建立聲學特徵提取模型的方法、提取聲學特徵的方法、裝置與流程
2023-12-08 23:09:31 2
【技術領域】
本發明涉及計算機應用技術領域,特別涉及一種建立聲學特徵提取模型的方法、提取聲學特徵的方法及對應裝置。
背景技術:
隨著人工智慧的不斷發展,語音交互已經成為最自然的交互方式之一得到日益推廣,語音識別技術也越來越得到人們的重視。在語音識別技術中,聲學特徵的提取是核心技術,其可以用於用戶識別、驗證或分類等。
現有聲學特徵提取方式,主要是依據預設的特徵類型,對語音數據進行預設方式的變換後,從中提取對應類型的特徵。這種聲學特徵提取方式很大程度上依靠特徵類型的設置和變換方式的設置,準確性和靈活性較低。
技術實現要素:
本發明提供了一種建立聲學特徵提取模型的方法、提取聲學特徵的方法、裝置、設備和計算機存儲介質,以便於提高所提取聲學特徵的準確性和靈活性。
具體技術方案如下:
本發明提供了一種建立聲學特徵提取模型的方法,該方法包括:
將從各用戶標識對應的語音數據中分別提取的第一聲學特徵,作為訓練數據;
利用所述訓練數據訓練深度神經網絡,得到聲學特徵提取模型;
其中所述深度神經網絡的訓練目標為:最大化相同用戶的第二聲學特徵之間的相似度且最小化不同用戶的第二聲學特徵之間的相似度。
根據本發明一優選實施方式,所述第一聲學特徵包括:fbank64聲學特徵。
根據本發明一優選實施方式,所述深度神經網絡包括:卷積神經網絡cnn、殘差卷積神經網絡rescnn或者門控遞歸單元gru。
根據本發明一優選實施方式,利用所述訓練數據訓練深度神經網絡,得到聲學特徵提取模型包括:
利用深度神經網絡對各語音數據的第一聲學特徵進行學習,輸出各語音數據的第二聲學特徵;
利用所述各語音數據的第二聲學特徵計算三元組損失,利用所述三元組損失對所述深度神經網絡進行調參,以最小化所述三元組損失;
其中,所述三元組損失體現不同用戶的第二聲學特徵之間的相似度與相同用戶的第二聲學特徵之間的相似度的差值狀況。
根據本發明一優選實施方式,所述利用深度神經網絡對各語音數據的第一聲學特徵進行學習,輸出各語音數據的第二聲學特徵包括:
利用深度神經網絡對各語音數據的第一聲學特徵進行學習,輸出幀級別的第二聲學特徵;
對幀級別的第二聲學特徵進行池化和語句標準化處理,輸出句子級別的第二聲學特徵;
在計算三元組損失時利用的所述各語音數據的第二聲學特徵為各語音數據的句子級別的第二聲學特徵。
本發明還提供了一種提取聲學特徵的方法,該方法包括:
提取待處理語音數據的第一聲學特徵;
將所述第一聲學特徵輸入聲學特徵提取模型,得到待處理語音數據的第二聲學特徵;
其中所述聲學特徵提取模型是採用上述建立聲學特徵提取模型的方法預先建立的。
根據本發明一優選實施方式,該方法還包括:
利用所述待處理語音數據的第二聲學特徵,註冊所述待處理語音數據所對應用戶標識的聲紋模型;或者,
將所述待處理語音數據的第二聲學特徵與已註冊的各用戶標識的聲紋模型進行匹配,確定所述待處理語音數據對應的用戶標識。
本發明還提供了一種建立聲學特徵提取模型的裝置,該裝置包括:
數據獲取單元,用於將從各用戶標識對應的語音數據中分別提取的第一聲學特徵,作為訓練數據;
模型訓練單元,用於利用所述訓練數據訓練深度神經網絡,得到聲學特徵提取模型;其中所述深度神經網絡的訓練目標為:最大化相同用戶的第二聲學特徵之間的相似度且最小化不同用戶的第二聲學特徵之間的相似度。
根據本發明一優選實施方式,所述第一聲學特徵包括:fbank64聲學特徵。
根據本發明一優選實施方式,所述深度神經網絡包括:卷積神經網絡cnn、殘差卷積神經網絡rescnn或者門控遞歸單元gru。
根據本發明一優選實施方式,所述模型訓練單元,具體用於:
利用深度神經網絡對各語音數據的第一聲學特徵進行學習,輸出各語音數據的第二聲學特徵;
利用所述各語音數據的第二聲學特徵計算三元組損失,利用所述三元組損失對所述深度神經網絡進行調參,以最小化所述三元組損失;
其中,所述三元組損失體現不同用戶的第二聲學特徵之間的相似度與相同用戶的第二聲學特徵之間的相似度的差值狀況。
根據本發明一優選實施方式,所述模型訓練單元在利用深度神經網絡對各語音數據的第一聲學特徵進行學習,輸出各語音數據的第二聲學特徵時,具體執行:利用深度神經網絡對各語音數據的第一聲學特徵進行學習,輸出幀級別的第二聲學特徵;對幀級別的第二聲學特徵進行池化和語句標準化處理,輸出句子級別的第二聲學特徵;
在模型訓練單元計算三元組損失時利用的所述各語音數據的第二聲學特徵為各語音數據的句子級別的第二聲學特徵。
本發明還提供了一種提取聲學特徵的裝置,該裝置包括:
預處理單元,用於提取待處理語音數據的第一聲學特徵;
特徵提取單元,用於將所述第一聲學特徵輸入聲學特徵提取模型,得到待處理語音數據的第二聲學特徵;
其中所述聲學特徵提取模型是由上述建立聲學特徵提取模型的裝置預先建立的。
根據本發明一優選實施方式,該裝置還包括:
聲紋註冊單元,用於利用所述待處理語音數據的第二聲學特徵,註冊所述待處理語音數據所對應用戶標識的聲紋模型;或者,
聲紋匹配單元,用於將所述待處理語音數據的第二聲學特徵與已註冊的各用戶標識的聲紋模型進行匹配,確定所述待處理語音數據對應的用戶標識。
本發明提供了一種設備,包括
存儲器,包括一個或者多個程序;
一個或者多個處理器,耦合到所述存儲器,執行所述一個或者多個程序,以實現上述方法中執行的操作。
本發明還提供了一種計算機存儲介質,所述計算機存儲介質被編碼有電腦程式,所述程序在被一個或多個計算機執行時,使得所述一個或多個計算機執行上述方法中執行的操作。
由以上技術方案可以看出,本發明基於神經網絡,以最小化相同用戶的第二聲學特徵之間的相似度且最大化不同用戶的第二聲學特徵之間的相似度為目標,訓練得到聲學特徵提取模型。也就是說,本發明的聲學特徵提取模型能夠自學習到達到訓練目標的最優聲學特徵。相比較現有預設特徵類型和變換方式的聲學特徵提取方式,實現更加靈活,準確性更高。
【附圖說明】
圖1為本發明實施例提供的建立聲學特徵提取模型的方法流程圖;
圖2為本發明實施例提供的聲學特徵提取模型的結構示意圖;
圖3為本發明實施例提供的堆疊殘差塊的結構示意圖;
圖4為本發明實施例提供的提取聲學特徵的方法流程圖;
圖5為本發明實施例提供的建立聲學特徵提取模型的裝置結構圖;
圖6為本發明實施例提供的提取聲學特徵的裝置結構圖;
圖7為實現本發明實施方式的示例性計算機系統/伺服器的框圖。
【具體實施方式】
為了使本發明的目的、技術方案和優點更加清楚,下面結合附圖和具體實施例對本發明進行詳細描述。
在本發明實施例中使用的術語是僅僅出於描述特定實施例的目的,而非旨在限制本發明。在本發明實施例和所附權利要求書中所使用的單數形式的「一種」、「所述」和「該」也旨在包括多數形式,除非上下文清楚地表示其他含義。
應當理解,本文中使用的術語「和/或」僅僅是一種描述關聯對象的關聯關係,表示可以存在三種關係,例如,a和/或b,可以表示:單獨存在a,同時存在a和b,單獨存在b這三種情況。另外,本文中字符「/」,一般表示前後關聯對象是一種「或」的關係。
取決於語境,如在此所使用的詞語「如果」可以被解釋成為「在……時」或「當……時」或「響應於確定」或「響應於檢測」。類似地,取決於語境,短語「如果確定」或「如果檢測(陳述的條件或事件)」可以被解釋成為「當確定時」或「響應於確定」或「當檢測(陳述的條件或事件)時」或「響應於檢測(陳述的條件或事件)」。
本發明的核心思想在於,基於深度神經網絡提取語音數據的高層聲學特徵,訓練深度神經網絡的目標是最大化相同用戶的高層聲學特徵之間的相似度且最小化不同用戶的高層聲學特徵之間的相似度,從而得到聲學特徵提取模型。該聲學特徵提取模型用於提取語音數據的高層聲學特徵。
另外,在進行聲學特徵提取模型的訓練時,需要首先對訓練數據中的語音數據進行低層聲學特徵的提取,即進行預處理。其中該低層聲學特徵相對於高層聲學特徵粒度更粗,包含信息量也更粗;相反,經過聲學特徵提取模型處理後得到的高層聲學特徵相對於低層聲學特徵粒度更細,包含信息量也更細緻,更適於建立聲紋模型,以進行用戶聲紋的建立。在本發明實施例中,為了對這兩種聲學特徵進行區分,將對語音數據進行預處理後得到的低層聲學特徵稱為第一聲學特徵;將經過聲學特徵提取模型對低層聲學特徵進行處理後,得到的高層聲學特徵稱為第二聲學特徵。
在本發明中存在兩個階段:聲學特徵提取模型的建立階段以及利用聲學特徵提取模型提取聲學特徵的階段。其中兩個階段互相獨立,聲學特徵提取模型的建立階段可以是預先執行的階段,但也可以在後續過程中不斷對聲學特徵提取模型進行更新。下面結合實施例對這兩個進行詳細描述。
圖1為本發明實施例提供的建立聲學特徵提取模型的方法流程圖,如圖1所示,該方法可以包括以下步驟:
在101中,從各用戶標識對應的語音數據中分別提取第一聲學特徵,作為訓練數據。
可以預先採集已知用戶的語音數據,在選擇訓練數據時可以對這些語音數據有一些質量要求,例如選取清晰度較好的語音數據,再例如刪除長度過長或過短的語音數據,等等。
對於採集到的語音數據首先進行預處理,從中提取各語音數據的第一聲學特徵。如前面所述的,該第一聲學特徵是低層的聲學特徵。在本發明實施例中可以採用fbank(mel-scalefilterbank,梅爾標度濾波器組)特徵作為第一聲學特徵。例如,以25ms為一幀、10ms為步長提取語音數據的fbank特徵。但本發明並不限於fbank特徵,還可以採用其他特徵作為第一聲學特徵。
這樣,就可以得到各用戶標識對應的第一聲學特徵,從而構成訓練數據。其中本發明並不限定用戶標識的具體類型,可以是任意類型的標識,只要能夠區分用戶即可。在訓練數據中可以包含同一用戶對應的不同語音數據的第一聲學特徵,不同用戶對應的語音數據的第一聲學特徵,等等。訓練數據中各第一聲學特徵均具有對應的用戶標識作為標籤。
在102中,利用各語音數據的第一聲學特徵,訓練深度神經網絡,得到聲學特徵提取模型;其中深度神經網絡的訓練目標為:最大化相同用戶的第二聲學特徵之間的相似度且最小化不同用戶的第二聲學特徵之間的相似度。
本步驟中,可以首先利用深度神經網絡對各語音數據的第一聲學特徵進行學習,輸出各語音數據的第二聲學特徵。然後利用各語音數據的第二聲學特徵計算三元組損失,將三元組損失反饋給深度神經網絡,以便調整深度神經網絡的參數以最小化該三元組損失。
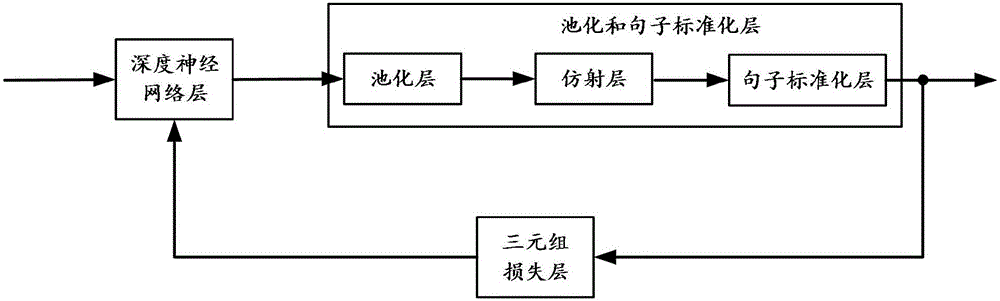
為了方便對本發明實施例提供的聲學特徵提取模型的理解,對該聲學特徵提取模型的結構進行介紹。如圖2所示,該聲學特徵提取模型可以包括深度神經網絡層、池化和句子標準化層以及三元組損失層。
其中,深度神經網絡可以採用cnn、gru(gatedrecurrentunit,門控遞歸單元)等,當然也可以採用其他諸如rnn、lstm等其他類型的深度神經網絡。由於cnn相比較rnn、lstm等而言,能夠更加有效地減小頻譜變化以及將頻譜相關性在聲學特徵中進行體現,因此在本發明實施例中優選cnn這種類型的深度神經網絡。
然而,儘管深度神經網絡具有很好地學習能力,但更難進行訓練,在一定深度情況下準確性反而下滑。為了解決該問題,本發明可以基於cnn使用但不限於resnet(residualnet,殘差網絡)型cnn,或者採用gru。
首先對resnet型cnn進行介紹。
resnet可以用於簡化cnn的訓練。resnet包括若干resblock(堆疊殘差塊),各resblock包括低層輸出和高層輸入間的直接連接。如圖3中所示,各resblock可以定義為:
h=f(x,wi)+x
其中,x和h分別表示resblock的輸入和輸出。f表示堆疊的非線性層的映射函數。
如圖3所示,resblock可以包括兩個卷積層和兩個激活層。其中,兩個卷積層可以包括諸如3×3的過濾器和1×1的stride(步幅)。每個resblock包括相同的結構,並且跳轉連接是對x的相同映射。若通道的數量增加,則可以使用一個卷積層(例如具有5×5的過濾器和2×2的stride)。因此,頻率維度始終在卷積層中保持恆定。經過研究發現,語音識別在時間維度上對stride並不敏感。在本發明實施例中,可以使用如下relu(rectifiedlinearunits,修正線性)函數作為所有激活層的非線性處理:
σ(x)=min{max{x,0},20}
下面對gru進行介紹。
gru相比較lstm而言,訓練速度更快且發散程度更小。本發明實施例中深度神經網絡層可以採用多個gru構成。例如,每個gru可以包括一個5×5過濾器和2×2stride的卷積層,能夠減少時域和頻域的維度,從而允許gru的計算速度更快。緊接著卷積層的是三個具有1024個單元的前向gru層,在時間維度上進行循環。在gru中也可以採用諸如relu進行激活。
緊接著深度神經網絡層的是池化和句子標準化層。池化和句子標準化層用來對深度神經網絡層輸出的幀級別的第二聲學特徵進行池化和句子標準化處理,從而得到句子級別的第二聲學特徵。
具體地,如圖2所示,池化和句子標準化層可以包括:池化層、仿射層和句子標準化層。
其中池化層用於將幀級別的輸入轉變為句子級別的表示,即將幀級別的第二聲學特徵進行取平均,得到句子級別的第二聲學特徵。
池化層的輸出h'可以採用如下公式:
其中,t為句子包含的幀數目,x'(t)為池化層的輸入。
經過池化(pooling)層的處理,使得本發明實施例提供的聲學特徵提取模型能夠處理不同時長的語句,解決了文本無關的情況。
仿射層將句子級別的第二聲學特徵投射到預設的維度,例如投射到512維度。
長度標準化層將仿射層輸出的句子級別的第二聲學特徵的長度進行規整,使模為1。
本發明實施例中,三元損失層採用三元損失對深度神經網絡層進行反饋訓練,以最大化相同用戶的第二聲學特徵之間的相似度且最小化不同用戶的第二聲學特徵之間的相似度。
三元損失層可以採用三個樣本作為輸入:錨樣本,包括一個用戶的句子級別的第二聲學特徵;正樣本,包括與錨樣本同一用戶的另一句子級別的第二聲學特徵;負樣本,包括與錨樣本不同用戶的句子級別的第二聲學特徵。將上述樣本構成一個三元組。
三元損失層對深度神經網絡層進行反饋,以使得錨樣本和正樣本之間的餘弦相似度(在本發明實施例中樣本之間的相似度採用餘弦相似度體現,但不排除其他相似度計算方式)大於錨樣本和負樣本之間的餘弦相似度。形式上,
其中,為三元組i中錨樣本a和正樣本p之間的餘弦相似度。為三元組i中錨樣本a和正樣本n之間的餘弦相似度。訓練目標是找到這些相似度中的最小邊緣α。即計算三元組損失,該三元組損失體現不同用戶的第二聲學特徵之間的相似度與相同用戶的第二聲學特徵之間的相似度的差值狀況。例如該三元組損失的計算函數l可以為:
其中,n為三元組的數目,操作符[x]+=max(x,0)。
計算出的三元組損失反饋給深度神經網絡層,以不斷調整深度神經網絡層的參數,從而逐漸訓練深度神經網絡,最終最小化利用提取的第二聲學特徵計算的三元組損失。訓練結束後,得到聲學特徵提取模型,此次訓練過程結束。
圖4為本發明實施例提供的提取聲學特徵的方法流程圖,該流程基於如圖1所示實施例建立的聲學特徵提取模型。如圖4所示,該方法可以包括以下步驟:
在401中,提取待處理語音數據的第一聲學特徵。
本步驟是對待處理語音數據的預處理,即從中提取第一聲學特徵,該第一聲學特徵是低層的聲學特徵。此處提取的第一聲學特徵的類型和方式與圖1所示實施例中步驟101中提取第一聲學特徵的類型和方式一致。在此不再贅述。
在402中,將提取出的第一聲學特徵輸入聲學特徵提取模型,得到待處理語音數據的第二聲學特徵。
對於預先訓練得到的聲學特徵提取模型,由於其從訓練數據中已經完成從第一聲學特徵到第二聲學特徵的自學習,因此將步驟401中提取出的待處理語音數據的第一聲學特徵輸入聲學特徵提取模型,聲學特徵提取模型就能夠輸出待處理語音數據的第二聲學特徵。該第二聲學特徵可以為句子級別的高層聲學特徵。
在得到待處理語音數據的第二聲學特徵後,可以利用第二聲學特徵進行後續應用的處理,例如在403a中,利用待處理語音數據的第二聲學特徵,註冊該待處理語音數據所對應用戶標識的聲紋模型,或者在403b中,將待處理語音數據的第二聲學特徵與已註冊的各用戶標識的聲紋模型進行匹配,確定待處理語音數據對應的用戶標識。
在403a中,若待處理語音數據對應的用戶標識已知,則可以利用提取的第二聲學特徵註冊該用戶標識對應的聲紋模型。在註冊聲紋模型時,可以將提取的第二聲學特徵進行處理後,作為聲紋信息存儲於聲紋模型庫中。可以利用用戶標識對應的一個或多個第二聲學特徵來進行聲學模型的註冊,具體註冊過程本發明不做具體限制。
在403b中,若待處理語音數據對應的用戶標識未知,則可以利用提取的第二聲學特徵與聲紋模型庫中各已註冊的聲紋模型進行匹配,例如通過計算提取的第二聲學特徵與聲紋模型庫中各聲紋模型之間相似度的方式進行匹配。若匹配到某個聲紋模型,則可以確定該待處理語音數據對應該匹配到的聲紋模型對應的用戶標識。
上述403a和403b是本發明實施例提供的兩種在提取語音數據的第二聲學特徵後,對其的應用方式,當然除了這兩種應用方式之外,還可以進行其他應用,本發明不做一一窮舉。
上述方法可以應用於語音識別系統中,執行主體可以為對應裝置,該裝置可以是位於用戶設備的應用,或者還可以為位於用戶設備的應用中的插件或軟體開發工具包(softwaredevelopmentkit,sdk)等功能單元。其中,用戶設備可以包括但不限於諸如:智能移動終端、智能家居設備、網絡設備、可穿戴式設備、智能醫療設備、pc(個人計算機)等。其中智能行動裝置可以包括諸如手機、平板電腦、筆記本電腦、pda(個人數字助理)、網際網路汽車等。智能家居設備可以包括智能家電設備,諸如智能電視、智能空調、智能熱水器、智能冰箱、智能空氣淨化器等等,智能家居設備還可以包括智能門鎖、智能電燈、智能攝像頭等。網絡設備可以包括諸如交換機、無線ap、伺服器等。可穿戴式設備可以包括諸如智能手錶、智能眼鏡、智能手環、虛擬實境設備、增強現實設備、混合現實設備(即可以支持虛擬實境和增強現實的設備)等等。智能醫療設備可以包括諸如智能體溫計、智能血壓儀、智能血糖儀等等。
圖5為本發明實施例提供的建立聲學特徵提取模型的裝置結構圖,該裝置可以用於執行如圖1中所示的操作。如圖5所示,該裝置可以包括:數據獲取單元01和模型訓練單元02。其中各組成單元的主要功能如下:
數據獲取單元01負責將從各用戶標識對應的語音數據中分別提取的第一聲學特徵,作為訓練數據。
可以預先採集已知用戶的語音數據,在選擇訓練數據時可以對這些語音數據有一些質量要求,例如選取清晰度較好的語音數據,再例如刪除長度過長或過短的語音數據,等等。
在本發明實施例中可以採用fbank特徵作為第一聲學特徵。例如,以25ms為一幀、10ms為步長提取語音數據的fbank特徵。但本發明並不限於fbank特徵,還可以採用其他特徵作為第一聲學特徵。
模型訓練單元02負責利用訓練數據訓練深度神經網絡,得到聲學特徵提取模型;其中深度神經網絡的訓練目標為:最大化相同用戶的第二聲學特徵之間的相似度且最小化不同用戶的第二聲學特徵之間的相似度。
優選地,本發明實施例中採用的深度神經網絡可以包括:cnn、rescnn或者gru。rescnn和gru的相關描述參見方法實施例中的記載,在此不再贅述。
具體地,模型訓練單元02可以首先利用深度神經網絡對各語音數據的第一聲學特徵進行學習,輸出各語音數據的第二聲學特徵;然後利用各語音數據的第二聲學特徵計算三元組損失,將三元組損失反饋給深度神經網絡,以便調整深度神經網絡的參數以最小化三元組損失;其中,三元組損失體現不同用戶的第二聲學特徵之間的相似度與相同用戶的第二聲學特徵之間的相似度的差值狀況。
更具體地,模型訓練單元02在利用深度神經網絡對各語音數據的第一聲學特徵進行學習,輸出各語音數據的第二聲學特徵時,可以具體執行:利用深度神經網絡對各語音數據的第一聲學特徵進行學習,輸出幀級別的第二聲學特徵;對幀級別的第二聲學特徵進行池化和語句標準化處理,輸出句子級別的第二聲學特徵。此時,在模型訓練單元02計算三元組損失時利用的各語音數據的第二聲學特徵為各語音數據的句子級別的第二聲學特徵。
對於聲學特徵提取模型的具體架構以及該架構中各層次所執行的具體處理可以參見方法實施例中的相關描述,在此不再贅述。
圖6為本發明實施例提供的提取聲學特徵的裝置結構圖,如圖6所示,該裝置可以包括:預處理單元11和特徵提取單元12。其中各組成單元的主要功能如下:
預處理單元11負責提取待處理語音數據的第一聲學特徵。該第一聲學特徵的類型和提取方式與圖5中數據獲取單元01獲取訓練數據時所採用的第一聲學特徵的類型和提取方式一致。例如,第一聲學特徵可以採用fbank特徵。
特徵提取單元12負責將第一聲學特徵輸入聲學特徵提取模型,得到待處理語音數據的第二聲學特徵。
在得到待處理語音數據的第二聲學特徵後,可以利用第二聲學特徵進行後續應用的處理,例如該裝置還可以包括:
聲紋註冊單元(圖中未示出),負責利用待處理語音數據的第二聲學特徵,註冊該待處理語音數據所對應用戶標識的聲紋模型。
再例如,該裝置還可以包括:
聲紋匹配單元(圖中未示出),負責將待處理語音數據的第二聲學特徵與已註冊的各用戶標識的聲紋模型進行匹配,確定待處理語音數據對應的用戶標識。
圖7示出了適於用來實現本發明實施方式的示例性計算機系統/伺服器012的框圖。圖7顯示的計算機系統/伺服器012僅僅是一個示例,不應對本發明實施例的功能和使用範圍帶來任何限制。
如圖7所示,計算機系統/伺服器012以通用計算設備的形式表現。計算機系統/伺服器012的組件可以包括但不限於:一個或者多個處理器或者處理單元016,系統存儲器028,連接不同系統組件(包括系統存儲器028和處理單元016)的總線018。
總線018表示幾類總線結構中的一種或多種,包括存儲器總線或者存儲器控制器,外圍總線,圖形加速埠,處理器或者使用多種總線結構中的任意總線結構的局域總線。舉例來說,這些體系結構包括但不限於工業標準體系結構(isa)總線,微通道體系結構(mac)總線,增強型isa總線、視頻電子標準協會(vesa)局域總線以及外圍組件互連(pci)總線。
計算機系統/伺服器012典型地包括多種計算機系統可讀介質。這些介質可以是任何能夠被計算機系統/伺服器012訪問的可用介質,包括易失性和非易失性介質,可移動的和不可移動的介質。
系統存儲器028可以包括易失性存儲器形式的計算機系統可讀介質,例如隨機存取存儲器(ram)030和/或高速緩存存儲器032。計算機系統/伺服器012可以進一步包括其它可移動/不可移動的、易失性/非易失性計算機系統存儲介質。僅作為舉例,存儲系統034可以用於讀寫不可移動的、非易失性磁介質(圖7未顯示,通常稱為「硬碟驅動器」)。儘管圖7中未示出,可以提供用於對可移動非易失性磁碟(例如「軟盤」)讀寫的磁碟驅動器,以及對可移動非易失性光碟(例如cd-rom,dvd-rom或者其它光介質)讀寫的光碟驅動器。在這些情況下,每個驅動器可以通過一個或者多個數據介質接口與總線018相連。存儲器028可以包括至少一個程序產品,該程序產品具有一組(例如至少一個)程序模塊,這些程序模塊被配置以執行本發明各實施例的功能。
具有一組(至少一個)程序模塊042的程序/實用工具040,可以存儲在例如存儲器028中,這樣的程序模塊042包括——但不限於——作業系統、一個或者多個應用程式、其它程序模塊以及程序數據,這些示例中的每一個或某種組合中可能包括網絡環境的實現。程序模塊042通常執行本發明所描述的實施例中的功能和/或方法。
計算機系統/伺服器012也可以與一個或多個外部設備014(例如鍵盤、指向設備、顯示器024等)通信,在本發明中,計算機系統/伺服器012與外部雷達設備進行通信,還可與一個或者多個使得用戶能與該計算機系統/伺服器012交互的設備通信,和/或與使得該計算機系統/伺服器012能與一個或多個其它計算設備進行通信的任何設備(例如網卡,數據機等等)通信。這種通信可以通過輸入/輸出(i/o)接口022進行。並且,計算機系統/伺服器012還可以通過網絡適配器020與一個或者多個網絡(例如區域網(lan),廣域網(wan)和/或公共網絡,例如網際網路)通信。如圖所示,網絡適配器020通過總線018與計算機系統/伺服器012的其它模塊通信。應當明白,儘管圖7中未示出,可以結合計算機系統/伺服器012使用其它硬體和/或軟體模塊,包括但不限於:微代碼、設備驅動器、冗餘處理單元、外部磁碟驅動陣列、raid系統、磁帶驅動器以及數據備份存儲系統等。
處理單元016通過運行存儲在系統存儲器028中的程序,從而執行各種功能應用以及數據處理,例如實現一種建立聲學特徵提取模型的方法,可以包括:
將從各用戶標識對應的語音數據中分別提取的第一聲學特徵,作為訓練數據;
利用所述訓練數據訓練深度神經網絡,得到聲學特徵提取模型;
其中所述深度神經網絡的訓練目標為:最大化相同用戶的第二聲學特徵之間的相似度且最小化不同用戶的第二聲學特徵之間的相似度。
再例如,實現一種提取聲學特徵的方法,可以包括:
提取待處理語音數據的第一聲學特徵;
將所述第一聲學特徵輸入聲學特徵提取模型,得到待處理語音數據的第二聲學特徵。
上述的電腦程式可以設置於計算機存儲介質中,即該計算機存儲介質被編碼有電腦程式,該程序在被一個或多個計算機執行時,使得一個或多個計算機執行本發明上述實施例中所示的方法流程和/或裝置操作。例如,被上述一個或多個處理器執行的方法流程,可以包括:
將從各用戶標識對應的語音數據中分別提取的第一聲學特徵,作為訓練數據;
利用所述訓練數據訓練深度神經網絡,得到聲學特徵提取模型;
其中所述深度神經網絡的訓練目標為:最大化相同用戶的第二聲學特徵之間的相似度且最小化不同用戶的第二聲學特徵之間的相似度。
再例如,被上述一個或多個處理器執行的方法流程,可以包括:
提取待處理語音數據的第一聲學特徵;
將所述第一聲學特徵輸入聲學特徵提取模型,得到待處理語音數據的第二聲學特徵。
隨著時間、技術的發展,介質含義越來越廣泛,電腦程式的傳播途徑不再受限於有形介質,還可以直接從網絡下載等。可以採用一個或多個計算機可讀的介質的任意組合。計算機可讀介質可以是計算機可讀信號介質或者計算機可讀存儲介質。計算機可讀存儲介質例如可以是——但不限於——電、磁、光、電磁、紅外線、或半導體的系統、裝置或器件,或者任意以上的組合。計算機可讀存儲介質的更具體的例子(非窮舉的列表)包括:具有一個或多個導線的電連接、可攜式計算機磁碟、硬碟、隨機存取存儲器(ram)、只讀存儲器(rom)、可擦式可編程只讀存儲器(eprom或快閃記憶體)、光纖、可攜式緊湊磁碟只讀存儲器(cd-rom)、光存儲器件、磁存儲器件、或者上述的任意合適的組合。在本文件中,計算機可讀存儲介質可以是任何包含或存儲程序的有形介質,該程序可以被指令執行系統、裝置或者器件使用或者與其結合使用。
計算機可讀的信號介質可以包括在基帶中或者作為載波一部分傳播的數據信號,其中承載了計算機可讀的程序代碼。這種傳播的數據信號可以採用多種形式,包括——但不限於——電磁信號、光信號或上述的任意合適的組合。計算機可讀的信號介質還可以是計算機可讀存儲介質以外的任何計算機可讀介質,該計算機可讀介質可以發送、傳播或者傳輸用於由指令執行系統、裝置或者器件使用或者與其結合使用的程序。
計算機可讀介質上包含的程序代碼可以用任何適當的介質傳輸,包括——但不限於——無線、電線、光纜、rf等等,或者上述的任意合適的組合。
可以以一種或多種程序設計語言或其組合來編寫用於執行本發明操作的電腦程式代碼,所述程序設計語言包括面向對象的程序設計語言—諸如java、smalltalk、c++,還包括常規的過程式程序設計語言—諸如「c」語言或類似的程序設計語言。程序代碼可以完全地在用戶計算機上執行、部分地在用戶計算機上執行、作為一個獨立的軟體包執行、部分在用戶計算機上部分在遠程計算機上執行、或者完全在遠程計算機或伺服器上執行。在涉及遠程計算機的情形中,遠程計算機可以通過任意種類的網絡——包括區域網(lan)或廣域網(wan)連接到用戶計算機,或者,可以連接到外部計算機(例如利用網際網路服務提供商來通過網際網路連接)。
由以上描述可以看出,本發明提供的上述方法、裝置、設備和計算機存儲介質可以具備以下優點:
1)本發明的聲學特徵提取模型能夠自學習到達到訓練目標的最優聲學特徵。相比較現有預設特徵類型和變換方式的聲學特徵提取方式,實現更加靈活,準確性更高。
2)本發明中優選rescnn或gru類型的深度神經網絡,從而在採用較高層級深度的神經網絡情況下,也能夠保證特徵提取的準確性,且提高深度神經網絡的訓練速度。
3)本發明在訓練聲學特徵提取模型的過程中,對深度神經網絡的輸出進行池化和句子標準化處理,使得該模型除了能夠對文本相關的語音數據進行特徵提取之外,也能夠對文本無關的語音數據進行很好地特徵提取。
4)經過試驗後發現,本發明能夠更好的處理大規模的語音數據並且能夠很好地適應不同語言的處理。
在本發明所提供的幾個實施例中,應該理解到,所揭露的方法、裝置和設備,可以通過其它的方式實現。例如,以上所描述的裝置實施例僅僅是示意性的,例如,所述單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式。
所述作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位於一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本實施例方案的目的。
另外,在本發明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個單元中。上述集成的單元既可以採用硬體的形式實現,也可以採用硬體加軟體功能單元的形式實現。
以上所述僅為本發明的較佳實施例而已,並不用以限制本發明,凡在本發明的精神和原則之內,所做的任何修改、等同替換、改進等,均應包含在本發明保護的範圍之內。