一種G.729到AMR12.2速率的轉碼方法與流程
2023-07-23 23:20:21 5
本發明涉及一種G.729到AMR12.2速率的轉碼方法,屬於信號處理技術領域。
背景技術:
信息的傳輸與交換在當代人們生活中不可或缺,在諸多信息數據中,語音數據無疑佔有舉足輕重的地位。數字語音通信具有高可靠性、高抗幹擾能力等優點,隨著通信技術的不斷發展,其所佔的比重越來越大。為了提高通信效率,數字語音壓縮編碼技術得到了廣泛應用,出現了多種語音壓縮編碼標準。為了保證網際間的互通性,語音編碼器之間的無縫連接變得越來越重要。要實現不同網絡間的語音碼流順利轉換,就需要把一端編碼器的碼流轉換成另一端所能識別的碼流,這種碼流轉換技術就稱為語音轉碼。G.729和AMR是兩種使用廣泛的語音壓縮編碼標準。G.729是國際電信聯盟(ITU)於2006年制定的8kbps語音編碼協議,G.729A是G.729標準的簡化版本;G.729B是與G.729(A)配合的靜音壓縮標準;G.729AB是指將低複雜度的G.729A和具有靜音壓縮功能的G.729B聯合使用的語音編碼標準,它在實際中應用最多,已廣泛用於IP電話、視頻會議系統等領域。AMR是WCDMA移動通信系統的自適應多速率語音編碼標準,它共有8個速率,其中12.2kbps是其最高速率,該標準在蜂窩移動通信系統中發揮著重要作用。為了實現IP電話和蜂窩移動通信系統之間的互通,需要進行G.729AB與AMR編碼器之間的轉碼工作。傳統的解決方法是採用先解後編(DecodethenEncode,DTE)方式進行轉碼,即用源解碼器將傳輸的比特流進行解碼,恢復出重建語音,然後再使用目標編碼器對重建語音進行編碼,生成目標解碼器可以解碼的碼流。這種方法雖然能夠完成不同編碼器之間的轉碼操作,但存在轉碼後語音質量低、計算複雜度高和延時長等缺點。
技術實現要素:
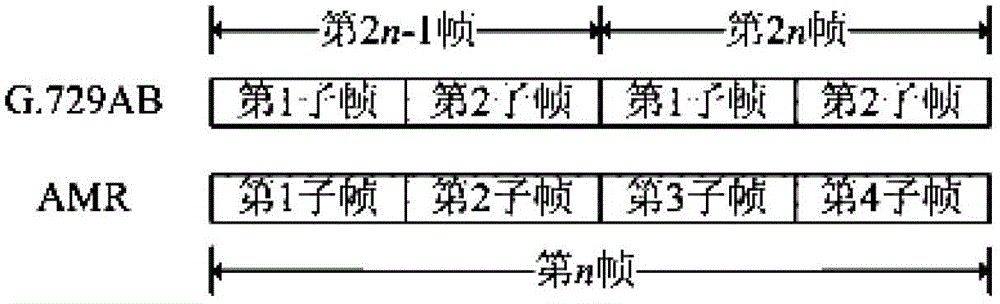
本發明針對以上問題的提出,而研製一種G.729到AMR12.2速率的轉碼方法。本發明採取的技術方案如下:將輸入比特流輸入到G.729AB解碼單元,利用G.729AB解碼單元對輸入比特流進行解碼,然後將解碼得到的幀類型、LSP係數、基音延時、固定碼本矢量、碼本增益以及合成語音輸入G.729AB到AMR-12.2kbps轉碼單元,對每一部分進行相應的轉碼:根據解碼得到的幀類型信息來對目標幀的VAD信息做出判斷;將解碼端得到的LSP係數和整數基音延時分別作為編碼端的LSP係數和開環基音延時;利用輸入語音與重構語音之間的均方誤差最小準則,同時採用G.729AB的快速搜索方法和AMR-12.2kbps1/6解析度,搜索編碼端的閉環基音延時;用加權輸入語音和加權重構語音之間的均方誤差最小準則來搜索固定碼本中的碼矢,在搜索過程中利用量化信號的最大絕對值來獲得部分脈衝的位置,同時減少部分脈衝的搜索個數。最後對各個參數進行編碼,得到輸出比特流。本發明的有益效果:為了驗證本發明方法的有效性,進行了若干實驗測試。測試中,將經過轉碼後的輸出比特流經過AMR-12.2kbps解碼後,得到轉碼後的語音,然後對該語音進行測試。本發明使用PESQ、MOS-LQO作為轉碼後客觀語音質量的衡量指標。測試序列選用ITU-T在G.729AB和AMR中提供的10組標準文件,測試結果如表3,表3在具體實施方式裡面。從表3中可以看出,本發明的轉碼方法在計算量上比傳統方式下降了44%左右,PESQ值和MOS-LQO都有所增加。附圖說明圖1G.729AB和AMR編解碼算法原理框圖。圖2G.729AB與AMR幀結構對應圖。圖3G.729AB到AMR12.2kbps轉碼裝置。圖4G.729AB到AMR-12.2kbps的轉碼。圖5LSP參數解碼流程圖。圖6基音延時解碼流程圖。圖7閉環基音搜索流程圖。圖8固定碼本搜索流程圖。具體實施方式下面結合附圖對本實用新型最進一步說明:G.729AB和AMR是兩種使用廣泛的語音壓縮編碼標準。G.729是國際電信聯盟(ITU)於2006年制定的8kbps語音編碼協議,G.729A是G.729標準的簡化版本;G.729B是與G.729(A)配合的靜音壓縮標準;G.729AB是指將低複雜度的G.729A和具有靜音壓縮功能的G.729B聯合使用的語音編碼標準,它在實際中應用最多,已廣泛用於IP電話、視頻會議系統等領域。AMR是WCDMA移動通信系統的自適應多速率語音編碼標準,它共有8個速率,其中12.2kbps是其最高速率,該標準在蜂窩移動通信系統中發揮著重要作用。為了實現IP電話和蜂窩移動通信系統之間的互通,需要進行G.729AB與AMR編碼器之間的轉碼工作。傳統的解決方法是採用先解後編(DecodethenEncode,DTE)方式進行轉碼,即用源解碼器將傳輸的比特流進行解碼,恢復出重建語音,然後再使用目標編碼器對重建語音進行編碼,生成目標解碼器可以解碼的碼流。這種方法雖然能夠完成不同編碼器之間的轉碼操作,但存在轉碼後語音質量低、計算複雜度高和延時長等缺點。為了解決上述DTE方式語音轉碼存在的問題,本發明給出了一種在G.729AB與AMR-12.2kbps間高效的轉碼方法。該方法在保證語音質量的前提下,使轉碼算法的計算複雜度降低40%以上。該發明具有轉碼後語音質量高、計算複雜度低、轉碼算法延時小等優點,從而可降低設備的成本,保證不同設備供應商間設備的兼容與互通。G.729AB與AMR均基於CELP語音生成模型,兩個編碼算法對於語音信號的處理過程基本相同。G.729AB和AMR編解碼算法的原理框圖如圖1所示:在編碼端,首先,都需要將輸入語音經過預處理後,通過VAD判決進行分類,分為語音幀和非語音幀;然後,根據不同的幀類型選用不同的編碼方法:對於語音幀,採用高速率的語音幀編碼算法;對於非語音幀,採用DTX技術進行編碼處理,將需要傳送的噪聲信息通過SID幀發送到解碼端;最後,將編碼後的比特流進行傳輸。在解碼端,根據不同的幀類型,選擇不同的解碼算法來生成合成語音:對非語音幀,採用CNG算法生成合成語音;對語音幀,採用語音幀解碼算法生成合成語音。最後對合成語音作一些後置處理以改善音質。現有技術介紹為了解決DTE方式轉碼存在的問題,國內外提出了一些轉碼方法。下面結合幾篇外文文獻和專利,對現有轉碼技術進行簡要介紹。現有技術簡介(1)2004年,M.Ghenania在文獻「Low-costSmartTranscodingAlgorithmbetweenITU-TG.729(8kbit/s)and3GPPNB-AMR(12.2kbit/s)」中提出了一種G.729與AMR12.2kbit/s之間的轉碼方法。其基本思路是:將源解碼器解碼得到的LSP參數和基音延時參數直接賦值給目標編碼器;對於代數碼書,則利用源編碼器搜索得到的代數碼書脈衝位置附近的N個非零脈衝構成子代數碼書;然後,目標編碼器在子代數碼書上,採用目標編碼器的代數碼書搜索算法來得到代數碼書脈衝位置和符號。(2)在公開號為US20050075868A1的美國專利中,申請人公開了一種從EVRC到G.729AB轉碼的方法。其基本思路是:通過內插EVRC的LSP參數來得到G.729AB的LSP參數,將EVRC的閉環基音延時賦值給G.729AB的開環基音延時,利用EVRC固定碼本搜索結果以及G.729AB相關信號的最大值來限制G.729AB固定碼本的搜索範圍。現有技術缺點(1)在目標編碼器開啟DTX功能時,需要採用VAD算法來重新判斷當前輸入幀的VAD信息,其中VAD操作會使整體轉碼操作的計算複雜度增加。(2)閉環基音搜索部分採用直接參數轉換,雖然可以大幅度降低計算量,但是語音質量下降較多,無法滿足電信用戶的要求。(3)利用源編碼器固定碼本的脈衝搜索結果來限制目標編碼器的固定碼本搜索範圍,使得語音質量下降明顯。本發明技術方案的詳細闡述本發明所要解決的技術問題(1)在目標編碼器開啟DTX功能時,需要採用VAD算法來重新判決當前輸入幀的VAD信息,其中VAD操作會使整體轉碼操作的計算複雜度增加。(2)閉環基音搜索部分採用直接參數轉換,雖然可以大幅度降低計算量,但是語音質量下降較多。(3)利用源編碼器固定碼本的脈衝搜索結果來限制目標編碼器的固定碼本搜索範圍,使得語音質量下降明顯。為了解決以上技術問題,在特定速率下,本發明給出一種有效的轉碼方法,在滿足不同編碼器間有效互通的同時,可以降低轉碼計算複雜度,提升轉碼後的語音質量。本發明提供的完整技術方案如下:本發明首先利用G.729AB解碼器對輸入比特流進行解碼,得到幀類型、LSP係數、基音延時、固定碼本矢量、碼本增益以及合成語音,將合成語音作為輸入語音輸入到AMR編碼器。然後對每一部分進行相應的轉碼:根據輸入比特流中的幀類型信息來對目標幀的VAD信息做出判斷;將解碼端得到的LSP係數和整數基音延時分別作為編碼端的LSP係數和開環基音延時;利用輸入語音與重構語音之間的均方誤差最小準則,同時採用G.729AB的快速搜索方法和AMR-12.2kbps1/6解析度,搜索編碼端的閉環基音延時;用加權輸入語音和加權重構語音之間的均方誤差最小準則來搜索固定碼本中的碼矢,在搜索過程中利用量化信號的最大絕對值來獲得部分脈衝的位置,同時減少部分脈衝的搜索個數。最後對各個參數進行編碼,得到輸出比特流。G.729AB與AMR-12.2kbps之間轉碼的首要問題是幀長不同,G.729AB是對10ms語音幀進行編碼,而AMR-12.2kbps是對20ms語音幀進行編碼。為了解決語音幀長度不同的問題,其對應關係如圖2所示:將2個G.729AB語音幀對應1個AMR語音幀,它們具有相同的子幀結構,G.729AB將1個語音幀分成2個5ms子幀,AMR將一個語音幀分成4個5ms子幀。本發明給出的G.729AB到AMR-12.2kbps轉碼裝置結構圖如圖3所示。該裝置由3個單元組成:G.729AB解碼單元、G.729AB到AMR-12.2kbps轉碼單元和AMR-12.2kbps編碼單元。本發明具體實現過程如圖4所示。G.729AB解碼單元G.729AB解碼單元包括比特解析單元、幀類型解碼單元、語音幀解碼單元和非語音幀解碼單元、合成濾波單元。語音幀解碼單元和非語音幀解碼單元包括LSP解碼單元、基音延時解碼單元、固定碼本解碼單元和增益解碼單元。(1)比特解析單元比特解析單元用於對輸入比特流的比特分配進行解析。語音幀、SID幀、非傳輸幀的有效長度不同,語音幀的有效長度為80bits,SID幀的有效長度為15bits,非傳輸幀的有效長度為0bits。表1和表2分別給出了語音幀和SID幀比特流順序及其對應的參數說明。(2)幀類型解碼單元根據輸入有效比特流的長度來判斷幀類型:若長度為80,則為語音幀,ftype=1;若長度為15,則為SID幀,ftype=2;若長度為0,則為不傳輸幀,ftype=0。(3)語音幀解碼單元語音幀解碼單元包括LSP解碼單元、基音延時解碼單元、固定碼本解碼單元和增益解碼單元。表1語音幀發送參數及其順序表2靜音幀發送參數及其順序1)LSP解碼單元LSP參數解碼流程圖如圖5:①根據L0、L1、L2、L3解析出LSP的量化輸出這裡,ξ1i(L1)表示第一級碼本中序號為L1的碼矢量中的第i個參數,ξ2i(L2)表示第二級低維碼本中序號為L2的碼矢量中的第i個參數,ξ3i(L3)表示第二級高維碼本中序號為L3的碼矢量中的第i個參數。②為避免在量化合成濾波中出現尖銳的震蕩,需調整解碼後的參數:式(1)中的循環變量i從2到10取值,每次增加1,每次循環中執行:若滿足條件,則執行操作。其中,J為最小距離。這個調整要作兩次,第一次J=0.0012,第二次J=0.0006。③計算當前幀m的量化LSF係數這裡,是前幾幀量化輸出,是當前幀的量化輸出,是滑動平均預測器的係數,可以由L0碼書搜索得到。④計算得到之後,檢查對應濾波器的穩定性,步驟如下:Ⅰ、按照的升序重新排列Ⅱ、若則Ⅲ、若則Ⅳ、若則⑤由LSF係數求出LSP係數計算得到的LSP係數作為G.729AB的第二子幀,第一子幀的LSP係數用相鄰幀對應的參數線性內插得到:其中,是前一幀10ms的LSP係數,是當前10ms幀的LSP係數。⑥將LSP係數轉換為LP係數ai,具體步驟如下:Ⅰ、循環變量i取值範圍從1到5,每次增加1;每次變量i循環時,執行f1(i)=-2q2i-1f1(i-1)+2f1(i-2)操作;Ⅱ、循環變量j取值範圍從i-1到1,每次減少1;每次循環變量j循環時,執行f1(j)=f1(j)-2q2i-1f1(j-1)+f1(j-2)操作;其中,f1(0)=1,f1(-1)=0;將q2i-1替換成q2i即可得到f2(i);Ⅲ、由f1(i),f2(i)計算f1'(i),f2'(i):f1'(i)=f1(i)+f1(i-1),i=1,…,5;f2'(i)=f2(i)+f2(i-1),i=1,…,5Ⅳ、計算LP係數:2)基音延時解碼單元基音延時解碼流程圖如圖6:①計算奇偶校驗位P:由收到的P1前6位異或得到P;②如果P與P0不相同,則認為接收發生了錯誤,當前幀第一子幀的基音延時T1用前一幀第二子幀的基音延時T2來替代;如果P與P0相同,則認為接收正確,那麼利用收到的基音延時序號P1尋找基音延時的整數部分和分數部分:如果P1<197,int(T1)=(P1+2)/3+19,frac=P1-3*int(T1)+58;否則,int(T1)=P1-112,frac=0。③第二子幀T2的整數部分由P2和t_min得到:t_min=int(T1)-5若t_min143則t_max=143;t_min=t_max-9T2解碼:int(T2)=(P1+2)/3-1+t_min,frac=P2-2-3*((P2+2)/3-1)④確定基音延時後,在給出的整數延時k和分數延時t處,內插過去的激勵resLP(n)來計算自適應碼本矢量v(n):這個內插濾波器b60由在±59處截斷的漢明窗截取取樣函數sinx/x得到,在±60處(b60(60)=0)用0填充,該濾波器的截止頻率為3.6KHz。3)固定碼本解碼單元固定碼本是代數碼本結構,每個碼本矢量含有N個非零脈衝,每個脈衝的幅度或正或負。脈衝位置由接收到的固定碼本序號C來得到,脈衝符號由S碼得到,構造固定碼本矢量c(n):c(n)=S0δ(n-C0)+S1δ(n-C1)+S2δ(n-C2)+S3δ(n-C3),n=0,…,39;(6)如果基音延時的整數部分T小於子幀長度40,c(n)按照下式修正:4)增益解碼單元增益解碼是在子幀上進行的,接收到的增益碼本序號GA、GB均是2維碼本,利用下式計算每子幀的自適應碼本增益和固定碼本增益相關因子γ:γ=GA2(GA)+GB2(GB);(9)其中,GA1、GA2、GB1、GB2中的下標是維號。量化固定碼本增益計算公式如下:其中,g'c是預測的固定碼本增益。(4)非語音幀解碼單元非語音幀LSP解碼與語音幀LSP解碼基本相同;基音延時值通過在範圍[40,103]內隨機產生;固定碼本的脈衝位置及脈衝符號也是隨機產生的;自適應碼本增益限制在0.5內,在[0,0.5]範圍內隨機選擇;能量值作為固定碼本增益。(5)合成濾波單元對於語音幀,將得到的自適應和固定碼本矢量分別乘以各自的增益,相加可得激勵信號;然後將激勵信號通過LP合成濾波器得到合成語音信號。對於非語音幀,激勵信號採用三個信號的混合,其中兩個信號來自G.729AB的激勵信號,另一個來自高斯白噪聲發生器;將上述得到的激勵信號通過LP合成濾波器,得到舒適噪聲信號。G.729AB到AMR-12.2kbps轉碼單元G.729AB到AMR-12.2kbps轉碼單元用於得到AMR-12.2kbps編碼所需的參數。具體步驟如下:(1)VAD部分本發明屏蔽AMR編碼時的VAD操作,利用G.729AB解碼得到的幀類型信息判斷AMR-12.2kbps編碼時VAD的信息,具體作法如下:1)若G.729AB解碼得到的幀類型ftype=1,則VAD_flagG.729AB=1;否則,VAD_flagG.729AB=0。2)根據連續兩幀G.729AB的VAD_flag判斷AMR編碼端VAD_flag的值,VAD_flag的值為VAD_flagAMR=VAD_flagG.729AB_1||VAD_flagG.729AB_2,(11)這裡,VAD_flagG.729AB_1表示第一幀G.729AB的VAD信息,VAD_flagG.729AB_2表示第二幀G.729AB的VAD信息。(2)LSP部分將G.729AB第2n-1幀和第2n幀的LSP參數,傳遞給AMR-12.2kbps第n幀的第二子幀和第四子幀,即其中,表示G.729AB第2n-1幀的LSP係數,表示G.729AB第2n幀的LSP係數,表示AMR-12.2kbps第n幀的第二子幀,表示AMR-12.2kbps第n幀的第四子幀。第一和第三子幀的LSP係數由下式得到:將得到LSP係數轉換為LP係數ai,具體步驟如下:1)循環變量i取值範圍從1到5,每次增加1;每次變量i循環時,執行f1(i)=-2q2i-1f1(i-1)+2f1(i-2)操作;2)循環變量j取值範圍從i-1到1,每次減少1;每次循環變量j循環時,執行f1(j)=f1(j)-2q2i-1f1(j-1)+f1(j-2)操作;其中,f1(0)=1,f1(-1)=0;將q2i-1替換成q2i即可得到f2(i);3)由f1(i),f2(i)計算f1'(i),f2'(i):f1'(i)=f1(i)+f1(i-1),i=1,…,5;f2'(i)=f2(i)+f2(i-1),i=1,…,54)計算LP係數:(3)開環基音搜索部分將G.729AB第2n-1幀和第2n幀的第一子幀閉環基音參數作為AMR-12.2kbps第n幀的兩個開環基音參數:(4)自適應碼本搜索部分本發明利用G.729AB閉環基音搜索的思想簡化AMR-12.2kbps整數部分的搜索過程,並且根據AMR-12.2kbps的1/6解析度進行分數部分的搜索,具體搜索流程圖如圖7所示:1)計算基音延時的搜索範圍[t0_min,t0_max]在第一/第三子幀,t0_min=max{18,TOP-3},t0_max=min{143,TOP+3}。在第二/第四子幀,t0_min=max{18,T1-5},t0_max=min{143,T1+4},其中T1是前一子幀(第一或第三子幀)基音分數延時的最大整數部分。2)計算LP濾波器的殘差信號resLP(n):其中,s(n)是G.729AB解碼後得到的合成語音;是量化了的預測係數。3)將殘差信號resLP(n)通過感知加權合成濾波器,從而得到用於自適應碼本搜索的目標信號x(n),即x(n)=resLP(n)*h(n);(19)4)計算x(n)與h(n)的相關:5)將LP殘差信號賦值給激勵信號u(n):u(n)=resLP(n),n=0,…,39;6)計算R(k):7)求出R(k)最大值對應的k,即為最佳整數基音延時。8)在最佳整數基音延時k附近的分數(從-3/6到-3/6,步長為1/6)內插R(k):其中,b24是內插濾波器係數,t=0,…,5分別對應分數0、1/6、2/6、3/6、-2/6和-1/6。搜索R(k)t的最大值所對應的t,即為最佳分數基音延時。9)確定基音延時後,在給出的整數延時k和分數延時t處內插過去的激勵u(n)來計算自適應碼本矢量v(n):其中,b60是內插濾波器係數。10)計算自適應碼本的增益:其中,y(n)=v(n)*h(n)。(5)固定碼本搜索部分固定碼本搜索流程圖如圖8所示:1)計算固定碼本搜索的目標信號x2(n):其中,y(n)=v(n)*h(n)是自適應碼本矢量濾波,是量化了的自適應碼本增益。2)計算x2(n)與h(n)的相關信號d(n):3)計算h(n)的自相關矩陣Φ,其中Φ的每個元素按下式計算:4)計算量化信號b(n):5)計算符號信號S(n)=sgn[b(n)]。6)脈衝搜索位置預選。按量化信號|b(n)|從大到小的順序重置每個軌道的脈衝位置。用前M區的脈衝位置作為搜索脈衝的候選,取M=5。7)記錄|b(n)|最大值的位置及其所在軌道數。將i0固定在所有軌道中|b(n)|最大值的位置,i1固定在下一軌道中|b(n)|最大值的位置。8)在候選的脈衝搜索位置上,按照AMR編碼標準裡的深度優先樹方法搜索出其它8個脈衝的位置,即脈衝{i2,i3}、{i4,i5}、{i6,i7}、{i8,i9}在依次軌道上成對地、順序地在嵌套環中搜索出。搜索準則是使下式最大:其中,mi是第i個脈衝的位置,N是脈衝的個數,N=10。9)計算固定碼本矢量c(n):其中,Si是第i個脈衝的符號,mi是第i個脈衝的位置,N是脈衝的個數,N=10。10)計算固定碼本增益gc:AMR-12.2kbps編碼單元AMR-12.2kbps編碼單元用於將轉碼後的參數按照AMR-12.2kbps量化方法重新量化後,寫入到輸出比特流。本發明技術方案帶來的有益效果為了驗證本發明方法的有效性,進行了若干實驗測試。測試中,將經過轉碼後的輸出比特流經過AMR-12.2kbps解碼後,得到轉碼後的語音,然後對該語音進行測試。本發明使用PESQ、MOS-LQO作為轉碼後客觀語音質量的衡量指標。測試序列選用ITU-T在G.729AB和AMR中提供的10組標準文件,測試結果如表3。從表3中可以看出,本發明的轉碼方法在計算量上比傳統方式下降了44%左右,PESQ值和MOS-LQO都有所增加。表3DTE方法與本發明方法性能測試結果對比本發明的實施在大幅度地降低計算量的同時,提高了語音質量,降低了通信設備的成本和功耗,因此本發明具有廣泛的應用價值和前景。以上所述,僅為本發明較佳的具體實施方式,但本發明的保護範圍並不局限於此,任何熟悉本技術領域的技術人員在本發明揭露的技術範圍內,根據本發明的技術方案及其發明構思加以等同替換或改變,都應涵蓋在本發明的保護範圍之內。本發明涉及的縮略語和關鍵術語定義如下:AMR:AdaptiveMulti-Rate自適應多速率。WCDMA:WidebandCodeDivisionMultipleAccess寬帶碼分多址。IP:InternetProtocol網絡協議。CELP:CodeExcitedLinearPrediction碼激勵線性預測。VAD:VoiceActivityDetector語音激活檢測。DTX:DiscontinuousTransmission不連續傳輸。CNG:ComfortNoiseGenerator舒適噪音生成。SID:SilenceInsertionDescriptor靜音插入描述。MA:MovingAverage滑動平均。LP:LinearPrediction線性預測。LPC:LinearPredictiveCoding線性預測編碼。LSP:LinearSpectrumPair線譜對。LSF:LinearSpectrumFrequency線譜頻率。PESQ:PerceptualEvaluationofSpeechQuality主觀語音質量評估。MOS-LQO:MeanOpinionScore–ListeningQualityObjective平均意見分數-客觀聽覺質量。ITU-T:InternationalTelecommunicationUnion-Telecommunicationstandardizationsector國際電信聯盟-電信標準化部門。MOPS:MillionOperationsPerSecond百萬次操作每秒。DTE:DecodethenEncode。