對話管理方法和裝置與流程
2023-11-04 03:25:32 4
本申請涉及自然語言處理技術領域,尤其涉及一種對話管理方法和裝置。
背景技術:
隨著智能化時代的到來,人機互動方式也越來越符合人類的交互方式,從鍵盤交互,到圖形界面交互,再到目前的通過聲音圖像的多媒體交互,實現人類和機器的更加自然更加人性化的交互方式。交互過程中,需要通過對話管理方法根據用戶的請求,確定用戶意圖後,將相應響應結果反饋給用戶。
相關技術中,對話管理方法一般是基於規則的方法確定用戶意圖後,找到相應響應文本數據反饋給用戶,所述規則需要預先收集大量對話文本數據後,人工分析出對話邏輯後,確定相應規則,所述規則一般只能針對對話邏輯出現過的語料,當對話邏輯未出現時,則很難適用,規則存在局限性,並且很難完全覆蓋所有對話邏輯;人工分析對話文本數據的對話邏輯,工作量較大,工作效率較低。因此,如何高效準確地根據用戶文本數據確定用戶意圖對人機互動的用戶體驗尤為重要。
技術實現要素:
本申請旨在至少在一定程度上解決相關技術中的技術問題之一。
為此,本申請的一個目的在於提出一種對話管理方法,該方法可以高效準確地確定出用戶意圖,進而高效準確地反饋響應文本數據。
本申請的另一個目的在於提出一種對話管理裝置。
為達到上述目的,本申請第一方面實施例提出的對話管理方法,包括:獲取待處理用戶文本數據,以及待處理用戶文本數據對應的歷史數據;分別對所述待處理用戶文本數據和所述歷史數據進行特徵提取,提取得到所述待處理用戶文本數據和所述歷史數據分別對應的句子語義特徵;根據預先構建的對話管理模型和提取得到的句子語義特徵,確定用戶意圖;根據所述用戶意圖,反饋與所述待處理用戶文本數據對應的響應文本數據。
本申請第一方面實施例提出的對話管理方法,通過根據對話管理模型確定用戶意圖,可以提高用戶意圖確定的準確性,並且不需要人工總結規則,大大提高了對話管理的效果,從而可以在對話管理時高效準確地確定出用戶意圖,進而高效準確地反饋響應文本數據。
為達到上述目的,本申請第二方面實施例提出的對話管理裝置,包括:獲取模塊,用於獲取待處理用戶文本數據,以及待處理用戶文本數據對應的歷史數據;提取模塊,用於分別對所述待處理用戶文本數據和所述歷史數據進行特徵提取,提取得到所述待處理用戶文本數據和所述歷史數據分別對應的句子語義特徵;確定模塊,用於根據預先構建的對話管理模型和提取得到的句子語義特徵,確定用戶意圖;反饋模塊,用於根據所述用戶意圖,反饋與所述待處理用戶文本數據對應的響應文本數據。
本申請第二方面實施例提出的對話管理裝置,通過根據對話管理模型確定用戶意圖,可以提高用戶意圖確定的準確性,並且不需要人工總結規則,大大提高了對話管理的效果,從而可以在對話管理時高效準確地確定出用戶意圖,進而高效準確地反饋響應文本數據。
本申請附加的方面和優點將在下面的描述中部分給出,部分將從下面的描述中變得明顯,或通過本申請的實踐了解到。
附圖說明
本申請上述的和/或附加的方面和優點從下面結合附圖對實施例的描述中將變得明顯和容易理解,其中:
圖1是本申請一個實施例提出的對話管理方法的流程示意圖;
圖2是本申請另一個實施例提出的對話管理方法的流程示意圖;
圖3是本申請實施例中對待提取文本數據進行特徵提取的方法的流程示意圖;
圖4是本申請實施例中確定用戶文本數據樣本對應的用戶意圖的方法的流程示意圖;
圖5是本申請實施例中對話管理模型的一種網絡結構示意圖;
圖6是本申請一個實施例提出的對話管理裝置的結構示意圖;
圖7是本申請另一個實施例提出的對話管理裝置的結構示意圖。
具體實施方式
下面詳細描述本申請的實施例,所述實施例的示例在附圖中示出,其中自始至終相同或類似的標號表示相同或類似的模塊或具有相同或類似功能的模塊。下面通過參考附圖描述的實施例是示例性的,僅用於解釋本申請,而不能理解為對本申請的限制。相反,本申請的實施例包括落入所附加權利要求書的精神和內涵範圍內的所有變化、修改和等同物。
圖1是本申請一個實施例提出的對話管理方法的流程示意圖。
如圖1所示,本實施例的方法包括:
S11:獲取待處理用戶文本數據,以及待處理用戶文本數據對應的歷史數據。
用戶文本數據是指人機互動過程中用戶主動發出的文本數據,可以為直接輸入到系統中的用戶文本數據,也可以為用戶使用語音數據輸入後,對所述語音數據進行語音識別後得到的識別文本。
人機互動過程中,可以以一句用戶文本數據與一句響應文本數據交替出現的形式進行,響應文本數據是指機器反饋給用戶的與用戶文本數據對應的數據。一句用戶文本數據及對應的一句響應文本數據可以組成一輪對話文本數據。在人機互動過程中,可以包括一輪或多輪對話文本數據,多輪指至少兩輪。
在處理時,可以分別將每輪對話文本數據中的用戶文本數據作為待處理用戶文本數據。在人機互動過程中可以記錄對話文本數據,以在記錄的數據中獲取到待處理用戶文本數據對應的歷史數據。
歷史數據是指待處理用戶文本數據之前的預設N輪的對話文本數據,N可以根據應用需求設置。如上所示,對話文本數據包括用戶文本數據和響應文本數據,則歷史數據包括歷史用戶文本數據和歷史響應文本數據。如果待處理用戶文本數據是第一輪交互中的用戶文本數據,則對應的歷史數據為空。
S12:分別對所述待處理用戶文本數據和所述歷史數據進行特徵提取,提取得到所述待處理用戶文本數據和所述歷史數據分別對應的句子語義特徵。
由於需要分別對待處理用戶文本數據和歷史數據進行特徵提取,因此,待處理用戶文本數據和歷史數據可以統稱為待提取文本數據,而在後續內容中,還會涉及對樣本進行特徵提取的步驟,因此,樣本也可以稱為待提取文本數據。具體的對待提取文本數據進行特徵提取的方法可以參見後續內容。
如果待提取文本數據為空,比如歷史數據為空,則可以設置對應的句子語義特徵為固定值,如將此時的句子語義特徵的取值設置為0。
S13:根據預先構建的對話管理模型和提取得到的句子語義特徵,確定所述待處理用戶文本數據對應的用戶意圖。
具體構建對話管理模型的方法可以如後續內容所示。
對話管理模型的輸入為句子語義特徵,輸出為用戶意圖信息,從而在提取得到句子語義特徵後,將提取得到的句子語義特徵作為對話管理模型的輸入,得到對話管理模型輸出的用戶意圖信息,再根據用戶意圖信息確定用戶意圖,比如,用戶意圖信息為每種預設用戶意圖的概率值,則將概率值最高的用戶意圖確定為待處理用戶文本數據對應的用戶意圖。
S14:根據所述用戶意圖,反饋與所述用戶文本數據對應的響應文本數據。
例如,可以預先配置每種用戶意圖對應的響應文本數據,從而在用戶意圖確定後,可以直接獲取對應的響應文本數據反饋給用戶。比如,預先配置用戶意圖為「查詢話費」對應的響應文本數據包括:「您想查詢哪個月的話費」,則在確定出用戶意圖為「查詢話費」時,向用戶反饋「您想查詢哪個月的話費」。在反饋時,可以顯示響應文本數據,或者,採用語音合成技術將響應文本數據轉換為語音,採用語音播放的方式進行反饋。
本實施例中,通過根據對話管理模型確定用戶意圖,可以提高用戶意圖確定的準確性,並且不需要人工總結規則,大大提高了對話管理的效果,從而可以在對話管理時高效準確地確定出用戶意圖,進而高效準確地反饋響應文本數據。
圖2是本申請另一個實施例提出的對話管理方法的流程示意圖。
如圖2所示的,本實施例的方法包括:
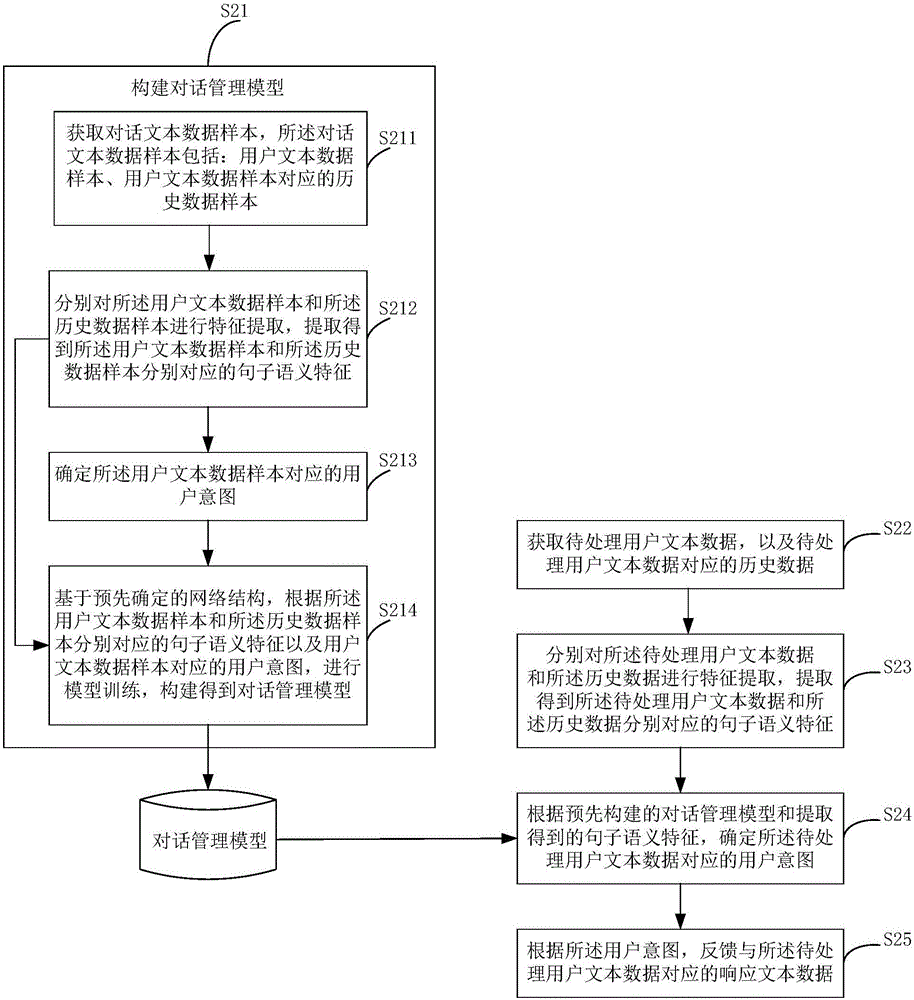
S21:構建對話管理模型。
具體如後續描述。
S22:獲取待處理用戶文本數據,以及待處理用戶文本數據對應的歷史數據。
S23:分別對所述待處理用戶文本數據和所述歷史數據進行特徵提取,提取得到所述待處理用戶文本數據和所述歷史數據分別對應的句子語義特徵。
S24:根據預先構建的對話管理模型和提取得到的句子語義特徵,確定所述待處理用戶文本數據對應的用戶意圖。
S25:根據所述用戶意圖,反饋與所述待處理用戶文本數據對應的響應文本數據。
其中,S22-S25的具體內容可以參見S11-S14,在此不再詳述。
如圖2所示,構建對話管理模型的方法可以包括:
S211:獲取對話文本數據樣本,所述對話文本數據樣本包括:用戶文本數據樣本、用戶文本數據樣本對應的歷史數據樣本。
對話文本數據樣本是指已有的對話文本數據,具體可以採用收集的方式或者從日誌中直接獲取的方式,獲取到對話文本數據樣本。
對話文本數據樣本包括多輪,每輪包括一句用戶文本數據樣本和一句響應文本數據樣本。在處理時,可以將每輪對話文本數據樣本中的用戶文本數據樣本依次作為當前處理的用戶文本數據樣本,以及獲取與當前處理的用戶文本數據樣本對應的歷史數據樣本。當前處理的用戶文本數據樣本對應的歷史數據樣本是指當前處理的用戶文本數據樣本之前的對話文本數據樣本,具體包括歷史用戶文本數據樣本和歷史響應文本數據樣本。
S212:分別對所述用戶文本數據樣本和所述歷史數據樣本進行特徵提取,提取得到所述用戶文本數據樣本和所述歷史數據樣本分別對應的句子語義特徵。
用戶文本數據樣本、歷史數據樣本以及上述實施例中的待處理用戶文本數據及其對應的歷史數據可以統稱為待提取文本數據,對待提取文本數據進行特徵提取的方法可以如圖3所示。
S213:確定所述用戶文本數據樣本對應的用戶意圖。
在獲取的對話文本數據樣本中還包括與用戶文本數據樣本屬於同一輪交互的響應文本數據樣本,可以基於響應文本數據樣本對應的句子語義特徵和用戶文本數據樣本對應的句子語義特徵確定用戶文本數據樣本對應的用戶意圖,具體如圖4所示。
S214:基於預先確定的網絡結構,根據所述用戶文本數據樣本和所述歷史數據樣本分別對應的句子語義特徵以及所述用戶文本數據樣本對應的用戶意圖,進行模型訓練,構建得到對話管理模型。
網絡結構可以具體為深度神經網絡結構。
模型訓練過程可以包括:將所述用戶文本數據樣本和所述歷史數據樣本分別對應的句子語義特徵作為模型輸入,經過與模型各層參數的運算後,得到模型輸出,模型輸出包括各用戶意圖的概率值,將概率值最高的用戶意圖作為預測值,再將所述用戶文本數據樣本對應的用戶意圖作為真實值,根據真實值和預測值得到損失函數,通過最小化損失函數,可以得到模型各層參數,從而得到對話管理模型。具體的模型訓練方式可以參見各種相關技術,在此不再詳述。
下面對上述涉及的一些步驟進行具體說明。
參見圖3,對待提取文本數據進行特徵提取的方法可以包括:
S31:對待提取文本數據進行分詞,得到分詞後的詞語。
具體分詞方法可以參見各種相關技術,如基於條件隨機場的方法對文本數據進行分詞,如文本數據「取消已經開通的十元一百兆的流量」分詞後得到的詞語包括「取消已經開通的十元一百兆的流量」。
需要說明的是,如果待提取文本數據中包含有非法或無意義的字符,可以先清洗待提取文本數據,去除其中的非法或無意義字符,具體清洗方法可以參見各種相關技術。
S32:對所述詞語進行詞向量化,得到所述詞語對應的詞向量。
具體詞向量化方法可以參見各種相關技術,如使用word2vec技術進行詞向量化。
一般收集的對話文本數據較多,因此,得到的詞語也非常多,為了將不同詞的詞向量區分開,可以使用高維向量表示每個詞語,如每個詞向量的維數為256維。
S33:根據所述詞向量提取出所述待提取文本數據對應的句子語義特徵。
具體的,可以將每句文本數據包含的詞語對應的詞向量的平均向量作為對應的句子語義特徵。例如,直接將每輪對話中用戶文本數據包含詞語的詞向量的平均向量作為用戶文本數據對應的句子語義特徵,將響應文本數據包含詞語的詞向量的平均向量作為響應文本數據對應的句子語義特徵。所述句子語義特徵的維數與詞向量維數相同,平均向量是指將向量包含的各元素按位進行平均。需要說明的是,由於句子語義特徵是一種向量,因此在後續內容中也可以將句子語義特徵稱為句子語義特徵向量。
參見圖4,確定用戶文本數據樣本對應的用戶意圖的方法可以包括:
S41:獲取所述響應文本數據樣本對應的句子語義特徵,並根據所述響應文本數據樣本對應的句子語義特徵確定初始用戶意圖。
可以採用如圖3所示的方法對所述響應文本數據樣本進行特徵提取,獲取到所述響應文本數據樣本對應的句子語義特徵。
在獲取到所述響應文本數據樣本對應的句子語義特徵後,可以對該句子語義特徵進行分類,確定初始用戶意圖。
具體的,可以預先設置多種類別的用戶意圖,比如設置用戶意圖包括「查話費、查流量、查帳單、話費套餐辦理、流量套餐辦理、網絡故障報修」六種類別,之後可以採用各種相關技術,將所述響應文本數據樣本對應的句子語義特徵分類到上述六種類別中的一種,作為初始用戶意圖,比如分類到「查話費」,則將初始用戶意圖標記為001。
S42:根據所述用戶文本數據樣本對應的句子語義特徵和所述初始用戶意圖,確定用戶意圖確定特徵,並根據所述用戶意圖確定特徵確定出所述用戶文本數據樣本對應的用戶意圖。
具體的,可以對所述用戶文本數據樣本對應的句子語義特徵和所述初始用戶意圖進行組合,將組合後的向量作為用戶意圖確定特徵,比如,句子語義特徵為256維,初始用戶意圖為3維,則組合後得到的用戶意圖確定特徵為259維。在得到用戶意圖確定特徵後,可以採用各種相關技術,將用戶意圖確定特徵分類到上述預設類別中的一種,作為最終的用戶意圖。其中,此時的預設類別與確定初始用戶意圖時的類別相同,如依然為上述的六種類別。
可以理解的是,上述以採用分類的方式確定用戶意圖為例,但不限於上述實現方式,比如還可以採用人工標註方式,由領域專家對用戶文本數據樣本對應的用戶意圖進行標註,從而可以根據標註信息直接確定用戶文本數據樣本對應的用戶意圖。
下面以一種網絡結構為例,對所述對話管理模型進行說明。
如圖5所示,示出了一種網絡結構的對話管理模型。參見圖5,該對話管理模型包括:輸入層、注意力層、連接層和輸出層。
需要說明的是,對話管理模型可以分為訓練階段和應用階段,且為了區分訓練階段和應用階段,使用的輸入數據可以具有不同的名稱。如在應用階段,輸入數據包括待處理用戶文本數據及其對應的歷史數據,歷史數據包括歷史用戶文本數據及其對應的歷史響應文本數據。而在訓練階段,輸入數據可以稱為樣本,具體包括用戶文本數據樣本及其對應的歷史數據樣本。可以理解的是,雖然在訓練階段在相應數據的名稱後加上了樣本,但是模型對輸入數據進行處理的原理是一致的,下面以輸入數據包括待處理用戶文本數據及其對應的歷史數據為例進行說明,對用戶文本數據樣本及其對應的歷史數據樣本進行處理的流程可以參照執行。
輸入層用於接收輸入特徵,其中,輸入特徵共包含三部分,具體如下:
1)待處理用戶文本數據的句子語義特徵向量,使用S表示;
2)待處理用戶文本數據對應的歷史用戶文本數據的句子語義特徵向量,使用U={u1,u2,...,uk}表示,其中,uk表示待處理用戶文本數據第k輪歷史用戶文本數據的句子語義特徵,k表示待處理用戶文本數據向前取的歷史數據的輪數;
3)待處理用戶文本數據對應的歷史響應文本數據的句子語義特徵向量,使用R={r1,r2,...,rk},其中,rk表示待處理用戶文本數據第k輪歷史響應文本數據的句子語義特徵向量;
進一步地,由於不同的用戶文本數據可能對應相同或類似的響應文本數據,直接根據響應文本數據得到的句子語義特徵向量的區分性不好,因此,在模型構建的過程中,可以對待處理用戶文本數據對應歷史響應文本數據的句子語義向量進行不斷更新,以保證句子語義向量更加準確。
注意力層用於計算待處理用戶文本數據對應的響應文本數據的特徵向量,具體的,可以先計算待處理用戶文本數據與其對應的每個歷史用戶文本數據的相關度權重,再根據上述的相關度權重計算待處理用戶文本數據對應的響應文本數據的特徵向量。
所述相關度權重計算時,可以先計算待處理用戶文本數據的句子語義特徵向量與其每一個歷史用戶文本數據的句子語義特徵向量的內積後,再計算待處理用戶文本數據與其每一個歷史用戶文本數據的相關度權重;也可以先計算待處理用戶文本數據的句子語義特徵向量與其每一個歷史用戶文本數據的句子語義特徵向量之間的距離,再計算待處理用戶文本數據與其每一個歷史用戶文本數據的相關度權重;所述相關度權重取值越大,待處理用戶文本數據與其對應的歷史用戶文本數據的相關度越高,具體使用P={p1,p2,...pk}表示,以先計算向量之間的內積為例,所述相關度權重的計算方法如式(1)所示:
pi=f(STui) (1)
其中,pi表示待處理用戶文本數據與其第i輪的歷史用戶文本數據的相關度權重,ui為待處理用戶文本數據的第i輪歷史用戶文本數據的句子語義特徵向量;f為相關度權重計算函數,如softmax函數。
所述待處理用戶文本數據對應的響應文本數據的特徵向量計算時,可以將上述的相關度權重作為對應的每個歷史響應文本數據的句子語義特徵向量的加權值,進行加權求和後得到,具體計算方法如式(2)所示:
其中,A表示待處理用戶文本數據對應的響應文本數據的特徵向量。
連接層用於對注意力層計算得到的待處理用戶文本數據對應的響應文本數據的特徵向量A以及待處理用戶文本數據的句子語義特徵向量S進行變換,得到變換後的特徵向量變換後的特徵向量中包含了待處理用戶文本數據的語義信息。具體變換方法如式(3)所示:
其中,W為特徵向量變換權重矩陣,為模型參數,具體可以通過大量訓練數據進行訓練得到,初始取值可以通過隨機初始化方法得到,或直接統一初始化為0;f為特徵向量變換函數,如softmax函數。
輸出層用於根據所述變換後的特徵向量輸出用戶意圖信息,例如每種預設用戶意圖的概率值。
本實施例中,通過根據對話管理模型確定用戶意圖,可以提高用戶意圖確定的準確性,並且不需要人工總結規則,大大提高了對話管理的效果,從而可以在對話管理時高效準確地確定出用戶意圖。進一步的,通過上述的深度神經網絡構建對話管理模型,可以進一步提高模型準確度,進而提高用戶意圖確定的準確度。
圖6是本申請一個實施例提出的對話管理裝置的結構示意圖。
如圖6所示,本實施例的裝置60包括:獲取模塊61、提取模塊62、確定模塊63和反饋模塊64。
獲取模塊61,用於獲取待處理用戶文本數據,以及待處理用戶文本數據對應的歷史數據;
提取模塊62,用於分別對所述待處理用戶文本數據和所述歷史數據進行特徵提取,提取得到所述待處理用戶文本數據和所述歷史數據分別對應的句子語義特徵;
確定模塊63,用於根據預先構建的對話管理模型和提取得到的句子語義特徵,確定用戶意圖;
反饋模塊64,用於根據所述用戶意圖,反饋與所述待處理用戶文本數據對應的響應文本數據。
一些實施例中,所述提取模塊62用於進行所述特徵提取包括:
對待提取文本數據進行分詞,得到分詞後的詞語;
對所述詞語進行詞向量化,得到所述詞語對應的詞向量;
根據所述詞向量提取出所述待提取文本數據對應的句子語義特徵;
其中,所述待提取文本數據包括:所述待處理用戶文本數據,和/或,所述歷史數據。
一些實施例中,參見圖7,該裝置60還包括:用於構建對話管理模型的構建模塊65,所述構建模塊65具體用於:
獲取對話文本數據樣本,所述對話文本數據樣本包括:用戶文本數據樣本、用戶文本數據樣本對應的歷史數據樣本;
分別對所述用戶文本數據樣本和所述歷史數據樣本進行特徵提取,提取得到所述用戶文本數據樣本和所述歷史數據樣本分別對應的句子語義特徵;
確定所述用戶文本數據樣本對應的用戶意圖;
基於預先確定的網絡結構,根據所述用戶文本數據樣本和所述歷史數據樣本分別對應的句子語義特徵以及所述用戶文本數據樣本對應的用戶意圖,進行模型訓練,構建得到對話管理模型。
一些實施例中,所述對話文本數據樣本還包括:與用戶文本數據樣本屬於同一輪交互的響應文本數據樣本;所述構建模塊65用於確定所述用戶文本數據樣本對應的用戶意圖,包括:
獲取所述響應文本數據樣本對應的句子語義特徵,並根據所述響應文本數據樣本對應的句子語義特徵確定初始用戶意圖;
根據所述用戶文本數據樣本對應的句子語義特徵和所述初始用戶意圖,確定用戶意圖確定特徵,並根據所述用戶意圖確定特徵確定出所述用戶文本數據樣本對應的用戶意圖。
一些實施例中,所述對話管理模型的網絡結構包括:深度神經網絡結構。
一些實施例中,所述歷史數據包括:歷史用戶文本數據和歷史響應文本數據,所述網絡結構包括:
輸入層、注意力層、連接層和輸出層;
所述輸入層用於輸入如下特徵:所述待處理用戶文本數據對應的句子語義特徵、所述歷史用戶文本數據對應的句子語義特徵和所述歷史響應文本數據對應的句子語義特徵;
所述注意力層用於根據所述待處理用戶文本數據對應的句子語義特徵和所述歷史用戶文本數據對應的句子語義特徵,計算所述待處理用戶文本數據與所述歷史用戶文本數據之間的相關度權重,並根據所述相關度權重和所述歷史響應文本數據對應的句子語義特徵,計算所述待處理用戶文本數據對應的響應文本數據的特徵向量;
所述連接層用於對所述特徵向量和所述待處理用戶文本數據對應的句子語義特徵進行變換,得到變換後的特徵向量;
所述輸出層用於根據所述變換後的特徵向量輸出用戶意圖信息。
可以理解的是,本實施例的裝置與上述方法實施例對應,具體內容可以參見方法實施例的相關描述,在此不再詳細說明。
本實施例中,通過根據對話管理模型確定用戶意圖,可以提高用戶意圖確定的準確性,並且不需要人工總結規則,大大提高了對話管理的效果,從而可以在對話管理時高效準確地確定出用戶意圖,進而高效準確地反饋響應文本數據。
可以理解的是,上述各實施例中相同或相似部分可以相互參考,在一些實施例中未詳細說明的內容可以參見其他實施例中相同或相似的內容。
需要說明的是,在本申請的描述中,術語「第一」、「第二」等僅用於描述目的,而不能理解為指示或暗示相對重要性。此外,在本申請的描述中,除非另有說明,「多個」的含義是指至少兩個。
流程圖中或在此以其他方式描述的任何過程或方法描述可以被理解為,表示包括一個或更多個用於實現特定邏輯功能或過程的步驟的可執行指令的代碼的模塊、片段或部分,並且本申請的優選實施方式的範圍包括另外的實現,其中可以不按所示出或討論的順序,包括根據所涉及的功能按基本同時的方式或按相反的順序,來執行功能,這應被本申請的實施例所屬技術領域的技術人員所理解。
應當理解,本申請的各部分可以用硬體、軟體、固件或它們的組合來實現。在上述實施方式中,多個步驟或方法可以用存儲在存儲器中且由合適的指令執行系統執行的軟體或固件來實現。例如,如果用硬體來實現,和在另一實施方式中一樣,可用本領域公知的下列技術中的任一項或他們的組合來實現:具有用於對數據信號實現邏輯功能的邏輯門電路的離散邏輯電路,具有合適的組合邏輯門電路的專用集成電路,可編程門陣列(PGA),現場可編程門陣列(FPGA)等。
本技術領域的普通技術人員可以理解實現上述實施例方法攜帶的全部或部分步驟是可以通過程序來指令相關的硬體完成,所述的程序可以存儲於一種計算機可讀存儲介質中,該程序在執行時,包括方法實施例的步驟之一或其組合。
此外,在本申請各個實施例中的各功能單元可以集成在一個處理模塊中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個模塊中。上述集成的模塊既可以採用硬體的形式實現,也可以採用軟體功能模塊的形式實現。所述集成的模塊如果以軟體功能模塊的形式實現並作為獨立的產品銷售或使用時,也可以存儲在一個計算機可讀取存儲介質中。
上述提到的存儲介質可以是只讀存儲器,磁碟或光碟等。
在本說明書的描述中,參考術語「一個實施例」、「一些實施例」、「示例」、「具體示例」、或「一些示例」等的描述意指結合該實施例或示例描述的具體特徵、結構、材料或者特點包含於本申請的至少一個實施例或示例中。在本說明書中,對上述術語的示意性表述不一定指的是相同的實施例或示例。而且,描述的具體特徵、結構、材料或者特點可以在任何的一個或多個實施例或示例中以合適的方式結合。
儘管上面已經示出和描述了本申請的實施例,可以理解的是,上述實施例是示例性的,不能理解為對本申請的限制,本領域的普通技術人員在本申請的範圍內可以對上述實施例進行變化、修改、替換和變型。