一種面向中文人物關係網絡的實體關係聯合抽取方法與流程
2024-04-16 12:52:05 4
1.本發明涉及涉及自然語言信息抽取領域,更具體地說,涉及一種面向中文人物關係網絡的實體關係聯合抽取方法。
背景技術:
2.隨著網際網路技術的高速發展,網際網路中的數據量也在飛速增長,面對海量數據,人們要求獲取到的信息更加簡潔準確,而網際網路中存在的大量人物關係數據是由非結構化的語料來表達的,知識抽取難度較大,針對海量非結構化文本數據,高效而又簡潔的知識抽取方法顯得尤為重要。
3.現有技術中存在一些實體關係抽取方法:
4.1.基於管道模型(pipeline)的知識抽取方法:管道模型把實體關係抽取分成兩個子任務,實體識別和關係分類,兩個子任務按照順序依次執行,之間沒有交互。兩個模型靈活性高,實體與關係模型可以使用獨立的數據集,並不需要同時標註實體和關係的數據集。
5.2.基於聯合模型(joint)的知識抽取方法:上述方式會降低實體與關係之間的關聯性且存在誤差累積問題,而以tplinker模型為代表的聯合抽取方式直接抽取實體與關係,降低可能存在的累積誤差,但過高的模型複雜度,可能受計算機內存上的限制,導致模型訓練過慢。
6.現如今,隨著網絡技術的發展,人們更習慣使用網絡來獲取信息和交流溝通,人物關係網越發龐大,對獲取信息的精確度需求也越來越高。龐大的人物社交網絡中存在大量的語義信息,而傳統的搜尋引擎逐漸不能滿足人們高效精準的檢索需求,局限性主要存在於檢索結果需要手動分析篩選,並且在檢索過程中沒有關注語句的語義信息,導致效果不理想。
7.為了解決上述問題,知識庫的信息檢索方式被提出,知識庫形式多樣,知識圖譜以三元組的方式存儲海量信息,能夠幫助計算機理解用戶需求,高效精確的返回答案。而信息抽取是構建大規模知識圖譜的必備關鍵,如何從海量的非結構化文本中,快速精確的抽取大量人物關係數據變得尤為重要。
技術實現要素:
8.本發明所要解決的技術問題是針對背景技術的不足提供一種對海量非結構化中文文本快速準確的抽取人物相關三元組關係的方法,幫助構建中文人物關係知識庫,向用戶推送更加準確的信息。
9.本發明為解決上述技術問題採用以下技術方案:
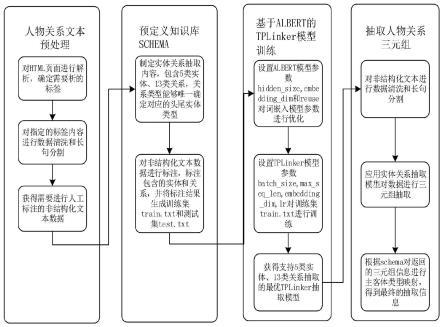
10.一種面向中文人物關係網絡的實體關係聯合抽取方法,包含人物關係文本預處理、預定義知識庫schema、基於輕量級的詞嵌入模型albert的tplinker模型訓練、人物關係三元組抽取四部分;
11.其中,基於albert的tplinker模型訓練,具體包含如下步驟:
12.步驟c1,設置隱含層數hidden_size,向量維度embedding_dim,跨層共享參數標識reuse;albert將使用以下步驟對詞嵌入模型參數進行優化:
13.步驟c11,對詞嵌入參數進行因式分解,albert採用因式分解的方法來降低bert算法的參數量,針對大小為v的詞彙表,它認為embedding_dim《《hiddern_size,故albert算法首先把one-hot向量映射到一個大小為e的低尺寸的向量空間,然後再將其投影到h大小的隱藏空間中,即o(v
×
h)轉換成o(v
×
e+e
×
h),
14.其中,e就是embedding_dim的大小,h為hidden_size的大小,v是詞表的大小,是詞嵌入模型所有詞彙的個數;一般設置embedding_dim=128,hidden_size=768;
15.步驟c12,跨層的參數共享cross-layerparameter sharing,對bert算法的全連接層與注意力層都進行參數共享,即共享編碼器內的所有參數,通過設置reuse=true開啟跨層參數共享,以此減少模型參數;其中,reuse為跨層共享參數標識;
16.步驟c2,初始化嵌入層模型參數:當前數據批次大小batch_size,最大序列長度max_seq_len,向量維度embedding_dim,根據albert算法輸出當前批次的詞嵌入向量,步驟如下;
17.步驟c21,將輸入序列轉換成向量作為嵌入層模型輸入,向量表達式為:
18.x
embedding
=token
embedding
+segnent
embedding
+position
embedding
19.其中,token
embedding
是當前token的詞向量,segment
embedding
表明當前詞屬於哪個句子,position
embedding
為學習到的位置編碼;
20.步驟c22,注意力機制進行特徵提取,表達式為:
[0021][0022]
其中,q、k、v是詞向量矩陣,dk為向量維度;
[0023]
步驟c23,特徵輸出,得到輸入序列的詞嵌入表示,表達式為:
[0024]
x
attention
=layernorm(x+x
attention
)
[0025]
x
hidden
=activate(linear(linear(x
attention
)))
[0026]
其中,layernorm為歸一化函數,linear為全連接層,activate為relu激活函數;
[0027]
步驟c3,設置tplinker算法的模型參數,學習因子lr,訓練迭代次數epoch和向量維度embedding_dim,數據批次大小batch_size,滑動塊大小sliding_len,tplinker對詞嵌入向量進行編碼操作。
[0028]
作為本發明一種面向中文人物關係網絡的實體關係聯合抽取方法的進一步優選方案,所述步驟c3具體如下:
[0029]
步驟c31,token詞對的表示法:
[0030]
給定一個長度為n的句子[w1,
…
,wn],通過一個基本編碼器將每個wi映射成一個低維的上下文向量hi;wi為句子的第i個字符token;
[0031]
為token對(wi,wj)生成一個表示法h
ij
,如下所示;
[0032]hi,j
=tanh(wh[hi;hj]+bh)j≥i
[0033]
其中,wh是一個參數矩陣,bh是在訓練過程中要學習的一個bias向量;
[0034]
步驟c32,握手標記器:
[0035]
給定一個標註對代表h
ij
,標註對(wi,wj)的連結標籤由以下表達式預測;
[0036]
p(y
i;j
)=softmax(wo*h
i,j
+bo)
[0037]
link(wi,wj)=argmaxp(y
i;j
=l)
[0038]
其中,p(y
i;j
=l)代表識別(wi,wj)的連結為l的概率;
[0039]
步驟c33,採用人工標註之後的訓練集對tplinker模型進行模型訓練,得到最優的tplinker實體關係抽取模型。
[0040]
作為本發明一種面向中文人物關係網絡的實體關係聯合抽取方法的進一步優選方案,所述人物關係文本預處理,具體如下:
[0041]
步驟a1,對html頁面進行解析,根據網頁特徵分析,對於百科人物信息,需要解析的是基本信息、人物關係、早年經歷、個人生活多個網頁標籤;
[0042]
其中,基本信息屬於半結構化數據,經整理為三元組可存為知識庫;
[0043]
步驟a2,數據預處理包括數據清洗和長句處理,結構化、半結構化數據經清洗可存為知識庫,長句處理是利用語言技術平臺ltp工具是對人物關係、個人生活等語料進行長句分割、指代消解、語句標註工作。
[0044]
作為本發明一種面向中文人物關係網絡的實體關係聯合抽取方法的進一步優選方案,所述步驟a2流程具體如下:
[0045]
步驟a21,根據特殊分隔符,將預料分為短句,使用ltp的分詞函數segmentor.segment進行分詞;詞性標註函數postagger.postag對分詞短句進行詞性標註;
[0046]
步驟a22,對語料進行依存句法分析,若結果沒有主謂依存關係sbv,則在句首添加人物作為主語;若存在主謂依存關係sbv,但標註的主語是人稱代詞,則轉換為人物名稱。
[0047]
作為本發明一種面向中文人物關係網絡的實體關係聯合抽取方法的進一步優選方案,所述預定義知識庫schema,具體如下:
[0048]
步驟b1,制定人物關係網絡包含的實體、關係類型;
[0049]
實體類型包含:人物、地址、機關單位、企業機構、學校;
[0050]
關係類型包含:父親、母親、兒子、女兒、丈夫、妻子、籍貫、出生地、工作地、任職單位、任職機構、畢業院校、工作院校;
[0051]
步驟b2,對預處理後的文本語料進行人工標註,分別標註包含的實體與關係,並將標註結果的80%作為訓練集,20%作為驗證集。
[0052]
作為本發明一種面向中文人物關係網絡的實體關係聯合抽取方法的進一步優選方案,所述人物關係三元組抽取,具體如下:
[0053]
步驟d1,對html頁面進行解析,對基本信息、人物關係、早年經歷、個人生活等多個標籤內容進行解析,並對其進行數據清洗和長句處理,將處理之後的文本輸入到albert詞嵌入層,進而生成對應的詞嵌入表示並將其作為抽取模型的輸入;
[0054]
步驟d2,使用最優模型對非結構化文本進行抽取,由於原始模型在抽取時,不能提取到三元組中頭尾實體的類型,使用預定義的知識庫schema信息對抽取的三元組進行頭為實體類型映射,得到包含頭尾實體類型的三元組信息。
[0055]
本發明採用以上技術方案與現有技術相比,具有以下技術效果:
[0056]
本發明一種對海量非結構化中文文本快速準確的抽取人物相關三元組關係的方
法,幫助構建中文人物關係知識庫,向用戶推送更加準確的信息;針對tplinker模型存在大量參數,而在海量數據訓練過程中達到內存限制,導致訓練過慢等問題,做出了以下改進;採用預訓練的albert詞嵌入向量作為模型的詞嵌入層輸入,它設計了參數減少的方法,用來降低內存消耗,同時加快模型的訓練速度;對於tplinker算法在解碼時無法輸出三元組頭尾實體類型的問題,採用預定義知識庫schema的方式解決該問題。
附圖說明
[0057]
圖1是本發明基於albert的tplinker的實體關係抽取方法流程圖;
[0058]
圖2是本發明基於albert的tplinker實體關係聯合抽取方法流程圖。
具體實施方式
[0059]
下面結合附圖對本發明的技術方案做進一步的詳細說明:
[0060]
下面將結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。基於本發明中的實施例,本領域普通技術人員在沒有做出創造性勞動前提下所獲得的所有其他實施例,都屬於本發明保護的範圍。
[0061]
如圖1所示,包含人物關係文本預處理、預定義知識庫schema、基於albert(alite bert,輕量級的詞嵌入模型)的tplinker(token pair linker,詞對連結)模型訓練、人物關係三元組抽取四部分具體如下:
[0062]
人物關係文本預處理:
[0063]
步驟a1,對html頁面進行解析,根據網頁特徵分析,對於百科人物信息,需要解析的是基本信息、人物關係、早年經歷、個人生活等多個網頁標籤。
[0064]
其中,基本信息屬於半結構化數據,經整理為三元組可存為知識庫;
[0065]
步驟a2,數據預處理包括數據清洗和長句處理,結構化、半結構化數據經清洗可存為知識庫,長句處理是利用ltp(language technology platform,語言技術平臺)工具是對人物關係、個人生活等語料進行長句分割、指代消解、語句標註工作,流程如下:
[0066]
步驟a21,根據特殊分隔符,將預料分為短句,使用ltp的分詞函數segmentor.segment進行分詞;詞性標註函數postagger.postag對分詞短句進行詞性標註;
[0067]
步驟a22,對語料進行依存句法分析,若結果沒有主謂依存關係sbv(主謂關係),則在句首添加人物作為主語;若存在sbv關係,但標註的主語是人稱代詞,則轉換為人物名稱;
[0068]
預定義知識庫schema:
[0069]
步驟b1,制定人物關係網絡包含的實體、關係類型;
[0070]
實體類型包含:人物、地址、機關單位、企業機構、學校,共5類;
[0071]
關係類型包含:父親、母親、兒子、女兒、丈夫、妻子、籍貫、出生地、工作地、任職單位、任職機構、畢業院校、工作院校,共13類;
[0072]
步驟b2,對預處理後的文本語料進行人工標註,分別標註包含的實體與關係,並將標註結果的80%作為訓練集,20%作為驗證集;
[0073]
基於albert的tplinker模型訓練:
[0074]
步驟c1,設置隱含層數hidden_size,向量維度embedding_dim,跨層共享參數標識reuse;albert將使用以下步驟對詞嵌入模型參數進行優化:
[0075]
步驟c11,對詞嵌入參數embedding進行因式分解(factorized embedding parameterization),
[0076]
albert採用因式分解的方法來降低bert(bidirectional encoder representation from transformer,雙向transformer編碼器)算法的參數量,針對大小為v的詞彙表,
[0077]
它認為embedding_dim《《hiddern_size,故albert算法首先把one-hot(獨熱編碼)向量映射到一個大小為e的低尺寸的向量空間embedding space,然後再將其投影到h大小的隱藏空間中,即o(v
×
h)轉換成o(v
×
e+e
×
h),v就是詞表的大小,是詞嵌入模型所有詞彙的個數,和數據輸入有關,沒有固定大小;這裡的e就是embedding_dim的大小,h為hidden_size的大小。
[0078]
一般設置embedding_dim=128,hidden_size=768;
[0079]
步驟c12,跨層的參數共享(cross-layer parameter sharing),對原始算法的全連接層與attention(注意力)層都進行參數共享,即共享encoder(編碼器)內的所有參數,通過設置reuse=true開啟跨層參數共享,以此減少模型參數;其中,reuse為跨層共享參數標識。
[0080]
步驟c2,初始化嵌入層模型參數:當前數據批次大小batch_size,最大序列長度max_seq_len,向量維度embedding_dim,根據albert算法輸出當前批次的詞嵌入向量,步驟如下;
[0081]
步驟c21,將輸入序列轉換成向量作為嵌入層模型輸入,向量表達式為:
[0082]
x
embedding
=token
embedding
+segment
embedding
+position
embedding
[0083]
其中,token
embedding
是當前token的詞向量,segment
embedding
表明當前詞屬於哪個句子,position
embedding
為學習到的位置編碼;
[0084]
步驟c22,注意力機制進行特徵提取,表達式為:
[0085][0086]
其中,q、k、v是詞向量矩陣,dk為向量維度;
[0087]
步驟c23,特徵輸出,得到輸入序列的詞嵌入表示,表達式為:
[0088]
x
attention
=layernorm(x+x
attention
)
[0089]
x
hidden
=activate(linear(linear(x
attention
)))
[0090]
其中,layernorm為歸一化函數,linear為全連接層,activate為relu激活函數;
[0091]
步驟c3,設置tplinker算法的模型參數,學習因子lr,訓練迭代次數epoch和向量維度embedding_dim,數據批次大小batch_size,滑動塊大小sliding_len,tplinker對詞嵌入向量進行編碼操作,步驟如下:
[0092]
步驟c31,token對的表示法
[0093]
給定一個長度為n的句子[w1,
…
,wn],首先通過一個基本編碼器將每個wi映射成一個低維的上下文向量hi。然後,為token對(wi,wj)生成一個表示法h
ij
,如下所示;
[0094]hi,j
=tanh(wh[hi;hj]+bh)j≥i
[0095]
其中,wh是一個參數矩陣,bh是在訓練過程中要學習的一個bias向量;
[0096]
步驟c32,握手標記器:
[0097]
給定一個標註對代表h
ij
,標註對(wi,wj)的連結標籤由以下表達式預測;
[0098]
p(y
i;j
)=softmax(wo*h
i,j
+bo)
[0099]
link(wi,wj)=argmaxp(y
i;j
=l)
[0100]
其中,p(y
i;j
=l)代表識別(wi,wj)的連結為l的概率;
[0101]
步驟c33,採用人工標註之後的訓練集對tplinker模型進行模型訓練,最終得到最優的tplinker實體關係抽取模型;
[0102]
人物關係三元組抽取:
[0103]
步驟d1,對html頁面進行解析,對基本信息、人物關係、早年經歷、個人生活等多個標籤內容進行解析,並對其進行數據清洗和長句處理,將處理之後的文本輸入到albert詞嵌入層,進而生成對應的詞嵌入表示並將其作為抽取模型的輸入;
[0104]
步驟d2,使用最優模型對非結構化文本進行抽取,由於原始模型在抽取時,不能提取到三元組中頭尾實體的類型,本發明使用預定義的知識庫schema信息對抽取的三元組進行頭為實體類型映射,得到包含頭尾實體類型的三元組信息。
[0105]
如圖2所示,此方法和裝置運用的實施例
[0106]
某企業知識庫中有一批人物關係文本數據,制定知識抽取的類別,共包含5類實體、13類關係,對數據中的基本信息、人物關係、早年經歷、個人生活等標籤內容進行知識抽取。整體的抽取方法流程如圖1所示:
[0107]
該流程共分為4個步驟,詳細流程圖如圖所示:
[0108]
1.人物關係文本預處理:需要對企業知識庫中包含的人物關係文本數據進行噪聲處理,主要是對指定標籤內容進行數據清洗和長句處理,流程包括分詞、詞性標註、依存句法分析等,原始數據經預處理後的數據樣例如下所示:
[0109]
何xx,女,漢族,四川眉山人,1963年03月出生,畢業於西南師範大學美術學院美術學專業,碩士學位。兒子,曾xx,畢業於清華大學。
[0110]
李xx,男,漢族,1966年9月生,浙江紹興人,1989年8月參加工作,江西財經學院財務會計系會計學專業畢業,大學學歷,對外經濟貿易大學工商管理碩士。
[0111]
梁xx(1962年12月-),山東泰安人,男,漢族,山東理工大學本科畢業,遼寧大學日本研究所經濟學碩士畢業,在職經濟學博士學位。
[0112]
…
[0113]
2.預定義知識庫schema:制定人物關係網絡包含的實體、關係類型,實體、關係映射如表1所示。
[0114]
表1
[0115][0116]
根據實體與關係定義,需要對預處理文本進行人工標註工作,分別標註包含的實體、關係信息,對標註數據進行處理之後,形成訓練集train.txt和測試集test.txt,train.txt部分
[0117]
樣例信息如表2所示:
[0118]
表2
[0119][0120][0121]
基於albert的tplinker模型訓練:設置tplinker算法的訓練參數,最大迭代次數epoch_num=50,當前數據批次大小batch_size=16,最大序列長度max_seq_len=256,向
量維度embedding_dim=128,隱含層數hidden_size=768,跨層共享參數標識reuse=true,學習率lr=4e-4,使用adam參數優化器,對訓練集數據train.txt進行模型訓練,得到最優的實體關係抽取模型,可以實現對非結構化文本的關係三元組抽取。
[0122]
3.抽取人物關係三元組:從知識庫中隨機抽取人物關係文本數據,應用實體關係抽取模型對數據進行三元組抽取,數據內容與其抽取的三元組結果如表3所示:
[0123]
表3
[0124][0125][0126]
原始模型在抽取三元組時,不能能將三元組的頭尾實體的實體類型一併抽取,故本發明採用預定義schema的方式,規定預先定義的關係類型是獨立的,即通過關係類型能夠唯一確定對應的頭尾實體類型,經過schema映射之後,上述示例的最終抽取結果如表4所示。
[0127]
表4
[0128][0129]