一種基於決策樹算法的製造業材料採購分析方法與流程
2023-08-02 17:15:06 5
本發明涉及企業管理領域,具體地涉及用算法分析製造業材料採購問題領域。
背景技術:
隨著全球市場一體化以及資訊時代的來臨,專業生產能夠發揮其巨大的作用,企業採購的比重也大大增加,採購的重要性日益被人們所認識。在全球範圍內,在工業企業的產品構成中,採購的原料以及零部件成本隨著行業不同而不同,大體在30%-90%,平均水平在60%以上。從世界範圍來說,對於一個典型的企業,採購成本(包括原材料,零部件)要佔60%。而在中國的工業企業,各種物資的採購成本要佔到企業銷售成本的70%。顯然採購成本是企業管理中的主體和核心部分,採購是企業管理中「最有價值」的部分。另外,根據國家經貿委1999年發布的有關數據,如果國有大中型企業每年降低採購成本2%-3%,則可增加效益500多億人民幣,相當於1997年國有工業企業實現的利潤總和。因此,採購受到了社會各界相當的重視,促使採購研究成為當今社會的熱點問題之一。
C4.5算法是決策樹類算法的一種,由Quinlan於1993年提出,現已居於決策樹經典分類之首。C4.5算法是ID3算法的改進算法,是一種基於信息增益率的決策分析算法。具體而言,它是以算法選擇信息增益的擴充信息增益率為屬性選擇度量,爭取克服算法中關於多值屬性選擇的偏向性問題,其關於決策樹分類器模型的構造過程同算法相同。
C4.5算法產生的分類規則易於理解,準確率較高。但是在構造樹的過程中,需要對數據集進行多次的順序掃描和排序,因而導致算法的效率較低。並且,由於其根據欄位進行分類的特性,當類別較多時,其錯誤率較高。
技術實現要素:
針對現有技術的上述不足,本發明要解決的技術問題是提供一種基於C4.5算法的製造業材料採購分析方法。
本發明的目的是克服現有技術中存在的問題:C4.5算法掃描樣本次數多效率低,準確率達不到想要效果以及C4.5在物料採購分析時只是基於欄位分析,錯誤率高。
本發明為實現上述目的所採用的技術方案是:一種基於C4.5算法的製造業材料採購分析方法。該算法的步驟如下:
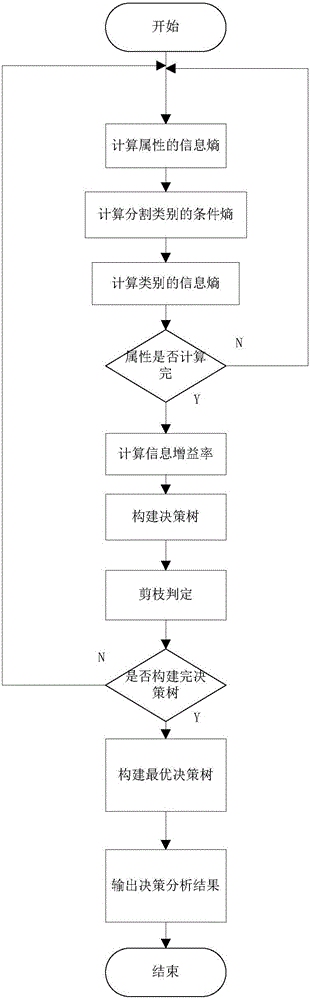
步驟1:計算屬性的信息熵:把採購的供應商、價格、數量等信息作為C4.5算法的樣本集參數,按照算法計算出屬性的信息熵。
步驟2:計算分割後的類別的條件熵:將樣本集分割成若干個屬性,計算屬性條件熵。
步驟3:計算類別的信息熵:利用信息熵公式計算類別的信息熵。
步驟4:判斷所有屬性是否計算完,已計算完轉到步驟1,否則轉步驟5。
步驟5:計算信息增益率:信息增益率為屬性的信息熵與類別信息熵之差。
步驟6:按分裂屬性值創建決策樹:在某一屬性集合中將最大增益率的屬性作為分列屬性,將最大增益率的屬性作為樹雙親結點,其餘的作為該結點的孩子。
步驟7:剪枝判定:當決策樹劃分得太細,數據量很大時,需要設定一個規則,使算法及時收斂,避免算法的無限分支和無限增長,即剪枝。本發明採用前剪枝法結合樹深度限定法對決策樹進行剪枝。
步驟8:判斷是否構建完決策樹,如果構建完成,則轉步驟9,否則轉步驟1。
步驟9:輸出決策分析結果:本發明採用後剪枝法對建立好的決策樹進行剪枝,構建最優決策樹。最優決策樹即為決策分析結果。
本發明的有益效果是:
1.通過前剪枝法和樹深度限定法對決策樹的分割進行限制,防止算法無限發散。
2.利用信息增益標準差作為前剪枝法的限定條件,提高了算法的準確率。
3.通過後剪枝法構建最優決策樹。簡單有效,易於實現和理解。最優決策樹將給出一個確定的採購方案,簡單明了,實用性高。
附圖說明
圖1為一種基於C4.5算法的製造業材料採購分析方法流程圖
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,以下結合算法流程圖 進行詳細、具體說明。
一、算法基本思想
決策樹是一種基於分類思想的決策分析方法,ID3算法是基於信息增量的決策樹分析算法,C4.5算法是ID3算法的改進算法,是一種基於信息增益率的決策分析算法。本發明通過利用改進的C4.5算法分析預測製造業材料的採購問題。通過前剪枝法和樹深度限定法對決策樹的分割進行限制,通過後剪枝法構建最優決策樹。最優決策樹將給出一個確定的採購方案,即:哪個材料到哪個供應商那裡去採購,採購多少,才能保證作業車間生產正常有序進行。
二、具體實施步驟
將物料供應商的類型、等級、所能供給的數量、所供給物料的質量信用度、供應商規模等信息抽象到C4.5算法中,作為算法的數據樣本、屬性等參數。具體問題具體給出對應的參數關係。改進的C4.5算法具體實施步驟如下:
步驟1:計算屬性的信息熵:設S為已知類標號的數據樣本集,類標號屬性為C={Ci|i=1,2,...,z},定義了m個不同類的Ci(i=1,2,...,z)。設Ci,s是S中Ci類數據樣本的集合,|S|和|Ci,s|分別表示S和Ci,s的樣本個數。則對Ci,s的信息熵Info(S)定義如下:
其中,pi是Ci,s中任意數據樣本屬於類Ci的概率,Info(S)的實際意義是類別S中數據樣本分類的平均信息量。
步驟2:計算分割後的類別的條件熵:若分類屬性Ai={aij|j=1,2,...,ni}將S劃分成ni個不同的子集Sij={(Xi,Yi)∈S|xij=aij}表示數據樣本集S中在Ai上的取值為aij的所有樣本組成的集合。選擇S的一個屬性A,則類別分割後的類別條件熵計算公式為:
步驟3:計算類別的信息熵:若選擇屬性Ai作為分裂屬性,則類別信息熵為:
步驟4:判斷所有屬性是否計算完,已計算完轉到步驟1,否則轉步驟5。
步驟5:信息增益率的計算:信息增益率使用分裂信息值將信息增益規範化。屬性Ai的信息增益為
從信息增益的計算公式可以看出,Gain(Ai)的實際意義是基於屬性Ai分裂後,數據集所含信息量的有效減少量。信息增益越大,表明按屬性Ai對數據集分裂所需的期望信息越少,即屬性Ai解決的不確定信息量越大,分裂後的輸出分區越純。
則信息增益率為:
步驟6:按分裂屬性值創建決策樹:決策樹基於數據結構中樹的概念。決策樹C4.5的創建是通過將所有屬性的信息增益率按大小排序,然後將各個屬性作為分支的根節點的順序。
在某一屬性集合中將最大增益率的屬性作為分列屬性,即θ=max{GainRatio(A)},即將最大增益率的屬性作為樹雙親結點,其餘的作為該結點的孩子。
步驟7:剪枝判定:當決策樹劃分得太細,數據量很大時,需要設定一個規則,使算法及時收斂,避免算法無限分支無限增長,即剪枝。本發明採用前剪枝法結合樹深度限定法對決策樹進行剪枝。具體的實施如下:
前剪枝法:前剪枝法是指在構造樹的過程中知道某些節點可以剪掉時,就不對此類節點進行分裂。本發明通過計算增益率方差來確定是否對某一節點剪枝。增益率標準差大於某一設定值,則對該節點剪枝,否則可以分割建立其子樹。數學公式描述為:
σi=GainRatio(Ai)-μ
如果σi>ε(標準差限定值),則剪枝,否則繼續分割生成決策子樹。
樹深度限定法:設定一個確定的樹深度值L,當決策樹的深度到達L以後,停止分割。
步驟8:判斷是否構建完決策樹,如果構建完成,則轉步驟9,否則轉步驟1。
步驟9:輸出決策分析結果:創建了決策樹後,可以清晰的看到各個屬性的效果,但是要得到一個具體的方案,還需要進一步的分析才能得到確切的決策方案。本發明採用後剪枝法對建立好的決策樹進行剪枝,最後留下最優決策樹作為最終的決策樹。後剪枝方法描述為:在建立好一顆決策樹以後,通過一定的剪枝標準來確定該剪掉的子樹。本發明對後剪枝標準設定為:通過計算價值函數值,來判定如何構建最優決策樹。價值函數用信息增益來刻畫。具體計算如下:
(1)在決策樹的第L層剪枝:
計算第L層節點的價值函數值:cl,i=Gain(Ai)。
選第L層節點中價值函數值最大的節點作為最優決策樹第L層的右孩子,選該右孩子的兄弟節點中價值函數值最大的兄弟節點作為最優決策樹第L層的左孩子。其餘的第L層的節點剪掉。
(2)在決策樹第2層到(L-1)層節點剪枝:
計算第l層的價值函數:
cl,i=cl+1,i+Gain(Ai),l=2,3,...,(L-1)。
其中,cl+1,i為第l層節點的在第(l+1)層的還未被剪掉的孩子價值,明顯地,如果沒有留下來的孩子,則cl+1,i=0。同樣的,選第l層節點中價值函數值最大的節點作為最優決策樹第l層的右孩子,選該右孩子的兄弟節點中價值函數值最大的兄弟節點作為最優決策樹第l層的左孩子。其餘的第l層的節點剪掉。如此下去,最終會得到一棵最優決策樹。最優決策樹即為決策分析結果。