對網頁中高頻關鍵詞進行聚類的方法及裝置與流程
2023-05-28 11:03:06 3
本發明涉及網際網路領域,具體而言,涉及一種對網頁中高頻關鍵詞進行聚類的方法及裝置。
背景技術:
在網際網路信息急劇增加的情況下,如何發現最有價值的信息是尚未解決的問題。因為信息會通過多種渠道和形式發布,甚至出現同一條信息有不同描述的情況,為讀者準確獲取某類別的信息帶來一定障礙。為了有效獲取不同類型的信息,現有技術會對多篇網頁文檔進行聚類,然而,現有技術的聚類方式是基於網頁文檔全文的,由於網頁文檔全文的信息量較大,對全文的聚類需耗費較大工作量;同時,全文裡涉及內容較多,一些詞語並不能反映文檔的主要內容,這些詞語會影響文檔聚類的準確性。因此,對通過全文對網頁文檔進行聚類不能滿足對信息的聚類要求。
技術實現要素:
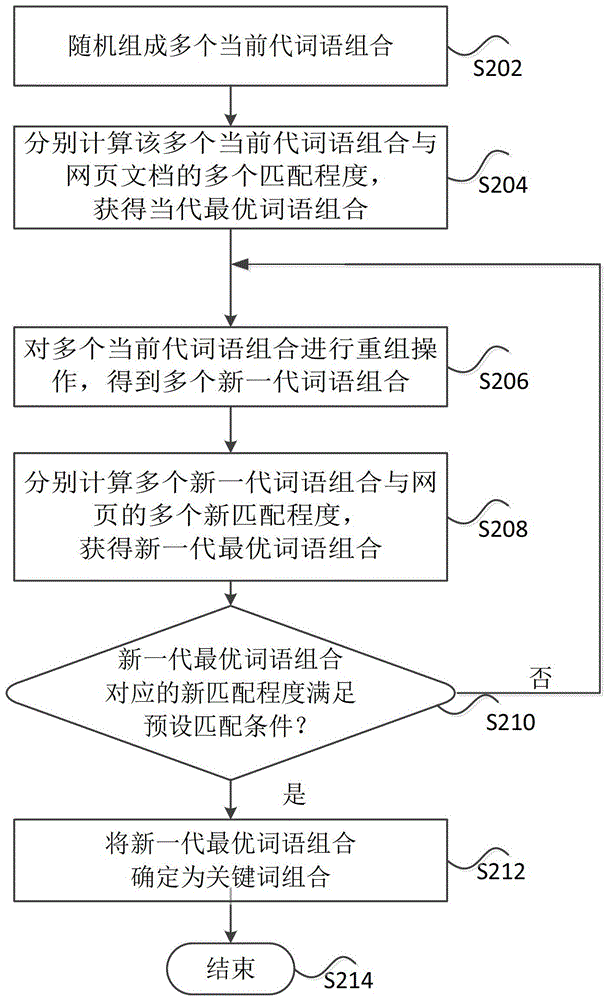
本發明實施例提供一種對網頁中高頻關鍵詞進行聚類的方法和裝置,以提供對網頁文檔更準確的分類方案。本發明為了實現上述目的,提供一種對多個網頁中高頻關鍵詞進行聚類的方法,包括:抓取所述多個網頁對應的多個網頁文檔;對抓取到的所述多個網頁文檔中的各個網頁文檔進行分詞以獲取多個詞語;確定各個網頁文檔對應的關鍵詞組合,其中,所述關鍵詞組合包括表徵對應網頁文檔內容的關鍵詞;從多個關鍵詞組合中獲取高頻關鍵詞,其中,所述高頻關鍵詞為多個關鍵詞組合中在預設時間周期內滿足預設條件的關鍵詞;以及按相似度對所述高頻關鍵詞進行聚類,以獲得同類高頻關鍵詞。在一個實施例中,確定各個網頁文檔對應的關鍵詞組合包括:隨機組成多個當前代詞語組合;計算所述多個當前代詞語組合與所述網頁文檔的匹配程度,獲得當前代最優個體;對所述多個當前代詞語組合進行重組操作,得到多個新一代詞語組合;計算所述多個新一代詞語組合與所述網頁文檔的多個新匹配程度,獲得新一代最優個體;判斷所述新一代最優個體對應的新匹配程度是否滿足預設匹配條件;以及在所述新匹配程度不滿足所述預設匹配條件時,重複所述重組操作,在所述新匹配程度滿足所述預設匹配條件時,將所述新一代最優個體確定為所述關鍵詞組合。在一個實施例中,計算所述詞語組合與所述網頁文檔的匹配程度包括:獲取網頁文檔中的詞語總數量;根據詞頻和反向文檔頻計算各詞語的詞頻值;根據所述詞語組合中各詞語的詞頻值和所述網頁文檔的詞語總數量對所述詞語組合進行矢量化,得到詞語組合矢量;根據所述網頁文檔中各詞語的詞頻值和所述網頁文檔的詞語總數量對所述網頁文檔進行矢量化,得到文檔矢量;以及根據所述詞語組合矢量和所述文檔矢量的矢量參數計算所述詞語組合的個體適應度,其中,所述個體適應度作為所述匹配程度的依據。在一個實施例中,從多個關鍵詞組合中獲取高頻關鍵詞包括:分別獲取所述多個網頁文檔對應的所述關鍵詞組合中所述多個關鍵詞的訪問數量,所述訪問數量為在所述預設時間周期內所述關鍵詞組合對應網頁文檔的獨立訪客數量;將所述訪問數量滿足預設數量條件的關鍵詞確定為所述多個網頁文檔的高頻關鍵詞。在一個實施例中,按相似度對所述高頻關鍵詞進行聚類包括:分別獲取所述多個網頁文檔對應的所述關鍵詞組合中所述多個關鍵詞的訪問數量,所述訪問數量為在所述預設時間周期內所述關鍵詞組合對應網頁文檔的獨立訪客數量;獲取各關鍵詞的訪問數量在所述預設時間周期內隨時間的變化趨勢;將所述變化趨勢的相似係數滿足預設係數條件的多個關鍵詞作為同類高頻關鍵詞。在一個實施例中,在按相似度對所述高頻關鍵詞進行聚類之後,所述方法還包括:將所述同類高頻關鍵詞對應的網頁文檔以話題的形式推送至用戶。在一個實施例中,抓取所述多個網頁對應的所述多個網頁文檔中包括:確定各個網頁中各行的字數;計算各個網頁的字數的標準差;在一個網頁中,當連續多行的字數大於所述標準差時,確定字數大於標準差的連續多行的文字為網頁文檔。本發明為了實現上述目的,提供一種對多個網頁中高頻關鍵詞進行聚類的裝置,包括:抓取單元,用於抓取所述多個網頁對應的多個網頁文檔;分詞單元,用於對抓取到的所述多個網頁文檔中的各個網頁文檔進行分詞以獲取多個詞語;確定單元,用於確定各個網頁文檔對應的關鍵詞組合,其中,所述關鍵詞組合包括表徵對應網頁文檔內容的關鍵詞;獲取單元,用於從多個關鍵詞組合中獲取高頻關鍵詞,其中,所述高頻關鍵詞為多個關鍵詞組合中在預設時間周期內滿足預設條件的關鍵詞;聚類單元,用於按相似度對所述高頻關鍵詞進行聚類,以獲得同類高頻關鍵詞。在一個實施例中,所述確定單元包括:組合子單元,用於隨機組成多個當前代詞語組合;第一計算子單元,用於計算所述當前代詞語組合與所述網頁文檔的匹配程度,獲得當前代最優詞語組合;重組子單元,用於對所述多個當前代詞語組合進行重組操作,得到多個新一代詞語組合;第二計算子單元,用於計算所述多個新一代詞語組合與所述網頁文檔的多個新匹配程度,獲得新一代最優詞語組合;判斷子單元,用於判斷所述新一代最優詞語組合對應的新匹配程度是否滿足預設匹配條件,以及確定子單元,在所述新匹配程度不滿足所述預設匹配條件時,重複所述重組操作,在所述新匹配程度滿足所述預設匹配條件時,將所述新一代最優個體確定為所述關鍵詞組合。在一個實施例中,所述第二計算子單元包括:獲取模塊,用於獲取網頁文檔中的詞語總數量;第一計算模塊,用於根據詞頻和反向文檔頻計算各詞語的詞頻值;第一矢量模塊,用於根據所述詞語組合中各詞語的詞頻值和所述網頁文檔的詞語總數量對所述詞語組合進行矢量化,得到詞語組合矢量;第二矢量模塊,用於根據所述網頁文檔中各詞語的詞頻值和所述網頁文檔的詞語總數量對所述網頁文檔進行矢量化,得到文檔矢量;以及第二計算模塊,用於根據所述詞語組合矢量和所述文檔矢量的矢量參數計算所述詞語組合的個體適應度,其中,所述個體適應度作為所述匹配程度的依據。本發明為了實現上述目的,提供一種對多個文檔進行分類的方法,包括:獲取所述多個文檔;對所述多個文檔分別進行分詞以獲取多個詞語;確定每個文檔對應的關鍵詞組合,其中,所述關鍵詞組合包括表徵對應文檔內容的關鍵詞;將包括相同關鍵詞的文檔分到相同類別。在一個實施例中,確定文檔對應的關鍵詞組合包括:通過遺傳算法從所述關鍵詞中確定關鍵詞組合。在一個實施例中,通過遺傳算法從所述關鍵詞中確定關鍵詞組合包括:將所述多個詞語初始化為多個詞語組合;對所述多個詞語組合進行複製、交叉及變異操作,獲得下一代詞語組合;計算所述下一代詞語組合與所述文檔的匹配程度;以及在所述匹配程度滿足預設條件時終止所述遺傳算法,得到所述關鍵詞組合。在一個實施例中,計算經過所述遺傳算法的所述詞語組合與所述文檔的匹配程度包括:獲取文檔中的詞語總數量;根據詞頻和反向文檔頻計算各詞語的詞頻值;根據所述詞語組合中各詞語的詞頻值和所述文檔的詞語總數量對所述詞語組合進行矢量化,得到詞語組合矢量;根據所述文檔中各詞語的詞頻值和所述文檔的詞語總數量對所述文檔進行矢量化,得到文檔矢量;以及根據所述詞語組合矢量和所述文檔矢量的矢量參數計算所述詞語組合的個體適應度,其中,所述個體適應度作為所述匹配程度的依據。本發明為了實現上述目的,提供一種對多個文檔進行分類的裝置,包括:獲取單元,用於獲取所述多個文檔;分詞單元,對所述多個文檔分別進行分詞以獲取多個詞語;確定單元,用於確定每個文檔對應的關鍵詞組合,其中,所述關鍵詞組合包括表徵對應文檔內容的關鍵詞;分類單元,用於將包括相同關鍵詞的文檔分到相同類別。在一個實施例中,所述確定單元還用於:通過遺傳算法從所述關鍵詞中確定關鍵詞組合。在一個實施例中,所述確定單元包括:組合子單元,用於將所述多個詞語初始化為多個詞語組合;處理子單元,用於對所述多個詞語組合進行複製、交叉及變異操作,獲得下一代詞語組合;計算子單元,用於計算所述下一代詞語組合與所述文檔的匹配程度;以及終止子單元,用於在所述匹配程度滿足預設條件時終止所述遺傳算法,得到所述關鍵詞組合。本發明通過提取關鍵詞組合來準確和全面地反映網頁文檔的內容,再對組合中的關鍵詞重新聚類,將具有關聯性的網頁文檔劃分在同一話題中,從而使用戶更加方便地閱讀同一話題的網頁文檔,簡化了用戶對信息的搜集,節省了用戶的時間。附圖說明構成本申請的一部分的附圖用來提供對本發明的進一步理解,本發明的示意性實施例及其說明用於解釋本發明,並不構成對本發明的不當限定。在附圖中:圖1是根據本發明實施例的對多個網頁中高頻關鍵詞進行聚類的方法的流程圖;圖2是根據本發明實施例的關鍵詞組合的確定方法的流程圖;圖3是根據本發明實施例的適應度計算方法的流程圖;圖4A是根據本發明實施例的獲取同類高頻關鍵詞方法的流程圖;圖4B為根據本發明實施例的關鍵詞聚類二叉樹示意圖,圖5是根據發明實施例的對多個網頁中高頻關鍵詞進行聚類的裝置的結構框圖;圖6是根據本發明實施例的確定單元的結構框圖;圖7是根據本發明實施例的第一計算子單元的結構框圖;圖8是根據本發明實施例的聚類單元510的結構框圖;圖9是根據本發明實施例的對文檔進行分類的方法的流程圖;圖10是根據本發明實施例的文檔的分類裝置的結構框圖;圖11是根據本發明實施例的確定單元1006的結構框圖。具體實施方式需要說明的是,在不衝突的情況下,本申請中的實施例及實施例中的特徵可以相互組合。下面將參考附圖並結合實施例來詳細說明本發明。本實施例的目的之一是對信息進行聚類,形成話題,話題是高頻關鍵詞組合,高頻關鍵詞是滿足一定條件的表徵文檔內容的關鍵詞,通過確定不同話題,便於網際網路用戶更加便捷地獲取所需的信息。基於此,本發明實施例提供了一種對多個網頁中高頻關鍵詞進行聚類的方法。圖1是根據本發明實施例的對多個網頁中高頻關鍵詞進行聚類的方法的流程圖。如圖1所示,該方法包括如下的步驟S102至步驟S110。步驟S102,抓取多個網頁對應的多個網頁文檔。本步驟可具體按以下方式完成:首先,從瀏覽器日誌中提取用戶訪問記錄,包括用戶唯一識別標識和用戶訪問過的統一資源定位符(UniformResourceLocator,URL),為避免重複抓取,可根據URL的哈希值進行排重過濾。然後,遍歷排重後的URL集合抓取網頁源碼。接著,可以對超文本標記語言(HypertextMarkupLanguage,HTML)進行格式化,因不規範的HTML代碼及噪音數據會嚴重影響正文提取的效果,所以首先對原始HTML代碼進行格式化。補齊不對稱的HTML標籤(如」表格」,格式化後為」表格」),使用正則表達式初步刪除噪音數據(如javascript和css代碼等)。為了更加準確的獲取網頁文本內容的信息,還可以獲取多個網頁文檔。首先可以確定各個網頁文本中各行的字數,以回車符作為換行標識,計算每行的字數LN,本實施例中的字數可以指非標籤字符的字數。然後計算各個網頁或整篇文檔的字數的標準差SD。在一個網頁中,當連續多行的字數大於標準差時,確定字數大於標準差的連續多行的文字為網頁文檔。具體地,字數超過標準差的行間距均值LS,從網頁文本中選取多個目標區塊,最終的網頁文檔從目標區塊中得出,目標區塊可以根據以下標準進行選取:以LN>SD的行作為目標區塊開始,以n表示當前行下標,若n+LS行中不存在任意行字數超過SD,則第n行作為目標區塊結束,在本實施例中,開始行和結束行為同一行的,不被認為是目標區塊。例如,格式化後的HTML源碼字數分布如下:以上舉例計算可得:字數標準差SD=4.4,超過標準差的行間距均值LS=1,所以可以從該網頁文檔中選取兩個目標區塊,以行標表示分別為目標區塊一{3,4,5}和目標區塊二{9,10},因為目標區塊一的字數最多,所以確定目標區塊一內的文本為網頁文檔。返回圖1中的步驟S104,對抓取到的多個網頁文檔中的各個網頁文檔進行分詞以獲取多個詞語。分詞過程基於詞庫的正向最大匹配,非詞庫中的連續出現的英文數字混排字符也會作分詞處理。首先可以獲取詞庫,其中,詞庫中包括常用的詞彙,例如各常用的動詞和名詞。然後將網頁文檔中的文字與詞庫匹配以進行分詞。例如對於「我想看電影」,分別可以和詞庫裡的「我」「想」「看」和「電影」匹配,因此,不會出現「看電」這樣的分詞。步驟S106,確定各個網頁文檔對應的關鍵詞組合,其中,關鍵詞組合包括表徵對應網頁文檔內容的關鍵詞。一般來講,每個網頁文檔唯一對應一個關鍵詞組合。關鍵詞組合中詞語的數量可預先設置,當多個詞語組成的特定組合與網頁文檔的匹配程度滿足預設匹配程度時,確定特定組合為關鍵詞組合。例如預設一篇網頁文檔的關鍵詞組合由4個關鍵詞組成,當某網頁文檔中由「中國」「鳥巢」「08」「奧運」組成的詞語組合與該網頁文檔的匹配程度滿足預設匹配程度時,那麼這個詞語組合就是這篇網頁文檔的關鍵詞組合。圖2是根據本發明實施例的關鍵詞組合的確定方法的流程圖。步驟S202,隨機組成多個當前代詞語組合。本步驟通過隨機組成詞語組合進行種群初始化。在利用遺傳算法對網頁文檔中的關鍵詞進行計算時,種群、個體及基因的相應定義如下:種群為多組詞語組合,其中每個詞語組合為單獨個體,每個詞語組合中的一個詞語即為基因。種群、個體、基因的關係為:多個詞語(基因)組成一個詞語組合(個體),多個詞語組合(個體)組成一個種群。對各篇文章中的所有詞語進行種群初始化,即將這些詞語隨機分為多個詞語組合,定義這多個詞語組合為種群,例如,某篇文檔共包括X個詞語,預設每個詞語組合包括N個詞語,將該X個詞語分為Y個詞語組合(X=N*Y),Y個詞語組合稱為一個種群,N個詞語組成的一個詞語組合稱為一個體。種群大小,即個體數指該種群的Y值,一個種群的種群大小和個體數可以進行預設。步驟S204,計算當前代詞語組合與網頁文檔的匹配程度,獲得當前代最優詞語組合。在本實施例中,以詞語組合的個體適應度作為匹配程度的依據。匹配度最高的詞語組合為當前代的最優個體。圖3是根據本發明實施例的適應度計算方法的流程圖。步驟S302,獲取網頁文檔中的詞語總數量。例如,一篇網頁文檔中有10個不同詞語,則詞語總數量為10。步驟S304,根據詞頻(TermFrequency,TF)和反向文檔頻(InverseDocumentFrequency,IF)計算各詞語的詞頻值。具體地,在本篇網頁文檔中出現頻率越高,則詞頻越高,在其他網頁文檔中出現頻率越低,則反向文檔頻越高,例如,在西遊記的某一個章節中,「孫悟空」出現頻率很高,TF為3,而「孫悟空」在另一篇網頁文檔中出現次數很少,IDF可能為5,根據用戶需求設置一個詞頻值的計算公式,帶入TF和IDF的值,則可以算出該詞語的詞頻值。步驟S306,根據詞語組合中各詞語的詞頻值和網頁文檔的詞語總數量對詞語組合進行矢量化。通過本步驟可以得到詞語組合矢量。例如,網頁文檔由3個不同的詞語組成,關鍵詞組合包含2個詞語,因此建立一個3維坐標系。如果以上3個詞的詞頻值分別是1,2,3,則第一個詞語經矢量化得到的矢量為(1,0,0,),第二個詞語經矢量化得到的矢量為(0,2,0),第三個詞語經矢量化得到的矢量為(0,0,3),通過矢量相加即可得到每個詞語組合的矢量,本實施例中可能出現的詞語組合的矢量為(1,2,0)、(0,2,3)和(1,0,3)。步驟S308,每篇網頁文檔同樣也有一個對應的文檔矢量,根據該網頁文檔中各詞語的詞頻值和網頁文檔的詞語總數量對該網頁文檔進行矢量化,可以得到該網頁文檔的文檔矢量。步驟S310,根據詞語組合矢量與文檔矢量的矢量參數計算該詞語組合的個體適應度,其中,個體適應度作為匹配程度的依據。個體適應度的計算函數根據不同的需求而不同,詞語組合矢量與文檔矢量越匹配,則該詞語組合的個體適應度越高,個體適應度最高的詞語組合即為該網頁文檔的關鍵詞組合。本實施例還可以認為矢量之間的夾角最小的為最匹配,或者矢量端點間距離最短的為最匹配,或者以直方圖的形式來表示,在直方圖中高度與網頁文檔最接近的詞語組合為該網頁文檔的關鍵詞組合。返回圖2,步驟S206,對當前代詞語組合進行重組操作,得到新一代詞語組合。重組操作具體可以表現為複製、交叉及變異。在針對網頁文檔的本實施例中,複製為將某個體直接遺傳到下一代,即選取一些詞語組合直接作為新一代詞語組合中的成員;交叉為將兩個個體的部分基因相互替換,生成新個體遺傳到下一代,即將兩個詞語組合中的某些詞語進行相互替換,得到新一代詞語組合中的成員;變異為個體中的某個基因隨機更換成別的基因生成新的個體遺傳到下一代,即將某個詞語組合中的個別詞語更換成其他詞語。例如,有第一個體(a,b)和第二個體(c,d),將(a,b)直接遺傳到下一代為複製,將(a,b)和(c,d)的相互替換變為(a,c)和(b,d)遺傳到下一代為交叉,直接將(a,b)變為(a,d)遺傳到下一代為變異。步驟S208,計算新一代詞語組合與網頁的新匹配程度,獲得新一代最優詞語組合。該計算方法可參照圖3的適應度計算方法。在一個實施例中,當步驟S204已針對當前代詞語組合與網頁文檔的匹配程度進行過計算後,步驟S302獲取多個網頁文檔中的詞語總數量及步驟S304根據詞頻和反向文檔頻計算各詞語的詞頻值步驟可被省略。新一代詞語組合中對應新匹配程度最高的詞語組合可作為新一代的最優詞語組合。步驟S210,判斷新一代最優詞語組合的匹配程度是否滿足預設匹配條件,例如,該預設匹配條件可以為以下兩種,其中,如前所述,匹配程度及對應個體適應度:例一,可對最優個體適應度連續不變的迭代代數進行預先指定。例如指定代數閾值n,在n代內種群最優個體的個體適應度不變,則最後一代的最優詞語組合為關鍵詞組合。具體地,假設閾值n為5,則在5代內,例如第1代、第2代、第3代、第4代及第5代連續5代內,最優個體的適應度值保持不變,則第5代的最優詞語組合為關鍵詞組合。例二,可將下述公式(1)作為預設匹配條件:Σx=n-mnS(x)---(1)]]>其中,n為當前代數,m為指定的閾值,S(x)為第x代最優個體的個體適應度。也即,當從第n-m-1代至第n-1代共計m代的最優個體的適應度總和大於從第n-m代至第n代共計m代的最優個體適應度總和時,終止進化。例如:當n=10,m=5時,即當前為第10代,預先指定的代數為5時,從第4代至第9代共計5代的最優個體適應度總和大於或等於從第5代至第10代共計5代的最優個體適應度總和時,最後一代的最優個體即為關鍵詞組合。步驟S212,當所述新匹配程度不滿足該預設匹配條件時,重複重組操作,在新匹配程度滿足該預設匹配條件時,將新一代最優詞語組合確定為關鍵詞組合。步驟S214,在確定關鍵詞組合後,終止迭代。返回圖1的步驟S108,從多個關鍵詞組合中獲取高頻關鍵詞,其中,高頻關鍵詞為多組關鍵詞組合中在預設時間周期內滿足預設條件的關鍵詞。在本步驟中,可以獲取多個網頁文檔在預設時間周期內的獨立訪客數量(UniqueVisitor,UV)並將每個網頁文檔的UV定義為該文檔對應的關鍵詞組合中多個關鍵詞的訪問數量;將訪問數量在預設數量條件以上的關鍵詞定義為該多個網頁文檔的高頻關鍵詞,具體地,包括以下步驟S1至S3。S1,統計每個網頁的預定時間周期內的UV,並以此作為關鍵詞的訪問數量,本實施例中的UV定義如下:同一用戶N(N≥1)次訪問同一網頁,UV為1。S2,根據步驟S1的數據繪製每個關鍵詞的時間-訪問數量走勢圖,由此可得出每個關鍵詞在預設時間周期內最大訪問數量和最大單位時間訪問數量,即斜率。S3,噪音關鍵詞過濾:將訪問數量滿足預設數量條件的關鍵詞作為高頻關鍵詞。例如,取所有關鍵詞最大斜率的平均值為預設數量條件對關鍵詞進行篩選,將最大斜率在該預設數量以下的關鍵詞刪去。本實施例將高頻關鍵詞涉及的內容作為輿論關注的熱點,通過高頻關鍵詞可以快速準確找出當前的熱點信息。返回圖1中的步驟S110,按相似度對高頻關鍵詞進行聚類,以獲得同類高頻關鍵詞。該獲取同類高頻關鍵詞方法的流程圖如圖4A所示。步驟S402,分別獲取多個網頁文檔對應的多個關鍵詞組合中的多個關鍵詞的訪問數量。該訪問數量定義為在預設時間周期內該關鍵詞組合對應的網頁文檔的UV,例如,預設時間周期為3天,則計算3天內網頁文檔的UV,該UV即為該網頁文檔對應的關鍵詞組合中各個關鍵詞的訪問數量。步驟S404,獲取各關鍵詞的訪問數量在預設時間周期內隨時間的變化趨勢,例如,建立坐標系,該坐標系的橫坐標為時間,縱坐標為某關鍵詞的訪問數量,獲得該關鍵詞的變化趨勢。步驟S406,將變化趨勢的相似係數滿足預設係數條件的多個關鍵詞作為同類高頻關鍵詞。本實施例可根據皮爾遜相關係數計算每兩個關鍵詞曲線的相似係數S,如下述公式(2)所示:其中,N為預定時間周期,X為一個關鍵詞的變化趨勢曲線,Y為另一個關鍵詞的變化趨勢曲線。在完成所有的兩個關鍵詞曲線的相似係數的計算後,可依據關鍵詞之間的相似係數S做分層聚類,根據相似係數大小順序排列,得出關鍵詞聚類二叉樹,其中,每個葉子節點表示一個關鍵詞的變化趨勢曲線,非葉子節點表示兩個葉子節點之間的相似係數,父葉子節點表示某葉子節點的次近關鍵詞的變化趨勢曲線。例如,圖4B為根據本發明實施例的關鍵詞聚類二叉樹示意圖,如圖所示,關鍵詞聚類二叉樹400包括葉子節點410、412、414及非葉子節點422、432。其中,非葉子節點422表示葉子節點412與414之間的相似係數,葉子節點410為葉子節點412、414的父葉子節點,非葉子節點432表示父葉子節點410與葉子節點412、414之間數值較高的相似係數。例如,當兩個關鍵詞分別為「海監」及「釣魚島」時,葉子節點412與414分別代表「海監」的變化趨勢曲線(X)和「釣魚島」(Y)的變化趨勢曲線,非葉子節點422即為根據上述公式(2)所計算的相似係數S,例如:0.5。得到聚類二叉樹400後,從聚類二叉樹的葉子節點開始遍歷,在原始文檔中檢索包含兩個最近葉子節點關鍵詞的文檔,若可以找到,加上父節點上的關鍵詞再次檢索,直至檢索不到文檔為止。由此可得出描述多個話題的詞語組合。仍以上述實例進行說明,如果父葉子節點410表示的關鍵詞為「中國」的變化趨勢曲線,計算所得其與葉子節點412、414之間數值較高的相似係數為0.5,則繼續檢索,一篇文檔中是否同時出現「海監」和釣魚島」和「中國」,若存在,則繼續檢索;如果父葉子節點為「釣魚帽」的變化趨勢曲線,計算所得其與葉子節點412、414之間數值較高的相似係數為0.3,檢索發現沒有文檔中同時出現「海監」和釣魚島」和「釣魚帽」,則釣魚帽無法與「海監」和「釣魚島」聚類。通過以上聚類,可以將雜亂無序的文檔按內容進行分類,便於對文檔的管理。完成話題的聚類後,就可以將同類高頻關鍵詞對應的網頁文檔以話題的形式推送至用戶。例如,某用戶在看過一篇近期發表的關於釣魚島的文章後,系統自動將其他近期發表的關於釣魚島的文章推送給該用戶。從以上的描述中,可以看出,本發明實施例使用戶更加方便地閱讀同一話題的網頁文檔,簡化了用戶對信息的搜集,節省了用戶的時間。本發明實施例還提供了一種對多個網頁中高頻關鍵詞進行聚類的裝置,以下對本發明實施例所提供的該裝置進行介紹。圖5是根據發明實施例的對多個網頁中高頻關鍵詞進行聚類的裝置的結構框圖。如圖5所示,該裝置包括抓取單元502、分詞單元504、確定單元506、獲取單元508和聚類單元510。抓取單元502用於抓取多個網頁對應的多個網頁文檔。分詞單元504用於對抓取到的多個網頁文檔中的各個網頁文檔進行分詞以獲取多個詞語。確定單元506用於各個網頁文檔對應的關鍵詞組合,其中,關鍵詞組合包括表徵對應網頁文檔內容的關鍵詞。具體地,確定單元506可以當多個詞語組成的特定組合與網頁文檔的匹配程度大於或等於任意由相同個數的詞語組成的詞語組合時,確定特定組合為關鍵詞組合。為了實現上述功能,確定單元506可以包括多個子單元,圖6是根據本發明實施例的確定單元的結構框圖,如圖6所示,確定單元506包括:組合子單元602,用於隨機組成多個當前代詞語組合。第一計算子單元604,用於計算當前代詞語組合與網頁文檔的匹配程度,獲得當前代最優詞語組合。重組子單元606,用於對當前代詞語組合進行重組操作,得到新一代詞語組合。重組操作具體可以表現為複製、交叉及變異。第二計算子單元608,用於計算新一代詞語組合與網頁的新匹配程度,獲得新一代最優詞語組合。在上述實施例中,第一計算子單元604可以包括多個模塊,圖7是根據本發明實施例的第一計算子單元的結構框圖,如圖7所示,第一計算子單元604包括以下模塊:獲取模塊702,用於獲取網頁文檔中的詞語總數量。第一計算模塊704,用於根據詞頻和反向文檔頻計算各詞語的詞頻值。第一矢量模塊706,用於根據詞語組合中各詞語的詞頻值和網頁文檔的詞語總數量對詞語組合進行矢量化。第二矢量模塊708,用於根據該網頁文檔中各詞語的詞頻值和網頁文檔的詞語總數量對該網頁文檔進行矢量化。第二計算模塊710,用於根據詞語組合矢量與文檔矢量的矢量參數計算該詞語組合的個體適應度。獲取單元508用於從多個關鍵詞組合中獲取高頻關鍵詞,其中,高頻關鍵詞為多組關鍵詞組合中在預設時間周期內滿足預設條件的關鍵詞。聚類單元510用於按相似度對高頻關鍵詞進行聚類,以獲得同類高頻關鍵詞。圖8是根據本發明實施例的聚類單元510的結構框圖,如圖8所示,聚類單元510包括:第一獲取子單元802,用於分別獲取多個網頁文檔對應的多個關鍵詞組合中的多個關鍵詞的訪問數量。第二獲取子單元804,用於獲取各關鍵詞的訪問數量在預設時間周期內隨時間的變化趨勢,例如,建立坐標系,該坐標系的橫坐標為時間,縱坐標為某關鍵詞的訪問數量,獲得該關鍵詞的變化趨勢。聚類子單元806,用於將變化趨勢的相似係數滿足預設係數條件的多個關鍵詞作為同類高頻關鍵詞。以上各單元和子單元的作用和功能對應於方法實施例中的步驟,各單元和模塊的作用和功能在此不再贅述。在本實施例中,通過提取關鍵詞組合來準確和全面地反映網頁文檔的內容,再對組合中的關鍵詞重新聚類,將具有關聯性的網頁文檔劃分在同一話題中,從而使用戶更加方便地閱讀同一話題的網頁文檔,簡化了用戶對信息的搜集,節省了用戶的時間。本實施例還提供了另一種對文檔進行分類的方法,該方法可以多篇文檔進行分類,圖9是根據本發明實施例的對文檔進行分類的方法的流程圖,如圖9所示,該方法包括步驟S902至S908。步驟S902,讀取多個文檔。在本步驟中讀取的文檔既可以是網頁文檔,也可以是本地文檔。在對該文檔進行分類時,可以不考慮時效性和閱讀次數。步驟S904,對讀取到的多個文檔進行分詞以獲取多個詞語。步驟S906,確定文檔對應的關鍵詞組合,其中,關鍵詞詞組包括表徵對應文檔的內容的詞語,關鍵詞組合中的詞語為關鍵詞。本方法中的分詞方法和確定關鍵詞的方法類似於上述對多個網頁中高頻關鍵詞進行聚類的方法,例如,可以通過遺傳算法從關鍵詞中確定關鍵詞組合。具體地,通過遺傳算法確定關鍵詞組合可以包括以下步驟:首先,將多個詞語初始化為組成詞語組合。然後,對詞語組合進行複製、交叉及變異操作,獲得下一代詞語組合。繼而,計算下一代詞語組合與文檔的匹配程度。進一步地,計算匹配程度的過程可以通過以下五步實現。第一步,獲取文檔中的詞語總數量。例如文檔共有1000個不同詞語。第二步,根據詞頻和反向文檔頻計算各詞語的詞頻值。例如每多出現一次,詞頻值加1。第三步,根據詞語組合中各詞語的詞頻值和文檔的詞語總數量對詞語組合進行矢量化,得到詞語組合矢量。第四步,根據文檔中各詞語的詞頻值和文檔的詞語總數量對文檔進行矢量化,得到文檔矢量。第五步,根據詞語組合矢量和文檔矢量的矢量參數計算詞語組合的個體適應度,其中,個體適應度作為匹配程度的依據。回到通過遺傳算法確定關鍵詞組合的方法中,最後,在匹配程度滿足預設條件時終止遺傳算法,得到關鍵詞組合。以上步驟的具體實現過程已在前述實施例具體描述,在此不再贅述。回到圖9所示步驟S908,將包括相同關鍵詞的文檔分到相同類別。例如,關鍵詞中都包括「足球」的文檔可以分到同一類別。同時,同一篇文章可以被分到多個類別中,例如,一篇文檔描述了總統觀看足球賽,關鍵詞包括「總統」和「足球」,那麼該文檔可以既歸入涉及體育的「足球」類別,也歸入涉及政治的「總統」類別。通過分類,提高了文檔閱讀時的用戶體驗。相應地,本實施例還提供了一種文檔的分類裝置。圖10是根據本發明實施例的文檔的分類裝置的結構框圖。如圖10所示,該裝置包括讀取單元1002、分詞單元1004、確定單元1006和分類單元1008。讀取單元1002用於讀取多個文檔。分詞單元1004用於對讀取到的多個文檔進行分詞以獲取多個詞語。確定單元1006用於確定文檔對應的關鍵詞組合,其中,關鍵詞詞組包括表徵對應文檔的內容的詞語,關鍵詞組合中的詞語為關鍵詞。確定單元1006具體可以通過遺傳算法從關鍵詞中確定關鍵詞組合。為了實現確定關鍵詞組合的功能,確定單元1006可以包括多個子單元,圖11是根據本發明實施例的確定單元1006的結構框圖,如圖11所示,確定單元1006包括以下子單元:初始化子單元1102,用於將多個詞語初始化為多個詞語組合。處理子單元1104,用於對詞語組合進行複製、交叉及變異操作,獲得下一代詞語組合。計算子單元1106,用於計算下一代詞語組合與文檔的匹配程度。獲取子單元1108,用於在匹配程度滿足預設條件時終止遺傳算法,得到關鍵詞組合。回到圖9所示的裝置,分類單元1008用於將包括相同關鍵詞的文檔分到相同類別。通過本裝置,可以對多篇文檔進行分類,從而方便用戶的閱讀。需要說明的是,在附圖的流程圖示出的步驟可以在諸如一組計算機可執行指令的計算機系統中執行,並且,雖然在流程圖中示出了邏輯順序,但是在某些情況下,可以以不同於此處的順序執行所示出或描述的步驟。顯然,本領域的技術人員應該明白,上述的本發明的各模塊或各步驟可以用通用的計算裝置來實現,它們可以集中在單個的計算裝置上,或者分布在多個計算裝置所組成的網絡上,可選地,它們可以用計算裝置可執行的程序代碼來實現,從而,可以將它們存儲在存儲裝置中由計算裝置來執行,或者將它們分別製作成各個集成電路模塊,或者將它們中的多個模塊或步驟製作成單個集成電路模塊來實現。這樣,本發明不限制於任何特定的硬體和軟體結合。以上所述僅為本發明的優選實施例而已,並不用於限制本發明,對於本領域的技術人員來說,本發明可以有各種更改和變化。凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。