處理圖數據的方法和裝置與流程
2023-09-17 19:31:40 3
本發明實施例涉及數據處理領域,尤其涉及一種處理圖數據的方法和裝置。
背景技術:
圖是一種抽象的數據結構,能夠描述豐富的信息以及信息之間的依賴關係。現有技術中存在很多基於圖數據的算法,如最短路徑算法、圖模擬算法、網頁排名算法以及廣度優先搜索等算法。圖數據及其相關算法的應用無處不在,如社交網絡分析、語義Web分析、生物信息科學和交通導航等。
隨著這些應用的迅速發展,它們涉及的圖數據的規模也變得越來越大,動輒有上億的頂點和數十億條邊。如何高效地存儲和處理大規模圖數據也越來越受到學術界和工業界的關注。
現有技術主要採用映射化簡(MapReduce)系統存儲和處理圖數據。具體地,MapReduce系統一般使用分布式文件系統(Distributed File System,DFS)存儲圖數據,當需要處理該圖數據時,一般由MapReduce系統的主控節點調度整個系統的計算節點(Map計算節點和Reduce計算節點)對圖數據進行多輪MapReduce作業(MapReduce job),得到圖數據的處理結果。
現有技術中,MapReduce系統對圖數據進行處理時,在Map階段只是針對輸入文件進行逐條數據的計算,在處理圖數據的過程中表現為以單個頂點為計算對象,其中每個頂點包含自身和出邊的信息,每輪MapReduce作業過程中,消息被限制為只能沿出邊進行單步傳遞,以進行下一輪MapReduce作業,當圖數據的規模很大時,需要進行多輪MapReduce作業,導致圖數據的處理效率低下。
技術實現要素:
本發明實施例提供了一種處理圖數據的方法和裝置,以提高圖數據的處理效率。
第一方面,本發明實施例提供了一種處理圖數據的方法,該方法包括:確定待處理的圖數據,該圖數據對應的圖被劃分成多個子圖;調度映射化簡MapReduce系統中的計算節點,對該圖數據進行多輪MapReduce作業,以得到該圖數據的處理結果,其中,該MapReduce作業中的每個Map計算節點用於處理該多個子圖中的一個子圖內的具有相互連接關係的頂點。
結合第一方面,在第一方面的第一種可能的實現方式中,該方法還包括:該多個子圖包括m個子圖,該圖數據存儲在分布式文件系統DFS中,該DFS包括與該m個子圖一一對應的m個第一文件,以及與該m個子圖一一對應的m個第二文件,其中,該m個第一文件分別用於存儲該m個子圖對應的子圖數據,該m個第二文件分別用於存儲該m個子圖中的被處理過的頂點對應的消息數據,該調度MapReduce系統中的計算節點,對該圖數據進行多輪MapReduce作業,包括:為該多輪MapReduce作業中的每輪MapReduce作業分配待處理的子圖;根據該待處理的子圖,從該m個第一文件和該m個第二文件中選取該每輪MapReduce作業的輸入數據,該輸入數據包括該待處理的子圖對應的子圖數據,以及該每輪MapReduce作業的上一輪MapReduce作業處理得到的消息數據;根據該輸入數據,進行該每輪MapReduce作業。
結合第一方面的第一種可能的實現方式,在第一方面的第二種可能的實現方式中,該方法還包括:該根據該輸入數據,進行該每輪MapReduce作業,包括:根據該輸入數據,為該每輪MapReduce作業的Map計算節點和Reduce計算節點分配計算任務;控制該每輪MapReduce作業中的Reduce計算節點將處理得到的消息數據存入該m個第二文件中。
結合第一方面、第一方面的第一種或第二種可能的實現方式,在第一方面的第三種實現方式中,該方法還包括:根據公式gr=(nid*m)/N,將該圖劃分成該多個子圖,其中,gr取值相同的頂點被劃分到同一子圖,nid為該圖中的頂點的編號,m為該子圖的個數,N為該圖中的頂點的個數。
結合第一方面、第一方面的第一種至第三種可能的實現方式中的任一種可能的實現方式,在第一方面的第四種實現方式中,該方法還包括:該MapReduce作業中的每個Map計算節點按照廣度優先搜索BFS算法處理該具有相互連接關係的頂點。
第二方面,本發明實施例提供了一種處理圖數據的裝置,該裝置包括: 確定模塊,用於確定待處理的圖數據,該圖數據對應的圖被劃分成多個子圖;調度模塊,用於調度映射化簡MapReduce系統中的計算節點,對該圖數據進行多輪MapReduce作業,以得到該圖數據的處理結果,其中,該MapReduce作業中的每個Map計算節點用於處理該多個子圖中的一個子圖內的具有相互連接關係的頂點。
結合第二方面,在第二方面的第一種可能的實現方式中,該多個子圖包括m個子圖,該圖數據存儲在分布式文件系統DFS中,該DFS包括與該m個子圖一一對應的m個第一文件,以及與該m個子圖一一對應的m個第二文件,其中,該m個第一文件分別用於存儲該m個子圖對應的子圖數據,該m個第二文件分別用於存儲該m個子圖中的被處理過的頂點對應的消息數據,該調度模塊具體用於:為該多輪MapReduce作業中的每輪MapReduce作業分配待處理的子圖;根據該待處理的子圖,從該m個第一文件中和該m個第二文件中選取該每輪MapReduce作業的輸入數據,該輸入數據包括該待處理的子圖對應的子圖數據,以及該每輪MapReduce作業的上一輪MapReduce作業處理得到的消息數據;根據該輸入數據,進行該每輪MapReduce作業。
結合第二方面的第一種可能的實現方式,在第二方面的第二種可能的實現方式中,該調度模塊具體用於:根據該輸入數據,為該每輪MapReduce作業的Map計算節點和Reduce計算節點分配計算任務;根據控制該每輪MapReduce作業中的Reduce計算節點將處理得到的消息數據存入該m第二個文件中。
結合第二方面、第二方面的第一種或第二種可能的實現方式,在第二方面的第三種可能的實現方式中,該裝置還包括:劃分模塊,用於根據公式gr=(nid*m)/N,將該圖劃分成該多個子圖,其中,gr取值相同的頂點被劃分到同一子圖,nid為該圖中的頂點的編號,m為該子圖的個數,N為該圖中的頂點的個數。
結合第二方面、第二方面的第一種至第三種可能的實現方式中的任一種可能的實現方式,在第二方面的第四種實現方式中,該MapReduce作業中的每個Map計算節點按照廣度優先搜索BFS算法處理該具有相互連接關係的頂點。
本發明實施例中,首先將待處理的圖數據對應的圖劃分成多個子圖,然 後每輪MapReduce作業中,每個Map計算節點每次處理多個子圖中的一個子圖內部的具有連接關係的頂點,使得每輪MapReduce作業儘可能處理更多的頂點,從而能夠減少了MapReduce作業的輪數,提高圖數據的處理效率。
附圖說明
為了更清楚地說明本發明實施例的技術方案,下面將對本發明實施例中所需要使用的附圖作簡單地介紹,顯而易見地,下面所描述的附圖僅僅是本發明的一些實施例,對於本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
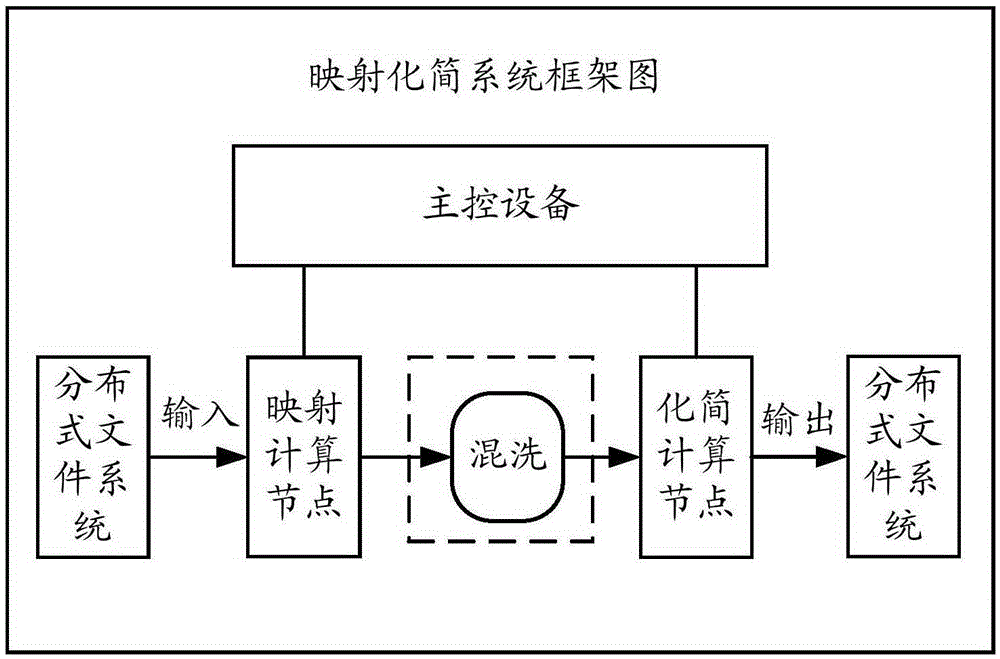
圖1是根據本發明實施例的一種處理圖數據的方法的映射化簡系統的示意性框圖。
圖2是根據本發明實施例的一種處理圖數據的方法的示意性流程圖。
圖3是根據本發明另一實施例的映射化簡作業流程圖。
圖4是根據本發明另一實施例的圖劃分的示意圖。
圖5是根據本發明另一實施例的處理圖數據的方法的示意性流程圖。
圖6是根據本發明另一實施例的處理圖數據的方法的示意性流程圖。
圖7是根據本發明又一實施例的處理圖數據的裝置的示意性框圖。
圖8是根據本發明又一實施例的處理圖數據的裝置的示意性框圖。
具體實施方式
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例是本發明的一部分實施例,而不是全部實施例。基於本發明中的實施例,本領域普通技術人員在沒有做出創造性勞動的前提下所獲得的所有其他實施例,都應屬於本發明保護的範圍。
圖1示出了可以應用本發明實施例的處理圖數據的方法的一種MapReduce系統的示意性框圖。如圖1所示,該系統可以包括DFS,Map計算節點和Reduce計算節點。處理圖數據的實現過程一般需要採用某種遍歷方式遍歷圖數據,因此處理一個完整的圖數據通常需要多輪MapReduce作業(job)。其中,Map計算節點包括至少一個Map計算節點,對應Map階段;Reduce計算節點包括至少一個Reduce計算節點,對應Reduce階段。 在Map階段,Map計算節點對輸入的數據進行處理,獲得中間計算結果或消息數據。在Reduce階段,Reduce計算節點對輸入的數據進行化簡操作,得到化簡後的消息數據,並保存在DFS中。其中,Map階段到Reduce階段之間可以經過一個混洗(Shuffle)階段,在Shuffle過程中將中間計算結果從磁碟中取出,在進行合併以及排序操作後,傳輸給Reduce計算節點作為Reduce階段的輸入數據。
應理解,如圖1所示,本發明實施例的處理圖數據的方法可以由主控設備執行。主控設備負責圖數據處理過程中所有的工作設備的調度和計算任務的分配,例如,主控設備可以調度Map計算節點、Reduce計算節點,並控制Map計算節點、Reduce計算節點的任務分配,或者控制Map計算節點從DFS中讀取需要的數據,或者控制Reduce計算節點把處理過的消息數據存入DFS之中。
應理解,本發明實施例的處理圖數據的方法和裝置可以應用於最短路徑算法、圖模擬算法、強模擬算法、網頁排名算法或廣度優先搜索算法(Breadth First Search,簡稱為「BFS」)等圖算法中,且並不限於此,還可以應用於其它圖算法。
應理解,本發明實施例中的分布式文件系統DFS,可以是Hadoop分布式文件系統(Hadoop Distributed File System,簡稱為「HDFS」),可以是網絡文件系統(Network File System,簡稱為「NFS」),可以是谷歌文件系統(Google File System,簡稱為「GFS」),也可以是其它任何分布式文件系統,本發明並不限於此。
圖2根據示出了本發明實施例的一種處理圖數據的方法200的示意性流程圖。如圖2所示,該方法200包括:
S210,確定待處理的圖數據,該圖數據對應的圖被劃分成多個子圖;
S220,調度映射化簡MapReduce系統中的計算節點,對該圖數據進行多輪MapReduce作業,以得到該圖數據的處理結果,其中,該MapReduce作業中的每個Map計算節點用於處理該多個子圖中的一個子圖內的具有相互連接關係的頂點。
可選地,該待處理的圖數據可以位於DFS中,上述確定待處理的圖數據可以包括確定待處理的圖數據在DFS系統中的存儲位置,以便於控制MapReduce系統中的計算節點從該存儲位置獲取MapReduce作業需要 的數據。
應理解,圖數據對應的圖被劃分為多個子圖,每個子圖可以對應一個子圖數據,圖數據可以包括該多個子圖中每個子圖對應的子圖數據。其中,每個子圖對應的子圖數據中可以包含子圖內的頂點的信息以及子圖內的頂點的連接關係的信息,其中,該子圖內的頂點的連接關係的信息可以包括該子圖內的頂點之間的連接關係的信息,也可以包括該子圖內的頂點到其它子圖內的頂點的連接關係的信息。
應理解,在確定待處理的圖數據之後,可以調度MapReduce中的計算節點,對待處理的圖數據進行MapReduce作業,以得到該圖數據的處理結果。對該圖數據的MapReduce作業可以包括多輪MapReduce作業。其中,每輪MapReduce作業中的每個Map計算節點處理一個子圖內的具有相互連接關係的頂點,或者,每個Map計算節點處理一個子圖內的具有相互連接關係的一組頂點或多組頂點。換句話說,每個Map計算節點的輸入數據可以包括一個子圖對應的子圖數據,該每個Map計算節點可用於處理一個子圖對應的子圖數據。可以這樣理解,在每輪MapReduce作業過程中,可以利用每個子圖內部頂點之間的連接關係,把存在連接關係的頂點放在同一個Map計算節點中進行處理,現有技術中,每輪MapReduce作業中的每個Map計算節點處理是孤立的頂點,在處理頂點時並沒有考慮或利用頂點之間的連接關係,是一種以頂點為中心的處理方式,而本發明實施例中,每輪MapReduce作業中的每個Map計算節點利用了一個子圖內部頂點之間的連接關係,把子圖數據中有連接關係的頂點當作一個計算對象進行處理,是一種以子圖為中心的處理方式。
例如,當其中一個Map計算節點在處理子圖內的頂點時,如果與該處理的頂點存在連接關係的頂點也屬於該子圖時,則可以在同一輪MapReduce作業中處理與該頂點存在連接關係的頂點。從而可以在一輪MapReduce作業過程中處理更多的頂點,進而減少圖數據,尤其是大規模圖數據處理過程中的MapReduce作業的輪數。在現有技術中,由於採取了以頂點為計算對象的MapReduce作業方式,處理頂點產生的消息只能沿出邊進行單邊傳遞,而本發明實施例的處理圖數據的方法中,採取了以子圖為計算對象的方法,消息數據在同一子圖內部的頂點之間可以進行多步傳遞,所以在一輪MapReduce作業過程中,可以同時處理同一 子圖內部存在連接關係的頂點,從而減少處理圖數據所需的處理的MapReduce作業輪數。由於採取了以子圖為中心的計算模型,在圖數據處理過程中利用子圖數據內頂點之間的連接關係,將計算粒度擴展為整個子圖,減少了MapReduce作業的輪數,從而提高圖數據處理的計算速度和計算效率,減少資源和時間的開銷。
可選地,作為一個實施例,可以將子圖的頂點分為內部頂點和邊界頂點兩類。其中,內部頂點表示與該內部頂點相連的所有頂點都屬於同一子圖。邊界頂點表示與該邊界頂點相連的至少一個頂點不屬於該邊界頂點所在的子圖。可選地,可以定義圖數據為圖G=(V,E),其中,V和E分別表示頂點集合和邊集合,邊集合中的邊用於表示頂點之間的連接關係。可以定義子圖數據為(G1[V1],...Gk[Vk]),表示圖數據G按頂點劃分得到的k個子圖,其中V1∪V2∪...∪Vk=V,且
另外,可以定義在子圖Gi[Vi](i∈[1,k])中,若ν∈Vi滿足條件{μ|(ν,μ)∈E∧μ∈Vi},則ν為內部頂點,若ν不滿足上述條件,則ν為邊界頂點。子圖之間通過邊界頂點進行通信,在每輪MapReduce作業過程中產生的中間結果以及消息數據在內部頂點之間完成多步傳遞以實現多步計算,然後沿邊界頂點傳輸給其它相關聯的子圖,以便於進行下一輪MapReduce作業的計算。
在本發明實施例中,通過將待處理的圖數據對應的圖劃分成多個子圖,在MapReduce作業中的Map計算節點以子圖為計算對象,每次處理一個子圖內的具有連接關係的頂點,充分利用了子圖內頂點的連接關係,使得每輪MapReduce作業儘可能處理更多的頂點,從而減少了處理圖數據所需的MapReduce作業的輪數,提高了圖數據的處理效率。
如圖1所示,Map階段到Reduce階段之間可以經過一個混洗(Shuffle)階段,在Shuffle過程中將中間計算結果從磁碟中取出,在進行合併以及排序操作後,傳輸給Reduce計算節點作為Reduce階段的輸入數據。圖數據在圖算法實現過程中屬於不變的數據,也即圖數據在每輪MapReduce作業過程中都保持不變,通常情況下圖數據的數據量相對較大,並且在每輪MapReduce作業過程中都會使用到。而消息數據屬於變化的數據,通常情況下消息數據的數據量都比較小。但是現有技術中在進行MapReduce作業時並沒有區分圖數據和消息數據,所以圖數據需要在每輪MapReduce作業的 過程中進行重複的處理並進行Shuffle。這種對於圖數據的重複讀寫以及網絡傳輸,造成了很大的開銷,極大地影響了圖數據的處理效率。
可選地,作為一個實施例,該多個子圖可以包括m個子圖,該圖數據存儲在分布式文件系統DFS中,該DFS包括與該m個子圖一一對應的m個第一文件,以及與該m個子圖一一對應的m個第二文件,其中,該m個第一文件分別用於存儲該m個子圖對應的子圖數據,該m個第二文件分別用於存儲該m個子圖中的被處理過的頂點對應的消息數據。
可選地,在S220中,調度MapReduce系統中的計算節點,對該圖數據進行多輪MapReduce作業,包括:為該多輪MapReduce作業中的每輪MapReduce作業分配待處理的子圖;根據該待處理的子圖,從該m個第一文件和該m個第二文件中選取該每輪MapReduce作業的輸入數據,該輸入數據包括該待處理的子圖對應的子圖數據,以及該每輪MapReduce作業的上一輪MapReduce作業處理得到的消息數據;根據該輸入數據,進行該每輪MapReduce作業。
在本發明實施例中,因為採取了對圖數據和消息數據分開處理的方式,把在整個MapReduce作業過程中始終保持不變的圖數據抽離出來,單獨保存在DFS中,並且每輪MapReduce作業產生的消息數據也被保存在DFS中與圖數據對應的位置。在每輪MapReduce作業的開始,從DFS中讀取需要的圖數據和消息數據作為本輪MapReduce的輸入數據。在每輪MapReduce作業過程中,Map計算節點在處理完子圖數據後,無需向其它計算節點傳輸圖數據,所以在Shuffle過程中也不需要傳輸圖數據,從而能夠減少圖數據在計算過程中帶來的I/O開銷以及在Shuffle過程中的通信開銷,進而加快了圖數據的處理速度。
例如,圖3示出了本發明另一實施例的映射化簡作業流程圖,如圖3所示,可選地,圖數據被劃分成指定數量的子圖數據之後被保存在DFS中。而消息數據可以是每輪MapReduce作業的結果,消息數據和子圖數據一一對應。消息數據在經過Reduce計算節點處理之後也可以被保存在DFS之中。在每輪MapReduce作業開始時,Map節點從DFS中讀取需要的消息數據和圖數據,並將消息數據和圖數據進行合併,作為本輪MapReduce作業中的Map計算節點的輸入數據。
具體地,消息數據又稱為消息,可以是每輪MapReduce作業處理的結 果。子圖和消息數據具有一一對應的關係。消息數據可以和子圖數據合併在一起,作為每輪MapReduce作業的輸入數據。例如,在DFS中,可以將放置m個子圖數據的文件命名為Gi(i∈[1,m]),將放置與m個子圖對應的消息數據的文件命名為Mi(i∈[1,m]),該Gi個文件與該Mi個文件一一對應。可以按照DFS的文件命名規則,把對應的Gi和Mi命名為相同的文件名。當MapReduce作業中的計算節點需要讀取輸入數據時,可以重載MapReduce的CombineFileInputFormat類,邏輯上將相同文件名的Gi和Mi合併成一個文件,作為Map計算節點的輸入。
可選地,根據該輸入數據,進行每輪MapReduce作業,包括:根據該輸入數據,為每輪MapReduce作業的Map計算節點和Reduce計算節點分配計算任務;控制該每輪MapReduce作業中的Reduce計算節點將處理得到的消息數據存入該m個第二文件中。
可選地,在每輪MapReduce作業中,當Reduce計算節點獲取本輪MapReduce的消息數據後,主控設備控制Reduce計算節點把消息數據存儲在與m個子圖一一對應的相應的m個第二文件中,以便於下輪MapReduce作業開始時,從該m個第二文件中讀取需要的輸入數據。從而使圖數據和消息數據能夠分開進行處理,減少了圖數據在計算過程中帶來的I/O開銷以及在Shuffle過程中的通信開銷,從而加快了圖數據的處理速度。
上文結合圖1至圖3描述了處理圖數據的方法的具體實施方式。下文將結合圖4至圖5,以BFS為例,說明本發明實施例的處理圖數據的方法的其中一種具體實現方案。
如圖4所示,首先待處理的圖G被劃分成三個子圖G1、G2、G3。其中V1=[1,2],V2=[3,4],V3=[5,6],其中,每個子圖中虛線標識的頂點用於表示不屬於該子圖但與該子圖有邊相連的頂點。其中,以頂點3為源點,計算的中間結果以消息的形式沿邊傳遞給相鄰頂點,直到遍歷到所有的可達頂點結束計算。由圖4可知,在圖G中,頂點3為源點,即起始的頂點,頂點3的出邊消息對應頂點1和頂點4,頂點1的出邊消息對應頂點2和頂點5,頂點4的出邊消息對應頂點1和頂點5,頂點2的出邊消息對應頂點6,頂點5的出邊消息對應頂點2和頂點6。具體地,圖5示出了本發明實施例處理圖G的MapReduce作業過程,其中虛線標識的頂點代表下輪MapReduce作業的起始的頂點,灰色標識的頂點代表已 經處理完的頂點。如圖5所示,在第一輪MapReduce作業過程中,Map計算節點以子圖G2為計算對象,由於頂點3和頂點4有連接關係,且頂點4與頂點3處於同一子圖,所以處理完頂點3產生的數據會傳遞給頂點4,可以在同一輪MapReduce作業過程中處理G2中的頂點3和頂點4,以獲得第一輪MapReduce作業的消息數據。同時,因為頂點4和子圖G1中的頂點1以及子圖G3中頂點5都有連接關係,所以將在本輪MapReduce作業得到的頂點4的消息數據傳給頂點1和頂點5,以便於進行下一輪MapReduce作業。在第二輪MapReduce作業過程中,因為子圖G1中的頂點2和頂點1有連接關係,子圖G3中的頂點5跟頂點6有連接關係,所以Map計算節點分別以子圖G1和子圖G3為計算對象,處理子圖G1中的頂點1和頂點2以及子圖G3中的頂點5和頂點6,以獲得第二輪MapReduce作業的消息數據。經過兩輪MapReduce作業可以處理完圖G中的所有頂點。
在現有技術中並沒有劃分子圖,而是採取以頂點為計算對象的圖數據處理方式。圖6示出了現有技術中處理圖G的MapReduce作業過程,其中虛線標識的頂點代表下輪MapReduce作業的起始的頂點,灰色標識的頂點代表已經處理完的頂點。如圖6所示,當以頂點為計算對象時,對於圖G,在第一輪MapReduce作業中,首先處理頂點3,獲得頂點3的消息數據後,將頂點3的消息數據傳給頂點1和頂點4;在第二輪MapReduce作業中,處理頂點1和頂點4,並將頂點1的消息數據傳遞給頂點2和頂點5,將頂點4的消息數據傳給頂點1和頂點5;在第三輪MapReduce作業中,處理頂點2和頂點5,並將頂點2的消息數據傳遞給頂點6,將頂點5的消息數據傳送給頂點2和頂點6;在第四輪MapReduce作業中,處理頂點6,以獲得本輪MapReduce作業的消息數據。經過四輪MapReduce作業處理完圖G中所有的頂點。
由此具體實施例可見,本發明實施例的處理圖數據的方法與現有技術相比較,MapReduce作業輪數明顯減少,從而提高了圖數據的處理效率。
可選地,在MapReduce編程框架下,為了實現以子圖為計算對象的計算模型,可以在Map階段重寫Mapper類的的setup、Map、clean三個函數。setup函數的作用是Map開始之前做一些相關工作的初始化,而clean函數則是在Map計算完成之後進行收尾工作,並且setup和 clean函數在Map階段可以只執行一次。因此,首先,使用setup函數初始化一個HashMap結構用於保存整個子圖;之後,Map函數逐條讀取頂點數據並映射到HashMap結構中;最後,在clean函數中可以按需要對已保存在HashMap中的整個子圖進行自定義計算。以BFS為例,Map階段實現本發明實施例的處理圖數據的方法的關鍵偽代碼可以如下所示。
應理解,本發明實施例提供的處理圖數據的方法,圖數據對應的圖被劃分為多個子圖時,在MapReduce作業實現過程中可以採用hash的方法劃分子圖。但是MapReduce分布式計算框架在設計過程中並沒有考慮圖數據內部的關聯關係,所以採用hash的方法劃分子圖時並沒有考慮子圖內部的頂點的連接關係。如果在保證負載均衡的前提下,將有邊相連的頂點儘可能的分到同一子圖,同時儘量減少跨子圖的邊的數量,則在一輪MapReduce作業過程中可以同時處理同一子圖內更多的頂點,從而可以減少處理圖數據所需的MapReduce作業的輪數,提高圖數據的處理效率。換句話說,在劃分子圖時可以充分考慮到圖數據的局部性特徵,根據圖數據在實際應用中的自身特點,來劃分子圖。例如,交通網絡對應的圖中,相鄰頂點的編號相差很小。因此,可以按照頂點的編號順序劃分子圖,如1~1000,1001~2000…並分別保存在同一子圖對應的子圖數據中。
可選地,可以根據公式gr=(nid*m)/N,將圖數據對應的圖劃分成多個子圖,其中,gr取值相同的頂點被劃分到同一子圖中,nid為圖中的頂點的編號,m為子圖的個數,N為圖中的頂點的個數。
例如,若需要將包含N個頂點的圖劃分成m個子圖,可以按照公式gr=(nid*m)/N來劃分,其在MapReduce系統中實現的關鍵偽代碼可以如 下所示。
例如,對於交通網絡圖,還可以根據GIS位置信息進行劃分,如按照實際需要將一個市或者省的交通網絡作為一個子圖。實現時Map函數中gr值的計算需要解析GIS數據,提取位置信息。其在MapReduce系統中實現的關鍵偽代碼可以如下所示。
此外,對於社交網絡也可以使用相應的劃分子圖的方法。用戶在註冊社交網站提供的公開信息,如所在城市、工作單位或學校等都可以作為劃分子圖的依據。在通過MapReduce系統架構實現時將Map函數中的gr按需賦值即可。
在本發明實施例中,通過分析實際應用中涉及的圖數據的特點,在考慮到負載均衡的前提下,將有邊相連的頂點儘可能劃分到同一子圖內,同時削弱子圖之間的耦合性,可以進一步地減少處理圖數據所需的MapReduce作業輪數,提高圖數據的處理速度和計算效率。
在本發明實施例中,一方面,通過將待處理的圖數據對應的圖劃分成多個子圖,在MapReduce作業中的Map計算節點以子圖為計算對象,每次處理一個子圖內的具有連接關係的頂點,充分利用了子圖內頂點的連接關係,使得每輪MapReduce作業儘可能處理更多的頂點,從而減少了處理圖數據所需的MapReduce作業輪數,提高了圖數據的處理效率。另一方面,因為採取了對圖數據和消息數據分開處理的方式,把在整個MapReduce作業過程中始終保持不變的圖數據抽離出來,單獨保存在DFS中,並且每輪MapReduce作業產生的消息數據也被保存在DFS中與圖數據對應的位置。在每輪MapReduce作業的開始,從DFS中讀取需要的圖數據和消息數據作為本輪MapReduce的輸入數據。在每輪MapReduce作業過程中,Map計算節點在處理完子圖數據後,無需向其它計算節點傳輸圖數據,所以在Shuffle過程中也不需要傳輸圖數據,從而能夠減少圖數據在計算過程中帶來的I/O開銷以及在Shuffle過程中的通信開銷,進而加快了圖數據的處理速度。又一方面,本發明實施例採取的劃分子圖的方法,通過分析實際應用中涉及的圖數據的特點,在考慮到負載均衡的前提下,將有邊相連的頂點儘可能劃分到同一子圖內,同時削弱子圖之間的耦合性,可以進一步地減少處理圖數據所需的MapReduce作業輪數,提高圖數據的處理速度和計算效率。
上文結合圖1至圖6詳細闡述了本發明實施例的處理圖數據的方法的具體實施例,下文將結合圖7和圖8,詳細描述本發明實施例的處理圖數據的裝置。
圖7示出了本發明實施例的處理圖數據的裝置700的示意圖,應理解,根據本發明實施例的的裝置700可對應於本發明方法實施例中的主控設備,並且裝置700中的各個模塊的下述和其它操作和/或功能分別為了實現圖2至圖6中的各個方法的相應流程,為了簡潔,在此不再贅述。該裝置700包括:
確定模塊710,用於確定待處理的圖數據,該圖數據對應的圖被劃分成 多個子圖;
調度模塊720,用於調度映射化簡MapReduce系統中的計算節點,對該圖數據進行多輪MapReduce作業,以得到該圖數據的處理結果,其中,該MapReduce作業中的每個Map計算節點用於處理該多個子圖中的一個子圖內的具有相互連接關係的頂點。
在本發明實施例中,通過將待處理的圖數據對應的圖劃分成多個子圖,在MapReduce作業中的Map計算節點以子圖為計算對象,每次處理一個子圖內的具有連接關係的頂點,充分利用了子圖內頂點的連接關係,使得每輪MapReduce作業過程儘可能處理更多的頂點,從而減少了處理圖數據所需的MapReduce作業的輪數,提高了圖數據的處理效率。
在本發明實施例中,裝置700的確定模塊710確定的待處理的圖數據對應的圖被劃分成多個子圖,可選地,在本發明實施例中,該多個子圖包括m個子圖,該圖數據存儲在分布式文件系統DFS中,該DFS包括與該m個子圖一一對應的m個第一文件,以及與該m個子圖一一對應的m個第二文件,其中,該m個第一文件分別用於存儲該m個子圖對應的子圖數據,該m個第二文件分別用於存儲該m個子圖中的被處理過的頂點對應的消息數據。
可選地,本發明實施例的裝置700的調度模塊720具體用於:為該多輪MapReduce作業中的每輪MapReduce作業分配待處理的子圖;根據該待處理的子圖,從該m個第一文件中和該m個第二文件中選取該每輪MapReduce作業的輸入數據,該輸入數據包括該待處理的子圖對應的子圖數據,以及該每輪MapReduce作業的上一輪MapReduce作業處理得到的消息數據;根據該輸入數據,進行該每輪MapReduce作業。
在本發明實施例中,因為採取了對圖數據和消息數據分開處理的方式,把在整個MapReduce作業過程中始終保持不變的圖數據抽離出來,單獨保存在DFS中,並且每輪MapReduce作業產生的消息數據也被保存在DFS中與圖數據對應的位置。在每輪MapReduce作業的開始,從DFS中讀取需要的圖數據和消息數據作為本輪MapReduce的輸入數據。在每輪MapReduce作業過程中,Map計算節點在處理完子圖數據後,無需向其它計算節點傳輸圖數據,所以在Shuffle過程中也不需要傳輸圖數據,從而能夠減少圖數據在計算過程中帶來的I/O開銷以及在Shuffle過程中的通信開銷,進而加快了圖數據的處理速度。
可選地,該調度模塊720具體用於:根據該輸入數據,為該每輪MapReduce作業的Map計算節點和Reduce計算節點分配計算任務;控制該每輪MapReduce作業中的Reduce計算節點將處理得到的消息數據存入該m第二個文件中。
可選地,本發明實施例的裝置700還包括:劃分模塊730,用於根據公式gr=(nid*m)/N,將該圖劃分成該多個子圖,其中,gr取值相同的頂點被劃分到同一子圖,nid為該圖中的頂點的編號,m為該子圖的個數,N為該圖中的頂點的個數。
在本發明實施例中,通過分析實際應用中涉及的圖數據的特點,在考慮到負載均衡的前提下,將有邊相連的頂點儘可能劃分到同一子圖內,同時削弱子圖之間的耦合性,可以進一步地減少處理圖數據所需的MapReduce作業輪數,提高圖數據的處理效率。
圖8示出了本發明另一實施例的處理圖數據的裝置800,如圖8所示,該裝置800包括:處理器810,存儲器820,總線系統830。其中,該裝置800與MapReduce系統中的計算節點通過該總線系統830相連,該處理器810和該存儲器820通過該總線系統830相連,該存儲器820用於存儲指令,該處理器810用於執行該存儲器820存儲的指令,以便於處理器810控制該MapReduce系統中的計算節點進行的MapReduce作業。
該處理器810用於:確定待處理的圖數據,該圖數據對應的圖被劃分成多個子圖;調度MapReduce系統中的計算節點,對該圖數據進行多輪MapReduce作業,以得到該圖數據的處理結果;其中,該MapReduce作業中的至少一個Map計算節點中的每個Map計算節點用於處理該多個子圖中的一個子圖內的頂點,該頂點之間具有相互連接關係。
在本發明實施例中,通過將待處理的圖數據對應的圖劃分成多個子圖,在MapReduce作業中的Map計算節點以子圖為計算對象,每次處理一個子圖內的具有連接關係的頂點,充分利用了子圖內頂點的連接關係,使得每輪MapReduce作業過程儘可能處理更多的頂點,從而減少了處理圖數據所需的MapReduce作業輪數,提高了圖數據的處理效率。
應理解,在本發明實施例中,該處理器810可以是中央處理單元(Central Processing Unit,簡稱為「CPU」),該處理器810還可以是其他通用處理器、數位訊號處理器(DSP)、專用集成電路(ASIC)、現成可編程門陣列(FPGA) 或者其他可編程邏輯器件、分立門或者電晶體邏輯器件、分立硬體組件等。通用處理器可以是微處理器或者該處理器也可以是任何常規的處理器等。
該存儲器820可以包括只讀存儲器和隨機存取存儲器,並向處理器810提供指令和數據。存儲器820的一部分還可以包括非易失性隨機存取存儲器。例如,存儲器820還可以存儲設備類型的信息。
該總線系統830除包括數據總線之外,還可以包括電源總線、控制總線和狀態信號總線等。該總線系統830還可以包括內部總線、系統總線和外部總線。但是為了清楚說明起見,在圖中將各種總線都標為總線系統830。
在實現過程中,上述方法的各步驟可以通過處理器810中的硬體的集成邏輯電路或者軟體形式的指令完成。結合本發明實施例所公開的方法的步驟可以直接體現為硬體處理器執行完成,或者用處理器中的硬體及軟體模塊組合執行完成。軟體模塊可以位於隨機存儲器,快閃記憶體、只讀存儲器,可編程只讀存儲器或者電可擦寫可編程存儲器、寄存器等本領域成熟的存儲介質中。該存儲介質位於存儲器820,處理器810讀取存儲器820中的信息,結合其硬體完成上述方法的步驟。為避免重複,這裡不再詳細描述。
在本發明實施例中,該處理器810處理的圖數據對應的圖被劃分成多個子圖,可選地,該多個子圖為m個子圖,與該m個子圖一一對應的m個第一文件和與該m個子圖一一對應的m個第二文件被存儲在分布式文件系統DFS中,其中,該第一文件中的每個文件用於存儲該m個子圖中每個子圖對應的子圖數據,該第二文件中的每個文件用於存儲該每個子圖對應的消息數據。
可選地,該處理器810調度MapReduce系統中的計算節點,對該圖數據進行多輪MapReduce作業,具體包括:
為該多輪MapReduce作業中的每輪MapReduce作業分配待處理的子圖;
根據該待處理的子圖,從該m個第一文件中和該m個第二文件中選取該每輪MapReduce作業的輸入數據,該輸入數據包括該待處理的子圖的子圖數據,以及該每輪MapReduce作業的上一輪MapReduce作業處理得到的消息數據;
根據該輸入數據,進行該每輪MapReduce作業。
在本發明實施例中,因為採取了對圖數據和消息數據分開處理的方式,把在整個MapReduce作業過程中始終保持不變的圖數據抽離出來,單獨保 存在DFS中,並且每輪MapReduce作業產生的消息數據也被保存在DFS中與圖數據對應的位置。在每輪MapReduce作業的開始,從DFS中讀取需要的圖數據和消息數據作為本輪MapReduce的輸入數據。在每輪MapReduce作業過程中,Map計算節點在處理完子圖數據後,無需向其它計算節點傳輸圖數據,所以在Shuffle過程中也不需要傳輸圖數據,從而能夠減少圖數據在計算過程中帶來的I/O開銷以及在Shuffle過程中的通信開銷,進而加快了圖數據的處理速度。
可選地,在本發明另一實施例中,該處理器810根據該輸入數據,進行該每輪MapReduce作業,具體可以包括:
根據該輸入數據,為該每輪MapReduce作業的Map計算節點和Reduce計算節點分配計算任務;
控制該每輪MapReduce作業中的Reduce計算節點將處理得到的消息數據存入該m第二個文件中。
可選地,在本發明另一實施例中,該處理器810還用於:根據公式gr=(nid*m)/N,將該圖劃分成該多個子圖,其中,gr取值相同的頂點被劃分到同一子圖,nid為該圖中的頂點的編號,m為該子圖的個數,N為該圖中的頂點的個數。
因此,在本發明實施例中,通過將待處理的圖數據對應的圖劃分成多個子圖,在MapReduce作業中的Map計算節點以子圖為計算對象,每次處理一個子圖內的具有連接關係的頂點,充分利用了子圖內頂點的連接關係,使得每輪MapReduce作業過程儘可能處理更多的頂點,從而減少了處理圖數據所需的MapReduce作業輪數,提高了圖數據的處理效率。
應理解,根據本發明實施例的傳輸信息控制信息的裝置800可對應於本發明方法實施例中的主控設備,並且裝置800中的各個模塊的上述和其它操作和/或功能分別為了實現圖2至圖6中的各個方法的相應流程,為了簡潔,在此不再贅述。
本發明實施例的處理圖數據的裝置採取的劃分子圖的方法,通過分析實際應用中涉及的圖數據的特點,在考慮到負載均衡的前提下,將有邊相連的頂點儘可能劃分到同一子圖內,同時削弱子圖之間的耦合性,可以進一步地減少處理圖數據所需的MapReduce作業輪數,提高圖數據的處理效率。
另外,本文中術語「系統」和「網絡」在本文中常被可互換使用。本文中術語「和/或」,僅僅是一種描述關聯對象的關聯關係,表示可以存在三種關係,例如,A和/或B,可以表示:單獨存在A,同時存在A和B,單獨存在B這三種情況。另外,本文中字符「/」,一般表示前後關聯對象是一種「或」的關係。
應理解,在本發明實施例中,「與A相應的B」表示B與A相關聯,根據A可以確定B。但還應理解,根據A確定B並不意味著僅僅根據A確定B,還可以根據A和/或其它信息確定B。
本領域普通技術人員可以意識到,結合本文中所公開的實施例描述的各示例的單元及算法步驟,能夠以電子硬體、計算機軟體或者二者的結合來實現,為了清楚地說明硬體和軟體的可互換性,在上述說明中已經按照功能一般性地描述了各示例的組成及步驟。這些功能究竟以硬體還是軟體方式來執行,取決於技術方案的特定應用和設計約束條件。專業技術人員可以對每個特定的應用來使用不同方法來實現所描述的功能,但是這種實現不應認為超出本發明的範圍。
所屬領域的技術人員可以清楚地了解到,為了描述的方便和簡潔,上述描述的系統、裝置和單元的具體工作過程,可以參考前述方法實施例中的對應過程,在此不再贅述。
在本申請所提供的幾個實施例中,應該理解到,所揭露的系統、裝置和方法,可以通過其它的方式實現。例如,以上所描述的裝置實施例僅僅是示意性的,例如,該單元的劃分,僅僅為一種邏輯功能劃分,實際實現時可以有另外的劃分方式,例如多個單元或組件可以結合或者可以集成到另一個系統,或一些特徵可以忽略,或不執行。另外,所顯示或討論的相互之間的耦合或直接耦合或通信連接可以是通過一些接口、裝置或單元的間接耦合或通信連接,也可以是電的,機械的或其它的形式連接。
該作為分離部件說明的單元可以是或者也可以不是物理上分開的,作為單元顯示的部件可以是或者也可以不是物理單元,即可以位於一個地方,或者也可以分布到多個網絡單元上。可以根據實際的需要選擇其中的部分或者全部單元來實現本發明實施例方案的目的。
另外,在本發明各個實施例中的各功能單元可以集成在一個處理單元中,也可以是各個單元單獨物理存在,也可以是兩個或兩個以上單元集成在一個 單元中。上述集成的單元既可以採用硬體的形式實現,也可以採用軟體功能單元的形式實現。
該集成的單元如果以軟體功能單元的形式實現並作為獨立的產品銷售或使用時,可以存儲在一個計算機可讀取存儲介質中。基於這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分,或者該技術方案的全部或部分可以以軟體產品的形式體現出來,該計算機軟體產品存儲在一個存儲介質中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,伺服器,或者網絡設備等)執行本發明各個實施例該方法的全部或部分步驟。而前述的存儲介質包括:U盤、移動硬碟、只讀存儲器(ROM,Read-Only Memory)、隨機存取存儲器(RAM,Random Access Memory)、磁碟或者光碟等各種可以存儲程序代碼的介質。
以上某一實施例中的技術特徵和描述,為了使申請文件簡潔清楚,可以理解適用於其他實施例,在其他實施例不再一一贅述。
以上所述,僅為本發明的具體實施方式,但本發明的保護範圍並不局限於此,任何熟悉本技術領域的技術人員在本發明揭露的技術範圍內,可輕易想到各種等效的修改或替換,這些修改或替換都應涵蓋在本發明的保護範圍之內。因此,本發明的保護範圍應以權利要求的保護範圍為準。