一種基於數據模型對工業廢水處理過程的故障檢測與診斷的方法與流程
2023-12-04 16:09:41 4
本發明屬於工業化工與過程控制交叉領域,涉及工業廢水處理過程中,通過測量數據量及時反映系統運行狀態的方法。
背景技術:
工業廢水處理工程的建設主要是解決排水系統汙水隨意排放的問題,改善和治理汙水對當地生態的嚴重汙染問題。工業系統的排水質量對於人們的生活環境,社會的可持續發展,都有著至關重要的影響。
針對進水水質為食品工業廢水,其可生化性較高。汙水濃度較高,其生化需氧量(biochemicaloxygendemand,bod)、化學需氧量(chemicaloxygendemand,cod)、氮總含量(totalnitrogen,tn)、磷總含量(totalphosphorous,tp)等濃度是普通城市汙水的3-4倍。對於大規模汙水,處理廠採用最多的工藝就是傳統活性汙泥法的生物曝氣工藝。這種工藝是對物理處理過程之後利用在同一人工環境中培養的好氧生物(包括細菌和原生物)對汙水中的有機汙染質進行降解。該工藝較為簡單,對cod,bod和ss的去除效率可以達到預期要求。但是,這種方法只有單一的生物環境,不能發揮和強化不同微生物的生物特性和優勢,既不能提高對高濃度汙水的有效處理,也不能對氮、磷營養元素的有效去除,因此必須採用生化二級處理來滿足預期的處理目標。生物處理技術所遵循的途徑主要有兩條:一是提高參與作用的微生物量,增加有機物與微生物接觸的機率,其實現的手段是提高混合液濃度。二是發揮不同微生物優勢的代謝特性,篩選菌種,提供與優勢微生物生理特性相適合的生物環境。使各類微生物盡其所能「分工負責」,發揮最大優勢來實現所預期的處理目標。生物除磷脫氮工藝即採取這一途徑。其脫氮是通過延長曝氣時間,利用世代時間較長的消化菌,將氨氮轉化為硝酸鹽,再利用缺氧條件下的兼性厭氧反消化菌將硝態氮轉化為氣態氮逸出,從而達到去除水中nh3-n的目的。除磷則是先利用厭氧條件下兼性和好氧聚磷菌進行磷的有效釋放,再利用經厭氧放磷的菌群在好氧條件下大家增殖吸磷的特性,使原汙水中的磷轉化為生物細胞(活性汙泥),最終通過沉澱分離,將富磷剩餘汙泥排除來實現的。由於這一完整的除磷、脫氮過程是分別在厭氧、兼氧和好氧條件下進行的,所以通常被稱之為a2/o工藝(即厭氧anaerobic+缺氧anoxic+好氧oxic工藝)。在此工藝改良基礎上,設計出整體汙水處理系統,其工藝流程框圖見圖1。
汙水系統中a2/o部分的詳細工藝,該池體由四個部分組成,並聯工作。每池從前至後依次是進水區,厭氧區,缺氧區,好氧區。好氧區內安裝爆氧頭,其餘各區均安裝水下攪拌器,防止混合液形成沉澱。a2/o反應池的運行過程對於廢水處理過程有著至關重要的作用。如當進水速度過快,使反應池中反應不充分,或是反應池中氧含量不在正常範圍,使得氮磷去除不充分,嚴重時導致處理後的水質不達標,影響生態環境。因此,如何確定目前生產狀態、維護設備安全、穩定與優化運行,是工業廢水處理工程迫切需要解決的重要問題之一。
近年來基於數據模型的過程建模在工業中獲得了大量成功的應用,解決了許多運行系統狀態監控問題。基於數據驅動的過程監控是利用收集系統過程中過程數據建模,構造過程觀測的監控統計量,從而監測系統運行的狀態,及時發現系統運行故障並進行診斷。a2/o反應池中的生物化學反應也產生了大量數據,這些數據蘊含汙水處理過程的特徵信息,因此可以基於工業廢水處理過程產生與分析數據,建立過程關聯模型。本發明採用了基於載荷選取主元的主元分析支持向量數據域描述(loading-basedprincipalcomponentselectionforprincipalcomponentanaylsisintegratedwithsupportvectordatadescription,ppca-svdd)建模方法,利用工業廢水處理過程中收集到的過程數據建立數學模型。針對每個變量選取特定敏感主元構成變量子空間,對每個變量的變化更敏感,從而具備更好的過程故障信息提取能力。通過svdd統計量構造,使得過程監控統計量具有反應過程狀態的能力,從而達到過程故障檢測的目的。當檢測到故障後,根據過程數據,做出相應的變量貢獻圖,使得過程故障原因得以診斷,從而可以進一步修正故障,使得過程恢復正常運行。
技術實現要素:
本發明目的是利用工業廢水處理工廠的過程數據,提供一個狀態監控的統計量來監測運行過程,及時發現系統故障並進行診斷。選取的觀測變量有:進水區溶氧量do(x1,mg/l)、好氧區懸浮體含量ss(x2,mg/l)、進水口流量qin(x3,m3/s)、出水口流量qef(x4,m3/s)、化學需氧量codin(x5,mg/l)、以及出水口懸浮體含量ssef(x6,mg/l)。將這6個變量作為該工業廢水處理系統的原始監測變量,利用相關的測量儀表,直接測量或間接計算獲得x1~x6。採集工業裝置樣本數據,構建數據模型,通過計算獲得的過程監測統計量對廢水處理過程實現故障監測和診斷,以保障系統過程的正常運行。
1.原始監測變量的選取
工業廢水處理的工藝流程中,a2/o反應池是整個系統中的核心單元。影響反應池氧化反應正常運行的關鍵因素有:反應池中的氧含量、實際需氧量、進水的流量、出水的流量、反應物濃度。
本發明的特點是:
通過利用過程收集的樣本數據,建立基於載荷選取主元的主元分析支持向量數據域描述(ppca-svdd)模型,構造過程監控統計量,實現對整個運行過程進行實時監控,從而及時地監測到過程故障並診斷。
為此,基於以上分析說明,該工業廢水處理工程的監測變量選取如下:
(1)進水區溶氧量do(x1,mg/l)
(2)好氧區懸浮體含量ss(x2,mg/l)
(3)進水口流量qin(x3,m3/s)
(4)出水口流量qef(x4,m3/s)
(5)化學需氧量codin(x5,mg/l)
(6)以及出水口懸浮體含量ssef(x6,mg/l)
以上六個變量均可由測量儀器直接獲得。
2.建模樣本的預處理
為了消除量綱的影響,對採集的樣本數據進行歸一化預處理。輸入變量利用式(1)進行歸一化處理:
(1)式中,xi是第i個觀測變量的實際測量值,μi表示觀測量xi所對應的均值,σi表示觀測量xi所對應的方差,表示第i個輸入變量歸一化後的值。
採集到n組代表性的工業裝置數據,其中每組數據包含輸入變量[x1,x2,x3,x4,x5,x6],經公式(1)歸一化處理後得到形成建模樣本。
對於在t時刻實時收集的數據xt,對其利用式(1)中獲得的均值方差進行歸一化處理,如下,
其中,μ=[μ1,μ2,…,μ6],且σ=[σ1,σ2,…,σ6]。
3.基於ppca-svdd的工業廢水處理過程監控模型
假設建模樣本的樣本容量為n,首先對建模數據按照(1)式歸一化,採用ppca-svdd建模方法,建立初始模型;然後,通過分析pca建模產生的載荷矩陣p以及每個載荷向量pi對應的特徵值λi,根據(2)式計算的轉換加權值,為每個變量選取敏感主元。
其中,pi,j為載荷矩陣中第(i,j)個元素。對於某一變量來說,計算其所對應的所有加權值的均值通過比較wi,j和選取大於均值的轉換加權值所對應的載荷向量,構成變量xi的投影空間同時,對應的特徵值也保留構成特徵值矩陣這樣,每個變量都產生與之對應的新子空間。將數據分別投影到各個空間,可以根據(3)式計算子統計量
由於每個變量所對應的子空間對於該變量的變化更為敏感,因此當變量發生故障變化時,所對應的空間可以更快更準確的檢測到。正常的訓練樣本得到對應於6個變量的統計量根據支持向量數據描述域svdd,將利用函數非線性投影到高維空間,再尋找可以將投影后數據點包圍的儘可能小的超球體,其中,svdd將問題轉換為解決下列最優化問題:
其中,r和τ分別表示超球體的半徑和中心,參數c表示球體體積大小與正常樣本分錯分數之間的權衡,ξi表示鬆弛係數,即允許訓練樣本被誤判的概率。上述優化問題的對偶形式可以表示成,
其中βi為對應的拉格朗日乘子,svdd選取0≤βi≤c所對應的各個樣本作為支持向量。這樣,超球體的球心和半徑就可以根據下式求得,
其中,為模型支持向量中的任意一個。
對於t時刻收集的一個有包含六個變量的歸一化目標測試樣本其投影到各子空間,計算各子空間的統計量組成統計量矩陣再計算其到球心的距離平方可以表示為,
當測試樣本在特徵空間中到圓心的距離大於訓練樣本所得半徑時,我們認為該樣本為異常樣本,反之,該樣本被認為處於正常狀態。過程監控統計量設計如下,
當dr統計量小於1時,認為系統正常;當大於1時,即認為過程監控統計量檢測到故障,發出警告。接著,就應進行相應的故障診斷來發現過程發生故障的根本原因,從而修復系統。這裡,利用能監測到故障的子空間中的主元信息,計算貢獻率,如下
其中為中第j個元素為中第j個元素,為中第(i,j)個元素,則可以計算得到變量xi對於得分的貢獻率conti,j。接著,變量xi的總貢獻率可以算得,
由於變量對應的敏感主元含有更多關於過程的故障信息量,因此基於敏感主元選取所作的貢獻圖可以給出一個更加準確的故障診斷結果。
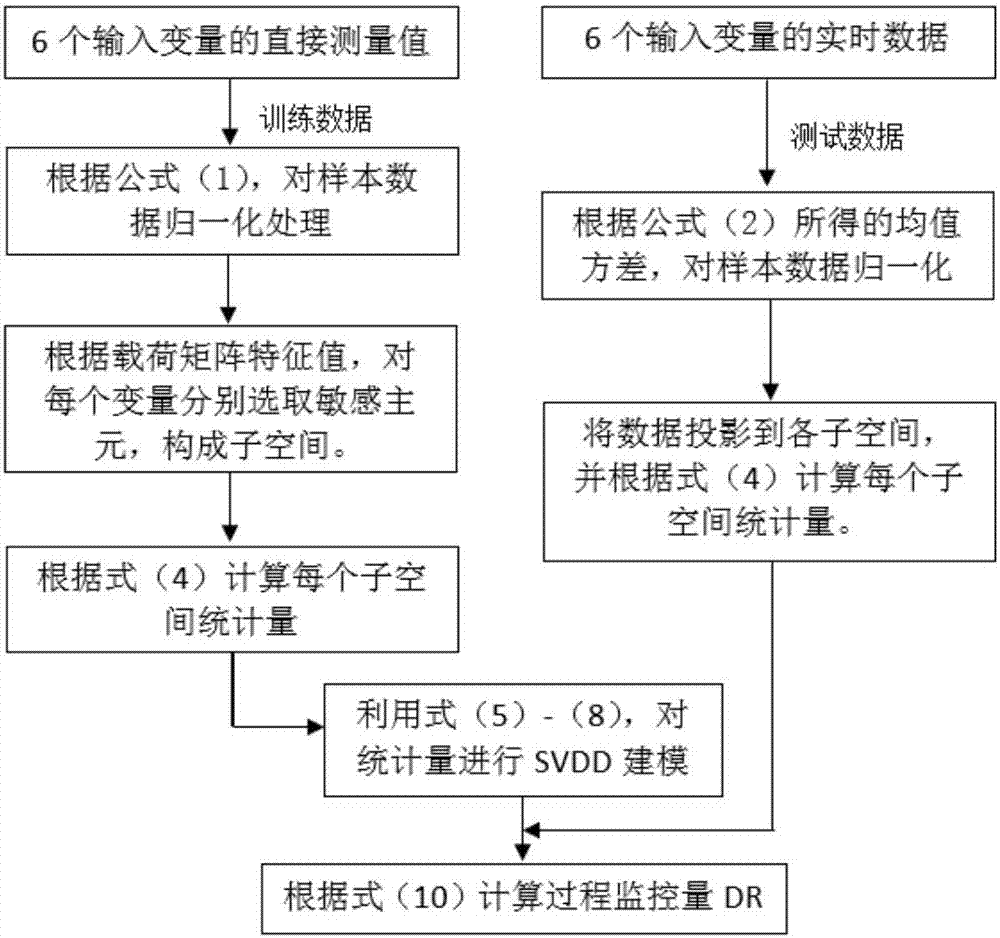
4.工業廢水處理系統中過程監控統計量的在線計算
工業廢水處理系統過程監控統計量在線計算流程如圖2所示。進水區溶氧量、好氧區懸浮體含量ss、進水口流量、出水口流量、化學需氧量、以及出水口懸浮體含量,基於上述6個輸入變量的直接測量數據,通過(1)式對數據進行歸一化處理;利用pca對訓練數據進行整體建模,根據產生的載荷向量為每個變量分別選取主元,形成子空間;分別計算每個子空間的t2統計量,並構造svdd模型;對於監控的實時數據,利用(2)式產生的均值方差,進行歸一化處理;將歸一化的實時監控數據投影到各子空間,計算得到相應的t2統計量;計算統計量在svdd構造的高維空間中距離圓心的距離,從而判斷該時刻的監控數據是否正常。另外,當發現系統中有故障時,用式(11)(12)計算變量的貢獻率,實現故障診斷。
附圖說明
圖1工業廢水處理工藝流程框圖。
圖2工業廢水處理過程監控統計量在線計算流程。
具體實施方式
以下通過實施例對本發明作進一步說明:
對於六個變量,進水區溶氧量do(x1,mg/l)、好氧區懸浮體含量ss(x2,mg/l)、進水口流量qin(x3,m3/s)、出水口流量qef(x4,m3/s)、化學需氧量codin(x5,mg/l)、以及出水口懸浮體含量ssef(x6,mg/l),採集一組100個樣本的系統的歷史正常數據作為訓練數據,以及一組由100個樣本組成的實時過程觀測數據。
1.預處理樣本
對上述採集的第一組由200個樣本構成的數據進行歸一化處理,利用(1)式:x1的均值為3.78,方差為1.37;x2的均值為4.00,方差為1.27;x3的均值為3417.48,方差為1290.31;x4的均值為4090.31,方差為1274.90;x5的均值為24.82,方差為3.58;x6的均值為19.58,方差為33.53。進行歸一化計算:
對t時刻實時收集的數據xt利用(8)式進行歸一化處理
其中,均值μ=[3.78,4.00,3417.48,4090.31,24.82,19.58],方差σ=[1.37,1.27,1290.31,1274.90,3.58,33.53]。這裡有小數的形式,一律保留小數點後兩位,四捨五入計算。
2.基於ppca-svdd的過程監控模型中統計量的構造
採用ppca-svdd建模方法,對樣本數為100的訓練數據進行建模,樣本數為100的數據進行測試。其具體的模型參數如下:
(1)首先對訓練數據進行pca建模,產生六個主元,按式(3)計算加權矩陣具體如下:
根據加權值大於該變量所對所有加權值的均值,即選中該加權值所對應的向量構造子空間這一原理,每個變量選取的主元結果如下:
變量x1:p2,p3,p5
變量x2:p2,p3
變量x3:p1,p6
變量x4:p1,p6
變量x5:p1,p2,p3,p5
變量x6:p1,p4
由此,對應6個變量生成6個子空間,對每個變量實現分散監控。每個子空間的轉換矩陣為:
空間1:
空間2:
空間3:
空間4:
空間5:
空間6:
(2)核函數k(·)中,s2=100;
(3)svdd模型中,參數c=1.2;
(4)由各子空間統計量構成的svdd模型,產生的參數值如下:
β值為0.3006,0.4931,0.6545,0.8119,0.9374,0;超球體半徑r=0.216。
上述通過實例描述了,基於工業廢水處理系統,通過測量得到的進水區溶氧量、好氧區懸浮體含量、進水口流量、出水口流量、化學需氧量、以及出水口懸浮體含量,實時、在線監測系統運行狀態。
由上述例子得到的模型,下面是一組實時收集到的測試數據樣本:
經歸一化計算得到:
通過(10)式,計算得到該實時樣本的統計量為0.3322。該值小於1,認為是該時刻系統處於正常狀態。對應於100個測試樣本的dr統計量計算結果如下:
計算結果中加粗數據表示該點超過控制限1,為不正常數據。第81點處的統計量為15.5309,明顯超過控制限。該時刻的過程數據被用來做故障診斷,計算出6個變量的貢獻率分別為:
0.315,2.031,0.929,2.743,46.401,0.972
由以上診斷結果可見,變量x5對此故障的貢獻率最大,故為廢水處理過程中的化學需氧量發生了變量。