一種基於兩分類Fisher判別分析的故障診斷方法與流程
2023-07-12 18:35:21 4
本發明涉及一種工業故障診斷方法,尤其涉及一種基於兩分類fisher判別分析的故障診斷方法。
背景技術:
日趨複雜而大規模化的工業過程對象對故障檢測與診斷系統的性能提出了越來越高的要求,不僅需要及時地觸發故障警報,而且還要求準確地識別出當前故障類型。考慮到過程對象的複雜特性,建立相應的機理模型幾乎不可能。對此,理論研究者與實踐者們建議利用生產過程採集的數據實施故障檢測與診斷。在工業「大數據」背景下,數據驅動的過程監測方法技術得到了空前的發展與應用,各種方法層出不窮。在已有的科研文獻與專利中,數據驅動的過程監測方法取得的矚目成就主要集中於對故障進行監測,也就是當故障發生時,能觸發故障警報。然而,當故障被檢測出來後,如何診斷所發生的故障類型卻成了數據驅動方法技術的軟肋。已有的數據驅動的故障診斷方法主要依賴於貢獻圖法與模式分類法,前者通過找出「可疑」變量以指導操作人員定位故障原因,後者通過比較當前故障數據與歷史資料庫中各種故障數據的相似性匹配當前故障類型。雖然利用貢獻圖法能夠定位出「可疑」變量,但是由於測量變量間的耦合性,無法保證「可疑」變量的正確性。利用模式分類法直接匹配故障類型相對來講更加可靠,但是由於故障開始階段所採集的數據是非穩態數據,非線性與動態性問題都是非常棘手的。若處理不當,所建立的分類模型誤報率會非常高。另一方面,建立分類模型通常需要比測量變量更多的樣本數,以避免小樣本問題的出現。這在實際應用中有時無法滿足,因為操作人員通常會及時採取措施消除故障,這樣一來採集到的歷史數據量非常有限。因此,基於模式分類方法的故障診斷技術同樣面臨著諸多挑戰。
建立分類模型最經典的算法莫過於fisher判別分析,它通過最大化類別間方差與最小化同類數據方差實現了對多類數據的分類目的。fisher判別分析方法發展至今,各種拓展與改進形式層出不窮,衍生出了各式各樣的算法,但其算法的基本宗旨卻未發生任何改變。在故障診斷領域,fisher判別分析已經被用來建立故障的多分類模型。值得一提的是,有學者曾研究證明若在建立fisher判別模型之前,對變量實施選擇可有效地提升模型的分類正確率。因為變量選擇除了降低「幹擾變量」的負面影響外,還起到了一定的降維作用,這對提高模型可靠性是有很大助益的。可是,當故障類型較多時,基於變量選擇的fisher判別模型精度依舊無法達到要求。然而,變量選擇仍舊不失為一種能有效提高模型分類能力的途徑。作為一種最簡單的分類建模算法,多分類的fisher判別分析用於故障分類診斷似乎遇到了發展的瓶頸,研究者們開始更多地關注於其他更高效的分類方法。因此,如何提升fisher判別模型用於故障分類診斷的識別精度是一個丞待解決的問題。
技術實現要素:
本發明所要解決的主要技術問題是:如何通過變量選擇提高fisher判別分析模型用於故障診斷的可適用性與分類正確率。為此,本發明提供一種基於兩分類fisher判別分析的故障診斷方法。該發明方法首先利用遺傳算法選擇出每種故障類型最能區別於正常數據的特徵變量集,然後利用特徵變量建立正常數據與每類故障數據之間的兩分類的fisher判別分析模型。最後,利用多個兩分類的fisher判別模型實施故障分類診斷。
本發明解決上述技術問題所採用的技術方案為:一種基於兩分類fisher判別分析的故障診斷方法,包括以下步驟:
(1)收集生產過程正常運行狀態下的採樣數據,組成數據矩陣x0∈rn×m,收集生產過程在不同故障操作狀態下的採樣數據,組成不同的參考故障數據集其中,n為訓練樣本數,m為過程測量變量數,下標號c=1,2,…,c表示第c種參考故障類型,nc為第c種故障的可用樣本數,r為實數集,rn×m表示n×m維的實數矩陣。
(2)對矩陣x0進行標準化處理,得到均值為0,標準差為1的新數據矩陣並利用矩陣x0的均值向量與標準差向量對進行同樣的標準化處理,得到矩陣
(3)利用遺傳算法找出第c種故障類型數據最能區別於正常數據的特徵變量集,記做θc。
(4)利用特徵變量集θc從矩陣與中選出相應的變量(即矩陣的列),對應組成新矩陣與
(5)利用fisher判別分析算法建立與之間的兩分類判別模型,並保留模型參數集θc以備調用。
(6)重複步驟(3)~(5)直至得到所有故障類型的特徵變量集θ1,θ2,…,θc,和兩分類fisher判別模型參數集θ1,θ2,…,θc。
(7)當系統已有的故障檢測系統觸發故障警報後,對新採集到的故障樣本z∈r1×m實施故障分類診斷。
與傳統方法相比,本發明方法的優勢在於:
首先,本發明方法採用遺傳算法為每種故障類型選出其能最大化區別正常數據的特徵變量集,不僅可以消去非特徵變量的幹擾影響,而且還能降低變量維數,這在一定程度上降低了參考故障樣本數量有限對建模的限制性。其次,本發明方法識別故障類型利用了多個兩分類fisher判別模型,而每個判別模型都只針對某一特定故障類型,實施故障診斷時就具備了較強的針對性。相比於傳統的基於多分類模型的故障診斷方法,本發明方法可以降低新故障數據的錯分類率。因此,本發明發是一種更為優選的故障分類診斷方法。
附圖說明
圖1為本發明方法的實施流程圖。
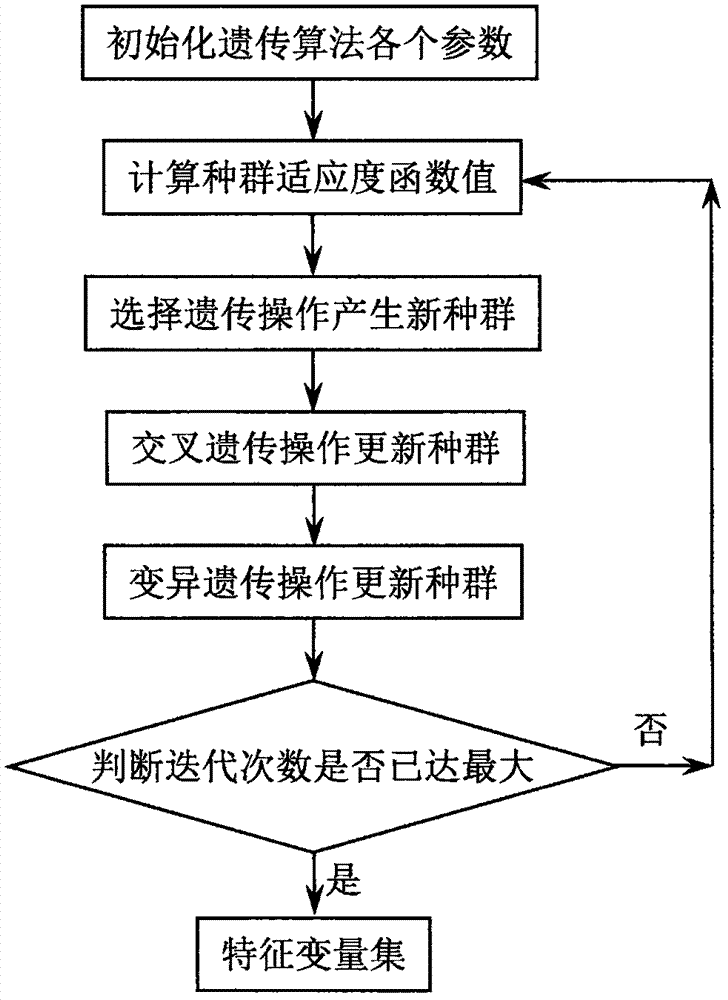
圖2為利用遺傳算法實施變量選擇的流程圖。
圖3為利用fisher判別分析建立兩分類fisher判別模型的實施流程圖。
圖4為對新故障樣本進行故障分類診斷的實施流程圖。
具體實施方式
下面結合附圖對本發明方法進行詳細的說明。
如圖1所示,本發明公開一種基於兩分類fisher判別分析的故障診斷方法,該方法的具體實施步驟如下所示:
步驟1:收集生產過程正常運行狀態下的採樣數據,組成數據矩陣x0∈rn×m,收集生產過程在不同故障操作狀態下的採樣數據,組成不同的參考故障數據集其中,n為訓練樣本數,m為過程測量變量數,下標號c=1,2,…,c表示第c種參考故障類型,nc為第c種故障的可用樣本數,r為實數集,rn×m表示n×m維的實數矩陣。
步驟2:對矩陣x0進行標準化處理,得到均值為0,標準差為1的新數據矩陣並利用矩陣x0的均值向量與標準差向量對進行同樣的標準化處理,得到矩陣
步驟3:利用遺傳算法找出第c種故障類型數據最能區別於正常數據的特徵變量集,記做θc。利用遺傳算法實施變量選擇的流程如圖2所示,具體來講包括如下所示過程:
①初始化遺傳算法的各個參數:主要包括初始化i=1,設置最大迭代次數imax=1000、種群個數p=40、交叉概率以及變異概率τ=0.1,並隨機產生p個,長度為m的二進位代碼;
②計算每個種群(即二進位代碼)所對應的適應度函數值f1,f2,…,fp,並記錄最大適應度值fbest及其對應的種群b,計算適應度函數值的詳細實施過程如下所示:
(a)初始化a=1;
(b)根據第a個種群二進位代碼中的非零元素所在位置,對應選取矩陣與中相應的列,組成新矩陣與
(c)分別計算矩陣與的行均值向量(即將矩陣中各行相加後除以行個數),記為與並計算總體行均值向量
(d)按照如下所示公式計算矩陣s1與s2:
上兩式中,表示xi為矩陣中的行向量,表示xj為矩陣中的行向量,上標號t表示矩陣或向量的轉置;
(e)求解如下所示廣義特徵值問題:
s1β=λs2β(3)
得出最大特徵值λ,該特徵值即為第a個種群的適應度函數值fa。
(f)置a=a+1,判斷a≤p?若是,返回②(b)計算下一個種群的適應度函數值;若否,則執行③
③對p個種群進行選擇遺傳操作得到p個新種群,具體操作過程如下所示:
(a)按照公式rp=(f1+f2+…+fp)/f計算每個種群的概率,並初始化q=1,這些概率值顯然滿足條件:r1<r2<…<rp,其中f=f1+f2+…+fp,p=1,2,…,p表示第p個種群標號;
(b)隨機產生一個位於區間(0,1]中的隨機數γi,並從概率值r1,r2,…,rp中找出滿足條件rp>γi的最小概率值所對應的種群,將該種群保留並記為第i個新種群;
(c)置i=i+1後,判斷i<p?若是,則返回③(b);若否,則將種群b保留並記錄為第p個新種群,初始化j=1並執行④;
④對p個新種群進行交叉遺傳操作更新這p個新種群,具體的操作過程如下所示:
(a)置交叉位置φ為小於m/2的最大整數,隨機產生一個位於區間(0,1]中的隨機數εj;
(b)判斷若是,則對第j個新種群與第j+1個新種群對應的二進位代碼實施交叉遺傳操作(即將兩條代碼的前φ個二進位數進行交換);若否,則不對第j個新種群與第j+1個新種群進行任何操作;
(c)置j=j+2後,判斷j<p?若是,則返回④(a);若否,則將種群b保留並記錄為第p個新種群,初始化k=1並執行⑤;
⑤對p個新種群進行變異操作更新這p個新種群,具體的操作過程如下所示:
(a)置變異位置ω為1至m之間任一隨機整數,隨機產生一個位於區間(0,1]中的隨機數ξk;
(b)並判斷ξk<τ?若是,則對j個新種群中的第ω個二進位數實施變異遺傳操作(即將0變為1或將1變為0);若否,則不對j個新種群採取任何措施;
(c)置k=k+1後,判斷k<p?若是,則返回⑤(a);若否,則置i=i+1並執行⑥;
⑥判斷i≤imax?若是,則將經過選擇、交叉、變異操作的新種群取代原種群,並返回②;若否,則根據最大適應度值所對應的種群b中的非零元素位置,選取相應的變量記錄為特徵變量集θc。
步驟4:利用特徵變量集θc從矩陣與中選出相應的變量(即矩陣的列),對應組成新矩陣與
步驟5:利用fisher判別分析算法建立與之間的兩分類判別模型,並保留模型參數集θc以備調用。利用fisher判別分析建立兩分類fisher判別模型的流程如圖3所示,具體的實施過程如下所示:
①分別計算矩陣與的行均值向量(即將矩陣中各行相加後除以行數),分別記為與並計算總體行均值向量
②按照如下所示公式計算矩陣與
上兩式中,表示為矩陣中的行向量,表示為矩陣中的行向量,上標號t表示矩陣或向量的轉置;
③求解如下所示廣義特徵值問題:
得出最大特徵值η所對應的特徵向量ac;
④根據公式計算向量並計算向量yc的均值與方差δc,那麼第c個兩分類fisher判別模型的參數集
步驟6:重複步驟3~5直至得到所有故障類型的特徵變量集θ1,θ2,…,θc,和兩分類fisher判別模型參數集θ1,θ2,…,θc。
步驟7:當系統已有的故障檢測系統觸發故障警報後,對新採集到的故障樣本z∈r1×m實施故障分類診斷。圖4展示了對新故障樣本進行故障分類診斷的實施流程,具體的實施步驟如下所示:
①利用矩陣x0的均值向量與標準差向量對z進行標準化處理,得到新樣本向量
②利用特徵變量集θ1,θ2,…,θc中記錄的特徵變量,分別從向量中選取相應的列,對應組成新向量
③利用兩分類fisher判別模型參數集θ1,θ2,…,θc中的特徵向量a1,a2,…,ac,根據公式計算得到標量s1,s2,…,sc;
④根據如下所示公式計算新故障樣本z屬於各類參考故障類型的隸屬度gc(z):
⑤找出g1(z),g2(z),…,gc(z)中最大的隸屬度值,它所對應的參考故障類型即為當前新故障樣本z的故障類型。