基於決策樹的數控車床車削過程能耗預測系統的製作方法
2023-05-29 14:30:26 2
本發明涉及工具機控制系統技術領域,尤其涉及一種基於決策樹的數控車床車削過程能耗預測系統。
背景技術:
目前,對數控車床的車削過程能耗的預測還沒有形成比較統一的技術體系。傳統的方法主要是有經驗的操作工依據經驗和操作手冊綜合選擇合適的車削參數,或者通過現場切削實驗或者監測加工過程來合理選擇車削參數。這種方法受工人的主觀因素、具體的車床種類以及加工方法、加工對象不同的影響而差異很大,無法大規模普及。有學者提出各種不同的假設和理論模型,將多種數學方法應用於數控車床的車削過程能耗的預測中,如支持向量機法、神經網絡法等。不可否認這些方法雖然取得了一定的成果,但各有其不足之處。
現有的支持向量機法,藉助二次規劃來求解支持向量時涉及m階矩陣的計算(m為樣本的個數),當m數目很大時該矩陣的存儲和計算將耗費大量的機器內存和運算時間。此外,經典的支持向量機法只給出了二類分類的算法,對於數據挖掘的實際應用中涉及的多類分類問題需要結合其他算法加以解決,比較複雜。
現有的神經網絡法,存在樣本數據訓練時間長甚至完全不能訓練的情況。此外,存在樣本訓練過程中學習新樣本時有遺忘舊樣本的趨勢。
技術實現要素:
本發明的目的是針對現有技術存在的問題,提供一種基於決策樹的數控車床車削過程能耗預測系統,利用數據挖掘技術中的決策樹算法,充分衡量各種因素對數控車床車削過程能耗的影響,建立各車削參數與車削過程能耗的定量關係,從而建立能耗決策樹預測模型,來進行數控工具機車削過程的能耗預測。
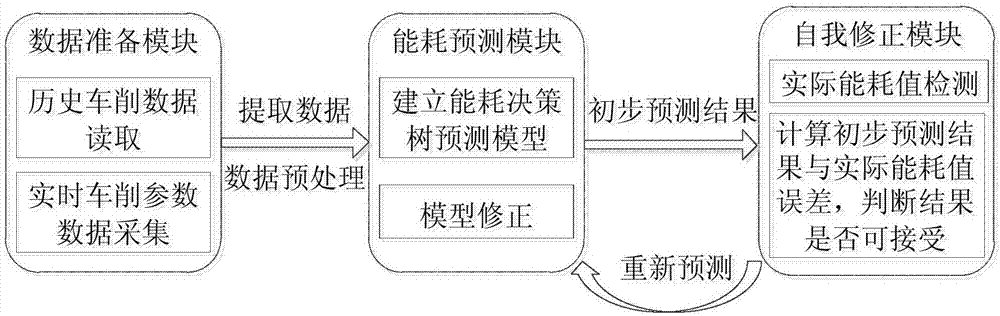
為實現上述目標,本發明採用的技術方案如下:所述的基於決策樹的數控車床車削過程能耗預測系統包括數據準備模塊、能耗預測模塊、自我修正模塊,其中,數據準備模塊主要包括歷史車削能耗數據讀取模塊以及實時車削參數數據採集模塊兩大部分,從車削參數資料庫中選取包括刀具類型、主軸轉速、進給量和切削深度在內的主要參數屬性構成屬性集作為評價指標,對從車削參數資料庫中提取的各參數屬性值以及實時檢測的各參數屬性值進行預處理,並將連續型屬性離散化,轉換成調用決策樹算法所需的數據格式,再傳送至能耗預測模塊;數據準備模塊的工作完成後,實時車削參數數據採集模塊與能耗預測模塊協同工作,調用決策樹算法,計算各參數屬性的信息增益率,選取信息增益率最大的屬性作為決策樹的根結點,再由該屬性的不同取值建立分支,調用此方法建立決策樹各節點的分支,直到所有子集只包含同一類別的數據為止,建立車削過程能耗決策樹預測模型;然後對模型進行修正,以提高模型預測精度,輸出初步的能耗預測結果;得到初步的能耗預測結果後,自我修正模塊與能耗預測模塊協同工作,對初步預測結果進行修正,得到最終的預測結果。
進一步的,在數據準備階段,從車削參數資料庫依據歷史車削參數與車削能耗的關係,獲取大量已知的樣本基礎數據構成樣本集,然後將樣本集劃分為兩類樣本,一類用作訓練樣本集s,用於建立能耗決策樹預測模型,一類作為測試樣本集,用來對初步建立的能耗決策樹預測模型中不正確的數據進行修正。
進一步的,訓練樣本集s中初步提取的各類車削參數都是具體的數值,具有連續屬性,構成屬性集a={a1,a2,...,an},表示屬性集a中共有n個屬性,每個屬性aj具有t個不同的取值即aj={a1,a2,...,at},j=1,2...n,將訓練樣本集s劃分為t個子集s={s1,s2,...,st},需要對屬性aj,j=1,2...n中的連續屬性值進行離散化處理,具體方法為:將屬性aj,j=1,2...n中t個不同的取值按照從小到大的順序依次排列,排列後的屬性取值序列為b1、b2、...、bt,逐一求取兩個相鄰值的平均值作為分割點;這t-1個分割點將屬性取值分別分為對應於aj≤c和aj>c,j=1,2...n的兩個子集,計算信息增益率,取出其中最大的信息增益率gr(c』)對應的分割點c』作為局部閾值,則按連續屬性aj,j=1,2...n劃分樣本集s的信息增益率為gr(c』);然後在b1、b2、...、bt中取不超過但又最接近局部閾值c』的取值c作為屬性aj,j=1,2...n的分割閾值。
進一步的,計算出訓練樣本集s中每個參數屬性的信息增益率的方法為:訓練樣本集s={s1,s2,...,sm},包含m個類ci,i=1,2,...,m,si為類ci中的樣本數,將進行分類的需要的信息量記為i(s),則:
其中,pi為訓練樣本集s中任意樣本屬於類ci的概率。訓練樣本集s按照上述屬性aj={a1,a2,...,at},j=1,2...n,的t個不同的取值劃分成t個子集,記為s={s1,s2,...,st},其中,sj,j=1,2...t是s的子集,它們在屬性aj,j=1,2...n上具有值aj,其中,aj為屬性aj的第j個分量。則由屬性aj,j=1,2...n劃分子集的信息熵e(aj)可表示為:
則可得到由屬性aj劃分子集的信息增益g(aj)表示為:
g(aj)=i(s)-e(aj),j=1,2...t;
信息增益率等於信息增益對分割信息量的比值,由分割信息量計算公式:
得出最終則由屬性aj劃分子集的信息增益率gr(aj)表示為:
進一步的,建立能耗決策樹預測模型的方法為:分別計算出訓練樣本集s中每個參數屬性的信息增益率,選取具有最大信息增益率的屬性作為測試屬性,建立決策樹的根結點,這樣,將樣本集劃分為若干子集;採用同樣的方法依次對子集進行新一輪的劃分,直到不可劃分或達到終止條件為止,建立初步的決策樹預測模型;同時,將實時檢測的車削參數數據代入決策樹模型,結合歷史數據,生成初步的預測結果,並將結果存入車削參數基礎資料庫中形成歷史數據。
進一步的,對生成的能耗決策樹預測模型進行修正的方法為:一方面,使用測試樣本集對生成的能耗決策樹中不正確的數據進行修正,另一方面,定時對樣本進行更新以提高能耗決策樹預測模型的準確性;可以選擇具有典型特徵的樣本加入訓練樣本集中,而資料庫中已有的重複的樣本數據則無需加入,具體的操作方法如下:
設有p個樣本的數據集e=(e1,e2...ep),其中心樣本為et,t∈(1,2,...,p);設ei為待檢測的數據樣本即ej為數據集e中的已知的數據樣本,j=1,2...p,則可以通過樣本與樣本之間的距離l(ei,ej)來衡量樣本間的相似度:
其中,ei,為待檢測的數據樣本,ej,j=1,2...p為數據集e中的已知的數據樣本,設定閾值ξ,若l(ei,ej)/l(ej,et)>ξ,則將其加入數據集e中作為新的樣本數據保存並重新訓練能耗預測決策樹;否則認為樣本數據集e中已存在重複的樣本數據,即不需將其加入樣本數據集e中;其中,為數據集e的中心樣本。
進一步的,所述自我修正模塊內置實際的能耗探測裝置,將能耗預測模塊預測的初步預測結果與能耗探測裝置實際檢測到的能耗相比較,得到誤差e;事先根據實際問題的要求,設置誤差允許範圍,當誤差e在所設置的誤差允許範圍內時,則該預測結果被判斷為可接受;當誤差e不在誤差允許範圍時,自我修正模塊將結果反饋到能耗預測模塊,能耗預測模塊結合所得的誤差e,重新預測並重新計算新一輪的誤差,重複上述過程直到得到的誤差滿足根據實際情況設置的判斷標準;如此,通過自我修正模塊對初步預測結果進行修正,將得到的修正量再與初步預測結果相結合,從而得到最終的預測結果。
與現有技術相比,本發明的有益效果為:
本發明充分考慮了各種因素對數控工具機車削能耗的影響,利用數據挖掘技術中的決策樹算法得到車削能耗與車削參數之間的定量關係,再與自我修正模塊相結合,對初步預測結果進行修正,來進行數控工具機車削過程的能耗預先測算,用於指導實際加工過程。此外,可根據實際情況不斷更新模型,從而不斷提高預測模型的預測精度,使操作者能夠選擇更加合理的車削參數,最終幫助企業提高加工效率。
附圖說明
圖1為本發明的數控工具機車削過程能耗預測系統的結構示意圖。
圖2為本發明的數控工具機車削過程能耗預測的流程圖。
具體實施方式
下面結合附圖對本發明進行詳細說明。
如圖1所示,本發明主要包括三大模塊,具體分別為:數據準備模塊、能耗預測模塊、自我修正模塊。其中,數據準備模塊主要包含歷史車削能耗數據讀取以及實時車削參數數據採集兩大模塊,主要完成的任務是對各類數據進行預處理,將其轉換成數據挖掘決策樹算法所需的數據格式,再傳送至能耗預測模塊;數據準備模塊的工作完成後,將實時車削參數數據採集模塊與能耗預測模塊結合,調用決策樹算法,然後對模型進行修正,輸出初步的能耗預測結果;自我修正模塊具有自我學習和自我完善的功能,得到初步的能耗預測結果後,將數據傳送至自我修正模塊對初步預測結果進行修正,即可得到最終的預測結果。總體步驟為:
步驟一:數據準備模塊完成歷史車削能耗數據的讀取以及實時車削參數數據的採集兩大任務,並對所得的各類數據進行預處理,將其轉換成數據挖掘決策樹算法所需的數據格式後傳送至能耗預測模塊;
步驟二:步驟一中數據準備模塊任務完成後,實時車削參數數據採集模塊與能耗預測模塊協同工作,調用決策樹算法,建立車削過程能耗決策樹預測模型;
步驟三:對步驟二中得到的能耗決策樹預測模型進行修正,得到初步的預測結果;
步驟四:將步驟三中所得到的初步預測結果傳送到自我修正模塊,自我修正模塊與能耗預測模塊協同工作,對初步預測結果進行修正,得到最終的預測結果。
如圖2所示,本發明進行數控車床車削過程能耗預測的步驟包括:
步驟1.1:數據準備模塊從車削參數資料庫中選取刀具類型、主軸轉速、進給量和切削深度等主要參數屬性構成屬性集作為評價指標;
步驟1.2:對從車削參數資料庫中提取的各參數屬性值以及實時檢測的各參數屬性值進行預處理,並將連續型屬性離散化,轉換成調用決策樹算法所需的數據格式,再傳送至能耗預測模塊;
步驟2:計算各參數屬性的信息增益率,選取信息增益率最大的屬性作為決策樹的根結點,再由該屬性的不同取值建立分支,調用此方法建立決策樹各節點的分支,直到所有子集只包含同一類別的數據為止,建立車削過程能耗決策樹預測模型;
步驟3:對步驟2中建立的能耗決策樹預測模型進行修正,以提高模型預測精度,輸出初步的能耗預測結果;
步驟4:將初步預測結果傳送到自我修正模塊,自我修正模塊與能耗預測模塊協同工作,對初步預測結果進行修正,得到最終的預測結果。
以下結合實施例對本發明的實施過程和原理進行進一步說明。
1、車削參數基礎數據提取。
如圖2所示,在數控工具機車削過程能耗預測過程中,首先是數據準備階段,即從車削參數資料庫依據歷史車削參數與車削能耗的關係,獲取大量已知的樣本基礎數據構成樣本集,然後將樣本集劃分為兩類樣本,一類用作訓練樣本集s,用於建立能耗決策樹預測模型,一類作為測試樣本集,用來對初步建立的能耗決策樹預測模型中不正確的數據進行修正。由於原始數據中包含大量不完整的、含噪聲的數據,必須對原始數據進行預處理以提高數據的質量,從而提高預測結果的準確性。
2、對訓練樣本集s中的連續屬性值進行離散化處理,計算信息增益率。
訓練樣本集s中初步提取的各類車削參數都是具體的數值,具有連續屬性,構成屬性集a={a1,a2,...,an},表示屬性集a中共有n個屬性,每個屬性aj具有t個不同的取值即aj={a1,a2,...,at},j=1,2...n,將訓練樣本集s劃分為t個子集s={s1,s2,...,st},需要對屬性aj,j=1,2...n中的連續屬性值進行離散化處理,具體方法為:將屬性aj,j=1,2...n中t個不同的取值按照從小到大的順序依次排列,排列後的屬性取值序列為b1、b2、...、bt,逐一求取兩個相鄰值的平均值作為分割點;這t-1個分割點將屬性取值分別分為對應於aj≤c和aj>c,j=1,2...n的兩個子集,計算信息增益率,取出其中最大的信息增益率gr(c』)對應的分割點c』作為局部閾值,則按連續屬性aj,j=1,2...n劃分樣本集s的信息增益率為gr(c』);然後在b1、b2、...、bt中取不超過但又最接近局部閾值c』的取值c作為屬性aj,j=1,2...n的分割閾值。
3、建立能耗決策樹預測模型。
訓練樣本集s={s1,s2,...,sm},包含m個類ci,i=1,2,...,m,si為類ci中的樣本數,將進行分類的需要的信息量記為i(s),則:
其中,pi為訓練樣本集s中任意樣本屬於類ci的概率。訓練樣本集s按照上述屬性aj={a1,a2,...,at},j=1,2...n,的t個不同的取值劃分成t個子集,記為s={s1,s2,...,st},其中,sj,j=1,2...t是s的子集,它們在屬性aj,j=1,2...n上具有值aj,其中,aj為屬性aj的第j個分量。則由屬性aj,j=1,2...n劃分子集的信息熵e(aj)可表示為:
則可得到由屬性aj劃分子集的信息增益g(aj)表示為:
g(aj)=i(s)-e(aj),j=1,2...t;
信息增益率等於信息增益對分割信息量的比值,由分割信息量計算公式:
得出最終則由屬性aj劃分子集的信息增益率gr(aj)表示為:
由此,分別計算出訓練樣本集s中每個參數屬性的信息增益率,選取具有最大信息增益率的屬性作為測試屬性,建立決策樹的根結點,這樣,將樣本集劃分為若干子集。採用同樣的方法依次對子集進行新一輪的劃分,直到不可劃分或達到終止條件為止,建立初步的能耗決策樹預測模型。同時,將實時檢測的車削參數數據代入決策樹模型,結合歷史數據,生成初步的預測結果,並將結果存入車削參數資料庫中形成歷史數據。
4、對生成的能耗決策樹預測模型進行修正。
一方面,使用測試樣本集對生成的能耗決策樹中不正確的數據進行修正,另一方面,由於數控車床實際運行的車削參數可能發生變化,需要定時對樣本進行更新以提高能耗決策樹預測模型的準確性。鑑於樣本數據非常龐大,可以選擇具有典型特徵的樣本加入樣本訓練集中,而資料庫中已有的重複的樣本數據則無需加入,具體的操作方法如下:
設有p個樣本的數據集e=(e1,e2...ep),其中心樣本為et,t∈(1,2,...,p)。設ei為待檢測的數據樣本即ej(j=1,2...p)為數據集e中的已知的數據樣本,則可以通過樣本與樣本之間的距離1(ei,ej)來衡量樣本間的相似度:
其中,ei,為待檢測的數據樣本,ej(j=1,2...p)為數據集e中的已知的數據樣本,設定閾值ξ,若l(ei,ej)/l(ej,et)>ξ,(其中,為數據集e的中心樣本),則將其加入數據集e中作為新的樣本數據保存並重新訓練能耗預測決策樹;否則認為樣本數據集e中已存在重複的樣本數據,即不需將其加入樣本數據集e中。同時,還可將能耗決策樹預測模型與相應專家系統相結合,利用專業的專家知識對能耗決策樹預測模型做進一步的完善,則可進一步提高模型的預測精度。
5、自我修正模塊對初步的能耗預測結果進行修正。
自我修正模塊內置實際的能耗探測裝置,建立的能耗修正模型具有學習和記憶的功能。將能耗預測模塊預測的初步預測結果與能耗探測裝置實際檢測到的能耗相比較,得到誤差e,事先根據實際問題的要求,設置合理的誤差允許範圍作為結果的判斷標準,當誤差e滿足所設置的判斷標準時,則該預測結果被判斷為可接受;當誤差e不滿足判斷標準時,自我修正模塊將結果反饋到能耗預測模塊,能耗預測模塊結合所得的誤差e,重新預測並重新計算新一輪的誤差,重複上述過程直到得到的誤差滿足根據實際情況設置的判斷標準。這樣,通過反饋使得每次得到的初步預測結果不斷得到修正,越來越接近能耗的真實值,從而提高預測的精度。如此,通過自我修正模塊對初步預測結果進行修正,將得到的修正量再與初步預測結果相結合,從而得到最終的預測結果。
本發明提出了一種基於決策樹的數控車床車削過程能耗預測系統及方法,主要包括如何獲取車削參數訓練樣本集以及屬性集,以及如何生成能耗決策樹預測模型,並給出預測結果的修正方案,通過本發明的方法,能夠有效指導數控車床車削過程合理選擇車削參數,並且預測結果更準確,具有實用價值。