基於完備局部二值模式重構殘差的煤巖識別方法與流程
2023-10-05 15:03:44 5
本發明涉及基於完備局部二值模式重構殘差的煤巖識別方法,屬於圖像識別技術領域。
背景技術:
煤巖識別是指通過各種技術手段自動判別煤炭和巖石。在煤炭資源開採及運輸過程中,存在許多生產環節需要判別區分煤炭和巖石,如採煤機滾筒高度調節、綜採放頂煤過程控制、選煤廠原煤選矸等。從20世紀50年代開始,南非、澳大利亞、德國、美國、中國等世界主要產煤國家對煤巖識別方法展開了一系列研究,相繼產生了一些代表性的研究成果,如自然γ射線探測法、雷達探測法、紅外探測法、有功功率檢測法、振動信號檢測法、聲音信號檢測法等。然而這些方法均存在以下共性問題:(1)需要在現有設備上安裝部署各種傳感器,相關裝置結構複雜,製造成本高;(2)採煤機、掘進機等機械設備在煤炭生產過程中受力複雜、振動劇烈、磨損嚴重,傳感器部署相對比較困難,其電子線路也容易受到損壞,裝置可靠性差;(3)針對不同類型的機械載體設備,傳感器的選型和安裝位置的選擇存在較大區別,這就需要進行個性化定製,因此其普適性不佳。
通過對塊狀的煤炭、巖石樣本的觀察,發現煤炭和巖石在顏色、光澤、紋理等方面存在較大差異。當通過現有的數字攝像機對煤炭和巖石進行成像時,煤炭和巖石的視覺信息就必然會隱藏在採集得到的數字圖像中,因此提出通過挖掘煤巖數字圖像中的視覺信息來區分煤炭和巖石。現有的基於圖像處理的煤巖識別方法在魯棒性、識別率等方面還存在著較大的提升空間。
技術實現要素:
為了克服現有煤巖識別方法存在的不足,本發明提出基於完備局部二值模式重構殘差的煤巖識別方法,該方法具有實時性強、識別率高、穩健性好等優點,有助於提高現代煤礦的生產效率和安全程度。
本發明所述的煤巖識別方法採用如下技術方案實現,包括樣本訓練階段和煤巖識別階段,具體步驟如下:
rs1.在樣本訓練階段,採集m幅煤炭樣本圖像和m幅巖石樣本圖像,截取不含非煤巖背景的子圖並對它們進行灰度化處理,處理後的煤炭樣本子圖和巖石樣本子圖分別記為c1,c2,…,cm和s1,s2,…,sm;
rs2.設定採樣半徑r=1和採樣鄰域數p=8,分別提取c1,c2,…,cm和s1,s2,…,sm的帶有旋轉不變特性和均勻特性的歸一化完備局部二值模式特徵行向量y1,y2,…,ym∈r1×200和z1,z2,…,zm∈r1×200;
rs3.設定採樣半徑r=2和採樣鄰域數p=16,分別提取c1,c2,…,cm和s1,s2,…,sm的帶有旋轉不變特性和均勻特性的歸一化完備局部二值模式特徵行向量α1,α2,…,αm∈r1×648和β1,β2,…,βm∈r1×648;
rs4.設定採樣半徑r=3和採樣鄰域數p=24,分別提取c1,c2,…,cm和s1,s2,…,sm的帶有旋轉不變特性和均勻特性的歸一化完備局部二值模式特徵行向量η1,η2,…,ηm∈r1×1352和μ1,μ2,…,μm∈r1×1352;
rs5.分別構建c1,c2,…,cm和s1,s2,…,sm的最終特徵列向量x1=[y1,α1,η1]t,x2=[y2,α2,η2]t,…,xm=[ym,αm,ηm]t∈r2200×1和xm+1=[z1,β1,μ1]t,xm+2=[z2,β2,μ2]t,…,x2m=[zm,βm,μm]t∈r2200×1,其中t為轉置運算;
rs6.分別構建煤炭訓練樣本特徵矩陣xc=[x1,x2,…,xm]∈r2200×m和巖石訓練樣本特徵矩陣xs=[xm+1,xm+2,…,x2m]∈r2200×m;
rs7.設置正則化參數λ1,λ2,迭代次數k和字典原子數τ,其中0<λ1<1,0<λ2<1,15≤k≤50,0<τ≤m,對xc和xs進行判別式字典學習,得到煤炭類別綜合型字典dc、巖石類別綜合型字典ds、煤炭類別解析型字典tc和巖石類別解析型字典ts;
rs8.在煤巖識別階段,採集未知類別樣本圖像,截取不含非煤巖背景的子圖並對它進行灰度化處理,處理後的未知類別子圖記為q;
rs9.設定採樣半徑r=1和採樣鄰域數p=8,提取q的帶有旋轉不變特性和均勻特性的歸一化完備局部二值模式特徵行向量vq∈r1×200;
rs10.設定採樣半徑r=2和採樣鄰域數p=16,提取q的帶有旋轉不變特性和均勻特性的歸一化完備局部二值模式特徵行向量δq∈r1×648;
rs11.設定採樣半徑r=3和採樣鄰域數p=24,提取q的帶有旋轉不變特性和均勻特性的歸一化完備局部二值模式特徵行向量θq∈r1×1352;
rs12.構建q的最終特徵列向量xq=[vq,δq,θq]t∈r2200×1,其中t為轉置運算;
rs13.如果滿足||xq-dctcxq||2≤||xq-dstsxq||2,那麼判定q為煤炭;否則,判定q為巖石,其中||·||2為向量的2–範數。
步驟rs7所述的判別式字典學習包括以下步驟:
rs701.從xc中隨機地抽取τ列構建煤炭類別綜合型字典dc∈r2200×τ,從xs中隨機地抽取τ列構建巖石類別綜合型字典ds∈r2200×τ,從xc中隨機地抽取τ列再通過轉置運算構建煤炭類別解析型字典tc∈rτ×2200,從xs中隨機地抽取τ列再通過轉置運算構建巖石類別解析型字典ts∈rτ×2200,然後分別對dc,ds,tc和ts進行逐列歸一化處理;
rs702.構建數據矩陣qc∈r2200×2200並通過qc=(λ1xcxct+λ2xsxst+0.00001i2200)-1初始化,構建數據矩陣qs∈r2200×2200並通過qs=(λ1xsxst+λ2xcxct+0.00001i2200)-1初始化,其中i2200為2200階單位矩陣,t為轉置運算,–1為求逆運算;
rs703.構建煤炭樣本稀疏編碼矩陣uc∈rτ×m並通過uc=(dctdc+λ1iτ)-1(dct+λ1tc)xc初始化,構建巖石樣本稀疏編碼矩陣us∈rτ×m並通過us=(dstds+λ1iτ)-1(dst+λ1ts)xs初始化,其中t為轉置運算,–1為求逆運算,iτ為τ階單位矩陣;
rs704.定義迭代序號b並初始化為0;
rs705.通過tc=λ1ucxctqc更新tc,通過ts=λ1usxstqs更新ts;
rs706.把數學描述為
的優化問題記為problem1,用problem1的解d*∈r2200×τ更新dc,其中||·||f為矩陣的frobenius範數,||·||2為向量的2–範數,為d*的第i列,i為d*的列標號,i=1,2,…,τ;
rs707.把數學描述為
的優化問題記為problem2,用problem2的解更新ds,其中||·||f為矩陣的frobenius範數,||·||2為向量的2–範數,為的第j列,j為的列標號,j=1,2,…,τ;
rs708.分別通過uc=(dctdc+λ1iτ)-1(λ1tc+dct)xc和us=(dstds+λ1iτ)-1(λ1ts+dst)xs更新uc和us,其中t為轉置運算,–1為求逆運算,iτ為τ階單位矩陣;
rs709.迭代序號b自增1;
rs710.如果滿足b<k,那麼執行步驟rs705–rs710;否則,執行步驟rs711;
rs711.完成字典學習,輸出dc,ds,tc和ts。
步驟rs706所述problem1的求解包括以下步驟:
rs70601.定義變量ε1並初始化為1.000,構建數據矩陣d*∈r2200×τ並通過d*=dc初始化;
rs70602.構建臨時數據矩陣a1∈r2200×τ並通過a1=dc初始化,構建臨時數據矩陣b1∈r2200×τ並初始化為零矩陣,構建臨時數據矩陣h1∈r2200×τ並初始化為零矩陣;
rs70603.通過h1=[xcuct+ε1(a1-b1)](ucuct+ε1iτ)-1更新h1,其中iτ為τ階單位矩陣,t為轉置運算,–1為求逆運算;
rs70604.通過a1=b1+h1更新a1;
rs70605.對a1中2–範數大於1的列進行2–範數歸一化處理;
rs70606.用(b1+h1-a1)的計算結果更新b1;
rs70607.用(1.25×ε1)的計算結果更新ε1;
rs70608.若滿足其中||·||f為矩陣的frobenius範數,則用h1的值更新d*,然後執行步驟rs70603–rs70608;否則,用h1的值更新d*,然後執行步驟rs70609;
rs70609.完成problem1的求解,返回problem1的解d*。
步驟rs707所述problem2的求解包括以下步驟:
rs70701.定義變量ε2並初始化為1.000,構建數據矩陣並通過初始化;
rs70702.構建臨時數據矩陣a2∈r2200×τ並通過a2=ds初始化,構建臨時數據矩陣b2∈r2200×τ並初始化為零矩陣,構建臨時數據矩陣h2∈r2200×τ並初始化為零矩陣;
rs70703.通過h2=[xsust+ε2(a2-b2)](usust+ε2iτ)-1更新h2,其中iτ為τ階單位矩陣,t為轉置運算,–1為求逆運算;
rs70704.通過a2=b2+h2更新a2;
rs70705.對a2中2–範數大於1的列進行2–範數歸一化處理;
rs70706.用(b2+h2-a2)的計算結果更新b2;
rs70707.用(1.25×ε2)的計算結果更新ε2;
rs70708.若滿足其中||·||f為矩陣的frobenius範數,則用h2的值更新然後執行步驟rs70703–rs70708;否則,用h2的值更新然後執行步驟rs70709;
rs70709.完成problem2的求解,返回problem2的解
附圖說明
圖1是基於完備局部二值模式重構殘差的煤巖識別方法的基本流程圖;
圖2是本發明所述判別式字典學習的基本流程圖;
圖3是本發明所述求problem1的解d*的基本流程圖;
圖4是本發明所述求problem2的解的基本流程圖;
具體實施方式
在對我國河南、山西、陝西等地主要煤種和巖種的圖像進行實驗分析的基礎上,本發明提出了基於完備局部二值模式重構殘差的煤巖識別方法,該方法可以有效判別煤炭和巖石。
下面結合附圖和具體實施方式對本發明作進一步的詳細描述。
參照圖1,基於完備局部二值模式重構殘差的煤巖識別方法的具體步驟如下:
ss1.在樣本訓練階段,採集m幅煤炭樣本圖像和m幅巖石樣本圖像,截取不含非煤巖背景的子圖並對它們進行灰度化處理,處理後的煤炭樣本子圖和巖石樣本子圖分別記為c1,c2,…,cm和s1,s2,…,sm;
ss2.設定採樣半徑r=1和採樣鄰域數p=8,分別提取c1,c2,…,cm和s1,s2,…,sm的帶有旋轉不變特性和均勻特性的歸一化完備局部二值模式特徵行向量y1,y2,…,ym∈r1×200和z1,z2,…,zm∈r1×200;
ss3.設定採樣半徑r=2和採樣鄰域數p=16,分別提取c1,c2,…,cm和s1,s2,…,sm的帶有旋轉不變特性和均勻特性的歸一化完備局部二值模式特徵行向量α1,α2,…,αm∈r1×648和β1,β2,…,βm∈r1×648;
ss4.設定採樣半徑r=3和採樣鄰域數p=24,分別提取c1,c2,…,cm和s1,s2,…,sm的帶有旋轉不變特性和均勻特性的歸一化完備局部二值模式特徵行向量η1,η2,…,ηm∈r1×1352和μ1,μ2,…,μm∈r1×1352;
ss5.分別構建c1,c2,…,cm和s1,s2,…,sm的最終特徵列向量x1=[y1,α1,η1]t,x2=[y2,α2,η2]t,…,xm=[ym,αm,ηm]t∈r2200×1和xm+1=[z1,β1,μ1]t,xm+2=[z2,β2,μ2]t,…,x2m=[zm,βm,μm]t∈r2200×1,其中t為轉置運算;
ss6.分別構建煤炭訓練樣本特徵矩陣xc=[x1,x2,…,xm]∈r2200×m和巖石訓練樣本特徵矩陣xs=[xm+1,xm+2,…,x2m]∈r2200×m;
ss7.設置正則化參數λ1,λ2,迭代次數k和字典原子數τ,其中0<λ1<1,0<λ2<1,15≤k≤50,0<τ≤m,對xc和xs進行判別式字典學習,得到煤炭類別綜合型字典dc、巖石類別綜合型字典ds、煤炭類別解析型字典tc和巖石類別解析型字典ts;
ss8.在煤巖識別階段,採集未知類別樣本圖像,截取不含非煤巖背景的子圖並對它進行灰度化處理,處理後的未知類別子圖記為q;
ss9.設定採樣半徑r=1和採樣鄰域數p=8,提取q的帶有旋轉不變特性和均勻特性的歸一化完備局部二值模式特徵行向量vq∈r1×200;
ss10.設定採樣半徑r=2和採樣鄰域數p=16,提取q的帶有旋轉不變特性和均勻特性的歸一化完備局部二值模式特徵行向量δq∈r1×648;
ss11.設定採樣半徑r=3和採樣鄰域數p=24,提取q的帶有旋轉不變特性和均勻特性的歸一化完備局部二值模式特徵行向量θq∈r1×1352;
ss12.構建q的最終特徵列向量xq=[vq,δq,θq]t∈r2200×1,其中t為轉置運算;
ss13.如果滿足||xq-dctcxq||2≤||xq-dstsxq||2,那麼判定q為煤炭;否則,判定q為巖石,其中||·||2為向量的2–範數。
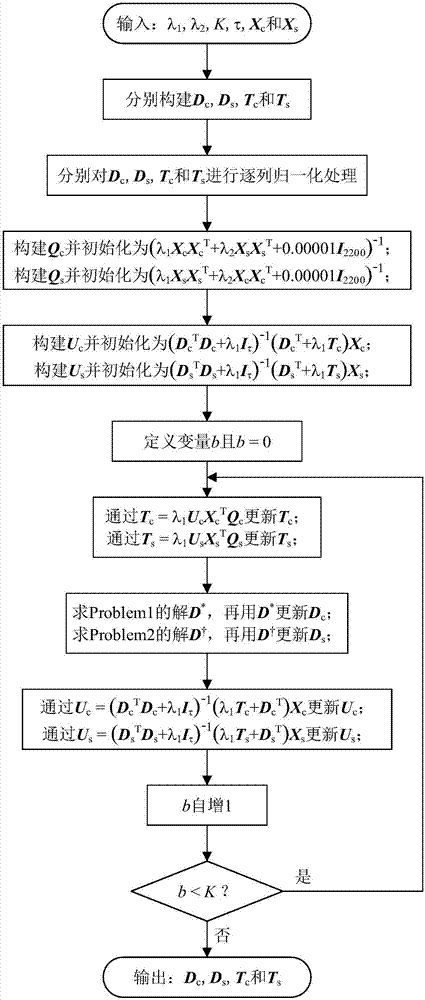
參照圖2,步驟ss7所述的判別式字典學習的具體步驟如下:
ss701.從xc中隨機地抽取τ列構建煤炭類別綜合型字典dc∈r2200×τ,從xs中隨機地抽取τ列構建巖石類別綜合型字典ds∈r2200×τ,從xc中隨機地抽取τ列再通過轉置運算構建煤炭類別解析型字典tc∈rτ×2200,從xs中隨機地抽取τ列再通過轉置運算構建巖石類別解析型字典ts∈rτ×2200,然後分別對dc,ds,tc和ts進行逐列歸一化處理;
ss702.構建數據矩陣qc∈r2200×2200並通過qc=(λ1xcxct+λ2xsxst+0.00001i2200)-1初始化,構建數據矩陣qs∈r2200×2200並通過qs=(λ1xsxst+λ2xcxct+0.00001i2200)-1初始化,其中i2200為2200階單位矩陣,t為轉置運算,–1為求逆運算;
ss703.構建煤炭樣本稀疏編碼矩陣uc∈rτ×m並通過uc=(dctdc+λ1iτ)-1(dct+λ1tc)xc初始化,構建巖石樣本稀疏編碼矩陣us∈rτ×m並通過us=(dstds+λ1iτ)-1(dst+λ1ts)xs初始化,其中t為轉置運算,–1為求逆運算,iτ為τ階單位矩陣;
ss704.定義迭代序號b並初始化為0;
ss705.通過tc=λ1ucxctqc更新tc,通過ts=λ1usxstqs更新ts;
ss706.把數學描述為
的優化問題記為problem1,用problem1的解d*∈r2200×τ更新dc,其中||·||f為矩陣的frobenius範數,||·||2為向量的2–範數,為d*的第i列,i為d*的列標號,i=1,2,…,τ;
ss707.把數學描述為
的優化問題記為problem2,用problem2的解更新ds,其中||·||f為矩陣的frobenius範數,||·||2為向量的2–範數,為的第j列,j為的列標號,j=1,2,…,τ;
ss708.分別通過uc=(dctdc+λ1iτ)-1(λ1tc+dct)xc和us=(dstds+λ1iτ)-1(λ1ts+dst)xs更新uc和us,其中t為轉置運算,–1為求逆運算,iτ為τ階單位矩陣;
ss709.迭代序號b自增1;
ss710.如果滿足b<k,那麼執行步驟ss705–ss710;否則,執行步驟ss711;
ss711.完成字典學習,輸出dc,ds,tc和ts。
參照圖3,求步驟ss706所述problem1的解d*的具體步驟如下:
ss70601.定義變量ε1並初始化為1.000,構建數據矩陣d*∈r2200×τ並通過d*=dc初始化;
ss70602.構建臨時數據矩陣a1∈r2200×τ並通過a1=dc初始化,構建臨時數據矩陣b1∈r2200×τ並初始化為零矩陣,構建臨時數據矩陣h1∈r2200×τ並初始化為零矩陣;
ss70603.通過h1=[xcuct+ε1(a1-b1)](ucuct+ε1iτ)-1更新h1,其中iτ為τ階單位矩陣,t為轉置運算,–1為求逆運算;
ss70604.通過a1=b1+h1更新a1;
ss70605.對a1中2–範數大於1的列進行2–範數歸一化處理;
ss70606.用(b1+h1-a1)的計算結果更新b1;
ss70607.用(1.25×ε1)的計算結果更新ε1;
ss70608.若滿足其中||·||f為矩陣的frobenius範數,則用h1的值更新d*,然後執行步驟ss70603–ss70608;否則,用h1的值更新d*,然後執行步驟ss70609;
ss70609.完成problem1的求解,返回problem1的解d*。
參照圖4,求步驟ss707所述problem2的的解的具體步驟如下:
ss70701.定義變量ε2並初始化為1.000,構建數據矩陣並通過初始化;
ss70702.構建臨時數據矩陣a2∈r2200×τ並通過a2=ds初始化,構建臨時數據矩陣b2∈r2200×τ並初始化為零矩陣,構建臨時數據矩陣h2∈r2200×τ並初始化為零矩陣;
ss70703.通過h2=[xsust+ε2(a2-b2)](usust+ε2iτ)-1更新h2,其中iτ為τ階單位矩陣,t為轉置運算,–1為求逆運算;
ss70704.通過a2=b2+h2更新a2;
ss70705.對a2中2–範數大於1的列進行2–範數歸一化處理;
ss70706.用(b2+h2-a2)的計算結果更新b2;
ss70707.用(1.25×ε2)的計算結果更新ε2;
ss70708.若滿足其中||·||f為矩陣的frobenius範數,則用h2的值更新然後執行步驟ss70703–ss70708;否則,用h2的值更新然後執行步驟ss70709;
ss70709.完成problem2的求解,返回problem2的解
需要指出的是,以上所述實施實例用於進一步說明本發明,實施實例不應被視為限制本發明的範圍。