一種完整的語音數據獲得方法及裝置與流程
2023-10-19 19:52:57 3
本發明涉及語音處理技術領域,特別是涉及一種完整的語音數據獲得方法及裝置。
背景技術:
隨著人工智慧的發展和語音處理技術的日漸成熟,自然語音交互技術也得到了快速發展。目前,雲端模式逐漸興起,終端負責簡單的語音信號處理運算,將超規模計算託付給雲端,這樣可以降低終端的運行壓力,也為語音交互提供了更多選擇。相應的,各大語音雲服務廠商已經推出了各種語音接入方案,終端只需將實時的語音信號數據發送至語音雲服務廠商的語音處理引擎中,即可對語音數據做進一步處理。在這種情況下,終端如何在實時接收到的麥克風採樣數據中保證獲得的語音數據的完整性,是當前關注重點問題之一。
在現有技術中,為解決上述問題,常使用的方法是,當檢測到語音信號的前端點時開始錄入語音數據,在檢測到語音信號的後端點時即停止錄入語音數據,即將相鄰的前端點和後端點之間的數據作為完整的語音數據。
這種方法過於依賴於語音端點檢測技術,目前語音端點檢測技術雖在準確率上有較大提升,但是仍有誤判的可能。如果存在誤判,則獲得的語音數據的起始位置可能被延後截取,結束位置又可能被提前,從而導致語音數據的不完整,容易出現音節丟失、語音不連續等問題,進而導致雲端無法完成對語音數據的進一步處理。
技術實現要素:
本發明的目的是提供一種完整的語音數據獲得方法及裝置,以降低對語音端點檢測精度要求,保證獲得完整的語音數據,避免出現音節丟失、語音不連續等問題,使雲端可以順利完成對語音數據的進一步處理。
為解決上述技術問題,本發明提供如下技術方案:
一種完整的語音數據獲得方法,包括:
在接收麥克風採樣數據的過程中,利用所述採樣數據實時刷新前向語音幀緩存器中的緩存數據;
在檢測到所述採樣數據中存在語音信號的前端點時,開始記錄所述採樣數據,並將所述前向語音幀緩存器中當前緩存數據確定為第一緩存數據;
在檢測到所述採樣數據中存在語音信號的後端點時,停止記錄所述採樣數據,並開始在空的後向語音幀緩存器中填充所述採樣數據,直至達到設定條件時,將所述後向語音幀緩存器中當前緩存數據確定為第二緩存數據;
在記錄得到的所述採樣數據的前部添加所述第一緩存數據,在記錄得到的所述採樣數據的尾部添加所述第二緩存數據,獲得完整的語音數據。
在本發明的一種具體實施方式中,所述直至達到設定條件時,將所述後向語音幀緩存器中當前緩存數據確定為第二緩存數據,包括:
直至所述後向語音幀緩存器填滿時,將所述後向語音幀緩存器中當前緩存數據確定為第二緩存數據。
在本發明的一種具體實施方式中,還包括:
如果在所述後向語音幀緩存器未填滿時,再次檢測到所述採樣數據中存在語音信號的前端點,則將所述後向語音幀緩存器清空,並繼續記錄所述採樣數據,直至再次檢測到所述採樣數據中存在語音信號的後端點時,重複執行所述停止記錄所述採樣數據,並開始在空的後向語音幀緩存器中填充所述採樣數據,直至所述後向語音幀緩存器填滿時,將所述後向語音幀緩存器中當前緩存數據確定為第二緩存數據的步驟。
在本發明的一種具體實施方式中,所述前向語音幀緩存器中初始預存有設定長度的隨機數據。
在本發明的一種具體實施方式中,所述前向語音幀緩存器和所述後向語音幀緩存器均為數據先進先出緩存結構。
一種完整的語音數據獲得裝置,包括:
數據刷新模塊,用於在接收麥克風採樣數據的過程中,利用所述採樣數據實時刷新前向語音幀緩存器中的緩存數據;
數據第一獲得模塊,用於在檢測到所述採樣數據中存在語音信號的前端點時,開始記錄所述採樣數據,並將所述前向語音幀緩存器中當前緩存數據確定為第一緩存數據;
數據第二獲得模塊,用於在檢測到所述採樣數據中存在語音信號的後端點時,停止記錄所述採樣數據,並開始在空的後向語音幀緩存器中填充所述採樣數據,直至達到設定條件時,將所述後向語音幀緩存器中當前緩存數據確定為第二緩存數據;
語音數據獲得模塊,用於在記錄得到的所述採樣數據的前部添加所述第一緩存數據,在記錄得到的所述採樣數據的尾部添加所述第二緩存數據,獲得完整的語音數據。
在本發明的一種具體實施方式中,所述數據第二獲得模塊,具體用於:
直至所述後向語音幀緩存器填滿時,將所述後向語音幀緩存器中當前緩存數據確定為第二緩存數據。
在本發明的一種具體實施方式中,還包括重複執行模塊,用於:
如果在所述後向語音幀緩存器未填滿時,再次檢測到所述採樣數據中存在語音信號的前端點,則將所述後向語音幀緩存器清空,並繼續記錄所述採樣數據,直至再次檢測到所述採樣數據中存在語音信號的後端點時,重複執行所述停止記錄所述採樣數據,並開始在空的後向語音幀緩存器中填充所述採樣數據,直至所述後向語音幀緩存器填滿時,將所述後向語音幀緩存器中當前緩存數據確定為第二緩存數據的步驟。
在本發明的一種具體實施方式中,所述前向語音幀緩存器中初始預存有設定長度的隨機數據。
在本發明的一種具體實施方式中,所述前向語音幀緩存器和所述後向語音幀緩存器均為數據先進先出緩存結構。
應用本發明實施例所提供的技術方案,在接收麥克風採樣數據的過程中,利用採樣數據實時刷新前向語音幀緩存器中的緩存數據,在檢測到採樣數據中存在語音信號的前端點時,開始記錄採樣數據,並將前向語音幀緩存器中當前緩存數據確定為第一緩存數據,在檢測到採樣數據中存在語音信號的後端點時,停止記錄採樣數據,並開始在空的後向語音幀緩存器中填充採樣數據,直至達到設定條件時,將後向語音幀緩存器中當前緩存數據確定為第二緩存數據,在記錄得到的採樣數據的前部添加第一緩存數據,在記錄得到的採樣數據的尾部添加第二緩存數據,獲得完整的語音數據。設置了前向語音幀緩存器和後向語音幀緩存器的雙緩存結構,可以降低對語音端點檢測精度要求,保證獲得完整的語音數據,避免出現音節丟失、語音不連續等問題,使雲端可以順利完成對語音數據的進一步處理。
附圖說明
為了更清楚地說明本發明實施例或現有技術中的技術方案,下面將對實施例或現有技術描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對於本領域普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他的附圖。
圖1為本發明實施例中一種完整的語音數據獲得方法的實施流程圖;
圖2為本發明實施例中完整的語音數據獲得方法的整體流程圖;
圖3為本發明實施例中一種完整的語音數據獲得裝置的結構示意圖。
具體實施方式
為了使本技術領域的人員更好地理解本發明方案,下面結合附圖和具體實施方式對本發明作進一步的詳細說明。顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。基於本發明中的實施例,本領域普通技術人員在沒有做出創造性勞動前提下所獲得的所有其他實施例,都屬於本發明保護的範圍。
本發明實施例提供的一種完整的語音數據獲得方法可以應用於終端,具體的,可以應用於終端處理器。
參見圖1所示,為本發明實施例所提供的一種完整的語音數據獲得方法的實施流程圖,該方法可以包括以下步驟:
s110:在接收麥克風採樣數據的過程中,利用採樣數據實時刷新前向語音幀緩存器中的緩存數據。
在本發明實施例中,設置有前向語音幀緩存器,該前向語音幀緩存器中初始預存有設定長度的隨機數據,該前向語音幀緩存器為數據先進先出緩存結構。
在實際應用中,終端中內置或外置的麥克風可以實時捕捉採樣數據。處理器在接收麥克風採樣數據的過程中,可以利用採樣數據實時刷新前向語音幀緩存器中的緩存數據,即將接收到採樣數據不斷地向前向語音幀緩存器中傳輸。初始時,前向語音幀緩存器中的緩存數據為隨機數據,隨著採樣數據不斷進入,後進入到前向語音幀緩存器中的數據將先進入到前向語音幀緩存器中的數據擠出。在實際應用中,可以使前向語音幀緩存器一直處於充滿狀態。
s120:在檢測到採樣數據中存在語音信號的前端點時,開始記錄採樣數據,並將前向語音幀緩存器中當前緩存數據確定為第一緩存數據。
在本發明實施例中,在接收麥克風採樣數據的過程中,可以實時對採樣數據進行端點檢測,確定採樣數據中是否存在語音信號的前端點或後端點。前端點可記為start,後端點可記為end。具體可以利用現有技術中語音端點檢測算法進行前端點或後端點的檢測,本發明實施例對此不再贅述。
在檢測到採樣數據中存在語音信號的前端點時,開始記錄採樣數據,記錄的採樣數據可以在指定位置處保存。
在檢測到採樣數據中存在語音信號的前端點之前,一直將採樣數據實時刷新前向語音幀緩存器中的緩存數據,即前向語音幀緩存器中的緩存數據一直處於刷新狀態。在檢測到採樣數據中存在語音信號的前端點時,前向語音幀緩存器中當前緩存數據為與當前檢測到的前端點相鄰的一段數據,可以將前向語音幀緩存器中當前緩存數據確定為第一緩存數據。
第一緩存數據的起始點距離前端點的時間長度與前向語音幀緩存器的長度的關係式如公式(1)所示:
其中,lp為前向語音幀緩存器的長度,tp為第一緩存數據的起始點距離前端點的時間長度,t為硬體採樣率,c為通道數,s為採樣數據精度。
s130:在檢測到採樣數據中存在語音信號的後端點時,停止記錄採樣數據,並開始在空的後向語音幀緩存器中填充採樣數據,直至達到設定條件時,將後向語音幀緩存器中當前緩存數據確定為第二緩存數據。
在本發明實施例中,設置有後向語音幀緩存器,該後向語音幀緩存器為數據先進先出緩存結構,該後向語音幀緩存器初始為空。
在檢測到採樣數據中存在語音信號的後端點時,停止記錄採樣數據,在上述指定位置處存儲有記錄得到的採樣數據。
在未檢測到採樣數據中存在語音信號的後端點時,後向語音幀緩存器一直為空。在檢測到採樣數據中存在語音信號的後端點時,開始在空的後向語音幀緩存器中填充採樣數據,直至達到設定條件時,如達到設定時長時,或者後向語音幀緩存器填滿時,將後向語音幀緩存器中當前緩存數據確定為第二緩存數據。第二緩存數據為與當前檢測到的後端點相鄰的一段數據。第二緩存數據的結束點距離後端點的時間長度與後向語音緩存器的長度的關係可以參考公式(1)獲得。
將後向語音幀緩存器中當前緩存數據確定為第二緩存數據後,可以將後向語音幀緩存器清空。
在本發明的一種具體實施方式中,設定條件可以為後向語音幀緩存器填滿條件,即在檢測到採樣數據中存在語音信號的後端點時,開始在後向語音幀緩存器中填充採樣數據,直至後向語音幀緩存器填滿時,將後向語音幀緩存器中當前緩存數據確定為第二緩存數據。後向語音幀緩存器填滿狀態可以記為end_delay。
在本發明的一個實施例中,該方法還可以包括以下步驟:
如果在後向語音幀緩存器未填滿時,再次檢測到採樣數據中存在語音信號的前端點,則將後向語音幀緩存器清空,並繼續記錄採樣數據,直至再次檢測到採樣數據中存在語音信號的後端點時,重複執行停止記錄採樣數據,並開始在後向語音幀緩存器中填充採樣數據,直至後向語音幀緩存器填滿時,將後向語音幀緩存器中當前緩存數據確定為第二緩存數據的步驟。
可以理解的是,如果檢測到採樣數據中存在語音信號的後端點後,在間隔很短的時間內再次檢測到採樣數據中存在語音信號的前端點,則表明前一段語音數據與後一段語音數據相關性較大,可以將這兩段語音數據作為一個語音數據來處理。
在檢測到採樣數據中存在語音信號的後端點時,停止記錄採樣數據,並開始在空的後向語音幀緩存器中填充採樣數據,在填充過程中,如果在後向語音幀緩存器未填滿時,再次檢測到採樣數據中存在語音信號的前端點,則可以將後向語音幀緩存器清空,繼續記錄採樣數據,記錄的採樣數據存儲至上述指定位置。直至再次檢測到採樣數據中存在語音信號的後端點時,重複執行停止記錄採樣數據,並開始在空的後向語音幀緩存器中填充採樣數據,直至後向語音幀緩存器填滿時,將後向語音幀緩存器中當前緩存數據確定為第二緩存數據的步驟。
這樣可以避免相關性較大的語音數據被分割成兩部分,影響對語音數據的進一步處理。
s140:在記錄得到的採樣數據的前部添加第一緩存數據,在記錄得到的採樣數據的尾部添加第二緩存數據,獲得完整的語音數據。
通過上述步驟s120,獲得了第一緩存數據,通過上述步驟s130,獲得了第二緩存數據。通過上述步驟s120和步驟s130可以獲得記錄得到的採樣數據。
記錄得到的採樣數據具有前端點和後端點,第一緩存數據是在前端點之前、與前端點相鄰的一段數據,第二緩存數據是在後端點之後、與後端點相鄰的一段數據。
在記錄得到的採樣數據的前部添加第一緩存數據,在記錄得到的採樣數據的尾部添加第二緩存數據,即可獲得完整的語音數據。通過第一緩存數據和第二緩存數據可以有效避免通過端點檢測技術檢測得到的前端點和後端點存在誤判時帶來的問題,如減少音節丟失概率等。
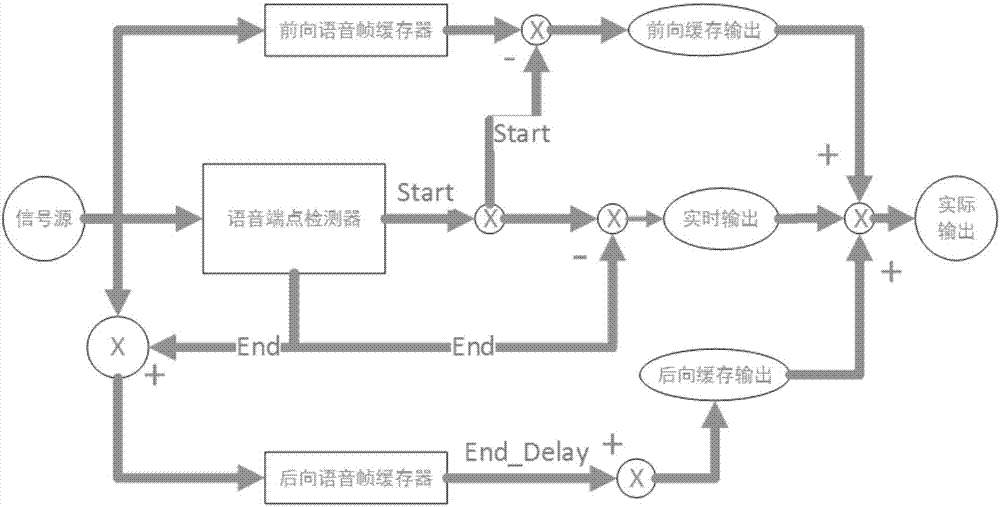
以圖2為例,對本發明實施例提供的完整的語音數據獲得方法進行整體說明。信號源為麥克風採樣數據,採樣數據實時刷新前向語音幀緩存器,通過語音端點檢測器可以對採樣數據中的語音信號端點進行檢測。在檢測到採樣數據中存在語音信號的前端點start時,開始記錄採樣數據,實時輸出採樣數據到指定位置,並通過前向緩存輸出得到第一緩存數據。在檢測到採樣數據中存在語音信號的後端點end時,停止實時輸出採樣數據,開始在空的後向語音幀緩存器中填充採樣數據,達到end_delay條件時,通過後向緩存輸出得到第二緩存數據,將前向緩存輸出的第一緩存數據、實時輸出的採樣數據和後向緩存輸出的第二緩存數據結合起來,即可得到完整的實際輸出的語音數據。
圖2中,+/-表示關卡的開通、斷開。
應用本發明實施例所提供的方法,在接收麥克風採樣數據的過程中,利用採樣數據實時刷新前向語音幀緩存器中的緩存數據,在檢測到採樣數據中存在語音信號的前端點時,開始記錄採樣數據,並將前向語音幀緩存器中當前緩存數據確定為第一緩存數據,在檢測到採樣數據中存在語音信號的後端點時,停止記錄採樣數據,並開始在空的後向語音幀緩存器中填充採樣數據,直至達到設定條件時,將後向語音幀緩存器中當前緩存數據確定為第二緩存數據,在記錄得到的採樣數據的前部添加第一緩存數據,在記錄得到的採樣數據的尾部添加第二緩存數據,獲得完整的語音數據。設置了前向語音幀緩存器和後向語音幀緩存器的雙緩存結構,可以降低對語音端點檢測精度要求,保證獲得完整的語音數據,避免出現音節丟失、語音不連續等問題,使雲端可以順利完成對語音數據的進一步處理。
相應於上面的方法實施例,本發明實施例還提供了一種完整的語音數據獲得裝置,下文描述的一種完整的語音數據獲得裝置與上文描述的一種完整的語音數據獲得方法可相互對應參照。
參見圖3所示,該裝置包括以下模塊:
數據刷新模塊310,用於在接收麥克風採樣數據的過程中,利用採樣數據實時刷新前向語音幀緩存器中的緩存數據;
數據第一獲得模塊320,用於在檢測到採樣數據中存在語音信號的前端點時,開始記錄採樣數據,並將前向語音幀緩存器中當前緩存數據確定為第一緩存數據;
數據第二獲得模塊330,用於在檢測到採樣數據中存在語音信號的後端點時,停止記錄採樣數據,並開始在空的後向語音幀緩存器中填充採樣數據,直至達到設定條件時,將後向語音幀緩存器中當前緩存數據確定為第二緩存數據;
語音數據獲得模塊340,用於在記錄得到的採樣數據的前部添加第一緩存數據,在記錄得到的採樣數據的尾部添加第二緩存數據,獲得完整的語音數據。
在本發明的一種具體實施方式中,數據第二獲得模塊330,具體用於:
直至後向語音幀緩存器填滿時,將後向語音幀緩存器中當前緩存數據確定為第二緩存數據。
在本發明的一種具體實施方式中,還包括重複執行模塊,用於:
如果在後向語音幀緩存器未填滿時,再次檢測到採樣數據中存在語音信號的前端點,則將後向語音幀緩存器清空,並繼續記錄採樣數據,直至再次檢測到採樣數據中存在語音信號的後端點時,重複執行停止記錄採樣數據,並開始在空的後向語音幀緩存器中填充採樣數據,直至後向語音幀緩存器填滿時,將後向語音幀緩存器中當前緩存數據確定為第二緩存數據的步驟。
在本發明的一種具體實施方式中,前向語音幀緩存器中初始預存有設定長度的隨機數據。
在本發明的一種具體實施方式中,前向語音幀緩存器和後向語音幀緩存器均為數據先進先出緩存結構。
本說明書中各個實施例採用遞進的方式描述,每個實施例重點說明的都是與其它實施例的不同之處,各個實施例之間相同或相似部分互相參見即可。對於實施例公開的裝置而言,由於其與實施例公開的方法相對應,所以描述的比較簡單,相關之處參見方法部分說明即可。
專業人員還可以進一步意識到,結合本文中所公開的實施例描述的各示例的單元及算法步驟,能夠以電子硬體、計算機軟體或者二者的結合來實現,為了清楚地說明硬體和軟體的可互換性,在上述說明中已經按照功能一般性地描述了各示例的組成及步驟。這些功能究竟以硬體還是軟體方式來執行,取決於技術方案的特定應用和設計約束條件。專業技術人員可以對每個特定的應用來使用不同方法來實現所描述的功能,但是這種實現不應認為超出本發明的範圍。
結合本文中所公開的實施例描述的方法或算法的步驟可以直接用硬體、處理器執行的軟體模塊,或者二者的結合來實施。軟體模塊可以置於隨機存儲器(ram)、內存、只讀存儲器(rom)、電可編程rom、電可擦除可編程rom、寄存器、硬碟、可移動磁碟、cd-rom、或技術領域內所公知的任意其它形式的存儲介質中。
本文中應用了具體個例對本發明的原理及實施方式進行了闡述,以上實施例的說明只是用於幫助理解本發明的技術方案及其核心思想。應當指出,對於本技術領域的普通技術人員來說,在不脫離本發明原理的前提下,還可以對本發明進行若干改進和修飾,這些改進和修飾也落入本發明權利要求的保護範圍內。