一種駕駛員情緒識別方法和裝置與流程
2023-05-30 12:56:32 4
本發明涉及汽車智能交互技術領域,尤其涉及一種駕駛員情緒識別方法和裝置。
背景技術:
隨著汽車的全球化普及以及汽車智能化的起步,人類對於汽車良好體驗的需求,使得人們希望汽車越來越懂自己,並且可以根據自己的性格與狀態定製對應的服務內容,人們希望汽車知道自己是誰,懂得自己的情感與需求,希望汽車在自己需要服務的時候主動提供服務。這樣對於車內人員的情緒識別與身份識別將會起到一個非常重要的作用,讓車可以更好的理解人以及提供更人性化與準確的服務。
在汽車駕駛中,行駛安全最為重要,但大多數的交通事故都是人為因素導致的,而車內人員的情緒則是導致人為交通事故的重要原因。在行車過程中,由於長途的駕駛容易導致駕駛員疲勞睏倦,而堵車、糟糕的路況以及其它的車輛也會導致車內人員的憤怒等不良情緒。因此有必要對車內人員的情緒進行識別,以便防止可能出現的交通事故。
現階段的車內人員的情緒識別一般是通過單一的方式進行識別,然而,單一的情緒識別方法無法達到準確識別車內人員情緒以及身份的效果,且單一方法在情緒識別所獲取的數據有限,判斷機制單一,故存在識別的準確度低、誤差大和容易受外界因素影響等問題。
技術實現要素:
鑑於上述問題,提出了本發明以便提供一種至少解決上述問題的駕駛員情緒識別方法和裝置。
依據本發明的一個方面,提供一種駕駛員情緒識別方法,包括:
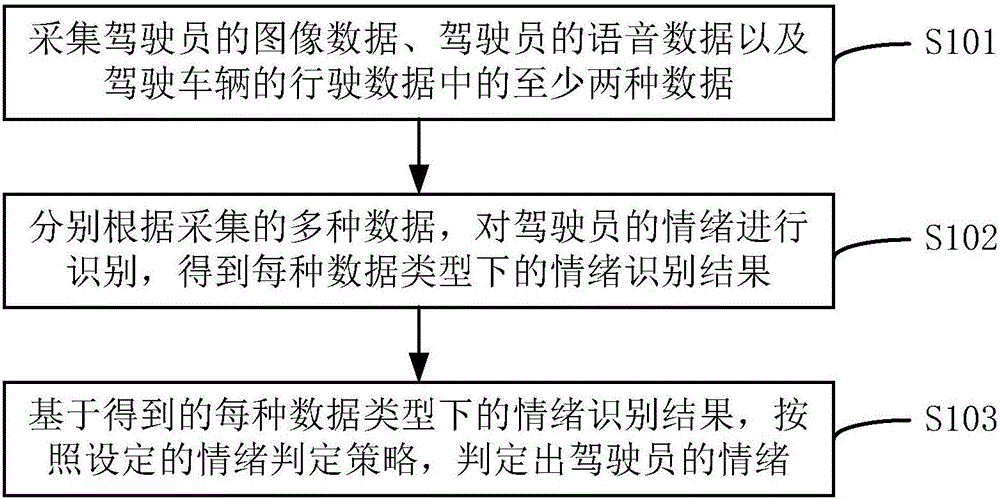
採集駕駛員的圖像數據、駕駛員的語音數據以及駕駛車輛的行駛數據中的至少兩種數據;
分別根據採集的多種數據,對駕駛員的情緒進行識別,得到每種數據類型下的情緒識別結果;
基於得到的每種數據類型下的情緒識別結果,按照設定的情緒判定策略,判定出駕駛員的情緒。
可選地,本發明所述方法中,所述情緒識別結果包括:識別出的情緒類型及識別出該情緒類型的置信度。
可選地,本發明所述方法中,所述基於得到的每種數據類型下的情緒識別結果,按照設定的情緒判定策略,判定出駕駛員的情緒,包括:
當至少兩個情緒識別結果中的情緒類型相同且置信度分別大於等於設定的對應數據類型的第一情緒置信度閾值時,將所述至少兩個情緒識別結果中的情緒類型作為最終識別出的駕駛員的情緒;
當各情緒識別結果中存在一個情緒識別結果的情緒類型的置信度大於等於設定的對應數據類型的第二情緒置信度閾值時,將該情緒識別結果中的情緒類型作為最終識別出的駕駛員的情緒;
其中,同一數據類型下的第一情緒置信度閾值小於第二情緒置信度閾值。
可選地,本發明所述方法中,所述判定出駕駛員的情緒之後,還包括:根據預設的情緒類型的置信度與情緒類型級別的對應關係,得到最終識別出的駕駛員的情緒的情緒級別。
可選地,本發明所述方法中,所述根據語音數據,對駕駛員的情緒進行識別,具體包括:提取語音數據中的聲紋特徵、以及識別所述語音數據中的語義,根據所述聲紋特徵和所述語義,對駕駛員的情緒進行識別。
可選地,本發明所述方法還包括:
當採集到圖像數據或者語音數據時,根據所述圖像數據或者語音數據,識別出駕駛員的身份;當採集到圖像數據和語音數據時,分別根據所述圖像數據和語音數據,對駕駛員的身份進行識別,得到兩種數據類型下的兩個身份識別結果,並基於得到的兩個身份識別結果,按照設定的身份判定策略,判定出駕駛員的身份。
可選地,本發明所述方法中,所述身份識別結果包括:識別出的用戶及識別出該用戶的置信度;
所述基於得到的兩個身份識別結果,按照設定的身份判定策略,判定出駕駛員的身份,包括:
當兩個身份識別結果中識別出的用戶相同且置信度分別大於等於設定的對應數據類型的第一身份置信度閾值時,以共同識別出的用戶作為最終的用戶身份識別結果;
當兩個身份識別結果中有一個身份識別結果中識別出的用戶的置信度大於等於設定的對應數據類型的第二身份置信度閾值時,以用戶的置信度大於等於第二置信度身份閾值對應的用戶,作為最終的用戶身份識別結果;
其中,同一數據類型下的第一身份置信度閾值小於第二身份置信度閾值。
可選地,本發明所述方法還包括:
利用得到的駕駛員的身份,在預先建立的各用戶行為習慣模型中匹配出與該駕駛員對應的用戶行為習慣模型,並將駕駛員的情緒信息輸入到匹配的用戶行為習慣模型中,以對駕駛員的狀態和/或行為進行預判,並根據預判結果,主動提供與預判結果相匹配的服務。
可選地,本發明所述方法中,所述根據預判結果,主動提供與預判結果相匹配的服務,具體包括:
確定與所述預判結果相匹配的服務,向用戶發出是否需要所述服務的詢問,並在確定出用戶需要時,向用戶提供所述服務。
可選地,本發明所述方法中,向用戶提供的與預判結果相匹配的服務,包括:內容服務和/或設備狀態控制服務;所述設備狀態控制服務包括:控制所述智能語音設備和/或與所述智能語音設備連接的設備到目標狀態。
依據本發明的一個方面,提供一種駕駛員情緒識別裝置,包括:
信息採集模塊,用於採集駕駛員的圖像數據、駕駛員的語音數據以及駕駛車輛的行駛數據中的至少兩種數據;
情緒識別模塊,用於分別根據採集的多種數據,對駕駛員的情緒進行識別,得到每種數據類型下的情緒識別結果;
情緒判定模塊,用於基於得到的每種數據類型下的情緒識別結果,按照設定的情緒判定策略,判定出駕駛員的情緒。
可選地,本發明所述裝置中,所述情緒識別結果包括:識別出的情緒類型及識別出該情緒類型的置信度。
可選地,本發明所述裝置中,所述情緒判定模塊,具體用於當至少兩個情緒識別結果中的情緒類型相同且置信度分別大於等於設定的對應數據類型的第一情緒置信度閾值時,將所述至少兩個情緒識別結果中的情緒類型作為最終識別出的駕駛員的情緒;當各情緒識別結果中存在一個情緒識別結果的情緒類型的置信度大於等於設定的對應數據類型的第二情緒置信度閾值時,將該情緒識別結果中的情緒類型作為最終識別出的駕駛員的情緒;其中,同一數據類型下的第一情緒置信度閾值小於第二情緒置信度閾值。
可選地,本發明所述裝置中,情緒判定模塊,還用於在判定出駕駛員的情緒之後,根據預設的情緒類型的置信度與情緒類型級別的對應關係,得到最終識別出的駕駛員的情緒的情緒級別。
可選地,本發明所述裝置中,所述情緒識別模塊,具體用於在根據採集的語音數據對駕駛員的情緒進行識別時,提取語音數據中的聲紋特徵、以及識別所述語音數據中的語義,根據所述聲紋特徵和所述語義,對駕駛員的情緒進行識別。
可選地,本發明所述裝置,還包括:
身份識別模塊,用於當所述信息採集模塊採集到圖像數據或者語音數據時,根據所述圖像數據或者語音數據,識別出駕駛員的身份;當所述信息採集模塊採集到圖像數據和語音數據時,分別根據所述圖像數據和語音數據,對駕駛員的身份進行識別,得到兩種數據類型下的兩個身份識別結果;
身份判定模塊,用於當所述身份識別模塊得到一種數據類型下的身份識別結果時,直接以該結果作為識別出的駕駛員的身份;當所述身份識別模塊得到兩種數據類型下的兩個身份識別結果時,基於得到的兩個身份識別結果,按照設定的身份判定策略,判定出駕駛員的身份。
可選地,本發明所述裝置中,所述身份識別結果包括:識別出的用戶及識別出該用戶的置信度;
所述身份判定模塊,具體用於當兩個身份識別結果中識別出的用戶相同且置信度分別大於等於設定的對應數據類型的第一身份置信度閾值時,以共同識別出的用戶作為最終的用戶身份識別結果;當兩個身份識別結果中有一個身份識別結果中識別出的用戶的置信度大於等於設定的對應數據類型的第二身份置信度閾值時,以用戶的置信度大於等於第二置信度身份閾值對應的用戶,作為最終的用戶身份識別結果,其中,同一數據類型下的第一身份置信度閾值小於第二身份置信度閾值。
可選地,本發明所述裝置還包括:
服務推薦模塊,用於利用得到的駕駛員的身份,在預先建立的各用戶行為習慣模型中匹配出與該駕駛員對應的用戶行為習慣模型,並將駕駛員的情緒信息輸入到匹配的用戶行為習慣模型中,以對駕駛員的狀態和/或行為進行預判,並根據預判結果,主動提供與預判結果相匹配的服務。
可選地,本發明所述裝置中,所述服務推薦模塊,具體用於確定與所述預判結果相匹配的服務,向用戶發出是否需要所述服務的詢問,並在確定出用戶需要時,向用戶提供所述服務。
可選地,本發明所述裝置中,向用戶提供的與預判結果相匹配的服務,包括:內容服務和/或設備狀態控制服務;所述設備狀態控制服務包括:控制所述智能語音設備和/或與所述智能語音設備連接的設備到目標狀態。
本發明有益效果如下:
首先,本發明可分別根據圖像數據、語音數據和車輛行駛數據中的至少兩種進行情緒識別,並根據得到的多個情緒識別結果綜合判斷駕駛員的情緒狀態,這種情緒狀態識別方式不會受單一的道路狀況、車輛狀況、面部特徵和語音特徵等影響,識別出的駕駛員的情緒更加符合實際的駕駛員情緒狀態,提高了情緒識別的準確性及環境適應性。
其次,本發明還可以分別根據圖像數據和語音數據進行駕駛員的身份識別,並根據得到的兩個身份識別結果綜合判斷駕駛員的身份,提高了身份識別的準確性和環境適應性;
第三,本發明還可以根據識別的駕駛員的情緒和身份,進行主動的服務推薦,提高了用戶的使用體驗。
上述說明僅是本發明技術方案的概述,為了能夠更清楚了解本發明的技術手段,而可依照說明書的內容予以實施,並且為了讓本發明的上述和其它目的、特徵和優點能夠更明顯易懂,以下特舉本發明的具體實施方式。
附圖說明
通過閱讀下文優選實施方式的詳細描述,各種其他的優點和益處對於本領域普通技術人員將變得清楚明了。附圖僅用於示出優選實施方式的目的,而並不認為是對本發明的限制。而且在整個附圖中,用相同的參考符號表示相同的部件。在附圖中:
圖1為本發明第一實施例提供的一種駕駛員情緒識別方法的流程圖;
圖2為本發明第三實施例提供的一種駕駛員情緒識別裝置的結構框圖。
具體實施方式
下面將參照附圖更詳細地描述本公開的示例性實施例。雖然附圖中顯示了本公開的示例性實施例,然而應當理解,可以以各種形式實現本公開而不應被這裡闡述的實施例所限制。相反,提供這些實施例是為了能夠更透徹地理解本公開,並且能夠將本公開的範圍完整的傳達給本領域的技術人員。
本發明實施例提供一種駕駛員情緒識別方法和裝置,本發明通過語音數據、圖像數據和駕駛車輛的行駛數據中的至少兩種,對駕駛員的情緒進行識別,並根據識別的多個結果進行綜合性的判斷,使得識別的駕駛員的情緒更加符合實際的駕駛員的情緒狀態,而不會受單一的道路狀況、車輛狀況、面部特徵和語音特徵等影響,能更加準確的識別出車內人員的情緒。所以,本發明提出的情緒識別方案環境適應性更強,可以適合更多環境中的駕駛員的情緒識別。下面就通過幾個具體實施例對本發明的具體實施過程進行詳細闡述。
在本發明的第一實施例中,提供一種駕駛員情緒識別方法,如圖1所示,包括如下步驟:
步驟S101,採集駕駛員的圖像數據、駕駛員的語音數據以及駕駛車輛的行駛數據中的至少兩種數據;
步驟S102,分別根據採集的多種數據,對駕駛員的情緒進行識別,得到每種數據類型下的情緒識別結果;
步驟S103,基於得到的每種數據類型下的情緒識別結果,按照設定的情緒判定策略,判定出駕駛員的情緒。
基於上述原理闡述,下面給出幾個具體及優選實施方式,用以細化和優化本發明所述方法的功能,以使本發明方案的實施更方便,準確。需要說明的是,在不衝突的情況下,如下特徵可以互相任意組合。
本發明實施例中,所述的情緒識別結果包括:識別出的情緒類型及識別出該情緒類型的置信度。其中,情緒類型包括但不限於為:高興、傷心、憤怒、厭煩、疲勞、激動和正常。
進一步地,本發明實施例中,通過布設在車內外的設備傳感器採集駕駛車輛的行駛數據,所述設備傳感器可以包括至少以下一種或幾種傳感器的組合:加速度傳感器、速度傳感器、紅外傳感器、角速度傳感器、雷射測距傳感器、超聲波傳感器等。根據車輛上布設的這些傳感器獲取的信息,就可以得到當前車輛的姿態信息、當前車況信息、當前路況信息、駕駛時長、車輛駕駛軌跡信息等,從而根據以上車輛的行駛數據進行駕駛員的情緒狀態判斷。
在本發明的一個具體實施例中,根據駕駛車輛的行駛數據對駕駛員的情緒進行識別,包括:從所述相關行駛數據中提取相關行駛特徵,根據相關行駛特徵在預設的分類器中進行分類,根據所述分類器中的分類結果識別與所述相關行駛特徵相對應的駕駛員情緒,最後給出對應的識別置信度。具體的,本發明實施例中,採集預設時間內汽車行駛中的訓練行駛信息,並從所述訓練行駛信息中提取訓練行駛特徵;獲取針對不同訓練行駛特徵標註的不同駕駛員情緒,並基於預設的分類算法對不同訓練行駛特徵標註的不同駕駛員情緒進行學習、訓練,形成預設的分類器。
進一步的,本發明實施例中,通過圖像採集裝置,如攝像頭,採集駕駛員的圖像數據。在本發明的一個具體實施例中,根據採集的圖像數據,對駕駛員的情緒進行識別,包括:在先需要進行人臉的離線訓練,所述離線訓練使用人臉的資料庫訓練人臉的檢測器、同時在人臉上標定標記點,根據所述人臉標記點訓練標記點擬合器,並且,通過人臉標記點和情緒的關係訓練情緒分類器。當進行人臉的在線運行時(即需要根據圖像數據進行情緒識別時),通過人臉檢測器在圖像數據中檢測人臉,然後通過標記點擬合器擬合人臉上的標記點,情緒分類器根據人臉標記點判斷當前駕駛員的情緒,最後給出對應的分類置信度。本發明實施例中個,基於圖像的情緒識別的置信度為情緒分類器根據獲取的面部圖像中的人臉標記點而得到的用戶面部表情與在先情緒訓練得到的用戶在不同情緒類型下的面部表情模型進行匹配的匹配度,當匹配度(即置信度)達到一定的閾值,判定為識別出用戶的情緒類型,例如,若匹配的結果為90%(置信度)以上的檢測結果為「愉悅」,則認為「此用戶為愉悅」。
進一步的,本發明實施例中,通過音頻採集裝置,如麥克風,採集駕駛員的聲音數據。在本發明的一個具體實施例中,根據採集的語音數據,對駕駛員的情緒進行識別,包括:在先需要進行人聲的離線訓練,所述人聲的離線訓練,使用語音資料庫訓練人聲檢測器,同時訓練語音特徵向量提取模型用於從人聲中提取特徵向量的聲音,採用已標定好的語音特徵向量以及情緒的訓練集訓練情緒分類器。當進行人聲的在線運行時(即需要根據語音數據進行情緒識別時),通過人聲檢測器在輸入的聲音流中檢測人聲數據,並從人聲數據中提取語音特徵向量,最後使用情緒分類器從語音特徵向量分辨當前用戶的情緒,並給出識別的置信度。可選地,本發明實施例中,還對所述語音數據中的語義進行識別。當根據語音特徵向量進行情緒識別時,可以結合語義識別結果,進行綜合識別判斷,得到基於語音數據的最終識別結果。本實施例中,基於語音的情緒識別的置信度為情緒分類器將獲取的語音數據中的語音特徵向量與在先已訓練好的用戶在不同情緒類型下的語音向量模型進行匹配的匹配度,當匹配度大於設定的閾值時,判定出用戶的情緒,例如,若匹配的結果為80%(置信度)以上的檢測結果為「愉悅」,則認為「此用戶為愉悅」。
進一步的,本發明實施例中,為了根據不同數據類型得到的識別結果進行駕駛員的情緒判定,要預先按照數據類型,進行情緒置信度閾值的設定。具體的,設定與圖像數據類型相對應的第一情緒置信度閾值、設定與語音數據類型相對應的第一情緒置信度閾值、以及設定與行駛數據類型相對應的第一情緒置信度閾值。其中,不同數據類型下的第一情緒置信度閾值可以相同,也可以不同,具體值可根據需求靈活設定。
對此,本發明實施例中,基於得到的每種數據類型下的情緒識別結果,按照設定的情緒判定策略,判定出駕駛員的情緒,具體包括:
檢測是否至少兩個情緒識別結果中的情緒類型相同且置信度分別大於等於設定的對應數據類型的第一情緒置信度閾值,並在是的情況下,將所述至少兩個情緒識別結果中的情緒類型作為最終識別出的駕駛員的情緒;
可選地,本發明實施例中,可以設定每個數據類型下的第一情緒置信度閾值為兩個等級,即第一等級下的情緒置信度閾值P1和第二等級下的情緒置信度閾值P2,其中,同一數據類型下的P2大於P1。第一等級的閾值P1用於三種類型數據下識別結果的判斷,第二等級的閾值P2用於兩種數據類型下識別結果的判斷。具體的,當得到三種數據類型下的三個情緒識別結果時,如果三個情緒識別結果的情緒類型相同,且對應的置信度均大於對應的第一等級下的閾值P1,則以三個情緒識別結果識別出的情緒類型作為最終識別出的駕駛員的情緒。當得到至少兩種數據類型下的至少兩個情緒識別結果時,如果有兩個情緒識別結果的情緒類型相同,且對應的置信度均大於對應的第二等級下的閾值P2,則直接以這兩個情緒識別結果識別出的情緒類型作為最終識別出的駕駛員的情緒。
進一步地,考慮到有些情況下,基於某種數據類型的識別置信度很高,具有很高的可信性,此時,可以直接利用置信度很高的數據類型對應的識別結果作為最終的識別結果,具體實現時,可檢測各情緒識別結果中是否存在一個情緒識別結果的情緒類型的置信度大於等於設定的對應數據類型的第二情緒置信度閾值,並在是的情況下,將該情緒識別結果中的情緒類型作為最終識別出的駕駛員的情緒。其中,同一數據類型下的第一情緒置信度閾值小於第二情緒置信度閾值。
下面通過具體示例,對上述提出的情緒判定過程進行解釋說明:
本示例中,設定基於語音數據的情緒識別置信度閾值為70%、基於圖像數據的情緒識別置信度閾值為80%、基於行駛數據的情緒識別置信度為60%,則:
當基於語音數據識別出的情緒類型為激動,且情緒識別置信度為「70%」以上、基於圖像數據識別出的情緒類型為激動,且情緒識別置信度為「80%」以上、且基於行駛數據識別出的情緒類型為激動,且情緒識別置信度為:「60%」以上,則判斷出此用戶「情緒為激動」。
本示例中,還可以進一步進行閾值設定,例如設定基於語音數據的情緒識別置信度閾值為80%、基於圖像數據的情緒識別置信度為85%、基於行駛數據的情緒識別置信度為75%;則:
當基於語音數據識別出的情緒類型為激動,且情緒識別置信度為「80%」以上、基於圖像數據識別出的情緒類型為激動,且情緒識別置信度為「85%」以上,則直接判斷出此用戶「情緒為激動」。或者,當基於語音數據識別出的情緒類型為激動,且情緒識別置信度為「80%」以上、基於行駛數據的情緒識別結果為激動,且情緒識別置信度為「75%」以上,則直接判斷出此用戶「情緒為激動」。或者,當基於圖像數據識別出的情緒類型為激動,且情緒識別置信度為「85%」以上、基於行駛數據的情緒識別結果為激動,且情緒識別置信度為「75%」以上,則直接判斷出此用戶「情緒為激動」。
本示例中,還可以進一步進行閾值設定,例如設定基於語音數據的情緒識別置信度閾值為95%、基於圖像數據的情緒識別置信度為98%、基於行駛數據的情緒識別置信度為90%,則:
當基於語音數據識別出的情緒類型為激動,且情緒識別置信度為「95%」以上、則直接判斷出此用戶「情緒為激動」。或者,基於行駛數據的情緒識別結果為激動,且情緒識別置信度為「90%」以上,則直接判斷出此用戶「情緒為激動」。或者,基於圖像數據識別出的情緒類型為激動,且情緒識別置信度為「98%」以上,則直接判斷出此用戶「情緒為激動」。
需要指出的是,在根據置信度閾值進行判斷時,如果出現判斷結果衝突的情況,則丟棄當前識別結果,繼續根據實時採集的數據進行判斷。例如,當基於語音數據的情緒識別結果為激動且置信度為95%、而基於圖像數據的情緒識別結果為高興且置信度為98%,此時,需要丟棄當前識別結果,繼續進行判斷。
進一步地,本發明實施例中,在判定出駕駛員的情緒之後,還包括:根據預設的情緒類型的置信度與情緒類型級別的對應關係,得到最終識別出的駕駛員的情緒的情緒級別。具體的,本實施例中,可以預先建立識別出的情緒類型的置信度與該情緒類型級別的對應關係,並在得到多個情緒識別結果時,根據識別結果中的識別置信度,匹配當前情緒類型的情緒級別(例如:激動、非常激動等)。
綜上可知,本發明實施例通過至少兩種類型的數據對駕駛員的情緒進行綜合識別判斷,提高了情緒識別的穩定性和準確度,提升了用戶的使用體驗。
在本發明的第二實施例中,提供一種駕駛員情緒識別方法,繼續如圖1所示,包括如下步驟:
步驟S101,採集駕駛員的圖像數據、駕駛員的語音數據以及駕駛車輛的行駛數據中的至少兩種數據;
步驟S102,分別根據採集的多種數據,對駕駛員的情緒進行識別,得到每種數據類型下的情緒識別結果;
步驟S103,基於得到的每種數據類型下的情緒識別結果,按照設定的情緒判定策略,判定出駕駛員的情緒。
本發明實施例中,情緒識別及判定過程與第一實施例相同,在此不再贅述。
本發明實施例中,在進行情緒識別的同時還進行駕駛員的身份識別,具體如下:
當採集到圖像數據或者語音數據時,根據所述圖像數據或者語音數據,識別出駕駛員的身份;
當採集到圖像數據和語音數據時,分別根據所述圖像數據和語音數據,對駕駛員的身份進行識別,得到兩種數據類型下的兩個身份識別結果,並基於得到的兩個身份識別結果,按照設定的身份判定策略,判定出駕駛員的身份。
本發明實施例中,所述的身份識別結果包括:識別出的用戶及識別出該用戶的置信度。
進一步地,本發明實施例中,通過圖像採集裝置,如攝像頭,採集駕駛員的圖像數據。在本發明的一個具體實施例中,根據採集的圖像數據,對駕駛員的身份進行識別,包括:在先需要進行人臉的離線訓練,所述離線訓練使用人臉的資料庫訓練人臉的檢測器、同時在人臉上標定標記點,根據所述人臉標記點訓練標記點擬合器,並且,通過人臉標記點和身份的關係訓練身份分類器;當進行人臉的在線運行時,通過人臉檢測器在圖像數據中檢測人臉,然後通過標記點擬合器擬合人臉上的標記點,身份分類器根據人臉標記點判斷當前駕駛員的身份,最後給出對應的分類置信度。本實施例中,基於圖像的身份識別的置信度為身份分類器將獲取的面部圖像中的人臉標記點與在先訓練的已知身份的人臉標記點進行匹配的匹配度,當匹配度(即置信度)達到一定的閾值,判定為識別出用戶身份,例如,若匹配度為85%(置信度)以上的檢測結果為用戶A,則認為「此用戶為用戶A」。
進一步的,本發明實施例中,通過音頻採集裝置,如麥克風,採集駕駛員的聲音數據。在本發明的一個具體實施例中,根據採集的語音數據,對駕駛員的身份進行識別,包括:在先需要進行人聲的離線訓練,所述人聲的離線訓練,使用語音資料庫訓練人聲檢測器,同時訓練語音特徵向量提取模型用於從人聲中提取特徵向量的聲音,採用已標定好的語音特徵向量以及身份的訓練集訓練身份分類器。當進行人聲的在線運行時,通過人聲檢測器在輸入的聲音流中檢測人聲數據,並從人聲數據中提取語音特徵向量,最後使用身份分類器從語音特徵向量分辨當前用戶的身份,並給出識別的置信度。本實施例中,基於語音的身份識別的置信度為身份分類器將獲取的語音數據中的語音特徵向量與在先已訓練好的已知用戶的語音向量模型進行匹配的匹配度,當匹配度大於設定的閾值時,判定出用戶的身份,例如,若匹配的結果為85%(置信度)以上的檢測結果為用戶A,則認為「此用戶為用戶A」。
進一步地,本發明實施例中,當採集到圖像數據和語音數據時,為了根據兩種數據類型得到的識別結果進行駕駛員的身份判定,要預先按照數據類型,進行身份置信度閾值的設定。具體的,設定與圖像數據類型相對應的第一身份置信度閾值以及設定與語音數據類型相對應的第一身份置信度閾值。其中,不同數據類型下的第一情緒置信度閾值可以相同,也可以不同,具體值可根據需求靈活設定。
對此,本發明實施例中,基於得到的兩個身份識別結果,按照設定的身份判定策略,判定出駕駛員的身份,包括:
當兩個身份識別結果中識別出的用戶相同且置信度分別大於等於設定的對應數據類型的第一身份置信度閾值時,以共同識別出的用戶作為最終的用戶身份識別結果;
當兩個身份識別結果中有一個身份識別結果中識別出的用戶的置信度大於等於設定的對應數據類型的第二身份置信度閾值時,以用戶的置信度大於等於第二置信度身份閾值對應的用戶,作為最終的用戶身份識別結果;
其中,同一數據類型下的第一身份置信度閾值小於第二身份置信度閾值。
下面通過一個具體示例,對上述提出的身份判定過程進行解釋說明:
本示例中,設定基於語音數據的身份識別置信度閾值為85%,基於圖像數據的身份識別置信度閾值為90%,則:當基於語音數據識別出的身份為用戶A,且身份識別置信度為85%以上,基於圖像數據識別出的身份為用戶A,且身份識別置信度為90%以上,則判斷出此用戶為用戶A。
本示例中,還可以進一步進行閾值設定,例如設定基於語音數據的身份識別置信度閾值為95%,基於圖像數據的身份識別置信度閾值為98%,則:當基於語音數據識別出的身份為用戶A,且身份識別置信度為95%以上,則直接判斷出駕駛員身份為用戶A;或者,當基於圖像數據識別出的身份為用戶A,且身份識別置信度為98%,則直接判斷出駕駛員身份為用戶A。
綜上可知,語音、圖像的置信度需要同時大於第一閾值,認為是用戶A;或者,語音和圖像的置信度需要至少有一個大於第二閾值,則認為是用戶A,其中第二閾值大於第一閾值。
在本發明的一個較佳實施例中,在確定出駕駛員的身份後,還包括:將識別的身份和情緒信息發送到大數據推薦引擎,由大數據推薦引擎利用得到的駕駛員的身份,在預先建立的各用戶行為習慣模型中匹配出與該駕駛員對應的用戶行為習慣模型,並將駕駛員的情緒信息輸入到匹配的用戶行為習慣模型中,以對駕駛員的狀態和/或行為進行預判,並根據預判結果,主動提供與預判結果相匹配的服務。
其中,根據預判結果,主動提供與預判結果相匹配的服務,具體包括:
確定與所述預判結果相匹配的服務,向用戶發出是否需要所述服務的詢問,並在確定出用戶需要時,向用戶提供所述服務。
本實施例中,向用戶提供的與預判結果相匹配的服務,包括:內容服務和/或設備狀態控制服務;所述設備狀態控制服務包括:控制所述智能語音設備和/或與所述智能語音設備連接的設備到目標狀態。
下面通過幾個具體應用案例對主動提供服務的過程進行說明。
案例一:若基於語音數據的情緒識別結果為「激動77%」、基於圖像的情緒識別結果為「激動90%」、以及基於車輛相關行駛數據的情緒識別結果為「激動65%」,則可判斷出此用戶「情緒為激動」;同時若基於語音數據的身份識別結果為「李女士88%」、基於圖像數據的身份識別結果為「李女士95%」,則可判斷出此用戶為李女士。那麼總的情緒、身份識別結果為「李女士情緒為激動」。
將李女士情緒為激動的識別結果發送到大數據推薦引擎,大數據推薦引擎觸發語音交互,並發送語音播報文件到智能車載中控自動發起語音交互:
智能車載中控:「剛剛學會了一個新笑話,李女士想不想聽啊」
李女士:「好的,說吧」
智能車載中控:「課堂上奧特曼舉手了,然後老師就死了」。
案例二:若基於語音數據的情緒識別結果為「疲勞84%」、基於圖像數據的情緒識別結果為「疲勞93%」,則可判斷出此用戶「情緒為疲勞」,同時若基於語音數據的身份識別結果為「張先生88%」、基於圖像數據的身份識別結果為「張先生95%」,則可判斷出此用戶為「張先生」。那麼總的情緒、身份識別結果為「張先生情緒為疲勞」。
將張先生情緒為疲勞的識別結果發送到大數據推薦引擎,大數據推薦引擎觸發語音交互,並發送語音播報文件到智能車載中控自動播放音樂:
智能車載中控:「張先生,要不要給您放點動感的歌啊,看你開車都累了」。
張三:「好的啊」
智能車載中控打開音樂播放器,並播放輕鬆歡快歌曲,並結合用戶的音樂歷史數據推薦張三可能喜歡的歌手與音樂類型。
案例三:若基於圖像數據的情緒識別結果為「憤怒80%」、基於車輛行駛數據的情緒識別結果為「憤怒99%」,則可判斷出此用戶「情緒為憤怒」,同時若基於語音數據的身份識別結果為「周先生88%」、基於圖像數據的身份識別結果為「周先生95%」,則可判斷出此用戶為「周先生」。那麼總的情緒、身份識別結果為「周先生情緒為憤怒」。
將周先生情緒為憤怒的識別結果發送到大數據推薦引擎,大數據推薦引擎觸發語音交互,並發送語音播報文件到智能車載中控自動發起語音交互,爭取用戶的功能操作的認同:
智能車載中控:「周先生,看您今天怎麼有點惱火啊,要不要幫您降降溫,打開空調呢」。
周先生:「好的,開吧」
智能車載中控接收到語音信息後,打開空調。
綜上可知,本發明實施例提出了一種全新的駕駛員情緒識別與身份識別的方法,並將身份、情緒識別結果發送到大數據推薦引擎,由大數據推薦引擎根據身份及情緒的識別結果,推薦匹配的服務,包括但不限於為UI展示,語音播報,內容服務提供,車內設備控制等,從而實現了主動為用戶提供更人性化的服務,提高了用戶的使用體驗。
在本發明的第三實施例中,提供一種駕駛員情緒識別裝置,如圖2所示,具體包括:
信息採集模塊210,用於採集駕駛員的圖像數據、駕駛員的語音數據以及駕駛車輛的行駛數據中的至少兩種數據;
情緒識別模塊220,用於分別根據採集的多種數據,對駕駛員的情緒進行識別,得到每種數據類型下的情緒識別結果;
情緒判定模塊230,用於基於得到的每種數據類型下的情緒識別結果,按照設定的情緒判定策略,判定出駕駛員的情緒。
基於上述結構框架及實施原理,下面給出在上述結構下的幾個具體及優選實施方式,用以細化和優化本發明所述裝置的功能,以使本發明方案的實施更方便,準確。具體涉及如下內容:
本發明實施例中,所述情緒識別結果包括:識別出的情緒類型及識別出該情緒類型的置信度。其中,情緒類型包括但不限於為:高興、傷心、憤怒、厭煩、疲勞、激動和正常。
進一步地,本發明實施例中,信息採集模塊210包括布設在車內外的設備傳感器、布設在車內的圖像採集裝置和音頻採集裝置。
具體的,本實施例中,通過布設在車內外的設備傳感器採集駕駛車輛的行駛數據,所述設備傳感器可以包括至少以下一種或幾種傳感器的組合:加速度傳感器、速度傳感器、紅外傳感器、角速度傳感器、雷射測距傳感器、超聲波傳感器等。根據車輛上布設的這些傳感器獲取的信息,就可以得到當前車輛的姿態信息、當前車況信息、當前路況信息、駕駛時長、車輛駕駛軌跡信息等。進一步的,本發明實施例中,通過圖像採集裝置,如攝像頭,採集駕駛員的圖像數據;以及通過音頻採集裝置,如麥克風,採集駕駛員的聲音數據。
在本發明的一個具體實施例中,情緒識別模塊220根據駕駛車輛的行駛數據對駕駛員的情緒進行識別,包括:從所述相關行駛數據中提取相關行駛特徵,根據相關行駛特徵在預設的分類器中進行分類,根據所述分類器中的分類結果識別與所述相關行駛特徵相對應的駕駛員情緒,最後給出對應的識別置信度。具體的,本發明實施例中,採集預設時間內汽車行駛中的訓練行駛信息,並從所述訓練行駛信息中提取訓練行駛特徵;獲取針對不同訓練行駛特徵標註的不同駕駛員情緒,並基於預設的分類算法對不同訓練行駛特徵標註的不同駕駛員情緒進行學習、訓練,形成預設的分類器。
在本發明的一個具體實施例中,情緒識別模塊220根據採集的圖像數據,對駕駛員的情緒進行識別,包括:在先需要進行人臉的離線訓練,所述離線訓練使用人臉的資料庫訓練人臉的檢測器、同時在人臉上標定標記點,根據所述人臉標記點訓練標記點擬合器,並且,通過人臉標記點和情緒的關係訓練情緒分類器。當進行人臉的在線運行時(即需要根據圖像數據進行情緒識別時),通過人臉檢測器在圖像數據中檢測人臉,然後通過標記點擬合器擬合人臉上的標記點,情緒分類器根據人臉標記點判斷當前駕駛員的情緒,最後給出對應的分類置信度。
在本發明的一個具體實施例中,情緒識別模塊220根據採集的語音數據,對駕駛員的情緒進行識別,包括:在先需要進行人聲的離線訓練,所述人聲的離線訓練,使用語音資料庫訓練人聲檢測器,同時訓練語音特徵向量提取模型用於從人聲中提取特徵向量的聲音,採用已標定好的語音特徵向量以及情緒的訓練集訓練情緒分類器。當進行人聲的在線運行時(即需要根據語音數據進行情緒識別時),通過人聲檢測器在輸入的聲音流中檢測人聲數據,並從人聲數據中提取語音特徵向量,最後使用情緒分類器從語音特徵向量分辨當前用戶的情緒,並給出識別的置信度。可選地,本發明實施例中,還對所述語音數據中的語義進行識別。當根據語音特徵向量進行情緒識別時,可以結合語義識別結果,進行綜合識別判斷,得到基於語音數據的最終識別結果。
進一步的,本發明實施例中,為了根據不同數據類型得到的識別結果進行駕駛員的情緒判定,要預先按照數據類型,進行情緒置信度閾值的設定。具體的,設定與圖像數據類型相對應的第一情緒置信度閾值、設定與語音數據類型相對應的第一情緒置信度閾值、以及設定與行駛數據類型相對應的第一情緒置信度閾值。其中,不同數據類型下的第一情緒置信度閾值可以相同,也可以不同,具體值可根據需求靈活設定。
對此,本發明實施例中,情緒判定模塊230基於得到的每種數據類型下的情緒識別結果,按照設定的情緒判定策略,判定出駕駛員的情緒,具體包括:
當至少兩個情緒識別結果中的情緒類型相同且置信度分別大於等於設定的對應數據類型的第一情緒置信度閾值時,將所述至少兩個情緒識別結果中的情緒類型作為最終識別出的駕駛員的情緒;
進一步地,考慮到有些情況下,基於某種數據類型的識別置信度很高,具有很高的可信性,此時,可以直接利用置信度很高的數據類型對應的識別結果作為最終的識別結果,具體實現時,可檢測各情緒識別結果中是否存在一個情緒識別結果的情緒類型的置信度大於等於設定的對應數據類型的第二情緒置信度閾值,並在是的情況下,將該情緒識別結果中的情緒類型作為最終識別出的駕駛員的情緒;其中,同一數據類型下的第一情緒置信度閾值小於第二情緒置信度閾值。
進一步地,本發明實施例中,情緒判定模塊230,還用於在判定出駕駛員的情緒之後,根據預設的情緒類型的置信度與情緒類型級別的對應關係,得到最終識別出的駕駛員的情緒的情緒級別。
在本發明的一具體實施例中,所述裝置還包括:
身份識別模塊240,用於當所述信息採集模塊210採集到圖像數據或者語音數據時,根據所述圖像數據或者語音數據,識別出駕駛員的身份;當所述信息採集模塊採集到圖像數據和語音數據時,分別根據所述圖像數據和語音數據,對駕駛員的身份進行識別,得到兩種數據類型下的兩個身份識別結果;
身份判定模塊250,用於當所述身份識別模塊240得到一種數據類型下的身份識別結果時,直接以該結果作為識別出的駕駛員的身份;當所述身份識別模塊240得到兩種數據類型下的兩個身份識別結果時,基於得到的兩個身份識別結果,按照設定的身份判定策略,判定出駕駛員的身份。
本發明實施例中,所述身份識別結果包括:識別出的用戶及識別出該用戶的置信度。
在本發明的一個具體實施例中,身份識別模塊240根據採集的圖像數據,對駕駛員的身份進行識別,包括:在先需要進行人臉的離線訓練,所述離線訓練使用人臉的資料庫訓練人臉的檢測器、同時在人臉上標定標記點,根據所述人臉標記點訓練標記點擬合器,並且,通過人臉標記點和身份的關係訓練身份分類器;當進行人臉的在線運行時,通過人臉檢測器在圖像數據中檢測人臉,然後通過標記點擬合器擬合人臉上的標記點,身份分類器根據人臉標記點判斷當前駕駛員的身份,最後給出對應的分類置信度。
在本發明的一個具體實施例中,身份識別模塊240根據採集的語音數據,對駕駛員的身份進行識別,包括:在先需要進行人聲的離線訓練,所述人聲的離線訓練,使用語音資料庫訓練人聲檢測器,同時訓練語音特徵向量提取模型用於從人聲中提取特徵向量的聲音,採用已標定好的語音特徵向量以及身份的訓練集訓練身份分類器。當進行人聲的在線運行時,通過人聲檢測器在輸入的聲音流中檢測人聲數據,並從人聲數據中提取語音特徵向量,最後使用身份分類器從語音特徵向量分辨當前用戶的身份,並給出識別的置信度。
進一步地,本發明實施例中,當採集到圖像數據和語音數據時,為了根據兩種數據類型得到的識別結果進行駕駛員的身份判定,要預先按照數據類型,進行身份置信度閾值的設定。具體的,設定與圖像數據類型相對應的第一身份置信度閾值以及設定與語音數據類型相對應的第一身份置信度閾值。其中,不同數據類型下的第一情緒置信度閾值可以相同,也可以不同,具體值可根據需求靈活設定。
對此,本發明實施例中,身份判定模塊250基於得到的兩個身份識別結果,按照設定的身份判定策略,判定出駕駛員的身份,具體包括:
當兩個身份識別結果中識別出的用戶相同且置信度分別大於等於設定的對應數據類型的第一身份置信度閾值時,以共同識別出的用戶作為最終的用戶身份識別結果;
當兩個身份識別結果中有一個身份識別結果中識別出的用戶的置信度大於等於設定的對應數據類型的第二身份置信度閾值時,以用戶的置信度大於等於第二置信度身份閾值對應的用戶,作為最終的用戶身份識別結果,其中,同一數據類型下的第一身份置信度閾值小於第二身份置信度閾值。
在本發明的又一具體實施例中,所述裝置還包括:
大數據推薦引擎模塊260,用於利用得到的駕駛員的身份,在預先建立的各用戶行為習慣模型中匹配出與該駕駛員對應的用戶行為習慣模型,並將駕駛員的情緒信息輸入到匹配的用戶行為習慣模型中,以對駕駛員的狀態和/或行為進行預判,並根據預判結果,主動提供與預判結果相匹配的服務。
其中,大數據推薦引擎模塊260,具體用於確定與所述預判結果相匹配的服務,向用戶發出是否需要所述服務的詢問,並在確定出用戶需要時,向用戶提供所述服務。其中,確定用戶是否需要,可通過對用戶輸入語音進行語音識別,得到文本信息,再通過文本信息進行語義識別來確定。
本實施例中,向用戶提供的與預判結果相匹配的服務,包括:內容服務和/或設備狀態控制服務;所述設備狀態控制服務包括:控制所述智能語音設備和/或與所述智能語音設備連接的設備到目標狀態。
綜上可知,本發明實施例所述裝置可分別根據圖像數據、語音數據和車輛行駛數據中的至少兩種進行情緒識別,並根據得到的多個情緒識別結果綜合判斷駕駛員的情緒狀態,這種情緒狀態識別方式不會受單一的道路狀況、車輛狀況、面部特徵和語音特徵等影響,識別出的駕駛員的情緒更加符合實際的駕駛員情緒狀態,提高了情緒識別的準確性及環境適應性。
另外,本發明實施例所述裝置還可以分別根據圖像數據和語音數據進行駕駛員的身份識別,並根據得到的兩個身份識別結果綜合判斷駕駛員的身份,提高了身份識別的準確性和環境適應性;
再者,本發明還可以根據識別的駕駛員的情緒和身份,進行主動的服務推薦,提高了用戶的使用體驗。
本說明書中的各個實施例均採用遞進的方式描述,各個實施例之間相同相似的部分互相參見即可,每個實施例重點說明的都是其與其他實施例的不同之處。尤其對於裝置實施例而言,由於其基本相似與方法實施例,所以,描述的比較簡單,相關之處參見方法實施例的部分說明即可。
本領域普通技術人員可以理解上述實施例的各種方法中的全部或部分步驟是可以通過程序來指令相關的硬體來完成,該程序可以存儲於一計算機可讀存儲介質中,存儲介質可以包括:ROM、RAM、磁碟或光碟等。
總之,以上所述僅為本發明的較佳實施例而已,並非用於限定本發明的保護範圍。凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。