將所述多維數據集劃分為多個網格單元。
在該技術方案中,通過根據每一維數據集的相鄰數據點之間的平均距離,計算每一維數據集的劃分間隔值,使得能夠將距離近的點分到一個網格單元中,同時又不會導致劃分間隔值取值過大而損失劃分精度的問題,也不會導致劃分間隔取值過小而產生較多的網格單元而增加離群點挖掘的計算量。
在上述任一技術方案中,優選地,根據所述多維數據集中每一維數據集的相鄰數據點之間的平均距離,計算所述每一維數據集的劃分間隔值的步驟具體包括:
將所述每一維數據集中的數據點進行排序,以確定所述每一維數據集的值域;計算所述每一維數據集中相鄰數據點之間的間隔值,並統計每個間隔值的個數;根據以下公式計算所述每一維數據集的劃分間隔值:
其中,si表示維標記,表示si維的網格劃分的間隔值,li表示在si維中具有不同間隔值的個數,每個間隔值及出現的次數分別為Invt、mt。
在上述任一技術方案中,優選地,確定所述多個網格單元中的邊界單元的步驟具體包括:通過哈希表存儲所述多個網格單元中的非空網格單元的信息;根據所述非空網格單元的相鄰單元內的數據點的數量,確定所述多個網格單元中的邊界單元。
在該技術方案中,通過採用哈希表形式的數據結構來存儲網格單元信息,可以有效減少遍歷和查詢的時間,從而減少算法的執行時間。通過只記錄有數據點的非空網格單元,可以防止當維數增加時網格單元數量呈指數增加而導致存儲量增加的問題。其中,對於每個非空網格單元,如果其相鄰單元含有少於預定數量的點,則這個單元稱為邊界單元。
在上述任一技術方案中,優選地,基於LOF算法對所述邊界單元中的數據點進行離群點的挖掘的步驟具體包括:基於所述LOF算法計算所述邊界單元中的每個數據點的LOF值;按照LOF值從大到小的順序,取出所述邊界單元中預定個數的數據點作為挖掘出的所述離群點。
根據本發明的另一方面,還提出了一種離群點的挖掘裝置,包括:劃分單元,用於將多維數據集劃分為多個網格單元,並確定所述多維數據集中的每個數據點所在的網格單元;確定單元,用於根據所述多個網格單元中的每個網格單元內的數據點的個數,確定所述多個網格單元中的邊界單元;處理單元,用於基於LOF算法對所述邊界單元中的數據點進行離群點的挖掘。
在該技術方案中,由於聚類的點集都有一定的邊界點,邊界點所處的範圍即邊界單元,而聚類的點通常是不可能成為離群點的,因此通過將多維數據集劃分為多個網格單元,以根據每個網格單元內的數據點的個數,確定多個網格單元中的邊界單元,進而採用LOF算法對所述邊界單元中的數據點進行離群點的挖掘,使得能夠在進行離群點挖掘時,先排除掉不 可能成為離群點的範圍,即非邊界單元,然後僅對可能出現離群點的邊界單元進行離群點的挖掘,有效減少了在進行離群點挖掘時需要檢測的數據量,從而減少了挖掘算法的計算量,降低了挖掘算法的運行時長。
在上述技術方案中,優選地,所述劃分單元包括:第一計算單元,用於根據所述多維數據集中每一維數據集的相鄰數據點之間的平均距離,計算所述每一維數據集的劃分間隔值;執行單元,用於基於所述每一維數據集的劃分間隔值將所述多維數據集劃分為多個網格單元。
在該技術方案中,通過根據每一維數據集的相鄰數據點之間的平均距離,計算每一維數據集的劃分間隔值,使得能夠將距離近的點分到一個網格單元中,同時又不會導致劃分間隔值取值過大而損失劃分精度的問題,也不會導致劃分間隔取值過小而產生較多的網格單元而增加離群點挖掘的計算量。
在上述任一技術方案中,優選地,所述第一計算單元具體用於:將所述每一維數據集中的數據點進行排序,以確定所述每一維數據集的值域;計算所述每一維數據集中相鄰數據點之間的間隔值,並統計每個間隔值的個數;根據以下公式計算所述每一維數據集的劃分間隔值:
其中,si表示維標記,表示si維的網格劃分的間隔值,li表示在si維中具有不同間隔值的個數,每個間隔值及出現的次數分別為Invt、mt。
在上述任一技術方案中,優選地,所述確定單元具體用於:通過哈希表存儲所述多個網格單元中的非空網格單元的信息,並根據所述非空網格單元的相鄰單元內的數據點的數量,確定所述多個網格單元中的邊界單元。
在該技術方案中,通過採用哈希表形式的數據結構來存儲網格單元信息,可以有效減少遍歷和查詢的時間,從而減少算法的執行時間。通過只記錄有數據點的非空網格單元,可以防止當維數增加時網格單元數量呈指數增加而導致存儲量增加的問題。其中,對於每個非空網格單元,如果其 相鄰單元含有少於預定數量的點,則這個單元稱為邊界單元。
在上述任一技術方案中,優選地,所述處理單元包括:第二計算單元,用於基於所述LOF算法計算所述邊界單元中的每個數據點的LOF值;選取單元,用於按照LOF值從大到小的順序,取出所述邊界單元中預定個數的數據點作為挖掘出的所述離群點。
通過以上技術方案,可以有效減少在進行離群點挖掘時需要檢測的數據量,從而減少了挖掘算法的計算量,降低了挖掘算法的運行時長;並且在劃分網格單元時能夠選擇到合適的劃分間隔值,以將距離近的點分到一個網格單元中,同時又不會導致劃分間隔值取值過大而損失劃分精度的問題,也不會導致劃分間隔取值過小而產生較多的網格單元而增加離群點挖掘的計算量。
附圖說明
圖1示出了根據本發明的一個實施例的離群點的挖掘方法的示意流程圖;
圖2示出了根據本發明的實施例的離群點的挖掘裝置的示意框圖;
圖3示出了根據本發明的另一個實施例的離群點的挖掘方法的示意流程圖。
具體實施方式
為了能夠更清楚地理解本發明的上述目的、特徵和優點,下面結合附圖和具體實施方式對本發明進行進一步的詳細描述。需要說明的是,在不衝突的情況下,本申請的實施例及實施例中的特徵可以相互組合。
在下面的描述中闡述了很多具體細節以便於充分理解本發明,但是,本發明還可以採用其他不同於在此描述的其他方式來實施,因此,本發明的保護範圍並不受下面公開的具體實施例的限制。
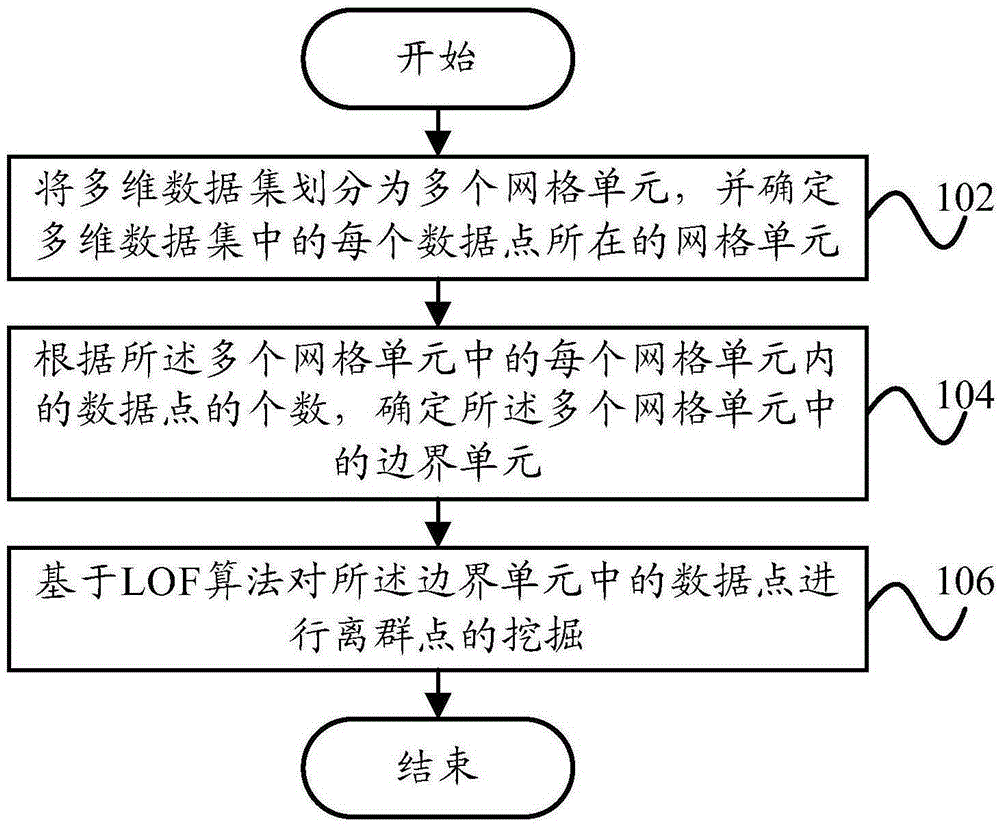
圖1示出了根據本發明的一個實施例的離群點的挖掘方法的示意流程圖。
如圖1所示,根據本發明的一個實施例的離群點的挖掘方法,包括:
步驟102,將多維數據集劃分為多個網格單元,並確定所述多維數據集中的每個數據點所在的網格單元;
步驟104,根據所述多個網格單元中的每個網格單元內的數據點的個數,確定所述多個網格單元中的邊界單元;
步驟106,基於LOF算法對所述邊界單元中的數據點進行離群點的挖掘。
在該技術方案中,由於聚類的點集都有一定的邊界點,邊界點所處的範圍即邊界單元,而聚類的點通常是不可能成為離群點的,因此通過將多維數據集劃分為多個網格單元,以根據每個網格單元內的數據點的個數,確定多個網格單元中的邊界單元,進而採用LOF算法對所述邊界單元中的數據點進行離群點的挖掘,使得能夠在進行離群點挖掘時,先排除掉不可能成為離群點的範圍,即非邊界單元,然後僅對可能出現離群點的邊界單元進行離群點的挖掘,有效減少了在進行離群點挖掘時需要檢測的數據量,從而減少了挖掘算法的計算量,降低了挖掘算法的運行時長。
在上述技術方案中,優選地,所述將多維數據集劃分為多個網格單元的步驟具體包括:根據所述多維數據集中每一維數據集的相鄰數據點之間的平均距離,計算所述每一維數據集的劃分間隔值;基於所述每一維數據集的劃分間隔值將所述多維數據集劃分為多個網格單元。
在該技術方案中,通過根據每一維數據集的相鄰數據點之間的平均距離,計算每一維數據集的劃分間隔值,使得能夠將距離近的點分到一個網格單元中,同時又不會導致劃分間隔值取值過大而損失劃分精度的問題,也不會導致劃分間隔取值過小而產生較多的網格單元而增加離群點挖掘的計算量。
在上述任一技術方案中,優選地,根據所述多維數據集中每一維數據集的相鄰數據點之間的平均距離,計算所述每一維數據集的劃分間隔值的步驟具體包括:
將所述每一維數據集中的數據點進行排序,以確定所述每一維數據集的值域;計算所述每一維數據集中相鄰數據點之間的間隔值,並統計每個間隔值的個數;根據以下公式計算所述每一維數據集的劃分間隔值:
其中,si表示維標記,表示si維的網格劃分的間隔值,li表示在si維中具有不同間隔值的個數,每個間隔值及出現的次數分別為Invt、mt。
在上述任一技術方案中,優選地,確定所述多個網格單元中的邊界單元的步驟具體包括:通過哈希表存儲所述多個網格單元中的非空網格單元的信息;根據所述非空網格單元的相鄰單元內的數據點的數量,確定所述多個網格單元中的邊界單元。
在該技術方案中,通過採用哈希表形式的數據結構來存儲網格單元信息,可以有效減少遍歷和查詢的時間,從而減少算法的執行時間。通過只記錄有數據點的非空網格單元,可以防止當維數增加時網格單元數量呈指數增加而導致存儲量增加的問題。其中,對於每個非空網格單元,如果其相鄰單元含有少於預定數量的點,則這個單元稱為邊界單元。
在上述任一技術方案中,優選地,基於LOF算法對所述邊界單元中的數據點進行離群點的挖掘的步驟具體包括:基於所述LOF算法計算所述邊界單元中的每個數據點的LOF值;按照LOF值從大到小的順序,取出所述邊界單元中預定個數的數據點作為挖掘出的所述離群點。
圖2示出了根據本發明的實施例的離群點的挖掘裝置的示意框圖。
如圖2所示,根據本發明的實施例的離群點的挖掘裝置200,包括:
劃分單元202,用於將多維數據集劃分為多個網格單元,並確定所述多維數據集中的每個數據點所在的網格單元;確定單元204,用於根據所述多個網格單元中的每個網格單元內的數據點的個數,確定所述多個網格單元中的邊界單元;處理單元206,用於基於LOF算法對所述邊界單元中的數據點進行離群點的挖掘。
在該技術方案中,由於聚類的點集都有一定的邊界點,邊界點所處的範圍即邊界單元,而聚類的點通常是不可能成為離群點的,因此通過將多維數據集劃分為多個網格單元,以根據每個網格單元內的數據點的個數,確定多個網格單元中的邊界單元,進而採用LOF算法對所述邊界單元中 的數據點進行離群點的挖掘,使得能夠在進行離群點挖掘時,先排除掉不可能成為離群點的範圍,即非邊界單元,然後僅對可能出現離群點的邊界單元進行離群點的挖掘,有效減少了在進行離群點挖掘時需要檢測的數據量,從而減少了挖掘算法的計算量,降低了挖掘算法的運行時長。
在上述技術方案中,優選地,所述劃分單元202包括:第一計算單元2022,用於根據所述多維數據集中每一維數據集的相鄰數據點之間的平均距離,計算所述每一維數據集的劃分間隔值;執行單元2024,用於基於所述每一維數據集的劃分間隔值將所述多維數據集劃分為多個網格單元。
在該技術方案中,通過根據每一維數據集的相鄰數據點之間的平均距離,計算每一維數據集的劃分間隔值,使得能夠將距離近的點分到一個網格單元中,同時又不會導致劃分間隔值取值過大而損失劃分精度的問題,也不會導致劃分間隔取值過小而產生較多的網格單元而增加離群點挖掘的計算量。
在上述任一技術方案中,優選地,所述第一計算單元2022具體用於:將所述每一維數據集中的數據點進行排序,以確定所述每一維數據集的值域;計算所述每一維數據集中相鄰數據點之間的間隔值,並統計每個間隔值的個數;根據以下公式計算所述每一維數據集的劃分間隔值:
其中,si表示維標記,表示si維的網格劃分的間隔值,li表示在si維中具有不同間隔值的個數,每個間隔值及出現的次數分別為Invt、mt。
在上述任一技術方案中,優選地,所述確定單元204具體用於:通過哈希表存儲所述多個網格單元中的非空網格單元的信息,並根據所述非空網格單元的相鄰單元內的數據點的數量,確定所述多個網格單元中的邊界單元。
在該技術方案中,通過採用哈希表形式的數據結構來存儲網格單元信息,可以有效減少遍歷和查詢的時間,從而減少算法的執行時間。通過只記錄有數據點的非空網格單元,可以防止當維數增加時網格單元數量呈指 數增加而導致存儲量增加的問題。其中,對於每個非空網格單元,如果其相鄰單元含有少於預定數量的點,則這個單元稱為邊界單元。
在上述任一技術方案中,優選地,所述處理單元206包括:第二計算單元2062,用於基於所述LOF算法計算所述邊界單元中的每個數據點的LOF值;選取單元2064,用於按照LOF值從大到小的順序,取出所述邊界單元中預定個數的數據點作為挖掘出的所述離群點。
綜上,本發明主要提出了一種基於網格聚類技術的離群點挖掘算法,該算法將離群點挖掘算法分成兩步挖掘過程:
1)先用基於網格的聚類方法刪除不可能成為離群點的點集,這一步稱之為挖掘前的數據準備;
2)採用LOF算法來對第1步篩選所剩下的點集進行離群點的挖掘。
本發明提出的基於網格聚類技術的離群點挖掘算法的優點是:
A、由於該算法首先採用聚類方法把非離群點集篩選出來刪除掉,然後再對剩下的可能成為離群點的點集做進一步考察,這樣一方面可以減少大部分不必要的計算,節省算法的運行時間,另一方面,避免了算法第2步在使用LOF方法判斷離群點時,對參數選擇要求高的不足;
B、該算法對相鄰單元的定義和網格的劃分加以改進,能更合理有效地對網格進行劃分,且能根據數據信息自動生成劃分間隔參數,體現了算法在性能上的改進;
C、該算法適用於處理大數據集和高維數據集。
具體地,以下詳細說明本發明的技術方案。
一個具有d個屬性的資料庫可認為是一個具有d維數據空間的數據集,因此資料庫中的每一條數據記錄與數據空間中的一個點相對應。本發明中的聚類算法採用的是基於網格的聚類方法,該方法將數據空間分割成網格狀,這樣將數據空間量化為有限數目的大小相同的網格單元,這些網格單元可簡稱為單元。因此,數據集中的每個數據點都有表示它們各維的數值,從而各數據點分屬於相應的網格單元,這樣所需進行的聚類操作可在網格上進行。在網格上進行聚類操作的關鍵技術主要包括確定聚類區域、網格的劃分技術和存儲技術。
1、確定聚類區域
由於本發明採用基於密度的算法,因此聚類的定義就是:聚類就是一個區域,滿足該區域中的點的密度大於與之相鄰的區域。在網格數據結構中,由於每個網格單元都有相同的體積,因此單元中數據點密度的計算可以轉換成簡單的數據點計數,即落到某個單元中點的個數當成這個單元的密度。這時可以指定一個數值δ,當某單元中點的個數大於該數值時,就說這個單元是密集的。最後,聚類也就定義為連通的所有的「密的」單元的集合。給定一個d維數據空間D,D中每維間隔數分別為k1,k2,…,kd,即第i維被劃分成ki等分(1≤i≤d)。一個網格單元cell可由一個d維數組表示,即cell=C[s1][s2]…[sd],其中si(1≤i≤d)標記維ID,表示第i維的第si個網格,si的取值在0和ki-1之間。
定義1:對於一個給定的網格單元cell=C[i1][i2]…[id],Ncell(cell)是其相鄰單元的集合,則:Ncell(cell)={NC[j1][j2]…[jd]|jp=ip±1},其中:1≤p≤d。
由定義1可知,在d維數據空間中,一個單元有3d-1個相鄰單元。
定義2:單元cell1=C1[i1][i2]…[id]與單元cell2=C2[j1][j2]…[jd]是相鄰的,當以下條件被滿足:|ip-jp|=1,p=v(1≤v≤d)ip=jp,p=1,2,…,v-1,v+1,…,d。
根據以上定義,d維數據空間中一個單元有2d個相鄰單元。由此,不僅參與計算的單元數目大為減少,而且單元增加與維數的關係由指數增長變為線性增長,所以能進一步減少算法運行所需的時間。
定義3:對於每個非空網格單元(含有數據點的單元),如果其相鄰單元為空或含有少於閾值δ的點,則這個單元稱為邊界單元,否則稱為非邊界單元。
每個聚類的點集一定有邊界點,這樣可以根據所求到的邊界單元求出聚類點的大致範圍,在這個範圍內的點稱為聚類點,它們是不可能成為離群點的,為此必須將這些聚類點刪除。這種方法的主要優點是速度快,其處理時間獨立於數據點的數目,僅依賴於量化空間中每一維上的網格單元數目。
2、網格的劃分
網格的劃分與劃分間隔大小的選擇直接影響著算法的正確性與算法的執行效率。如果間隔w選擇過大,則會導致一個含有離群點的網格單元的相鄰單元都不為空,該單元作為非空單元被刪除,其離群點不能被檢測到,從而引起有用數據的丟失;如果w選擇過小,則較稀疏的聚類點難以被刪除,這樣就會增加後面LOF的計算工作。因此,如何選擇一個好的方法來合理地劃分每一維是算法的關鍵所在,也是研究的重點。
劃分間隔最簡單的一種做法就是每個維度都劃分為相同的間隔。如數據集共有d維,每維取m個間隔,則網格單元總數就是m×d。這種劃分方法主要有兩點不足:(1)劃分的單元數隨維數呈指數增長,不適用於高維空間的劃分;(2)在劃分中也難以給m選定一個合適的值,因為m的一個微小變化都會引起單元數目的急劇波動。為了解決這個問題,本發明提出的劃分間隔的具體做法是:(1)各維劃分間隔的設定是獨立的,即每一維劃分的間隔是不同的;(2)在對其中每一維劃分時,以各相鄰數據點之間的距離分布規律為依據來確定劃分間隔。首先把每一維數據單獨取出、排序,計算相鄰兩點之間的距離,然後選擇合理單維分布公式計算出的距離作為劃分間隔。根據這種方法所計算出的劃分間隔的優點是:能較好地把距離近的點分到一起,而又不會取值過大而損失劃分精度,或過小產生多餘的單元而增加計算量。而且在每維的間隔相差較大的情況下,可以減少參與計算的網格單元數目。
3、存儲結構
在確定各維劃分的間隔後,可確定出各數據點所屬的網格單元位置。為了節省存儲空間,提高算法性能並加快算法的速度,本發明在存儲網格結構時,一是只記錄有數據點的非空網格單元,這樣就防止當維數增加時網格單元數量呈指數增加;二是採用Hash表(哈希表)形式的數據結構來存儲網格單元信息,它可以有效減少遍歷和查詢時間,從而減少算法的執行時間。
Hash表的結構如表1所示:
表1
如表1所示,count1表示在該位置衝突的網格單元數;flag為網格單元標記,指出該單元是否為邊界單元;count2表示該單元含有的數據點數;cellinfo表示網格單元的維數信息(在數據空間的位置);conflictcell表示當單元衝突時,指向下一個衝突單元的位置。
以下介紹本發明提出的關於離群點的數據挖掘和基於網格聚類技術的離群點挖掘算法:
1、離群點定義和數據集特徵分析
儘管不同的離群點檢測方法對於離群點的定義存在一定的差別,但Hawkins給出的形式化定義被研究者廣泛接受。
定義1:如果一個數據樣本與其它樣本之間存在足以引起懷疑的差異,則稱其為離群點。
雖然Hawkins的定義形象地描述了離群點的特徵,但卻沒有給出任何用於發現離群點的實現途徑。為此,本發明引用Knorr等人基於距離的離群點的定義如下∶
定義2:給定數據集D和閾值ξ,σ,稱樣本q∈D為離群點,如果存在至多ξ個樣本位於q的σ距離之內。
根據上述定義,Knorr等構造了基於距離的離群點發現算法FindAllOutsM和FindAllOutsD,它們分別用於對可駐留內存的和基於內外存交換的數據集的離群點分析。儘管Knorr等聲稱其算法具有相對於數據量的線性時間複雜度,然而對大規模數據集卻需要三次內外存交換和過濾。顯然,該算法無法取得令人滿意的效果。
構造高效的離群點檢測方法必須深入研究數據集本身的分布特徵。其中,數據集的主體聚類性和離群點個別屬性差異性可被用來有效提高離群 點的檢測效率。主體聚類性是指數據集的主體數據來自於對正常數據源的採樣,相對於離群點而言,這些數據具有明顯的聚類特徵,即大量數據密集分布於較小的空間範圍內。因此,在進行離群點檢測時,對於分布於稠密區域的數據的過濾處理將不會影響離群點的檢測效果。
其次,離群點是相對於正常的數據樣本而言的。通常地,它們分布於正常數據樣本的周圍或構成遠離數據主體的低密度聚類。然而,離群點並非在所有的屬性上與正常數據樣本存在明顯的差異。例如,在研究信用卡使用記錄數據集的眾多屬性時,惡意透支者的大部分屬性與正常消費者不存在明顯差異,其異常行為模式僅體現在個別的屬性欄位。因此,在採用基於距離的離群點檢測時,採用通常的歐氏距離考慮離群點相對於正常樣本點的全局差異不具有實際意義。為此,本發明在數據集的屬性域空間內引入距離,它使離群點檢測更加關注於數據樣本在個別屬性上的差異性。
定義3:點p的局部異常因子(LOF):LOF用來表徵數據集中每個數據對象的異常程度,並且這種異常是局部的,即與所求數據對象一定範圍內的鄰居的分布有關。
點p的LOF值定義為如下數學表達式:
其中,LOF是p的MinPts鄰近點的鄰近密度和p的鄰近密度比值的平均值,p的鄰近密度越低,p的LOF值越高。顯然,LOF值越高的點就是孤立點,這對於準確查找孤立點指定了相對明確的標準。
2、基於網格聚類技術的離群點挖掘算法
2.1、算法思想
首先用基於網格的聚類方法將空間劃分成為不同的網格單元,並確定各數據點所在的網格單元,根據統計每個網格單元相鄰單元中所含有的數據點數,確定該單元是否為邊界單元,進一步刪除非邊界單元,即刪除非邊界單元中不可能成為離群點的點集,這一步稱之為挖掘前的數據準備,減小了下一步對數據點LOF值的計算量,提高算法的運行時間;然後採用LOF算法來對第1步篩選所剩下的點集進行離群點的挖掘。
2.2、算法步驟
基於網格聚類技術的離群點挖掘算法主要由以下兩個步驟組成:
第1步:採用基於網格聚類技術找出大部分聚類數據,並將其刪除。
(1)劃分數據空間
第1遍掃描數據集,以各相鄰數據點之間的距離分布規律,具體地說是以各相鄰數據點之間的平均距離為依據來確定每一維的等分劃分的間隔。對每一維數據劃分間隔的過程如下:
1)將各數據點排序,確定每維的值域。
2)求各相鄰數據點之間的間隔值,並記下每個間隔值和它們出現的次數。
3)按下面的公式計算得到的值四捨五入作為該維網格單元劃分的間隔值:
其中,si表示維標記,Wsi表示該維網格劃分的間隔值,li表示在si中具有不同間隔值的個數,其中每個間隔的間隔值及出現的相應次數分別為Invt、mt。
(2)建立Hash表(如表1所示)
第2遍掃描數據集,將每個數據點所在的網格信息記錄到Hash表H中。在記錄每個點時,首先計算出該點所在的網格單元,然後通過哈希函數將對應的網格單元散列(映射)到表H中。如果在表H中沒有該點所在網格單元記錄,則把該單元的相關信息(如cellinfo,conflictcell)加入到H中,並對相應的count1,count2進行計數操作;如果該點所在網格單元已經記錄在H中,則僅對相應的count2進行計數操作。
(3)對H表中每個網格單元檢查它的相鄰單元,判斷是否為邊界單元,並對非邊界單元做出標記。當全部網格單元判斷結束後,刪除所有非邊界單元。在H表中刪除所有非邊界單元後,可通過H表中cellinfo等信息從數據集中取出剩下的數據點集。
第2步:對篩選後剩下的點集,採用LOF算法計算它們的LOF值, 然後取出值高的前k個數據點作為離群點挖掘結果。
以上過程如圖3所示,根據本發明的另一個實施例的離群點的挖掘方法,包括:
步驟302,載入數據。
步驟304,對每一維數據進行排序,確定劃分間隔。
步驟306,掃描數據集,計算每一個點所在的網格單元。
步驟308,判斷是否為邊界單元,若是,則執行步驟312;否則,執行步驟310。
步驟310,刪除非邊界單元。
步驟312,獲得剩下的點信息。
步驟314,計算剩下點的LOF值。
步驟316,輸出LOF值較高的k個點作為離群點挖掘結果。
2.3、算法實現主要部分的偽代碼
本發明提出的基於網格聚類技術的離群點挖掘算法的優點如下:
1)由於該算法首先採用聚類方法把非離群點集篩選出來刪除掉,然後再對剩下的可能成為離群點的點集做進一步考察,這樣一方面可以減少大部分不必要的計算,節省算法的運行時間,另一方面,避免了算法第2步在使用LOF方法判斷離群點時,對參數選擇要求高的不足。
2)該算法對相鄰單元的定義和網格的劃分加以改進,能更合理有效地對網格進行劃分,且能根據數據信息自動生成劃分間隔參數,體現了算法在性能上的改進。
3)該算法適用於處理大數據集和高維數據集。
4)為了快速判斷是否為邊界單元和算法執行效率,一是採用Hash表來存儲網格結構信息,以提高查找相鄰單元的速度;二是基於網格聚類 技術的離群點挖掘算法是以各相鄰數據點之間的距離分布規律為依據來確定數據空間劃分間隔的,與其它數據空間劃分的方法相比,既能使劃分所得的網格大小較為適合算法的執行,又能使所產生的網格單元數目少,這樣也就減少了算法的執行時間。
以上結合附圖詳細說明了本發明的技術方案,本發明提出了一種新的離群點的挖掘方案,可以有效減少在進行離群點挖掘時需要檢測的數據量,從而減少了挖掘算法的計算量,降低了挖掘算法的運行時長;並且在劃分網格單元時能夠選擇到合適的劃分間隔值,以將距離近的點分到一個網格單元中,同時又不會導致劃分間隔值取值過大而損失劃分精度的問題,也不會導致劃分間隔取值過小而產生較多的網格單元而增加離群點挖掘的計算量。
以上所述僅為本發明的優選實施例而已,並不用於限制本發明,對於本領域的技術人員來說,本發明可以有各種更改和變化。凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。