信息處理裝置的製作方法
2023-11-06 06:21:42 3
本發明涉及處理i/o指令的信息處理裝置。
背景技術:
近年來,以靈活用於商業為目的,高速解析大量的數據的技術受到矚目。一般而言,伺服器的主處理器(以下稱為處理器)從hdd(harddiskdrive:硬碟驅動器)等存儲設備讀出數據並進行數據的解析和運算。
作為存儲設備,正在普及與hdd相比能夠高速地進行訪問的、以快閃記憶體為存儲介質的ssd(solidstatedrive:固態驅動器)。進而,reram(resistancerandomaccessmemory:電阻隨機存取存儲器)或pcm(phasechangememory:相變存儲器)等與快閃記憶體相比能夠高速地訪問的半導體存儲介質的實用化正在推進。
由於這樣的存儲設備的出現,高速地讀出大量數據成為可能。但是,處理器的處理負荷高、與處理器連接的總線的帶寬成為瓶頸而導致數據傳送需要花費時間,因此無法有效利用高速的存儲設備的性能,作為信息處理裝置無法高速化。
現有技術中,已知有通過在信息處理裝置中添加具有運算功能的裝置(以下稱為加速器),使原本處理器執行的處理的一部分分散於該加速器的技術。例如,存在如下所述的技術:在具有處理器的伺服器中添加gpu(graphicsprocessingunit:圖形處理單元)作為加速器,由gpu對處理器執行的程序處理的一部分進行處理,由此實現處理速度的提高。
該技術是數據傳送較多的技術,即,處理器從存儲設備將處理對象數據傳送到與處理器連接的系統存儲器,進而處理器從系統存儲器對加速器傳送數據,由此gpu能夠處理數據。特別是因為數據在與處理器連接的總線往復,所以該總線的帶寬成為性能提高的瓶頸。
專利文獻1中記載有一種信息處理裝置,其目的在於,為了消除該數據傳送瓶頸,加速器和存儲設備不經由處理器而直接通信,由此進一步提高處理速度。
專利文獻1的技術中,在具有處理器和系統存儲器的信息處理裝置連接基板,gpu與非易失性存儲器陣列成一對地搭載於該基板上,在gpu與非易失性存儲器陣列間直接進行數據傳送。由於非易失性存儲器陣列的數據被傳送到gpu,僅該gpu的處理結果被傳送到與處理器連接的總線,所以能夠消除總線的帶寬因向系統存儲器的訪問而被壓迫的情況。
現有技術文獻
專利文獻
專利文獻1:美國專利申請公開第2014/129753號說明書
技術實現要素:
發明要解決的課題
專利文獻1中關於在信息處理裝置的初始化時gpu如何確定成為訪問目的地的非易失性存儲器陣列則沒有記載。存在如下課題:若作為pci-express(以下稱為pcle)的末端而連接有存儲設備和加速器,則加速器無法確定成為訪問目的地的存儲設備的指令接口的地址。還存在如下課題:若加速器無法確定存儲設備的指令接口的地址,則根本就無法訪問存儲設備來讀出數據並執行處理器的一部分處理。
因此,本發明的目的是提供一種信息處理裝置,加速器確定出存儲設備後加速器從存儲設備讀出數據,並且加速器執行處理器的一部分處理。
用於解決課題的手段
本發明是一種信息處理裝置,其具有處理器和存儲器,並且包括1個以上的加速器和1個以上的存儲設備,所述信息處理裝置具有將所述處理器與所述加速器和所述存儲設備連接的一個網絡,所述存儲設備具有從所述處理器接受初始化命令的初始設定接口和發行i/o指令的i/o發行接口,所述處理器對所述加速器通知所述初始設定接口的地址或者所述i/o發行接口的地址。
發明效果
根據本發明,能夠由加速器確定出存儲設備的指令接口的地址,從存儲設備讀出數據,並執行處理器的一部分處理,從而能夠使信息處理裝置的處理高速化。
附圖說明
圖1表示本發明的第一實施例,是表示信息處理裝置將資料庫的過濾處理卸載到加速器板的概念的圖。
圖2表示本發明的第一實施例,是表示信息處理裝置的構成的一例的框圖。
圖3表示本發明的第一實施例,是在信息處理裝置進行了i/o發行處理的情況的說明圖。
圖4表示本發明的第一實施例,是表示在信息處理裝置進行的初始化處理的一例的時序圖。
圖5表示本發明的第一實施例,是信息處理裝置使fpga執行資料庫的過濾處理的例子的時序圖。
圖6表示本發明的第一實施例,是表示主處理器的i/o和加速器板的i/o同時存在時的處理的一例的時序圖。
圖7表示本發明的第一實施例的變形例,是表示向1個pcle開關連接了存儲設備和加速器板的多個組的構成的一例的框圖。
圖8表示本發明的第一實施例的變形例,是表示存儲設備與加速器板之間的跳數的表格。
圖9a表示本發明的第一實施例的變形例,是表示加速器板的處理性能的表格。
圖9b表示本發明的第一實施例的變形例,是表示存儲設備的性能的表格。
圖10表示本發明的第一實施例,表示在存儲設備發生了故障時在信息處理裝置進行的處理的一例的時序圖。
圖11表示本發明的第一實施例,是表示在加速器板發生了故障時在信息處理裝置進行的處理的一例的時序圖。
圖12表示本發明的第一實施例,是表示在加速器板發生了故障時在信息處理裝置進行的重新分配處理的一例的時序圖。
圖13表示本發明的第一實施例,表示在初始化完成的狀態下新追加存儲設備或者加速器板的信息處理裝置的一例的框圖。
圖14表示本發明的第一實施例,是表示在信息處理裝置初始化完成後追加了新的存儲設備時的處理的一例的時序圖。
圖15表示本發明的第一實施例,是表示在信息處理裝置初始化完成後追加了新的加速器板時的處理的一例的時序圖。
圖16表示本發明的第一實施例的變形例,是表示信息處理裝置的一例的框圖。
圖17表示本發明的第二實施例,是表示信息處理裝置的一例的框圖。
圖18表示本發明的第二實施例,是表示在信息處理裝置進行的資料庫處理的一例的時序圖。
圖19表示本發明的第三實施例,是表示信息處理裝置的一例的框圖。
圖20表示本發明的第三實施例,是表示在信息處理裝置進行的初始化處理的一例的時序圖。
圖21表示本發明的第一實施例,是表示信息處理裝置的一例的框圖。
具體實施方式
以下使用附圖說明本發明的實施方式。
首先,作為本發明的概要,針對進行資料庫處理(以下稱為db處理)的信息處理裝置10進行說明。
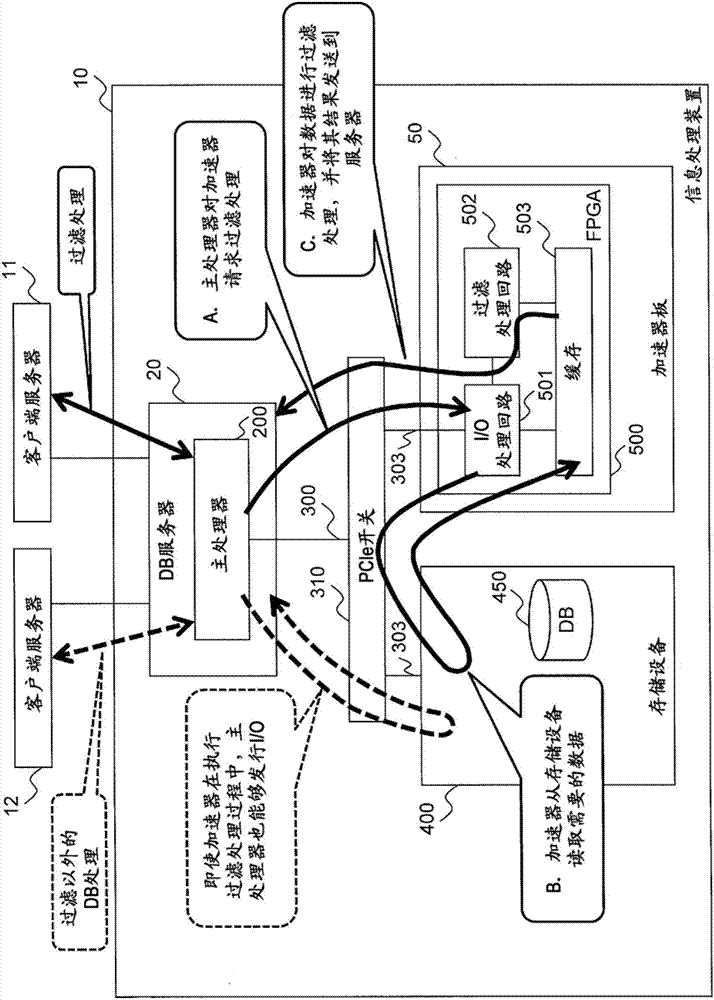
圖1是表示本發明的思想的框圖。圖1是包括信息處理裝置10和利用信息處理裝置10的客戶端伺服器11、12的計算機系統,信息處理裝置10搭載有以卸載資料庫處理的過濾處理為前提的加速器板50。
過濾處理是比較成為對象的資料庫(以下稱為db)和條件式,僅提取與條件式一致的db的處理,特別是在所述條件式複雜的情況、或成為所述對象的db的數據量多的情況下,會對信息處理裝置10的主處理器200施加高的負荷,因此向加速器板50的卸載是有效的處理。
在加速器板50搭載例如fieldprogrammablegatearray(現場可編程門陣列)(以下稱為fpga)、graphicsprocessingunit(圖形處理單元)(以下稱為gpu)、副處理器等。加速器板50通常搭載於帶有pcle接口的基板等上,並作為加速器利用於信息處理裝置10。
圖1的信息處理裝置10中包括:帶有進行資料庫處理的主處理器200(以下稱為處理器)的資料庫伺服器20(以下稱為db伺服器);保存有資料庫(以下稱為db)450的存儲設備400;和搭載有能夠卸載主處理器200的處理的fpga500的加速器板50。此外,資料庫處理是例如dbms(databasemanagementsystem:資料庫管理系統)進行的處理。
主處理器200、存儲設備400、加速器板50和fpga500利用pcle總線300、303與pcle開關310相互連接。此外,加速器板50和fpga500映射於db伺服器20(主處理器200)的存儲器空間上,能夠使用該存儲器映射上的地址相互通信,將其稱為一個網絡。
fpga500中包括:i/o處理電路501,其具有接受來自主處理器200的訪問的功能和進行來自fpga500的i/o發行的功能(具體而言,pcle末端功能和pcle末端的控制功能);能夠高速地執行過濾處理的過濾處理電路502;和臨時存儲db450的數據的緩存503,它們通過內部總線相互連接。
i/o處理電路501和過濾處理電路502兩者都可以作為fpga500的硬體電路安裝,也可以通過fpga500內部的嵌入式處理器實現一部分或者全部的功能。此外,本實施例中,作為加速器板50使用fpga500進行說明,但是也可以採用gpu和副處理器。
客戶端伺服器11和12是利用由信息處理裝置10管理的db450的應用程式所運行的伺服器,向db伺服器20請求db處理。
db伺服器20從客戶端伺服器11、12接收使用過濾處理的命令,作為db伺服器20將過濾處理卸載到fpga500的順序,說明a~c。
db伺服器20的主處理器200對fpga500發行指示過濾處理的執行的指令(a)。接收到指令的fpga500的i/o處理電路501對存儲設備400發行讀取命令,獲取成為過濾處理的對象的db450的數據,並將其存儲在fpga500的緩存503(b)。
接著,過濾處理電路502從緩存503讀出i/o處理電路501所讀取的db450的數據,進行過濾處理,並將該過濾處理結果作為結果數據發送到db伺服器20(c)。
通過以這樣的順序進行過濾處理,在與db伺服器20連接的總線300中,db450的數據其本身不流動,僅流動指令和結果數據,所以與所述現有例的順序相比,能夠減少在總線300流動的數據量。
此外,由於能夠在信息處理裝置10連接多個客戶端伺服器11、12,所以有可能在例如客戶端伺服器11請求過濾處理的期間,其他的客戶端伺服器12請求過濾處理以外的db處理(例如更新處理)。
該情況下,主處理器200需要對存儲設備400進行i/o訪問,但是在fpga500執行過濾處理中,信息處理裝置10的主處理器200也能夠對存儲設備400發行i/o,並行執行多個處理,能夠發送被客戶端伺服器11、12所請求的處理的結果。
實施例1
接著,使用圖2~6,詳細說明本發明的實施例1。
圖2是表示適用本發明的信息處理裝置10的構成的一例的框圖。
信息處理裝置10包括db伺服器20和擴展器30。db伺服器20具有處理器200、系統存儲器210和晶片組220,它們由內部總線230連接。在晶片組220中pcle根聯合體221發揮功能,經由pcle總線2300與pcle開關2310連接。
在晶片組220連接有具有輸入裝置和輸出裝置(例如、顯示器)的終端180。在系統存儲器210中加載os110、pcle驅動器130、dbms120並由主處理器200執行。
pcle驅動器130控制與pcle網絡上連接的存儲設備或者加速器。其中,pcle驅動器130也可以包括在os110中。dbms120在訪問與pcle總線2300連接的裝置時經由pcle驅動器130訪問各裝置。
擴展器30包括2個存儲設備400、410、2個加速器板50、51、pcle開關2310、2320、2330,它們分別經由pcle總線2300~2304與db伺服器20連接。
存儲設備400和加速器板50經由pcle總線2303與pcle開關2320連接。pcle開關2320經由pcle總線2301與pcle開關2310連接。
同樣,存儲設備410和加速器板51經由pcle總線2304與pcle開關2330連接。pcle開關2330經由pcle總線2302與pcle開關2310連接。
因為加速器板50、51和存儲設備400、410映射在db伺服器20的存儲器空間上,所以圖2那樣的構成也是一個網絡。本實施例中使用pcle總線,所以稱為pcle網絡。這樣,一個網絡不限定於如圖1的存儲設備400和加速器板50那樣僅夾著一級pcle開關310的構成。即使如圖2的pcle開關2310、2320、2330那樣是夾著多級開關的構成,只要映射在db伺服器20(主處理器200)的存儲器空間上即可。
加速器板50、51分別搭載fpga500、510。在fpga500中具有i/o處理電路501、過濾處理電路502、緩存503,它們相互連接。雖然未圖示,但是fpga510也與fpga500同樣地構成。
存儲設備400是能夠使用nvm(nonvolatilememory:非易失性存儲器)express協議(以下稱為nvme)進行通信的存儲設備,具有i/o控制器401和資料庫保存區域404。在資料庫保存區域404保存db450。資料庫保存區域404能夠由例如快閃記憶體、reram(resistancerandomaccessmemory:電阻隨機存取存儲器)、pcm(phasechangerandomaccessmemory:相變隨機存取存儲器)等非易失性存儲介質構成。再者,雖然未圖示,但是存儲設備410也與存儲設備400同樣地構成。
存儲設備400的資料庫保存區域404,沒有直接映射在db伺服器20(主處理器200)的存儲器空間上,僅映射指令接口。主處理器200和fpga500無法使用pcle總線2300~2304直接訪問資料庫保存區域404。因此,主處理器200和加速器板50通過向存儲設備400發行i/o指令(讀取指令/寫入指令),實施向資料庫保存區域的讀取寫入。
即,在系統存儲器210中,通過os110對地址空間分配系統存儲器210的存儲元件來管理訪問。與之相對,在nvme和sata中,以區塊為單位管理資料庫保存區域404,但不將全部的區塊分配給系統存儲器210的地址空間(邏輯塊),通過指令的交換來實現訪問。
i/o控制器401接收來自存儲設備400、410外部的i/o指令,根據指令進行以下的處理。在讀取指令的情況下從資料庫保存區域404讀出對應的讀取地址的數據,並將其寫入到讀取數據的請求目的地地址。在寫入指令的情況下,從寫入數據發送源的地址讀取寫入數據,並將其保存在與寫入地址對應的資料庫保存區域404。
i/o控制器401包括進行運算處理的處理器402、包括多個隊列的指令接口405、和保存用於進行處理的信息的管理信息保存區域403。
指令接口405具有:admin隊列406,其用於接受主要在初始化(在nvme中生成(或者有效化)i/o發行隊列的功能等)或者錯誤時使用的admin指令;主處理器用i/o發行隊列407(以下稱為處理器隊列),其用於接受來自主處理器200的i/o指令;和fpga用i/o發行隊列408(以下稱為fpga隊列),其用於接受來自fpga500的i/o指令。再者,以下將處理器隊列407和fpga隊列408總稱為i/o發行隊列。
這些i/o發行隊列作為指令接口405與存儲設備400的管理用寄存器等共同映射於pcle網絡的地址空間(mmio空間)。
再者,admin隊列406、處理器隊列407和fpga隊列408是分別被分配了不同的地址的獨立的隊列。這些admin隊列406、處理器隊列407和fpga隊列408的地址在pcle網絡的地址空間被分配於存儲設備的指令接口405內。pcle網絡的地址空間能夠由在db伺服器20運行的os110或者pcle驅動器130來分配。
db伺服器20的主處理器200或者fpga500使用這些i/o發行隊列發行i/o指令時,檢測到i/o指令的存儲設備400的處理器402進行寫入或者讀取這樣的i/o指令處理。
在電源起動時的存儲設備400中,i/o發行隊列不成為有效,而僅admin隊列406為有效。通過主處理器200對該admin隊列406發行i/o發行隊列的生成(或者有效化)命令(或者初始化的命令),接收到該命令的處理器402使例如處理器隊列407有效。
然後,處理器402對db伺服器20的主處理器200發送生成了(或者有效化)主處理器隊列407的通知,主處理器200能夠使用處理器隊列407。
此處,將使用了該admin隊列406的i/o發行隊列407~408的有效化稱為生成i/o發行隊列。在存儲設備400準備有多個i/o發行隊列,其有效還是無效的信息保存在i/o控制器401的管理信息保存區域(例如dram等易失性存儲介質、或者快閃記憶體、reram、pcm等非易失性存儲介質)403。
再者,admin隊列406接受來自主處理器200的初始化的命令,作為用於生成和管理i/o發行隊列407、408的初始設定接口起作用。此外,i/o發行隊列407、408作為接受來自主處理器200和fpga500的i/o指令的i/o發行接口起作用。
圖2中,存儲設備400具有3個i/o發行隊列407~409,其中,對主處理器200分配處理器隊列407並使其有效,對fpga500分配fpga隊列408並使其有效,i/o發行隊列409為無效。
成為無效的i/o發行隊列409能夠分配給其他處理器或者fpga。例如,可以使主處理器200為雙核處理器,將其一個核分配給處理器隊列407,將另一個核分配給i/o發行隊列409,成為不進行核間的排他處理而各核能夠進行i/o發行的狀態。或者,也可以對fpga500分配fpga隊列408,對fpga510分配i/o發行隊列409,而成為能夠從多個fpga對一個存儲設備400發行i/o命令的狀態。
圖2中,存儲設備400具有3個i/o發行隊列,但是其個數不限定於3個,幾個都可以。
圖3是由信息處理裝置10進行了i/o發行處理的情況的說明圖。此處,使用圖3說明使主處理器200用和fpga500用獨立地來準備i/o發行隊列的必要性。
例如,在nvme的技術中,存儲設備400的處理器隊列407由供主處理器200進行寫入的寄存器構成,主處理器200記錄i/o指令發行的累計個數。
主處理器200發行的i/o指令能夠保存在i/o控制器401的管理信息保存區域403中。或者,也可以將主處理器200發行的i/o指令保存在系統存儲器210的規定區域。對於主處理器200發行的i/o指令的保存目的地,使用周知或者公知的技術即可,因此本實施例中不詳述。
另一方面,存儲設備400的處理器200(402?)將過去處理的指令數存儲在管理信息保存區域403中。例如,如果處理器隊列407的值和管理信息保存區域403的值的任一者的值均成為4,則表示過去主處理器200發行了4個指令,存儲設備400將該4個指令全部處理完畢。
使用圖3的a~c說明從主處理器200對存儲設備400新發行1個i/o指令的處理。首先,主處理器200在系統存儲器210的規定地址生成i/o指令(a)。
接著,主處理器200在處理器隊列407寫入對當前值=「4」加上1所得的值=「5」(b)。
與之相對,i/o控制器401的處理器402檢測到處理器隊列407的值「5」與存儲在管理信息保存區域403的、過去處理過的指令數=「4」的值具有差值,判斷為有新的指令,從系統存儲器210獲取指令(c)。
由於主處理器200自身能夠存儲寫入到處理器隊列407的值,所以在下次的i/o發行時不用讀取處理器隊列407,能夠容易地寫入對過去的值加上1而得的值,能夠高速地發行指令。
該情況下,若fpga500共有主處理器200和處理器隊列407而要新發行i/o指令,則首先,必需讀取一次處理器隊列407,才能知道當前的值。
此外,fpga500需要與主處理器200進行排他處理,例如指示主處理器200不更新處理器隊列407等。這些與通常的來自主處理器200的i/o發行相比存在不僅花費時間,還產生主處理器200無法發行i/o指令的時間,信息處理裝置10整體的性能降低的問題。
另一方面,本實施例1的存儲設備400中,對主處理器200用生成處理器隊列407,對fpga500用生成fpga隊列408。像這樣在i/o控制器401具有針對主處理器200和fpga500而獨立的i/o發行隊列的情況下,在處理器200與fpga500之間,可以不進行排他處理和多餘的i/o發行隊列的讀取,所以主處理器200和fpga500都能夠高速地發行i/o指令。
圖4是表示在信息處理裝置10進行的初始化處理的一例的時序圖。
在信息處理裝置10的初始化開始時,主處理器200從系統存儲器210獲取自身所連接的pcle網絡的構成信息(1000)。此外,本實施例的初始化處理由加載到系統存儲器210的os110和pcle驅動器130執行。以下,將進行os110或者pcle驅動器130的處理的主體作為主處理器200進行說明。
在pcle網絡中,具有pcle根聯合體221的晶片組220在起動時檢測與該晶片組220連接的pcle末端設備的網絡構成,將檢測結果(pci設備樹等)保存在系統存儲器210的規定區域中。主處理器200通過訪問系統存儲器210的規定區域,能夠獲取所存儲的pcle網絡(或者總線)的構成信息。
作為pcle網絡的構成信息,能夠包括網絡(或者總線)上的設備的位置、設備的性能、設備的容量等。pcle網絡的構成信息在os110或者pcle驅動器130的起動時由主處理器200收集,並保存在系統存儲器210的規定區域。
接著,主處理器200使用所獲取的pcle網絡的構成信息,分配訪問存儲設備400、410的加速器板50、51(1001)。分配所使用的信息使用例如存儲設備400、410與加速器板50、51之間的距離的信息。其中,對加速器板50分配存儲設備400、410的處理能夠以pcle驅動器130或者os110成為主體的方式進行。以下,將執行pcle驅動器130或者os110的主處理器200作為分配的主體進行說明。
作為距離的信息,能夠使用例如pcle網絡的跳數。本實施例中,將通過pcle開關2310、2320、2330的個數(或者次數)作為跳數。
在fpga500與存儲設備400的通信中,由於通過一個pcle開關2320,所以跳數=1。另一方面,fpga510與存儲設備400之間通過pcle開關2310、2320、2330,跳數=3。因此,圖2的構成中,將跳數少的fpga500分配給存儲設備400。通過同樣的距離的信息的比較,對存儲設備410分配fpga510。
再者,存儲設備400和加速器板50的分配不限定於一對一。例如,主處理器200能夠對存儲設備400分配fpga500和fpga510兩者,或者也能夠將fpga500分配給存儲設備400和存儲設備410兩者。
接著,主處理器200對存儲設備400發送生成i/o發行隊列的指令(1002)。此處,與pcle根聯合體221連接的主處理器200能夠獲取存儲設備400的i/o控制器401具有的、admin隊列406的地址。另一方面,如所述課題中也已陳述的那樣,作為pcle末端的fpga500無法獲取同樣作為pcle末端的admin隊列406的地址。
因此,主處理器200使用存儲設備400的admin隊列406,生產用於自身對存儲設備400發行i/o指令的處理器隊列407和用於fpga500對存儲設備400發行i/o指令的fpga隊列408這兩個隊列(1002)。
接著,主處理器200對fpga500通知fpga隊列408的隊列信息(fpga隊列408的地址和最大同時發行指令數(隊列的深度))(1003)。
這樣,如果有最低限fpga隊列408的地址和隊列的深度,則fpga500能夠對存儲設備400發行i/o指令。進而,作為隊列信息,還可以包括存儲設備400的pcle(或者pci)配置寄存器(省略圖示)的地址和能夠訪問的lba(logicalblockaddress:邏輯塊地址)的範圍(能夠訪問的起始lba和容量等)等信息。
例如,若fpga500能夠獲取存儲設備400的pcle配置寄存器的地址,則還能夠獲取存儲設備400的nvme寄存器(省略圖示)的地址。fpga500能夠根據這些地址計算能夠訪問的lba的範圍。在fpga500使用能夠訪問的lba的範圍對例如一臺加速器板50分配了多個存儲設備400、410的情況下,fpga500能夠判斷對哪個存儲設備發行i/o指令好。
再者,nvme寄存器是例如在「nvmexpress」(revision1.1bjuly2,2014、nvmexpressworkgroup刊)的第37頁~第45頁等記載的寄存器。
進而,主處理器200使用admin隊列在存儲設備410也同樣生成處理器隊列和fpga隊列(1004),並將fpga隊列的信息通知給fpga510(1005)。
通過以上圖4的處理,fpga500能夠向存儲設備400發行i/o指令,此外,fpga510能夠向存儲設備410發行i/o指令。
再者,以主處理器200使用admin隊列406生成處理器隊列407和fpga隊列408的順序為例進行了說明,但是也可以是,主處理器200對fpga500通知admin隊列406的地址,fpga500生成處理器隊列407和fpga隊列408。
通過以上圖3、圖4的處理,作為pcle網絡的末端而連接的加速器板50的fpga500能夠從主處理器200獲取fpga隊列408的隊列信息。由此,能夠從pcle末端的fpga500對同樣為pcle末端的存儲設備400發行i/o指令,加速器板50能夠訪問保存在存儲設備400的db450的數據。
圖5是表示在信息處理裝置10的初始化完成後主處理器200使fpga500執行資料庫450的過濾處理的例子的時序圖。
執行dbms120的主處理器200首先對fpga500發行指示過濾處理的過濾處理指令(1101)。該過濾處理指令中至少包括:表示執行過濾處理的資料庫450的表格的排頭位於存儲設備400的db保存區域404的地址的哪裡的信息;和執行過濾處理的db450的大小的信息、過濾處理的條件式=a。再者,過濾處理指令中除此之外還可以包括保存過濾處理的結果數據的系統存儲器210的地址。
過濾處理指令是包括例如表格的排頭為存儲設備400的lba=0x1000,並按1m(兆)字節的數據執行過濾條件式=a的過濾處理這樣的信息的指令。
此外,過濾處理指令的發行目的地(fpga500或者fpga510)也可以由dbms120或者pcle驅動器130的任一個決定。在pcle驅動器130進行決定的情況下,dbms120發行過濾處理指令時,pcle驅動器130決定發行目的地(fpga500或者fpga510)而發送過濾處理指令。
從執行dbms120的主處理器200接收到過濾處理指令的fpga500的i/o處理電路501,根據過濾處理指令的信息對存儲設備400發行讀取指令(1102)。該讀取指令可以是一次,也可以是多次。圖示的例子中,表示fpga500將對1m字節的讀取分為4次而按每256k字節發行4個讀取指令的例子。
4個讀取指令通過例如對於lba=0x1000、0x1200、0x1400、0x1600的4次256k字節讀取指令,fpga500讀取將lba=0x1000作為排頭的1m字節的數據。
從存儲設備400的db保存區域404讀取到的數據保存在fpga500的緩存503中(1103)。收到4次的讀取完成通知的i/o處理電路501對過濾處理電路502進行指示以使得對緩存503的數據執行規定的過濾處理(1104)。
接受了指示的過濾處理電路502執行過濾條件式=a的過濾處理。
接著,過濾處理電路502將過濾處理的結果發送到db伺服器20的系統存儲器210(1105)。發送目的地的地址可以由過濾處理指令指定,也可以為預先設定的固定地址。
過濾處理完成後,過濾處理電路502將完成通知發送到i/o處理電路501(1106)。接收到完成通知的i/o處理電路501對主處理器200通知過濾處理的完成,並且主處理器200接收到該完成通知,由此一系列的過濾處理完成(1107)。
此外,圖5中,說明了作為保存過濾處理的結果數據的地址而使用系統存儲器210的地址的例子,但是過濾處理的結果數據的保存目的地地址不限定於此。例如,如果是表示存儲設備400的地址的信息,則在存儲設備400寫入過濾處理的結果數據即可,如果是表示加速器板51的地址的信息,則在加速器板51寫入過濾處理的結果數據即可,如果是表示加速器板50的地址的信息,則保存在加速器板50的存儲器上即可。
此外,雖然表示了在過濾處理指令之中直接放入過濾條件式=a的例子,但是不限定於此,也可以是用於得到過濾條件式的信息。例如,也可以在系統存儲器210上保存過濾條件式,並將該過濾條件式的保存地址放入過濾處理指令之中。
通過上述圖5的處理,從與pcle總線的末端連接的加速器板50直接訪問同樣為末端的存儲設備400,由此能夠降低db伺服器20的負荷。此外,db450的數據不通過pcle總線2300,而經由pcle開關2320被讀入fpga500。因此,pcle總線2300的性能(傳送速度等)不成為瓶頸,fpga500能夠高速地執行過濾處理。特別是,以如圖21那樣pcle開關9000~9006構成為樹狀、且在其前端連接有存儲設備9300、9400、9500、9600和加速器9301、9401、9501、9601那樣的樹狀的構成將多個存儲設備和加速器組連接時,本發明尤其能發揮效果。此時,加速器9031訪問的存儲設備全部是跳數為1的存儲設備的情況下,從各存儲設備9300、9400、9500、9600讀取到的數據由pcle開關9003~9006關閉,所以即使增加存儲設備和加速器的組也不使用樹狀的上位的pcle開關(9000、9001、9002)的帶寬。由此,能夠橫向擴展過濾處理性能。
圖6是表示主處理器200的i/o和加速器板50的i/o同時存在時的處理的一例的時序圖。圖6的例子是在fpga500執行過濾處理時,主處理器200在存儲設備400進行讀取的時序圖。
與上述圖5的過濾處理的時序圖同樣,執行dbms120的主處理器200首先對fpga500發行指示過濾處理的過濾處理指令(1111)。
從主處理器200接收到過濾處理指令的fpga500的i/o處理電路501根據過濾處理指令的信息對存儲設備400發行讀取指令(1112)。該情況下,fpga500使用在上述初始化時從主處理器200通知了地址的fpga隊列408。此外,同時,主處理器200也對存儲設備400發行了讀取指令(1113)。該情況下,主處理器200使用處理器隊列407。
圖示的例子中,存儲設備400執行fpga隊列408的第一個讀取指令,並將從db保存區域404讀入的數據保存在fpga500的緩存503中(1114)。存儲設備400將第一個讀取指令的讀取完成通知發送到fpga500(1115)。
接著,存儲設備400執行處理器隊列407的讀取指令,並將從db保存區域404讀入的數據保存在系統存儲器210中(1116)。存儲設備400將讀取指令的讀取完成通知發送到主處理器200(1117)。
使主處理器200的i/o處理完成了的存儲設備400依次執行fpga隊列408的第二個以後的讀取指令,並將從db保存區域404讀入的數據保存在fpga500的緩存503中(1118)。存儲設備400將各讀取指令的讀取完成通知分別發送到fpga500(1119)。
收到了4次讀取完成通知的i/o處理電路501對過濾處理電路502指示對緩存503的數據執行規定的過濾處理(1120)。接受了指示的過濾處理電路502執行規定的過濾處理。
接著,過濾處理電路502將過濾處理的結果發送到db伺服器20的系統存儲器210(1121)。過濾處理完成後,過濾處理電路502將完成通知發送到i/o處理電路501。接收到完成通知的i/o處理電路501對主處理器200通知過濾處理完成,主處理器200收到該完成通知,由此一系列的過濾處理完成(1122)。
如以上圖5的處理那樣,存儲設備400通過初始化處理(圖4)獨立地設置處理器隊列407和fpga隊列408,使用任意隊列都能夠讀取和寫入db保存區域404的數據。因此,即使主處理器200和fpga500不進行排他處理,這些讀取請求也會被正確地處理。
例如,圖6中表示了正從fpga500向存儲設備400發行4個讀取指令時從主處理器200也發行了讀取指令的例子,i/o控制器401中,fpga500和主處理器200寫入讀取指令的隊列分別獨立,所以不需要進行fpga500和主處理器200的排他控制。由此,信息處理裝置10能夠不降低處理性能地從fpga500和主處理器200並行地發行i/o指令。
接著,使用圖7~圖9說明在本實施例1中多個存儲設備400和加速器板50與同一pcle開關連接的情況下的分配方法。
圖7是表示將向1個pcle開關3320連接了存儲設備和加速器板的多個組的構成的一例的框圖。代替圖2所示的pcle開關2320,圖7的信息處理裝置10在pcle開關3320和pcle總線3303添加存儲設備410、420和加速器板52,而且在pcle驅動器130添加表格140~160。其他的構成與上述圖2相同。
圖8是表示存儲設備400、410、420與加速器板50~52之間的跳數的跳數表格140。跳數表格140表示圖7的存儲設備400、410、430與fpga500、510、520之間的跳數的表格。跳數表格140由信息處理裝置10的管理者等預先設定,並由pcle驅動器130管理,存儲在系統存儲器210中。
關於與pcle開關3330連接的存儲設備410,跳數最少的加速器板51僅為fpga510,所以能夠僅通過跳數對fpga510分配存儲設備410。
另一方面,關於存儲設備400、420、430,跳數最少的加速器板50、52存在多個。這樣的情況下,可以在pcle網絡構成中選擇距離信息近的加速器板。該情況下,圖7的構成中,對fpga500分配存儲設備400和存儲設備410。此外,對fpga520分配存儲設備430。再者,作為pcle網絡構成的距離信息,能夠定義為pcle開關3320的埠編號越近則距離越近。
此外,os110或者pcle驅動器130也可以使用跳數等距離信息以外的信息來決定存儲設備400和加速器板50的分配。該信息能夠從存儲設備和/或加速器板50獲取,例如,具有圖9a、圖9b所示那樣的加速器板50的過濾處理性能、存儲設備的容量、存儲設備的讀取性能等。
圖9a是表示fpga的過濾處理性能的fpga性能表格150。fpga性能表格150由fpga的標識符1511和過濾處理性能1512構成。fpga性能表格150可以由信息處理裝置10的管理者等預先設定而由pcle驅動器130管理,並保存在系統存儲器210中,還可以是pcle驅動器130在加速器識別時進行查詢,並將其結果保存在系統存儲器210中。
圖9b是表示存儲設備的性能的存儲設備性能表格160。存儲設備性能表格160由存儲設備的標識符1601、容量1602和讀取性能1603構成。存儲設備性能表格160可以由信息處理裝置10的管理者等預先設定而由pcle驅動器130管理,並保存在系統存儲器210中,也可以是pcle驅動器130在存儲設備識別時查詢存儲設備的性能,並將其結果保存在系統存儲器210中。
圖9a、圖9b的例子中,os110或者pcle驅動器130也可以以將容量大的存儲設備分配給處理性能高的設備這樣的邏輯,對fpga500分配存儲設備420,對fpga510分配存儲設備400和存儲設備430。
或者,os110或者pcle驅動器130還可以以使得加速器板的過濾性能和存儲設備的讀取性能平衡的方式對fpga500分配存儲設備420,對fpga520分配存儲設備400和410。
或者,也可以對fpga500分配存儲設備400、存儲設備420和存儲設備430,對fpga510也分配存儲設備400、存儲設備420和存儲設備430。該情況下,存儲設備400、420、430的i/o控制器401,除了生成各個主處理器200用的處理器隊列407以外,還能生成加上fpga500用的fpga隊列408和fpga510用的fpga隊列409這兩個而得到的數量的i/o發行隊列。主處理器200能夠在使用了存儲設備400、410、420、430的資料庫450的過濾處理中並行使用fpga500和fpga510兩者。
信息處理裝置10中,通過進行這樣的fpga和存儲設備的分配,例如能夠以存儲設備的讀取性能的合計與加速器板的過濾性能平衡的方式進行分配,能夠採用在高負荷時存儲設備和加速器板都能夠發揮最大性能的構成等,實現信息處理裝置10整體的性能的最優化。
接著,說明在本實施例1中在存儲設備400產生了故障的情況下的處理的一例。圖10是表示在存儲設備400產生了故障時在信息處理裝置10進行的處理的一例的時序圖。
當存儲設備400被分配給fpga500時,執行dbms120的主處理器200對fpga500發行過濾處理指令,對存儲設備400的db450執行過濾處理(1201)。
fpga500接收過濾處理指令,為了讀取成為處理對象的db450,對存儲設備400發行讀取指令(1202)。
但是,在該時刻存儲設備400產生了故障的情況下(1203),例如存儲設備400檢測到自身的故障,經由pcle根聯合體221對主處理器200通知故障(1204)。
接受了故障通知的主處理器200檢測存儲設備400的故障,並將該故障通知給fpga500(1205)。接收到故障的通知的fpga500,因為過濾處理尚未完成,所以將因故障而過濾處理失敗了的情況通知給主處理器200。
上述圖10的例子中,說明了存儲設備400自身檢測到故障並通知給主處理器200的例子,但是也可以是主處理器200監視存儲設備400的狀態,檢測故障,對fpga500通知存儲設備400的故障。
此外,也可以是fpga500通過輪詢(polling)等檢測在存儲設備400產生了故障的情況。例如,也可以通過從fpga500對存儲設備400發行的讀取的超時等來進行檢測。檢測到故障的fpga500對主處理器200通知該故障和過濾處理失敗了的情況。
通過這種方式檢測到存儲設備400的故障的主處理器200能夠對db伺服器20通知在存儲設備400發生了故障的情況,並催促更換。例如,存在在db伺服器20的管理畫面顯示告知產生故障的消息等的方法。此外,當具有通過鏡像等方法而被保護的、存儲設備400的備份設備時,能夠代替存儲設備400而使用該設備。
接著,對在本實施例1中在加速器板50產生了故障的情況下的處理的一例進行說明。圖11是表示在加速器板50產生了故障時由信息處理裝置10進行的處理的一例的時序圖。
在存儲設備400被分配給fpga500的情況下,執行dbms120的主處理器200指示fpga500進行對存儲設備400的db450的過濾處理(1211)。
但是,在該時刻,在fpga500產生了故障的情況下(1212),fpga500經由pcle根聯合體221對主處理器200通知故障(1213)。接受了故障的通知的主處理器200檢測fpga500的故障。另外,也可以由主處理器200監視fpga500,來檢測故障。
主處理器200從存儲設備400讀取過濾處理中所需的db450(1214),並將其保存在系統存儲器210(1215)。讀取完成後(1216),執行dbms120的主處理器200不使用fpga500,而由自身執行db450的過濾處理(1217)。
此外,主處理器200也可以將分配給fpga500的存儲設備400再次分配給fpga510等其他加速器板51。關於該處理,用以下的圖12進行說明。
圖12是表示在加速器板50產生了故障時由信息處理裝置10進行的重新分配處理的一例的時序圖。
在存儲設備400被分配給fpga500的情況下,執行dbms120的主處理器200對fpga500指示對存儲設備400的db450執行過濾處理(1221)。
但是,在該時刻,在fpga500產生了故障的情況下(1222),fpga500經由pcle根聯合體221對主處理器200通知故障(1223)。接受了故障的通知的主處理器200檢測fpga500的故障。此外,也可以由主處理器200監視fpga500來檢測故障。
主處理器200決定對新的加速器板51分配存儲設備400。主處理器200指示存儲設備400生成fpga510用的fpga隊列408(1224)。主處理器200對fpga510通知包括存儲設備400的fpga510用的fpga隊列408的地址在內的信息(1225)。
接著,執行dbms120的主處理器200對新的fpga510重新發行指示進行使用保存在存儲設備400的db450的過濾處理的過濾處理指令(1226)。
從主處理器200接收到過濾處理指令的fpga510根據過濾處理指令的信息對存儲設備400發行讀取指令(1227)。從存儲設備400的db保存區域404讀取的數據保存在fpga510的緩存中(1228)。
存儲設備400在所請求的數據的讀出完成時將讀取完成通知發送到fpga510(1229)。接收到讀取完成通知的fpga510基於過濾處理指令執行過濾處理(1230)。
接著,fpga510將過濾處理的結果發送到db伺服器20的系統存儲器210(1231)。過濾處理完成後,fpga500將過濾處理的完成通知發送到主處理器200(1232),結束一系列的過濾處理。
另外,雖然說明了在存儲設備400生成新的fpga510用的fpga隊列408的例子,但是也可以是fpga510援用fpga500所使用的fpga隊列408。在該情況下,主處理器200對fpga510通知fpga500所使用的fpga隊列408的地址和fpga隊列408的值等、用於援用fpga隊列408的交接信息。
如以上圖12那樣,在fpga500產生了故障的情況下,對存儲設備400分配其他fpga510,由此,即使在fpga500發生故障時也能夠保持處理能力,能夠繼續信息處理裝置10的運用。
圖13是表示對1個pcle開關4320追加了存儲設備和加速器板的構成的一例的框圖。圖13的信息處理裝置10,代替圖2所示的pcle開關2320,在經由pcle總線4300與db伺服器20連接的pcle開關4310上,經由pcle總線4303連接有加速器板50和存儲設備400。而且,在該pcle開關4310熱插拔存儲設備440和加速器板53。對於其他構成,與所述圖2相同。
圖14是表示在信息處理裝置10的初始化完成後,追加了新的存儲設備440時的處理的一例的時序圖。
在向將fpga500分配給存儲設備400的信息處理裝置10新插入了存儲設備440時(1301),從存儲設備440對主處理器200發行中斷(1302)。
檢測通過熱插拔進行的中斷,檢測到存儲設備440的追加的主處理器200進行存儲設備440和fpga500的重新分配。例如,示出將存儲設備440追加分配給fpga500的例子。
主處理器200指示存儲設備440生成主處理器200用的處理器隊列407和fpga500用的fpga隊列408(1303)。
主處理器200對fpga510通知包括fpga510用的fpga隊列408的地址在內的隊列信息(1304)。
通過進行這樣的重新分配,即使在信息處理裝置10的初始化完成後,也能夠在存儲設備440的追加後賦予fpga500處理新的存儲設備的信息的功能。
圖15是表示在信息處理裝置10的初始化完成後追加了新的加速器板53時的處理的一例的時序圖。
圖13中,在向將fpga500分配給存儲設備400的信息處理裝置10新追加了加速器板53(fpga530)時(1311),從fpga530對主處理器200發行中斷(1312)。
檢測通過熱插拔進行的中斷,檢測到追加了fpga530的主處理器200對存儲設備400、440、fpga500、530再次進行分配。例如,在存儲設備400仍然被分配給fpga500、且存儲設備440被分配給新追加的fpga530的情況下,主處理器200對fpga500通知存儲設備440的分配解除(1313)。
接著,主處理器200指示存儲設備440生成fpga530用的fpga隊列408(1314)。之後,主處理器200對fpga530通知包括存儲設備440的fpga530用的fpga隊列408的地址在內的隊列信息(1315)。之後,執行dbms120的主處理器200指示由fpga530執行使用存儲設備440的db的過濾處理。
此外,說明了在存儲設備440生成新的fpga530用的fpga隊列408的例子,但也可以是fpga530援用fpga500所使用的fpga隊列408。該情況下,主處理器200對fpga530通知fpga500所使用的fpga隊列408的地址和fpga隊列408的值等、用於援用fpga隊列408的交接信息。
通過進行這樣的重新分配,即使在信息處理裝置10的初始化完成後,也能夠在追加加速器板53後使用加速器板53來提高信息處理裝置10的性能。
以上,根據本實施例1,db伺服器20的主處理器200對同樣作為末端的加速器的fpga500通知與pcle總線2300~2304的末端連接的存儲設備400的隊列的信息。由此,pcle總線2300~2304的末端的fpga500同樣能夠訪問末端的存儲設備400。而且,fpga500能夠直接從存儲設備400讀出數據並執行主處理器200的處理的一部分,能夠使信息處理裝置10高速化。
此外,本實施例1使用資料庫450的過濾處理進行了說明,但是適用本發明的處理不限定於資料庫450的過濾處理,只要是能夠將主處理器200的負荷卸載到加速器板50的處理即可。例如可以是數據的壓縮處理等。
此外,在本實施例1中,說明了主處理器200對加速器板50通知nvme的admin隊列406的地址和i/o發行隊列407~409的地址的例子,但是本發明不限定於nvme和隊列接口。只要是處理器對加速器板50通知用於能夠進行i/o指令發行的初始設定接口的地址和從其他設備向存儲設備的i/o發行接口的地址的構成即可。
此外,在本實施例1中,如圖2所示,說明了利用在db伺服器20的外部連接存儲設備400和加速器板50的構成,執行db450的過濾處理的例子。但是,本發明不限定於該構成,只要是主處理器200、存儲設備400和加速器板50通過網絡連接的構成即可。
例如也可以是在db伺服器20的內部的pcle插槽搭載有存儲設備400或者加速器板50的構成,或者圖16的信息處理裝置10那樣的構成。
圖16表示實施例1的變形例,是表示信息處理裝置10a的一例的框圖。信息處理裝置10a具有通過伺服器-存儲裝置間網絡700(例如、光纖通道、infiniband(無線帶寬技術)等)連接於db伺服器20的存儲裝置60。在存儲裝置60的內部包括具有存儲處理器600、高速緩存610、存儲晶片組620的存儲控制器61。
存儲控制器61的存儲晶片組620包括pcle根聯合體621。pcle根聯合體621經由pcle總線5301連接pcle開關5310。
包括fpga500、510的加速器板50、51和存儲設備400、410、420、430經由pcle總線5303與pcle開關5310連接。
此外,在本實施例1中,說明了使用pcle總線作為將主處理器200、存儲設備400和加速器板50連接的總線,但是本發明中使用的總線不限定於的pcle。例如代替pcle總線可以使用sas(serialattachedscsi:串列scsi)。
實施例2
圖17表示本發明的第二實施例,是表示信息處理裝置10的一例的框圖。本實施例2中,代替加速器板50,採用加速器板54,僅使用pcle開關2310,其他的構成與所述實施例1相同。
所述實施例1中,說明了不具有存儲元件的加速器板50對存儲設備400發行i/o指令的例子,但是本發明中,搭載有加速器板50的設備也可以具有存儲元件。
例如,圖17的信息處理裝置10是具有加速器板54和存儲設備400的構成,加速器板54搭載有作為加速器的fpga540和作為非易失性存儲器的db保存區域545雙方。
db伺服器20與所述實施例1同樣,主處理器200在存儲設備400的i/o控制器401生成fpga用i/o發行隊列409,並將所生成的隊列信息通知給fpga540。由此,fpga540能夠使用隊列信息對存儲設備400發行i/o指令。
以下說明在該加速器板54發行了過濾處理指令時的處理。
圖18是表示由信息處理裝置10進行的資料庫處理的一例的時序圖。
與所述實施例1的圖5同樣,執行dbms120的主處理器200對fpga540發行過濾處理指令(1401)。過濾處理指令中至少包括:表示執行過濾處理的資料庫450的表格的排頭位於存儲設備400的db保存區域404的地址的哪裡的信息;和執行過濾處理的db450的大小信息、過濾處理的條件式=a。收到過濾處理指令的i/o處理電路541針對自身的db保存區域545中沒有的lba區域的數據向存儲設備400發行讀取指令(1402)。存儲設備400讀出所請求的數據並將其寫入緩存543(1404、1408),向i/o處理電路541發行讀取完成通知(1406、1410)。
另一方面,對於保存在fpga540自身的db保存區域545的lba區域的數據,對非易失性存儲器控制電路544發行讀取指令(1403)。db保存區域545讀出所請求的數據並將其寫入緩存543(1405、1409),對i/o處理電路541發行讀取完成通知(1407、1411)。
i/o處理電路541,在過濾處理中所需的全部數據被寫入緩存543時,基於接收到的條件式=a對過濾處理電路542發出執行過濾處理的指令(1412)。過濾處理電路542使用緩存543的數據執行過濾處理,在db伺服器20的系統存儲器210寫入過濾處理結果(1413)。而且,過濾處理電路542對i/o處理電路541發行過濾處理的完成通知(1414)。i/o處理電路541對db伺服器20的主處理器200通知過濾處理的完成通知(1415),結束處理。
通過這樣的處理,db伺服器20能夠對加速器板54將在存儲設備400的db保存區域404和加速器板54的db保存區域545中保存的db的過濾處理卸載到作為加速器的fpga540。
實施例3
圖19表示本發明的第三實施例,是表示信息處理裝置10的一例的框圖。本實施例3中,代替加速器板50和存儲設備400,將多個加速器搭載存儲設備800、810連接在pcle開關310上,其他構成與所述實施例1相同。
所述實施例1中,說明了不具有存儲元件的加速器板50對存儲設備發行i/o指令的例子,但是本發明中,能夠採用包括加速器的功能和存儲設備的功能的加速器搭載存儲設備800、810。
例如,如圖19的信息處理裝置10那樣,存在將作為加速器而搭載有fpga900的加速器搭載存儲設備800和搭載有fpga910的加速器搭載存儲設備810經由pcle開關310與db伺服器20連接的構成等。db伺服器20和pcle開關310是與所述實施例1相同的構成。
加速器搭載存儲設備800中,i/o控制器801和fpga900具有晶片間通信電路901,能夠對fpga900的緩存903傳送db保存區域804的數據。由此,能夠利用過濾處理電路902對db保存區域804的db進行過濾處理。
再者,i/o控制器801與所述實施例1的圖2所示的i/o控制器401同樣,具有處理器802、管理信息保存區域803和指令接口805。指令接口805具有admin隊列806、處理器隊列807和fpga隊列808、809。
加速器搭載存儲設備810也是同樣的構成,i/o控制器811和fpga910具有晶片間通信電路,能夠對fpga910的緩存913傳送db保存區域814的數據。由此,能夠利用過濾處理電路912對db保存區域814的db進行過濾處理。
再者,i/o控制器811與所述實施例1的圖2所示的i/o控制器401同樣,具有處理器812、管理信息保存區域813和指令接口815。指令接口815具有admin隊列816、處理器隊列817和fpga隊列818、819。
圖20是表示由信息處理裝置10進行的初始化處理的一例的時序圖。
主處理器200在信息處理裝置10的初始化開始時從系統存儲器210取得自身連接的pcle網絡的構成信息(1501)。
接著,主處理器200使用所取得的pcle網絡的構成信息分配訪問資料庫保存區域804、814的fpga900、910(1502)。該分配能夠與所述實施例1的圖4同樣地進行。
主處理器200使用加速器搭載存儲設備800的admin隊列806,生成主處理器200用的i/o發行隊列807和加速器搭載存儲設備810的fpga910用的i/o發行隊列808(1503)。
此外,同樣地,主處理器200使用加速器搭載存儲設備810的admin隊列816,生成主處理器200用的i/o發行隊列817和加速器搭載存儲設備800的fpga900用的i/o發行隊列818(1504)。
之後,主處理器200對加速器搭載存儲設備800通知加速器搭載存儲設備810的i/o發行隊列818的信息(1505)。此外,主處理器200對加速器搭載存儲設備810通知加速器搭載存儲設備800的i/o發行隊列808的信息(1506)。通過上述圖20的處理,加速器搭載存儲設備800和加速器搭載存儲設備810能夠相互發行i/o指令來執行過濾處理。
再者,上述實施例3中介紹了i/o控制器801、811和fpga900、910作為獨立的晶片而被安裝的例子,但是也可以將過濾處理電路902、912搭載於i/o控制器801、811等一體化為具有加速器的功能的i/o控制器。
再者,將所述實施例1的圖5的處理適用於本實施例3時,主處理器200對加速器搭載存儲設備810發行過濾處理指令,加速器搭載存儲設備810從加速器存儲設備800讀入數據。然後,加速器搭載存儲設備810的fpga910執行過濾處理,並將處理結果保存在主處理器200的系統存儲器210。
此外,將所述實施例1的圖7、圖8、圖9a、圖9b的內容適用於本實施例3時,首先,在主處理器200起動等時多個加速器收集存儲設備800、810的信息,並作為pcle網絡的構成信息保存在系統存儲器210中。然後,主處理器200基於pcle網絡的構成信息,使滿足規定條件的加速器決定存儲設備800、810和fpga900、910的分配。主處理器200基於該決定了的分配,通過加速器對加速器搭載存儲設備810通知存儲設備800的admin隊列806的地址或者i/o發行隊列807、808的地址,來進行分配並執行。
再者,將所述實施例1的圖10的處理適用於本實施例3時,在加速器搭載存儲設備800產生了故障時,基於來自加速器搭載存儲設備800的通知,主處理器200檢測故障。主處理器200對執行過濾處理的加速器搭載存儲設備810通知加速器搭載存儲設備800的故障。
再者,將所述實施例1的圖11的處理適用於本實施例3時,在加速器搭載存儲設備810的fpga910產生了故障時,加速器搭載存儲設備810對讀入了數據的加速器搭載存儲設備800通知fpga910的故障。
或者,也可以是,加速器搭載存儲設備810對主處理器200通知fpga910的故障,主處理器200對加速器搭載存儲設備800通知fpga910的故障。
再者,將所述實施例1的圖14或者圖15的處理適用於本實施例3時,主處理器200檢測到新的加速器搭載存儲設備的追加時,參照系統存儲器210的pcle網絡的構成信息,決定新的加速器搭載存儲設備和fpga的分配。然後,主處理器200基於新的分配,將admin隊列和i/o發行隊列的地址通知給新的加速器搭載存儲設備或已有的加速器搭載存儲設備800來改變分配。
再者,本發明不限定於上述的實施例,包括各種變形例。例如,為了容易理解地說明本發明,上述的實施例是詳細記載的例子,不必限定於具有所說明的全部構成。此外,能夠將某實施例的構成的一部分置換為其他實施例的構成,此外,還能夠在某實施例的構成中添加其他實施例的構成。此外,對於各實施例的構成的一部分,均能夠單獨地或者組合地應用其他構成的任何追加、刪除或者置換。
此外,上述的各構成、功能、處理部和處理單元等,它們的一部分或者全部可以通過例如集成電路進行設計等由硬體實現。此外,上述的各構成和功能等,也可以通過解釋、執行處理器實現各個功能的程序而由軟體實現。實現各功能的程序、表格、文件等信息能夠放在存儲器、硬碟、ssd(solidstatedrive)等記錄裝置、或者ic卡、sd卡、dvd等記錄介質中。
此外,控制線和信息線示出了說明上認為必要的部分,不限定於產品上必須示出全部的控制線和信息線。實際上也可以認為幾乎所有的構成相互連接。
<補充>
一種信息處理裝置,是存儲數據的存儲設備,
所述存儲設備具有接受所述初始化的命令的初始設定接口和發行i/o指令的i/o發行接口,
所述i/o發行接口包括接受來自所述第一裝置的i/o指令的第一i/o發行接口和接受來自所述第二裝置的i/o指令的第二i/o發行接口,
所述存儲設備能夠從所述第一裝置和第二裝置分別獨立地接受所述i/o指令。