玉米鋅鐵調控轉運體ZmZIP3基因及其應用的製作方法
2023-04-27 23:09:06 2
技術領域
本發明涉及從植物中分離的金屬離子轉運體基因,尤其涉及從玉米中分離的與鋅鐵的吸收、轉運或儲存有關的調控轉運體ZmZIP3基因,本發明進一步涉及調控轉運體ZmZIP3基因在調控植物吸收、轉運或儲存鋅或鐵能力,促進胚和胚乳的發育或成熟以及增加糧食作物種子鋅鐵含量中的應用,屬於植物金屬離子調控轉運體基因的分離和應用領域。
背景技術:
鋅和鐵是生物體所必需的微量元素,在植物的生長發育過程中有著重要作用(Wintz H,Fox T,Wu YY,et al.Expression profiles of Arabidopsis thaliana in mineral deficiencies reveal novel transporters involved in metal homeostasis.The Journal of biological chemistry 2003,278(48):47644-47653.)。鋅是生物體300多種酶和重要蛋白質的結構輔助因子(Haydon MJ,Cobbett CS.A novel maj or facilitator superfamily protein at the tonoplast influences zinc tolerance and accumulation in Arabidopsis.Plant physiology 2007,143(4):1705-1719.)。鋅不僅參與機體的各種代謝,在生物膜穩定和基因表達調控等生理機能中也擔負著重要的角色(Mathews WR,Wang F,Eide DJ,et al.Drosophila fear of intimacy encodes a Zrt/IRT-like protein(ZIP)family zinc transporter functionally related to mammalian ZIP proteins.The Journal of biological chemistry 2005,280(1):787-795.)。適量增加植物體內鋅的含量可提高作物產量,而鋅的缺乏會導致葉綠素、脂質、蛋白、質膜的氧化破壞,植物體內鋅離子的過度積累又會對植物產生毒害。
鐵在細胞呼吸、光合作用和金屬蛋白的催化反應過程中發揮重要作用,是重要的電子傳遞體,因此,鐵元素在原核和真核生物的生命活動中具有不可替代的功能。另外,細胞內過高的Fe3+/Fe2+氧化還原勢會導致超氧化合物的產生,對細胞造成傷害(Briat JF,Lebrun M.Plant responses to metal toxicity.Comptes rendus de l'Academie des sciences Serie III,Sciences de la vie 1999,322(1):43-54.)。因此,嚴格控制植物體內金屬離子的平衡是至關重要的。
參與鋅鐵吸收的蛋白主要有三類,都是以蛋白家族形式存在的,包括:ZIP,即鋅調控轉運體(Zinc-regulated transporter,ZRT)和鐵調控轉運體(Iron-regulated transporter,IRT)。酵母功能互補實驗顯示ZIP家族基因能夠轉運包括Zn2+、Fe2+、Cu2+、Cd2+在內的多種金屬離子(Colangelo EP,Guerinot ML.Put the metal to the petal:metal uptake and transport throughout plants.Current opinion in plant biology 2006,9(3):322-330.)。ZIP一般由309-476個胺基酸殘基組成,有8個潛在的跨膜結構域和相似的拓撲結構,第3和第4跨膜區之間有一長的可變區,可變區位於胞內,其C、N末端位於胞外,該區富含組氨酸殘基,可能與金屬的結合、轉運有關(Guerinot ML.The ZIP family of metal transporters.Biochim Biophys Acta 2000,1465(1-2):190-198.)。
目前在擬南芥、水稻、蒺藜、苜蓿、大豆、野生型二粒小麥、葡萄等植物中鑑定出ZIP基因並對其功能進行了研究。在擬南芥中發現16個ZIP家族基因,AtIRT1是通過酵母互補實驗分離得到的第一個ZIP功能基因,其主要在根部表達,且該基因的過表達可導致鎳的過度積累(Eide D,Broderius M,Fett J,et al.A novel iron-regulated metal transporter from plants identified by functional expression in yeast.Proceedings of the National Academy of Sciences of the United States of America 1996,93(11):5624-5628;Henriques R,Jasik J,Klein M,et al.Knock-out of Arabidopsis metal transporter gene IRT1 results in iron deficiency accompanied by cell differentiation defects.Plant molecular biology 2002,50(4-5):587-597;Varotto C,Maiwald D,Pesaresi P,et al.The metal ion transporter IRT1 is necessary for iron homeostasis and efficient photosynthesis in Arabidopsis thaliana.The Plant journal:for cell and molecular biology 2002,31(5):589-599;Vert G,Grotz N,Dedaldechamp F,et al.IRT1,an Arabidopsis transporter essential for iron uptake from the soil and for plant growth.Plant Cell 2002,14(6):1223-1233;Nishida S,Tsuzuki C,Kato A,et al.AtIRT1,the primary iron uptake transporter in the root,mediates excess nickel accumulation in Arabidopsis thaliana.Plant&cell physiology 2011,52(8):1433-1442.)。AtIRT2主要在根部表達,定位在囊泡,推測具有細胞內過量金屬元素的解毒功能(Vert G,Briat JF,Curie C.Arabidopsis IRT2 gene encodes a root-periphery iron transporter.The Plant journal:for cell and molecular biology 2001,26(2):181-189;Vert G,Barberon M,Zelazny E,et al.Arabidopsis IRT2 cooperates with the high-affinity iron uptake system to maintain iron homeostasis in root epidermal cells.Planta 2009,229(6):1171-1179.14,15)。AtIRT3能互補鋅、鐵轉運雙突變體,過表達AtIRT3會使鋅在地上部以及鐵在地下部積累(Lin YF,Liang HM,Yang SY,et al.Arabidopsis IRT3 is a zinc-regulated and plasma membrane localized zinc/iron transporter.The New phytologist 2009,182(2):392-404.)。表達分析顯示,AtZIP1、AtZIP5、AtZIP9、AtZIP12和AtIRT3受缺鋅誘導,由此推測,這些基因在缺鋅條件下可能增強鋅的吸收能力(Kramer U,Talke IN,Hanikenne M.Transition metal transport.FEBS Lett 2007,581(12):2263-2272.)。
玉米(Zea mays)是中國重要的糧食、飼料和經濟作物,增加玉米籽粒中鋅、鐵等微量元素的含量,對提高飲食或飼料利用效率、促進經濟的發展及人體健康尤為重要。目前,已知許多轉運蛋白參與了植物體內鋅鐵離子平衡網絡系統,其中ZIP(Zinc-regulated transporters,Iron-regulated transporter-like proteins,ZIP)基因家族對鋅、鐵等二價金屬離子的吸收、運輸和儲存起著重要作用,在擬南芥、水稻、大麥、大豆上,已報導了一些有關ZIP家族基因的研究,但對ZIP家族基因在植物體內具體的作用機制尚未完全了解,而關於玉米的ZIP家族基因的研究報導較少。了解Zn2+、Fe2+在玉米中的吸收、運輸方式,分布規律和調節機制,將有助於改善玉米在鋅、鐵缺乏的環境中的生長發育,為進一步揭示玉米中ZIP家族基因的作用機理奠定基礎,為玉米鋅、鐵高效轉基因育種提供候選基因,也為人類鋅鐵營養提供良好的基礎。
技術實現要素:
本發明的目的之一是提供從玉米(Zea mays)中分離的鋅鐵調控轉運體基因;
本發明的目的之二是提供鋅鐵調控轉運體基因所編碼的蛋白質;
本發明的目的之三是將所述的鋅鐵調控轉運體基因應用於調控植物對鋅鐵等金屬離子的吸收、轉運或儲存,促進胚根和胚芽發育以及胚成熟或者增加糧食作物籽粒中鋅鐵含量。
本發明的上述目的是通過以下技術方案來實現的:
從玉米(Zea mays)中分離的鋅鐵調控轉運體ZmZIP1基因,其cDNA序列為(a)、(b)或(c)所示:
(a)、SEQ ID No.1所示的核苷酸序列;
(b)、編碼SEQ ID No.2所示胺基酸的核苷酸序列;
(c)、與SEQ ID No.1所示核苷酸的互補序列在嚴謹雜交條件能夠進行雜交的核苷酸,該核苷酸所編碼的蛋白質具有鋅鐵調控轉運體的功能。
從玉米(Zea mays)中分離的鋅鐵調控轉運體ZmZIP2基因,其cDNA序列為(a)、(b)或(c)所示:
(a)、SEQ ID No.3所示的核苷酸序列;
(b)、編碼SEQ ID No.4所示胺基酸的核苷酸序列;
(c)、與SEQ ID No.3所示核苷酸的互補序列在嚴謹雜交條件能夠進行雜交的核苷酸,該核苷酸所編碼的蛋白質具有鋅鐵調控轉運體的功能。
從玉米(Zea mays)中分離的鋅鐵調控轉運體ZmZIP3基因,其cDNA序列為(a)、(b)或(c)所示:
(a)、SEQ ID No.5所示的核苷酸序列;
(b)、編碼SEQ ID No.6所示胺基酸的核苷酸序列;
(c)、與SEQ ID No.5所示核苷酸的互補序列在嚴謹雜交條件能夠進行雜交的核苷酸,該核苷酸所編碼的蛋白質具有鋅鐵調控轉運體的功能。
從玉米(Zea mays)中分離的鋅鐵調控轉運體ZmZIP7基因,其cDNA序列為(a)、(b)或(c)所示:
(a)、SEQ ID No.7所示的核苷酸序列;
(b)、編碼SEQ ID No.8所示胺基酸的核苷酸序列;
(c)、與SEQ ID No.7所示核苷酸的互補序列在嚴謹雜交條件能夠進行雜交的核苷酸,該核苷酸所編碼的蛋白質具有鋅鐵調控轉運體的功能。
從玉米(Zea mays)中分離的鋅鐵調控轉運體ZmZIP8基因,其cDNA序列為(a)、(b)或(c)所示:
(a)、SEQ ID No.9所示的核苷酸序列;
(b)、編碼SEQ ID No.10所示胺基酸的核苷酸序列;
(c)、與SEQ ID No.9所示核苷酸的互補序列在嚴謹雜交條件能夠進行雜交的核苷酸,該核苷酸所編碼的蛋白質具有鋅鐵調控轉運體的功能。
所述「嚴謹雜交條件」意指在所屬領域中已知的低離子強度和高溫的條件。通常,在嚴謹條件下,探針與其靶序列雜交的可檢測程度比與其它序列雜交的可檢測程度更高(例如超過本底至少2倍。嚴謹雜交條件是序列依賴性的,在不同的環境條件下將會不同,較長的序列在較高溫度下特異性雜交。通過控制雜交的嚴謹性或洗滌條件可鑑定與探針100%互補的靶序列。對於核酸雜交的詳盡指導可參考有關文獻(Tijssen,Techniques in Biochemistry and Molecular Biology-Hybridization with Nucleic Probes,"Overview of principles of hybridization and the strategy of nucleic acid assays.1993)。更具體的,所述嚴謹條件通常被選擇為低於特異序列在規定離子強度pH下的熱熔點(Tm)約5-10℃。Tm為在平衡狀態下50%與目標互補的探針雜交到目標序列時所處的溫度(在指定離子強度、pH和核酸濃度下)(因為目標序列過量存在,所以在Tm下在平衡狀態下50%的探針被佔據)。嚴謹條件可為以下條件:其中在pH 7.0到8.3下鹽濃度低於約1.0M鈉離子濃度,通常為約0.01到1.0M鈉離子濃度(或其它鹽),並且溫度對於短探針(包括(但不限於)10到50個核苷酸)而言為至少約30℃,而對於長探針(包括(但不限於)大於50個核苷酸)而言為至少約60℃。嚴謹條件也可通過加入諸如甲醯胺的去穩定劑來實現。對於選擇性或特異性雜交而言,正信號可為至少兩倍的背景雜交,視情況為10倍背景雜交。例示性嚴謹雜交條件可如下:50%甲醯胺,5×SSC和1%SDS,在42℃下培養;或5×SSC,1%SDS,在65℃下培養,在0.2×SSC中洗滌和在65℃下於0.1%SDS中洗滌。所述洗滌可進行5、15、30、60、120min或更長時間。
優選的,本發明從玉米中所分離的鋅鐵調控轉運體ZmZIP1、ZmZIP2、ZmZIP3、ZmZIP7或ZmZIP8基因的cDNA序列分別為SEQ ID No.1、SEQ ID No.3、SEQ ID No.5、SEQ ID No.7或SEQ ID No.9所示的核苷酸序列。
本發明目的之二是提供由上述鋅鐵調控轉運體ZmZIPs基因(ZmZIP1、ZmZIP2、ZmZIP3、ZmZIP7或ZmZIP8)所編碼的能夠吸收、轉運或儲存鋅鐵的蛋白質;
本發明目的之二是通過以下技術方案來實現的:
ZmZIPs基因所編碼的鋅鐵調控轉運體,其胺基酸序列為(a)或(b)所示:
(a)、SEQ ID No.2、SEQ ID No.4、SEQ ID No.6、SEQ ID No.8或SEQ ID No.10所示的胺基酸序列;
(b)、將SEQ ID No.2、SEQ ID No.4、SEQ ID No.6、SEQ ID No.8或SEQ ID No.10所示的胺基酸序列通過一個或多個胺基酸殘基的替換、缺失或/和插入而衍生得到的仍具有鋅鐵調控轉運體功能的蛋白變體。
所述的「多個」通常意味著2-8個,優選為2-4個,這取決於鋅鐵調控轉運體三維結構中胺基酸殘基的位置或胺基酸的種類;所述的「替換」是指分別用不同的胺基酸殘基取代一個或多個胺基酸殘基;所述的「缺失」是指胺基酸殘基數量的減少,也即是分別缺少其中的一個或多個胺基酸殘基;所述的「插入」是指胺基酸殘基序列的改變,相對天然分子而言,所述改變導致添加一個或多個胺基酸殘基。
本發明所述的蛋白變體可由遺傳多態性或人為操作產生,這些操作方法通常為本領域所了解。例如,可通過DNA的突變來製備鋅鐵調控轉運體的胺基酸序列變體或片段,其中由於誘變或改變多核苷酸的方法為本領域所習知。其中,保守的取代是將一種胺基酸殘基替換成具有相似性質的另一種胺基酸。因此,本發明所述的鋅鐵調控轉運體及其編碼基因包括天然存在的序列和變體兩種形式。「變體」意指基本相似的序列,對於多核苷酸,變體包含天然多核苷酸中一個或多個位點處一個或多個核苷酸的缺失、插入或/和替換。對於多核苷酸,保守的變體包括由於遺傳密碼的簡併性而不改變編碼的胺基酸序列的那些變體。諸如此類天然存在的變體可通過現有的分子生物學技術來鑑定。變體多核苷酸還包括合成來源的多核苷酸,例如,採用定點誘變所得到的仍編碼SEQ ID No.2所示的胺基酸的多核苷酸變體,或者是通過重組的方法(例如DNA重排等)。本領域技術人員可通過以下分子生物技術手段來篩選或評價變體多核苷酸所編碼蛋白的功能或活性:DNA結合活性,蛋白之間的相互作用,瞬時研究中基因表達的激活情況或轉基因植物中表達的效應等。
從亞細胞定位結果可知,本發明分離的5個ZmZIPs基因(ZmZIP1、ZmZIP2、ZmZIP3、ZmZIP7或ZmZIP8基因)所編碼的蛋白定位在質膜與細胞內膜上。為進一步確定細胞內膜的具體定位,本發明選用ER marker與5個ZmZIPs基因共定位進行擬南芥葉肉原生質體的轉化,結果證明這5個ZmZIPs基因均定位在細胞質膜及內質網上。在亞細胞定位的基礎上,通過real-timeRT-PCR表達分析發現,正常營養條件下,5個ZmZIPs基因主要在地上部表達,其中,缺鋅條件下,ZmZIP8在96h地上部表達上調,ZmZIP3在6h時地上部和地下部表達量都有所升高;在高鋅條件ZmZIP7和ZmZIP8在地上部的表達量是逐漸降低的,ZmZIP3在地下部的表達量明顯的降低。這些結果表明,ZmZIP3、ZmZIP7和ZmZIP8在幼苗時期對鋅的濃度比較敏感。缺鐵條件下,ZmZIP7和ZmZIP8在地上與地下的表達量是逐漸增高的,說明ZmZIP7和ZmZIP 8對鐵的濃度比較敏感。缺銅、缺錳條件下,5個ZmZIPs基因的表達量都沒有明顯的變化。
酵母互補實驗表明,本發明所分離的5個ZmZIPs不論在低鋅還是在低鐵條件下都表現出不同程度的轉運鋅或鐵活性,說明本發明所分離的5個ZmZIPs均具有轉運鋅鐵的功能。
目前,已知許多轉運蛋白參與了植物體內鋅鐵離子平衡網絡系統,一些蛋白也被應用到植物的轉基因研究中,比如在大麥中過表達AtZIP1基因能夠增加鋅和鐵在種子中的含量(Ramesh SA,Choimes S,Schachtman DP.Over-expression of an Arabidopsis zinc transporter in hordeum vulgare increases short-term zinc uptake after zinc deprivation and seed zinc content.Plant molecular biology 2004,54(3):373-385.),同樣,過表達OsIRT1基因,水稻中鋅和鐵的含量在地上部、地下部和種子中都有所提高(Lee S,An G.Over-expression of OsIRT1 leads to increased iron and zinc accumulations in rice.Plant,cell&environment 2009,32(4):408-416.)。然而,在水稻中過表達OsZIP4、OsZIP5、OsZIP8,OsZIP9結果導致過量的鋅聚集於根部,降低了植株地上部分的鋅含量(Lee S,Kim SA,Lee J,et al.Zinc deficiency-inducible OsZIP8 encodes a plasma membrane-localized zinc transporter in rice.Molecules and cells 2010,29(6):551-558;Lee S,Jeong HJ,Kim SA,et al.OsZIP5 is a plasma membrane zinc transporter in rice.Plant molecular biology 2010,73(4-5):507-517;Ishimaru Y,Masuda H,Suzuki M,et al.Overexpression of the OsZIP4 zinc transporter confers disarrangement of zinc distribution in rice pl ants.Journal of experimental botany 2007,58(11):2909-2915.)沒有達到在籽粒中增加鋅含量的目的,因此,這些基因的過表達對水稻籽粒中鋅的富集是不利的。這些結果表明,異位過表達對於鋅鐵的積累與分布可能會起到一定的作用。然而,有關鋅鐵轉運蛋白在籽粒中的研究還很少。
因此,本發明提供了一種調控植物吸收、轉運或儲存鋅鐵的能力的方法,包括:將本發明ZmZIPs基因可操作的與表達調控元件相連接得到重組植物表達載體;將重組植物表達載體轉化到植物中,在植物體中過表達ZmZIPs基因,能夠有效調控或改善目標植物對鋅鐵的吸收、轉運或儲存的能力。
本發明提供了一種解除過量的鋅鐵對植物體毒害的方法,該方法包括:將本發明ZmZIPs基因可操作的與表達調控元件相連接得到重組植物表達載體;將重組植物表達載體轉化到植物中,在植物體中過表達ZmZIPs基因。
本發明還提供了一種調控或促進植物種子胚發育的方法,該方法包括:將本發明ZmZIPs基因可操作的與表達調控元件相連接得到重組植物表達載體;將重組植物表達載體轉化到植物中,在植物體中過表達ZmZIPs基因;其中,所述的表達調控元件中啟動子優選為種子特異性表達的啟動子。
本發明進一步提供了一種調控或促進種子胚成熟的方法,該方法包括:將本發明ZmZIPs基因可操作的與表達調控元件相連接得到重組植物表達載體;將重組植物表達載體轉化到植物中,在植物體中過表達ZmZIPs基因;其中,所述的表達調控元件中的啟動子優選為種子特異性表達的啟動子。
本發明進一步提供了含有所述鋅鐵調控轉運體ZmZIPs基因的重組植物表達載體以及含有該重組植物表達載體的宿主細胞。
將本發明所述鋅鐵調控轉運體ZmZIPs基因可操作的與表達調控元件相連接,得到可以在植物中表達該鋅鐵調控轉運體基因的重組植物表達載體。「可操作的連接」指兩個或更多個元件之間功能性的連接,可操作的連接的元件可為鄰接或非鄰接的。例如,該重組植物表達載體可以由5′端非編碼區,SEQ ID No.1(或者是SEQ ID No.3、SEQ ID No.5、SEQ ID No.7或SEQ ID No.9中的任一序列)所示的核苷酸和3′非編碼區組成,其中,所述的5′端非編碼區可以包括啟動子序列、增強子序列或/和翻譯增強序列;所述的啟動子可以是組成性啟動子、誘導型啟動子、組織或器官特異性啟動子;所述的3′非編碼區可以包含終止子序列、mRNA切割序列等。合適的終止子序列可取自根癌農桿菌的Ti-質粒,例如章魚鹼合成酶或胭脂鹼合成酶終止區。例如,為了使本發明的鋅鐵調控轉運體基因在糧食作物種子進行特異性表達,可以將鋅鐵調控轉運體基因連接在種子特異性表達啟動子的下方構建得到重組植物表達載體,將該重組植物表達載體轉化受體植物後,鋅鐵調控轉運體基因可以在受體植物的種子裡進行特異性表達,達到促進胚根和胚芽發育、促進胚成熟或增加種子鋅鐵含量或調控胚發育的效果。
另外,本領域技術人員可以將ZmZIPs的核苷酸序列進行優化以增強其在植物中的表達。例如。可採用目標植物的偏愛密碼子進行優化來合成多核苷酸以增強該基因在目標植物中的表達水平,這些方法均為本領域技術人員所習知。
此外,該重組植物表達載體還可含有用於選擇轉化細胞的選擇性標記基因。選擇性標記基因用於選擇經轉化的細胞或組織。所述的選擇性標記基因包括:編碼抗生素抗性的基因以及賦予除草化合物抗性的基因等。此外,所述的標記基因還包括表型標記,例如β-半乳糖苷酶和螢光蛋白等。
所述的「轉化」指將基因導入到植物細胞內部這樣的方式將多核苷酸或多肽遺傳轉化到植物中。將所述多核苷酸或多肽引入到植物中的方法為本領域所習知,包括但不限於穩定轉化法、瞬時轉化法和病毒介導法等。「穩定轉化」指被引入的多核苷酸構建體整合至植物細胞的基因組中並能通過其子代遺傳;「瞬時轉化」指多核苷酸被引入到植物中但只能在植物中暫時性表達或存在。
轉化方案以及將所述多核苷酸引入植物的方案可視用於轉化的植物(單子葉植物或雙子葉植物)或植物細胞的類型而變化。將所述多核苷酸轉化植物細胞的合適方法包括:顯微注射、電穿孔、農桿菌介導的轉化、直接基因轉移以及高速彈道轟擊等。在特定的實施方案中,可利用多種瞬時轉化法將本發明的ZmZIPs基因提供給植物。在其它實施方案中,本發明的ZmZIPs基因可通過將植物與病毒或病毒核酸接觸來引入到植物中,通常,這樣的方法涉及將本發明的ZmZIPs基因構建體引入病毒DNA或RNA分子中。
利用常規方法可使已轉化的細胞再生穩定轉化植株(McCormick et al.Plant Cell Reports.1986.5:81-84)。本發明可用於轉化任何植物種類,包括但不限於:單子葉植物或雙子葉植物;優選的,所述的目標植物包括糧食作物、蔬菜或果樹等,更優選為糧食作物,例如,可以是玉米、水稻、大麥小麥、高粱、大豆、馬鈴薯等糧食作物。
本發明所涉及到的術語定義
除非另外定義,否則本文所用的所有技術及科學術語都具有與本發明所屬領域的普通技術人員通常所了解相同的含義。雖然在本發明的實踐或測試中可使用與本文所述者類似或等效的任何方法、裝置和材料,但現在描述優選方法、裝置和材料。
術語「重組宿主細胞株」或「宿主細胞」意指包含本發明多核苷酸的細胞,而不管使用何種方法進行插入以產生重組宿主細胞,例如直接攝取、轉導、f配對或所屬領域中已知的其它方法。外源性多核苷酸可保持為例如質粒的非整合載體或者可整合入宿主基因組中。宿主細胞可為原核細胞或真核細胞,宿主細胞還可為單子葉或雙子葉植物細胞。
術語「核苷酸」意指單股或雙股形式的脫氧核糖核苷酸、脫氧核糖核苷、核糖核苷或核糖核苷酸及其聚合物。除非特定限制,否則所述術語涵蓋含有天然核苷酸的已知類似物的核酸,所述類似物具有類似於參考核酸的結合特性並以類似於天然產生的核苷酸的方式進行代謝。除非另外特定限制,否則所述術語也意指寡核苷酸類似物,其包括PNA(肽核酸)、在反義技術中所用的DNA類似物(硫代磷酸酯、磷醯胺酸酯等等)。除非另外指定,否則特定核酸序列也隱含地涵蓋其保守修飾的變異體(包括(但不限於)簡併密碼子取代)和互補序列以及明確指定的序列。特定而言,可通過產生其中一個或一個以上所選(或所有)密碼子的第3位經混合鹼基和/或脫氧肌苷殘基取代的序列來實現簡併密碼子取代。
術語「多肽」、「肽」和「蛋白質」在本文中互換使用以意指胺基酸殘基的聚合物。即,針對多肽的描述同樣適用於描述肽和描述蛋白,且反之亦然。所述術語適用於天然產生胺基酸聚合物以及其中一個或一個以上胺基酸殘基為非天然編碼胺基酸的胺基酸聚合物。如本文中所使用,所述術語涵蓋任何長度的胺基酸鏈,其包括全長蛋白(即抗原),其中胺基酸殘基經由共價肽鍵連接。
附圖說明
圖1酵母表達載體pFL61的示意圖。
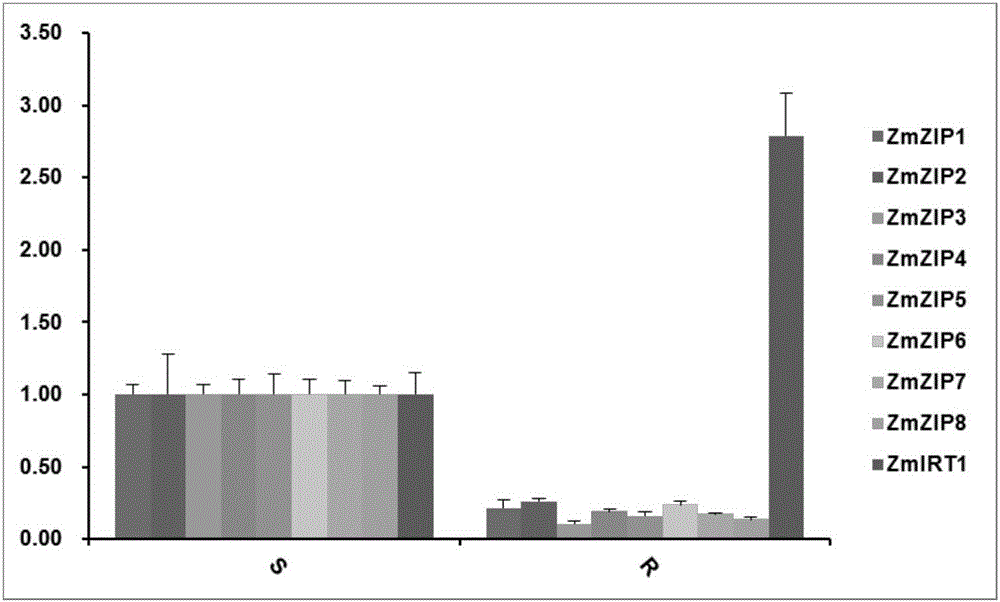
圖2標準Hoagland培養基條件下ZmZIPs的表達模式;S(shoot),R(root)。
圖3 ZmZIPs基因在各種處理條件下的表達模式。
圖4 ZmZIPs基因在玉米胚和胚乳發育過程中的表達模式。
圖5 pRTL2NGFP-ZmZIPs重組載體酶切鑑定;M為1Kb的Marker;1-5分別為pRTL2NGFP-ZmZIP1、ZmZIP2、ZmZIP3、ZmZIP7、ZmZIP8雙酶切的結果
圖6 ZmZIPs洋蔥表皮細胞中的亞細胞定位;GFP為pRTL2NGFP空載體定位情況;ZmZIP1、ZmZIP2、ZmZIP3、ZmZIP7、ZmZIP8為pRTL2NGFP-ZmZIP1、2、3、7、8的亞細胞定位情況。
圖7 ZmZIPs擬南芥葉肉原生質體中的亞細胞定位;GFP為pRTL2NGFP空載體定位情況;GFP為pRTL2NGFP空載體定位情況;ZmZIP1、ZmZIP2、ZmZIP3、ZmZIP7、ZmZIP8分別為pRTL2NGFP-ZmZIP1、2、3、7、8的亞細胞定位情況。
圖8 pFL61-ZmZIPs及pFL61-OsZIP5、pFL61-OsZIP8、pFL61-OsIRT1正向連接重組載體酶切鑑定;M為1Kb的Marker;1-8依次為pFL61-ZmZIP1、pFL61-ZmZIP2、pFL61-ZmZIP3、pFL61-ZmZIP7、pFL61-ZmZIP8、pFL61-OsZIP5、pFL61-OsZIP8、pFL61-OsIRT1雙酶切結果。
圖9 ZmZIPs酵母互補實驗結果。
圖10 ZmZIP1、ZmZIP2、ZmZIP3、ZmZIP7和ZmZIP8的植物表達載體示意圖。
圖11 ZmZIPs基因在擬南芥中過表達提高擬南芥中鋅含量的實驗結果;ZmZIP2為轉ZmZIP2基因在擬南芥中過表達提高擬南芥中鐵或鋅含量的實驗結果;ZmZIP3為轉ZmZIP3基因在擬南芥中過表達提高擬南芥中鐵或鋅含量的實驗結果;ZmZIP7為轉ZmZIP7基因在擬南芥中過表達提高擬南芥中鐵或鋅含量的實驗結果;ZmZIP8為轉ZmZIP8基因在擬南芥中過表達提高擬南芥中鐵或鋅含量的實驗結果;WT為野生型哥倫比亞種子中鐵和鋅含量測定的結果。
具體實施方式
下面結合具體實施例來進一步描述本發明,本發明的優點和特點將會隨著描述而更為清楚。但這些實施例僅是範例性的,並不對本發明的範圍構成任何限制。本領域技術人員應該理解的是,在不偏離本發明的精神和範圍下可以對本發明技術方案的細節和形式進行修改或替換,但這些修改和替換均落入本發明的保護範圍內。
實驗材料
1.1植物材料
玉米自交系X178由河北農業大學農學院/國家玉米改良中心河北分中心實驗室提供,水稻自交系日本晴由北京師範大學生命科學院惠贈。
1.2菌株與載體
大腸桿菌(E.coli)菌株Mach1-T1和農桿菌(A.tumefacterium)菌株EHA105、GV3101均由本實驗室保存。pGEM-Teasy載體購自Promega公司。酵母表達載體pFL61(示意圖見圖1)、酵母菌株zrt1zrt2 ZHY3(MATαade6 can1 his3 leu2 trp1 ura3 zrt1::LEU2 zrt2::HIS3),fet3fet4 DEY1453(MATa/MATa ade2/+can1/can1 his3/his3 leu2/leu2 trp1/trp1 ura3/ura3 fet3-2::HIS3/fet3-2::HIS3fet4-1::LEU2/fet4-1::LEU2),DY1455(MATa ade6 can1 his3 leu2 trp1 ura3)由南京農業大學張紅生教授友情惠贈。
實施例1玉米鋅鐵調控轉運體ZmZIPs基因的克隆
1、植物材料的處理
先把蛭石用Hoagland營養液浸透,將玉米自交系X178種子點播於育苗盤中,上面覆蓋上一層幹蛭石,在溫室(16h光照/8h黑暗,26℃)中培養,12天幼苗長至2葉一心時移入標準Hoagland營養液中生長6天至3葉一心(每3天換一次營養液),3葉一心的玉米幼苗在標準營養液和不加鋅、鐵、銅、錳、高鋅、鐵的條件下處理0、6、12、24、48、96h後,分別收取幼苗地上部和根,液氮速凍後於-80℃保存用於總RNA提取。
2、玉米總RNA的提取
採用Trizol法提取玉米總RNA。
3、cDNA的合成
(1)去除DNA,按下述配製反應體系:總RNA(1μg/μL)1.0μL,DNAse I(10U/μL)
1.0μL,10×DNAse I buffer 1.0μL,DEPC H2O 7.0μL,總計10.0μL;37℃30min,加入1μL 25mM EDTA,65℃5min終止反應。
(2)、加入1μL oligo(dT18),65℃5min;
(3)、以上共12μL,再加入以下組分得到反轉錄體系:5×反應緩衝液4.0μL,Ri RT(20U/μL)
1.0μL,Re RT(200U/μL)1.0μL,10mM dNTP mix 2.0μL,總計:20.0μL;42℃60min,70℃5min,終止反應。
4、目的基因的克隆
(1)、根據目的基因的ORF框設計引物:
ZmZIP1F 5'-GCGGCCGCATGCGCCGCCAAAGCCT-3'NotI
ZmZIP1R 5'-GCGGCCGCTTATTCTACCAGAGAAATGCCTAGAGCG-3'NotI
ZmZIP2F 5'-TACGTAATGGCCCGCGCCAC-3'SnaBI
ZmZIP2R 5'-TACGTATCAGGTGTCCCATATCATGACG-3'SnaBI
ZmZIP3F 5'-CCCGGGATGGGAGCTGTGAAGCATACATTG-3'SmaI
ZmZIP3R 5'-GGTACCCTATGCCCATATAGCAAGCATGGAC-3'KpnI
ZmZIP7F 5'-TCTAGAATGGTTCTCGCCGGCCTC-3'XbaI
ZmZIP7R 5'-GAGCTCTCAAGCCCATATTGCAAGTGATGACATAG-3'SacI
ZmZIP8F 5'-CCCGGGATGGCCATGAGGCCACG-3'SmaI
ZmZIP8R 5'-GAGCTCCTAGGCCCACTTGGCCAGC-3'SacI
以上述步驟3的cDNA為模板,選用ExTaq酶,2×GCI buffer進行PCR擴增,PCR程序為:95℃預變性4min;94℃變性1min,60℃退火1min,72℃延伸1min,33個循環;72℃延伸10min;
(2)、將克隆得到的片段克隆到pGEM-T載體中,轉化Mach1-T1菌株;
(3)、經酶切鑑定獲得陽性的重組質粒,測序得到正確克隆,所克隆的第1個基因命名為ZmZIP1,該基因的cDNA序列為SEQ ID No.1所示,所推導的胺基酸序列為SEQ ID No.2所示;所克隆的第2個基因命名為ZmZIP2,該基因的cDNA序列為SEQ ID No.3所示,所推導的胺基酸序列為SEQ ID No.4所示;所克隆的第3個基因命名為ZmZIP3,該基因的cDNA序列為SEQ ID No.5所示,所推導的胺基酸序列為SEQ ID No.6所示;所克隆的第4個基因命名為ZmZIP7,該基因的cDNA序列為SEQ ID No.7所示,所推導的胺基酸序列為SEQ ID No.8所示;所克隆的第5個基因命名為ZmZIP8,該基因的cDNA序列為SEQ ID No.9所示,所推導的胺基酸序列為SEQ ID No.10所示。
實施例2 ZmZIPs在幼苗、胚和胚乳中的表達模式
將實施例1步驟3中反轉錄的cDNA稀釋10倍作為PCR反應的模板,PCR反應體系如下:
cDNA 2.0μL,ExTaq 0.1μL,2×GCI緩衝液10.0μL,10mM dNTP mix 0.8μL,上遊引物RTZmZIP1F/RTZmZIP2F/RTZmZIP3F/RTZmZIP7F/RTZmZIP8F(10μM/μL)1.0μL,下遊引物RTZmZIP1R/RTZmZIP2R/RTZmZIP3R/RTZmZIP7R/RTZmZIP8R(10μM/μL)1.0μL,ddH2O 5.1μL,總計20.0μL;
RTZmZIP1F 5'-CCTCTCTGCGTTGGTTGCTCT-3'
RTZmZIP1R 5'-TTGATGGTTGTTTTCTGGTCGT-3'
RTZmZIP2F 5'-CCACAAATGGCACGAGGTCT-3'
RTZmZIP2R 5'-CGAAGACGGAGTGGAAGCAAA-3'
RTZmZIP3F 5'-GCCTCTTGTTGGTGCCCTTA-3'
RTZmZIP3R 5'-TCAACAATGAACGCTGTAGTGCT-3'
RTZmZIP7F 5'-ACTAGGTGGGTGCATTGCTCAG-3'
RTZmZIP7R 5'-TGCCAGCAGATACCGAGTCAA-3'
RTZmZIP8F 5'-CGTGTCATCGCTCAGGTTCTTG-3'
RTZmZIP8R 5'-CCCTCGAACATTTGGTGGAAG-3'
PCR反應條件:94℃預變性4min;30個循環,每個循環94℃變性45秒,60℃退火1min,72℃延伸1min;最後再延伸72℃10min,降溫至16℃,取出PCR產物放入4℃保存。
目的基因表達量的檢測:實施例1步驟3中反轉錄的cDNA稀釋20倍作為Real-time PCR反應的模板,Actin為內參照,反應體系如下:cDNA 5.0μL,SYBR Green I 10.0μL,Rox0.4μL,上遊引物ZmActin1F(10μM/μL)0.4μL,下遊引物ZmActin1R(10μM/μL)0.4μL,ddH2O3.8μL,總計10.0μL;
ZmActin1F 5'-ATGTTTCCTGGGATTGCCGAT-3'
ZmActin1R 5'-CCAGTTTCGTCATACTCTCCCTTG-3'
所用程序:95℃2min,95℃15sec,60℃34sec,40個循環,通過ΔΔCt法計算表達量。
通過real-time RT-PCR表達分析發現,正常營養條件下,5個ZmZIPs基因主要在地上部表達,其中,缺鋅條件下,ZmZIP8在96h地上部表達上調,ZmZIP3在6h時地上部和地下部表達量都有所升高;在高鋅條件ZmZIP7和ZmZIP8在地上部的表達量是逐漸降低的,ZmZIP3在地下部的表達量明顯的降低。這些結果表明,ZmZIP3、ZmZIP7和ZmZIP8在幼苗時期對鋅的濃度比較敏感。缺鐵條件下,ZmZIP7和ZmZIP8在地上與地下的表達量是逐漸增高的,說明ZmZIP7和ZmZIP8對鐵的濃度比較敏感。缺銅、缺錳條件下,5個ZmZIPs基因的表達量都沒有明顯的變化。5個ZmZIPs基因可能參與胚和胚乳的發育(圖2、圖3和圖4)。
實施例3 ZmZIPs的生物信息學分析
ZmZIPs由367-483個胺基酸組成,含有6-9個跨膜結構域,在第3與第4跨膜區之間有一富含組氨酸的可變區,可能和金屬離子的結合轉運有關。進化樹分析顯示,ZmZIP1與AtIAR1、OsIAR1進化關係較近。另外,ZmZIP3和ZmZIP4與OsZIP3和OsZIP4形成一個基因簇,ZmZIP2與OsZIP2鄰近,和鋅轉運體OsZIP1,AtZIP2和AtZIP11在一個分支上,ZmZIP5與ZmZIP7在一個分支上,ZmZIP8與OsZIP8,ZmZIP6與OsZIP6進化關係較近,這些結果顯示,本發明所分離的5個ZmZIPs可能是鋅鐵轉運體。
實施例4 ZmZIPs的亞細胞定位
1、融合表達載體的構建
根據ZmZIPs基因的序列設計引物,引物序列如下:
ZmZIP1GF 5'-GAATTCATGCGCCGCCAAAGCCT-3'EcoRI
ZmZIP1GR 5'-TCTAGATTCTACCAGAGAAATGCCTAGAGCG-3'XbaI
ZmZIP2GF 5'-GAATTCATGGCCCGCGCCACCAA-3'EcoRI
ZmZIP2GR 5'-TCTAGAGGTGTCCCATATCATGACGACGG-3'XbaI
ZmZIP3GF5'-GAATTCATGGGAGCTGTGAAGCATAC-3'EcoRI
ZmZIP3GR5'-TCTAGATGCCCATATAGCAAGCATGGACAT-3'XbaI
ZmZIP7GF 5'-GAATTCATGGTTCTCGCCGGCCTC-3'EcoRI
ZmZIP7GR 5'-TCTAGAAGCCCATATTGCAAGTGATGACATAG-3'XbaI
ZmZIP8GF 5'-GAATTCATGGCCATGAGGCCACGC-3'EcoRI
ZmZIP8GR 5'-TCTAGAGGCCCACTTGGCCAGCAT-3'XbaI
加入合適的酶切位點,並且基因3』端去除終止密碼子,以克隆基因時連接到pGEM-T載體上測序正確的質粒為模板,選用ExTaq酶與2×GCI buffer進行PCR擴增,PCR程序為:95℃預變性4min;94℃變性1min,60℃退火1min,72℃延伸1min,33個循環;72℃延伸10min。擴增片段經1%瓊脂糖凝膠電泳回收後克隆到pGEM-T載體中,轉化大腸桿菌菌株Mach1-T1,經LB培養基(IPTG、X-gal、Amp)得到陽性克隆,提質粒、酶切和測序驗證;以克隆基因時連接到pGEM-T載體上測序正確的質粒為模板,選用ExTaq酶與2×GCI buffer進行PCR擴增,擴增片段經1%瓊脂糖凝膠電泳回收後克隆到pGEM-T載體中,測序正確的質粒酶切後,將目的片段構建到pRTL2NGFP載體上,分別命名為pRTL2NGFP-ZmZIP1、pRTL2NGFP-ZmZIP2、pRTL2NGFP-ZmZIP3、pRTL2NGFP-ZmZIP7、pRTL2NGFP-ZmZIP8,圖5為酶切鑑定圖。
2、用相應的酶切pRTL2NGFP載體與不同的酶切後的基因片段,經T4DNA連接酶連接,轉化Mach1-T1菌株,提質粒酶切鑑定篩選出正確重組體大提質粒用於基因槍轉化洋蔥表皮。
3、基因槍微彈的製備
4、用基因槍進行洋蔥表皮轉化
從定位結果可知5個ZmZIPs(ZmZIP1、ZmZIP2、ZmZIP3、ZmZIP7或ZmZIP8)均定位在質膜與細胞內膜上(圖6)。為進一步確定細胞內膜的具體定位,選用ER marker與ZmZIPs共定位進行擬南芥葉肉原生質體的轉化,結果證明5個ZmZIPs均定位在細胞質膜及內質網上(圖7)。
實施例五酵母互補實驗
1、酵母表達載體的構建
根據目的基因序列加入合適的酶切位點設計引物:
ZmZIP1YF 5'-GCGGCCGCATGCGCCGCCAAAGCCT-3'NotI
ZmZIP1YR 5'-GCGGCCGCTTATTCTACCAGAGAAATGCCTAGAGCG-3'NotI
ZmZIP2YF 5'-TACGTAATGGCCCGCGCCAC-3'SnaBI
ZmZIP2YR 5'-TACGTATCAGGTGTCCCATATCATGACG-3'SnaBI
ZmZIP3YF5'-CCCGGGATGGGAGCTGTGAAGCATACATTG-3'SmaI
ZmZIP3YR5'-GGTACCCTATGCCCATATAGCAAGCATGGAC-3'KpnI
ZmZIP7YF 5'-TACGTAATGGTTCTCGCCGGCCTC-3'SnaBI
ZmZIP7YR 5'-TACGTATCAAGCCCATATTGCAAGTGATGACATAG-3'SnaBI
ZmZIP8YF 5'-TGCCATGGCCATGAGGCCAC-3'
ZmZIP8YR 5'-CTAGGCCCACTTGGCCAGCATG-3'
OsZIP5YF5'-CCCGGGGAGCCATCGGCGATGGCGA-3'SmaI
OsZIP5YR5'-GAGCTCGTGATGGTCACTCACTCATCACGCC-3'SacI
OsZIP8YF 5'-GCGGCCGCATGAGGACGAACACCACC-3'NotI
OsZIP8YR 5'-GCGGCCGCCCTCTACATTAGTCCCTGAG-3'NotI
OsIRT1YF 5'-GCGGCCGCCCCGGGATGGCGACGCCGCGGA-3'NotI,SmaI
OsIRT1YR 5'-GCGGCCGCCCCGGGTCACGCCCACTTGGCCATG-3'NotI,SmaI
以克隆基因時連接到pGEM-T載體上測序正確的質粒為模板,選用ExTaq與2×GCI buffer進行PCR擴增,PCR程序為:95℃預變性4min;94℃變性1min,60℃退火1min,72℃延伸1min,33個循環;72℃延伸10min。擴增片段經1%瓊脂糖凝膠電泳回收後克隆到pGEM-T載體中,轉化大腸桿菌菌株Mach1-T1,經LB培養基(IPTG、X-gal、Amp)得到陽性克隆,提質粒、酶切和測序驗證,測序正確的質粒酶切後,將目的片段構建到pFL61載體上,命名為pFL61-ZmZIP1、pFL61-ZmZIP2、pFL61-ZmZIP3、pFL61-ZmZIP7、pFL61-ZmZIP8及pFL61-OsZIP5、pFL61-OsZIP8和pFL61-OsIRT1,圖8為酶切鑑定圖。
用NotI酶切pFL61載體與酶切後的ZmZIPs片段經T4DNA連接酶連接,轉化Mach1-T1菌株,提質粒酶切鑑定篩選出正確重組體大提質粒用於轉化釀酒酵母。
2、電擊轉化法轉化酵母
(1)、從YPD平板上挑取zrt1zrt2ZHY3、fet3fet4DEY1453和DY1455的單菌落於20mL的YPD液體培養基中,28℃搖床培養約24h;
(2)、吸取以上2%體積的菌液轉接到100mL的YPD培養基中繼續擴繁約4-5h,待菌液OD600為1.2-1.5時即可製備感受態;
(3)、將菌液收集到50mL的離心管中,4℃,5,000rpm,離心5min,倒掉上清;
(4)、加入等體積的去離子水,冰上重懸菌體,4℃,5,000rpm,5min離心,倒掉上清;
(5)、加入1/2體積的去離子水,冰上重懸菌體,4℃,5,000rpm,5min離心,倒掉上清;
(6)、加入10mL的1M山梨醇溶液,冰上重懸菌體,4℃,5,000rpm,5min離心,倒掉上清;
(7)、加入450-600μL的山梨醇溶液,用去頭的槍頭輕吸,重懸菌體;
(8)、按照每個1.5mL的離心管裡加入約100μL的感受態為準,分裝;
(9)、在每管感受態中加入適量的DNA(10μL左右,c≥200ng/μL),冰上放置1-2min,之後吸到預冷的電擊杯中,不要有氣泡;
(10)、電擊轉化,立即加入約800μL,1M的預冷的山梨醇溶液,重懸菌體;
(11)、從電擊杯中吸出菌體,塗布SD/Ura-平板;
(12)、SD平板上28℃培養約6天可長出肉眼可見的菌斑。
3、酵母陽性克隆的鑑定
(1)、取1.5mL酵母培養物,9,000rpm離心30秒,儘可能的吸棄上清,收集酵母細胞;
(2)、加入600μL Sorbitol buffer,輕柔吹打充分重懸細胞,加入80U的Lyticase,充分顛倒混勻,37℃溫育30min消化細胞壁,中間顛倒數次;
(3)、13,000rpm離心1min,儘可能吸棄上清,加入250μL溶液YP1重懸菌體沉澱,渦旋震蕩至徹底懸浮;
(4)、加入250μL YP2溶液,輕柔地翻轉,使菌體充分裂解,室溫放置4min;
(5)、加入350μL YP3溶液,輕柔地翻轉,充分混勻時會出現白色絮狀沉澱,冰上靜置3-5min,13,000rpm離心5min,小心吸取上清液。
(6)、將上一步所得上清液加入吸附柱AC中(吸附柱放入收集管中),12,000rpm離心30-60秒,倒掉收集管中的廢液;
(7)、加入500μL去蛋白液PD,12,000rpm離心30-60秒,棄廢液;
(8)、加入500μL漂洗液WB(已加無水乙醇),12,000rpm離心30-60秒,棄廢液;
(9)、加入500μL漂洗液WB,12,000rpm離心30-60秒,棄廢液;
(10)、將吸附柱AC放回空收集管中,13,000rpm離心2min,除去漂洗液;
(11)、取出吸附柱AC,放入一個乾淨的離心管中,在吸附膜的中間部位加50μL洗脫緩衝液EB(65-70℃水浴),室溫放置2min,13,000rpm離心1min。
(12)、以抽提的1μL DNA為模板,基因的兩端引物為PCR擴增引物,進行PCR擴增驗證目的基因,驗證正確的菌液,加入25%的甘油於-80℃保存。
4、酵母互補實驗結果
將pFL61、pFL61-ZmZIP1、pFL61-ZmZIP2、pFL61-ZmZIP3、pFL61-ZmZIP7、pFL61-ZmZIP8、pFL61-OsZIP5、pFL61-OsZIP8、pFL61-OsIRT1質粒分別轉化到酵母突變株zrt1zrt2ZHY3和fet3fet4DEY1453中,pFL61為陰性對照,OsZIP5、OsZIP8(Lee S,Kim SA,Lee J,et al.Zinc deficiency-inducible OsZIP8 encodes a plasma membrane-localized zinc transporter in rice.Molecules and cells 2010,29(6):551-558;Lee S,Jeong HJ,Kim SA,et al.OsZIP5 is a plasma membrane zinc transporter in rice.Plant molecular biology 2010,73(4-5):507-517;Ishimaru Y,Masuda H,Suzuki M,et al.Overexpression of the OsZIP4 zinc transporter confers disarrangement of zinc distribution in rice plants.Journal of experimental botany 2007,58(11):2909-2915.)為鋅轉運體的陽性對照,OsIRT1(Lee S,An G.Over-expression of OsIRT1 leads to increased iron and zinc accumulations in rice.Plant,cell&environment 2009,32(4):408-416.)為鐵轉運體的陽性對照,pFL61轉化野生型菌株DY1455作為另一陽性對照,轉化後鑑定為陽性的酵母菌在SD液體培養基中培養,酵母菌液分別稀釋4個濃度(OD600=1、0.1、0.01、0.001),然後取5μL點在低鋅、低鐵和正常SD的培養基中,低鋅培養基(SD培養基加入0.4mM EDTA、0.4mM EDTA和250μM ZnSO4、0.4mM EDTA和300μM ZnSO4),低鐵培養基(SD培養基加入50mM MES、50mM MES和50μM FeCl3、50mM MES和100μM FeCl3)酵母互補參照Lin,Y.F的試驗(Lin YF,Liang HM,Yang SY,et al.Arabidopsis IRT3 is a zinc-regulated and plasma membrane localized zinc/iron transporter.The New phytologist 2009,182(2):392-404.)方法進行,28℃培養,6天觀察試驗結果。
實驗結果顯示,在低鋅條件下,加有250μM ZnSO4的培養基中能明顯觀察到DY-pFL61(野生型)、Z-ZmZIP1、Z-ZmZIP2、Z-ZmZIP3、Z-ZmZIP7、Z-ZmZIP8、Z-OsZIP5、Z-OsZIP8、Z-OsIRT1比空載體Z-pFL61長勢好,並且,Z-ZmZIP1、Z-ZmZIP2、Z-ZmZIP3、Z-ZmZIP7、Z-ZmZIP8與已經報導的水稻OsZIP長勢相當。在低鐵條件下,D-ZmZIP1、D-ZmZIP2、D-ZmZIP3、D-ZmZIP7、D-ZmZIP8比空載體D-pFL61長勢好,但是沒有已經報導的D-OsIRT1的轉運活性強(圖9);ZmZIP1、ZmZIP2、ZmZIP3、ZmZIP7或ZmZIP8不論在低鋅還是在低鐵條件下都表現出不同程度的轉運活性,說明ZmZIP1、ZmZIP2、ZmZIP3、ZmZIP7或ZmZIP8具有轉運鋅鐵的功能。
實驗例1 ZmZIPs基因在擬南芥中過表達提高擬南芥種子中鐵和鋅含量的實驗
將ZmZIP1、ZmZIP2、ZmZIP3、ZmZIP7以及ZmZIP8基因分別與組成型35S啟動子控制的植物表達載體pBI121相連接構建得到ZmZIP1、ZmZIP2、ZmZIP3、ZmZIP7和ZmZIP8基因重組植物表達載體(圖10);將構建的重組植物表達載體分別轉化到擬南芥中,鑑定獲得陽性的轉ZmZIP1、ZmZIP2、ZmZIP3、ZmZIP7和ZmZIP8基因擬南芥;將陽性的轉ZmZIPs基因擬南芥與野生型哥倫比亞在相同的載培條件下培養,收穫轉ZmZIPs基因擬南芥種子和野生型種子,分別測定轉ZmZIPs基因擬南芥種子和野生型擬南芥種子中鐵或鋅的含量;稱取一定量的種子材料經微波消解,定容,用ICP-MS方法進行鋅鐵含量的測定;每批測定200mg種子,測定三批,取三批數據的平均值。測定結果見圖11。從圖11的結果可見,在擬南芥中過表達ZmZIP1、ZmZIP2、ZmZIP3、ZmZIP7或ZmZIP8基因均能夠不同程度的提高種子中鐵或鋅含量。
河北農業大學
玉米鋅鐵調控轉運體ZmZIP3基因及其應用
XLB--0030
10
PatentIn version 3.5
1
1473
DNA
Zea mays
1
atgcgccgcc aaagcctcgc caccgtactg ctgctcctgg tggccgccgc ggccctggcc 60
gcccccgccg ctgggcactc tgagtcctcc tgccccttct acgaccacgg cggccacggc 120
gaaccacacg aacgccacga ccatggccac agctgcggcg gcggcgcgga ccatgagcac 180
caccatcacc atcaccacgg ccatggacac ggcgagatcc agcggctgct cccggaggag 240
atggcggagg aggcggatct cgagctcgag tccttcggtt acgaagacca tgaccatgac 300
cacggccacc accaccacca ccaccatcac cacagccacg gcgacatgga gacatcgccc 360
atgggcgtgt ggctgagcgc gatggggtgc tcgctgctgg tcagtatggc gtcccttgtc 420
tgcctcgtcc tcttgccggt catcttcttt aaggggaaac cgtctaaggc catagtggat 480
tcgcttgcag tgtttggggc aggagctatg cttggagatt catttcttca tcagctgcca 540
catgcttttg gtggaggaca ttctcactcg catgatcatg agggtcatga tcatgctcat 600
gctcatgagc atgcacatgc acactcactg caagatctat ctgtgggttt gtctgtacta 660
tttggcattg tactgttttt tattgtcgag aagattgtga ggtatgttga agacaattct 720
caaaatgggg ctcatagcat gggtcatggg caccatcatc ataatcataa acggcacgat 780
tctagcgata aagccaaatt gaattaccaa aagagtgata ctgatggtaa agacattgat 840
catgctgaag aggaaccttc ggttaatgat accactggaa aaataagtga tggccatgaa 900
tcagaagcta ctatacgcaa gaggagctca tccaaagcca ctgatggaga agccaccaat 960
tctggaaggg atcctgcccc tgaaaaagca ccatcaaatg aaggttcatc aatttcaaac 1020
tctaacttag tgtttggcta cctcaacctt ttctcagatg gtgttcataa cttcactgat 1080
gggatggctc ttgggagtgc ctttctgctg catggtcctg ttggtggctg gtctaggact 1140
ttatttctgc ttgcacatga acttccccaa gaggtaggag attttggtat ccttgtgcgg 1200
tcaggcttca cggtatctaa ggccttattc ttcaatttcc tctctgcgtt ggttgctctt 1260
gctggaacag cactagcatt gtctttgggt aaagatccgg gacattcctc cctgattgag 1320
ggtttcaccg ccggtggttt catttacatt gctgtcgcgg gagtcctacc acagatgaac 1380
gaccagaaaa caaccatcaa gagctcagta gctcagctga tctccctggc aatggggatg 1440
ctggtcgctc taggcatttc tctggtagaa taa 1473
2
490
PRT
Zea mays
2
Met Arg Arg Gln Ser Leu Ala Thr Val Leu Leu Leu Leu Val Ala Ala
1 5 10 15
Ala Ala Leu Ala Ala Pro Ala Ala Gly His Ser Glu Ser Ser Cys Pro
20 25 30
Phe Tyr Asp His Gly Gly His Gly Glu Pro His Glu Arg His Asp His
35 40 45
Gly His Ser Cys Gly Gly Gly Ala Asp His Glu His His His His His
50 55 60
His His Gly His Gly His Gly Glu Ile Gln Arg Leu Leu Pro Glu Glu
65 70 75 80
Met Ala Glu Glu Ala Asp Leu Glu Leu Glu Ser Phe Gly Tyr Glu Asp
85 90 95
His Asp His Asp His Gly His His His His His His His His His Ser
100 105 110
His Gly Asp Met Glu Thr Ser Pro Met Gly Val Trp Leu Ser Ala Met
115 120 125
Gly Cys Ser Leu Leu Val Ser Met Ala Ser Leu Val Cys Leu Val Leu
130 135 140
Leu Pro Val Ile Phe Phe Lys Gly Lys Pro Ser Lys Ala Ile Val Asp
145 150 155 160
Ser Leu Ala Val Phe Gly Ala Gly Ala Met Leu Gly Asp Ser Phe Leu
165 170 175
His Gln Leu Pro His Ala Phe Gly Gly Gly His Ser His Ser His Asp
180 185 190
His Glu Gly His Asp His Ala His Ala His Glu His Ala His Ala His
195 200 205
Ser Leu Gln Asp Leu Ser Val Gly Leu Ser Val Leu Phe Gly Ile Val
210 215 220
Leu Phe Phe Ile Val Glu Lys Ile Val Arg Tyr Val Glu Asp Asn Ser
225 230 235 240
Gln Asn Gly Ala His Ser Met Gly His Gly His His His His Asn His
245 250 255
Lys Arg His Asp Ser Ser Asp Lys Ala Lys Leu Asn Tyr Gln Lys Ser
260 265 270
Asp Thr Asp Gly Lys Asp Ile Asp His Ala Glu Glu Glu Pro Ser Val
275 280 285
Asn Asp Thr Thr Gly Lys Ile Ser Asp Gly His Glu Ser Glu Ala Thr
290 295 300
Ile Arg Lys Arg Ser Ser Ser Lys Ala Thr Asp Gly Glu Ala Thr Asn
305 310 315 320
Ser Gly Arg Asp Pro Ala Pro Glu Lys Ala Pro Ser Asn Glu Gly Ser
325 330 335
Ser Ile Ser Asn Ser Asn Leu Val Phe Gly Tyr Leu Asn Leu Phe Ser
340 345 350
Asp Gly Val His Asn Phe Thr Asp Gly Met Ala Leu Gly Ser Ala Phe
355 360 365
Leu Leu His Gly Pro Val Gly Gly Trp Ser Arg Thr Leu Phe Leu Leu
370 375 380
Ala His Glu Leu Pro Gln Glu Val Gly Asp Phe Gly Ile Leu Val Arg
385 390 395 400
Ser Gly Phe Thr Val Ser Lys Ala Leu Phe Phe Asn Phe Leu Ser Ala
405 410 415
Leu Val Ala Leu Ala Gly Thr Ala Leu Ala Leu Ser Leu Gly Lys Asp
420 425 430
Pro Gly His Ser Ser Leu Ile Glu Gly Phe Thr Ala Gly Gly Phe Ile
435 440 445
Tyr Ile Ala Val Ala Gly Val Leu Pro Gln Met Asn Asp Gln Lys Thr
450 455 460
Thr Ile Lys Ser Ser Val Ala Gln Leu Ile Ser Leu Ala Met Gly Met
465 470 475 480
Leu Val Ala Leu Gly Ile Ser Leu Val Glu
485 490
3
1080
DNA
Zea mays
3
atggcccgcg ccaccaacgc ccaccaccac cgcctccgcc tcctcctctg cctctccctc 60
gcggccgccg cgtgggcgca cggcggaggc ggggactccg acgccgacgc cgacgcggat 120
gggggcgccg ccgccaggcc ggacctgcgc gcgcgcagcc tggtggaggc caagctgtgg 180
tgcctggcgg tggtgttcgt cggcacgctg ctgggcgggg tgtcccccta cttcatgcgc 240
tggaacgagg cgttcctcgc gctgggcacg cagttcgcgg gcggcgtctt cctcggcacg 300
gcgctcatgc acttcctcag cgacgccaac gagacgttcg gggacctgct ccccgacagc 360
gggtacccct gggcgttcat gctcgcctgc gccggttacg tcgtcaccat gctcgccgac 420
gtcgccatct cctacgtcgt ctcacggtca caggggcgca gcaccggcac cgccgctacc 480
ggcggttctg atgcagggct ggaggagggc aagatgagaa ccacaaatgg cacgaggtct 540
gagcccacac cagctgatgc acacggatct gatcactcgg ccgcatccat tctgcgcaac 600
gcgagcacga tcggtgacag cgtgctgctc atagtagccc tttgcttcca ctccgtcttc 660
gagggcatcg ccatcgggat cgccgagacc aaggccgacg catggaaggc gctgtggacc 720
ataagcctgc acaagatctt cgcggccatc gccatgggca tcgcgctgct ccggatgctg 780
cccaaccggc ccctcctctc ctgcttcgcc tacgccttcg cgttcgccat ctccagcccc 840
gtcggcgtcg gcatcggcat catcatcgat gccaccacgc agggccgggt ggccgactgg 900
atcttcgccg tctccatggg cctcgccacg ggcatcttcg tctacgtctc catcaaccac 960
ctcctctcca aagggtaccg gccccagagg cccgtcgccg tcgacacgcc ggtcgggagg 1020
tggctcgccg tcgtgttcgg cgtggctgtc atcgccgtcg tcatgatatg ggacacctga 1080
4
359
PRT
Zea mays
4
Met Ala Arg Ala Thr Asn Ala His His His Arg Leu Arg Leu Leu Leu
1 5 10 15
Cys Leu Ser Leu Ala Ala Ala Ala Trp Ala His Gly Gly Gly Gly Asp
20 25 30
Ser Asp Ala Asp Ala Asp Ala Asp Gly Gly Ala Ala Ala Arg Pro Asp
35 40 45
Leu Arg Ala Arg Ser Leu Val Glu Ala Lys Leu Trp Cys Leu Ala Val
50 55 60
Val Phe Val Gly Thr Leu Leu Gly Gly Val Ser Pro Tyr Phe Met Arg
65 70 75 80
Trp Asn Glu Ala Phe Leu Ala Leu Gly Thr Gln Phe Ala Gly Gly Val
85 90 95
Phe Leu Gly Thr Ala Leu Met His Phe Leu Ser Asp Ala Asn Glu Thr
100 105 110
Phe Gly Asp Leu Leu Pro Asp Ser Gly Tyr Pro Trp Ala Phe Met Leu
115 120 125
Ala Cys Ala Gly Tyr Val Val Thr Met Leu Ala Asp Val Ala Ile Ser
130 135 140
Tyr Val Val Ser Arg Ser Gln Gly Arg Ser Thr Gly Thr Ala Ala Thr
145 150 155 160
Gly Gly Ser Asp Ala Gly Leu Glu Glu Gly Lys Met Arg Thr Thr Asn
165 170 175
Gly Thr Arg Ser Glu Pro Thr Pro Ala Asp Ala His Gly Ser Asp His
180 185 190
Ser Ala Ala Ser Ile Leu Arg Asn Ala Ser Thr Ile Gly Asp Ser Val
195 200 205
Leu Leu Ile Val Ala Leu Cys Phe His Ser Val Phe Glu Gly Ile Ala
210 215 220
Ile Gly Ile Ala Glu Thr Lys Ala Asp Ala Trp Lys Ala Leu Trp Thr
225 230 235 240
Ile Ser Leu His Lys Ile Phe Ala Ala Ile Ala Met Gly Ile Ala Leu
245 250 255
Leu Arg Met Leu Pro Asn Arg Pro Leu Leu Ser Cys Phe Ala Tyr Ala
260 265 270
Phe Ala Phe Ala Ile Ser Ser Pro Val Gly Val Gly Ile Gly Ile Ile
275 280 285
Ile Asp Ala Thr Thr Gln Gly Arg Val Ala Asp Trp Ile Phe Ala Val
290 295 300
Ser Met Gly Leu Ala Thr Gly Ile Phe Val Tyr Val Ser Ile Asn His
305 310 315 320
Leu Leu Ser Lys Gly Tyr Arg Pro Gln Arg Pro Val Ala Val Asp Thr
325 330 335
Pro Val Gly Arg Trp Leu Ala Val Val Phe Gly Val Ala Val Ile Ala
340 345 350
Val Val Met Ile Trp Asp Thr
355
5
1104
DNA
Zea mays
5
atgggagctg tgaagcatac attgaaaatg ctttcatggc tcctactctt cgcacaattg 60
gctgcggcca ccacctccaa gtgcacaaat gccacaaatg ggactgagac tgacagcctg 120
ggtgcaatga aactgaagct gattgccatt gcatccatcc tcacagctgg agcagctggt 180
gtgctagtgc cagtacttgg ccgctccatg gccacgctac atcctgatgg tgacatcttt 240
ttcgctgtca aggcatttgc agccggtgtc atcctggcca cgggcatggt ccacattctg 300
ccagcagcat ttgatgggct gacatcccca tgcctctaca aaggtggcag tggtgggaac 360
attttcccct ttgcaggact cattgcaatg tctgctgcaa tggccactat ggtgatagac 420
tcactagctg ctgggtacta ccgccggtct cacttcaaga aggcacggcc aatcgacatc 480
ctagagatcc atgaacaacc aggagatgag gaaaggtccg ggcatgcaca acatgtgcat 540
gtgcacaccc atgcaacaca tgggcattca cacggagagg tggatgtcat cagttcaccg 600
gaggaggctt caatagctga cacgatccgg cacagggtgg tatctcaggt ccttgagctc 660
ggaattttgg tgcattcagt gataattggg gtgtccttag gtgcatctgt gaggtcatcg 720
accataaggc ctcttgttgg tgcccttagc ttccatcaat tctttgaagg cattggcctg 780
ggtggttgca ttgtgcaggc aaatttcaag ttgagggcta ccgtcatgat ggcaattttt 840
ttctccctga ctgcacccat tggcattgca ttagggattg gaatttcatc aagctacaat 900
ggccatagca ctacagcgtt cattgttgaa ggagtgttca actcagcctc agcaggaatt 960
ttgatctaca tgtcattagt cgatcttctg gccacagatt tcaataagcc caaactgcag 1020
acgaatacaa agcttcagct gatgacatat cttgcacttt tcttaggtgc agggatgatg 1080
tccatgcttg ctatatgggc atag 1104
6
367
PRT
Zea mays
6
Met Gly Ala Val Lys His Thr Leu Lys Met Leu Ser Trp Leu Leu Leu
1 5 10 15
Phe Ala Gln Leu Ala Ala Ala Thr Thr Ser Lys Cys Thr Asn Ala Thr
20 25 30
Asn Gly Thr Glu Thr Asp Ser Leu Gly Ala Met Lys Leu Lys Leu Ile
35 40 45
Ala Ile Ala Ser Ile Leu Thr Ala Gly Ala Ala Gly Val Leu Val Pro
50 55 60
Val Leu Gly Arg Ser Met Ala Thr Leu His Pro Asp Gly Asp Ile Phe
65 70 75 80
Phe Ala Val Lys Ala Phe Ala Ala Gly Val Ile Leu Ala Thr Gly Met
85 90 95
Val His Ile Leu Pro Ala Ala Phe Asp Gly Leu Thr Ser Pro Cys Leu
100 105 110
Tyr Lys Gly Gly Ser Gly Gly Asn Ile Phe Pro Phe Ala Gly Leu Ile
115 120 125
Ala Met Ser Ala Ala Met Ala Thr Met Val Ile Asp Ser Leu Ala Ala
130 135 140
Gly Tyr Tyr Arg Arg Ser His Phe Lys Lys Ala Arg Pro Ile Asp Ile
145 150 155 160
Leu Glu Ile His Glu Gln Pro Gly Asp Glu Glu Arg Ser Gly His Ala
165 170 175
Gln His Val His Val His Thr His Ala Thr His Gly His Ser His Gly
180 185 190
Glu Val Asp Val Ile Ser Ser Pro Glu Glu Ala Ser Ile Ala Asp Thr
195 200 205
Ile Arg His Arg Val Val Ser Gln Val Leu Glu Leu Gly Ile Leu Val
210 215 220
His Ser Val Ile Ile Gly Val Ser Leu Gly Ala Ser Val Arg Ser Ser
225 230 235 240
Thr Ile Arg Pro Leu Val Gly Ala Leu Ser Phe His Gln Phe Phe Glu
245 250 255
Gly Ile Gly Leu Gly Gly Cys Ile Val Gln Ala Asn Phe Lys Leu Arg
260 265 270
Ala Thr Val Met Met Ala Ile Phe Phe Ser Leu Thr Ala Pro Ile Gly
275 280 285
Ile Ala Leu Gly Ile Gly Ile Ser Ser Ser Tyr Asn Gly His Ser Thr
290 295 300
Thr Ala Phe Ile Val Glu Gly Val Phe Asn Ser Ala Ser Ala Gly Ile
305 310 315 320
Leu Ile Tyr Met Ser Leu Val Asp Leu Leu Ala Thr Asp Phe Asn Lys
325 330 335
Pro Lys Leu Gln Thr Asn Thr Lys Leu Gln Leu Met Thr Tyr Leu Ala
340 345 350
Leu Phe Leu Gly Ala Gly Met Met Ser Met Leu Ala Ile Trp Ala
355 360 365
7
1164
DNA
Zea mays
7
atggttctcg ccggcctccg ccggcacgtc ggccagttct tgaccagcag taatgagctt 60
atggcggcgt cgctctcggc cgtgagctgc gcggacgagg tgcagaaggc ggagggagcg 120
gggtgccgtg acgacgccgc ggcgctgcgg ctcaagaagg tggccatggc ggcgatactg 180
gtggccgggg tgctcggggt ggtcctgccg ctcgcggggc ggaagcggcg cgcgctgcgc 240
acggacagcg ccgcgttcct ggcggccaag gcgttcgccg ccggggtcat cctggccacg 300
gggttcgtcc acatgcttca cgacgccgag cacgcgctgt ccagcccgtg cctccccgcc 360
gcgccgtggc gacggttccc agtccccggg ttcgtcgcca tggccgccgc gctagccacg 420
ctggtgctcg acttccttgc caccaggttc tacgaggcca agcatcgcga cgaggccgcg 480
cgcgtcaagg cggccgccgc cgccgcactg gttgcgacct cctctgggag cgacgaggac 540
atcaccgtgg tcaccgtcga tgaggacgag cgcaaggccc cgctgttgca aacgcactgc 600
catggacacg gtcacagcca cagccacagc catgtgcatg agccggtgca ggtagagggt 660
agcgaggcgg aggtgtcggc acatgtgcgc tccattgtcg tgtcacagat actggagatg 720
gggattgtgt cacactctgt gatcatcgga ttgtcactgg gagtgtcgcg gagcccatgc 780
acaatcaggc cacttgttgc agcacttgca ttccaccagt tcttcgaggg gtttgcacta 840
ggtgggtgca ttgctcaggc acaattcaag aacctttcag cagttctaat ggcatctttc 900
ttcgccatca caacaccggc aggaatagct gctggggcag gcatgaccac attctacaat 960
cccaatagcc caagggccct tgtggtcgag ggcattcttg actcggtatc tgctggcatt 1020
ctcatataca tgtcactagt ggatctcatt gctgtagatt tcttgggtgg aaagatgaca 1080
gggaccctgc gacaacaagt gatggcatac atcgcattgt tcctcggtgc gctctctatg 1140
tcatcacttg caatatgggc ttga 1164
8
387
PRT
Zea mays
8
Met Val Leu Ala Gly Leu Arg Arg His Val Gly Gln Phe Leu Thr Ser
1 5 10 15
Ser Asn Glu Leu Met Ala Ala Ser Leu Ser Ala Val Ser Cys Ala Asp
20 25 30
Glu Val Gln Lys Ala Glu Gly Ala Gly Cys Arg Asp Asp Ala Ala Ala
35 40 45
Leu Arg Leu Lys Lys Val Ala Met Ala Ala Ile Leu Val Ala Gly Val
50 55 60
Leu Gly Val Val Leu Pro Leu Ala Gly Arg Lys Arg Arg Ala Leu Arg
65 70 75 80
Thr Asp Ser Ala Ala Phe Leu Ala Ala Lys Ala Phe Ala Ala Gly Val
85 90 95
Ile Leu Ala Thr Gly Phe Val His Met Leu His Asp Ala Glu His Ala
100 105 110
Leu Ser Ser Pro Cys Leu Pro Ala Ala Pro Trp Arg Arg Phe Pro Val
115 120 125
Pro Gly Phe Val Ala Met Ala Ala Ala Leu Ala Thr Leu Val Leu Asp
130 135 140
Phe Leu Ala Thr Arg Phe Tyr Glu Ala Lys His Arg Asp Glu Ala Ala
145 150 155 160
Arg Val Lys Ala Ala Ala Ala Ala Ala Leu Val Ala Thr Ser Ser Gly
165 170 175
Ser Asp Glu Asp Ile Thr Val Val Thr Val Asp Glu Asp Glu Arg Lys
180 185 190
Ala Pro Leu Leu Gln Thr His Cys His Gly His Gly His Ser His Ser
195 200 205
His Ser His Val His Glu Pro Val Gln Val Glu Gly Ser Glu Ala Glu
210 215 220
Val Ser Ala His Val Arg Ser Ile Val Val Ser Gln Ile Leu Glu Met
225 230 235 240
Gly Ile Val Ser His Ser Val Ile Ile Gly Leu Ser Leu Gly Val Ser
245 250 255
Arg Ser Pro Cys Thr Ile Arg Pro Leu Val Ala Ala Leu Ala Phe His
260 265 270
Gln Phe Phe Glu Gly Phe Ala Leu Gly Gly Cys Ile Ala Gln Ala Gln
275 280 285
Phe Lys Asn Leu Ser Ala Val Leu Met Ala Ser Phe Phe Ala Ile Thr
290 295 300
Thr Pro Ala Gly Ile Ala Ala Gly Ala Gly Met Thr Thr Phe Tyr Asn
305 310 315 320
Pro Asn Ser Pro Arg Ala Leu Val Val Glu Gly Ile Leu Asp Ser Val
325 330 335
Ser Ala Gly Ile Leu Ile Tyr Met Ser Leu Val Asp Leu Ile Ala Val
340 345 350
Asp Phe Leu Gly Gly Lys Met Thr Gly Thr Leu Arg Gln Gln Val Met
355 360 365
Ala Tyr Ile Ala Leu Phe Leu Gly Ala Leu Ser Met Ser Ser Leu Ala
370 375 380
Ile Trp Ala
385
9
1191
DNA
Zea mays
9
atggccatga ggccacgcgc cgcgctcgcc ctcgccctgg cagccggcgt cccgctggtc 60
ctcctcctcc tcctcgcgcc cggcgcgcgc gccgacgacg gcagcggcgg gtgcggggcg 120
gcgggcggcg gcgaggcggc gccgggcgac cgcgcgcggg ccagggcgct gaagatcgcg 180
gccttcttct ccatcctcgt gtgcggggcg ctgggctgct gcctgcccgt gctggggcgg 240
cgcgtgccgg cgctgcgccc cgacagggac gtgttcttcc tgatcaaggc gttcgcggcg 300
ggggtcatcc tggccacggg gttcatccac atcctccccg acgcgttcga gaagctcacg 360
tccgattgcc tctccgacgg gccgtggcag gacttcccct tcgcggggct cggcgccatg 420
gtcggcgcca tcggcacgct cgtcgtcgac accgtcgcca cgggctactt cacgcgcgtc 480
cacttcaagg acagcgccgc cgccgccgtg ggcgccgccg ccgtcggcga cgaggagaag 540
cagcagcagc aggcggcgtc ggcgccgcac gtcgacgacg gagcagacgg cgacggccac 600
ggccacggcg ggcacgtgca catgcacacg cacgcgacgc acgggcactc gcacggcgcc 660
tcggcgctcg tggccgccgt cggcggcgcc gagggcgaca aggagcacgc gctgcgccac 720
cgtgtcatcg ctcaggttct tgagcttggg attgtggtgc actcggtgat catcggcatc 780
tccctcggcg cgtctcaaga ccccagcacc atcaagcctc ttgtggtcgc cctcagcttc 840
caccaaatgt tcgagggcat gggtcttggc ggctgcatcg ttcaggccaa gttcaagctg 900
cggtcgatcg tgacgatggt gctcttcttc tgcctgacga cgccggtggg catcgtggtg 960
ggcgtcggga tctcgtcggt gtacgacgag gacagcccca cggcgctggt cgtggagggc 1020
gtgctcaact cggtggcggc ggggatcctg gtgtacatgg cgctggtgga cctgctcgcc 1080
gaggacttca tgaaccctag ggtgcagagc cggggcaagc tgcagctcgg catcaacgcc 1140
tccatgctcg tcggcgccgg cctcatgtcc atgctggcca agtgggccta g 1191
10
396
PRT
Zea mays
10
Met Ala Met Arg Pro Arg Ala Ala Leu Ala Leu Ala Leu Ala Ala Gly
1 5 10 15
Val Pro Leu Val Leu Leu Leu Leu Leu Ala Pro Gly Ala Arg Ala Asp
20 25 30
Asp Gly Ser Gly Gly Cys Gly Ala Ala Gly Gly Gly Glu Ala Ala Pro
35 40 45
Gly Asp Arg Ala Arg Ala Arg Ala Leu Lys Ile Ala Ala Phe Phe Ser
50 55 60
Ile Leu Val Cys Gly Ala Leu Gly Cys Cys Leu Pro Val Leu Gly Arg
65 70 75 80
Arg Val Pro Ala Leu Arg Pro Asp Arg Asp Val Phe Phe Leu Ile Lys
85 90 95
Ala Phe Ala Ala Gly Val Ile Leu Ala Thr Gly Phe Ile His Ile Leu
100 105 110
Pro Asp Ala Phe Glu Lys Leu Thr Ser Asp Cys Leu Ser Asp Gly Pro
115 120 125
Trp Gln Asp Phe Pro Phe Ala Gly Leu Gly Ala Met Val Gly Ala Ile
130 135 140
Gly Thr Leu Val Val Asp Thr Val Ala Thr Gly Tyr Phe Thr Arg Val
145 150 155 160
His Phe Lys Asp Ser Ala Ala Ala Ala Val Gly Ala Ala Ala Val Gly
165 170 175
Asp Glu Glu Lys Gln Gln Gln Gln Ala Ala Ser Ala Pro His Val Asp
180 185 190
Asp Gly Ala Asp Gly Asp Gly His Gly His Gly Gly His Val His Met
195 200 205
His Thr His Ala Thr His Gly His Ser His Gly Ala Ser Ala Leu Val
210 215 220
Ala Ala Val Gly Gly Ala Glu Gly Asp Lys Glu His Ala Leu Arg His
225 230 235 240
Arg Val Ile Ala Gln Val Leu Glu Leu Gly Ile Val Val His Ser Val
245 250 255
Ile Ile Gly Ile Ser Leu Gly Ala Ser Gln Asp Pro Ser Thr Ile Lys
260 265 270
Pro Leu Val Val Ala Leu Ser Phe His Gln Met Phe Glu Gly Met Gly
275 280 285
Leu Gly Gly Cys Ile Val Gln Ala Lys Phe Lys Leu Arg Ser Ile Val
290 295 300
Thr Met Val Leu Phe Phe Cys Leu Thr Thr Pro Val Gly Ile Val Val
305 310 315 320
Gly Val Gly Ile Ser Ser Val Tyr Asp Glu Asp Ser Pro Thr Ala Leu
325 330 335
Val Val Glu Gly Val Leu Asn Ser Val Ala Ala Gly Ile Leu Val Tyr
340 345 350
Met Ala Leu Val Asp Leu Leu Ala Glu Asp Phe Met Asn Pro Arg Val
355 360 365
Gln Ser Arg Gly Lys Leu Gln Leu Gly Ile Asn Ala Ser Met Leu Val
370 375 380
Gly Ala Gly Leu Met Ser Met Leu Ala Lys Trp Ala
385 390 395