一種基於深度LSTM網絡的圖像描述生成方法與流程
2023-06-17 02:51:06 2
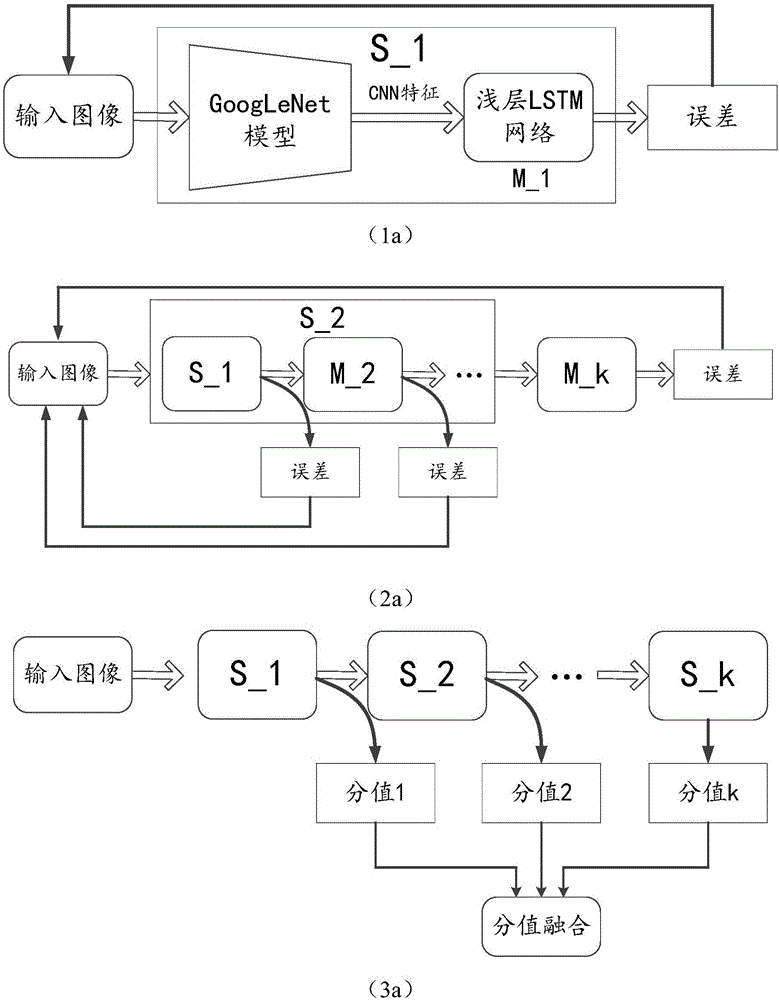
本發明涉及圖像理解領域,尤其是涉及一種基於深度LSTM網絡的圖像描述生成方法。
背景技術:
:圖像標題生成是一項極具挑戰性的工作,在嬰幼兒早期教育、視覺障礙輔助、人機互動等領域具有廣泛的應用前景。它結合了自然語言處理與計算機視覺兩個領域,將一副自然圖像使用自然語言的形式描述出來,或者說將圖像翻譯成自然語言。它首先要求系統能夠準確理解圖像中的內容,如識別出圖像中的場景、各種對象、對象的屬性、正在發生的動作及對象之間的關係等;然後根據語法規則及語言結構,生成人們能夠理解的句子。人們已提出多種方法來解決這一難題,包括基於模板的方法、基於語義遷移的方法,基於神經機器翻譯的方法及混合方法等。隨著深度學習技術,尤其是CNN技術在語言識別和視覺領域連續取得突破,目前基於神經機器翻譯及其與其他視覺技術混合的方法已成為解決該問題的主流。這類方法考慮了CNN模型能夠提取抽象性及表達能力更強的圖像特徵,能夠為後續的語言生成模型提供可靠的可視化信息。但這些方法過於依賴前期的視覺技術,處理過程複雜,對系統後端生成句子的語言模型優化不足;在使用LSTM單元生成句子時,其模型深度較淺(常使用1層或2層LSTM),多模信息變換層次不夠,生成的句子語義信息不強,整體性能難以改善。技術實現要素:本發明的目的就是為了克服上述現有技術存在的缺陷而提供一種多層次、提高表達能力、有效更新、準確性高的基於深度LSTM網絡的圖像描述生成方法。本發明的目的可以通過以下技術方案來實現:一種基於深度LSTM網絡的圖像描述生成方法,包括以下步驟:1)提取圖像描述數據集中圖像的CNN特徵並獲取與圖像對應描述參考句子中單詞的嵌入式向量;2)建立雙層LSTM網絡,其中,第一層LSTM以單詞的嵌入式向量為輸入,第二層LSTM以第一層LSTM的輸出和CNN網絡輸出的圖像的CNN特徵為輸入,並結合雙層LSTM網絡和CNN網絡進行序列建模生成多模LSTM模型;3)採用聯合訓練的方式對多模LSTM模型進行訓練,將CNN網絡和LSTM網絡中的參數進行聯合優化;4)逐層增加多模LSTM模型中LSTM網絡的層次,每增加一層並進行訓練,直至生成圖像描述句子的質量性能不再提升,最終獲得逐層多目標優化及多層概率融合的圖像描述模型;5)將逐層多目標優化及多層概率融合的圖像描述模型中多層LSTM網絡中各分支輸出的概率分值進行融合,採用共同決策的方式,將概率最大對應的單詞輸出。所述的步驟1)具體包括以下步驟:11)將圖像描述數據集中的圖像縮放至256×256大小;12)在圖像上隨機截取5個224×224大小的圖像塊,並將其進行水平翻轉,對數據集進行擴充;13)設置CNN網絡中的卷積層和分類層的學習率調整因子和權值衰減因子為原來的1/10;14)加載在Imagenet數據集上已優化完畢的參數對模型進行初始化;15)將各圖像塊輸入CNN網絡,提取圖像的CNN特徵,該CNN特徵維度為1000維。所述的步驟2)具體包括以下步驟:21)構建雙層LSTM網絡中的LSTM單元,並設置輸入門、輸出門、遺忘門和記憶單元;22)獲取數據集中描述參考句子的平均長度,並設置每層LSTM的時間步長和隱層單元個數;23)對單詞表中的每個單詞採用One-Hot方式進行編碼,編碼維度為單詞表的長度;24)將描述參考句子中每個單詞的One-Hot編碼映射為一個嵌入式向量,並設置向量維度;25)將每個單詞的嵌入式向量作為第一層LSTM的輸入,並將第一層LSTM的輸出和圖像CNN特徵作為第二層LSTM的輸入,建立多模LSTM模型;27)將雙層LSTM網絡的最終輸出輸送到分類層,並採用Softmax函數輸出該特徵在每個單詞上的概率分值。所述的步驟3)具體包括以下步驟:31)構建目標函數O,並獲取使得損失函數最小的優化參數集合(θ1,θ2):θ1為CNN網絡的參數集合,θ2為LSTM網絡的參數集合,X2為圖像描述數據集中的輸入圖像,S為與X2對應的描述參考句子,f(·)表示系統函數,為損失函數,N2為訓練LSTM網絡時,一次迭代中所使用的樣本總數,Lk為第k個樣本所對應的參考句子的長度,為第k張圖像對應的描述參考句子的第t個單詞,為生成的第k張圖像的第t個單詞,為輸入的第k張圖像,為第k張圖像的參考句子的第t-1個單詞,為實數域。32)採用鏈式法則計算誤差並採用隨機梯度下降的方法對誤差進行修正;33)將誤差回傳到CNN網絡中,將每條句子中每個單詞的的誤差進行求和,並逐層向前傳遞,完成優化。所述的步驟4)具體包括以下步驟:41)將訓練好的多模LSTM模型作為初始模型,記為S_1,初始模型S_1中的雙層LSTM網絡為初始層次,記為M_1;42)在初始層次M_1的基礎上,增加一層與初始層次M_1結構相同的新層次,並採用因式分解的方式進行聯結,即:新層次中的第一層LSTM以初始層次的輸出以及單詞的嵌入式向量為輸入,第二層LSTM以第一層LSTM的輸出和初始模型中CNN網絡輸出的圖像CNN特徵為輸入;43)對增加新層次後的模型進行訓練優化,包括以下步驟:431)保留初始層次M_1中的目標函數,並將其輔助分支中的分類層的學習率調整因子和衰減因子設置為原來的1/10;432)構建增加新層次後的模型的系統代價函數為其中,n為增加新層次的總數,為在模型增加到第i層進行訓練時對應的代價函數,如模型共有3個層次,其中在訓練第一層次時,對應一個代價函數,在訓練第二個層次時,對應2個代價函數,這樣整個模型已有3個代價函數,當有三個階段時,則共有1+2+3=6個代價函數。43)重複步驟41)-42),在初始層次M_1上逐層增加新的層次並進行訓練,直到增加層次使得模型性能不再提升。所述的步驟5)具體包括以下步驟:51)為每個輔助分支添加Softmax函數,輸出當前特徵屬於單詞表中每個單詞的概率分值;52)對相應位置的所有概率分值使用乘法原理進行融合;53)取所有概率值最大者所對應的單詞作為最終輸出。與現有技術相比,本發明具有以下優點:一、多層次、提高表達能力:本發明提出了一種構建更深LSTM網絡的方法,通過逐層優化的方法,對可視化信息和語言信息進行更多層次的非線性變換,提高生成句子的語義表達能力。二、有效更新:本發明將深度監督的方法引入到了多層LSTM網絡中,防止因參數過多造成的過擬合現象,為低層LSTM單元提供正則化,同時保證低層LSTM參數不會因為梯度彌散而造成的難以有效更新的問題。三、準確性高:本發明利用了多層LSTM共同決策的方式,通過乘法原理,將連接多層LSTM的多個輔助分類器輸出融合在一起,共同決定下一個單詞的輸出,其輸出單詞更加準確,進一步提升了系統性能,並且本發明在MSCOCO、Flickr30K和Flickr8K三個公開數據集上表現優良。在MSCOCO上,其CIDEr達到了94.6,在Flickr30K和Flickr8K上,其METEOR分別達到了19.4和20.8,超過同類其他模型。附圖說明圖1為本發明的方法流程圖,其中,圖(1a)為訓練第一階段的流程圖,圖(2a)為訓練第k階段的流程圖,圖(3a)為測試階段的流程圖。圖2為LSTM單元的結構圖。圖3為LSTM逐層優化示意圖,其中,圖(3a)為多模LSTM模型結構圖,圖(3b)為逐層多目標優化及多層概率融合的圖像描述模型結構圖。圖4為LSTM深度監督訓練示意圖。圖5為LSTM多層概率融合示意圖。具體實施方式下面結合附圖和具體實施例對本發明進行詳細說明。實施例下面結合附圖和具體實施例對本發明進行詳細說明。本實施例以本發明技術方案為前提進行實施,給出了詳細的實施方式和具體的操作過程,但本發明的保護範圍不限於下述的實施例。一種基於深度LSTM網絡的圖像描述生成方法,如圖3、圖4和圖5所示,包括步驟:1)製作訓練集、驗證集和測試集,使用GoogLeNet模型提取圖像的CNN特徵;具體過程包括:11)將訓練集、驗證集和測試集轉換為hdf5格式,每張圖像對應多個標籤,每個標籤為該圖像所對應的參考句子中的單詞;12)讀取圖像,將其縮放到256×256大小,然後隨機截取5個大小為224×224大小的圖像塊,並將其做水平翻轉,將數據集擴充為原來的10倍;13)將GoogLeNet模型文件中的學習率因子和權值衰減因子調整為原來的1/10;14)調用GoogLeNet在Imagenet大規模數據集上已優化完畢的參數集合做為預訓練模型,對GoogLeNet進行初始化;15)計算所有圖像的均值,將減去均值後的圖像數據送入GoogLeNet網絡,取最後一層的分類層作為圖像的CNN特徵,特徵維度為1000維;2)建立兩層LSTM網絡,其中第一層用於接收單詞的嵌入式向量,建立語言模型;第二層LSTM用於接收第一層LSTM的輸出和圖像的CNN特徵,並對多模特徵進行序列建模;具體步驟包括:21)構建LSTM單元,如圖1所示,其中:22)根據訓練集中參考句子的情況,生成單詞表,對於MSCOCO數據集,單詞表長度為10020,對於Flickr30K數據集,單詞表長度為7406,對於Flick8K,單詞表長度為2549;並統計數據集中參考句子的長度,將每層LSTM的步長設置為20;在MSCOCO數據集上,其隱層輸出設置為1000,在Flickr30K數據集上,LSTM隱層輸出為512,在Flickr8K上,隱層輸出設置為256.23)將單詞表中每個單詞,使用「One-Hot」方式進行映射,每個單詞對應一個映射後的向量,向量維度為單詞表大小;24)使用「因子分解」的方式建立LSTM網絡,首先在CNN網絡和LSTM之間添加嵌入層,將樣本參考句子中的每個單詞通過嵌入的方式映射為一個維度為1000的長度固定的向量;然後建立兩層LSTM單元,第一層用於接收單詞的嵌入式向量,建立語言模型,第二層用於接收第一層LSTM的輸出和圖像的CNN特徵,建立多模模型;25)在LSTM網絡上添加一個全連接層(分類層),其隱層輸出為單詞表大小;3.採用聯合訓練的方式對模型進行訓練,將CNN網絡和LSTM網絡中的參數進行聯合優化,避免模型陷入局部最優(如圖3(a)所示)。具體步驟包括:31)將每張圖像看作一個單獨的類別,為其分別類別標籤;32)使用GoogLeNet提取圖像的CNN特徵,並送入LSTM網絡;33)使用交叉熵函數計算網絡輸出的每個單詞與實際值之間的誤差,並對每張圖像中生成句子的每個單詞與所有參考句子中單詞的誤差進行求和;具體表示為:則系統目標為迭代優化(θ1,θ2),使得損失函數最小。其中系統損失函數可表示為:N2表示在訓練LSTM網絡時,一次迭代中所使用的樣本總量,Lk表示第k個樣本所對應的參考句子的長度。34)使用鏈式法則逐層計算誤差,並將其回傳至整個模型的底層,採用梯度下降的算法,對參數進行更新;其中α表示學習率。4.使用逐層優化的思想和深度監督的方法,逐步增加LSTM網絡的層次,提取更加抽象,泛化能力更強的特徵,提升生成句子的質量(如圖3(b)和圖4所示)。具體過程包括:41)將第3)步中已訓練好的模型記為S_1,其中的LSTM網絡部分記為M_1;將S_1作為下一階段的預訓練模型;42)在M_1的基礎上添加新的LSTM層,記為M_2,同時保留M_1中的輔助分支(分類層)和目標函數,但將輔助分支中的學習率調整因子和權值衰減因子設置為原來的1/10;M_2仍然包括兩層LSTM單元,第一層用於接收M_1中頂層LSTM單元的輸出,第二層接收第一層LSTM的輸出和圖像的CNN特徵;同時添加新的輔助分支(分類層)和目標函數;43)重複42)過程,直到在驗證集上性能不再提升,目前還沒有發現很好的方法來判定什麼時候性能不再提升,所以一般都是通過實驗來決定,具體指標包括BLEU、METEOR、CIDEr等,根據經驗,一般在大的數據集上可添加的層次更多,在小的數據集上則由於經常發生過擬合現象,添加的層次較少,系統整體的損失函數可描述為:其中n為階段數(也為目標函數的個數)。5.在測試階段,將LSTM網絡中各分支輸出的概率分值進行融合,採用共同決策的方式,決定下一個單詞的輸出(如圖5所示)。具體步驟包括:51)在每個M_i上,在輔助分支(分類層)後添加Softmax函數,取出當前特徵屬於單詞表中每個單詞的概率分值;52)將當前特徵的所有概率分值使用乘法原理進行融合,具體為:其中,表示CNN特徵在t時刻屬於第k個單詞的概率,表示LSTM網絡中在t時刻第j個階段的特徵輸出;53)對於t時刻,取所有概率值最大者所對應的單詞作為最終輸出,具體為:為了驗證本申請方法的性能,設計了以下實驗。在三個公開數據集上(MSCOCO、Flickr30K和Flickr8K)使用本方法進行訓練以及測試,使用BLEU、METEOR、ROUGE_L和CIDEr標準來對生成的句子進行評價。為便於對比,使用S_1模型作為基準模型(baseline)。在MSCOCO數據集上,其訓練集有113287張圖像,驗證集和驗證集各有5000張圖像,每張圖像有5條以上人工標註的參考句子;在Flickr30K數據集上,共有31783張圖像,使用其中的29000張圖像作為訓練集,1000張圖像作為測試集,其他作為驗證集;在Flickr8K數據集上,共包含有8091張圖像,我們取其中6000張圖像用於訓練,1000張圖像用於測試,其餘作為驗證集。在各數據集上的實驗結果如表1、表2和表3所示。表1本發明在MSCOCO數據集上性能表現表2本發明在Flickr30K數據集上性能表現methodB-1B-2B-3B-4METEORROUGE_LCIDErbaseline64.345.731.821.919.145.543.7Deep-264.445.831.621.619.345.443.9Deep-464.846.432.322.319.445.644.1表3本發明在Flickr8K數據集上性能表現methodB-1B-2B-3B-4METEORROUGE_LCIDErbaseline61.543.930.120.420.546.951.7Deep-261.843.729.920.320.747.352.2Deep-462.444.530.520.720.847.252.1當前第1頁1 2 3