一種面向問答系統的輸入文本自動糾錯方法與流程
2023-05-03 21:25:26
本發明涉及信息檢索與查詢領域,尤其涉及一種面向問答系統的輸入文本自動糾錯方法。
背景技術:
問答系統(questionansweringsystem,qa)是信息檢索系統的一種高級形式,它能用準確、簡潔的自然語言回答用戶用自然語言提出的問題。其研究興起的主要原因是人們對快速、準確地獲取信息的需求。問答系統的設計主要側重於如何提高對用戶提出問題獲得的答案的質量上,而沒有對用戶的輸入的提問進行判別和糾正。
然而用戶對問答系統提出問題,不可避免的會出現一些輸入錯誤,這些錯誤會極大的影響問答系統輸出的正確率。問答系統由於用戶的輸入錯誤,必然會導致獲取的相應答案質量降低,使問答系統的正確率降低,用戶體驗性不高。
在搜索應用中,拼音檢索技術可以有效避開輸入法,實現拼音原始性檢索,在一定程度上改變搜索行為;而在輸入法應用中,拼音糾錯技術能夠自動識別並修改用戶輸入的錯誤字符串,以保證正確漢字輸出,提高輸入法的容錯性。拼音糾錯技術能夠有效增強應用擴展性與用戶體驗性。
有鑑於此,亟待研發出一種能夠解決上述問題的輸入文本自動糾錯方法。
技術實現要素:
本發明的目的旨在解決現有問答系統中用戶輸入的問題會出現錯誤,從而導致問答效果不理想,問答系統的準確率及正確率低的問題。從而提供一種面向問答系統的輸入文本自動糾錯方法,它能夠自動糾正用戶的輸入錯誤,並考慮用戶本身地方的發音錯誤,從而提升問答效果。
為實現上述目的,本發明提供了一種面向問答系統的輸入文本自動糾錯方法。該方法包括以下步驟:
1)定義常見錯誤拼音音節表;
2)構建領域名詞詞典,所述領域名詞包括名詞和名詞短語;
3)使用確定的有限自動機構建步驟2)的領域名詞詞典,
所述確定的有限自動機定義為:r=(q,a,δ,q0,f),其中,q表示狀態集,a表示輸入拼音集,δ:q×a→q,δ是q與a的直積q×a到q的映射,q0∈q為起始狀態,為終止狀態;
4)接收用戶輸入的文本,所述用戶輸入的文本包括漢字或拼音,使用漢字轉拼音工具轉為拼音,然後使用逆向最大匹配法切分除了單音節拼音之外的所有合法或不合法的拼音;
5)將步驟4)中切割的拼音採用模糊匹配算法逐一匹配步驟3)中構建的領域名詞詞典,並記錄匹配過程中拼音的編輯距離,然後根據步驟1)中常見錯誤拼音音節表對常見錯誤下拼音的編輯距離進行調整,在拼音的編輯距離或調整後的拼音的編輯距離小於設定的閾值β時繼續匹配,匹配出最長的領域名詞,最終取路徑所有的漢字組合;
6)對步驟5)中所有漢字組合形成的一個或多個的領域名詞進行打分;
7)輸出步驟6)中打分最高的領域名詞。
進一步地,所述步驟1)中常見錯誤拼音音節表包括拼音開頭出錯的拼音和拼音結尾出錯的拼音,所述拼音開頭出錯的拼音包括:n和l錯誤、h和f錯誤,翹舌音z、c、s和平舌音zh、ch、sh錯誤;所述拼音結尾出錯的拼音包括:前鼻音an、en、in和後鼻音ang、eng、ing錯誤。
進一步地,所述步驟2)具體包括:
201)根據詞頻對領域名詞進行排序;
202)將詞頻小於預定詞頻閾值α的領域名詞剔除,將詞頻大於設定詞頻閾值α的領域名詞提取出來加入領域名詞詞典。
進一步地,所述步驟3)具體包括:
301)逐一讀取步驟2)中的領域名詞;
302)判斷領域名詞首字拼音庫中是否包含當前領域詞的首字拼音,即判斷是否已經包含當前首字拼音的樹,若是,則執行步驟303);若否,則執行步驟304);
303)如果領域名詞首字拼音庫中包含當前領域名詞的首字拼音,即判斷已經包含當前首字拼音的樹,則找出已經存在的首字拼音樹並得到首節點;
304)將當前領域名詞的首字拼音加入到領域詞首字拼音庫中,構建一棵領域名詞拼音樹並將當前拼音放入節點中;
305)判斷當前拼音是否為終節點,即判斷當前拼音是否為領域名詞最後一個字的拼音,若是,則執行步驟311;若否,則執行步驟306;
306)如果步驟305中當前拼音不是終節點,即當前拼音不是領域名詞的最後一個字的拼音,則判斷當前標誌位是否已經被設置為1,若是,則執行步驟308),若否,則執行步驟307);
307)若步驟306中拼音標誌位之前未被設置為1,則將此處拼音標誌位設置為0,然後執行步驟308);
308)讀取當前領域名詞下一個字的拼音;
309)判斷步驟303)或步驟304)當前節點的子節點是否包含步驟308)的拼音,若是,則跳轉到步驟305),若否,則執行步驟310);
310)將步驟308)的拼音添加為當前節點的子節點,然後再跳轉到步驟305);
311)如果步驟305)中當前拼音是終節點,即是領域名詞最後一個字的拼音,則將拼音節點的標誌位設置為1;
312)判斷領域名詞是否讀完;若是,則結束進程,若否,則返回到步驟301)繼續讀取下一個領域名詞。
進一步地,所述步驟5)具體包括:
所述步驟5)具體包括:
501)接收步驟4)中使用逆向最大匹配算法分割後的n個拼音序列;
502)對i和k賦初值,i=1,k=1,i表示第幾個拼音序列,k表示第k棵樹;
503)判斷是否存第k棵領域名詞樹;若存在,則執行步驟504),若不存在,則執行步驟505);
504)計算當前第i個拼音與第k棵樹的首字拼音的編輯距離dis,然後執行步驟506);
505)若不存在第k棵領域名詞樹,即領域名詞樹已經匹配結束,均沒有匹配上的拼音,說明當前第i個拼音沒有匹配上,此時匹配下一個拼音序列,並從第1棵領域詞樹開始匹配,然後執行步驟504);
506)判斷當前匹配的拼音是否為常見的拼音錯誤;若是,則執行步驟507),若否,則執行步驟508);
507)如果為常見的拼音錯誤,則減小編輯距離dis;
508)判斷步驟504)和步驟507)中編輯距離dis是否小於設定的距離閾值β;若是,則執行步驟509),若否,則執行步驟512);
509)若步驟508)中編輯距離dis小於等於設定閾值β,記錄拼接上的拼音串;
510)判斷步驟504)中當前拼音的標誌位是否為1;若是,則執行步驟511),若否,則執行步驟514);
511)若步驟510)中當前拼音的標誌位為1,表明已經匹配上領域名詞的拼音,將匹配成功的領域名詞的拼音標誌位設置為1,記錄匹配上的領域名詞拼音,然後執行步驟514);
512)若步驟508)中編輯距離dis大於設定閾值β,則執行k++,匹配切斷,去匹配下一棵樹的首字拼音,然後執行步驟513);
513)清空匹配切斷的拼音串,然後跳轉至步驟503)重新匹配下一棵領域名詞樹;
514)若步驟510)中當前拼音的標誌位為0,即不是結束標誌位,則執行i++,繼續匹配下一個拼音序列,將用戶輸入的下一個拼音與領域名詞樹當前節點的下一級節點比較匹配;
515)判斷步驟514)中的i是否小於等於n,即判斷第i個拼音是否為用戶輸入文本的拼音序列的最後一個拼音;若是,則執行步驟516),若否,則執行步驟517);
516)若i小於等於n,即用戶輸入的文本的拼音序列還沒有匹配結束,此時依次計算匹配上的拼音的下一個狀態的拼音集合中的拼音與輸入的文本轉化的下一個拼音的編輯距離,同時找出最小的編輯距離與之前的dis疊加,再跳轉到步驟506),判斷是否為常見拼音錯誤更新編輯距離,並判斷距離閾值;
517)若i大於n,即輸入的拼音序列已經匹配結束,則結束匹配進程,然後執行步驟6)。
進一步地,所述步驟6)具體包括以下步驟:
601)逐一計算步驟5)中匹配上的領域名詞漢字與用戶輸入文本漢字的編輯距離,並將計算出的漢字編輯距離結合步驟5)中匹配過程中拼音的編輯距離和領域名詞的長度來打分;
602)判斷匹配上的領域名詞的分數是否大於設定分數的閾值θ;若是,則執行步驟603),若否,則執行步驟604);
603)若是,則去除小於或等於設定閾值θ的領域名詞。
604)若否,則保留大於設定閾值θ的領域名詞。
本發明的有益效果:與現有的技術相比,本面向問答系統的輸入文本自動糾錯方法,考慮用戶的地方發音錯誤的情況下,使用有限自動機構建領域詞庫,將領域名詞構建為一棵棵查詢樹,大大減少了算法時間複雜度,同時採用模糊匹配,設置編輯距離閾值,並根據常見的用戶拼音錯誤調整編輯距離,既能夠解決用戶輸入的漢字錯誤,亦能夠解決用戶輸入的拼音錯誤,糾錯後的問題能夠提升問答效果,增強用戶體驗性。
附圖說明
圖1為本發明實施例的一種面向問答系統的輸入文本自動糾錯方法的流程圖;
圖2為本發明實施例提供的一種採用確定的有限自動機構建領域名詞詞典的方法流程圖;
圖3為本發明實施例提供了一種模糊匹配的算法流程圖;
圖4為本發明實施例提供的確定的有限自動機的原理示意圖;
圖5為本發明實施例提供的構建的領域詞庫樹的一個示例圖。
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,下面將結合發明實施例中的附圖,對發明實施例中的技術方案進行清楚、完整地描述,顯然,下面所描述的實施例僅僅是發明一部分實施例,而非全部的實施例。基於發明中的實施例,本領域普通技術人員在沒有做出創造性勞動前提下所獲得的所有其它實施例,都屬於發明保護的範圍。
請參閱圖1,本發明實施例提供了一種面向問答系統的輸入文本自動糾錯方法的流程圖。
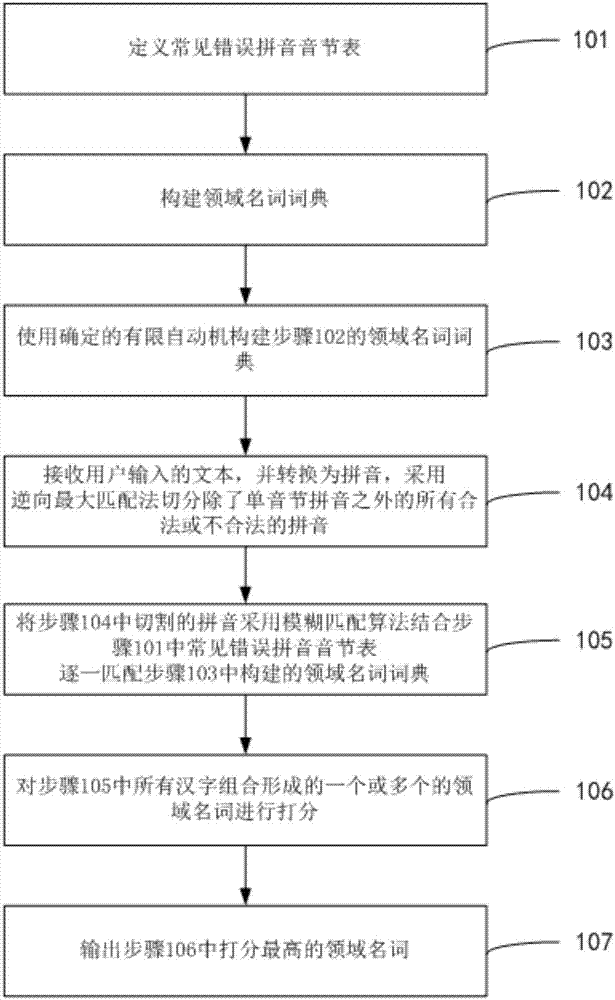
在步驟101中,定義常見錯誤拼音音節表。
本實施例中的錯誤拼音音節表可包括兩類,一類為拼音開頭出錯的拼音,一類為拼音結尾出錯的拼音;拼音開頭出錯的拼音可以包括:n和l錯誤、h和f錯誤,翹舌音z和平舌音zh錯誤、翹舌音c和平舌音ch錯誤、翹舌音s和平舌音sh錯誤;拼音結尾出錯的拼音可以包括:前鼻音an和後鼻音ang錯誤、前鼻音en和後鼻音eng錯誤、前鼻音in和後鼻音ing錯誤等。
在步驟102中,構建領域名詞詞典,所述領域名詞包括名詞和名詞短語。名詞可以普通名詞和非普通名詞,例如是知識、身份證等。名詞短語可以是諸如智慧財產權、註冊企業、企業管理和企業實名認證這類詞等。
在步驟103中,使用確定的有限自動機構建步驟102的領域名詞詞典。
其中,確定的有限自動機定義為:r=(q,a,δ,q0,f),其中,q表示狀態集,a表示輸入拼音集,δ:q×a→q,δ是q與a的直積q×a到q的映射,q0∈q為起始狀態,為終止狀態,原理圖可參見圖4。在糾錯過程中要少運算,而在dfa算法中幾乎沒有什麼計算,有的只是狀態的轉換。同時這裡沒有狀態轉換,沒有動作,有的只是query(查找)。我們可以認為,通過squery(查找)u、v,通過uquery(查找)v、q,通過vquery(查找)u、q。
例如,在領域名詞庫中存在如下幾個名詞:知識、指示、智慧、智慧財產權、指揮、制服、支付寶。通過dfa構建將其構建為如圖5所示的樹結構,這樣就將我們的領域詞庫構建成了一個類似與一顆一顆的樹,這樣我們判斷一個用戶輸入的問題中是否存在錯字,就大大減少了檢索的匹配範圍。比如我們要判斷智慧財產權,根據第一個字的拼音,我們就可以確認需要檢索的是那棵樹,然後再在這棵樹中進行檢索。如何來判斷一個領域詞是否已經結束,利用標識位來判斷。領域詞中最後一個字的拼音,表示這個詞結束,我們將一個詞的的最後一個字的標誌位設置為isend=1,其餘的則設置為isend=0;如圖5所示中的知識與智慧財產權,知識是一個詞,智慧財產權也是一個詞,將shi和quan的標誌位都設置為isend=1。
在步驟104中,接收用戶輸入的文本,即用戶輸入的問題。用戶輸入的文本包括漢字或拼音。然後使用漢字轉拼音工具轉為拼音。考慮到用戶會輸入錯誤的拼音,此時的拼音可能並非一個拼音音節,將非法拼音的部分除了單音節的拼音之外,其餘合併,為模糊匹配做準備;再使用逆向最大匹配法切分除了單音節拼音之外的所有合法或不合法的拼音。
在步驟105中,將步驟104中切割的拼音採用模糊匹配算法逐一匹配步驟103中構建的領域名詞詞典,並記錄匹配過程中拼音的編輯距離,然後根據步驟101中常見錯誤拼音音節表對常見錯誤下拼音的編輯距離進行調整,在拼音的編輯距離或調整後的拼音的編輯距離小於設定的閾值β時繼續匹配,匹配出最長領域名詞。最終取路徑的所有漢字組合。那麼經過本步驟之後,會匹配出符合條件的一個或多個領域名詞。
在步驟106中,對步驟105中所有漢字組合形成的一個或多個的領域名詞進行打分。
具體的打分方式可參見如下步驟:
在步驟106-1中,逐一計算步驟105中匹配上的領域名詞漢字與用戶輸入文本漢字的編輯距離,並將計算出的漢字編輯距離結合步驟105中匹配過程中拼音的編輯距離和領域名詞的長度來打分。編輯距離越小、領域名詞長度越大,得分越高。
在步驟106-2中,判斷匹配上的領域名詞的分數是否大於設定分數的閾值θ;若是,則執行步驟106-3,若否,則執行步驟106-4。
在步驟106-3中,若是,則去除小於或等於設定閾值θ的領域名詞。
在步驟106-4中,若否,則保留大於設定閾值θ的領域名詞。
在步驟107中,輸出步驟106中打分最高的領域名詞。
以上對本發明實施例提供的一種面向問答系統的輸入文本自動糾錯方法進行了詳細的描述,以下將對步驟103中使用確定的有限自動機構建領域名詞進行詳細的描述。
請參閱圖2,本發明實施例提供了一種採用確定的有限自動機構建步驟102的領域名詞詞典的方法流程圖,該實施例主要對圖1中步驟103進行具體描述,其包括以下步驟:
在步驟201中,逐一讀取圖1中步驟102中的領域名詞。
在步驟202中,判斷領域名詞首字拼音庫中是否包含當前領域詞的首字拼音,即判斷是否已經包含當前首字拼音的樹;若是,則執行步驟203;若否,則執行步驟204。
在步驟203中,如果領域名詞首字拼音庫中包含當前領域名詞的首字拼音,即判斷已經包含當前首字拼音的樹,則找出已經存在的首字拼音樹並得到首節點。
在步驟204中,將當前領域名詞的首字拼音加入到領域詞首字拼音庫中,構建一棵領域名詞拼音樹並將當前拼音放入節點中。
在步驟205中,判斷當前拼音是否為終節點,即判斷當前拼音是否為領域名詞最後一個字的拼音,若是,則執行步驟211;若否,則執行步驟206。
在步驟206中,如果步驟205中當前拼音不是終節點,即當前拼音不是領域名詞的最後一個字的拼音,則判斷當前標誌位是否已經被設置為1,若是,則執行步驟208,若否,則執行步驟207。
此步判斷是因為防止短的領域名詞的結束標誌位被長的領域名詞的標誌位覆蓋,例如有領域名詞知識和智慧財產權,先將知識加入有限自動機,則shi的標誌位被設置為1,當將智慧財產權加入有限自動機時,如果不做此步判斷,shi的結束標誌位則會被替換為0,搜索時則無法匹配知識這個領域名詞,因此此處判斷很重要。
在步驟207中,若步驟206中拼音標誌位之前未被設置為1,則將此處拼音標誌位設置為0,然後執行步驟208。
在步驟208中,讀取當前領域名詞下一個字的拼音。
在步驟209中,判斷步驟203或步驟204當前節點的子節點是否包含步驟208的拼音;若是,則跳轉到步驟205;若否,則執行步驟210。
在步驟210中,將步驟208的拼音添加為當前節點的子節點,然後再跳轉到步驟205。
在步驟211中,如果步驟205中當前拼音是終節點,即是領域名詞最後一個字的拼音,則將拼音節點的標誌位設置為1。
在步驟212中,判斷領域名詞是否讀完;若是,則結束進程,若否,則返回到步驟201繼續讀取下一個領域名詞。
以一個具體例子說明:假如步驟201中讀取的是領域名詞是智慧財產權,對應的拼音是zhishichanquan。則判斷領域名詞首字拼音庫中是否包含當前領域名詞(智慧財產權)的首字拼音zhi;若是,則找出已經存在的首字拼音zhi這棵樹。若否,則將領域名詞(智慧財產權)首字拼音zhi加入到領域名詞首字拼音庫中,構建一棵領域名詞拼音數,並將當前拼音zhi放入節點中。判斷結束後,再進一步判斷當前拼音zhi是否為終節點,即判斷當前拼音zhi是否為領域名詞的最後一個拼音;若是,則將當前拼音節點zhi標誌位isend設置為1,然後再判斷領域名詞(智慧財產權)是否全部讀取完,讀取完則結束進程,否則,讀取下一個領域名詞。顯然這裡,當前拼音zhi並不是終節點,那麼這個時候則判斷當前標誌位為是否已經被標註為1,也就是zhi是否已經被標註為1,否的話,則將zhi的標誌位isend設置為0,然後再讀取領域名詞(智慧財產權)的下一個字拼音shi。然後判斷當前節點的子節點是否包含該拼音,也就是當前zhi這棵數的子節點是否包含shi這個拼音,包含,則判斷當前拼音shi是否為終節點,判斷過程如上所述zhi的過程。不包含,則添加當前拼音shi作為zhi這棵數的子節點,然後再判斷當前拼音shi是否為終節點,判斷過程如上所述zhi的過程,在此,不一一贅述。重複上述操作過程,直至將步驟201中所有的領域名詞讀取完。
以上是對本發明實施例提供的一種採用確定的有限自動機構建步驟102的領域名詞詞典的方法進行詳細的描述,以下將對本發明實施例提供的模糊匹配算法進行詳細的描述。
請參閱圖3,本發明實施例提供了一種模糊匹配的算法流程圖,該實施例主要對圖1中步驟105進行具體描述。具體如下:
在步驟301中,接收圖1中步驟104中使用逆向最大匹配算法分割後的n個拼音序列。
在步驟302中,對i和k賦初值,i=1,k=1,i表示第幾個拼音序列,k表示第k棵樹。
在步驟303中,判斷是否存第k棵領域名詞樹;若存在,則執行步驟304,若不存在,則執行步驟305。
在步驟304中,計算當前第i個拼音與第k棵樹的首字拼音的編輯距離dis,然後執行步驟306。
在步驟305中,若不存在第k棵領域名詞樹,即領域名詞樹已經匹配結束,均沒有匹配上的拼音,說明當前第i個拼音沒有匹配上,此時匹配下一個拼音序列,並從第1棵領域詞樹開始匹配,然後執行步驟304。
在步驟306中,判斷當前匹配的拼音是否為常見的拼音錯誤;若是,則執行步驟307,若否,則執行步驟308。
在步驟307中,如果為常見的拼音錯誤,則減小編輯距離dis。
在步驟308中,判斷步驟304和步驟307中編輯距離dis是否小於設定的距離閾值β;若是,則執行步驟309;若否,則執行步驟312。
在步驟309中,若步驟308中編輯距離dis小於等於設定閾值β,記錄拼接上的拼音串。
在步驟310中,判斷步驟304中當前拼音的標誌位是否為1;若是,則執行步驟311;若否,則執行步驟314。
在步驟311中,若步驟310中當前拼音的標誌位為1,表明已經匹配上領域名詞的拼音,將匹配成功的領域名詞的拼音標誌位設置為1,記錄匹配上的領域名詞拼音,然後執行步驟314。
在步驟312中,若步驟308中編輯距離dis大於設定閾值β,則執行k++,匹配切斷,去匹配下一棵樹的首字拼音,然後執行步驟313。
在步驟313中,清空匹配切斷的拼音串,然後跳轉至步驟303重新匹配下一棵領域名詞樹。
在步驟314中,若步驟310中當前拼音的標誌位為0,即不是結束標誌位,則執行i++,繼續匹配下一個拼音序列,將用戶輸入的下一個拼音與領域名詞樹當前節點的下一級節點比較匹配。
在步驟315中,判斷步驟314中的i是否小於等於n,即判斷第i個拼音是否為用戶輸入文本的拼音序列的最後一個拼音;若是,則執行步驟316;若否,則執行步驟317。
在步驟316中,若i小於等於n,即用戶輸入的文本的拼音序列還沒有匹配結束,此時依次計算匹配上的拼音的下一個狀態的拼音集合中的拼音與輸入的文本轉化的下一個拼音的編輯距離,同時找出最小的編輯距離與之前的dis疊加,再跳轉到步驟506,判斷是否為常見拼音錯誤更新編輯距離,並判斷距離閾值;
在步驟317中,若i大於n,即輸入的拼音序列已經匹配結束,則結束匹配進程,然後執行圖1中的步驟106。
以一個具體例子說明:假設步驟104中使用逆向最大匹配算法分割後的n個拼音序列為zishichanquan(子識產權),那麼具體步驟如下:,
接收步驟104中使用逆向最大匹配算法分割後的拼音zi;判斷是否存第1棵領域名詞樹(一般情況下都會存在第1棵樹)。若存在,則計算當前第1個拼音zi與第1棵樹的首字拼音的編輯距離dis,假設第一棵樹是zhi,那麼當前第一個拼音zi與第1棵樹zhi的編輯距離dis=1。若不存在第1棵領域名詞樹,即領域名詞樹已經匹配結束,均沒有匹配上的拼音,說明當前第1個拼音zi沒有匹配上,此時匹配下一個拼音si,並從第1棵領域詞樹開始匹配。然後判斷當前匹配的拼音zi是否為常見的拼音錯誤,顯然zi轉換到zhi只需要一步,即編輯距離為1,可以判斷出是常見的錯誤,然後減小編輯距離dis,比如可以減小至0.5。如果第一棵數是shen,則拼音zi到shen的轉換距離為4步,即編輯距離為4,就判斷為不是常見錯誤。然後對將常見錯誤或不是常見錯誤下的當前拼音zi的編輯距離都與預定的距離閾值β(假定等於2)進行比較,大於,則查找第二棵樹,查找判斷過程與第一棵樹一致;小於或等於,則記錄匹配上的zi這棵樹,然後判斷當前拼音zi的標誌位是否為1,顯然這裡zi的標誌位不是1,那麼則執行i++,繼續匹配下一個拼音shi,將用戶輸入的下一個拼音shi與領域名詞樹當前節點zhi的下一級節點(比如圖5中shi、hui、fu)比較匹配;然後再判斷zi這個拼音是否是步驟104拼音序列中最後一個拼音quan,顯然不是,則將說明用戶輸入的文本拼音序列還沒有匹配結束,則此時計算匹配上的拼音zhi下一個狀態的拼音集合中的拼音(比如圖5中shi、hui、fu)與輸入文本轉化的下一個拼音shi的編輯距離,找出最小的編輯距離,也就是子節點shi,編輯距離為0,將0與之前的dis=0.5進行疊加後再與β比較,即此時dis=0.5+0=0.5<β,然後,記錄匹配上的zhishi拼音串,進行下一個拼音chan和quan的查找與匹配,過程與上述過程一致。最後匹配上的詞為智慧財產權、知示產權、知識、指示。打分的時候就逐一計算匹配上的領域名詞漢字與用戶輸入文本漢字的編輯距離(子識產權),並將計算出的漢字編輯距離結合匹配過程中拼音的編輯距離和領域名詞的長度來打分,因為匹配上的詞中,智慧財產權與輸入文本子識產權只需變化一步,zhishichanquan與輸入拼音zishichanquan也只需要變化一步,且長度最大,所以智慧財產權這個領域名詞得分最高,最後變將打分最高的領域名詞(智慧財產權)輸出。
以上對本發明實施例的一種模糊匹配的算法進行了詳細的闡述,結合本文所闡述的面向問答系統的輸入文本自動糾錯方法,考慮用戶的地方發音錯誤的情況下,使用有限自動機構建領域詞庫,將領域名詞構建為一棵棵查詢樹,大大減少了算法時間複雜度,同時採用模糊匹配,設置編輯距離閾值,並根據常見的用戶拼音錯誤調整編輯距離,既能夠解決用戶輸入的漢字錯誤,亦能夠解決用戶輸入的拼音錯誤,糾錯後的問題能夠提升問答效果,增強用戶體驗性。
以上所述的具體實施方式,對本發明的目的、技術方案和有益效果進行了進一步詳細說明,所應理解的是,以上所述僅為本發明的具體實施方式而已,並不用於限定本發明的保護範圍,凡在本發明的精神和原則之內,所做的任何修改、等同替換、改進等,均應包含在本發明的保護範圍之內。