一種基於內存的頻繁模式挖掘方法與流程
2023-05-29 07:20:46 1
本發明屬於存儲器技術領域,具體涉及一種基於內存的頻繁模式挖掘方法。
背景技術:
隨著計算機科技的日益成熟,數據分析自20世紀確立以來有了極大的發展。數據分析能夠在海量數據中發現並提取出感興趣的項目,從而給決策機構提供指導意見。機器學習和數據挖掘能夠揭示數據背後隱藏的信息,已成為是數據分析的關鍵技術。
在數據挖掘領域中,發現數據集中的頻繁項或頻繁模式是數據挖掘研究中的一個重要課題,它是相關性分析、序列模式、因果關係、顯露模式等許多重要數據挖掘任務的基礎。目前有諸如Apriori和FP-tree等技術來處理頻繁模式挖掘問題。
由於基於內存的頻繁模式挖掘方法的條件是,被挖掘數據和數據元是保存在字節尋址寄存器上的,而DRAM要求需要持續供電來保持數據,因此,能效和持久性可能成為數據挖掘系統中的關鍵設計問題。為了解決該類問題,在基於內存的數據分析中如相變存儲器(PCM)等非易失性存儲器(NVM)由於其出色的非易失性和能效性能,通常被認為是DRAM的優秀替代品。但使用NVM作為主存又存在以下的問題:一是對NVM的讀寫操作時間差異比較大,讀操作通常比寫操作所耗費的時間和能量更多;二是NVM寫操作次數有限,不均勻的寫操作通常會加速整塊NVM失效。正是由於缺乏對NVM本質特點的考慮,目前在NVM上進行的數據挖掘與機器學習算法嚴重影響存儲系統的性能和壽命。
現有技術採用一種叫做FP-tree算法的技術方案,它是對Apriori算法的改進,將頻繁模式的關鍵信息壓縮為頻繁模式樹(FP-tree)的結構,以減少Apriori算法中開銷巨大的候補項,從而解決了Apriori算法的性能瓶頸。簡單地說,FP-tree算法是在不生成候選項的情況下,完成Apriori算法的功能。
J. Han, J. Pei, and Y. Yin. Mining frequent patterns without candidate generation. ACM SIGMOD International Conference on Management of Data (SIGMOD』00), 29(2):1–12, May 2000.(J. Han, J. Pei, and Y. Yin. 「不產生候選項的頻繁模式挖掘」,數據管理國際會議, 29(2):1–12, 2000.05.)記載了FP-tree算法的步驟如下:
(1) 掃描整個事務資料庫D一次,獲得D中所包含的全部項的支持度計數,排除支持度計數值小於閾值的項,剩餘的項即為頻繁項,對頻繁項按其支持度計數降序排列得到一個列表L;
(2) 創建FP-tree的根節點T,以「null」標記。再次掃描事務資料庫。對D中每個事務,將其中的頻繁項選出並按L中的次序排序。設排序後的頻繁項表為[p|P],其中p是第一個頻繁項,而P是剩餘的頻繁項。調用insert_tree([p|P],T)。insert_tree([p|P],T)過程執行情況如下:如果T有子女N使N .item_name=p.item_name,則N的計數增加1;否則創建一個新結點N,將其計數設置為1,連結到它的父結點T。如果P非空,遞歸地調用insert_tree(P,N)。
經過以上步驟,就建立好了一棵完整的FP-tree。最後根據建立好的FP-tree由下往上循序進行挖掘,即可產生所需要的頻繁模式。簡言之可描述為利用事務資料庫中的信息構造FP-tree,然後從FP-tree中挖掘頻繁模式。其核心思想是直接壓縮資料庫構建一個頻繁模式樹,然後通過這棵樹生成關聯規則。
圖1給出了FP-tree的構建過程示例。圖1(a)為資料庫,其中「交易ID」為每一條交易記錄的序號,「項目」為每一條交易記錄中的所有項,「排序後的項」為按照每個項出現次數降序排列後的項;首先建立一個標籤為null的結點作為整個頻繁模式樹的根節點,掃描第一條交易記錄後,建立結點a,並令結點a的計數域的值為1,表明項目a出現1次,如圖1(b)所示;掃描第二條交易記錄後,依次建立結點b,c,d,其結點計數域的值均為1,表明項目b,c,d也分別出現1次,如圖1(c)所示;依次掃描完資料庫中所有交易記錄後,建立的完整的FP-tree如圖1(d)所示,其中各字母表示資料庫中的項,字母後的數字表示計數域中存儲的值,即為該項在資料庫中出現的次數。
但FP-tree算法存在的問題有:在構建頻繁模式樹的過程中,每掃描一條事務中的一個項,都要對FP-tree進行更新操作,即對FP-tree中對應項的結點計數域進行寫操作,這就導致了大量重複的寫操作,內存開銷巨大;且越靠近根節點的寫操作越多,密集的大量寫操作會導致NVM的使用壽命減少。
技術實現要素:
針對現有技術存在的問題,本發明所要解決的技術問題就是提供一種基於內存的頻繁模式挖掘方法,它能減少在構建頻繁模式樹過程中對NVM的寫操作,能避免密集的大量寫操作,達到延長NVM壽命的目的
本發明所要解決的技術問題是通過這樣的技術方案實現的,它包括以下步驟:
步驟1,構建頻繁模式初始樹
1)、依次掃描資料庫中的每一條交易記錄,獲得資料庫中所包含的全部項的支持度計數,排除支持度計數值小於閾值的項,剩餘的項即為頻繁項,對頻繁項按其支持度計數降序排列得到一個列表L;
2)、創建頻繁模式樹的根結點T,以「null」標記;
3)、再次掃描資料庫,將讀取的每條事務中的頻繁項選出並按L中的次序排序;排序後以null為根結點構建一條頻繁模式樹的路徑,只對路徑上位於最末的結點的計數加1,路徑上的其他結點的計數保持不變;依次掃描完整個資料庫中所有事務後獲得頻繁模式初始樹;
步驟2,用深度優先搜索算法對頻繁模式初始樹依次進行遍歷,遍歷結點的計數器值為該結點本身的值加上其所有孩子結點的值。
本發明的頻繁模式樹中所有元素的計數域的值即為該元素在整個資料庫中出現的次數,與現有技術的頻繁模式挖掘算法構建的樹一樣。
與現有技術相比,本發明的技術效果是:
本發明不再對當前整條事務中的所有項的結點的計數域進行更新操作,避免了在構建頻繁模式樹過程中的大量重複的寫操作,減少對NVM的寫操作,能快速的構建頻繁模式樹;且能減少對靠近根結點的結點計數域的大量密集的寫操作,延長了NVM壽命。
附圖說明
本發明的附圖說明如下:
圖1為背景技術中的頻繁模式樹的構建示例圖;
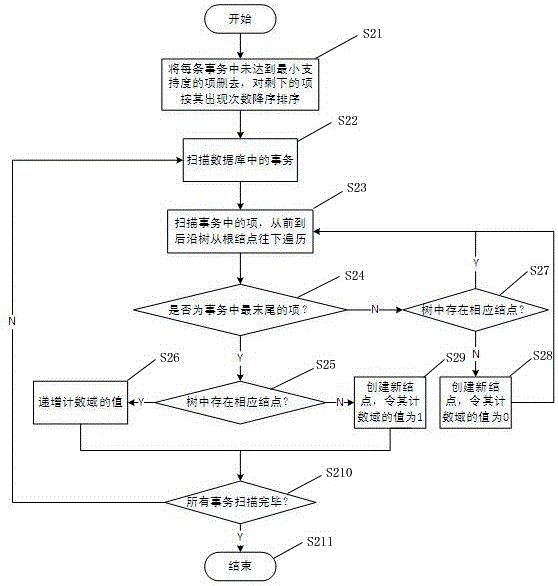
圖2為本發明構建頻繁模式初始樹的流程圖;
圖3為本發明的頻繁模式樹的構建示例圖;
圖4為試驗中讀操作測試的對比圖;
圖5為試驗中寫操作測試的對比圖;
圖6為試驗中構建樹時間測試的對比圖;
圖7為試驗中PCM壽命測試的對比圖。
具體實施方式
下面結合附圖和實施例對本發明作進一步說明:
本發明的輸入是資料庫和最小支持度閾值σ,輸出是FP-tree。
本發明包括以下步驟:
步驟1,構建頻繁模式初始樹
1)、依次掃描資料庫中的每一條交易記錄,獲得資料庫中所包含的全部項的支持度計數,排除支持度計數值小於閾值的項,剩餘的項即為頻繁項,對頻繁項按其支持度計數降序排列得到一個列表L;
2)、創建頻繁模式樹的根結點T,以「null」標記;
3)、再次掃描資料庫,將讀取的每條事務中的頻繁項選出並按L中的次序排序;排序後以null為根結點構建一條頻繁模式樹的路徑,只對路徑上位於最末的結點的計數加1,路徑上的其他結點的計數保持不變;依次掃描完整個資料庫中所有事務後獲得頻繁模式初始樹。
圖2為本發明構建頻繁模式初始樹的流程圖,其流程如下:
在步驟S21,將每個事務中未達到最小支持度的項刪去,對剩下的項按其出現次數降序排序;
在步驟S22,依次掃描資料庫中的事務;
在步驟S23,依次掃描事務中的每一個項,從前到後沿樹從根結點往下遍歷;
在步驟S24,判斷當前項是否為事務中最末尾的項,若是,執行步驟S25;如不是,則執行步驟S27;
在步驟S25,判斷樹中是否存在相應結點,如存在,則執行步驟S26;如不存在,則執行步驟S29;
在步驟S26,遞增該項中計數域的值;然後轉至步驟S210;
在步驟S27,判斷樹中是否存在相應結點,如存在,則返回步驟S23;如不存在,則執行步驟S28;
在步驟S28,創建新結點,令其計數域的值為0;然後回步驟S23;
在步驟S29,創建新結點,令其計數域的值為1;然後轉至步驟S210;
在步驟S210,判斷所有事務是否掃描完畢,若未掃描完畢,則返回步驟S22;若掃描完畢,則執行步驟S211
在步驟S211,程序結束;
步驟2,構建完整的頻繁模式樹
用深度優先搜索算法對頻繁模式初始樹依次進行遍歷,遍歷結點的計數器值為該結點本身的值加上其所有孩子結點的值。
實施例
圖3為本發明構建頻繁模式樹的一個實例,本實施例包括以下步驟:
步驟1,根據圖3(a)資料庫構建頻繁模式初始樹,具體過程如下:
如圖3(b)所示,建立一個標籤為null的結點作為整個頻繁模式樹的根節點;掃描第一條交易記錄後,建立結點a,令結點a的計數域值為1,表明項目a出現1次;
如圖3(c)所示,掃描第二條交易記錄後,構建結點b、c、d,令b、c的count域值為0,d的count域值為1,表明項目d出現1次(此時為了減少構建頻繁模式樹時產生冗餘的寫,並不記錄b,c出現的次數,僅記錄位於該條交易記錄末尾的項d出現的次數,因為之後b,c出現的次數可根據其孩子結點的計數域的值得到);
如圖3(d)所示,依次掃描完整個資料庫所有交易記錄後所構建出的初始樹;
步驟2,構建完整的頻繁模式樹
如圖3(e)所示,用深度優先搜索算法對頻繁模式初始樹依次進行遍歷,遍歷結點的計數器值為該結點本身的值加上其所有孩子結點的值。例如c計數域的值為c原來的值0與d計數域的值5之和,最終得出c出現5次;f計數域的值為f的孩子結點e和g的值與f原來的值3之和,最終得出f出現6次。依次遍歷完頻繁模式樹之後,構建出完整的頻繁模式樹。
實驗測試
選取不同類型的數據集進行試驗,統計各個數據集的讀寫操作次數、總的構建樹的時間和PCM壽命。這些數據集的名稱分別為T10I4D100K、T40I10D100K、chess、mushroom、pumsb*、connect、pumsb、accidents、C73D10、C20D10。
實驗結果參見圖4至圖7:
圖4中,縱坐標代表讀的次數,橫坐標代表各個數據集,從圖4看出,本發明減少了大量的讀操作;
圖5中,縱坐標代表寫的次數,橫坐標代表各個數據集,從圖5看出,本發明減少了大量的寫操作;
圖6中,縱坐標代表總的構建樹的時間,橫坐標代表各個數據集,從圖6看出,本發明減少了構建樹的時間;
圖7中,縱坐標代表直到PCM被寫壞,能處理的總的交易數目,橫坐標代表各個數據集,從圖7中看出,本發明最少可延長PCM的壽命為16.67%(發生在數據集T40I10D100K),最大可延長99.05%(發生在數據集connect),極大地延長了PCM的壽命。