一種基於3DCNN的肺結節假陽性樣本抑制方法與流程
2023-10-23 18:14:12 2
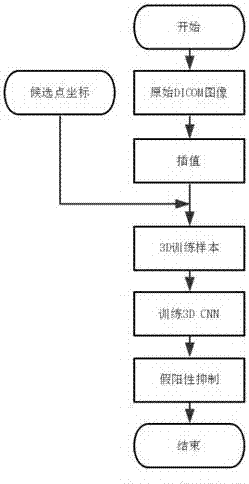
本發明屬於醫學影像的智能診斷領域,尤其涉及一種基於3dcnn的肺結節假陽性樣本抑制方法。
背景技術:
:肺結節的檢測對於肺部ct影像的處理十分關鍵,它是肺癌在早期狀態的一種主要表現形式。而對於肺結節進行有效的早期檢測和篩查能顯著提高肺癌患者的五年存活率,因此具有十分重要的研究價值和意義。雖然目前隨著ct影像技術和各種新型診斷、檢測手段的出現和發展,以及各種新型ct技術的出現,使得肺癌的診斷相比之前變得相對容易,但因為在早期發現癌症仍然不易,而且新型ct技術,如多排ct產生數量巨大的ct片子,會給影像科醫生的閱片增加繁重負擔,在高強度的工作下,造成漏診率偏高;再者,即使醫生給出了結果,但對初期惡性腫瘤的誤診率較高,常常使得病人疏於防範,仍然不能在早期發現肺癌病例,造成發現時已經很難治癒。為了把影像科醫生從繁重的閱片負擔中解脫出來,眾多科研人員先後研製了肺部影像計算機輔助診斷系統,即肺部cad(computeraideddiagnosis,計算機輔助診斷),輔助醫生進行肺結節檢測、肺結節良惡性判斷等工作。當前相關研究領域中基於肺部ct影像進行計算機輔助肺結節的自動檢測系統一般包括兩個關鍵步驟:第一步是肺結節候選點檢測,即通過一些閾值規則進行粗略的候選區域篩選,這些候選區域中,包含肺結節的則定義為陽性樣本,否則定義為陰性樣本或假陽性樣本。第二步是假陽性樣本抑制,即通過訓練一個合適的肺結節分類器,對正負樣本進行分類,最終選擇出真正包含結節的候選區。通常情況下,由第一步檢測得到的候選點中除了真實的陽性樣本外,還會包含大量的假陽性樣本,選用合適的技術方案對候選點中的假陽性樣本進行抑制,是提高肺結節檢測系統精度的重要步驟和手段。目前的假陽性樣本抑制方法多基於傳統的圖像處理方法,這些方法基於陽性樣本和假陽性樣本之間的區別,通過人工選擇和設計的特徵來設計分類器,對真假陽性樣本進行分類,從而達到假陽性樣本抑制的效果。但肺結節的真假陽性樣本區分度十分不明顯,人工選擇和設計能夠將其區分開來的特徵任務複雜,往往需要具有豐富專業知識的研究者長達數年的研究,才能選擇出符合任務需求的特徵,建立分類器;而一旦任務發生了變化,已經選擇和設計的特徵失效,還需要根據新任務的特點選擇和設計新的特徵。如此研究,耗費大量的人力物力,還不能取得令人滿意的效果。深度學習是近年來隨著各類研究中數據量的增大、計算機計算能力的增強以及人工神經網絡模型中的一些關鍵技術的推演而由傳統人工神經網絡發展來的具有強大擬合和泛化能力的分析模型。因為其不需要研究者手動選擇和設計特徵,能夠根據不同的具體應用自動對圖像中的特徵進行分析提取,深度學習在圖像分析處理中獲得了廣泛應用,並取得了很大成功。比如在經典的imagenet圖像分類識別比賽中,深度學習如今已經具有統治地位,基於深度學習而開發的算法已經獲得了超越人類水平的結果[1][2]。對ct影像進行肺結節檢測和假陽性抑制是一個典型的圖像處理中的識別和分類任務,使用基於深度學習技術而研發的3d深度網絡能夠綜合分析肺結節的3d圖像特徵,並通過對損失函數的加權操作巧妙地解決真假陽性樣本不均衡的問題,從而訓練出對肺結節特徵進行有效提取並對真假陽性樣本精準分類的3d深度神經網絡模型,解決這一肺部cad系統中的重要問題。技術實現要素:本發明的目的在於提供一種基於3dcnn的肺結節假陽性樣本抑制方法,旨在通過訓練3dcnn模型對肺部ct圖像中檢測到的肺結節候選點進行假陽性抑制,以達到準確檢測肺結節,從而篩查早期肺癌,提高潛在肺癌病人的生存可能性。為實現上述目的,本發明提供的基於3dcnn的肺結節假陽性樣本抑制方法包括以下步驟:a)從肺部ct影像序列數據中檢測肺結節候選點坐標;b)對原始的dicom圖像進行插值,得到插值後的3d原始圖像數據;c)對此前檢測得到的候選點坐標,按照如上b)插值步驟進行相應處理,將其映射到插值後的3d原始圖像數據上;d)對於每個候選點,根據其轉換後的坐標,從插值後的3d原始圖像數據中切出3d數據,作為訓練樣本;e)根據每個候選點的坐標,與原始圖像中的標籤(label)進行對應,為步驟c)中切出的每一個3d數據貼上相應的label;f)使用準備好的3d數據訓練3dcnn網絡;g)使用訓練得到的3dcnn模型對候選點進行假陽性抑制。進一步地,所述步驟b)中對原始dicom圖像進行插值,將z方向的切片間隔(spacing)插值為與x、y方向的像素間隔相等。這樣,在插值完成後,x、y、z三個方向的間隔相等。進一步地,所述步驟d)中,根據轉換後的候選點坐標,從插值後的3d原始圖像數據中切出3d數據,切出數據的長寬高(x、y、z方向)均為40像素,即數據大小為40×40×40。隨後對切出的數據進行如下處理:將小於-1000hu的數據置為-1000hu,將大於400hu的數據置為400hu,並將處理後的圖像數據歸一化到0到1之間。如果候選點為陽性樣本,則還需要對其進行數據擴充(augmentation),擴充方式包括平移、縮放和旋轉等。對每一個陽性樣本擴充個數大約為陰性樣本總數除以原始陽性樣本個數(如果所除結果不是整數,則取最近的整數),以使得擴充後的陰陽性樣本均衡。進一步地,所述步驟e)中,為每一個3d數據貼上相應的label:如果候選點距任意一個結節的外接邊框(boundingbox)中心點的距離小於該結節的半徑,則候選點的label為1;否則,該候選點的label為0。進一步地,所述步驟f)中,使用準備好的3d數據訓練3dcnn網絡,網絡結構(如圖2)如下:輸入為40×40×40大小的3d數據,逐步通過以下網絡層進行處理:卷積層1:16個大小為3×3×3的卷積核prelu層1最大池化層1:大小為2×2×2的池化核卷積層2:32個大小為3×3×3的卷積核prelu層2最大池化層2:大小為2×2×2的池化核卷積層3:64個大小為3×3×3的卷積核prelu層3最大池化層3:大小為2×2×2的池化核卷積層4:128個大小為3×3×3的卷積核prelu層4最大池化層4:大小為2×2×2的池化核輸出數據拉伸為大小為128×2×2×2即1024的一列數據全連層1:大小為1024×32的核dropout層:drop概率為0.5全連層2:大小為32×2的核softmax層得到的輸出,即為輸入樣本分別屬於陰陽性樣本的概率。進一步地,所述步驟f)中3dcnn網絡模型中權值參數的初始化使用khe等[3]提出的初始化激活函數為relu的神經網絡的方式完成,該方法以方差為輸入到當前層的神經元個數的倒數的2倍的截斷高斯分布小隨機數來初始化當前層的權值參數,如下:var=2/nin。進一步地,所述步驟f)中訓練3dcnn模型時,其loss函數如下:loss=weighted_sparse_softmax_cross_entropy+l1_l2_regularizer其中,weighted_sparse_softmax_cross_entropy為加權稀疏交叉熵損失函數,其通過如下方式構建:對於原始的陽性樣本,計算其標準的稀疏交叉熵損失函數得到損失值,並乘以一個權重,將所得乘積作為該樣本的損失值;對於其他樣本,使用標準的稀疏交叉熵損失函數,計算其損失值;對於任一batch的所有樣本,將使用以上方法得到的加權損失值和不需加權的原始損失值求和,將其作為該batch最終的加權稀疏交叉熵損失函數值;其中公式中的l1_l2_regularizer為對3dcnn模型中的各可訓練參數如權值和偏差添加l1和l2正則化項,以保證訓練得到的參數的稀疏性,並保證其具有較小值,從而達到抑制模型過擬合的目的。進一步地,所述步驟f)中訓練3dcnn模型時,其學習速率設定一個初始值0.01,隨後隨著訓練過程進行衰減調整,在訓練的一個epoch中衰減5次,每次變為原來的學習速率的0.95倍。在本發明的技術方案中,先從樣本中檢測到肺結節候選點,建立3d訓練樣本,再通過這些樣本訓練3d深度神經網絡,訓練出對肺結節特徵進行有效提取並對真假陽性樣本精準分類的3d深度神經網絡模型。該發明方法使用損失函數的加權操作巧妙地解決真假陽性樣本不均衡的問題,而在3dcnn網絡模型中權值參數的初始化使用khe等[3]提出的初始化激活函數為relu的神經網絡的方式能更好地達到目的,將本發明使用於醫學臨床上,能夠精準高效的檢測肺結節,從而篩查早期肺癌,提高患者生存可能性。附圖說明圖1是本發明方法流程圖。圖2是本發明方法3dcnn網絡結構圖。圖3是本發明名3d肺結節樣本實例。圖4是基於肺結節候選點訓練的模型的froc曲線。具體實施方式下面結合附圖和實例來說明基於3dcnn的肺結節假陽性樣本抑制方法在實際中的應用,並對本發明做進一步的說明和解釋。以被本領域研究者廣泛關注和使用的肺部ct影像公開資料庫lidc中的888個切片間隔在2.5mm以內(切片間隔大於2.5mm的對小結節的研究效果大打折扣,故忽略)的病例來進行本方法的演示和說明,並隨機選擇其中第582個病例(seriesuid為1.3.6.1.4.1.14519.5.2.1.6279.6001.100621383016233746780170740405)進行本方法中數據處理部分的演示和說明。步驟一:前期使用候選點檢測方法得到的肺結節候選點中心坐標如下所示:-76.62,156.53,-529.43120.13,160.73,-404.6894.23,171.24,-392.76等等。第582個病例一共有602個候選點,全部lidc病例一共有55萬餘肺結節候選點。在此示例中,檢測出的候選點坐標為世界坐標。步驟二:對該病例的原始圖像數據進行插值處理,得到插值後的圖像數據。對應於每一個肺結節候選點的x,y,z坐標,根據對病例數據進行的插值處理過程,對中心坐標進行相應的處理和轉換,並將其轉換為像素坐標。步驟三:根據轉換後的病例圖像數據和肺結節候選點的中心點坐標,從病例圖像數據中切出大小為40×40×40像素的立方體,作為該結節候選點的圖像數據。步驟四:根據肺結節候選點的陰陽性,決定是否對該候選點進行數據擴充。因為我們檢測出的候選點一共有55萬個左右,而陽性樣本(即涵蓋肺結節的樣本)一共有1351個,所以,為保證正負樣本的均衡,我們對陽性樣本進行55萬除以1351,即大約408倍的數據擴充。考慮到病例數據和肺結節的特點,我們選擇的數據擴充方式包括:平移、縮放和旋轉。平移範圍在±5個像素之間,縮放比例在圖像的0.9到1.1倍之間,旋轉則在±30°之間。步驟五:根據以上處理,生成用以訓練模型的數據,並根據以上分析,該數據一共有大約55萬×2,即110萬個;此外,為了保證訓練效果的最優化,我們對該數據進行了一個隨機亂序。同時,為了接下來對損失函數進行加權處理的方便,我們維護了一個用以記錄這110萬個數據的順序的文件,該文件中記錄了每個數據的病例id、真假陽性、是否通過數據擴充得到,等等。從生成的數據中隨機取出的一個肺結節圖像圖3所示。步驟六:根據以上生成的肺結節候選點數據訓練3dcnn深度神經網絡,網絡結構圖在前面已經進行了詳細描述。此處需要注意的是,需要根據不同的數據對損失函數進行處理,包括是否需要對其進行加權,等等。比如,如果數據屬於原始的55萬個假陽性樣本,或者數據屬於陽性樣本經數據擴充得到的樣本,則對其損失值不進行特別處理;而對於1351個陽性樣本,則需要對其損失值進行加權處理,權值取為55萬除以1351,即408。同時,為處理的簡便考慮,直接將由1351個陽性樣本得到的損失值乘以這個權值,並將其作為最終損失值。步驟七:依以上分析和處理訓練3dcnn,神經網絡的權值初始化使用以方差為輸入到當前層的神經元個數的倒數的2倍的截斷高斯分布小隨機數來完成,訓練的一個迭代(epoch)中有110萬個樣本。對學習速率的選擇和處理如下:初始學習速率取為0.01,每經過1/5個迭代過程,即大約22萬步訓練之後,學習速率下降為原來的0.95倍。如此迭代訓練,直到110萬個樣本中1351個真陽性樣本的總體正確率達到98%以上(當然,也可以根據具體需求,對其進行靈活選擇),或者根據我們的經驗,訓練2個epoch後保存模型停下即可。模型的訓練在ubuntu上基於google的tensorflow框架完成。下面列舉分析本示例在選出的lidc的888個病例上使用本發明的方法訓練3dcnn進行假陽性抑制的效果。圖4是基於551065個肺結節候選點訓練的模型的froc曲線,888個病例中平均每個病例有大約620個左右的候選點,包含1351個真陽性候選點。這些前期由其他檢測方法檢測出的候選點涵蓋了所有1186個結節中的1120個,其敏感度為94.4%。將圖4中的數據摘錄如下表:假陽性0.1250.250.51248~620敏感度0.7470.8260.8950.9300.9400.9430.94360.944最初的檢測結果為,在每個病例有大約620個假陽性樣本的情況下,其敏感度為94.4%;經過使用本發明的方法訓練的3dcnn模型進行假陽性抑制之後,在抑制掉大量假陽性樣本的情況下,可以保持與檢測結果基本相同的敏感度。這證明了本發明的方法在對肺結節假陽性樣本進行假陽性抑制時的有效性。參考文獻[1]a.krizhevsky,i.sutskever,andg.e.hinton,「imagenetclassificationwithdeepconvolutionalneuralnetworks,」inadvancesinneuralinformationprocessingsystems,2012,pp.1097–1105.[2]k.he,x.zhang,s.ren,andj.sun,「deepresiduallearningforimagerecognition,」arxivprepr.arxiv1512.03385,2015.[3]k.he,x.zhang,s.ren,andj.sun,「delvingdeepintorectifiers:surpassinghuman-levelperformanceonimagenetclassification,」inproceedingsoftheieeeinternationalconferenceoncomputervision,2016。當前第1頁12