一種過濾垃圾消息的方法及系統與流程
2023-05-08 12:14:11 5
本發明屬於終端領域,具體地說,涉及一種過濾垃圾消息的方法及系統。
背景技術:
現有技術 隨著網際網路的發展壯大,各個網站(包括門戶網站、專題網站等)推出了越來越多的社區頻道,如:各類專題論壇、博客、評論等,這些社區頻道吸引的互動網友日益增多,為網站及網民帶來了利益。但同時也有一些人員借這些社區頻道大肆發布各類商業廣告信息,甚至發布大量的色情、低俗、粗口及與其他同行惡意競爭的帖子,這些不良信息幹擾了網站的正常運營,損害了網站的品牌和口碑,同時也極大地影響了其它網民的正常使用。
目前,智慧型手機的屏幕上方通常會顯示有一個消息通知欄,用於以小圖標的形式向用戶顯示通知消息。手機允許系統或第三方應用向通知欄推送通知消息,用戶對通知欄進行下拉操作可以展開查看通知消息的具體內容,例如包括手機系統推送的當前電量、信號強度等通知消息,也包括第三方應用推送的未讀消息提醒等通知消息。用戶在使用終端設備時經常會收到各種通知消息,例如系統更新提示消息,以及APP(應用程式)的消息,例如QQ消息、微信消息、網銀相關消息等。
但是這些消息中有很多是用戶不需要的垃圾消息,將這些消息全部推送給用戶就會對用戶造成打擾,因此,需要一種新的技術方案,能夠將終端上推送的消息通知經過本地和雲端雙重判斷後確定出有用消息並推送給用戶。
有鑑於此特提出本發明。
技術實現要素:
本發明要解決的技術問題在於克服現有技術的不足,提供一種過濾垃圾消息的方法及系統,能夠將終端上推送的消息經過本地和雲端雙重判斷後確定出有用消息並推送給用戶。
為解決上述技術問題,本發明採用技術方案的基本構思是:
本發明的第一方面提出了一種過濾垃圾消息的方法,應用於終端,步驟包括:
S1,接收消息,提取消息中的文字信息,並對所述文字信息進行分詞處理獲取分詞集合;
S2,將所述分詞集合進行本地判斷,當判斷所述消息為垃圾消息時進行過濾,否則進入步驟S3;
S3,將所述分詞集合進行雲端判斷,當判定所述消息為垃圾消息時進行過濾,否則進行顯示。
優選地,所述分詞集合的獲取方法為:
S11,將被分詞處理後的文字信息進行詞性劃分,分為實詞類和虛詞類;
S12,去除虛詞類的分詞,保留實詞類分詞,並將實詞類分詞組成分詞集合。
優選地,所述步驟S2具體包括:
S21,將所述分詞集合與本地垃圾詞庫進行匹配,確定所述消息中垃圾消息的本地匹配指數;
S22,判斷所述本地匹配指數是否大於第一預定閾值,是則判定所述消息為垃圾消息並進行過濾,否則進入步驟S3。
優選地,所述本地匹配指數的計算方法為:
S211,獲取所述分詞集合中與本地垃圾詞庫相匹配的每個本地垃圾分詞的權重值,進而計算所述分詞集合的本地平均權重值;
S212,計算本地垃圾分詞在所述分詞集合中的第一比例;
S213,根據所述平均本地平均權重值和所述第一比例確定本地匹配指數。
優選地,所述本地匹配指數為:
P1=max(t1,q1);
其中,P1為本地匹配指數,t1為平均本地平均權重值,q1為第一比例。
優選地,所述步驟S3具體包括:
S31,將所述分詞集合與雲端垃圾詞庫進行匹配,確定所述消息為垃圾消息的雲端匹配指數;
S32,判斷所述雲端匹配指數是否大於第二預定閾值,是則判定所述消息為垃圾消息並進行過濾,否則判定為非垃圾消息進行顯示。
優選地,所述雲端匹配指數的計算方法為:
S311,獲取所述分詞集合中與雲端垃圾詞庫相匹配的每個雲端垃圾分詞的權重值,進而計算所述分詞集合的雲端平均權重值;
S312,計算雲端垃圾分詞在所述分詞集合中的第二比例;
S313,根據所述雲端平均權重值和所述第二比例確定雲端匹配指數。
優選地,所述雲端匹配指數為
P2=max(t2,q2);
其中,P2為雲端匹配指數,t2為雲端平均權重值,q2為第二比例。
本發明的第二方面提出了一種過濾垃圾消息的系統,包括:
處理單元,用於提取接收的消息中的文字信息,並對所述文字信息進行處理獲取分詞集合;
本地判斷單元,用於將所述分詞集合進行本地判斷,當判斷所述消息為垃圾消息時進行過濾,否則將分詞集合推送至雲端判斷單元;
雲端判斷單元,用於將所述分詞集合進行雲端判斷,當判定所述消息為垃圾消息時進行過濾,否則在顯示單元進行顯示。
優選地,所述處理單元包括:
劃分模塊,用於將文字信息進行分詞處理,並對獲得的文字信息進行詞性劃分,分為實詞類分詞和虛詞類分詞;
提取模塊,去除虛詞類分詞,保留實詞類分詞,並將實詞類分詞組成分詞集合。
優選地,所述本地判斷單元具體包括:
本地匹配單元,用於將所述分詞集合中的每個分詞與本地垃圾詞庫進行匹配,從分詞集合中提取本地垃圾分詞,並確定所述本地垃圾分詞的本地匹配指數;
本地過濾單元,當所述本地匹配指數大於第一預定閾值時,則判定所述消息為垃圾消息並進行過濾,否則將分詞集合推送至雲端判斷單元。
所述本地匹配單元具體包括:
本地權重計算模塊,用於獲取所述分詞集合中與本地垃圾詞庫相匹配的每個本地垃圾分詞的權重值,進而計算所述分詞集合的本地平均權重值;
本地比例計算模塊,用於計算本地垃圾分詞在所述分詞集合中的第一比例;
本地指數計算模塊,用於根據所述平均本地平均權重值和所述第一比例確定本地匹配指數。
優選地,所述本地指數計算模塊針對本地匹配指數的計算方法為:
P1=max(t1,q1);
其中,P1為本地匹配指數,t1為平均本地平均權重值,q1為第一比例。
優選地,雲端判斷單元具體包括:
雲端匹配單元,用於將所述分詞集合中的每個分詞與雲端垃圾詞庫進行匹配,從分詞集合中提取雲端垃圾分詞,並確定所述雲端垃圾分詞的雲端匹配指數;
雲端過濾單元,當所述雲端匹配指數大於第二預定閾值時,則判定所述消息為垃圾消息並進行過濾,否則判定為非垃圾消息進行顯示。
所述雲端匹配單元具體包括:
雲端權重計算模塊,用於獲取所述分詞集合中與雲端垃圾詞庫相匹配的每個雲端垃圾分詞的權重值,進而計算所述分詞集合的雲端平均權重值;
雲端比例計算模塊,用於計算雲端垃圾分詞在所述分詞集合中的第二比例;
雲端指數計算模塊,用於根據所述雲端平均權重值和所述第二比例確定雲端匹配指數。
優選地,所述雲端指數計算模塊針對雲端匹配指數的計算方法為
P2=max(t2,q2);
其中,P2為雲端匹配指數,t2為雲端平均權重值,q2為第二比例。
採用上述技術方案後,本發明與現有技術相比具有以下有益效果。
將終端上推送的消息經過本地和雲端雙重判斷後確定出的有用消息推送給用戶,這樣能夠提高垃圾消息過濾的準確率,進而高效地將垃圾消息過濾出去,進而保證推送的消息是用戶需要的消息。
本發明的本地匹配指數和雲端匹配指數,是從對應垃圾分詞的平均權重值和相應的佔有比例進行比較,選取其中的最大值作為相應本地或雲端的匹配指數,這樣能夠減小垃圾消息的誤判率,提升消息的過濾效果,方便用戶使用。
下面結合附圖對本發明的具體實施方式作進一步詳細的描述。
附圖說明
附圖作為本發明的一部分,用來提供對本發明的進一步的理解,本發明的示意性實施例及其說明用於解釋本發明,但不構成對本發明的不當限定。顯然,下面描述中的附圖僅僅是一些實施例,對於本領域普通技術人員來說,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他附圖。在附圖中:
圖1是本發明的一個實施例的過濾垃圾消息的方法的流程圖;
圖2是本發明圖1中步驟S1的流程展開示意圖;
圖3是本發明圖1中步驟S2的流程展開示意圖;
圖4是本發明圖3中步驟S21的流程展開示意圖;
圖5是本發明圖1中步驟S3的流程展開示意圖;
圖6是本發明圖5中步驟S31的流程展開示意圖;
圖7是本發明的一個實施例的過濾垃圾消息的系統的結構框圖。
需要說明的是,這些附圖和文字描述並不旨在以任何方式限制本發明的構思範圍,而是通過參考特定實施例為本領域技術人員說明本發明的概念。
具體實施方式
為使本發明實施例的目的、技術方案和優點更加清楚,下面將結合本發明實施例中的附圖,對實施例中的技術方案進行清楚、完整地描述,以下實施例用於說明本發明,但不用來限制本發明的範圍。
實施例一
如圖1所示,本發明的實施例提出了一種過濾垃圾消息的方法,應用於終端,步驟包括:
S1,提取接收的消息中的文字信息,並對所述文字信息進行處理獲取分詞集合;
S2,將所述分詞集合進行本地判斷,當判斷所述消息為垃圾消息時進行過濾,否則進入步驟S3;
S3,將所述分詞集合進行雲端判斷,當判定所述消息為垃圾消息時進行過濾,否則進行顯示。
在上述技術方案中,消息為微博、微信、淘寶、QQ或者其他應用程式推送的新聞、廣告或者其他推送給用戶的消息,當用戶的手機(即,終端)接收到消息後,就會自動提取消息中的文字信息,並將該文字信息進行分詞,得到分詞集合,將該分詞集合一一存儲在存儲列表中,然後從存儲列表中一一調取分詞集合中的分詞,並分別與本地垃圾詞庫中存儲的垃圾分詞進行匹配,再然後當匹配得出該分詞集合中垃圾分詞的數量達到垃圾消息的垃圾分詞數量時,就會對其進行過濾,否則進行進一步的雲端判斷;
在進行雲端判斷時,同樣將分詞集合與雲端伺服器中雲端垃圾詞庫中存儲的垃圾分詞進行匹配,如果匹配確定出該分詞集合為中垃圾分詞的數量達到垃圾消息的垃圾分詞數量時,就會對其進行過濾,如果沒有達到垃圾消息的垃圾分詞數量時,則確定該消息為有用消息並將消息推送給用戶。
其中,如果消息中還包括除了文字以外的語音或圖片信息時,會將語音信息和圖片信息中的文字信息提取出來然後與消息中原有的文字信息結合在一起之後,再對結合後的文字信息進行處理。
通過上述技術方案,將終端上推送的消息經過本地和雲端雙重判斷後確定出的有用消息推送給用戶,這樣能夠提高垃圾消息過濾的準確率,進而高效地將垃圾消息過濾出去,進而保證推送的消息是用戶需要的消息。
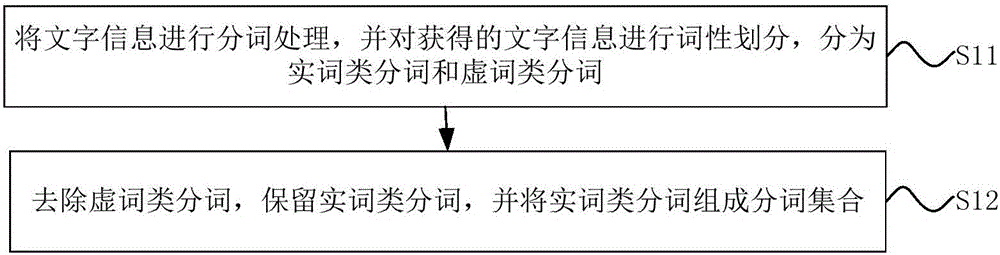
如圖2所示,所述分詞集合的獲取方法為:
S11,將文字信息進行分詞處理,並對獲得的文字信息進行詞性劃分,分為實詞類分詞和虛詞類分詞;
S12,去除虛詞類分詞,保留實詞類分詞,並將實詞類分詞組成分詞集合。
在上述技術方案中,在將分詞集合與本地垃圾詞庫進行匹配之前,先對獲得分詞進行詞性分析,詞性具體包括:實詞分為,名詞、動詞、形容詞、數詞、量詞和代詞,虛詞分為,副詞、介詞、連詞、助詞、擬聲詞和嘆詞,將分詞中的副詞、介詞、連詞、助詞、擬聲詞和嘆詞等虛詞去除;
然後將去除虛詞後的分詞組合起來,形成分詞集合。
例如,收到消息內容為「今天的天氣很好」,進行分詞處理後為「今天/的/天氣/很好」,其中,「的」為助詞,因此將分詞中的「的」去除,然後得到的分詞集合為「今天/天氣/很好」。
如圖3所示,所述步驟S2具體包括:
S21,將所述分詞集合中的每個分詞與本地垃圾詞庫進行匹配,從分詞集合中提取本地垃圾分詞,並確定所述本地垃圾分詞的本地匹配指數;
S22,判斷所述本地匹配指數是否大於第一預定閾值,是則判定所述消息為垃圾消息並進行過濾,否則進入步驟S3。
在上述技術方案中,將去除虛詞後的分詞集合與本地垃圾詞庫進行匹配,確定出垃圾分詞的佔有指數(可以是垃圾分詞的佔有比例,也可以是垃圾分詞的權重值)為本地匹配指數;
然後判斷本地匹配指數是否在第一預定閾值範圍內,如果不在則確定該消息為垃圾消息進行過濾,不推送給用戶,如果在則進行進一步的雲端判斷,並根據云端判斷結果確定是否將該消息過濾。
通過上述技術方案,首先將消息進行上述的本地判斷,本地垃圾詞庫存儲的是根據用戶的使用習慣提取的與用戶平時使用習慣不符的相應信息的垃圾詞彙,這樣,經過本地判斷之後就可以將不符合用戶習慣的消息過濾出去,但是本地判斷比較局限,這樣就需要進一步的雲端判斷,對該消息進行再一次過濾之後得到的消息為用戶需要的有用消息,並推送給用戶。
如圖4所示,所述本地匹配指數的計算方法為:
S211,獲取所述分詞集合中與本地垃圾詞庫相匹配的每個本地垃圾分詞的權重值,進而計算所述分詞集合的本地平均權重值;
S212,計算本地垃圾分詞在所述分詞集合中的第一比例;
S213,根據所述平均本地平均權重值和所述第一比例確定本地匹配指數。
在上述技術方案中,為分詞賦予權重值的方式可以包括如下方式:
(1)根據詞性的不同,為不同詞性的分詞賦予不同的權重值(例如,名詞權重值為9,動詞為8,形容詞為7等);或者
(2)根據分詞在分詞集合中的出現頻率進行由大到小的排序,根據排序的結果為該分詞賦予相應權值,可以是頻率由大到小對應權重值由大到小;或者
(3)提取獲取分詞的時間信息,並為不同的時間段獲取的分詞賦予不同的權重值;或者
(4)將消息分為新聞、廣告、購物、美食、生活等種類,根據消息的種類為消息進行初次加權,然後再對消息進行分詞處理並採取上述的方案中的至少之一的加權方式進行再次加權處理,進而獲得最終的加權結果,其中初次加權是根據消息種類的不同而為消息賦予不同的初次加權值。
將上述幾種加權方式中任意一種或多種的分詞與權值進行設置,在本地種將每個分詞和與之對應的權值進行列表存儲,以供後續獲取的分詞集合進行匹配;
分詞集合中與本地垃圾詞庫相匹配的垃圾詞彙為本地垃圾分詞,從存儲的列表中調取與本地垃圾分詞一一對應的權重值,進而將對應的權重值賦予給每個本地垃圾分詞,然後將所有的本地垃圾分詞的權重值進行累加並除以本地垃圾分詞的數目進而得出本地平均權重值;
將本地垃圾分詞的數目除以分詞集合總數,計算得出第一比例;再然後將本地平均權重值與第一比例代入相應函數中計算得出本地匹配指數。
通過上述技術方案,可以選擇不同的加權方式為分詞進行加權處理,這樣能夠根據實際情況進行選擇,並匹配出最合適的加權方式,並且相應的加權方式可以互相結合使用,這樣更能滿足用戶多樣化的需求。
優選地,所述本地匹配指數為:
P1=max(t1,q1);
其中,t1為平均本地平均權重值,q1為第一比例,P1為本地匹配指數。
在上述技術方案中,將得到的平均本地平均權重值t1和第一比例q1代入max函數中,進行運算,得出的數值P1就是本地匹配指數,這樣就可以將本地匹配指數與第一預定閾值進行比較,進而判斷該消息是否為垃圾消息。
其中,如果分詞集合中的詞語未在本地垃圾詞庫中,則權值為0,如果分詞集合中的詞語在本地垃圾詞庫中,即,本地垃圾分詞,則根據垃圾詞庫中的對應權值,為每個本地垃圾分詞進行賦值。
通過比較平均本地平均權重值和第一比例的大小,如果消息中的垃圾詞彙所對應的權重值都比較小,得出的本地平均權重值比較小,但是垃圾詞彙的佔有比例(即,第一比例)比較高,當出現這種情況時,就將第一比例作為本地匹配指數,根據第一比例的數值進行後續的處理;
另外,如果消息中的垃圾詞彙對應的權重值比較大,得出的本地平均權重值比較大,但是垃圾詞彙的佔有比例比較小,出現這種情況時,就會選取本地平均權重值作為本地匹配指數,根據本地匹配指數進行後續處理。
這樣,能夠提高垃圾消息過濾的準確性。
例如,當用戶收到以下消息:
「你好,你好,你好,你好,你好,你好」時,「你好」屬於本地垃圾詞庫中的詞語,「你好」在垃圾詞彙中的權重為0.1,上述消息中共有6個「你好」,則得出平均本地權值為0.1,但是計算得出的第一比例是1,1>0.1,因此,就選取第一比例1為本地匹配指數;1大於設定的閾值0.6,因此該消息是垃圾消息,並進行過濾。
又如,當用戶收到以下消息:
「不給錢就殺了你」時,該消息進行分詞處理「不給/錢/就/殺了/你」共5個詞,其中「殺了」屬於本地垃圾詞庫中的詞語,權重是4,則得出平均本地權值為0.8,計算得出的第一比例是0.2,因此,就選取平均本地權值0.8為本地匹配指數;0.8大於設定的閾值0.6,因此該消息是垃圾消息,並進行過濾。
如圖5所示,所述步驟S3具體包括:
S31,將所述分詞集合中的每個分詞與雲端垃圾詞庫進行匹配,從分詞集合中提取雲端垃圾分詞,並確定所述雲端垃圾分詞的雲端匹配指數;
S32,判斷所述雲端匹配指數是否大於第二預定閾值,是則判定所述消息為垃圾消息並進行過濾,否則判定為非垃圾消息進行顯示。
在上述技術方案中,將去除虛詞後的分詞集合與雲端垃圾詞庫進行匹配,確定出垃圾詞彙的佔有指數(即,雲端匹配指數);
然後判斷雲端匹配指數是否在第二預定閾值範圍內,如果不在則確定該消息為垃圾消息進行過濾,不推送給用戶,如果在則將該消息推送給用戶。
由於本地判斷比較局限,這樣就需要進一步的雲端判斷,對該消息進行再一次過濾之後得到的消息才為用戶需要的有用消息,並推送給用戶,這樣能夠提高推送消息的準確性。
如圖6所示,所述雲端匹配指數的計算方法為:
S311,獲取所述分詞集合中與雲端垃圾詞庫相匹配的每個雲端垃圾分詞的權重值,進而計算所述分詞集合的雲端平均權重值;
S312,計算雲端垃圾分詞在所述分詞集合中的第二比例;
S313,根據所述雲端平均權重值和所述第二比例確定雲端匹配指數。
在上述技術方案中,在步驟S311之前,先獲取分詞集合中的分詞總數N,然後採取與本地匹配指數的計算方法中的加權方式相同,為每個雲端垃圾分詞進行加權處理,並將所有和雲端垃圾分詞對應的權值進行累加得到權值總和M,然後M/N,得出雲端平均權值;
然後,提取雲端垃圾分詞的數目A,將A/N,得出第二比例;再然後將雲端平均權重值與第一比例代入相應函數中計算得出雲端匹配指數。
優選地,所述雲端匹配指數為
P2=max(t2,q2);
其中,t2為雲端平均權重值,q2為第二比例,P2為雲端匹配指數。
通過比較雲端平均權重值和第二比例的大小,如果消息中的垃圾詞彙所對應的權重值都比較小,得出的雲端平均權重值比較小,但是垃圾詞彙的佔有比例(即,第二比例)比較高,當出現這種情況時,就將第二比例作為雲端匹配指數,根據第二比例的數值進行後續的處理;
另外,如果消息中的垃圾詞彙對應的權重值比較大,得出的雲端平均權重值比較大,但是垃圾詞彙的佔有比例比較小,出現這種情況時,就會選取雲端平均權重值作為雲端匹配指數,利用雲端平均權重值進行後續處理。
這樣能夠減小垃圾消息的誤判率,提升消息的過濾效果,方便用戶使用。
實施例二
如圖7所示,本發明的實施例提出了一種過濾垃圾消息的系統1,包括:
處理單元11,用於提取接收的消息中的文字信息,並對所述文字信息進行處理獲取分詞集合;
本地判斷單元12,用於將所述分詞集合進行本地判斷,當判斷所述消息為垃圾消息時進行過濾,否則將分詞集合推送至雲端判斷單元;
雲端判斷單元13,用於將所述分詞集合進行雲端判斷,當判定所述消息為垃圾消息時進行過濾,否則在顯示單元進行顯示。
優選地,所述處理單元11包括:
劃分模塊111,用於將文字信息進行分詞處理,並對獲得的文字信息進行詞性劃分,分為實詞類分詞和虛詞類分詞;
提取模塊112,去除虛詞類分詞,保留實詞類分詞,並將實詞類分詞組成分詞集合。
優選地,所述本地判斷單元12具體包括:
本地匹配單元,用於將所述分詞集合中的每個分詞與本地垃圾詞庫進行匹配,從分詞集合中提取本地垃圾分詞,並確定所述本地垃圾分詞的本地匹配指數;
本地過濾單元,當所述本地匹配指數大於第一預定閾值時,則判定所述消息為垃圾消息並進行過濾,否則將分詞集合推送至雲端判斷單元。
所述本地匹配單元具體包括:
本地權重計算模塊,用於獲取所述分詞集合中與本地垃圾詞庫相匹配的每個本地垃圾分詞的權重值,進而計算所述分詞集合的本地平均權重值;
本地比例計算模塊,用於計算本地垃圾分詞在所述分詞集合中的第一比例;
本地指數計算模塊,用於根據所述平均本地平均權重值和所述第一比例確定本地匹配指數。
優選地,所述本地指數計算模塊針對本地匹配指數的計算方法為:
P1=max(t1,q1);
其中,P1為本地匹配指數,t1為平均本地平均權重值,q1為第一比例。
優選地,雲端判斷單元13具體包括:
雲端匹配單元,用於將所述分詞集合中的每個分詞與雲端垃圾詞庫進行匹配,從分詞集合中提取雲端垃圾分詞,並確定所述雲端垃圾分詞的雲端匹配指數;
雲端過濾單元,當所述雲端匹配指數大於第二預定閾值時,則判定所述消息為垃圾消息並進行過濾,否則判定為非垃圾消息進行顯示。
所述雲端匹配單元具體包括:
雲端權重計算模塊,用於獲取所述分詞集合中與雲端垃圾詞庫相匹配的每個雲端垃圾分詞的權重值,進而計算所述分詞集合的雲端平均權重值;
雲端比例計算模塊,用於計算雲端垃圾分詞在所述分詞集合中的第二比例;
雲端指數計算模塊,用於根據所述雲端平均權重值和所述第二比例確定雲端匹配指數。
優選地,所述雲端指數計算模塊針對雲端匹配指數的計算方法為
P2=max(t2,q2);
其中,P2為雲端匹配指數,t2為雲端平均權重值,q2為第二比例。
本領域那些技術人員可以理解,可以對實施例中的設備中的模塊進行自適應性地改變並且把它們設置在與該實施例不同的一個或多個設備中。可以把實施例中的模塊或單元或組件組合成一個模塊或單元或組件,以及此外可以把它們分成多個子模塊或子單元或子組件。除了這樣的特徵和/或過程或者單元中的至少一些是相互排斥之外,可以採用任何組合對本說明書(包括伴隨的權利要求、摘要和附圖)中公開的所有特徵以及如此公開的任何方法或者設備的所有過程或單元進行組合。除非另外明確陳述,本說明書(包括伴隨的權利要求、摘要和附圖)中公開的每個特徵可以由提供相同、等同或相似目的的替代特徵來代替。
本發明的各個部件實施例可以以硬體實現,或者以在一個或者多個處理器上運行的軟體模塊實現,或者以它們的組合實現。本領域的技術人員應當理解,可以在實踐中使用微處理器或者數位訊號處理器(DSP)來實現根據本發明實施例的文件保護處理設備中的一些或者全部不見的一些或者全部功能。本發明還可以實現為用於執行這裡所描述的方法的一部分或者全部的設備或者裝置程序,這樣的實現本發明的程序可以存儲在計算機可讀介質中,或者具有一個或者多個信號的形式,這樣的信號可以從網際網路網站上下載得到,或者在載體信號上提供,或者以任何其他形式提供。
以上所述僅是本發明的較佳實施例而已,並非對本發明作任何形式上的限制,雖然本發明已以較佳實施例揭露如上,然而並非用以限定本發明,任何熟悉本專利的技術人員在不脫離本發明技術方案範圍內,當可利用上述提示的技術內容做出些許更動或修飾為等同變化的等效實施例,但凡是未脫離本發明技術方案的內容,依據本發明的技術實質對以上實施例所作的任何簡單修改、等同變化與修飾,均仍屬於本發明方案的範圍內。