知識圖譜構建系統的製作方法
2023-06-24 18:56:56 1
本發明屬於大規模數據挖掘技術領域,具體涉及一種知識圖譜構建系統。
背景技術:
知識圖譜的構建對於智能對話知識性問題的理解與準確回答有著極大的作用;因此對於對話系統的後臺,如何快速有效的從大量的規則和不規則數據中挖掘出有價值的知識信息,成為構建知識圖譜的關鍵。這其中需要通過爬蟲進行海量相關數據的抓取和存儲;對後臺抓取的數據進行數據處理,提取相關的信息;對於提取的信息,結構化的數據可以以相對簡單的方式處理入庫。對於非結構化的信息,要通過分詞,命名實體識別,文本聚類,文本分類等算法進一步做數據處理;最後通過一系列的數據挖掘算法挖掘諸如頻繁項的挖掘等,以一定的方式進入後臺的審核系統,在通過人工審核後,入庫。
目前的工程應用中,或者不存在知識發現到入庫這一完整的知識圖譜全生命周期系統設計;或者已有的系統設計在處理海量數據時效率偏低,難以滿足大規模知識挖掘和知識發現的應用需求。
技術實現要素:
針對現有的大規模知識挖掘和知識發現應用中系統設計不佳導致的效率偏低問題,本發明提出一種知識圖譜構建系統。本發明提出的知識圖譜構建系統可以快速構建知識發現和知識入庫的體系架構。
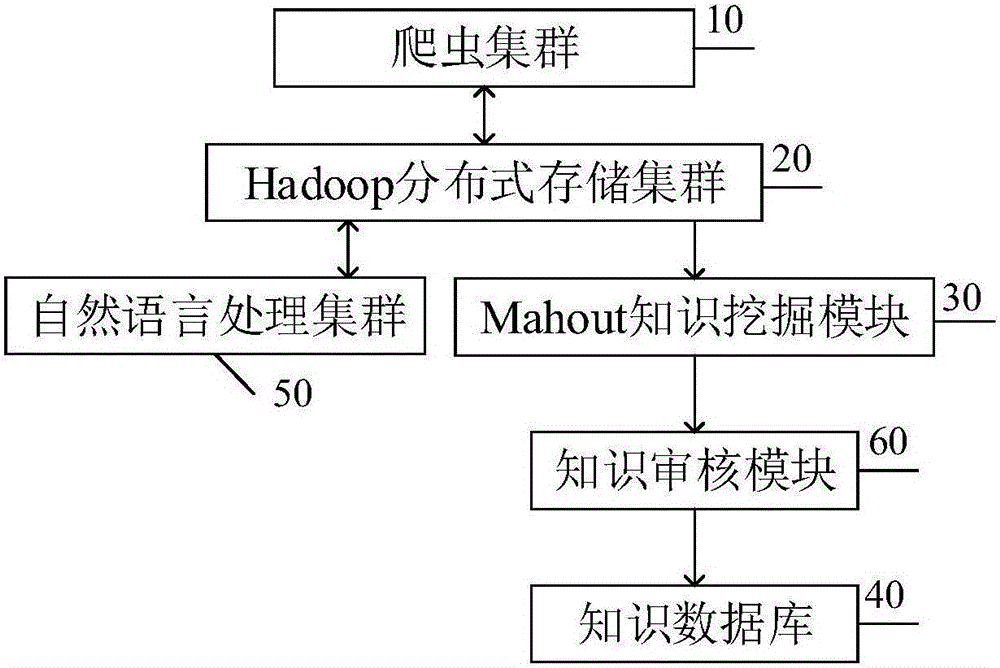
本發明提出的知識圖譜構建系統,包括爬蟲集群、Hadoop分布式存儲集群、自然語言處理集群、Mahout知識挖掘模塊和知識資料庫;該爬蟲集群用於根據種子地址,抓取網頁數據,並將該網頁數據存儲在網頁HBase表中,該網頁HBase表存儲在該Hadoop分布式存儲集群中;該自然語言處理集群用於從該Hadoop分布式存儲集群中獲取該網頁HBase表,生成原始知識信息,並將該原始知識信息存儲在原始知識HBase表中,該原始知識HBase表存儲在該Hadoop分布式存儲集群中;該Mahout知識挖掘模塊用於對該原始知識信息進行知識挖掘,生成非結構化數據,並將該非結構化數據存儲在非結構化數據HBase表中,該非結構化數據HBase表存儲在該Hadoop分布式存儲集群中;該知識資料庫用於根據經過人工審核的該非結構化數據構建知識圖譜。
進一步地,本發明提出的知識圖譜構建系統,還包括知識審核模塊;該知識審核模塊用於獲取該非結構化數據,並獲取對應於該非結構化數據的人工審核信息,並在人工審核信息為審核通過時,將該非結構化數據發送給該知識資料庫。
進一步地,本發明提出的知識圖譜構建系統,還包括結構化數據處理模塊;該結構化處理模塊用於利用Jsoup工具從該網頁數據中提取結構化數據,並發送給該知識資料庫;該知識資料庫還用於根據該結構化數據構建該知識圖譜。
進一步地,本發明提出的知識圖譜構建系統,該爬蟲集群包括多個爬蟲伺服器節點;該Hadoop分布式存儲集群還用於存儲HBase邏輯分表;每個該爬蟲伺服器節點用於根據從該HBase邏輯分表獲取的第一組種子表抓取網頁數據,並將該網頁數據存儲在該網頁HBase表中;該第一組種子表中包括多個待抓取的URL;該HBase邏輯分表中包括該多個爬蟲伺服器節點待抓取的URL的總和。
進一步地,本發明提出的知識圖譜構建系統,每個該爬蟲伺服器節點還用於在完成該第一組種子表後,根據從該HBase邏輯分表獲取的第二組種子表抓取網頁數據;該HBase邏輯分表在檢測到該第一組種子表完成後立即被更新。
進一步地,本發明提出的知識圖譜構建系統,該爬蟲集群還包括一個安裝有Ansible的運維伺服器節點;該運維伺服器節點與該多個爬蟲伺服器節點連接。
進一步地,本發明提出的知識圖譜構建系統,該Hadoop分布式存儲集群還包括Map/Reduce運算模塊;該Map/Reduce運算模塊用於對該種子表,該HBase邏輯分表和/或該網頁HBase表進行統計和更新。
進一步地,本發明提出的知識圖譜構建系統,該自然語言處理集群包括至少一個自然語言處理伺服器節點,該自然語言處理伺服器節點配置有HanNLP工具。
進一步地,本發明提出的知識圖譜構建系統,該知識資料庫為配置有Jena圖關係資料庫的Hadoop集群。
本發明提出的知識圖譜構建系統基於Hadoop平臺,應用HBase資料庫、Mahout知識挖掘算法實現了從大數據抓取、大數據挖掘到人工審核知識入庫的整個系統構建。
附圖說明
為了更清楚地說明本發明具體實施方式或現有技術中的技術方案,下面將對具體實施方式或現有技術描述中所需要使用的附圖作簡單地介紹。在所有附圖中,類似的元件或部分一般由類似的附圖標記標識。附圖中,各元件或部分並不一定按照實際的比例繪製。
圖1示出了本發明實施例知識圖譜構建系統的組成示意圖;
圖2示出了本發明實施例知識圖譜構建系統實現知識審核時的組成示意圖;
圖3示出了本發明實施例知識圖譜構建系統處理結構化數據時的組成示意圖;
圖4示出了本發明實施例知識圖譜構建系統設置有運維工具和統計工具時的組成示意圖。
具體實施方式
下面將結合附圖對本發明技術方案的實施例進行詳細的描述。以下實施例僅用於更加清楚地說明本發明的技術方案,因此只是作為示例,而不能以此來限制本發明的保護範圍。
需要注意的是,除非另有說明,本申請使用的技術術語或者科學術語應當為本發明所屬領域技術人員所理解的通常意義。
需要說明的是,Hadoop平臺、Mahout算法、Jsoup工具、HanNLP工具、Jena圖關係資料庫、HBase資料庫支持的各HBase表;Map/Reduce並行運算框架、Ansible運維工具、LNMP分別具有本發明所屬領域技術人員所理解的通常意義,這裡不再贅述。
實施例
如圖1所示,本實施例知識圖譜構建系統,包括爬蟲集群10、Hadoop分布式存儲集群20、自然語言處理集群50、Mahout知識挖掘模塊30和知識資料庫40;爬蟲集群10用於根據種子地址,抓取網頁數據,並將網頁數據存儲在網頁HBase表中,網頁HBase表存儲在Hadoop分布式存儲集群中;自然語言處理集群50用於從Hadoop分布式存儲集群中獲取網頁HBase表,生成原始知識信息,並將原始知識信息存儲在原始知識HBase表中,原始知識HBase表存儲在Hadoop分布式存儲集群中;Mahout知識挖掘模塊30用於對原始知識信息進行知識挖掘,生成非結構化數據,並將非結構化數據存儲在非結構化數據HBase表中,非結構化數據HBase表存儲在Hadoop分布式存儲集群中;知識資料庫40用於根據經過人工審核的非結構化數據構建知識圖譜。
需要說明的是,每個爬蟲節點會根據自己的機器名在hbase中生成屬於自己的獨一無二的url種子表和對應的存放抓取網頁的表,也即url種子表是由爬蟲節點自行生成的,而不是由統一的爬蟲集群管理工具根據每個爬蟲集群的機器名為之統一分配的。
對應的存放抓取網頁的表是由爬蟲節點自行生成的,並存儲在Hadoop分布式存儲集群中。
需要說明的是,具體實施時,本實施例知識圖譜構建系統中的Mahout知識挖掘模塊30和知識資料庫40,可以分別單獨設置,也可以設置在Hadoop分布式存儲集群20中,也可以組合實施並完成組合後的功能。但是,Mahout知識挖掘模塊30和知識資料庫40目前都是基於Hadoop平臺的,以實現較好的兼容性。
需要說明的是,Mahout算法工具是基於hadoop平臺的一個算法包Mahout算法工具應用與自然語言處理集群是分開的,可以應用在知識挖掘模塊及應用在頻繁規則發現的算法。
本實施例知識圖譜構建系統基於Hadoop平臺,應用HBase資料庫、Mahout知識挖掘算法實現了從大數據抓取、大數據挖掘到人工審核知識入庫的整個系統構建。
如圖2所示,具體應用時,本實施例知識圖譜構建系統,還可以包括知識審核模塊60;知識審核模塊60用於獲取非結構化數據,並獲取對應於非結構化數據的人工審核信息,並在人工審核信息為審核通過時,將非結構化數據發送給知識資料庫40。
需要說明的是,知識審核模塊和知識資料庫是兩個獨立的模塊,知識審核模塊的輸入數據是mahout處理爬蟲數據後產生的待審核數據知識審核模塊對待審核數據進行審核,審核通過就會通過審核模塊程序寫入知識資料庫40中。
其中,Mahout知識挖掘模塊利用Mahout算法包處理非結構化數據,運用頻繁規則發現等算法發現知識。
本實施例知識圖譜構建系統給出了針對非結構化數據進行知識審核的方法。
如圖3所示,具體應用時,本實施例知識圖譜構建系統,還可以包括結構化數據處理模塊70;結構化處理模塊用於利用Jsoup工具從網頁數據中提取結構化數據,並發送給知識資料庫;知識資料庫還用於根據結構化數據構建知識圖譜。
需要說明的是,具體實施時,本實施例知識圖譜構建系統中的結構化數據處理模塊70可以分別單獨設置,也可以設置在Hadoop分布式存儲集群20中,也可以設置在知識資料庫40中。
本實施例知識圖譜構建系統給出了針對結構化數據進行處理的方法。
如圖4所示,具體應用時,本實施例知識圖譜構建系統,爬蟲集群還可以包括多個爬蟲伺服器節點11;Hadoop分布式存儲集群還用於存儲HBase邏輯分表;每個爬蟲伺服器節點用於根據從HBase邏輯分表獲取的第一組種子表抓取網頁數據,並將網頁數據存儲在網頁HBase表中;種子表中包括多個待抓取的URL;HBase邏輯分表中包括多個爬蟲伺服器節點待抓取的URL的總和。
具體應用時,本實施例知識圖譜構建系統,每個爬蟲伺服器節點還可以用於在完成第一組種子表後,根據從HBase邏輯分表獲取第二組種子表抓取網頁數據;HBase邏輯分表在檢測到第一組種子表完成後立即被更新。
需要說明的是,種子地址和抓取地址指的都是url,種子地址指的是爬蟲系統每個爬蟲節點起始的抓取地址,比如抓取新浪一般是從新浪的首頁抓取,那麼新浪首頁就是種子地址。一般種子地址是手動配置,等爬蟲開抓以後就會源源不斷產生新的抓取地址。
也即種子地址url可以衍生出抓取地址url。不同爬蟲節點之間自動負載平衡時,在完成為自己指定的任務之後,分擔的其他爬蟲節點的任務時,可能分擔的是其他爬蟲節點的種子地址url,也可能是衍生出的抓取地址url。
本實施例知識圖譜構建系統給出了爬蟲集群的組成及各爬蟲伺服器節點的工作方式。
如圖4所示,具體應用時,本實施例知識圖譜構建系統,爬蟲集群還包括一個安裝有Ansible的運維伺服器節點12;運維伺服器節點12與多個爬蟲伺服器節點11連接。
本實施例知識圖譜構建系統利用安裝有Ansible的運維伺服器節點對爬蟲集群進行管理。
如圖4所示,具體應用時,本實施例知識圖譜構建系統,Hadoop分布式存儲集群還包括Map/Reduce運算模塊21;Map/Reduce運算模塊21用於對種子表,HBase邏輯分表和/或網頁HBase表進行統計和更新。
本實施例知識圖譜構建系統利用Map/Reduce運算模塊進行業務統計和更新。
具體應用時,本實施例知識圖譜構建系統,自然語言處理集群包括至少一個自然語言處理伺服器節點,自然語言處理伺服器節點配置有HanNLP工具。
具體應用時,本實施例知識圖譜構建系統,知識資料庫為配置有Jena圖關係資料庫的Hadoop集群。
以下對知識圖譜構建系統進行具體說明。
爬蟲伺服器節點伺服器抓取到的網頁數據和待爬取的種子地址分別採用HBase表存儲於基於Hadoop的分布式文件存儲平臺,優選地,為Hadoop分布式存儲集群。
爬蟲集群工作時,首先將要抓取的地址放在HBase邏輯分表,每個爬蟲伺服器節點負責抓取自己的種子表,當自己的種子表完成後,以預先設定的策略去分擔其他任務負載比較重的爬蟲伺服器節點的種子表內的部分任務;這時,這兩個爬蟲伺服器節點的種子表及HBase邏輯分表都將動態更新為最新的任務分配狀態。
網頁HBase表記錄一條網頁的基本信息,其欄位包括:網頁地址,網頁源碼,網頁抓取時間等。
爬蟲集群通過配置文件實現爬蟲伺服器節點與HBase邏輯分表中的種子表,網頁HBase表,以及種子分發表等實現邏輯對應關係。邏輯對應關係主要指創建的HBase邏輯分表可以表明網頁HBase表是依靠不同的爬蟲伺服器節點完成的;種子地址表的表名以爬蟲伺服器節點的機器名為唯一標識,每個爬蟲伺服器節點有唯一的種子表名與之對應。
爬蟲集群的部署、運行和維護由Ansible運維工具進行控制。Ansible運維工具是一個對多個節點伺服器進行統一命令執行的工具。通過編寫安裝腳本,在一臺Ansible機器上執行安裝腳本,就能夠實現在多個伺服器節點上無差異地安裝某種軟體。Ansible運維工具能夠極大地提高爬蟲集群的運維效率。
Hadoop分布式存儲集群還包括Map/Reduce運算模塊;爬蟲集群還與Map/Reduce運算模塊協同工作。Map/Reduce運算模塊用於對種子表,HBase邏輯分表和/或網頁HBase表進行統計和更新。
具體地,Map/Reduce是基於Hadoop平臺的並行計算框架,Map/Reduce運算模塊主要對種子表,抓取頁面的表(是指網頁HBase表)進行一系列的計算,如對爬蟲已經抓取和將要抓取的存儲在HBase表裡的數據進行統計,比如統計抓取總數,每天數據增加量等。另外,還包括爬蟲種子均衡分發控制等。
與現有技術相比,綜合應用了Map/Reduce並行計算框架、Hadoop平臺及HBase資料庫及Ansible運維工具,本實施例知識圖譜構建系統由爬蟲集群實現的知識抓取步驟,是一整套的完整解決方案,在商業中得到了成熟運用,能夠支持億級數據的抓取和處理。
Hadoop分布式存儲集群為知識圖譜構建系統後臺處理數據的存儲模塊,其中爬蟲集群抓取的網頁數據以及經過自然語言處理後的原始知識信息分別存儲在對應的HBase表中,即網頁HBase表、原始知識HBase表、非結構化數據HBase表;最終獲得的知識圖譜數據存儲於Jena圖關係資料庫中。
在Hadoop平臺上配置HBase資料庫,有著很高的可靠性、兼容性和穩定性。
目前分布式Spark在處理速度上優於Hadoop,但鑑於Spark的穩定性不如Hadoop,及知識圖譜數據屬於後臺數據,實時性要求並不是第一優先需要保證的,相對而言,對其穩定性要求的優先級更高,所以選擇Hadoop分布式存儲集群作為整個系統的存儲和並行計算處理平臺。
優選地,從成本、可兼容性、安全性角度考慮,Hadoop分布式存儲集群的作業系統無關一般採用Linux。
與現有技術相比,綜合應用了Hadoop平臺、HBase資料庫及Jena圖關係資料庫,本實施例知識圖譜構建系統的存儲集群採用業界主流技術,通用性好,有著很高的可靠性、兼容性和穩定性。
由於數據處理壓力較大,自然語言處理集群部署在多臺自然語言處理伺服器節點上。這多臺自然語言處理伺服器的配置、功能是等同的,可以相互替換,並可以多臺協同工作。在具體應用時,隨機選擇一個或多個自然語言處理伺服器節點進行數據處理。
自然語言處理可以認為是對抓取的數據進行預處理。自然語言處理用於對抓取的數據進行分詞、句法分析等基本的語義理解。
本實施例知識圖譜構建系統的自然語言處理伺服器節點申請配置有HanNLP工具,並進行了二次開發,從而在現有的基礎上進行功能強化,如:分詞功能中加入大量的詞典。詞典主要是用戶詞典,添加一系列需要關注的各行業關鍵詞,比如人名、地名等。強化分詞功能可以更準確地更好挖掘人物之間的關係
進一步地,利用Mahout知識挖掘模塊進行知識挖掘,採用關聯規則等算法進行實體識別和多實體關係識別。Mahout知識挖掘模塊也配置有HanNLP工具。如命名實體識別中針對人名和地名在現有HanNLP基礎上增加人名地名的正則表達式,從而降低Mahout算法識別人名地名時候的錯誤率,提高命名實體的識別正確率。語料是指大量出現人名的資料,比如人民日報的語料中間會大量出現國家領導人的姓名,那麼基於這些語料就可以用概率算法計算一些字組合的凝聚度,從而計算出疑似人名。進一步地,基於大量的語料使用n-gram分割算法,對於大量的詞頻進行計算,可以進行疑似新詞發現。
綜上所述,本實施例知識圖譜構建系統的自然語言處理及知識挖掘都基於HanNLP工具進行了二次開發,包括分詞,關鍵詞提取,句法分析,命名實體識別等,從而提高了Mahout算法的正確率。
Mahout算法運行在Hadoop平臺,也是Hadoop平臺生態的一系列機器學習算法包。這系列算法運行完成後會生成原始知識信息。
生成的原始知識信息屬於非結構化數據,存儲在在非結構化數據HBase表中,非結構化數據HBase表則存儲在所述Hadoop分布式存儲集群中。
本實施例知識圖譜構建系統,還包括結構化數據處理模塊;結構化處理模塊用於利用Jsoup工具從網頁數據中提取結構化數據,並發送給知識資料庫;知識資料庫還用於根據結構化數據構建知識圖譜。
相比於非結構化數據,結構化數據的處理較為簡單。本實施例知識圖譜構建系統利用Jsoup工具從爬蟲集群抓取的網頁數據中提取出結構化數據,並發送給知識資料庫,用於構建知識圖譜。
本實施例知識圖譜構建系統還包括知識審核模塊;知識審核模塊用於獲取非結構化數據,並獲取對應於非結構化數據的人工審核信息,並在人工審核信息為審核通過時,將非結構化數據發送給知識資料庫。
知識審核模塊用於對前述產生的非結構化數據中表徵的知識請求人工審核,人工審核合格就進入Jena資料庫,正式作為知識圖譜中的有效知識。
知識審核模塊配置有Mahout算法工具,用於對得到的非結構化數據中表徵的知識進行人工審核。可以支持批量審核和單條審核。知識審核模塊基於LNMP開發,可以做成網頁訪問的形式,並通過普通的臺式機進行訪問。
人工審核通過的知識數據根據知識類別進入Jena圖關係資料庫,從而完成後臺知識的挖掘生成工作。其中,知識類別包括人物類,地理類等。優選地,知識類別的劃分基於Mahout算法工具進行。
本實施例知識圖譜構建系統設置有大規模分布式數據抓取和存儲架構,包括定時增量抓取,後臺監控統計等模塊的設計,實現從海量網頁數據中提取結構化和非結構化數據。對於非結構化數據進行數據處理,包括文本分類,聚類,自然語言處理(分詞,句法分析等),從中發現命名實體,命名實體屬性和多個命名實體之間的關係。還設置有人工審核環節,並將通過審核的規則自動導入Jena圖關係資料庫,實現了整個知識圖譜構件系統的穩定架構設計。
最後應說明的是:以上各實施例僅用以說明本發明的技術方案,而非對其限制;儘管參照前述各實施例對本發明進行了詳細的說明,本領域的普通技術人員應當理解:其依然可以對前述各實施例所記載的技術方案進行修改,或者對其中部分或者全部技術特徵進行等同替換;而這些修改或者替換,並不使相應技術方案的本質脫離本發明各實施例技術方案的範圍,其均應涵蓋在本發明的權利要求和說明書的範圍當中。