一種多副本存儲快速校驗一致性方法及其裝置與流程
2023-05-15 08:31:46 2
本發明涉及分布式數據存儲和數據校驗技術領域,尤其涉及多副本存儲快速校驗一致性方法及其裝置。
背景技術:
現有的分布式存儲系統中,絕大多數是通過多副本技術來提升系統可靠性、可用性、性能以及可擴展性。
多副本技術可以保證分布式存儲系統中個別主機和磁碟發生故障時,系統還能提供正常的讀寫服務,提高系統的可靠性,多個副本可以用於分流和加快響應時間。但分布式存儲系統都是通過網絡通信,網絡的不穩定性容易造成後端數據不一致,並且分布式存儲系統一般包含較多的伺服器主機和磁碟數量,硬體損壞的概率也比較高。如果不能快速檢測副本的一致性,分布式存儲系統的數據完整性和高可用性就大大降低。
現有校驗一致性方法主要是計算文件的哈希值,並對比多個副本文件的哈希值是否一致來判斷文件是否數據一致。但如果對於大型文件,計算哈希值將消耗大量的cpu和磁碟帶寬,嚴重影響系統的性能。文件不一致的位置往往比較少,但計算文件哈希值需要讀取整個文件的內容,造成巨大資源的浪費。
技術實現要素:
為解決以上問題,本發明提供了一種基於稀疏文件的快速文件哈希計算方法和基於快照技術的多副本一致性快速檢測方法。
本發明提供了一種多副本存儲快速校驗一致性方法,包含以下步驟:
s1:在系統處於空閒狀態時,判斷head文件的數據寫入量,當head文件的數據寫入量達到整個稀疏文件的30%以上時,採用i/o重定向技術創建一次快照文件,繼續寫入數據的新的head文件作為空白對照的稀疏文件,計算快照文件的哈希值,把哈希值作為快照文件的擴展屬性保存起來;
s2:每隔預定時間對head文件進行一次快照操作,如果發生異常情況,需要及時驗證數據的一致性時,只需計算新的head文件的哈希值,並將新的head文件的哈希值與快照文件的哈希值對比,以此校驗多副本存儲時數據的一致性。
優選地,所述方法還包括:
s3:對多個快照文件進行合併,並重新計算合併後的快照文件的哈希值,把哈希值作為合併後的快照文件的擴展屬性保存起來。
優選地,所述存儲組件包括head文件和對應的快照文件,head文件和快照文件都是大小相等的稀疏文件。
優選地,所述哈希值計算方法包括以下步驟:
ss1,利用lseek函數調用,獲取整個head文件數據段信息;
ss2,把每個數據塊的偏移量和數據長度結合起來作為head文件信息和head文件數據一起作為哈希函數的輸入,輸出得到head文件的哈希值。
優選地,所述存儲組件的讀寫方法包括:
寫i/o寫入到head文件,讀i/o先判斷head文件是否存在數據,如果存在,進入s01,如果不存在,進入s02,直至讀到數據或者到最底層快照文件;
s01,讀取數據並返回,
s02,判斷下一級快照文件是否存在數據;
優選地,創建稀疏文件時,文件索引節點記錄head文件的大小,沒有數據寫入時不給head文件分配磁碟空間,當有數據寫入時才給head文件分配磁碟空間。
優選地,所述快照方法採用i/o重定向方法。
本發明還提供了一種多副本存儲快速校驗一致性裝置,包括控制主機和存儲主機,所述控制主機生成虛擬磁碟,作為存儲數據路徑的前端主機,完成數據接收、轉發功能;存儲主機作為數據最終的存放地點,將存儲資源抽象成多個由稀疏文件鏈組成存儲組件。
本發明提供一種多副本存儲快速校驗一致性方法,結合分布式塊存儲的特點,提出了一種基於快照技術的多副本一致性快速檢測方法,哈希值計算的任務分成多個時間段進行,在系統比較空閒的時候計算文件的哈希值,避免影響系統正常的讀寫業務。
附圖說明
下面結合附圖,通過對本發明的具體實施方式詳細描述,將使本發明的技術方案及其它有益效果顯而易見。
圖1為一種多副本存儲快速校驗一致性方法流程圖;
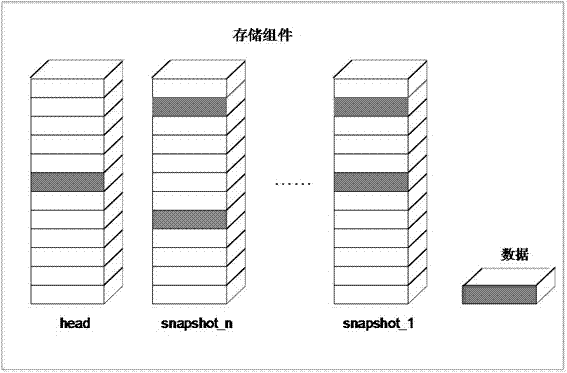
圖2為存儲組件結構示意圖;
圖3為哈希值計算方法方框圖;
圖4為儲存組件讀寫方法方框圖;
圖5為一種多副本存儲快速校驗一致性裝置方框圖。
具體實施方式
為更進一步闡述本發明所採取的技術手段及其效果,以下結合本發明的優選實施例及其附圖進行詳細描述。
為解決以上問題,本發明提供了一種基於稀疏文件的快速文件哈希計算方法和基於快照技術的多副本一致性快速檢測方法。
請參考圖1,本發明提供了一種多副本存儲快速校驗一致性方法,包含以下步驟:
s1:在系統處於空閒狀態時,判斷head文件的數據寫入量,當head文件的數據寫入量達到整個稀疏文件的30%以上時,採用i/o重定向技術創建一次快照文件,繼續寫入數據的新的head文件作為空白對照的稀疏文件,計算快照文件的哈希值,把哈希值作為快照文件的擴展屬性保存起來;
s2:每隔預定時間對head文件進行一次快照操作,如果發生異常情況,需要及時驗證數據的一致性時,只需計算新的head文件的哈希值,並將新的head文件的哈希值與快照文件的哈希值對比,以此校驗多副本存儲時數據的一致性。
如果發生異常情況,需要及時驗證數據的一致性,只需計算head文件的哈希值,此時雖然前段還有寫i/o造成的head文件修改,由於在進行副本一致性判斷之間,由於是採用i/o重定向技術對數據進行了一次快照操作創建了快照文件,所有寫i/o操作都會寫入head文件中,快照文件不會被寫i/o修改,在進行文件一致性判斷的過程中,前端虛擬塊設備不用暫停讀寫i/o的操作。
本發明提供一種多副本存儲快速校驗一致性方法,結合分布式塊存儲的特點,提出了一種基於快照技術的多副本一致性快速檢測方法,哈希值計算的任務分成多個時間段進行,在系統比較空閒的時候計算文件的哈希值,避免影響系統正常的讀寫業務。
優選地,所述方法還包括:
s3:對多個快照文件進行合併,以在快照文件過多、系統負載比較低時,減少文件數量和磁碟空間的使用量,降低磁碟帶寬消耗,並重新計算合併後的快照文件的哈希值,把哈希值作為合併後的快照文件的擴展屬性保存起來。
其中,所述存儲組件包括head文件和對應的快照文件,head文件和快照文件都是大小相等的稀疏文件。為本發明存儲組件結構圖。如圖2所示,為本發明存儲組件結構圖。存儲組件包括head文件和對應的快照文件,head文件和快照文件都是大小相等的稀疏文件。稀疏文件的大小就是存儲組件的大小,在創建虛擬磁碟時就指定了存儲組件的大小,大小為1g-128g。
請參考圖3,優選地,所述哈希值計算方法包括以下步驟:
ss1,利用lseek函數調用,獲取整個head文件數據段信息;
ss2,把每個數據塊的偏移量和數據長度結合起來作為head文件信息和head文件數據一起作為哈希函數的輸入,輸出得到head文件的哈希值。避免計算head文件空洞部分的哈希值,大大加快head文件的哈希值的計算速度,提高一致性檢測速度。
請參考圖4,優選地,所述存儲組件的讀寫方法包括:
寫i/o寫入到head文件,讀i/o先判斷head文件是否存在數據,如果存在,進入s01,如果不存在,進入s02,直至讀到數據或者到最底層快照文件;
s01,讀取數據並返回,
s02,判斷下一級快照文件是否存在數據;
優選地,創建稀疏文件時,文件索引節點記錄head文件的大小,沒有數據寫入時不給head文件分配磁碟空間,當有數據寫入時才給head文件分配磁碟空間。
請參考圖5,本發明還提供了一種多副本存儲快速校驗一致性裝置,包括控制主機和存儲主機,所述控制主機生成虛擬磁碟,作為存儲數據路徑的前端主機,完成數據接收、轉發功能;存儲主機作為數據最終的存放地點,將存儲資源抽象成多個由稀疏文件鏈組成存儲組件。
本發明提出一種高速度,低磁碟帶寬消耗的多副本存儲快速校驗一致性方法,使用一種改進的計算稀疏文件哈希值的方法來校驗副本之間的一致性,並基於快照技術把一個組件的數據分成多個快照文件存儲。可以在系統空閒的時候計算快照文件的哈希值,充分利用系統的資源。當需要校驗多個副本的一致性時,只需校驗head文件,由於head文件的數據量比較小,所以可以及時計算出文件的哈希值,並且消耗很低的磁碟帶寬,對集群資源消耗低,避免影響系統正常的讀寫業務,大大降低了對集群業務的影響。
以上所述,對於本領域的普通技術人員來說,可以根據本發明的技術方案和技術構思作出其他各種相應的改變和變形,而所有這些改變和變形都應屬於本發明權利要求的保護範圍。