程序猿細說GTX680如何100萬線程代碼!
2024-12-16 15:19:09 1
泡泡網顯卡頻道8月10日 自從NV開放 4GB版本的GTX680之後,所有遊戲都阻止不了GTX680了。除了遊戲,我們還有什麼點子可以發揮這塊單晶片神卡的威力呢?沒錯,就是通用運算技術CUDA!高性能運算,複雜的物理運算和人工智慧仿真等等的如果只用CPU運行,估計6核的Ivy Bridge也夠嗆的了。即使啟動了超線程技術,也只能硬體上實現12線程。對於動輒上千ALU的GPU來說,這只能是小菜一碟。另外,還有一個巨大的線程切換差異,就是說CPU多線程切換需要上千時鐘周期,而GPU則只需要個位數的時鐘周期。
這就為什麼GPU隱藏著巨大的能量。NVIDIA很聰明地看到了這塊市場的契機。Fermi的設計創新性地加入了和處理器一樣的統一讀寫二級緩存,隨後GK104更把底層的SMX進行變革。下面我們通過技術宅男玩家為我們展開一場奇幻的CUDA旅行。當然,主角是當下性能極其強悍的GTX680 4GB。

據說,技術宅的廁紙用完了之後就會用書本。

技術宅受到刺激後,迷上了超大規模程序設計,那個叫什麼CUDA神秘兮兮的東西。

平臺豔照

那個神秘兮兮的CUDA的環境配置。1安裝CUDA工具箱,第二步安裝顯卡驅動,第三步安裝CUDA SDK。前兩步必不可少,第三步可以預設。
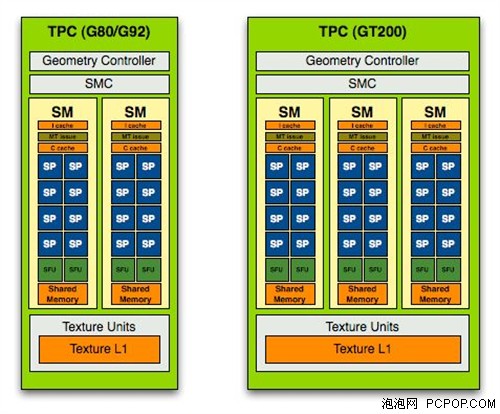
技術宅幫我們複習一下,G80和GT200的SM架構。這種差異導致了CUDA程序上的不同優化。
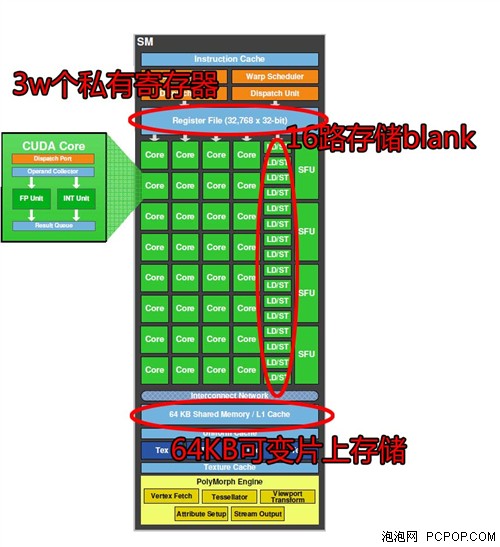
好了,老架構的不花時間去討論,直奔最近在通用計算大放異彩的費米架構。技術宅說它革命性地加入了讀寫統一的1,2級緩存。親,這是模仿CPU的設計嗎?下面結合硬體來說說CUDA是如何根據它來優化。SM擁有3萬個高速寄存器!天哪,8核CPU的不過百的寄存器情何以堪!難怪線程切換的速度如此之快。16路高速存儲通道來並行操作64KB的片上高速緩存,速度達到1TB/s的級別!
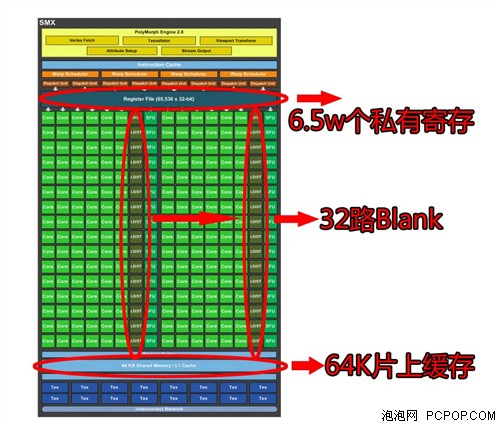
克卜勒再度加強,在電晶體數量控制在30億的情況下竟然設計出比費米多100%的CUDA核心。從SMX架構上可以到處,要以往 CUDA程序為克卜勒優化,首要任務是讓block裡面的線程儘量地多。GT200 SM允許活動線程是1024個,費米優化的代碼可以增加到1536個線程,而克卜勒更爆增到2048個活動線程(註:規格上和GK110一樣)。
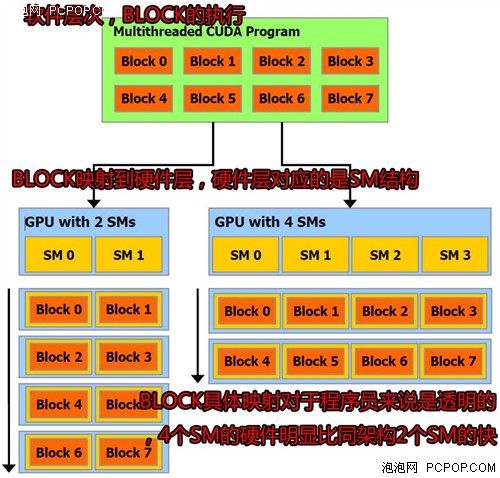
這個是軟體層次對應的硬體層次。BLOCK編程上的線程塊,它們是分時在SM裡運行,一個CUDA程序會有多個blcok並行運行,而每個block就是說線程塊又包含了舒數十到上百的線程組成。也就構成了CUDA。
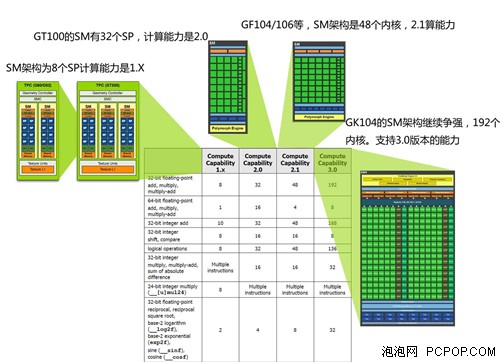
架構的不同對應不同的計算規格。3代運算架構,對用不同的支持。代碼優化可以適當對不同特徵進行優化。譬如克卜勒等硬體可以支持更大的block內部線程,因此可以支持更多的線程進行片上的同步工作。另外譬如Fermi和克卜勒有DRAM緩存,所以對DRAM優化的力度沒有G80那麼吃力。
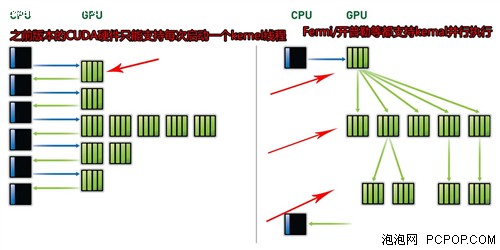
克卜勒在CUDA上加入了更大的革新。就是支持多內核函數的並行執行。注意一個CUDA內核就是一個可具備百萬線程的並行程序,而這些內核函數更可以並行執行。









