基於關鍵詞的不良文本檢測方法及裝置與流程
2023-05-10 00:23:36 6
本發明涉及網頁內容檢測領域,更具體地說,涉及一種基於關鍵詞的不良文本檢測方法及裝置。
背景技術:
隨著網際網路的普及和網絡帶寬的提高,網際網路中可訪問的網站數量及網頁內容也呈現出爆炸性增加的趨勢。由於網際網路的開放性,網頁內容中摻雜了不少涉黃、涉賭及涉毒等違規的不良信息。為了封鎖包含不良信息的違規網頁,淨化網絡環境,需對網頁內容進行實時監控。
以往,為了對網頁內容進行實時監控,提出了根據關鍵詞出現的次數來衡量一個網頁是否違規。具體地,當某一網頁中的關鍵詞出現的次數超過閾值時,判斷該網頁違規。
然而,網際網路中網站數量龐大,網頁內容繁多,其中涉黃、涉賭及涉毒的違規詞的基數龐大,違規詞的偽裝詞也五花八門。例如,對於涉黃的違規詞「性愛」,違規網站常常不直接使用該違規詞,而是使用近音詞、近形詞來替代,例如「悻愛」、「性噯⌒」、「狌曖」等,而且還可能在違規詞中間加上分隔符來幹擾違規詞的識別,例如「性☆愛」。
因此,按照以往的檢測方法,即使耗費大量的人工去標記各種違規詞作為關鍵詞,也會不可避免地遺漏很多違規詞。另一方面,基於違規詞進行檢測時難以識別偽裝詞。因此,現有技術由於關鍵詞的限制,識別網頁違規的準確率 較低。
技術實現要素:
本發明提供一種基於關鍵詞的不良文本檢測方法及裝置,能夠提高基於關鍵詞進行不良文本檢測的準確率。
本發明解決其技術問題所採用的技術方案是:
第一方面,提供一種基於關鍵詞的不良文本檢測方法,包括如下步驟:
S0、獲取多個種子詞,所述種子詞為用於表徵不良信息的詞語;
S1、根據語義聚類法對所述種子詞進行擴展,得到與所述種子詞語義關聯的語義關聯詞,以所述種子詞和所述語義關聯詞作為用於檢測不良文本的關鍵詞;
S2、在網頁文本在寬帶環境中傳輸的情況下,統計每個網頁文本中所述關鍵詞的出現次數,並根據所述出現次數確定屬於不良文本的網頁文本。
結合第一方面,在其第一種可能的實現方式中,所述種子詞為N個,N為整數且N≥2,所述步驟S1具體包括:
S11、獲取含有不良信息的訓練文檔,將所述訓練文檔中的每個詞轉換為詞向量形式的待訓練詞向量,並將所述種子詞轉換為詞向量形式的種子詞向量,所述待訓練詞向量與所述種子詞向量位於同一詞向量空間中;
S12、計算每個所述待訓練詞向量與每個所述種子詞向量之間的餘弦距離;
S13、在所述詞向量空間中,以N個所述種子詞向量作為初始質心,利用K-means聚類算法對所述待訓練詞向量進行聚類,得到K個詞向量簇,每個所述詞向量簇分別具有一個聚類質心,其中K為正整數且K≤N;
S14、對於所述聚類質心距所述種子詞向量的餘弦距離最小的所述詞向量簇,確定其中的所述待訓練詞向量對應的詞,並將所確定的詞作為與該種子詞向量對應的所述種子詞的所述語義關聯詞。
結合第一方面的第一種可能的實現方式,在其第二種可能的實現方式中,所述步驟S11中的所述獲取含有不良信息的訓練文檔具體包括:
獲取所述步驟S2中被確定為不良文本的所述網頁文本。
結合第一方面,在其第三種可能的實現方式中,所述步驟S2具體包括:
S21、統計每個網頁文本中所述關鍵詞的出現次數,並判斷所述出現次數是否超出閾值;
S22、當所述出現次數超出所述閾值時,初步判斷所述網頁文本為不良文本;
S23、顯示被初步判斷為不良文本的所述網頁文本;
S24、接收檢測人員輸入的、表示被初步判斷為不良文本的所述網頁文本屬於不良文本的指示,並根據所述指示,確定被初步判斷為不良文本的所述網頁文本屬於不良文本。
結合第一方面,在其第四種可能的實現方式中,所述步驟S0還包括:
對獲取的多個所述種子詞進行分類;
所述步驟S1具體包括:對於每種類型的所述種子詞,分別根據語義聚類法進行擴展得到與該種類型的所述種子詞語義關聯的語義關聯詞,以該種類型的所述種子詞及其所述語義關聯詞作為用於檢測該種類型的不良文本的關鍵詞。
結合第一方面或其第一種至第四種任一可能的實現方式,在其第五種可能的實現方式中,
所述步驟S0、步驟S1在離線模式下進行,所述步驟S2在在線模式下進行。
第二方面,提供一種基於關鍵詞的不良文本檢測裝置,包括:
種子詞獲取單元,其用於獲取多個種子詞,所述種子詞為用於表徵不良信息的詞語;
語義關聯詞擴展單元,其用於根據語義聚類法對所述種子詞獲取單元獲取的種子詞進行擴展,得到與所述種子詞語義關聯的語義關聯詞,以所述種子詞和所述語義關聯詞作為用於檢測不良文本的關鍵詞;
不良文本判斷單元,其在網頁文本在寬帶環境中傳輸的情況下,統計每個網頁文本中所述語義關聯詞擴展單元得到的關鍵詞的出現次數,並根據所述出現次數確定屬於不良文本的網頁文本。
結合第二方面,在其第一種可能的實現方式中,所述種子詞為N個,N為整數且N≥2,所述語義關聯詞擴展單元具體用於:
獲取含有不良信息的訓練文檔;
將所述訓練文檔中的每個詞轉換為詞向量形式的待訓練詞向量,並將所述種子詞獲取單元獲取的種子詞轉換為詞向量形式的種子詞向量,所述待訓練詞向量與所述種子詞向量位於同一詞向量空間中;
計算所述每個所述待訓練詞向量與每個所述種子詞向量之間的餘弦距離;
在所述詞向量空間中,以N個所述種子詞向量作為初始質心,利用K-means聚類算法對所述待訓練詞向量進行聚類,得到K個詞向量簇,每個所述K個詞向量簇分別具有一個聚類質心,其中K為正整數且K≤N;
對所述聚類質心距所述種子詞向量的餘弦距離最小的所述詞向量簇,確定其中的所述待訓練詞向量對應的詞,並將所確定的詞作為與該種子詞向量對應的所述種子詞的所述語義關聯詞。
結合第二方面的第一種可能的實現方式,在其第二種可能的實現方式中,
所述語義關聯詞擴展單元具體用於:獲取在所述不良文本判斷單元中被確定為不良文本的所述網頁文本。
結合第二方面,在其第三種可能的實現方式中,所述不良文本判斷單元具體用於:
統計每個網頁文本中所述語義關聯詞擴展單元得到的關鍵詞的出現次數;
判斷所述出現次數是否超出閾值;
在所述出現次數超出所述閾值時,初步判斷所述網頁文本為不良文本;
顯示被初步判斷為不良文本的所述網頁文本;
接收檢測人員輸入的、表示被初步判斷為不良文本的所述網頁文本屬於不良文本的指示,並根據所述指示,確定被初步判斷為不良文本的所述網頁文本屬於不良文本。
根據本發明提供的基於關鍵詞的不良文本檢測方法及裝置,由於能夠根據較少的種子詞自動拓展得到較為全面的關鍵詞,因此,能夠解決現有技術中因遺漏較多違規詞及難以識別偽裝詞造成的識別網頁違規的準確率較低的問題, 提高基於關鍵詞進行不良文本檢測的準確率。
附圖說明
下面將結合附圖及實施例對本發明作進一步說明,附圖中:
圖1為基於關鍵詞的不良文本檢測方法的流程圖;
圖2為基於關鍵詞的不良文本檢測裝置的結構框圖。
具體實施方式
為了對本發明的技術特徵、目的和效果有更加清楚的理解,現對照附圖詳細說明本發明的具體實施方式。
實施例一
本實施例提供一種基於關鍵詞的不良文本檢測方法,可由具有信息處理功能的計算機、網絡伺服器等執行。不良文本是指含有涉黃、涉賭及涉毒等違規的不良信息的文本內容。關鍵詞是檢測人員為進行不良文本檢測而預先獲取的、具有不良信息或敏感信息的詞語,例如「性愛」等違規詞。作為本發明的一個應用場景,在本實施例中,網絡伺服器根據本發明提供的方法,檢測網絡中數據流形式的網頁文本。可以理解的是,為了進行檢測,可將數據流形式的網頁文本還原為自然語言形式的網頁文本。以下,對本實施例提供的基於關鍵詞的不良文本檢測方法進行說明。
圖1為實施例一提供的基於關鍵詞的不良文本檢測方法流程圖。如圖1所示,所述方法包括如下步驟:
S0、獲取多個種子詞,種子詞為用於表徵不良信息的詞語。
如上所述,為了進行檢測,需預先準備關鍵詞。而為了提高基於關鍵詞進行不良文本檢測的準確率,需準備全面的關鍵詞。所謂全面,是指關鍵詞的數量足夠龐大,能夠涵蓋絕大部分違規詞。為了獲得全面或趨於全面的關鍵詞,本發明採用這樣的方式:預先準備一部分關鍵詞作為種子詞,並根據種子詞進行自動擴展得到更全面的關鍵詞。也就是說,顧名思義,種子詞作為種子使用,通過對種子進行信息處理,衍生出更多的關鍵詞。種子詞實質上是關鍵詞的一 部分,同樣用於表徵不良信息。
在此步驟中,網絡伺服器可從其他設備獲取種子詞,或者直接接收檢測人員輸入的種子詞。在兼顧為獲取或接收種子詞所需耗費的資源或人力不過大的前提下,種子詞的數量優選越多越好。需要說明的是,現有技術中為了儘可能取得全面的關鍵詞,需要檢測人員竭盡所能地標記、獲取關鍵詞。雖然這種方式有可能取得較多的關鍵詞,但需要耗費了巨大的資源及人力,並且,相對於變化多樣、數量龐大的關鍵詞庫,通過人力獲取的關鍵詞的數量畢竟有限。與此相對,在本步驟中,對於作為種子詞的關鍵詞,可進行適度的獲取,這種適度以所耗費的資源及人力合理為限。也就是說,相對於現有技術,本步驟中能夠節約為獲取關鍵詞的資源及人力。
在一種可選的實現方式中,網絡伺服器可分門別類地獲取或接收種子詞,即,網絡伺服器可對獲取的種子詞進行分類。舉例而言,網絡伺服器可分別按照涉黃、涉賭及涉毒的類型,獲取涉黃種子詞、涉賭種子詞及涉毒種子詞。涉黃種子詞例如包括性愛等,涉賭種子詞例如包括六合彩、百家樂等,涉毒種子詞例如包括K粉、搖頭丸等。
S1、根據語義聚類法對種子詞進行擴展,得到與種子詞語義關聯的語義關聯詞,以種子詞和語義關聯詞作為用於檢測不良文本的關鍵詞。
在本發明中,語義聚類法是指,使用少量的關鍵詞作為種子詞,以種子詞為標杆將與其語義相近或關聯的詞聚類在一起,從而自動擴展關鍵詞的總量。
在此,對通過對種子進行信息處理衍生出更多關鍵詞的過程進行說明。假定種子詞為N個,N為整數且N≥2。步驟S1具體可分為步驟S11~S14。
S11、獲取含有不良信息的訓練文檔,將訓練文檔中的每個詞轉換為詞向量形式的待訓練詞向量,並將種子詞轉換為詞向量形式的種子詞向量。
作為拓展關鍵詞的訓練資料,需準備含有不良信息的文檔,稱為訓練文檔。例如,一篇被判定為涉黃的文檔,其中含有違規詞,此外,還含有其他非違規詞。
為了對訓練文檔中的詞語與關鍵詞之間語義是否相近或關聯進行判斷,本實施例採用了詞向量及餘弦距離。詞向量是指,通過訓練將某種語言中的每一 個詞語映射成一個固定長度(即固定維度)的向量。例如,一個詞可以被映射成一個M(M為整數且M≥2)維向量Wi:
Wi=(V1,V2,...,VM),其中,V1、V1、……、VM為在各維上的值。
每個詞都轉換為唯一的詞向量,所有詞向量構成一個詞向量空間。像這樣地,將一個詞語轉換為具有某一固定維度的模型,可稱為詞向量模型。
對於詞向量模型,可使用Google公司提供的word2vec工具。word2vec是Google在2013年開源的一款將詞表徵為實數值向量的高效工具,其利用深度學習的思想,可以通過訓練,把對文本內容的處理簡化為K維向量空間中的向量運算,而向量空間上的相似度可以用來表示文本語義上的相似度。與潛在語義分析(Latent Semantic Index,LSI)、潛在狄立克雷分配(Latent Dirichlet Allocation,LDA)的經典過程相比,word2vec利用了詞的上下文,語義信息更加地豐富。
S12、計算每個待訓練詞向量與每個種子詞向量之間的餘弦距離。
餘弦距離也稱為餘弦相似度,是用向量空間中兩個向量夾角的餘弦值作為衡量兩個個體間差異的大小的度量。兩個向量之間的夾角越大,它們之間的餘弦距離越大,反之越小。若兩個向量的方向趨於一致,即夾角接近零,那麼這兩個向量的餘弦距離趨於零。由於詞向量是根據自然語言的詞法、語義進行映射得到的,因此,餘弦距離能夠表徵兩個詞向量各自對應的詞語在詞法、語義上的關聯性。餘弦距離越小,兩個詞語在語義上越相近或關聯。
在本步驟中,為了確定訓練文本中哪些詞語與種子詞在語義上關聯,首先需要分別計算訓練文本中的每個詞語轉換為待訓練詞向量後每個待訓練詞向量與每個種子詞向量之間的餘弦距離。具體地,令N個種子詞對應的詞向量分別為S1、S2、……、SN,訓練文本中的詞語對應的待訓練詞向量分別為W1、W2、W3、……。在本步驟中,對於種子詞向量S1,計算它與各個待訓練詞向量之間的餘弦距離,即D11=CosinDistance(S1,W1)、D12=CosinDistance(S1,W2)、D13=CosinDistance(S1,W3)……。對於種子詞向量S2,計算它與各個待訓練詞向量之間的餘弦距離,即D21=CosinDistance(S2,W1)、D22=CosinDistance(S2,W2)、D23=CosinDistance(S2,W3)……。對於種子 詞向量SN,計算它與各個待訓練詞向量之間的餘弦距離,即DN1=CosinDistance(SN,W1)、DN2=CosinDistance(SN,W2)、DN3=CosinDistance(SN,W3)……。從而得到每個待訓練詞向量與每個種子詞向量之間的餘弦距離:
Dij=Co sin Dis tan ce(Si,Wj)。
S13、在詞向量空間中,以N個種子詞向量作為初始質心,利用K-means聚類算法對待訓練詞向量進行聚類,得到K個詞向量簇,每個詞向量簇分別具有一個聚類質心。
在確定每個待訓練詞向量與每個種子詞向量之間的餘弦距離之後,為了高效快捷地確定與種子詞向量對應的種子詞的語義關聯詞,在本步驟中,採用K-means聚類算法對待訓練詞向量進行聚類。
具體地,首先選取N個種子詞向量作為初始質心,利用步驟S12中計算得到的餘弦距離進行第一輪聚類:對於某一初始質心,使餘弦距離距該初始質心比距其他質心都要小的待訓練詞向量聚成一類;對於其他另外每個初始質心同樣進行類似的聚類處理。經過第一輪聚類後,得到至多N個詞向量簇(由於存在這樣的初始質心,任意一個待訓練詞向量距該初始質心的餘弦距離都要大於距其他初始質心的餘弦距離,因此沒有待訓練詞向量聚類到該初始質心下,因此,存在詞向量簇的個數K小於或等於種子詞向量個數N的情況。以下,以K個詞向量簇進行說明,其中K為正整數且K≤N)。每個詞向量簇分別具有一個質心,可稱為第一輪聚類質心。
接著,又可根據K個第一輪聚類質心進行第二輪聚類,經過第二輪聚類之後,得到的K個詞向量簇更加集中,同時對應K個第二輪聚類質心。接著,可重複上述過程,進行第三次、第四次乃至更多次的聚類。當某一輪聚類質心與其前一輪的聚類質心之間的變化小於預先設定的值,可停止K-means聚類算法,最終得到聚類質心穩定的K個詞向量簇。
S14、對於聚類質心距種子詞向量的餘弦距離最小的詞向量簇,確定其中的待訓練詞向量對應的詞,並將所確定的詞作為與該種子詞向量對應的種子詞的語義關聯詞。
在此步驟中,根據步驟S13所得到的K個詞向量簇,進行種子詞的語義 關聯詞的判斷。具體地,對於每個詞向量簇,重新計算其聚類質心距每個種子詞向量的餘弦距離。然後,對於某個詞向量簇,判斷其聚類質心距哪個種子詞向量的餘弦距離最小,並記錄該詞向量簇與該種子詞向量之間餘弦距離最小的對應關係。對於其他每個詞向量簇,進行類似的判斷,得到每個詞向量簇及與其餘弦距離最小的種子詞向量之間的對應關係。最後,根據上述餘弦距離最小的對應關係,將詞向量簇中的所有待訓練詞向量所對應的詞語,作為對應的種子詞向量所對應的種子詞的語義關聯詞。
據此,完成了根據語義聚類法將種子詞擴展為語義關聯詞得到包括種子詞和語義關聯詞在內的關鍵詞的過程。
需要說明的是,在上述說明中對根據步驟S11至S14的處理能夠擴展關鍵詞的數量,這包括兩方面的含義。具體地,如背景技術部分所述,一方面,違規詞的基數龐大;另一方面,違規詞的偽裝詞也五花八門。在本實施例中,關鍵詞的擴展一方面包括違規詞的拓展,另一方面還包括違規詞的偽裝詞的拓展。所謂違規詞的拓展,是指不考慮偽裝詞的情況下的拓展;而違規詞的偽裝詞的拓展,是指在違規詞的基礎上拓展其偽裝詞。舉例而言,對於涉毒違規詞,假設已標記的種子詞為「六合彩」、「百家樂」,但是未標記「時時彩」、「老虎機」等,根據種子詞「六合彩」、「百家樂」拓展得到「時時彩」、「老虎機」等屬於違規詞的拓展。而涉黃違規詞,假設已標記的種子詞為「性愛」,但是未標記「悻愛」、「性噯⌒」、「狌曖」等,根據種子詞「性愛」拓展得到「悻愛」、「性噯⌒」、「狌曖」等則屬於違規詞的偽裝詞的拓展。
由此可見,根據本發明提供的基於關鍵詞的不良文本檢測方法,既能夠避免遺漏過多違規詞,又能夠識別違規詞的偽裝詞。
另外,如步驟S0所述,網絡伺服器可對獲取的種子詞進行分類。對應地,在步驟S1中,可對於每種類型的種子詞,分別根據語義聚類法進行擴展得到與該種類型的種子詞語義關聯的語義關聯詞,以該種類型的種子詞及其語義關聯詞作為用於檢測該種類型的不良文本的關鍵詞。即,對於每種類型的種子詞,分別進行上述步驟S11至S14。
S2、在網頁文本在寬帶環境中傳輸的情況下,統計每個網頁文本中關鍵 詞的出現次數,並根據出現次數確定屬於不良文本的網頁文本。
在根據步驟S1拓展用於檢測不良文本的關鍵詞後,可根據拓展的關鍵詞對網頁文本中的詞語進行檢測。具體地,步驟S2可分為步驟S21~S22。
S21、統計每個網頁文本中關鍵詞的出現次數,並判斷出現次數是否超出閾值。
對於作為待檢測的對象,在利用網絡伺服器對網絡中傳輸的內容進行檢測的情況下,其一般為數據流形式的網頁代碼,為了進行關鍵詞出現次數的統計,需將數據流形式的網頁代碼還原為自然語言形式的網頁文本。因此,在執行步驟S21之前,對應於數據流形式的網頁代碼先進行網頁文本還原。網頁文本還原屬於現有技術中較為成熟的技術,本發明對採用何種還原技術不做限定。
在得到自然語言形式的網頁文本後,提取文本中的每個特徵詞,然後,逐一比較網頁文本中的特徵詞是否與某一關鍵詞相同,每當一個特徵詞與某一關鍵詞相同時,計數一次。對網頁文本中的每個特徵詞重複上述比較,得到整個網頁文本中關鍵詞出現的次數,即總出現次數。
接著,對於每篇網頁文本,將其對應的關鍵詞的總出現次數與一個閾值進行比較,判斷其是否超出該閾值。在此,閾值是用于衡量一篇網頁文本中關鍵詞出現的總次數到達何種程度時可以被判定為不良文本的標準,具體可為檢測人員根據實際情況進行設置的一個數量。
S22、當出現次數超出閾值時,初步判斷網頁文本為不良文本。
一般地,當某個網頁文本中關鍵詞的出現次數超出了閾值時,即可判斷該網頁文本為不良文本,並進行進一步處理,例如,實時地阻止該不良文本的網絡數據流的傳輸或封鎖其網頁。具體地,可利用如下公式:
其中,p表示網頁,c表示類別,np是網頁p中特徵詞的個數,Mc,i是類別c中第i個關鍵詞出現的次數。
如果E(p,c)>λ,則認為網頁p屬於c類違規,其中E(p,c)為某一網頁文本中關鍵詞的出現次數,λ為閾值。
在本發明中,根據拓展的關鍵詞進行檢測能夠簡單高效地確定屬於不良文本的網頁文本。與此相對,現有技術中還存在通過語義分析方法來對整個文檔使用語義分析技術以進行判斷的方法,這種方法雖然能夠保證較高的準確率,但由於語義分析技術過於複雜,會增加額外的在線計算開銷,同時監管部門通常還需要安排專人對機器檢測的結果進行審核,需人工參與的工作量較大。然而,對監管部門而言,如何快速穩定的處理高帶寬下用戶訪問的網頁信息裡是否包含不良信息,儘量減少人工參與的工作量,才是最為關注的重點。對於這一問題,本發明所提供的基於關鍵詞的不良文本檢測方法具有簡單高效的特點,因此適用於在高帶寬傳輸環境下進行不良文本檢測這一場景。
在本實施例中,為了更準確地判斷不良文本,步驟S2還可包括為步驟S23~S24。
S23、顯示被初步判斷為不良文本的網頁文本。
對於被初步判斷為不良文本的網頁文本,網絡伺服器可控制顯示器使其顯示這些網頁文本,據此,檢測人員可觀察被初步判斷為不良文本的網頁文本。
S24、接收檢測人員輸入的、表示被初步判斷為不良文本的網頁文本屬於不良文本的指示,並根據指示,確定被初步判斷為不良文本的網頁文本屬於不良文本。
通過觀察、閱讀,檢測人員能夠確定被初步判斷為不良文本的網頁文本是否真為不良文本。然後,檢測人員可向網絡伺服器輸入自身的確定結果,即輸入用於表示被初步判斷為不良文本的網頁文本是否屬於不良文本的指示。當該網頁文本確為不良文本時,輸入用於表示被初步判斷為不良文本的網頁文本屬於不良文本的指示;當該網頁文本被誤判為不良文本時,輸入用於表示被初步判為不良文本的網頁文本並非不良文本的指示。
基於檢測人員輸入的指示,網絡伺服器可從被初步判斷為不良文本的網頁文本中,進一步確定真正屬於不良文本的網頁文本。
這種將自動判斷(步驟S21~S22)與人工判斷(步驟S23~S24)結合起來的不良文本檢測方式,能夠顯著提高不良文本檢測的效率與準確率。其中,由 於步驟S21~S22中的自動判斷已經篩選掉了大部分不屬於不良文本的網頁文本,因此,步驟S23~S24中人工判斷的工作量得以大大縮減,效率得以顯著提高,而人工判斷能夠彌補自動判斷的智能性限制,因而準確率得以顯著提高。
需要說明的是,這種在自動判斷的基礎上結合人工判斷的檢測方式,尤其適用於基於關鍵詞的不良文本檢測方法的初始實現階段。在此,所謂初始實現階段不是指步驟S0~S2中靠前的步驟,而是指在該檢測方法的整個過程一次次地實現過程中靠前的若干次實現過程。例如,對於成千上萬的待檢測網頁文本,使用該檢測方法對開始的前幾篇、前幾十篇甚至前幾百篇進行檢測的過程,可稱為該檢測方法的初始實現階段。這是因為,基於關鍵詞的不良文本檢測方法需要一定的試用、調試、學習期間,才能取得較為穩定、準確的結果。
在本實施例的一個更具體的實現方式中,在步驟S11中,具體地,網絡伺服器可獲取步驟S2中被確定為不良文本的網頁文本。在此,步驟S2中被確定為不良文本的網頁文本可為步驟S21~S22中自動判斷得到的被確定為不良文本的網頁文本,還可為步驟S23~S24中人工判斷得到的被確定為不良文本的網頁文本。
也就是說,在本實施例中,作為拓展關鍵詞訓練資料的訓練文檔,除了檢測人員人工獲取外,還可採用網絡伺服器自身判斷得到的。一方面,能夠減少檢測人員為獲取及輸入訓練文檔所需耗費的工作量;另一方面,由於網絡伺服器自身判斷得到的不良文本的數量龐大、種類繁多,且這些不良文本含有較多的與種子詞語義關聯的不良詞語及敏感詞語,因此,以這些不良文本作為訓練文檔能夠擴展得到更多的語義關聯詞(步驟S11~S14),從而能夠進一步優化基於關鍵詞的不良文本檢測方法,進一步提高不良文本檢測的準確率。
需要說明的是,在基於關鍵詞的不良文本檢測方法的初始實現階段,步驟S11中網絡伺服器優選步驟S23~S24中人工判斷得到的被確定為不良文本的網頁文本,這是因為,人工判斷的判斷準確率高,因而使用人工判斷得到的不良文本進行語義關聯詞擴展,能夠取得更加優化的擴展結果。
在本實施例的一個更具體的實現方式中,步驟S0、步驟S1在離線模式下進行,而僅步驟S2在在線模式下進行。如上所述,在現有技術中,由於通過 語義分析方法來對整個文檔使用語義分析技術以進行判斷的方法在在線模式下進行,因此,在線開銷大,檢測效率低下。與此相對,在本實施例中,由於步驟S0、步驟S1所對應的訓練過程不需要網絡的參與,在離線模式下進行能夠避免額外的在線處理開銷,提高檢測效率。
由上可知,根據實施例一提供的基於關鍵詞的不良文本檢測方法,由於能夠根據較少的種子詞自動拓展得到較為全面的關鍵詞,因此,能夠解決現有技術中因遺漏較多違規詞及難以識別偽裝詞造成的識別網頁違規的準確率較低的問題,提高基於關鍵詞進行不良文本檢測的準確率。
實施例二
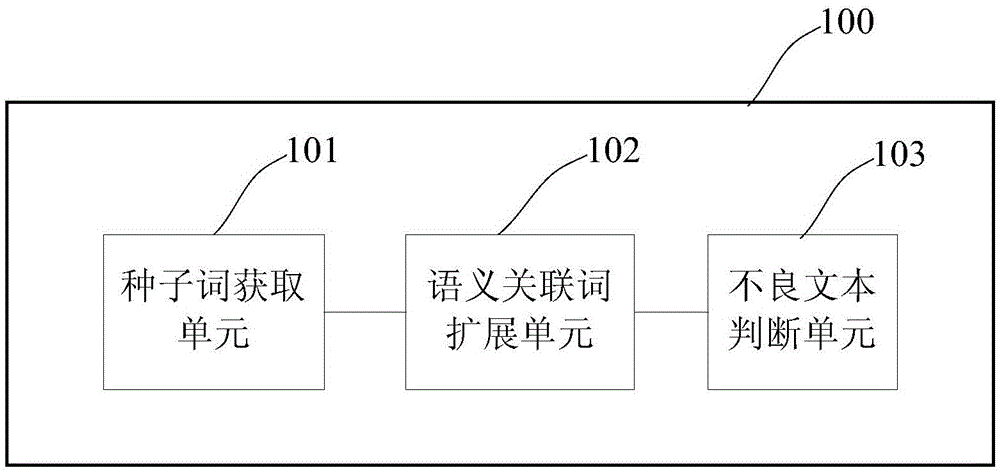
對應於實施例一提供的基於關鍵詞的不良文本檢測方法,實施例二提供的一種基於關鍵詞的不良文本檢測裝置。該裝置具體可為具有信息處理功能的計算機、網絡伺服器等。如圖2所示,基於關鍵詞的不良文本檢測裝置100包括:
種子詞獲取單元101,其用於獲取多個種子詞,種子詞為用於表徵不良信息的詞語;
語義關聯詞擴展單元102,其用於根據語義聚類法對種子詞獲取單元101獲取的種子詞進行擴展,得到與種子詞語義關聯的語義關聯詞,以種子詞和語義關聯詞作為用於檢測不良文本的關鍵詞;
不良文本判斷單元103,其在網頁文本在寬帶環境中傳輸的情況下,統計每個網頁文本中語義關聯詞擴展單元102得到的關鍵詞的出現次數,並根據出現次數確定屬於不良文本的網頁文本。
在實施例二的一個更具體的實現方式中,種子詞為N個,N為整數且N≥2,語義關聯詞擴展單元102具體用於:
獲取含有不良信息的訓練文檔;
將訓練文檔中的每個詞轉換為詞向量形式的待訓練詞向量,並將種子詞獲取單元101獲取的種子詞轉換為詞向量形式的種子詞向量,待訓練詞向量與種子詞向量位於同一詞向量空間中;
計算每個待訓練詞向量與每個種子詞向量之間的餘弦距離;
在詞向量空間中,以N個種子詞向量作為初始質心,利用K-means聚類 算法對待訓練詞向量進行聚類,得到K個詞向量簇,每個K個詞向量簇分別具有一個聚類質心,其中K為正整數且K≤N;
對聚類質心距種子詞向量的餘弦距離最小的詞向量簇,確定其中的待訓練詞向量對應的詞,並將所確定的詞作為與該種子詞向量對應的種子詞的語義關聯詞。
在實施例二的另一個更具體的實現方式中,語義關聯詞擴展單元102具體用於:獲取在不良文本判斷單元103中被確定為不良文本的網頁文本。
在實施例二的另一個更具體的實現方式中,不良文本判斷單元103具體用於:統計每個網頁文本中語義關聯詞擴展單元102得到的關鍵詞的出現次數;判斷出現次數是否超出閾值;在出現次數超出閾值時,初步判斷網頁文本為不良文本;顯示被初步判斷為不良文本的網頁文本;接收檢測人員輸入的、表示被初步判斷為不良文本的網頁文本屬於不良文本的指示,並根據該指示,確定被初步判斷為不良文本的網頁文本屬於不良文本。
由於實施例一中已經對基於關鍵詞的不良文本檢測裝置所進行的處理進行了說明,在此,不再進行贅述。同樣地,根據本實施例提供的基於關鍵詞的不良文本檢測裝置,由於能夠根據較少的種子詞自動拓展得到較為全面的關鍵詞,因此,能夠解決現有技術中因遺漏較多違規詞及難以識別偽裝詞造成的識別網頁違規的準確率較低的問題,提高基於關鍵詞進行不良文本檢測的準確率。
上面結合附圖對本發明的實施例進行了描述,但是本發明並不局限於上述的具體實施方式,上述的具體實施方式僅僅是示意性的,而不是限制性的,本領域的普通技術人員在本發明的啟示下,在不脫離本發明宗旨和權利要求所保護的範圍情況下,還可做出很多形式,這些均屬於本發明的保護之內。