數據壓縮方法及裝置與流程
2023-10-09 00:06:59 4
本發明涉及數據壓縮領域,具體地,涉及一種數據壓縮方法及裝置。
背景技術:
實體企業的工作空間使用或產生了海量的實時數據,這些實時數據的讀寫和特徵分析效率關係著生產運維決策的制定和執行的效率,尤其在即將到來的「工業4.0」或《中國製造2025》時代,海量數據的處理將越發重要。
在目前的存儲、讀寫、搜索架構中,實時數據並需要全部保存,因此,可以通過有損數據壓縮算法來對實時數據進行處理,現有技術中使用的有損數據壓縮算法例如可以是死區壓縮算法、pi的旋轉門壓縮算法及其擴展等算法,這些數據壓縮算法兼顧了特徵數據覆蓋率、計算和存儲性能,在工業界具有廣泛的應用。
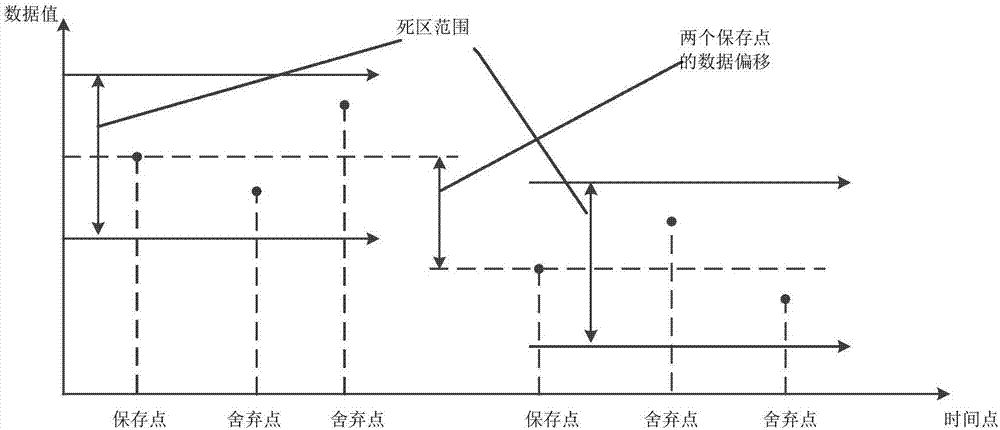
圖1示出了死區壓縮算法的原理示意圖。死區壓縮算法工作在一維線型空間中,如圖1所示,在時間點-數據值的坐標中,比對當前數據和上一個保存的數據的偏差是否位於預先設定好的變化區間內,即死區範圍內,若是則將當前數據確定為捨棄點並將其過濾掉,否則將當前數據確定為保存點並將其保存,新的保存點與先前保存點之間的數據偏移超過預先設定好的變化區間。在確定出新的保存點之後,根據該新的保存點來確定位於該新的保存點之後的數據點是保存還是捨棄。死區壓縮算法適用于波動穩定的數據壓縮,不適用於總是沿一個方向波動的數據壓縮。
圖2示出了pi的旋轉門壓縮算法的原理示意圖。pi的旋轉門壓縮算法工作在二維線型空間中,如圖2所示,在時間點-數據值的坐標中,使用上一個保存點a和當前的數據點b畫一條線段ab,並按照設定的偏差將此線段在垂直方向上向上向下移動,進而擴展出一個二維數據空間1。選擇上一個保存點a和當前的數據點b的下一個數據點c繼續上述過程,擴展出一個二維數據空間2。如果後一個二維數據空間2能包含位於上一個保存點a和下一個數據點c之間的所有數據點,則判斷數據點c之前的數據點b為捨棄點,否則判斷據點c之前的數據點b為保存點。繼續上述的判斷過程,可以判斷出圖2中,二維數據空間3能夠包含保存點a與數據點d之間的所有數據點(數據點b和數據點c),則數據點d的前一數據點c為捨棄點。二維數據空間4並不能夠包含保存點a與數據點e之間的所有數據點(數據點b、數據點c和數據點d),則數據點e的前一數據點d為保存點。然後根據保存點d來對保存點d之後的數據點繼續上述的判斷過程。pi的旋轉門壓縮算法適用於慢變化的數據。
從上述對死區壓縮算法、pi的旋轉門壓縮算法的描述中可知,現有技術進行數據壓縮時,均採取一刀切的方式,即根據數據點在一條邊界線的內側還是外側、數據點在一個邊界四邊形的內側還是外側,來決定捨棄或保存數據,本質上都是檢查數據點的數據值是否在純人為設定的上限或下限之間來決定捨棄或保存。
技術實現要素:
本發明實施例的目的是提供一種數據壓縮方法及裝置,以解決或至少部分解決上述技術問題。
為了實現上述目的,本發明實施例提供一種數據壓縮方法,該方法包括:將採集的數據的採集時間和數據值映射為時間-數據值的坐標系中的數據點;根據指定為起始點的已保存的數據點確定在採集時間上位於該已保存的數據點之後的下一個要被保存的數據點;將確定的要被保存的數據點重新指定為起始點並根據該重新指定的起始點確定在採集時間上位於該重新指定的起始點之後的下一個要被保存的數據點,直到確定出所述數據點中所有要被保存的數據點;以及保存被確定要被保存的數據點;其中,確定下一個要被保存的數據點包括:按照採集時間的順序依次判斷所述起始點之後的數據點是否滿足當前被考慮的數據點與所述起始點之間存在至少一個數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值;如果所述當前被考慮的數據點與所述起始點之間存在至少一個數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值,則將當前被考慮的數據點之前的一個相鄰的數據點確定為下一個要被保存的數據點。
可選地,所述按照採集時間的順序依次判斷所述起始點之後的數據點是否滿足當前被考慮的數據點與所述起始點之間存在至少一個數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值包括:針對所述當前被考慮的數據點與所述起始點之間的所有數據點中的每一個數據點,以該每一個數據點的坐標為圓心、以所述預定義值為半徑建立針對所述每一個數據點的圓;判斷所述當前被考慮的數據點與所述起始點之間的線段是否與針對所述每一個數據點的圓中的至少一個圓相離;在所述當前被考慮的數據點與所述起始點之間的線段與針對所述每一個數據點的圓中的至少一個圓相離的情況下,確定所述當前被考慮的數據點與所述起始點之間存在至少一個數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值;以及在所述當前被考慮的數據點與所述起始點之間的線段與針對所述每一個數據點的圓中的每一個圓均不相離的情況下,確定所述當前被考慮的數據點與所述起始點之間不存在數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值。
可選地,所述判斷所述當前被考慮的數據點與所述起始點之間的線段是否與針對所述每一個數據點的圓中的至少一個圓相離包括:根據所述當前被考慮的數據點與所述起始點之間的線段方程和針對所述每一個數據點的圓中的每一個圓的方程來判斷所述當前被考慮的數據點與所述起始點之間的線段是否與針對所述每一個數據點的圓中的至少一個圓相離。
可選地,所述確定下一個要被保存的數據點還包括:如果所述當前被考慮的數據點與所述起始點之間不存在數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值,則將當前被考慮的數據點之前的一個相鄰的數據點確定捨棄點。
可選地,所述預定義值為2。
相應地,本發明實施例還提供一種數據壓縮裝置,所述裝置包括:映射模塊,用於將採集的數據的採集時間和數據值映射為時間-數據值的坐標系中的數據點;第一確定模塊,用於根據指定為起始點的已保存的數據點確定在採集時間上位於該已保存的數據點之後的下一個要被保存的數據點;第二確定模塊,用於將確定的要被保存的數據點重新指定為起始點並根據該重新指定的起始點確定在採集時間上位於該重新指定的起始點之後的下一個要被保存的數據點,直到確定出所述數據點中所有要被保存的數據點;以及保存模塊,用於保存被確定要被保存的數據點;其中,所述第一確定模塊包括:判斷單元,用於按照採集時間的順序依次判斷所述起始點之後的數據點是否滿足當前被考慮的數據點與所述起始點之間存在至少一個數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值;確定單元,用於如果所述當前被考慮的數據點與所述起始點之間存在至少一個數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值,則將當前被考慮的數據點之前的一個相鄰的數據點確定為下一個要被保存的數據點。
可選地,所述判斷單元包括:圓建立子單元,用於對所述當前被考慮的數據點與所述起始點之間的所有數據點中的每一個數據點,以該每一個數據點的坐標為圓心、以所述預定義值為半徑建立針對所述每一個數據點的圓;判斷子單元,用於判斷所述當前被考慮的數據點與所述起始點之間的線段是否與針對所述每一個數據點的圓中的至少一個圓相離;確定子單元,用於:在所述當前被考慮的數據點與所述起始點之間的線段與針對所述每一個數據點的圓中的至少一個圓相離的情況下,確定所述當前被考慮的數據點與所述起始點之間存在至少一個數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值;以及在所述當前被考慮的數據點與所述起始點之間的線段與針對所述每一個數據點的圓中的每一個圓均不相離的情況下,確定所述當前被考慮的數據點與所述起始點之間不存在數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值。
可選地,所述判斷子單元用於根據所述當前被考慮的數據點與所述起始點之間的線段方程和針對所述每一個數據點的圓中的每一個圓的方程來判斷所述當前被考慮的數據點與所述起始點之間的線段是否與針對所述每一個數據點的圓中的至少一個圓相離。
可選地,所述確定單元還用於如果所述當前被考慮的數據點與所述起始點之間不存在數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值,則將當前被考慮的數據點之前的一個相鄰的數據點確定捨棄點。
可選地,所述預定義值為2。
相應地,本發明實施例還提供一種機器可讀存儲介質,該機器可讀存儲介質上存儲有指令,該指令用於使得機器執行上述的數據壓縮方法。
通過上述技術方案,能夠實現壓縮後的相鄰數據點的數據特徵儘量不重複,從而可以在數據壓縮率和數據特徵覆蓋率之間取得很好的平衡。
本發明實施例的其它特徵和優點將在隨後的具體實施方式部分予以詳細說明。
附圖說明
附圖是用來提供對本發明實施例的進一步理解,並且構成說明書的一部分,與下面的具體實施方式一起用於解釋本發明實施例,但並不構成對本發明實施例的限制。在附圖中:
圖1示出了死區壓縮算法的原理示意圖;
圖2示出了pi的旋轉門壓縮算法的原理示意圖;
圖3示出了根據本發明一實施例的數據壓縮方法的流程示意圖;
圖4示出了根據本發明又一實施例的數據壓縮方法的流程示意圖;
圖5示出了根據本發明一實施例的數據壓縮方法的原理示意圖;
圖6示出了根據本發明一實施例的數據壓縮方法的計算示意圖;
圖7示出了本發明實施例提供的數據壓縮算法的應用示意圖;以及
圖8示出了根據本發明一實施例的數據壓縮裝置的結構框圖。
具體實施方式
以下結合附圖對本發明實施例的具體實施方式進行詳細說明。應當理解的是,此處所描述的具體實施方式僅用於說明和解釋本發明實施例,並不用於限制本發明實施例。
圖3示出了根據本發明一實施例的數據壓縮方法的流程示意圖。如圖3所示,本發明實施例提供一種數據壓縮方法,該方法可以包括以下步驟:
步驟s31,將採集的數據的採集時間和數據值映射為時間-數據值的坐標系中的數據點。
具體地,可以首先定義橫軸代表時間、縱軸代表數據值的坐標系。該坐標系例如可以以(0,0)為原點,或者可以根據需要以任意一點作為坐標原點。然後再將採集的數據的採集時間和數據值映射為所述坐標系中的數據點。這樣,所採集的每一個數據在所述坐標系中均唯一的對應一個數據點。
步驟s32,根據指定為起始點的已保存的數據點確定在採集時間上位於該已保存的數據點之後的下一個要被保存的數據點。
具體地,確定下一個要保存的數據點可以包括:按照採集時間的順序依次判斷所述起始點之後的數據點是否滿足當前被考慮的數據點與所述起始點之間存在至少一個數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值;如果所述當前被考慮的數據點與所述起始點之間存在至少一個數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值,則將當前被考慮的數據點之前的一個相鄰的數據點確定為下一個要被保存的數據點。
在所述當前被考慮的數據點與所述起始點之間存在至少一個數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值的情況下,說明當前被考慮的數據點之前的一個相鄰的數據點與相鄰數據點的數據特徵不同,需要保存,因此可以將該當前被考慮的數據點之前的一個相鄰的數據點確定為保存點。
如果所述當前被考慮的數據點與所述起始點之間不存在數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值,說明當前被考慮的數據點之前的一個相鄰的數據點與相鄰數據點的數據特徵相似,可以不保存,因此可以將當前被考慮的數據點之前的一個相鄰的數據點確定捨棄點。
其中,可以在所述坐標系中確定所述當前被考慮的數據點與所述起始點之間的線段的方程,然後根據點到直線之間的距離公式來計算數據點到線段之間的距離。
可選地,所述預定義值可以根據實際需要進行設置,例如所述預定義值可以設置為2。
可選地,可以將所採集的數據中的第一個數據確定為要保存的數據,則該要保存的數據所映射的數據點就是已保存的數據點。
步驟s33,將確定的要被保存的數據點重新指定為起始點並根據該重新指定的起始點確定在採集時間上位於該重新指定的起始點之後的下一個要被保存的數據點,直到確定出所述數據點中所有要被保存的數據點。
採用步驟s32中的具體執行方式繼續確定下一個要保存的數據點,直到確定出所述數據點中所有要被保存的數據點。
步驟s34,保存被確定要被保存的數據點。
在確定出所有要保存的數據點後,可以將確定為要保存的數據點保存,將確定為捨棄點的數據點捨棄。可選地,可以將要保存的數據點逆映射為所採集的數據,然後再進行保存。
本發明實施例提供的數據壓縮方法可以實現壓縮後的相鄰數據點的數據特徵儘量不重複,從而可以在數據壓縮率和數據特徵覆蓋率之間取得很好的平衡。
基於圖3所示的實施例,上述步驟s32可以進一步包括以下步驟:
步驟s321,針對所述當前被考慮的數據點與所述起始點之間的所有數據點中的每一個數據點,以該每一個數據點的坐標為圓心、以所述預定義值為半徑建立針對所述每一個數據點的圓。
可選地,在執行上述步驟s32時,可以針對每一個數據點以該每一個數據點的坐標為圓心、預定義值為半徑計算建立針對每一數據點的圓,例如,可以在所述坐標系中,通過計算圓的直角坐標方程來實現建立針對每一數據點的圓。
步驟s322,判斷所述當前被考慮的數據點與所述起始點之間的線段是否與針對所述每一個數據點的圓中的至少一個圓相離。
在平面中,線段與圓的位置關係可以是相離、相切或相交。
可選地,在步驟s322中可以根據所述當前被考慮的數據點與所述起始點之間的線段方程和針對所述每一個數據點的圓中的每一個圓的方程來判斷所述當前被考慮的數據點與所述起始點之間的線段是否與針對所述每一個數據點的圓中的至少一個圓相離。具體地,可以在坐標系中根據當前被考慮的數據點的坐標和起始點的坐標計算當前被考慮的數據點與所述起始點之間的線段的方程,然後將該線段的方程分別帶入上述的每一數據點的圓的方程中從而得到一個一元二次方程,通過解該一元二次方程來判斷所述位置關係,在該一元二次方程無實數解的情況下,確定參考線段與圓相離,說明圓對應的數據點到所述線段的距離大於預定義值,否則,確定線段與圓不相離,也就是說數據點到所述線段的距離不大於所述預定義值。
步驟s323,在所述當前被考慮的數據點與所述起始點之間的線段與針對所述每一個數據點的圓中的至少一個圓相離的情況下,確定所述當前被考慮的數據點與所述起始點之間存在至少一個數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值。
另一方面,在所述當前被考慮的數據點與所述起始點之間的線段與針對所述每一個數據點的圓中的至少一個圓相離的情況下,說明當前被考慮的數據點之前的一個相鄰的數據點與相鄰數據點的數據特徵不同,需要保存,因此可以將該當前被考慮的數據點之前的一個相鄰的數據點確定為保存點。
步驟s324,在所述當前被考慮的數據點與所述起始點之間的線段與針對所述每一個數據點的圓中的每一個圓均不相離的情況下,確定所述當前被考慮的數據點與所述起始點之間不存在數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值。
另一方面,在所述當前被考慮的數據點與所述起始點之間的線段與針對所述每一個數據點的圓中的每一個圓均不相離的情況下,說明當前被考慮的數據點之前的一個相鄰的數據點與相鄰數據點的數據特徵相似,可以不保存,因此可以將當前被考慮的數據點之前的一個相鄰的數據點確定捨棄點。
本發明實施例中,根據映射到坐標系中的兩個數據點之間的線段與所述起始點之間的線段與針對所述每一個數據點的圓中的每一個圓(以這個數據點作為圓心,通過擴大樣本容量而擴展出的一個圓)之間的位置關係(相離、相切或相交)來判斷當前被考慮的數據點之前的一個相鄰的數據點是否符合其相鄰數據點的特徵,實現壓縮後的相鄰數據點的數據特徵儘量不重複,從而能夠在數據壓損率和數據特徵覆蓋率上取得了一個很好的平衡。
圖5示出了根據本發明一實施例的數據壓縮方法的原理示意圖。在圖5所示的直角坐標中,原點為0,橫軸代表數據點的採集時間,縱軸代表數據點的數值,實時數據值隨著橫軸上的採集時間而在縱軸上波動。圖5中以6個數據採集點在坐標系中映射的數據點a至數據點f這6個數據點為例來對本發明實施例提供的數據壓縮算法的原理進行進一步說明,其中所述6個數據點中a點是已知保存點。
參考圖5,可以通過以下步驟來對本發明實施例提供的數據壓縮算法的原理進行說明:
步驟s51,以每個數據點為圓心,以預定義值為半徑分別建立圓針對數據點a至數據點f的圓。
步驟s52,從已知保存點a出發,向下一個數據點b連線,形成線段ab。
步驟s53,從已知保存點a出發,繼續向數據點b的下一個數據點c連線,形成線段ac。
步驟s54,判斷線段ac與已知保存點a和數據點c之間的數據點b的圓的位置關係,如果線段ac與數據點b的圓相離,則數據點b是保存點,否則,數據點b是捨棄點,從圖5中可以看出,線段ac與數據點b的圓不相離,因此,可以確定數據點b是捨棄點。
已知保存點a和數據點c之間的所有圓(數據點b的圓)相離,則當前點(數據點c)的前一個點(數據點b)需要被保存,否則從已知保存點a繼續向下一個點(數據點d)連線重複此過程(從數據點a出發繼續向數據點d連線,即線段ad。如果線段ad和數據點b的圓、數據點c的圓其中的任一相離,則數據點d的前一個數據點點即數據點c需要被保存,否則繼續從已知保存點a向下一個數據點e連線段來重複這一過程)。
步驟s55,從已知保存點a繼續向數據點c的下一個數據點d連線形成線段ad,並重複步驟s54的過程,確定線段ad與已知保存點a和數據點d之間的所有圓(數據點b和數據點c的圓)之間的位置關係。從圖5中可知,線段ad與數據點b的圓相交而非相離,並且於數據點c的圓也相交而非相離,從而可以確定出數據點d的前一數據點c是捨棄點。
步驟s56,重複步驟s54的過程,從圖5中可以確定,線段ae與數據點b的圓和與數據點c的圓均不相離,但是線段ae與數據點d的圓相離,則說明數據點d的數據特徵不同於相鄰數據點的數據特徵,因此,可以確定出數據點d為保存點。
步驟s57,從新保存的點(數據點d)出發,重複上面的步驟s51至步驟s56。
使用上述步驟一致迭代下去,就能根據數據點的採集順序的先後確定出每一數據點是保存點還是捨棄點。
圖6示出了根據本發明一實施例的數據壓縮方法的計算示意圖。在圖6所示的直角坐標中,原點為0,橫軸代表數據點的採集時間。在該實施例中預先設定的半徑值為2,圖6中數據點a為已知保存點,其是以確定下一個保存點為例說明數據壓縮方法的計算過程,具體地,本發明實施例提供的數據壓縮方法可以包括以下計算步驟:
步驟s61,確定數據點b的圓的方程:(x-10)2+(y-6)2=22,即x2+y2-20×x-12×y-4=0,其中x屬於[8,12]。
步驟s62,確定線段ac的方程:
設線段ac的方程為y=kx+b,根據下面兩個等式:
4=b,
11=k×20+b,
可知線段ac的方程為y=0.35×x+4,其中x屬於[0,20]。
步驟s63,判斷線段ac是否和圓b相交:
將線段ac的方程帶入數據點b的圓的方程,整理可得以下一元二次方程:
1.1225x2-21.4x-36=0,
一元二次方程的判別式為:(-21.4)×(-21.4)-4×1.1225×(-36)=619.6,該判別式大於0,所以可知線段ac與數據點b的圓相交。
步驟s64,繼續執行步驟s61至步驟s63可知,線段ad和數據點b的圓、數據點c的圓都相交,線段ae和數據點d的圓相離,可知數據點d的數據特徵與數據點b、c、e不同,所以數據點d為保存點。
根據保存d繼續上面的判斷過程,從而確定數據點d之後的下一保存點。使用上述步驟一致迭代下去,就能根據數據點的採集順序的先後確定出每一數據點是保存點還是捨棄點。
圖7示出了本發明實施例提供的數據壓縮算法的應用示意圖。本本發明實施例提供的數據壓縮方法已經在神華國神集團的數據採集項目中實施,在生產指揮中心部署的採集器中運行,用於安全監測實時數據和人員定位實時數據的數據壓縮。目前,採集器運行穩定,數據壓縮性能良好,根據各個測點的數據特徵分別設置各個測點的數據變化量後,各個測點的數據特徵能成功提取。
在實施過程中,合理劃分各個模塊,模塊間應用生產者-消費者模式,實現了模塊間低耦合,模塊內高內聚,其中所劃分的各模塊分別是數據獲取模塊、數據映射模塊、數據壓縮模塊、數據規約模塊、數據發送模塊以及數據緩存模塊。圖7中隊列q1至隊列q4均為時間優先的優先級隊列。參考圖7,各個模塊具體實施方式如下:
數據獲取模塊,用於將從各種數據源獲取到的實時數據分別放入到隊列q1中。
數據映射模塊,用於從隊列q1中拉取數據,將原生實時數據映射成按測點分類的實時數據,並分別放入隊列q2中。
數據壓縮模塊,用於從隊列q2中拉取數據,按照本發明實施例提供的數據壓縮方法壓縮實時數據,並將壓縮後的實時數據分別放入隊列q3中。
數據規約模塊,用於從隊列q3中拉取數據,執行數據映射的逆過程,即數據規約,獲得按時間點分類的分批實時數據並將其放入隊列q4中。
數據發送模塊,用於從隊列q4中拉取數據,異步發送至數據服務端。
數據緩存模塊,用於在數據發送模塊中註冊回調函數,根據異步發送的響應和緩存策略,緩存相應的實時數據。
圖8示出了根據本發明一實施例的數據壓縮裝置的結構框圖。如圖8所示,本發明實施例還提供一種數據壓縮裝置,該裝置可以包括:映射模塊81,用於將採集的數據的採集時間和數據值映射為時間-數據值的坐標系中的數據點;第一確定模塊82,用於根據指定為起始點的已保存的數據點確定在採集時間上位於該已保存的數據點之後的下一個要被保存的數據點;第二確定模塊83,用於將確定的要被保存的數據點重新指定為起始點並根據該重新指定的起始點確定在採集時間上位於該重新指定的起始點之後的下一個要被保存的數據點,直到確定出所述數據點中所有要被保存的數據點;以及保存模塊84,用於保存被確定要被保存的數據點;其中,所述第一確定模塊82包括:判斷單元821,用於按照採集時間的順序依次判斷所述起始點之後的數據點是否滿足當前被考慮的數據點與所述起始點之間存在至少一個數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值;確定單元822,用於如果所述當前被考慮的數據點與所述起始點之間存在至少一個數據點到當前被考慮的數據點與所述起始點之間的線段的距離超過預定義值,則將當前被考慮的數據點之前的一個相鄰的數據點確定為下一個要被保存的數據點。本發明實施例提供的數據壓縮裝置可以實現壓縮後的相鄰數據點的數據特徵儘量不重複,從而可以在數據壓縮率和數據特徵覆蓋率之間取得很好的平衡。
本發明實施例提供的數據壓縮裝置的具體工作原理及益處與上述本發明實施例提供的數據壓縮方法的具體工作原理及益處相似,這裡將不再贅述。
相應的,本發明提供一種機器可讀存儲介質,該機器可讀存儲介質上存儲有指令,該指令用於使得機器執行本申請上述的數據壓縮方法。
以上結合附圖詳細描述了本發明例的可選實施方式,但是,本發明實施例並不限於上述實施方式中的具體細節,在本發明實施例的技術構思範圍內,可以對本發明實施例的技術方案進行多種簡單變型,這些簡單變型均屬於本發明實施例的保護範圍。
另外需要說明的是,在上述具體實施方式中所描述的各個具體技術特徵,在不矛盾的情況下,可以通過任何合適的方式進行組合。為了避免不必要的重複,本發明實施例對各種可能的組合方式不再另行說明。
本領域技術人員可以理解實現上述實施例方法中的全部或部分步驟是可以通過程序來指令相關的硬體來完成,該程序存儲在一個存儲介質中,包括若干指令用以使得一個(可以是單片機,晶片等)或處理器(processor)執行本申請各個實施例所述方法的全部或部分步驟。而前述的存儲介質包括:u盤、移動硬碟、只讀存儲器(rom,read-onlymemory)、隨機存取存儲器(ram,randomaccessmemory)、磁碟或者光碟等各種可以存儲程序代碼的介質。
此外,本發明實施例的各種不同的實施方式之間也可以進行任意組合,只要其不違背本發明實施例的思想,其同樣應當視為本發明實施例所公開的內容。