文本關鍵詞生成方法及裝置和電子設備及可讀存儲介質與流程
2023-06-20 14:29:17 3
本發明涉及多媒體技術領域,特別是涉及一種文本關鍵詞生成方法及裝置和電子設備及可讀存儲介質。
背景技術:
隨著網際網路的發展,網際網路用戶每天接觸的信息越來越多,不管是新聞或者電影字幕,如何從海量的信息中提取對網際網路用戶有用的信息越來越重要。同時,提取信息的關鍵詞對網際網路用戶快速理解信息的作者要表達的意思非常有幫助。目前,常用的關鍵詞提取算法包括:tf-idf(termfrequency–inversedocumentfrequency,詞頻-逆向文件頻率)算法和textrank算法等。
其中,tf-idf算法通過詞頻判斷一個詞在文中是否重要,同時對在各個文章中都出現的詞降低權重,對在本文章中出現但在其它文章不出現的詞增加權重。
根據tf-idf計算公式:tf-idf(w,di)=tfw*idf(w),計算特徵詞w的tf-idf值。根據tf-idf值即可判斷特徵詞的重要性,進而根據特徵詞的重要性生成關鍵詞。
其中,idf計算公式為:idf(w)表示特徵詞w在所有文檔中的逆向文檔頻率,|d|表示文檔的總個數,di表示文檔,dfw表示包含特徵詞w的文檔的總個數,tfw表示tf值,也即特徵詞w在文檔d中出現的個數。
但是,tf-idf算法僅僅從詞頻的角度挖掘信息,不能體現文本的深層次語義信息。因此,tf-idf算法生成關鍵詞的準確性比較低。
技術實現要素:
本發明實施例的目的在於提供一種文本關鍵詞生成方法及裝置和電子設備及可讀存儲介質,以提高關鍵詞生成的準確性。具體技術方案如下:
本發明實施例公開了一種文本關鍵詞生成方法,包括:
獲取待檢測文本,對所述待檢測文本中的每一個字符進行向量表示,得到所述待檢測文本的字符矩陣;
將所述待檢測文本的字符矩陣輸入預先建立的關鍵詞模型,得到所述待檢測文本的字符矩陣對應的關鍵詞矩陣;
計算所述關鍵詞矩陣中的每一個向量和向量模型中的字符向量的相似度,根據所述相似度獲取所述待檢測文本的關鍵詞,其中,所述向量模型包括:字符和所述字符對應的字符向量。
可選的,在所述獲取待檢測文本之前,所述文本關鍵詞生成方法還包括:
構建訓練數據;
對所述訓練數據中每一個樣本文本中的每一個字符進行向量表示,得到所述每一個樣本文本的字符矩陣;
對所述訓練數據中每一個樣本文本對應的關鍵詞中的每一個字符進行向量表示,得到所述每一個樣本文本的關鍵詞矩陣;
根據所述每一個樣本文本的字符矩陣和所述每一個樣本文本的關鍵詞矩陣的對應關係,通過長短期記憶lstm神經網絡對所述訓練數據進行訓練,建立所述關鍵詞模型。
可選的,所述構建訓練數據,包括:
獲取多個待訓練文本,對所述多個待訓練文本中的每一個待訓練文本進行過濾,得到多個待處理文本;
對所述多個待處理文本中的每一個待處理文本進行長度設置,得到所述樣本文本;
根據所述每一個樣本文本的長度,以及預先建立的文本長度和關鍵詞個數的對應關係,提取所述每一個樣本文本中的關鍵詞;
建立所述樣本文本和所述樣本文本中關鍵詞的對應關係。
可選的,所述對所述多個待訓練文本中的每一個待訓練文本進行過濾,包括:
刪除所述每一個待訓練文本中的數字字符和標點符號;和/或,
刪除所述每一個待訓練文本中出現次數小於預設閾值的詞語。
可選的,所述對所述多個待處理文本中的每一個待處理文本進行長度設置,包括:
在所述待處理文本的長度小於預設下限閾值時,在所述待處理文本中添加預設字符,使所述待處理文本的長度等於預設下限閾值;
在所述待處理文本的長度大於預設上限閾值時,對所述待處理文本進行截短處理,使所述待處理文本的長度等於預設上限閾值。
可選的,所述對所述訓練數據中每一個樣本文本中的每一個字符進行向量表示,得到所述每一個樣本文本的字符矩陣,包括:
對所述每一個樣本文本進行文本倒序,得到倒序的樣本文本;
對所述倒序的樣本文本中的每一個字符進行向量表示,得到所述倒序的樣本文本的字符矩陣;
所述根據所述每一個樣本文本的字符矩陣和所述樣本文本中關鍵詞的對應關係,通過lstm神經網絡對所述訓練數據進行訓練,建立所述關鍵詞模型,包括:
根據所述倒序的樣本文本的字符矩陣和所述樣本文本中關鍵詞的對應關係,通過lstm神經網絡對所述訓練數據進行訓練,建立所述關鍵詞模型。
可選的,所述獲取待檢測文本,包括:
刪除文本數據中的數字字符和標點符號,得到所述待檢測文本。
可選的,所述計算所述關鍵詞矩陣中的每一個向量和向量模型中的字符向量的相似度,根據所述相似度獲取所述待檢測文本的關鍵詞,包括:
計算所述關鍵詞矩陣中的每一個向量和所述向量模型中的字符向量的餘弦值;
將每一個餘弦值中最大值對應的所述向量模型中的字符作為目標字符,依次獲取所述目標字符,得到所述待檢測文本的關鍵詞。
本發明實施例還公開了一種文本關鍵詞生成裝置,包括:
字符矩陣獲取模塊,用於獲取待檢測文本,通過所述待檢測文本中的每一個字符進行向量表示,得到所述待檢測文本的字符矩陣;
關鍵詞矩陣生成模塊,用於將所述待檢測文本的字符矩陣輸入預先建立的關鍵詞模型,得到所述待檢測文本的字符矩陣對應的關鍵詞矩陣;
關鍵詞生成模塊,用於計算所述關鍵詞矩陣中的每一個向量和向量模型中的字符向量的相似度,根據所述相似度獲取所述待檢測文本的關鍵詞,其中,所述向量模型包括:字符和所述字符對應的字符向量。
可選的,本發明實施例的文本關鍵詞生成裝置,還包括:
訓練數據構建模塊,用於構建訓練數據;
樣本字符矩陣生成模塊,用於對所述訓練數據中每一個樣本文本中的每一個字符進行向量表示,得到所述每一個樣本文本的字符矩陣;
樣本關鍵詞矩陣生成模塊,用於對所述訓練數據中每一個樣本文本對應的關鍵詞中的每一個字符進行向量表示,得到所述每一個樣本文本的關鍵詞矩陣;
關鍵詞模型建立模塊,用於根據所述每一個樣本文本的字符矩陣和所述每一個樣本文本的關鍵詞矩陣的對應關係,通過長短期記憶lstm神經網絡對所述訓練數據進行訓練,建立所述關鍵詞模型。
可選的,所述訓練數據構建模塊,包括:
預處理子模塊,用於獲取多個待訓練文本,對所述多個待訓練文本中的每一個待訓練文本進行過濾,得到多個待處理文本;
長度設置子模塊,用於對所述多個待處理文本中的每一個待處理文本進行長度設置,得到所述樣本文本;
關鍵詞提取子模塊,用於根據所述每一個樣本文本的長度,以及預先建立的文本長度和關鍵詞個數的對應關係,提取所述每一個樣本文本中的關鍵詞;
對應關係建立子模塊,用於建立所述樣本文本和所述樣本文本中關鍵詞的對應關係。
可選的,所述預處理子模塊,包括:
第一刪除單元,用於刪除所述每一個待訓練文本中的數字字符和標點符號;和/或,
第二刪除單元,用於刪除所述每一個待訓練文本中出現次數小於預設閾值的詞語。
可選的,所述長度設置子模塊,包括:
第一長度設置單元,用於在所述待處理文本的長度小於預設下限閾值時,在所述待處理文本中添加預設字符,使所述待處理文本的長度等於預設下限閾值;
第二長度設置單元,用於在所述待處理文本的長度大於預設上限閾值時,對所述待處理文本進行截短處理,使所述待處理文本的長度等於預設上限閾值。
可選的,所述樣本字符矩陣生成模塊,包括:
倒序設置子模塊,用於對所述每一個樣本文本進行文本倒序,得到倒序的樣本文本;
向量表示子模塊,用於對所述倒序的樣本文本中的每一個字符進行向量表示,得到所述倒序的樣本文本的字符矩陣;
所述關鍵詞模型建立模塊具體用於,根據所述倒序的樣本文本的字符矩陣和所述樣本文本中關鍵詞的對應關係,通過lstm神經網絡對所述訓練數據進行訓練,建立所述關鍵詞模型。
可選的,所述字符矩陣獲取模塊具體用於,刪除文本數據中的數字字符和標點符號,得到所述待檢測文本。
可選的,所述關鍵詞生成模塊,包括:
相似度計算子模塊,用於計算所述關鍵詞矩陣中的每一個向量和所述向量模型中的字符向量的餘弦值;
生成子模塊,用於將每一個餘弦值中最大值對應的所述向量模型中的字符作為目標字符,依次獲取所述目標字符,得到所述待檢測文本的關鍵詞。
本發明實施例還公開了一種電子設備,包括:處理器、通信接口、存儲器和通信總線,其中,所述處理器、所述通信接口、所述存儲器通過所述通信總線完成相互間的通信;
所述存儲器,用於存放電腦程式;
所述處理器,用於執行所述存儲器上所存放的程序時,實現以下步驟:
獲取待檢測文本,對所述待檢測文本中的每一個字符進行向量表示,得到所述待檢測文本的字符矩陣;
將所述待檢測文本的字符矩陣輸入預先建立的關鍵詞模型,得到所述待檢測文本的字符矩陣對應的關鍵詞矩陣;
計算所述關鍵詞矩陣中的每一個向量和向量模型中的字符向量的相似度,根據所述相似度獲取所述待檢測文本的關鍵詞,其中,所述向量模型包括:字符和所述字符對應的字符向量。
本發明實施例還公開了一種計算機可讀存儲介質,所述計算機可讀存儲介質內存儲有電腦程式,所述電腦程式被處理器執行時實現以下步驟:
獲取待檢測文本,對所述待檢測文本中的每一個字符進行向量表示,得到所述待檢測文本的字符矩陣;
將所述待檢測文本的字符矩陣輸入預先建立的關鍵詞模型,得到所述待檢測文本的字符矩陣對應的關鍵詞矩陣;
計算所述關鍵詞矩陣中的每一個向量和向量模型中的字符向量的相似度,根據所述相似度獲取所述待檢測文本的關鍵詞,其中,所述向量模型包括:字符和所述字符對應的字符向量。
本發明實施例提供的文本關鍵詞生成方法及裝置和電子設備及可讀存儲介質,對待檢測文本中的每一個字符進行向量表示,得到待檢測文本的字符矩陣;將待檢測文本的字符矩陣輸入預先建立的關鍵詞模型,得到待檢測文本的字符矩陣對應的關鍵詞矩陣;計算關鍵詞矩陣中的每一個向量和向量模型中的字符向量的相似度,根據相似度獲取待檢測文本的關鍵詞。本發明實施例通過時間遞歸神經網絡得到待檢測文本的關鍵詞,提高了文本關鍵詞生成的準確性。當然,實施本發明的任一產品或方法並不一定需要同時達到以上所述的所有優點。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹。
圖1為本發明實施例的文本關鍵詞生成方法的一種流程圖;
圖2為本發明實施例的文本關鍵詞生成方法的另一種流程圖;
圖3為本發明實施例的文本關鍵詞生成裝置的一種結構圖;
圖4為本發明實施例的文本關鍵詞生成裝置的另一種結構圖;
圖5為本發明實施例的電子設備的結構圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行描述。
由於現有技術中通過tf-idf得到關鍵詞的方法僅僅從詞頻的角度挖掘信息,不能體現文本的深層次語義信息。因此,tf-idf算法得到關鍵詞的準確性比較低,為了解決該問題,本發明實施例提供了一種文本關鍵詞生成方法及裝置和電子設備及可讀存儲介質,以提高文本關鍵詞生成的準確性。下面首先對本發明實施例所提供的文本關鍵詞生成方法進行介紹。
參見圖1,圖1為本發明實施例的文本關鍵詞生成方法的一種流程圖,包括:
s101,獲取待檢測文本,對待檢測文本中的每一個字符進行向量表示,得到待檢測文本的字符矩陣。
需要說明的是,word2vec是google在2013年年中開源的一款將詞表徵為實數值向量的高效工具,word2vec利用深度學習的思想,通過訓練,把對文本內容的處理簡化為k維向量空間中的向量運算,而向量空間上的相似度可以用來表示文本語義上的相似度。因此,word2vec輸出的詞向量可以被用來做很多nlp(naturallanguageprocessing,自然語言處理)相關的工作,比如聚類、找同義詞、詞性分析等等。word2vec把特徵映射到k維向量空間,可以為文本尋求更加深層次的特徵表示。本發明實施例中,待檢測文本可以為一句話、一段話或一篇文章等,可以通過word2vec把待檢測文本中的每一個字符映射為k維向量空間,當然,對每一個字符進行向量表示的方法也可以是其他任何向量表示的方法。如果待檢測文本中包含m個字符,那麼,每一個字符由k維向量表示,待檢測文本就可以表示為m×k的矩陣,即字符矩陣。其中,m為大於0的整數,k維向量一般是高維向量,因此,k為數值比較大的整數,例如,k可以取值為400,當然k也可以為其他數值,在此不做限定。
s102,將待檢測文本的字符矩陣輸入預先建立的關鍵詞模型,得到待檢測文本的字符矩陣對應的關鍵詞矩陣。
具體的,關鍵詞模型為本發明實施例對訓練數據進行訓練得到的模型,訓練數據包括:訓練數據中樣本文本的字符矩陣和字符矩陣對應的該樣本文本中關鍵詞的關鍵詞矩陣,其中,關鍵詞矩陣為對樣本文本中的關鍵詞進行向量表示得到的矩陣。那麼,在得到關鍵詞模型之後,將待檢測文本的字符矩陣輸入關鍵詞模型,即可得到待檢測文本的字符矩陣對應的關鍵詞矩陣。例如,將s101中待檢測文本的字符矩陣(m×k的矩陣)輸入關鍵詞模型,得到的待檢測文本的字符矩陣對應的關鍵詞矩陣可以為n×k的矩陣,其中,n為關鍵詞中字符的個數。關鍵詞模型的建立方法將在下文進行詳細描述,這裡不再贅述。
s103,計算關鍵詞矩陣中的每一個向量和向量模型中的字符向量的相似度,根據相似度獲取待檢測文本的關鍵詞,向量模型包括:字符和字符對應的字符向量。
本發明實施例中,在通過關鍵詞模型得到待檢測文本的字符矩陣對應的關鍵詞矩陣之後,需要對關鍵詞矩陣進行相似度計算,得到關鍵詞矩陣對應的關鍵詞。更為具體的,如果關鍵詞矩陣為n×k的矩陣,k表示每個字符的維數,n為關鍵詞中字符的個數。那麼,將n個1×k的向量分別與向量模型中存儲的字符向量進行相似度計算,即可得到n個相似度最大值對應的字符,該n個字符即為得到的待檢測文本的關鍵詞。需要說明的是,向量模型中存儲的是字符向量和字符的對應關係,因此,通過向量模型可以對字符進行向量表示,得到字符對應的字符向量,同樣地,通過向量模型可以得到關鍵詞矩陣對應的關鍵詞。可選的,向量模型可以是word2vec。
可見,本發明實施例的文本關鍵詞生成方法,通過對獲取到的待檢測文本中的每一個字符進行向量表示,得到待檢測文本的字符矩陣。將待檢測文本的字符矩陣輸入預先建立的關鍵詞模型,即可得到待檢測文本的字符矩陣對應的關鍵詞矩陣。計算關鍵詞矩陣中的每一個向量和向量模型中的字符向量的相似度,根據相似度獲取待檢測文本的關鍵詞。本發明實施例通過時間遞歸神經網絡得到待檢測文本的關鍵詞,提高了文本關鍵詞生成的準確性。
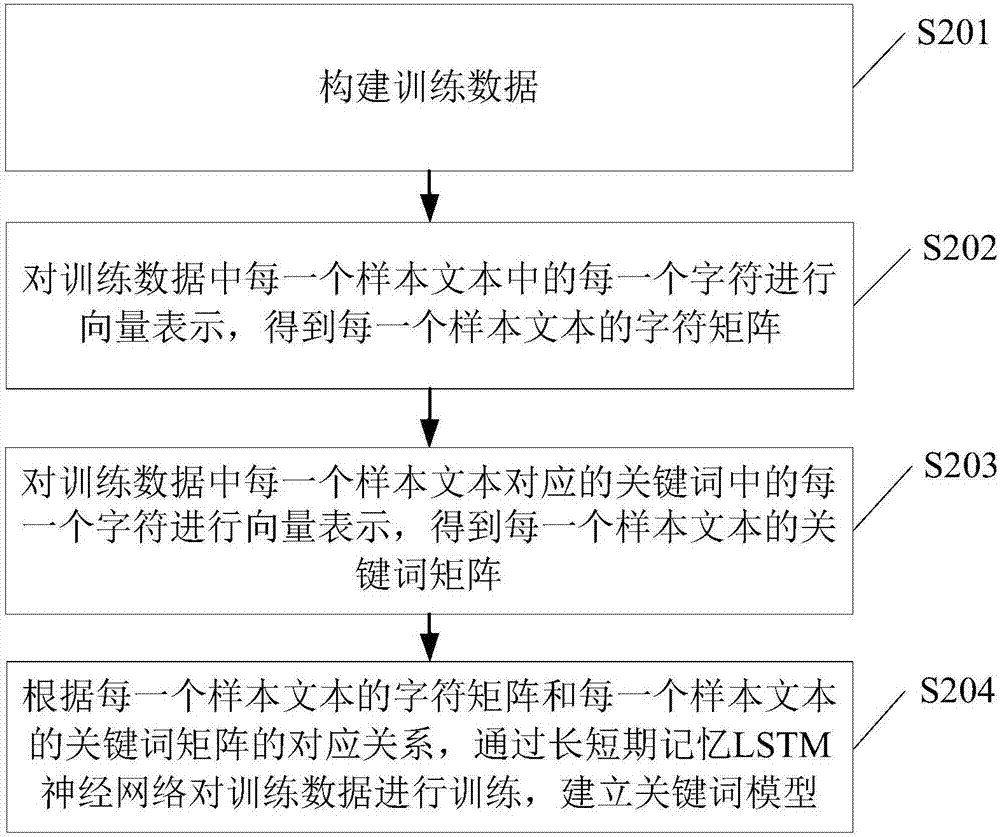
圖1所示實施例中,s102中關鍵詞模型的建立方法,可參見圖2,圖2為本發明實施例的文本關鍵詞生成方法的另一種流程圖,包括:
s201,構建訓練數據。
本發明實施例中,訓練數據是指用於訓練關鍵詞模型的數據,並且,每一條數據都具有對應的關鍵詞。例如,可以通過抓取4000w條「新華網」的新聞數據,同時得到每一條新聞數據中經過人工編輯的關鍵詞,其中,新聞數據涵蓋政治、軍事、財經、房產、教育、旅遊等方面,新聞數據的長度可以在100到800個詞之間,關鍵詞的個數可以在4到10個之間。這樣,新聞數據以及每一條新聞數據對應的關鍵詞構成了訓練數據。
s202,對訓練數據中每一個樣本文本中的每一個字符進行向量表示,得到每一個樣本文本的字符矩陣。
s203,對訓練數據中每一個樣本文本對應的關鍵詞中的每一個字符進行向量表示,得到每一個樣本文本的關鍵詞矩陣。
需要說明的是,s202和s203中都是對字符進行向量表示,不同的是,s202中是對樣本文本中的每一個字符進行向量表示,s203中是對樣本文本對應的關鍵詞中的每一個字符進行向量表示,其中,對每一個字符進行向量表示的方法可以是word2vec,通過word2vec對字符進行向量表示的方法可參見s101,這裡不再贅述。
s204,根據每一個樣本文本的字符矩陣和每一個樣本文本的關鍵詞矩陣的對應關係,通過長短期記憶lstm神經網絡對訓練數據進行訓練,建立關鍵詞模型。
本發明實施例中,在得到每一個樣本文本的字符矩陣之後,將每一個樣本文本的字符矩陣和該樣本文本的關鍵詞矩陣輸入關鍵詞模型,通過lstm神經網絡對輸入的每一個樣本文本的字符矩陣和樣本文本中的關鍵詞矩陣進行訓練,得到關鍵詞模型。
本發明實施例的一種實現方式中,構建訓練數據,包括:
獲取多個待訓練文本,對多個待訓練文本中的每一個待訓練文本進行過濾,得到多個待處理文本。
對多個待處理文本中的每一個待處理文本進行長度設置,得到樣本文本。
根據每一個樣本文本的長度,以及預先建立的文本長度和關鍵詞個數的對應關係,提取每一個樣本文本中的關鍵詞。
建立樣本文本和樣本文本中關鍵詞的對應關係。
本發明實施例中,為了得到有效的文本,需要對待訓練文本進行預處理,例如,過濾掉待訓練文本中不需要的文本和字符等,得到待處理文本。
另外,為了解決輸入關鍵詞模型中數據的變長問題,本發明實施例中,對多個待處理文本中的每一個待處理文本進行長度設置,得到樣本文本。具體的,通過構建桶,使不同長度的輸入文本和輸出關鍵詞的個數根據桶的大小訓練網絡。構建的桶可以為:(200,5)、(300,5)、(600,5)、(200,8)、(300,8)、(600,8)、(200,11)、(300,11)、(600,11)等。當然,桶的大小可以根據實際情況進行設定,在此不做限定。其中,括號內第一個數字表示輸入文本的長度,括號內第二個數字表示輸入文本對應的輸出的關鍵詞的個數。
因此,在對每一個待處理文本進行長度設置時,可以根據待處理文本的長度,將待處理文本的長度設置為200、300、600等,然後根據設置的桶的大小以及待處理文本的長度,提取待處理文本中的關鍵詞。例如:待處理文本的長度為200,提取的待處理文本中的關鍵詞的個數可以為5個或8個。由此,建立樣本文本和樣本文本中關鍵詞的對應關係。
本發明實施例的一種實現方式中,對多個待訓練文本中的每一個待訓練文本進行過濾,包括:
刪除每一個待訓練文本中的數字字符和標點符號。和/或,
刪除每一個待訓練文本中出現次數小於預設閾值的詞語。
通常,待訓練文本是包含多種字符的文本,特殊字符對於關鍵詞的提取是沒有貢獻的,而且,待訓練文本中詞頻很低的詞語對於大量的待訓練文本來講,也是可以忽略不計的。那麼,當訓練文本中包含特殊字符而不包含詞頻很低的詞語時,可以刪除每一個待訓練文本中特殊字符,特殊字符包括:數字字符和標點符號等。當待訓練文本中包含詞頻很低的詞語而不包含特殊字符時,還可以刪除待訓練文本中詞頻很低的詞語。當訓練文本中同時包含特殊字符和詞頻很低的詞語時,可以將特殊字符和詞頻很低的詞語同時刪除。例如,可以刪除在待訓練文本出現次數小於預設閾值的詞語,預設閾值可以取值為100,也可以為根據實際情況設定的其他值,例如,可以包括(50,200)範圍內的值。
本發明實施例的一種實現方式中,對多個待處理文本中的每一個待處理文本進行長度設置,包括:
在待處理文本的長度小於預設下限閾值時,在待處理文本中添加預設字符,使待處理文本的長度等於預設下限閾值。
在待處理文本的長度大於預設上限閾值時,對待處理文本進行截短處理,使待處理文本的長度等於預設上限閾值。
實際應用中,不同的待處理文本的長度是各不相同的,因此,在構建桶的時候,將待處理文本的長度設置為桶的長度,例如,待處理文本的長度為286,那麼,可以根據預先設置的桶(300,5)、(300,8)和(300,11),在待處理文本中添加預設字符,將待處理文本的長度設置為300。在待處理文本的長度小於預設下限閾值時,同樣地,在待處理文本中添加預設字符,使待處理文本的長度等於預設下限閾值。例如,預設下限閾值為200,待處理文本的長度為183,可以在待處理文本的後面添加預設字符,使待處理文本的長度為200,本發明實施例對預設字符不做具體限定。在待處理文本的長度大於預設上限閾值時,對待處理文本進行截短處理,使待處理文本的長度等於預設上限閾值。例如,預設上限閾值為800,當待處理文本的長度為986時,對待處理文本進行截短處理,可以取待處理文本中的前800個字符,也可以取待處理文本中的後800個字符。另外,預設下限閾值和預設上限閾值可以是根據實際情況設定的值,例如預設下限閾值可以為(100,300)範圍內的值,預設上限閾值可以為(700,1000)範圍內的值。
本發明實施例的一種實現方式中,對訓練數據中每一個樣本文本中的每一個字符進行向量表示,得到每一個樣本文本的字符矩陣,包括:
對每一個樣本文本進行文本倒序,得到倒序的樣本文本。
對倒序的樣本文本中的每一個字符進行向量表示,得到倒序的樣本文本的字符矩陣。
根據每一個樣本文本的字符矩陣和樣本文本中關鍵詞的對應關係,通過lstm神經網絡對訓練數據進行訓練,建立關鍵詞模型,包括:
根據倒序的樣本文本的字符矩陣和樣本文本中關鍵詞的對應關係,通過lstm神經網絡對訓練數據進行訓練,建立關鍵詞模型。
需要說明的是,文本倒序指的是將文本按照相反的順序進行表示。例如:樣本文本為:我是一名來自a大學的大學生,那麼,得到的倒序的樣本文本為:生學大的學大a自來名一是我。通過多次試驗表明,將文本倒序輸入關鍵詞模型會得到更好的效果,即,生成關鍵詞的準確性更高。主要原因在於雖然lstm能夠解決長程依賴問題,但是隨著數據的傳遞,前向信息的損失也在增加,同時,當訓練數據為新聞數據時,由於新聞自身的性質決定重要的新聞信息一般都會放在靠前的位置。因此,本發明實施例中,對每一個樣本文本進行文本倒序,對倒序的樣本文本中的每一個字符進行向量表示,得到倒序的樣本文本的字符矩陣,然後對倒序的樣本文本的字符矩陣和對應的該樣本文本中的關鍵詞進行訓練,得到關鍵詞模型。
可選的,本發明實施例的文本關鍵詞生成方法中,獲取待檢測文本,包括:
刪除文本數據中的數字字符和標點符號,得到待檢測文本。
具體的,待檢測文本可以是對文本數據進行預處理之後得到的文本。文本數據是包含多種字符的文本,文本數據中的特殊字符對於關鍵詞的提取是沒有貢獻的。那麼,可以刪除文本數據中的特殊字符,特殊字符包括:數字字符和標點符號等。在對文本數據進行預處理之後,得到待檢測文本,然後再對待檢測文本進行向量表示,可以減小計算量,提高關鍵詞生成的效率。
本發明實施例的一種實現方式中,計算關鍵詞矩陣中的每一個向量和向量模型中的字符向量的相似度,根據相似度獲取待檢測文本的關鍵詞,包括:
計算關鍵詞矩陣中的每一個向量和向量模型中的字符向量的餘弦值。
將每一個餘弦值中最大值對應的向量模型中的字符作為目標字符,依次獲取目標字符,得到待檢測文本的關鍵詞。
需要說明的是,由於關鍵詞矩陣和字符向量是一個多維向量,兩個多維向量之間的相似度可以通過計算兩個向量之間的餘弦值判斷,兩個向量之間的餘弦值指的是,兩個向量形成的夾角的餘弦值。在通過餘弦值對關鍵詞矩陣中的每一個向量和向量模型中的字符向量進行判斷時,餘弦值與整數1越接近,表明兩個向量越接近。那麼,餘弦值中最大值對應的向量模型中的字符即為目標字符,也就是待檢測文本的關鍵詞對應的字符。由於關鍵詞矩陣中的每一個向量表示一個字符,因此,得到的目標字符為多個,依次獲取目標字符,即可得到待檢測文本的關鍵詞。
另外,也可以通過計算兩個向量之間的歐式距離判斷兩個向量之間的相似度。歐式距離指在多維空間中兩個點之間的真實距離,或者向量的自然長度。在通過歐式距離進行判斷時,歐式距離越小,表明兩個向量之間相似度越高。當然,現有的計算向量相似度的方法都屬於本發明實施例的保護範圍。
相應於上述方法實施例,本發明實施例還公開了一種文本關鍵詞生成裝置,參見圖3,圖3為本發明實施例的文本關鍵詞生成裝置的一種結構圖,包括:
字符矩陣獲取模塊301,用於獲取待檢測文本,對待檢測文本中的每一個字符進行向量表示,得到待檢測文本的字符矩陣。
關鍵詞矩陣生成模塊302,用於將待檢測文本的字符矩陣輸入預先建立的關鍵詞模型,得到待檢測文本的字符矩陣對應的關鍵詞矩陣。
關鍵詞生成模塊303,用於計算關鍵詞矩陣中的每一個向量和向量模型中的字符向量的相似度,根據相似度獲取待檢測文本的關鍵詞。
可見,本發明實施例的文本關鍵詞生成裝置,通過對獲取到的待檢測文本中的每一個字符進行向量表示,得到待檢測文本的字符矩陣。將待檢測文本的字符矩陣輸入預先建立的關鍵詞模型,即可得到待檢測文本的字符矩陣對應的關鍵詞矩陣。計算關鍵詞矩陣中的每一個向量和向量模型中的字符向量的相似度,根據相似度獲取待檢測文本的關鍵詞。本發明實施例通過時間遞歸神經網絡得到待檢測文本的關鍵詞,提高了文本關鍵詞生成的準確性。
需要說明的是,本發明實施例的裝置是應用上述文本關鍵詞生成方法的裝置,則上述文本關鍵詞生成方法的所有實施例均適用於該裝置,且均能達到相同或相似的有益效果。
參見圖4,圖4為本發明實施例的文本關鍵詞生成裝置的另一種結構圖,包括:
訓練數據構建模塊401,用於構建訓練數據。
樣本字符矩陣生成模塊402,用於對訓練數據中每一個樣本文本中的每一個字符進行向量表示,得到每一個樣本文本的字符矩陣。
樣本關鍵詞矩陣生成模塊403,用於對訓練數據中每一個樣本文本對應的關鍵詞中的每一個字符進行向量表示,得到每一個樣本文本的關鍵詞矩陣。
關鍵詞模型建立模塊404,用於根據每一個樣本文本的字符矩陣和每一個樣本文本的關鍵詞矩陣的對應關係,通過lstm神經網絡對訓練數據進行訓練,建立關鍵詞模型。
可選的,本發明實施例的關鍵詞生成裝置中,訓練數據構建模塊,包括:
預處理子模塊,用於獲取多個待訓練文本,對多個待訓練文本中的每一個待訓練文本進行過濾,得到多個待處理文本。
長度設置子模塊,用於對多個待處理文本中的每一個待處理文本進行長度設置,得到樣本文本。
關鍵詞提取子模塊,用於根據每一個樣本文本的長度,以及預先建立的文本長度和關鍵詞個數的對應關係,提取每一個樣本文本中的關鍵詞。
對應關係建立子模塊,用於建立樣本文本和樣本文本中關鍵詞的對應關係。
可選的,本發明實施例的關鍵詞生成裝置中,預處理子模塊,包括:
第一刪除單元,用於刪除每一個待訓練文本中的數字字符和標點符號。和/或,
第二刪除單元,用於刪除每一個待訓練文本中出現次數小於預設閾值的詞語。
可選的,本發明實施例的關鍵詞生成裝置中,長度設置子模塊,包括:
第一長度設置單元,用於在待處理文本的長度小於預設下限閾值時,在待處理文本中添加預設字符,使待處理文本的長度等於預設下限閾值。
第二長度設置單元,用於在待處理文本的長度大於預設上限閾值時,對待處理文本進行截短處理,使待處理文本的長度等於預設上限閾值。
可選的,本發明實施例的關鍵詞生成裝置中,樣本字符矩陣生成模塊,包括:
倒序設置子模塊,用於對每一個樣本文本進行文本倒序,得到倒序的樣本文本。
向量表示子模塊,用於對倒序的樣本文本中的每一個字符進行向量表示,得到倒序的樣本文本的字符矩陣。
關鍵詞模型建立模塊具體用於,根據倒序的樣本文本的字符矩陣和樣本文本中關鍵詞的對應關係,通過lstm神經網絡對訓練數據進行訓練,建立關鍵詞模型。
可選的,本發明實施例的關鍵詞生成裝置中,字符矩陣獲取模塊具體用於,刪除文本數據中的數字字符和標點符號,得到待檢測文本。
可選的,本發明實施例的關鍵詞生成裝置中,關鍵詞生成模塊,包括:
相似度計算子模塊,用於計算關鍵詞矩陣中的每一個向量和向量模型中的字符向量的餘弦值。
生成子模塊,用於將每一個餘弦值中最大值對應的向量模型中的字符作為目標字符,依次獲取目標字符,得到待檢測文本的關鍵詞。
本發明實施例還提供了一種電子設備,參見圖5,圖5為本發明實施例的電子設備的結構圖,包括:處理器501、通信接口502、存儲器503和通信總線504,其中,處理器501、通信接口502、存儲器503通過通信總線504完成相互間的通信;
存儲器503,用於存放電腦程式;
處理器501,用於執行存儲器503上所存放的程序時,實現以下步驟:
獲取待檢測文本,對待檢測文本中的每一個字符進行向量表示,得到待檢測文本的字符矩陣;
將待檢測文本的字符矩陣輸入預先建立的關鍵詞模型,得到待檢測文本的字符矩陣對應的關鍵詞矩陣;
計算關鍵詞矩陣中的每一個向量和向量模型中的字符向量的相似度,根據相似度獲取待檢測文本的關鍵詞,其中,向量模型包括:字符和所述字符對應的字符向量。
需要說明的是,上述電子設備提到的通信總線504可以是pci(peripheralcomponentinterconnect,外設部件互連標準)總線或eisa(extendedindustrystandardarchitecture,擴展工業標準結構)總線等。該通信總線504可以分為地址總線、數據總線、控制總線等。為便於表示,圖5中僅用一條粗線表示,但並不表示僅有一根總線或一種類型的總線。
通信接口502用於上述電子設備與其他設備之間的通信。
存儲器503可以包括ram(randomaccessmemory,隨機存取存儲器),也可以包括非易失性存儲器(non-volatilememory),例如至少一個磁碟存儲器。可選的,存儲器還可以是至少一個位於遠離前述處理器的存儲裝置。
上述的處理器501可以是通用處理器,包括:cpu(centralprocessingunit,中央處理器)、np(networkprocessor,網絡處理器)等;還可以是dsp(digitalsignalprocessing,數位訊號處理器)、asic(applicationspecificintegratedcircuit,專用集成電路)、fpga(field-programmablegatearray,現場可編程門陣列)或者其他可編程邏輯器件、分立門或者電晶體邏輯器件、分立硬體組件。
由以上可見,本發明實施例的電子設備中,處理器通過執行存儲器上所存放的程序,從而獲取待檢測文本,對待檢測文本中的每一個字符進行向量表示,得到待檢測文本的字符矩陣;將待檢測文本的字符矩陣輸入預先建立的關鍵詞模型,得到待檢測文本的字符矩陣對應的關鍵詞矩陣;計算關鍵詞矩陣中的每一個向量和向量模型中的字符向量的相似度,根據相似度獲取待檢測文本的關鍵詞。本發明實施例通過時間遞歸神經網絡得到待檢測文本的關鍵詞,提高了文本關鍵詞生成的準確性。
本發明實施例還提供了一種計算機可讀存儲介質,計算機可讀存儲介質內存儲有電腦程式,電腦程式被處理器執行時,使得計算機執行上述實施例中任一所述的方法。
由以上可見,本發明實施例的計算機可讀存儲介質內存儲的電腦程式被處理器執行時,獲取待檢測文本,對待檢測文本中的每一個字符進行向量表示,得到待檢測文本的字符矩陣;將待檢測文本的字符矩陣輸入預先建立的關鍵詞模型,得到待檢測文本的字符矩陣對應的關鍵詞矩陣;計算關鍵詞矩陣中的每一個向量和向量模型中的字符向量的相似度,根據相似度獲取待檢測文本的關鍵詞。本發明實施例通過時間遞歸神經網絡得到待檢測文本的關鍵詞,提高了文本關鍵詞生成的準確性。
在本發明提供的又一實施例中,還提供了一種包含指令的電腦程式產品,當其在計算機上運行時,使得計算機執行上述實施例中任一所述的方法。
在上述實施例中,可以全部或部分地通過軟體、硬體、固件或者其任意組合來實現。當使用軟體實現時,可以全部或部分地以電腦程式產品的形式實現。所述電腦程式產品包括一個或多個計算機指令。在計算機上加載和執行所述電腦程式指令時,全部或部分地產生按照本發明實施例所述的流程或功能。所述計算機可以是通用計算機、專用計算機、計算機網絡、或者其他可編程裝置。所述計算機指令可以存儲在計算機可讀存儲介質中,或者從一個計算機可讀存儲介質向另一個計算機可讀存儲介質傳輸,例如,所述計算機指令可以從一個網站站點、計算機、伺服器或數據中心通過有線(例如同軸電纜、光纖、數字用戶線(dsl))或無線(例如紅外、無線、微波等)方式向另一個網站站點、計算機、伺服器或數據中心進行傳輸。所述計算機可讀存儲介質可以是計算機能夠存取的任何可用介質或者是包含一個或多個可用介質集成的伺服器、數據中心等數據存儲設備。所述可用介質可以是磁性介質,(例如,軟盤、硬碟、磁帶)、光介質(例如,dvd)、或者半導體介質(例如固態硬碟solidstatedisk(ssd))等。
需要說明的是,在本文中,諸如第一和第二等之類的關係術語僅僅用來將一個實體或者操作與另一個實體或操作區分開來,而不一定要求或者暗示這些實體或操作之間存在任何這種實際的關係或者順序。而且,術語「包括」、「包含」或者其任何其他變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者設備不僅包括那些要素,而且還包括沒有明確列出的其他要素,或者是還包括為這種過程、方法、物品或者設備所固有的要素。在沒有更多限制的情況下,由語句「包括一個……」限定的要素,並不排除在包括所述要素的過程、方法、物品或者設備中還存在另外的相同要素。
本說明書中的各個實施例均採用相關的方式描述,各個實施例之間相同相似的部分互相參見即可,每個實施例重點說明的都是與其他實施例的不同之處。尤其,對於系統實施例而言,由於其基本相似於方法實施例,所以描述的比較簡單,相關之處參見方法實施例的部分說明即可。
以上所述僅為本發明的較佳實施例而已,並非用於限定本發明的保護範圍。凡在本發明的精神和原則之內所作的任何修改、等同替換、改進等,均包含在本發明的保護範圍內。