針對海量數據成對存儲的分布式存儲方法和系統與流程
2023-06-19 15:48:47 2
本發明涉及一種針對海量數據文件成對存儲的分布式文件存儲系統和方法,屬於分布式存儲技術論域。
技術背景
隨著信息技術的迅速發展,科研,商業及工業領域對於海量數據的存儲及分析規模不斷擴大。分式式文件系統由於自身的高可靠性,高可擴展性及相對低廉的使用成本獲得了越來越多的關注。對於目前的分布文件存儲系統,儘管具備不同的數據存儲及恢復策略,支持不同的數據類型及兼容不同的作業系統平臺,這些分布式文件存儲系統在設計之初就將數據存儲與數據處理分割成相互分離的兩個階段。這種對於數據處理場景的滯後考慮使得現有分布式文件系統在處理某些特定模式的大數據問題時存在嚴重的性能問題。
文件比對作為一類特殊的計算模式(任一比對計算均需要處理兩個不同數據文件),在生物科學,數據挖掘,圖像處理等領域應用廣泛。比如在基因識別,基因表達及物種進化分析的過程中,為了揭示數據所蘊含的生物學意義,數據集中的任意兩個不同基因序列文件或核酸序列文件均需要進行兩兩比對計算。在圖像識別領域,圖書、商品、人臉、視頻識別等均包含比對計算這一重要的處理過程。因此,優化這一計算模式的大數據處理問題具有很強烈的現實需求。
目前的解決方案主要分為兩類,一類方案針對小規模數據集,採取單機或在分布式計算系統中的所有結點統一部署全部數據的方法,此類方案雖然可以確保任一比對計算任務均可在本地存儲中讀取全部所需數據,此類解決方案的使用場景嚴重受限於單個結點的存儲能力;另一類方案採用現有通用分布式文件系統,每個結點只存儲部分數據。雖然可以解決海量數據存儲問題,但由於在數據存儲時並未考慮文件比對計算的特點,導致大量比對計算任務需要遠程讀取所需數據,數據的頻繁傳輸嚴重的影響了文件比對計算的效率。
文件比對計算屬上笛卡爾乘積問題的一類情況。考慮數據集合A,比對計算C和表示結果的相似度矩陣M,多文件比對問題如圖1所示:
在圖1所示的文件比對計算過程中,全部所需完成的比對計算任務如圖中相似度矩陣M所示,其中矩陣中每一項M[i,j]=C(A[i],A[j]),對集合A={A1,A2…An},整個集合的任意兩個不同元素之間都要進行比對運算,因此整個過程需要進行次比對運算。
在對於大數據計算問題的一般解決方案中,在計算任務開始之前全部待處理數據需要提前部署在計算集群的分布式文件系統中。目前廣泛使用的分布式文件系統如(HDFS,GFS等)在數據存儲的具體策略上多以單個文件或文件塊為單位,在數據存儲的位置選擇上以提高文件可靠性,平衡系統數據存儲空間佔用等為主要考慮,並未考慮不同數據之間的依賴關係,而對於文件比對類問題,計算任務以成對數據為基本輸入,傳統分布式文件系統的存儲策略必然導致了大量數據在計算過程中需要重新移動位置,大量的數據移動和硬碟讀寫嚴重的影響了文件比對的計算效率。此外,在計算過程中的數據重新移動和副本生成也嚴重的抵消了最初數據存儲策略帶來的存儲空間節省及存儲速速率提高等優點。因此,迫切需要研究一種針對文件比對計算模式的分布式數據存儲方法及系統,即滿足海量數據文件的存儲需要,又可以避免文件比對過程中的遠程數據傳輸,提高大規模文件比對的計算效率及存儲效率。
技術實現要素:
針對現有技術的局限與不足,本發明提供一種針對海量數據文件成對存儲的分布式數據存儲系統,屬於分布式存儲技術領域
本發明還提供一種利用上述分布式計算系統存儲數據的方法。
本發明的技術方案在於:
一種針對海量數據文件成對存儲的分布式文件存儲系統,包括基於主從式分布式集群的存儲系統設計,主結點功能模塊,子結點功能模塊及存儲及計算流程設計。該分布式存儲系統旨在應用分布式文件存儲系統高效處理滿足數據集文件比對模式的計算問題。本發明通過將文件存儲及文件處理協同考慮,從數據存儲初始階段即滿足後續比對計算的需要,實現了對於同一計算任務,一次存儲,無需移動的數據文件存儲及處理解決方案;此分式文件系統同時兼顧降低存儲空間,保證數據文件可靠性的存儲需要,並通過物理存儲與邏輯存儲的分離設計保證了系統對於多用戶多應用場景的支持。
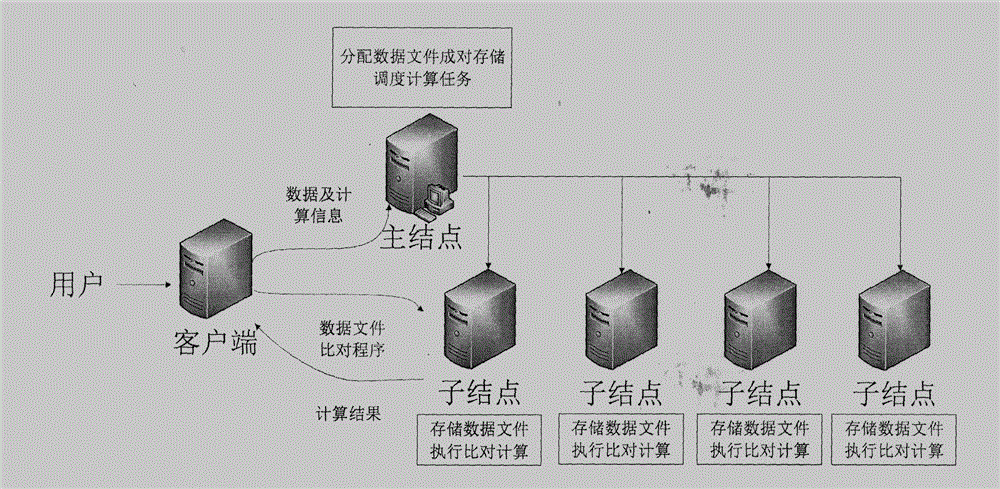
根據本發明優選的,所述的分布式文件存儲系統包括以下三個獨立組成部分:用戶客戶端、系統主結點及系統子結點。基於數據成對存儲的高性能分布式文件系統組成如圖2所示:
所述每個組成部分都具有不同的功能:所述客戶端為用戶提供基本操作接口,包括數據文件管理,計算程序管理及計算結果採集等。所述系統主結點負責收集用戶提供的數據集信息及相應計算任務信息,確定數據文件部署方案。所述系統主結點同時採集系統各子結點信息,確定相應計算任務調度。所述系統子結點同時具備數據文件存儲及數據對比處理計算功能。依據主結點的調度信息,所述的分布式文件系統各子結點以數據 對為單位存儲各相應的數據文件,並進行數據文件的比對計算任務,最終計算任務全部結果在所述主結點的管理下匯總至所述用戶客戶端。在本發明所述分布式文件系統中主結點的控制下,不同子結點協同運行,構成一個具體的數據文件成對存儲及後續比對計算過程。
根據本發明優先的,所述基於分布式集群的分布式文件系統中主要包括以下五種功能模塊:數據文件管理模塊,計算任務調度模塊,數據文件處理模塊,系統資源監控模塊和用戶操作接口模塊。
本發明針對海量數據文件比對計算數據文件規模龐大,分布式集群硬體配置不同,計算資源動態變化的特點,提出了高性能及高擴展性的以數據文件成對存儲為基礎的分布式文件存儲系統所述分布式文件系統主要負責數據文件的存儲管理,基於數據文件對的計算處理工作。各種功能模塊在此分布式文件系統的組成如圖3所示:
其中數據文件管理模塊運行於所述分布式文件系統主結點(Master結點)。用戶在提交所有數據文件後,數據文件管理系統根據相應數據處理任務信息,分布式文件系統中可用子結點的數量及空間資源信息,生成數據成對存儲的具體部署方案。隨後每個對應子結點存儲相應數據文件對,同時主結點保存所有數據文件在整個文件系統中的存儲情況(元數據信息)。
其中計算任務調度模塊運行於所述分布式文件系統主結點(Master結點)。用戶在提交比對計算任務後,計算任務調度模塊計算整個計算完成需要的子任務數量及及每個計算任務需要的基本計算資源。隨後計算任務調度模塊將計算任務信息傳遞至數據文件管理模塊,協助數據管理模塊確實數據文件的存儲方案。計算任務調度模塊隨後根據系統中各子結點的空閒計算資源信息,各子結點存儲的數據文件對信息,計算任務所對應計算資源要求信息等生成計算任務隊列,剛不同的計算任務調度至不同的子結點進行處理。
其中數據文件處理模塊運行於分布式文件系統子結點(Slaves結點)。子結點在接受主結點的調度信息後,從子結點本地存儲空間中讀取相應數據文件對,進行數據文件比對計算,並將計算任務狀態實時反饋回主結點,最終計算結果按用戶計算程序中的要求返回至用戶客戶端。
其中系統資源監控模塊運行於分布式文件系統主結點(Master結點)。資源監控模塊負責收集分布式文件系統中各子結點的運行信息,監控子結點存儲及計算資源使用情況,提供基本的結點通信,數據傳輸,故障處理,數據備份功能。
基中用戶操作接口模塊運行於分布式文件系統的用戶客戶端(Client結點)。用戶操作接口模塊提供用戶相應的數據操作接口,包括數據上傳,下載,修改,查詢等基本功能其次,用戶操作接口模塊提供用戶接口負責上傳數據比對計算任務相應的計算程序及計算信息。此外,用戶操作接口模塊提供用戶讀取和操作最終數據比對計算結果的功能。
一種利用上述分布式文件存儲系統進行數據成對存儲和數據比對計算的方法,包括步驟如下:
(1)用戶根據具體數據比對計算問題,準備以下信息:數據文件集,比對計算程序,計算資源需求信息。
(2)數據對比計算任務分析階段:在此階段,所述分布式文件系統根據用戶提供的相關信息,確定完成比對計算所需要的全部子計算任務數量,每個子計算任務對應的具體數據對及每個子計算任務需要的硬體資源。
(3)數據成對存儲階段:在此階段,所述分布式文件系統根據第二步中產生的信息,以計算任務為分配依據,考慮不同結點的處理能力,將全部計算任務預分配至不同結點;同時將每個計算任務對應的數據文件對預分配至相應結點,從而保證了每個計算任務所需要處理的數據均能夠存儲在相應子結點。所述分布式文件系統根據預分配產生的數據文件及計算任務分配方案,生成生成每個子結點需要存儲的數據文件信息及每個子結點需要處理的比對計算任務信息。隨後所述分布式文件系統將全部數據文件依數據分配方案轉輸分配至不同的子結點。
(4)數據比對處理階段:在此階段,所述分布式文件系統根據階段3中生成的各子結點處理比對計算任務的具體信息,考慮每個子任務需要的具體計算資源,對應每個不同子結點生成各自的任務隊列。隨後所述分布式文件系統中的每個子結點依據各自計算任務隊列執行比對計算任務,並將計算任務執行情況實時傳遞給主結點。
(5)數據輸出階段:在此階段,每個計算任務產生的比對計算結果在主結點的調度下匯總至用戶客戶端,輸出最終結果文件供用戶進一步分析需要。
本發明的優勢在於:
本發明針對海量數據文件成對存儲的分布式文件系統針對但不限於基於Linux作業系統的異構分布式集群。在異構分布式集群環境中,不同結點具備不同的數據存儲及數據處理能力,各結點之間由高速網絡相連,在主控制結點的管理下協同運行。本文所述分布式文件系統的處理能力可隨著集群中結點數量的增加而擴充,滿足了數據存儲規模擴大下的高擴展性要求。
本發明基於主從式分布式集群結構,易於構建。用戶可以通過自主選擇主控制結點和子結點部署所述的分布式文件存儲系統,達到海量數據文件成對存儲和數據文件比對計算的任務要求
本發明針對大規模數據文件比對運算的計算特點,以計算任務的分配為指導,使數據文件的分配不再簡單以增加副本,提高存儲可靠性為唯一指標。以比對計算任務為目標的分配方式使得所述的分布式文件系統對於每一比對計算問題可以達到數據文件一次存儲,無需移動的優點,從而避免了在數據處理過程中產生的大量數據移動和數據副本生成,極大的提高了比對計算的計算性能。此外,本發明所提出的基本數據成對存儲的分布式文件系統與硬體無關,可以方便的在不同的分布式集群環境中部署使用。
附圖說明
圖1為海量數據文件比對計算問題的圖解描述;
圖2為本發明所述的針對海量數據文件成對存儲的分布式存儲系統架構圖;
圖3為本發明所述的針對海量數據文件成對存儲的分布式存儲系統功能模塊圖;
圖4為利用上述分布式文件存儲系統進行數據文件比對計算的方法流程框圖;
圖5為利用上述分布式文件存儲系統進行數據文件比對計算的數據存儲策略圖。
具體實施方法:
下面結合實施例和說明書附圖對本發明做詳細的說明,但不限於此。
實施例1、
如圖2-3所示。
一種針對海量數據成對存儲的分布式文件存儲系統,包括基於分布式集群的文件存儲主結點,子結點及各功能模塊。此分布式文件存儲系統旨在應用分布式存儲和計算技術高效處理海量數據文件比對的計算問題,在節省存儲空間的同時提高比對計算的計算效率。本發明通過以計算任務分配做為數據存儲的指導,避免了傳統分布式文件系統數據存儲階段只考慮存儲可靠性及存儲空間,計算階段無法避免大量數據複製和傳輸的問題;將數據文件成對存儲過程與數據文件比對計算過程結合,保證用戶在處理比對計算問題時計算程序只需讀取本地文件資源,避免了用戶考慮數據遠程調用,網絡傳輸等性能問題;基於分布式集群環境,提供了很好的系統存儲和計算擴展能力。
所述的基於數據文件成對存儲的分布式文件系統由三個部分組成:系統主結點,系統子結點及客戶端結點。在分布式文件系統的工作過程中,用戶通過客戶端上傳全部數據文件,並上傳相應數據文件比對程序;數據存儲階段數據文件及比對程序在系統控制下被部署在相應的結點;數據處理階段各子結點依據所分配的對比任務各自處理存儲在本地的數據文件;最終處理結果在主結點調度下反回給客戶端結點供用戶進一步分析。
所述的分布式文件系統中主要包括以下五種功能模塊:數據文件管理模塊,計算任務調度模塊,數據文件處理模塊,系統資源監控模塊和用戶操作接口模塊。
其中數據文件管理模塊負責依據分布式文件系統中可用子結點數量,存儲資源信息,相應數據比對任務信息等生成數據對存儲方案,並且管理數據文件在所有結點的存儲信息。此模塊以數據對為基本存儲單位,在存儲階段提前考慮了不同數據文件之間的關聯性,避免了計算過程中數據文件的二次移動。
所述計算任務調度模塊負責計算完成整個數據文件比對處理所需要的任務數量,並依據用戶提供的任務信息,確實每個計算計算所需要的具體計算資源。此外,所述計算任務調度模塊與數據文件管理模塊協同操作,確實不同結點需要處理的不同計算任務並進行具體的任務調度工作。計算任務調度模塊確保了所有的數據比對計算任務均在包含有完整數據對的子結點上執行,充分利用了數據存儲階段的數據部署方案,避免了計算過程中數據的遠程調用和複製。
所述數據文件處理模塊負責進行具體的數據比對計算工作。每個子結點的數據處理模塊在接受主結點調度的子任務後,分配相應的計算資源處理相應數據文件對並將計算狀態實時反饋給主結點。此外全部計算結果在主結點的管理下返回至客戶端結點供用戶進一步分析。數據文件處理模塊避免了用戶考慮複雜的遠程數據傳輸,結點間交互等問題,簡化了數據對比程序的開發工作。
所述系統資源監控模塊負責整個分布式文件系統的運行控制。系統中所有子節點的運行信息,存儲及計算資源使用情況等均被主結點收集分析,以提供基本的結點通信,數據傳輸,故障處理,數據備份等功能。
所述用戶操作接口模塊負責提供簡單的操作接口供用戶進行數據文件和計算程序的管理工作。用戶使用此模塊提供計算所需要的相應信息,並接受最終計算結果。所述操作接口模塊使用戶可以專注單機操作,隱藏了分布式文件系統複雜的運行細節和系統結構,降低了用戶的使用成本。
實施例2、
一種利用如實施例1所述分布式文件系統處理數據比對問題的方法,包括步驟如下:
(1)用戶根據具體數據比對計算問題,準備相應數據及計算程序信息。
(2)數據對比計算任務分析階段:在此階段,系統計算對比計算所需要的全部子計算任務並確實每個子計算對應的數據對及計算資源。
(3)數據成對存儲階段:在此階段,所述分布式文件系統根據第二步中產生的信息,同時收集系統中可用子結點數量信息及全部待處理數據文件數量信息,以計算任務為分配依據,生成每個子結點需要存儲的數據文件信息及每個子結點需要處理的比對計算任務信息。所有數據文件在此階段被傳輸及存儲在不同的系統子結點。
(4)數據比對處理階段:在此階段,所述分布式文件系統根據階段3中生成的各子結點處理比對計算任務的具體信息,考慮每個子任務需要的具體計算資源,對應每個不同子結點生成各自的任務隊列。隨後每個子結點接受相應的任務序列執行比對計算任務,任務狀態在過程中時實反饋給主結點進行管理。
(5)數據輸出階段:在此階段,每個計算任務產生的比對計算結果在主結點的調度下匯總至用戶客戶端,輸出最終結果文件供用戶進行進一步分析。
下面結合生物計算領域一個具體的海量RNA序列文件對比計算問題對本發明做進一步說明,但不限於此。此具體實例依照圖5所示處理過程,包含此海量生物數據文件的成對存儲及基因序列文件比對計算兩部分。
針對海量RNA序列文件對比計算問題的數據存儲及計算方法,包括步驟如下:
(1)分析RNA序列文件對比計算問題,依據本發明提出的針對海量數據成對存儲的分布式系統的需要,提供以下信息:
a.RNA基因序列文件信息,包括文件格式,文件本地路徑,分布式文件系統中存儲的相對位置
b.比對程序相關信息,包括比對計算程序,所對應需要處理基因序列文件集,每個比對計算所需要硬體資源,包括CPU數量,內存數量。
(2)應用本系統提供的用戶操作接口,將以上信息傳遞至系統主結點點,在數據文件管理模塊及計算任務調度模塊的處理下,進行數據對比計算任務分析,確定比對任務總數,每節點需要執行的比對計算任務數量等信息。
(3)根據分析產生的結果,將數據文件以數據對的方式存儲在不同的子結點,如圖5所示。在圖5實例中,系統分析產生了全部比對計算任務如圖5中矩陣所示。隨後,不同計算任務被分配至相應子結點,每個計算任務所涉及的數據文件存儲位置也隨之確實。根據此分配方法,每個子結點均含有不同的序列文件並且每個子結點只存儲部分數據文件,有效節省了空間。同時,每個子結點所需要處理的計算任務也在此過程中被確定,具中圖5各子結點中星號代表此子結點需要執行的比對計算任務。
(4)所述分布式文件系統根據階段3中生成的各子結點對應的處理比對計算任務,考慮第一步中用戶提供的每個子任務需要的具體計算資源,對應每個不同子結點生成各自的任務隊列如圖5所示。每個子結點隨後依據各自己的任務隊列,依次獨立的執行不同比對計算任務,並將計算信息反饋給主結點。從圖5示例可見,所有計算結點均包括均衡數理的計算任務並且所有計算任務僅需要處理結點本存儲的數據文件。
(5)計算完成後,所有計算結果按用戶定義返回至客戶端結點,如下所示,供用戶分析使用,完成整個過程。
最終得到計算結果如下所示,輸出結果格式如下所示:
Key:[AcMNPV.faa,ASFV.faa] Value:0.0016810058966743133
Key:[AsGV.faa,AdhoNPV.faa] Value:0.011683080339163805。