與語音質量估計相關的改進方法和設備與流程
2023-10-17 08:19:34 1
本公開落入語音通信系統領域,更具體地涉及基於分組的語音通信系統中的語音質量估計領域。特別地,本公開提供了通過考慮丟失的語音分組的內容來減小語音質量估計的預測誤差的方法和設備。此外,本公開提供了使用語音質量估計算法以基於可以在第一輸入模式和第二輸入模式之間切換的輸入來計算語音質量估計的方法和設備。
背景技術:
在過去的幾年中,網際網路協議語音(voiceoverinternetprotocol(voip))已經變成重要的應用,並且被預期通過tcp/ip網絡攜帶越來越多的語音流量。
在這種基於網際網路協議(ip)的語音通信系統中,通常用戶的語音波形被在時間上分片、由語音編碼器壓縮、分組化並發送(transmit)給其他用戶。由於ip網絡的固有性質和人類語音通信的實時約束,在發送期間丟失語音分組或者遲到的語音分組即使接收到也會被丟棄是常見的,從而導致劣化的語音質量。移動和wifi網絡通常在許多情況下使情況更糟。因而,語音質量的精確實時監視是語音通信系統的分析、管理和優化的基本特徵。
典型的語音質量監視系統採用分析分組丟失信息(諸如分組丟失率和丟失模式(例如,丟失是隨機的或具有突發性質))的方案,因為它提供了簡單且計算成本低的方法來估計語音質量。這種方案被稱為經修改的e模型。但是,這些系統在估計語音質量方面具有低精確度,這是因為在估計語音質量時,它們不考慮丟失的語音分組的內容(例如,有效載荷)。
可以通過在完全解碼在voip呼叫(例如itu-tp.563,ansianique+)中發出的所有分組和其它數據之後分析語音波形來實現更精確的語音質量估計。但是,這種方法需要用於分析語音波形的大量的計算。而且,這種方法丟棄了在分組層級可用的重要分組丟失統計信息。
因而,期望具有利用分組丟失信息和語音波形信息兩者而不需要昂貴的完全解碼過程的語音質量監視系統。
附圖說明
現在將參考附圖描述示例實施例,其中:
圖1是根據示例實施例的語音質量估計設備的一般框圖,
圖2通過示例示出與連續丟失的語音分組的組相關的統計度量的修改,其中修改基於每組中的丟失的語音分組的感知重要性,
圖3通過示例描述了怎樣基於與丟失的語音分組相鄰的語音分組估計丟失的語音分組的感知重要性,
圖4通過示例示出當在計算語音質量估計時使用丟失的語音分組的感知重要性時怎樣減小語音質量估計的預測誤差,
圖5通過示例示出用於修改與丟失的語音分組相關的統計度量的方法,
圖6通過示例示出用於計算語音質量估計的方法。
所有附圖都是示意性的並且一般僅示出為了闡明本公開所必需的部分,而其它部分可以被省略或僅僅被暗示。除非另有指示,否則在不同圖中相同的附圖標記指的是相同部分。
具體實施方式
鑑於以上,一個目的是提供通過基於丟失的語音分組的感知重要性修改與丟失的語音分組相關的常規統計量度來提供語音質量估計的減小的預測誤差的設備和相關聯方法。而且,一個目標是提供在計算語音質量估計時促進兩種操作模式的設備和相關聯方法,使得提供低複雜度模式和高精確度模式。
i.概述-使用丟失的分組的感知重要性
根據第一方面,示例實施例提出了用於修改與丟失的語音分組相關的統計度量的方法、實現該方法的設備以及適於實施該方法的電腦程式產品。所提出的方法、設備和電腦程式產品一般可以具有相同的特徵和優點。
根據示例實施例,提供了用於修改基於分組的語音通信系統中的與丟失的語音分組相關的統計度量的方法。
該方法包括接收包括從語音通信系統中的一個或多個端點發送的編碼語音分組的序列的數據,其中從所述一個或多個端點發送的編碼語音分組包括接收到的編碼語音分組的序列以及在從所述一個或多個端點的發送期間丟失的或由於發送中的延時(latency)和/或抖動而被丟棄的一個或多個丟失的語音分組。
該方法還包括基於接收到的編碼語音分組的序列計算與丟失的語音分組相關的統計度量,以及基於丟失的語音分組的感知重要性來修改統計度量,以便在使用修改的統計度量作為語音質量估計算法的輸入時減小語音質量估計的預測誤差。
本公開一般涉及包括多個電話端點的電話會議系統,並且特別地涉及當這樣的系統經歷信道劣化或網絡劣化時感知到的呼叫質量的改進。
作為背景,在典型的電話會議系統中,混合器從語音呼叫中的電話端點中的每個接收攜帶由該電話端點捕獲的音頻信號的相應上行鏈路數據流,並將相應的下行鏈路數據流發出到電話端點中的每個。結果,每個電話端點接收攜帶由其它電話端點捕獲的相應音頻信號的混合的下行鏈路數據流。從而,當電話會議中的兩個或更多個參與者同時發言時,其他(一個或多個)參與者可以聽到這兩個參與者發言。
如果攜帶去往端點中的一個的下行鏈路數據流和來自端點中的該一個端點的上行鏈路數據流的數據信道存在問題,則這可以引起在下行鏈路和/或上行鏈路數據流中的誤差。對於使用端點中的所述一個端點的參與者和/或語音呼叫中的其他參與者,該誤差可以是可感知的。誤差可以導致在從一個或多個端點發送期間丟失的、丟失的語音分組。
誤差會進一步導致抖動。抖動在技術上是跨網絡的延時隨時間的變化性的測量,並且是基於分組的語音通信系統中的常見問題。因為語音分組可以通過從發送器(sender)到接收器的不同路逕行進,所以語音分組可能按照與它們原始發出的次序不同的次序到達它們意圖的目的地。即使使用抖動緩衝區來臨時存儲到達的語音分組以便最小化延遲變化,一些抖動特性也會超過抖動緩衝區的能力並且一些語音分組仍然可能遲到。這些分組最終被丟棄。因而,這種丟棄的語音分組被看作是由於發送中的延時和/或抖動而被丟棄的、丟失的語音分組。
因而,丟失的語音分組可以在發送中被動丟失或由於抖動/延時而被主動丟棄(例如,被抖動緩衝區主動丟棄)。
以上討論的與下行鏈路和/或上行鏈路數據流中的誤差相關的問題可以導致從一個或多個端點發送的編碼語音分組中,一些編碼語音分組在發送期間丟失或由於發送中的延時和/或抖動而被丟棄,其餘的作為編碼語音分組的序列被接收。
如本文所使用的,「端點」指的是電話端點和/或混合器。應當注意,術語「電話端點」包括可以在電話會議系統中使用的任何端點設備,其中聲音被轉換成電脈衝以用於發送,並且其中電脈衝被轉換回聲音。
以上方法提供了減小語音質量估計的預測誤差的簡單且靈活的方式。
計算語音質量估計時的常規統計度量不考慮丟失的語音分組的有效載荷。有效載荷包含語音呼叫中對應時間幀的語音波形或音頻數據。相反,僅考慮語音分組是丟失還是被接收的信息。
但是,丟失的語音分組的內容可以與減小語音質量估計的預測誤差非常相關。例如,攜帶表示語音呼叫中主演示者的語音的音頻數據的丟失的語音分組可以比攜帶表示語音呼叫中收聽者的沉默的音頻數據的丟失的語音分組降低更多感知到的語音質量。結果,通過使用丟失的語音分組的感知重要性來計算隨後可以被用作語音質量估計算法的輸入的統計度量,可以減小語音質量估計的預測誤差。
通過減小預測誤差,可以更早地和/或更精確地檢測可能導致一個或多個參與者感知劣化的呼叫質量的問題,並且因而可以更好地處理該問題。
根據示例實施例,修改統計度量的步驟包括根據丟失的語音分組的感知重要性對該丟失的語音分組進行加權。結果,可以考慮每個丟失的語音分組的感知重要性。例如,兩個連續的丟失的語音分組可以具有不同的感知重要性,並且因而在計算語音質量估計時被不同地加權。這可以在修改統計度量時提供改進的靈活性。
根據示例實施例,統計度量與連續的丟失的語音分組的組相關,每組包括一個或多個丟失的語音分組,其中在計算統計度量的步驟中,每組連續的丟失的語音分組基於該組中連續的丟失的語音分組的數量被加權,並且其中在修改統計度量的步驟中,每組基於該組中丟失的語音分組的感知重要性被進一步加權。
因為統計度量基於連續的丟失的語音分組的組,所以丟失分組的模式被考慮到。應當注意,組可以僅包括一個丟失的語音分組。
在基於分組的語音通信系統中,隨機丟失模式可以比丟失的分組被編組(grouped)(例如,突發丟失模式)的情況更少地降低語音質量,因為更大數量的連續的丟失的語音分組可以增加感知重要的數據丟失的風險。例如,在主演示者正在闡述重要觀點的同時,攜帶表示他或她的語音的音頻數據的數個連續的語音分組的丟失比在上行鏈路數據流上與主演示者分隔開一段時間的相同數量的語音分組的丟失更多地負面地影響感知到的語音質量。換言之,突發丟失模式可以會增加整個單詞或重要音素丟失的風險,而更隨機的丟失模式可以被聽眾忽略。
根據示例實施例,基於與從一個或多個端點發送期間丟失或者由於發送的延時和/或抖動而被丟棄的分組相鄰的編碼語音分組的序列中的語音分組的感知重要性來估計丟失的語音分組的感知重要性。
結果,可以在沒有與實際丟失的語音分組相關的任何信息的情況下估計丟失的語音分組的感知重要性。而且,因為每個語音分組例如與諸如1/100或1/50秒之類的小時間幀對應,所以具有某個感知重要性的語音分組有可能在具有相似感知重要性的語音分組之前和之後。應當注意,語音分組可以與第一時間幀(例如20ms)對應,而相同發送中的另一語音分組可以與第二時間幀(例如10ms)對應。
根據示例實施例,接收到的編碼語音分組的序列中的每個語音分組包括指示語音分組的感知重要性的單獨的位或單獨的多位。這可以減小從語音分組提取感知重要性的計算複雜度,因為不需要為了提取感知重要性而執行對語音分組中的實際語音波形的分析。
根據示例實施例,該方法還包括以下步驟:接收指示從一個或多個端點發送的編碼語音分組中的每個的感知重要性的信號。這個實施例可能是有利的,因為丟失的分組的感知重要性仍然在指示從一個或多個端點發送的編碼語音分組中的每個的感知重要性的信號中被描述。結果,不需要為了估計(一個或多個)丟失的語音分組的感知重要性而執行基於相鄰語音分組的分析或計算。這可以導致在基於丟失的語音分組的感知重要性修改統計度量時更低的計算複雜度。
根據示例實施例,該方法還包括對接收的編碼語音分組中的至少一些進行部分解碼以便估計丟失的語音分組的感知重要性的步驟。可以例如使用基於經修改的離散餘弦變換(mdct)的編碼器對編碼語音分組進行編碼,其中通過對接收到的編碼語音分組中的至少一些進行部分解碼來提取mdct增益參數,其中mdct增益參數被用於估計丟失的語音分組的感知重要性。與語音分組被完全解碼和分析的策略相比,這可以減小丟失的語音分組的感知重要性的估計的計算複雜度。
根據示例實施例,該方法還包括完全解碼接收到的編碼語音分組中的至少一些以便估計丟失的語音分組的感知重要性的步驟。這可以改進丟失的分組的感知重要性的估計,並且與在itu-tp.563、ansianique+中使用的策略相比,這與分組層級的分組丟失統計相結合可以減小語音質量估計的預測誤差。
根據示例實施例,統計度量包括以下中的至少一個:分組丟失率plr,其是與所發送的語音分組的總數量相關的丟失的語音分組的數量,以及突發性因子bf,其是一減去與丟失的語音分組的數量相關的連續的丟失的語音分組的組的數量。
這些是常規語音質量估計算法中的典型參數,並且通過修改這些統計度量中的至少一個,可以重用這樣的語音質量估計算法。
根據示例實施例,基於丟失的語音分組的感知重要性修改統計度量的步驟包括plr和/或bf的線性或非線性映射。這將在下面詳細解釋。
根據示例實施例,語音分組的感知重要性基於語音分組的響度值、語音分組的音素類別和語音分組的頻帶加權信號能量水平中的至少一個。這些參數全都解決語音波形的感知重要性並且可以單獨使用或組合使用以便提取語音分組的感知重要性。
如本文所使用的,「響度」表示聲音強度的建模的心理聲學測量;換言之,響度表示由普通用戶感知到的一個或多個聲音的音量的近似。響度可以例如指語音波形的對白歸一(dialnorm)值(根據itu-rbs.1770建議)。可以使用其它合適的響度測量標準,諸如glasberg和moore的響度模型,該響度模型提供對zwicker的響度模型的修改和擴展。
根據示例實施例,接收到的數據還包括表示一個或多個丟失的語音分組的分組。如上面所解釋的,電話會議系統中的設備(例如,混合器或電話端點)通常包括抖動緩衝區,該抖動緩衝區存儲可以以不規則的時間間隔到達的、傳入的語音分組以便以均勻隔開的時間間隔創建語音分組。通過也創建例如帶有丟失的語音分組的標記的分組,就每個時間幀的語音分組的數量和語音分組之間的時間段而言,從抖動緩衝區的輸出總是看起來相同。這進而可以減小系統的其餘部分(例如,計算語音質量估計的部分)的複雜度。
根據示例實施例,提供了包括計算機代碼指令的計算機可讀介質,該計算機代碼指令適於在具有處理能力的設備上執行時執行第一方面的任何方法。
根據示例實施例,提供了用於估計基於分組的語音通信系統中的語音質量的設備。該設備包括接收級,被配置為接收包括從語音通信系統中的一個或多個端點發送的編碼語音分組的序列的數據,其中從一個或多個端點發送的編碼語音分組包括接收到的編碼語音分組的序列以及在從一個或多個端點的發送期間丟失或由於發送中的延時和/或抖動而被丟棄的一個或多個丟失的語音分組。該設備還包括計算級,被配置為基於接收到的編碼語音分組的序列來計算與丟失的語音分組的數量相關的統計度量。該設備還包括感知變換級,被配置為基於丟失的語音分組的感知重要性來修改統計度量,以便在使用修改的統計度量作為語音質量估計算法的輸入時減小語音質量估計的預測誤差。
ii.概述-可切換的輸入模式
根據第二方面,示例實施例提出了用於計算基於分組的語音通信系統中的語音質量估計的方法、實現該方法的設備以及適於執行該方法的電腦程式產品。所提出的方法、設備和電腦程式產品一般可以具有相同的特徵和優點。一般地,第二方面的特徵可以具有與第一方面的對應特徵相同的優點。
根據示例實施例,提供了用於計算基於分組的語音通信系統中的語音質量估計的方法。該方法包括以下步驟:使用語音質量估計算法接收包括編碼語音分組的序列的數據,以基於可在第一輸入模式和第二輸入模式之間切換的輸入來計算語音質量估計。
在第一輸入模式下,輸入是與編碼語音分組的序列相關的統計度量。
在第二輸入模式下,輸入是與編碼語音分組的序列相關的統計度量的預處理版本。
根據這個方法,預處理改進語音質量估計的精確度,使得與基於統計度量的語音質量估計的預測誤差相比,基於統計度量的預處理版本的語音質量估計的預測誤差被減小。
通過提供兩種輸入模式,其中一種是為了低複雜度並且一種提供更高的精確度,提供了用於計算語音質量估計的更靈活的方法。而且,因為兩種輸入模式共享相同的語音質量估計算法,所以可以實現改進的可擴展性。
根據示例實施例,該方法還包括接收來自端點中的一個的、指示要選擇的第一輸入模式和第二輸入模式中的一個的輸入的步驟。這個輸入可以例如由端點電話的用戶感知到語音質量不令人滿意來觸發。在這種情況下,為了更好地處理語音分組發送中的問題,可能需要在例如混合器處對語音質量進行更好的估計。
根據示例實施例,第一輸入模式與第二輸入模式之間的選擇基於與第一輸入模式和第二輸入模式相關聯的計算負荷。在這種情況下,例如,如果混合器的處理器正在計算上過載,則混合器本身可以從第二輸入模式切換到第一輸入模式。這可以在例如如果許多端點連接到語音呼叫時發生,使得需要執行更多的混合。
根據示例實施例,第一輸入模式與第二輸入模式之間的選擇基於與同期望的語音質量估計精確度相關的第一輸入模式和第二輸入模式相關聯的計算負荷。結果,兩種輸入模式之間的切換可以是執行該方法的設備的計算負荷與語音質量估計的精確度之間的權衡。
根據示例實施例,第一輸入模式與第二輸入模式之間的選擇基於預設模式。
根據示例實施例,從語音通信系統中的一個或多個端點發送接收到的數據,其中從一個或多個端點發送的編碼語音分組包括接收到的編碼語音分組的序列以及在從一個或多個端點發送期間丟失或由於發送中的延時和/或抖動而被丟棄的一個或多個丟失的語音分組,其中統計度量根據接收到的編碼語音分組的序列被計算並且與丟失的語音分組相關,並且其中預處理與基於丟失的語音分組的感知重要性來修改統計度量相關。如上所述,通過在計算語音質量估計時考慮丟失的語音分組的感知重要性,可以實現更精確的語音質量估計。應當注意,可以採用任何其它類型的預處理,例如使用如「animprovedgmm-basedvoicequalitypredictor」(falk等人)中描述的高斯混合模型,或者使用元音和輔音音素的發音轉換(articulatorytransition)(即,主動和被動發音器)以便修改統計度量。
根據示例實施例,預處理包括根據丟失的語音分組的感知重要性對該丟失的語音分組進行加權。
根據示例實施例,統計度量與連續的丟失的語音分組的組相關,每組包括一個或多個丟失的分組,其中通過基於每組中連續的丟失的語音分組的數量對該組連續的丟失的語音分組進行加權來計算統計度量,並且其中預處理還包括基於每組中的丟失的語音分組的感知重要性對該組進行加權。
根據示例實施例,基於編碼語音分組的序列中與從一個或多個端點的發送期間丟失的分組相鄰的語音分組的感知重要性來估計丟失的語音分組的感知重要性。
根據示例實施例,該方法還包括至少部分地解碼接收到的編碼語音分組中的至少一些以便估計丟失的語音分組的感知重要性的步驟。
這樣的至少部分解碼可以導致執行該方法的設備上的計算負荷增加。結果,當第二輸入模式包括至少部分地解碼接收到的編碼語音分組中的一些時;可能甚至更有利的是具有兩種輸入模式,使得如果需要則可以釋放設備的計算負荷。
根據示例實施例,接收到的編碼語音分組的序列中的每個語音分組包括指示語音分組的感知重要性的單獨位。
根據示例實施例,該方法還包括接收指示從一個或多個端點發送的編碼語音分組中的每個的感知重要性的信號的步驟。
根據示例實施例,統計度量包括以下中的至少一個:分組丟失率plr,其是與所發送的語音分組的總數量相關的丟失的語音分組的數量,以及突發性因子bf,其是一減去與丟失的語音分組的數量相關的連續的丟失的語音分組的組的數量。
根據示例性實施例,語音分組的感知重要性基於語音分組的響度值、語音分組的音素類別和語音分組的頻帶加權信號能量水平中的至少一個。
根據示例性實施例,提供了包括計算機代碼指令的計算機可讀介質,該計算機代碼指令適於在具有處理能力的設備上執行時執行第二方面的任何方法。
根據示例實施例,提供了一種用於計算基於分組的語音通信系統中的語音質量估計的設備。該設備包括接收級,被配置為接收包括編碼語音分組的序列的數據,以及語音質量估計級,被配置為使用語音質量估計算法以基於可在第一輸入模式與第二輸入模式之間切換的輸入來計算語音質量估計,其中,在第一輸入模式下,輸入是與編碼語音分組的序列相關的統計度量,其中在第二輸入模式下,輸入是與編碼語音分組的序列相關的統計度量的預處理版本,並且其中與基於統計度量的語音質量估計的預測誤差相比,基於統計度量的預處理版本的語音質量估計的預測誤差被減小。
iii.示例實施例
圖1描述了根據示例實施例的語音質量估計設備100的一般框圖。設備100是基於分組的語音通信系統的一部分,例如,電話會議系統中的混合器或電話端點。
設備100包括兩個不同的部分100a、100b。圖1中包括抖動緩衝區102和用於解碼和分組丟失隱藏(plc)的級104的上部100a是接收器(例如,行動電話)的典型語音處理單元。抖動緩衝區102通常是從基於分組的語音通信系統的其它部分接收傳入的語音分組101的緩衝區。由於基於分組的語音通信系統中的上行鏈路和/或下行鏈路數據流的問題,傳入的語音分組101通常以不規則的時間間隔到達。傳入的分組中的一些由於它們因網絡中的延時而遲到而被丟棄,這意味著語音呼叫的對應時間區段已經被接收器的揚聲器呈現。由於抖動特性超過了抖動緩衝區的能力,所以將丟棄一些語音分組。抖動緩衝區102可以以均勻隔開的時間間隔輸出語音分組103。可選地,抖動緩衝區102還可以創建表示丟失的語音分組的分組,照此(assuch)標記它們,並以均勻隔開的時間間隔將它們包括在輸出的語音分組103中。用於丟失的語音分組的標記可以是輸出的語音分組中的單個位,例如,如果語音分組沒有丟失則為零,如果語音分組表示丟失的語音分組則為一。抖動緩衝區可以例如使用被包括在語音分組中的序列號以便確定分組是否丟失以及那些丟失的語音分組原始(當發送時)位於語音分組流中的哪裡。
用於解碼和plc的級104解碼語音分組流的內容(有效載荷)以合成語音波形。如果在語音分組中有丟失,該丟失有可能由抖動緩衝區102標記或以其他方式被級104已知(例如,通過每個語音分組中的行程(running)數量),則採用plc來通過使用先前接收的語音分組來估計丟失分組的語音波形。
圖1中的設備100的下部100b是執行丟失的分組對感知到的語音質量的影響的估計的部分,即,計算語音質量估計116的部分。可以在平均意見得分(mos)量表(scale)中輸出計算出的語音質量估計116。
來自抖動緩衝區102的輸出語音分組103由分組丟失統計(pls)計算單元106(即,設備100的計算級)接收。pls計算單元106包括接收級,該接收級適於接收包括從語音通信系統中的一個或多個端點發送的編碼語音分組103的序列的數據。如上所述,從一個或多個端點發送的編碼語音分組中的一些可能已經在從一個或多個端點到設備100的發送期間丟失,或者由於遲到而被抖動緩衝區102丟棄。這些丟失的分組可以引起編碼語音分組與其相關的語音呼叫的感知質量降低。
plc計算單元106被配置為基於接收到的編碼語音分組的序列103來計算與丟失的語音分組的數量相關的統計度量107。統計度量107可以包括分組丟失率plr,plr是與所發送的語音分組的總數量相關的丟失的語音分組的數量。例如,如果100個語音分組中的10個丟失,則plr等於0.1。
附加地或替代地,統計度量107可以與突發性因子bf相關,bf是一減去與丟失的語音分組的數量相關的連續的丟失的語音分組的組的數量。如果在10個丟失的語音分組中可以形成三組連續的丟失的分組,例如,各組包括1、3和6個丟失的語音分組,則bf等於1-(3/10)=0.7。
設備100包括用於在語音質量估計級108中計算語音質量估計116的兩種不同的輸入模式112、114。應當注意,這兩種模式的語音質量估計級108相等,即,不管採用兩種輸入模式112、114中哪一種,都使用相同的語音質量估計算法。
第一輸入模式112僅使用分組層級上的統計,例如,plr和/或bf,用於計算語音質量估計。這是計算語音質量估計的典型方法,該方法計算成本低,但是因為不考慮丟失的語音分組的實際內容而可能會遭受語音質量估計的低精確度。
現在將描述語音質量估計級108的示例實施例。根據這個實施例,語音質量估計級108需要兩個輸入,它們是分組丟失率值和突發性值。
語音質量估計級108包括l個回歸模型。l是突發性因子的選擇的預設數量。例如,語音質量估計級108可以包括六個回歸模型(l=6),分別對應於bf值0、0.2、0.4、0.6、0.8和1.0。
給定plr值和bf值的輸入,選擇具有與bf值最接近的近似的兩個回歸模型,這兩個回歸模型根據plr值估計語音質量值。最後的語音質量由該兩個語音質量值的加權和來估計。
但是,為了改進語音質量估計116的精確度,可以使用第二輸入模式114。在第二輸入模式114下,到語音質量估計級108的輸入是與由pls計算單元100計算的編碼語音分組的序列相關的統計度量107的預處理版本111。預處理在設備100的預處理級110中進行,這將在下面詳細描述。
第一輸入模式112與第二輸入模式114之間的切換可以基於來自端點中的一個的、指示要選擇的第一輸入模式和第二輸入模式中的一個的、接收到的輸入(圖1中未示出)。
例如,連接到基於分組的電話會議的電話端點可以確定設備100(例如,會議伺服器或另一電話端點)的操作模式。而且,當設備100是連接到基於分組的電話會議的電話端點時,會議伺服器或混合器可以發出用於確定操作模式的適當信令。
根據其它實施例,其中計算語音質量估計116的電話端點或會議伺服器可以基於與第一輸入模式112和第二輸入模式114相關聯的計算負荷在第一輸入模式112與第二輸入模式114之間進行選擇。如從上面可以理解的,第一輸入模式112下的語音質量估計116的計算是相當直接的,因而具有低的計算複雜度。第二輸入模式114下的語音質量估計116的計算經常意味著更高的計算複雜度,這依賴於所採用的是什麼類型的預處理。因而,計算語音質量估計116的設備100可以依賴於該設備100可用的計算資源確定應當使用兩種輸入模式112、114中的哪一種。而且,第一輸入模式112與第二輸入模式114之間的選擇可以基於與期望的語音質量估計精確度相關的和第一輸入模式和第二輸入模式相關聯的計算負荷。
要使用的輸入模式的選擇也可以基於預設模式。
根據一些實施例,在設備100的預處理級110中進行的預處理可以與基於丟失的語音分組的感知重要性來修改統計度量相關。例如,plr值和/或bf值可以根據丟失的分組的感知重要性而被變換,並進一步輸入到如上面所解釋的將使用輸入值111的語音質量估計級108。
下面將結合圖4進一步解釋被感知加權的或不被感知加權的、在語音質量估計級108中的plr和bf值的使用。
語音分組的感知重要性可以基於語音分組的語音波形的若干屬性中的一個或多個。根據一些實施例,感知重要性基於語音分組的響度值,即,語音分組的有效載荷中的語音波形的響度值。根據其它實施例,感知重要性基於語音分組的頻帶加權信號能量水平(或響度水平)。這個能量水平可以通過以下方式變換成響度值(例如,以宋(sone)為單位):
響度=20.1*p-4(1)
其中p是頻帶加權信號能量水平或響度水平。
其它信息(諸如語音分組周圍或用於語音分組的音素類別)可以與響度信息一起使用或單獨使用以計算語音分組的感知重要性。
現在將結合圖2和圖3進一步描述丟失的語音分組的感知重要性的計算和使用。
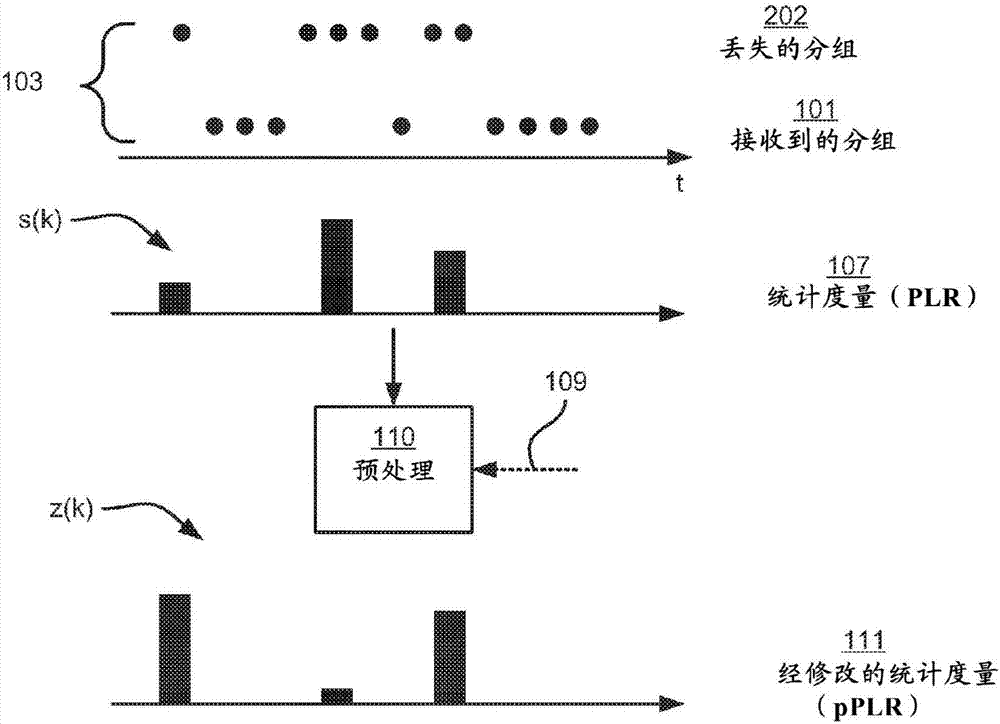
根據一些實施例,統計度量與連續的丟失的語音分組的組相關,其中在計算統計度量的步驟中,每組連續的丟失的語音分組基於該組中連續的丟失的語音分組的數量進行加權。這在圖2中描述。圖2的上部例示了從一個或多個端點發送到設備100的編碼語音分組中的接收到的分組101與丟失的分組202之間的關係。如上面結合圖1所描述的,抖動緩衝區102可以包括表示由pls計算單元106以及可選地由預處理級110接收的數據103中的一個或多個丟失的語音分組202的分組。這些分組可以是空的和/或包括指示它們表示丟失的分組的數據。這在圖2中描述,其中數據103包括表示一個或多個丟失的語音分組202的空分組。
給定可以從103獲得的丟失的語音分組的時間序列,可以定義分組丟失事件函數s(k),對於k=1,2,...,k,s(k)表示第k組丟失事件處連續的丟失的分組的數量,其中k是連續的丟失的分組的組的數量。在圖2中,這樣的組的數量是3。在這個示例中,分組丟失事件函數s(k)是具有值[1,3,2]的向量。然後,分組丟失率(plr)可以通過下式來計算
其中m是接收到的分組101和丟失的分組202的總數量,即,在圖2中m=14。
圖2還描述了怎樣將統計度量107(在這種情況下是向量s(k))輸入到預處理級110。預處理級可以例如是感知變換級,該感知變換級被配置為基於丟失的語音分組的感知重要性來修改統計度量107,使得每個組還基於該組中的丟失的語音分組的感知重要性被進一步加權。感知變換級將向量s(k)變換為新的向量z(k),可以通過下式根據該新的向量計算感知分組丟失率(pplr):
z(k)在圖2中被示出並且這個經修改的向量被用作根據等式3計算經修改的統計度量pplr的基礎。
丟失的語音分組的感知重要性可以以數種不同方式來計算。例如,預處理級110可以接收指示從一個或多個端點發送的編碼語音分組中的每個的感知重要性的信號109。因而,信號109可以包括數據103中包括丟失的語音分組202在內的所有語音分組的感知重要性。通過採用這樣的附加的信號109,可以減小統計度量107的預處理的計算負荷。
根據其它實施例,基於編碼語音分組的序列中與在從一個或多個端點的發送期間丟失或由於遲到而被抖動緩衝區丟棄的分組相鄰的語音分組的感知重要性來估計丟失的語音分組的感知重要性。這可以是有利的,因為不需要發送額外的信號,這可能意味著設備100可以被插入到標準的基於分組的通信系統中。根據一些實施例,設備100可以被配置為檢查附加信號109是否被接收並且在被接收的情況下使用它,並且如果未接收到信號109,則基於編碼語音分組的序列中與在從一個或多個端點的發送期間丟失或由於遲到而被抖動緩衝區丟棄的分組相鄰的語音分組的感知重要性來估計丟失的語音分組的感知重要性。
圖3描述了怎樣基於編碼語音分組的序列中與在從一個或多個端點的發送期間丟失或由於遲到而被抖動緩衝區丟棄的分組相鄰的語音分組的感知重要性來估計丟失的語音分組的感知重要性。
令x為k乘(d+1)特徵矩陣,其中第k行表示與第k組丟失的語音分組相關聯的(d+1)維特徵向量x(k),d是特徵的數量,並且額外的維度是恆定移位項。
特徵向量x(k)包含關於第k組丟失的分組的語音特性或感知重要性的有用信息。在信息不可用的情況下,即,設備100沒有接收到信號109的情況下;這個信息可以根據接收到的丟失的分組周圍的臨近分組而被估計。
在一個示例實施例中,特徵向量可以基於第k組丟失的分組的鄰域中的響度信息和plr,表達為
x(k)=[plrlinterp(k)lleft(k)lright(k)ltd(k)1](4)
其中
如果ed(k)-st(k)<6,則
並且否則
st(k)和ed(k)是就在第k組丟失之前和之後的分組的時間索引。
ltd(k)=[l(ed(k))-l(st(k))]/[ed(k)-st(k)](9)
l(i)是第i個時間索引的語音分組的估計響度。這在圖3中總結。
x(k)中的最後一項是要適應在下面描述的線性變換中的平移(translation)分量。
感知分組丟失事件函數z=[z(1)z(2)...z(k)](如圖2中所示)可以通過下式得出
z=xw·s(10)
其中w=[w(1)w(2)...w(d+1)]是特徵矩陣x的加權因子,s=[s(1)s(2)...s(k)]是分組丟失事件函數的向量表示(如等式2和圖2中所述)。可以使用訓練數據集來訓練加權因子w,使得改進語音質量估計的精確度。
獲得感知分組丟失事件函數的過程可以被解釋為對每組分組丟失事件分配感知重要性,其中感知重要性通過特徵的線性組合來估計。應當注意,也可以使用特徵的非線性組合。例如,在s向量中,包括大於閾值數量的丟失的語音分組的組可以被求平方。
然後,感知分組丟失率(pplr)可以如等式3中那樣被定義,等式3因而將plr變換到感知域,用於以更精確的方式計算語音質量估計。
這個概念在圖4中描繪。回歸曲線402基於bf值來確定。回歸曲線基於實際感知語音質量的經驗數據並且因而是預定義的參考。如先前所述,回歸曲線也可以基於根據以上而被變換到感知域的bf值來確定。
圖4示出了與使用常規plr值404作為輸入相比,使用pplr值406作為語音質量估計級的輸入怎樣使預測誤差減小了大的值(在圖4中稱為408)。換言之,通過應用將plr變換為pplr的處理,將數據點404平移到數據點406,從而導致使用相同回歸曲線402的語音質量估計誤差減小。
當如上所述從相鄰語音分組得出丟失的分組的感知重要性時,相鄰語音分組的感知重要性可以通過從接收到的編碼語音分組中部分地解碼所需的語音分組而得出。語音分組的有效載荷包含編碼位以便在呈現語音呼叫時產生發送的語音波形。有效載荷的內容通常包括一些形式的信息,例如在單獨的一個或多個位中,該信息可以被用來估計信號的能量水平或響度。在這種情況下,可以通過有效載荷的部分解碼而不是完全解碼處理來估計響度信息。例如,如果編碼語音分組是使用基於經修改的離散餘弦變換(mdct)的編碼器被編碼的,則可以通過對接收到的編碼語音分組進行部分解碼來提取mdct增益參數。然後可以使用mdct增益參數來估計語音分組(以及任何鄰近的丟失的語音分組)的感知重要性。
對於基於mdct的編碼器,為了減小在隨後的編碼過程中的熵,首先用具有對數量化的包絡編碼器對mdct增益進行編碼。這個增益是語音帶信號能量水平的直接反映並且可以由計算語音質量估計的設備檢索。可以根據下式從mdct增益直接計算頻帶加權信號能量水平p:
n:原始頻帶中用於響度生成的帶數量;
m:mdct增益中的帶數量;
k:mdct係數中的槽(bin)數量;
t:時間軸上的幀數量;
binmdct:mdct槽係數,它是k*t矩陣
bandloudness=w1·binmdct(11)
其中w1是n*k矩陣,以將槽係數變換為帶能。帶加權信號能量p可以通過下式計算:
其中b是1*n向量(頻帶感知重要性的加權,諸如b加權),nf是用於歸一化的n*n矩陣。mdct增益由下式得出:
bandgain=w2·binmdct(13)
其中binmdct是k*t矩陣,w2是m*k矩陣。
從等式13,可以近似逆矩陣以恢復具有與binmdct完全相同的帶能的bin′mdct:
bin′mdct=w3·bandgain(14)
其中w3是k*m矩陣。
通過將等式14代入等式11,我們可以得到:
p=b·nf·w1·(w3·bandgain)2=w4·(w3·bandgain)2(15)
其中w4是1*k向量,由下式計算:
w4=b·nf·w1(16)
用於計算頻帶加權信號能量水平p的以上策略可以被用於任何基於變換的編解碼器(dct、qmf等),其中對應的增益是可提取的。
為了估計丟失的語音分組的感知重要性而部分解碼接收到的編碼語音分組中的至少一些的其它合適方法同樣可以被使用。在美國專利申請us20090094026(alcatellucentusainc)中描述了一種這樣的方法。
應當注意,根據一些實施例,通過完全解碼接收到的編碼語音分組中的至少一些來估計丟失的語音分組的感知重要性。
圖5描述了用於修改基於分組的語音通信系統中與丟失的語音分組相關的統計度量的方法500。第一步驟s502是接收包括從語音通信系統中的一個或多個端點發送的編碼語音分組的序列的數據的步驟,其中從一個或多個端點發送的編碼語音分組包括接收的編碼語音分組的序列以及在從一個或多個端點的發送期間丟失或由於發送中的延時和/或抖動而被丟棄的一個或多個丟失的語音分組。基於接收到的編碼語音分組的序列,計算與丟失的語音分組相關的統計度量s504。然後,基於丟失的語音分組的感知重要性修改s506統計度量。可選地,經修改的統計度量被用作語音質量估計算法的輸入,使得與使用在步驟s504中計算的未經修改的統計度量作為到相同語音質量估計算法的輸入相比,語音質量估計的預測誤差被減小。
圖6描述了用於計算基於分組的語音通信系統中語音質量估計的方法600。第一步驟s602是接收包括編碼語音分組的序列的數據的步驟。基於接收到的編碼語音分組的序列,計算統計度量s604。方法600中的最後步驟是使用語音質量估計算法來計算s608語音質量估計的步驟。計算s608基於可在第一輸入模式與第二輸入模式之間切換的輸入。在第一輸入模式下,使用基於接收到的編碼語音分組的序列被計算s604的統計度量作為輸入。在第二輸入模式下,基於接收到的編碼語音分組的序列計算s604的統計度量首先被預處理s606,然後用作語音質量估計的計算s608的輸入。預處理s606的步驟導致,與不執行預處理相比,語音質量估計的預測誤差被減小。
iv.等同物、擴展、替代和雜項
在研究了以上描述之後,本公開的另外的實施例對於本領域技術人員將變得清楚。雖然本說明書和附圖公開了實施例和示例,但是本公開不限於這些具體示例。在不違背由所附權利要求限定的本公開的範圍的情況下,可以進行許多修改和變化。權利要求中出現的任何附圖標記都不應當被理解為限制權利要求的範圍。
此外,實踐本公開的技術人員可以通過研究附圖、公開內容和所附權利要求來理解和實現所公開的實施例的變化。在權利要求中,單詞「包括」並不排除其它元素或步驟,並且不定冠詞「一個」或「一」不排除多個。僅僅在相互不同的從屬權利要求中記載某些測量這一事實並不指示這些測量的組合不能被有利地使用。
上文公開的系統和方法可以被實現為軟體、固件、硬體或其組合。在硬體實現中,在以上描述中提及的功能單元之間的任務劃分不一定對應於到物理單元的劃分;相反,一個物理部件可以具有多個功能,並且一個任務可以通過若干個物理部件合作來執行。某些部件或所有部件可以被實現為由數位訊號處理器或微處理器執行的軟體,或者被實現為硬體或專用集成電路。這樣的軟體可以分布在計算機可讀介質上,計算機可讀介質可以包括計算機存儲介質(或非暫態介質)和通信介質(或暫態介質)。如本領域技術人員眾所周知的,術語「計算機存儲介質」包括以任何方法或技術實現的易失性和非易失性、可移動和不可移動介質以用於存儲信息(諸如計算機可讀指令、數據結構、程序模塊或其它數據)。計算機存儲介質包括但不限於ram、rom、eeprom、快閃記憶體或其它存儲器技術,cd-rom、數字多功能盤(dvd)或其它光碟存儲器、磁帶盒、磁帶、磁碟存儲器或其它磁存儲設備,或者可用於存儲期望信息並且可由計算機訪問的任何其它介質。另外,本領域技術人員眾所周知的是,通信介質通常在諸如載波或其它傳送機制的調製數據信號中體現計算機可讀指令、數據結構、程序模塊或其它數據,並且包括任何信息輸送介質。