一種身份認證的方法和裝置與流程
2023-12-04 14:46:36 6
本文涉及但不限於生物安全動態認證技術領域,尤指一種身份認證的方法和裝置。
背景技術:
隨著網際網路信息技術的不斷發展,網上業務、電子商務等日益繁榮,人們與計算機網絡的聯繫越來越緊密,各種網絡安全威脅也隨之而來,保護用戶個人信息成為人們急需解決的問題。動態聲紋密碼識別技術結合了說話人識別和語音識別兩重身份認證技術,從而可以有效地防止了錄音攻擊,極大地增強了系統的安全性。通常,在接收到用戶含有密碼的語音後,系統首先對聲紋和動態密碼分別計算得分,然後分別比較兩種得分與閾值大小,或者將兩種得分融合後判斷其與綜合閾值的大小,若大於事先設定的閾值,則請求人進入被保護系統,否則,拒絕其進入。但在實際應用時,受環境的影響,說話人聲紋匹配分數分布和文本匹配分數分布往往各不相同,而僅僅利用預先設定的閾值來判斷則有失準確性。
技術實現要素:
以下是對本文詳細描述的主題的概述。本概述並非是為了限制權利要求的保護範圍。
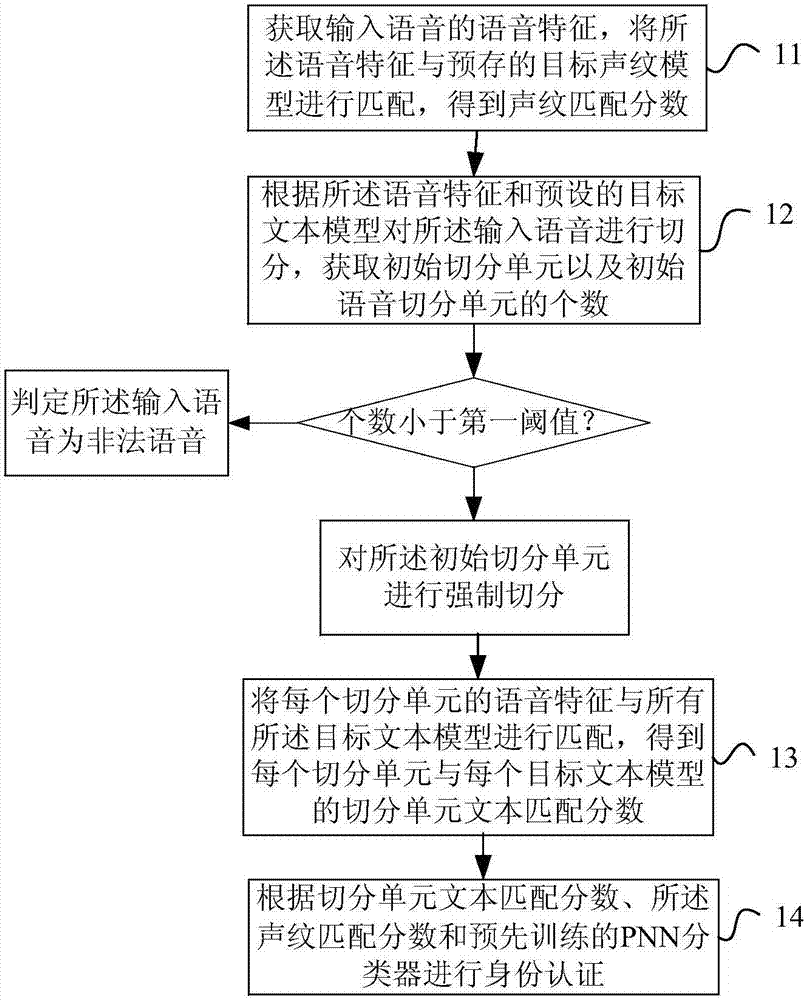
本發明實施例提供一種身份認證的方法,包括:
獲取輸入語音的語音特徵,將所述語音特徵與預存的目標聲紋模型進行匹配,得到聲紋匹配分數;
根據所述語音特徵和預設的目標文本模型對所述輸入語音進行切分,獲取初始切分單元以及初始語音切分單元的個數,如所述初始語音切分單元的個數小於第一閾值,則判定所述輸入語音為非法語音;如所述初始語音切分單元的個數大於或等於第一閾值,則對所述初始切分單元進行強制切分,使得切分單元的總個數與預設的目標文本的個數相同;
將每個所述切分單元的語音特徵與所有所述目標文本模型進行匹配,得到每個所述切分單元與每個所述目標文本模型的切分單元文本匹配分數;
根據所述切分單元文本匹配分數、所述聲紋匹配分數和預先訓練的概率神經網絡pnn分類器進行身份認證。
可選地,所述pnn分類器是通過以下方式進行訓練的:
將目標語音與所述目標文本模型和目標聲紋模型進行匹配分別得到第一文本打分和第一聲紋打分,將所述第一文本打分和第一聲紋打分組合成為所述判決分類器的接受特徵信息;
將非目標語音與所述目標文本模型和目標聲紋模型進行匹配分別得到第二文本打分和第二聲紋打分,將所述第二文本打分和第二聲紋打分組合成為所述判決分類器的拒絕特徵信息;
根據所述接受特徵信息和所述拒絕特徵信息對所述pnn分類器進行訓練。
可選地,在根據所述接受特徵信息和所述拒絕特徵信息對所述pnn分類器進行訓練之前,還包括對所述目標語音和所述非目標語音的聲紋打分和文本打分進行得分規整,包括:
依次選取所述目標文本模型,取非目標文本的語音特徵與對應的所述目標文本模型匹配,得到冒認文本打分,獲取所述目標文本模型對應的冒認文本打分的均值及標準差;
將所述第一文本打分和所述第二文本打分分別減去對應的所述冒認文本打分的均值且除以所述標準差,分別得到規整後的文本打分;
合併規整後的第一文本打分和所述第一聲紋打分,獲取每一目標文本對 應的最大值和最小值;利用該最大值和最小值將規整後的第一文本打分和所述第一聲紋打分進行歸一化,作為所述pnn分類器的接受特徵信息;
合併規整後的第二文本打分和所述第二聲紋打分,獲取每一目標文本對應的最大值和最小值;利用該最大值和最小值將規整後的第二文本打分和所述第二聲紋打分進行歸一化,作為所述pnn分類器的拒絕特徵信息。
可選地,所述根據所述語音特徵和預設的目標文本模型對所述輸入語音進行切分,獲取初始切分單元,包括:
根據目標密碼中的目標文本序列,將對應的目標文本隱馬爾可夫模型hmm組合成第一複合hmm;
將所述語音特徵作為所述第一複合hmm的輸入進行維特比解碼,得到第一狀態輸出序列,將所述第一狀態輸出序列中為單個目標文本hmm的狀態數的整數倍的狀態對應的位置作為初始切分點;
依次選取所述相鄰兩個初始切分點作為區間起止點,在所述區間內,以指定幀為單位計算平均能量,尋找平均能量連續指定次增大的點,並將開始增大的點作為新的初始切分點,由所述初始切分點分割成的所述初始切分單元。
可選地,將對應的目標文本hmm組合成第一複合hmm,包括:
所述第一複合hmm的狀態數為單個目標文本hmm的狀態數總和;所述第一複合hmm的每個狀態的高斯混合模型參數與所述單個目標文本hmm模型每個狀態的高斯混合模型參數相同;
將所述單個目標文本hmm的狀態轉移矩陣中的最後一個狀態自身轉移概率設為0,轉移到下一個狀態的狀態轉移概率設為1;所述目標文本的最後一個單個目標文本hmm的狀態轉移概率矩陣不作改變;
將所述單個目標文本hmm的狀態轉移概率矩陣按照所述目標文本的單個目標文本排列順序合併,得到所述複合hmm的狀態轉移概率矩陣。
可選地,所述對所述初始切分單元進行強制切分,使得切分單元的總個數與預設的目標文本的個數相同,包括:
選擇特徵段最長的所述初始切分單元進行強制切分,使得強制切分後的所有切分單元的總個數與預設的目標文本的個數相同。
可選地,所述對所述初始切分單元進行強制切分,使得切分單元的總個數與預設的目標文本的個數相同,包括:
按照所述初始切分單元的長度從大到小的順序開始強制拆分,每次將一個所述初始切分單元平均切分成兩個段,直至切分後的切分單元總個數等於所述目標文本的個數為止;
若強制切分的次數大於等於第二閾值,則強制切分結束;若強制切分的次數小於所述第二閾值,則將當前每個切分單元分別與每個目標文本隱馬爾可夫模型hmm進行匹配打分,分別選定最高打分對應的所述目標文本hmm,將所選定的所述目標文本hmm組合成第二複合hmm;將所述語音特徵作為所述第二複合hmm的輸入進行維特比解碼,得到第二狀態輸出序列,將所述第二狀態輸出序列中為單個目標文本hmm的狀態數的整數倍的狀態對應的位置作為切分點,由該切分點對所述語音特徵分割得到的不同單元為所述切分單元,若當前的所述切分單元個數小於第三閾值,則將當前切分後的切分單元作為所述初始切分單元繼續進行強制切分,當前的所述切分單元個數大於或小於所述第三閾值,則強制切分結束。
可選地,所述將每個所述切分單元的語音特徵與所有所述目標文本模型進行匹配,得到每個所述切分單元與每個所述目標文本模型的切分單元文本匹配分數,包括:
將每個所述切分單元的語音特徵作為每個目標文本隱馬爾可夫模型hmm的輸入,將根據維特比算法獲得的輸出概率作為對應的切分單元文本匹配分數。
可選地,所述根據所述切分單元文本匹配分數、所述聲紋匹配分數和預先訓練的判決分類器進行身份認證,包括:
取每個所述切分單元對應的所述切分單元文本匹配分數中m個最高分數對應的文本作為待選文本,若所述待選文本中包含所述切分單元對應的目標文本,則所述切分單元認證通過,計算通過的切分單元的總數,若通過的 切分單元總數小於或等於第四閾值,則文本認證不通過,身份認證不通過;若通過的切分單元總數大於所述第四閾值,則所述輸入語音的文本認證通過;
判斷所述聲紋匹配分數是否大於第五閾值,如是,則聲紋認證通過,身份認證通過;如不是,則將每個所述切分單元與對應目標文本模型的文本打分以及所述聲紋匹配分數進行得分規整,將規整後的打分作為所述判決分類器的輸入進行身份認證。
本發明實施例還提供了一種身份認證的裝置,包括概率神經網絡pnn分類器,包括:
聲紋匹配模塊,設置為獲取輸入語音的語音特徵,將所述語音特徵與預存的目標聲紋模型進行匹配,得到聲紋匹配分數;
切分模塊,設置為根據所述語音特徵和預設的目標文本模型對所述輸入語音進行切分,獲取初始切分單元以及初始語音切分單元的個數,如所述初始語音切分單元的個數小於閾值,則判定所述輸入語音為非法語音;如所述初始語音切分單元的個數大於或等於第一閾值,則對所述初始切分單元進行強制切分,使得切分單元的總個數與預設的目標文本的個數相同;
文本匹配模塊,設置為將每個所述切分單元的語音特徵與所有所述目標文本模型進行匹配,得到每個所述切分單元與每個所述目標文本模型的切分單元文本匹配分數;
認證模塊,設置為根據所述切分單元文本匹配分數、所述聲紋匹配分數和預先訓練的所述pnn分類器進行身份認證。
可選地,所述裝置還包括處理模塊,
所述聲紋匹配模塊,是設置為將目標語音與目標聲紋模型進行匹配得到第一聲紋打分,將非目標語音與所述目標聲紋模型進行匹配得到第二聲紋打分;
所述文本匹配模塊,是設置為將所述目標語音與所述目標文本模型進行匹配得到第一文本打分,將所述非目標語音與所述目標文本模型進行匹配得到第二文本打分;
所述處理模塊,設置為將所述第一文本打分和第一聲紋打分組合成為所述pnn分類器的接受特徵信息,將所述第二文本打分和第二聲紋打分組合成為所述pnn分類器的拒絕特徵信息;
所述pnn分類器,根據所述接受特徵信息和所述拒絕特徵信息進行訓練。
可選地,所述處理模塊,還設置為依次選取所述目標文本模型,取非目標文本的語音特徵與對應的所述目標文本模型匹配,得到冒認文本打分,獲取所述目標文本模型對應的冒認文本打分的均值及標準差;將所述第一文本打分和所述第二文本打分分別減去對應的所述冒認文本打分的均值且除以所述標準差,分別得到規整後的文本打分;合併規整後的第一文本打分和所述第一聲紋打分,獲取每一目標文本對應的最大值和最小值;利用該最大值和最小值將規整後的第一文本打分和所述第一聲紋打分進行歸一化,作為所述pnn分類器的接受特徵信息;合併規整後的第二文本打分和所述第二聲紋打分,獲取每一目標文本對應的最大值和最小值;利用該最大值和最小值將規整後的第二文本打分和所述第二聲紋打分進行歸一化,作為所述pnn分類器的拒絕特徵信息。
可選地,所述切分模塊,根據所述語音特徵和預設的目標文本模型對所述輸入語音進行切分,獲取初始切分單元,包括:根據目標密碼中的目標文本序列,將對應的目標文本隱馬爾可夫模型hmm組合成第一複合hmm;將所述語音特徵作為所述第一複合hmm的輸入進行維特比解碼,得到第一狀態輸出序列,將所述第一狀態輸出序列中為單個目標文本hmm的狀態數的整數倍的狀態對應的位置作為初始切分點;依次選取所述相鄰兩個初始切分點作為區間起止點,在所述區間內,以指定幀為單位計算平均能量,尋找平均能量連續指定次增大的點,並將開始增大的點作為新的初始切分點,由所述初始切分點分割成的所述初始切分單元。
可選地,所述切分模塊,將對應的目標文本hmm組合成第一複合hmm,包括:所述第一複合hmm的狀態數為單個目標文本hmm的狀態數總和;所述第一複合hmm的每個狀態具有的高斯混合模型參數與所述單個目標文本hmm的每個狀態具有的高斯混合模型參數相同;將所述單個目標文本 hmm的狀態轉移矩陣中的最後一個狀態自身轉移概率設為0,轉移到下一個狀態的狀態轉移概率設為1;所述目標文本的最後一個單個目標文本hmm的狀態轉移概率矩陣不作改變;將所述單個目標文本hmm的狀態轉移概率矩陣按照所述目標文本的單個目標文本排列順序合併,得到所述複合hmm的狀態轉移概率矩陣。
可選地,所述切分模塊,對所述初始切分單元進行強制切分,使得切分單元的總個數與預設的目標文本的個數相同,包括:選擇特徵段最長的所述初始切分單元進行強制切分,使得強制切分後的所有切分單元的總個數與預設的目標文本的個數相同。
可選地,所述切分模塊,對所述初始切分單元進行強制切分,使得切分單元的總個數與預設的目標文本的個數相同,包括:按照所述初始切分單元的長度從大到小的順序開始拆分,每次將一個所述初始切分單元平均切分成兩個段,直至切分後的單元總個數等於所述目標文本的個數為止;若強制切分的次數大於等於第二閾值,則強制切分結束;若強制切分的次數小於所述第二閾值,則將當前每個切分的單元分別與每個目標文本隱馬爾可夫模型hmm進行匹配打分,分別選定最高打分對應的所述目標文本hmm,將所選定的所述目標文本hmm組合成第二複合hmm;將所述語音特徵作為所述第二複合hmm的輸入進行維特比解碼,得到第二狀態輸出序列,將所述第二狀態輸出序列中為單個目標文本hmm的狀態數的整數倍的狀態對應的位置作為切分點,由該切分點對所述語音特徵分割得到的不同單元為所述切分單元,若當前的所述切分單元個數小於第三閾值,則將當前切分後的切分單元作為所述初始切分單元繼續進行強制切分,若當前的所述切分單元個數大於或等於第三閾值,則強制切分結束。
可選地,所述文本匹配模塊,將每個所述切分單元的語音特徵與所有所述目標文本模型進行匹配,得到每個所述切分單元與每個所述目標文本模型的切分單元文本匹配分數,包括:將每個所述切分單元的語音特徵作為每個目標文本隱馬爾可夫模型hmm的輸入,將根據維特比算法獲得的輸出概率作為對應的切分單元文本匹配分數。
可選地,所述認證模塊,根據所述切分單元文本匹配分數、所述聲紋匹 配分數和預先訓練的判決分類器進行身份認證,包括:取每個所述切分單元對應的所述切分單元文本匹配分數中m個最高分數對應的文本作為待選文本,若所述待選文本中包含所述切分單元對應的目標文本,則所述切分單元認證通過,計算通過的切分單元的總數,若通過的切分單元總數小於或等於第四閾值,則文本認證不通過,身份認證不通過;若通過的切分單元總數大於所述第四閾值,則所述輸入語音的文本認證通過;判斷所述聲紋匹配分數是否大於第五閾值,如是,則聲紋認證通過,身份認證通過;如不是,則將每個所述切分單元與對應目標文本模型的文本打分以及所述聲紋匹配分數進行得分規整,將規整後的打分作為所述pnn分類器的輸入進行身份認證。
本發明實施例還提供了一種計算機可讀存儲介質,存儲有計算機可執行指令,所述計算機可執行指令用於上述的一種身份認證的方法。
綜上,本發明實施例提供一種身份認證的方法及裝置,將聲紋與動態密碼認證兩者相結合,實現了對用戶進行雙重驗證的目的,提高了系統的安全性、可靠性和準確性。
附圖說明
圖1是本發明實施例提供的一種身份認證的方法的流程圖;
圖2是本發明實施例的訓練pnn分類器的方法的流程圖;
圖3是本發明實施例一的一種身份認證的方法的流程圖;
圖4是本發明實施例一的語音信號初始切分的方法的流程圖;
圖5是本發明實施例一的聲紋與文本初步認證的方法的流程圖;
圖6是本發明實施例一的得分規整的方法的流程圖;
圖7是本發明實施例二的一種身份認證的方法的流程圖;
圖8是本發明實施例二的語音信號初始切分的方法的流程圖;
圖9為本發明實施例的一種身份認證的裝置的示意圖。
具體實施方式
下文中將結合附圖對本發明的實施例進行詳細說明。需要說明的是,在不衝突的情況下,本申請中的實施例及實施例中的特徵可以相互任意組合。
圖1是本發明實施例提供的一種身份認證的方法的流程圖,如圖1所示,本實施例的方法包括以下步驟:
步驟11、獲取輸入語音的語音特徵,將所述語音特徵與預存的目標聲紋模型進行匹配,得到聲紋匹配分數;
步驟12、根據所述語音特徵和預設的目標文本模型對所述輸入語音進行切分,獲取初始切分單元以及初始語音切分單元的個數,如所述初始語音切分單元的個數小於閾值,則判定所述輸入語音為非法語音,結束流程;如所述初始語音切分單元的個數大於或等於第一閾值,則對所述初始切分單元進行強制切分,使得切分單元的總個數與預設的目標文本的個數相同;
步驟13、將每個所述切分單元的語音特徵與所有所述目標文本模型進行匹配,得到每個所述切分單元與每個所述目標文本模型的切分單元文本匹配分數;
步驟14、根據所述切分單元文本匹配分數、所述聲紋匹配分數和預先訓練的pnn(probabilisticneuralnetworks,概率神經網絡)分類器進行身份認證。
本發明實施例提供的一種身份認證方法,將聲紋與動態密碼認證兩者相結合,實現了對用戶進行雙重驗證的目的,提高了系統的安全性、可靠性和準確性。
本實施例中,需要預先對pnn分類器進行訓練,根據已有的語音獲取目標文本模型和目標聲紋模型;將已有語音與所述目標文本模型和目標聲紋模型進行匹配得到文本打分和聲紋打分,根據所述聲紋打分和文本打分組合成接受特徵信息和拒絕特徵信息,將所述信息接受特徵和所述拒絕特徵信息作為綜合pnn判決分類器的輸入進行訓練,得到最終的綜合判決分類器;實現方式如下:
將目標語音與所述目標文本模型和目標聲紋模型進行匹配分別得到第一文本打分和第一聲紋打分,將所述第一文本打分和第一聲紋打分組合成為所述判決分類器的接受特徵信息;
將非目標語音與所述目標文本模型和目標聲紋模型進行匹配分別得到第二文本打分和第二聲紋打分,將所述第二文本打分和第二聲紋打分組合成為所述判決分類器的拒絕特徵信息;
根據所述接受特徵信息和所述拒絕特徵信息對所述pnn分類器進行訓練。
所述目標語音為所述目標話者讀取所述目標文本的語音,所述非目標語音為所述目標話者讀取非目標文本的語音以及非目標話者的語音。
可選地,在訓練所述綜合分類器之前對所述聲紋打分和文本打分進行得分規整,例如包括以下步驟:
a.依次選取目標文本模型,取非目標文本語音特徵與該目標文本模型匹配,得到冒認文本打分;
b.求所述目標文本模型對應的所述冒認文本打分均值及標準差;
c.將所述第一文本打分和所述第二文本打分分別減去對應的所述冒認文本打分的均值且除以所述標準差,分別得到規整後的文本打分;
d.合併所述聲紋打分和規整後的文本打分,求得每一目標文本對應的最大值和最小值,利用步驟d中的所述最大值和最小值將所述聲紋打分和文本打分進行歸一化;例如:
合併規整後的第一文本打分和所述第一聲紋打分,獲取每一目標文本對應的最大值和最小值;利用該最大值和最小值將規整後的第一文本打分和所述第一聲紋打分進行歸一化,作為所述pnn分類器的接受特徵信息;
合併規整後的第二文本打分和所述第二聲紋打分,獲取每一目標文本對應的最大值和最小值;利用該最大值和最小值將規整後的第二文本打分和所述第二聲紋打分進行歸一化,作為所述pnn分類器的拒絕特徵信息。
本實施例中為方便描述,做以下定義:
目標文本:事先選定作為備選密碼的文本,如0~9數字;
目標話者:系統受信任的話者,在聲紋認證時需要讓其通過的話者;
冒認話者:系統非受信任話者,在聲紋認證時需要拒絕其進入的話者;
目標密碼:系統受信任的目標文本組合,在文本認證時需要讓其通過;
冒認密碼:系統不受信任的文本組合,在文本認證時需要拒絕其進入的文本。
系統進行認證之前,需要選擇目標文本集,並針對目標文本集中的每個目標文本進行訓練,得到目標文本模型集。以下實施例目標文本集選擇為:0~9十個數字,目標模型集由0~9十個數字訓練出來的模型組成,目標模型種類可以為hmm(hiddenmarkovmodel,隱馬爾可夫模型)。為方便描述,動態密碼均由0~9十個數字中的8個組成,即系統選擇8個目標文本,作為目標密碼。同時在系統進行認證之前,需要註冊目標話者的聲紋信息,通過訓練生成聲紋模型,並通過聲紋模型和目標模型訓練綜合判決分類器,如圖2所示包括如下步驟:
步驟001:訓練目標文本模型:使用0~9的數字錄音訓練單個數字的hmm,每個數字的模型稱為目標文本模型,訓練方法可使用現有的訓練方法;
hmm是一個雙重隨機過程,一個過程用來描述短時平穩信號的時變性,另一個過程用來描述hmm模型的狀態數與特徵序列之間的對應關係。兩個過程相互作用,不僅能夠描述語音信號的動態特性,而且可以解決短時平穩信號之間的過渡問題。
步驟002:註冊目標話者聲紋模型:系統在使用之前,事先註冊目標話者聲紋模型,目標話者即為系統受信任的話者,在認證時需要讓其通過;
步驟003:求接受特徵:使用目標話者的目標文本對應的語音與其對應的hmm進行匹配,得到目標文本接受打分;使用目標話者的目標文本對應的語音與目標話者聲紋模型進行打分,得到目標話者聲紋接受打分;一系列的目標話者聲紋接受打分和目標文本接受打分組成綜合分類器的接受特徵, 對應綜合分類器輸出為1;
步驟004:求拒絕特徵:使用目標文本對應的語音與非對應的hmm模型進行匹配,得到冒認文本的拒絕打分;使用冒認話者與目標聲紋模型進行打分,得到冒認聲紋拒絕打分,由一系列的冒認文本拒絕打分和冒認聲紋拒絕打分組成綜合分類器的拒絕特徵,對應綜合分類器輸出為0;
步驟005:訓練分類器:合併綜合分類器的接受特徵和拒絕特徵,將合併後的特徵進行得分規整(詳見步驟109)後作為分類器的訓練輸入,根據現有訓練算法(如梯度下降算法)可得到綜合分類器。
實施例一:
如圖3所示,包括以下步驟:
步驟101、預處理:根據短時能量和短時過零率,對用戶輸入的測試語音進行預處理,去掉語音中的非語音段;
步驟102、特徵參數提取:對預處理後的測試語音進行特徵參數提取,該系統可以採用12維梅爾頻域倒譜係數(melfrequencycepstrumcoefficient,簡稱mfcc)和其一階差分係數作為特徵參數,共24維;
步驟103、計算聲紋匹配分數:將測試語音特徵與目標話者的聲紋模型進行匹配,得到聲紋匹配分數;
步驟104、對語音特徵初始切分:通過對測試語音特徵的初始切分,獲得初始切分單元以及初始切分單元個數。
本實施例中,根據目標密碼中的目標文本序列,將對應的目標文本hmm組合成複合hmm;
將所述語音特徵作為所述複合hmm的輸入進行viterbi(維特比)解碼,得到第一狀態輸出序列,將所述第一狀態輸出序列中為單個目標文本hmm的狀態數的整數倍的狀態對應的位置作為初始切分點;
依次選取所述相鄰兩個初始切分點作為區間起止點,在所述區間內,以指定幀為單位計算平均能量,尋找平均能量連續指定次增大的點,並將開始增大的點作為新的初始切分點,否則,不更新初始切分點,由所述初始切分 點分割成的所述初始切分單元。
其中,所述複合hmm的狀態數為單個目標文本hmm的狀態數總和;所述複合hmm的每個狀態具有的高斯混合模型參數與所述單個目標文本hmm的每個狀態具有的高斯混合模型參數相同,
將所述單個目標文本hmm的狀態轉移矩陣中的最後一個狀態自身轉移概率設為0,轉移到下一個狀態的狀態轉移概率設為1;所述目標文本的最後一個單個目標文本hmm的狀態轉移概率矩陣不作改變;
將所述單個目標文本hmm的狀態轉移概率矩陣按照所述目標文本的單個目標文本排列順序合併,得到所述複合hmm的狀態轉移概率矩陣。
對語音特徵初始切分的方法如圖4所示,包括步驟如下:
步驟104a、複合hmm模型的組合:按照目標密碼中目標文本序列,將對應的單個目標文本hmm組合為複合hmm模型。
假設每個數字的hmm模型有8個狀態數,每個狀態由3個高斯函數擬合,那麼,複合hmm模型的狀態數為單個目標文本hmm模型狀態數之和,每個狀態仍由3個高斯函數擬合,且其高斯混合模型參數與單個hmm模型每個狀態的高斯混合模型參數相同,複合hmm的狀態轉移概率矩陣參數的變化以3個單個目標文本hmm模型連接成一個複合型hmm為例進行說明,該例中單個目標文本hmm模型狀態數為3,如下式所示:
組合成複合hmm模型時,每個狀態矩陣將改寫成如下形式:
於是複合hmm模型的狀態轉移概率矩陣為:
步驟104b、viterbi(維特比)解碼:利用viterbi解碼將步驟102中得到的特徵序列與步驟104a中得到的複合hmm模型匹配,得到一個最佳狀態輸出序列,使每一幀特徵都有其對應的狀態;
步驟104c、尋找初始切分點:由步驟104a可知單個數字hmm模型的狀態數為8,在步驟104b中所得最佳狀態輸出序列中尋找對應狀態為8的整數倍的位置作為初始切分點p(i);
步驟104d、更新初始切分點:依次選取步驟104c中相鄰的兩個初始切分點p(i-1)和p(i),並分別作為區間的起始點和終止點。在該區間內,每k幀組成一段,共l段,每段平均能量為e(n),n為段索引號,計算s(n-1)=e(n)-e(n-1)n=2…l,從s(n1)>0,n1=1…l-1的索引號開始向後搜索,若s(n1+1),s(n1+2),……,s(n1+q)均大於0,其中q是一個大於1的常數,則將n1段的起始點作為新的初始切分點代替p(i-1);若無該類索引號,則不 更新初始切分點。由初始切分點分割成的不同單元即初始切分單元,假設初始切分單元個數為m,由於最佳狀態序列的最大狀態為64,所以初始切分單元個數小於等於8個(該更新過程並未改變初始切分點個數);
步驟105、初始切分單元個數判決:步驟104將語音切分後得到若干個初始切分單元,對於目標密碼語音,其初始切分單元個數一般近似等於目標密碼中目標文本個數;對於冒認密碼語音,其切分單元個數往往遠小於目標密碼中目標文本個數。由步驟104可知測試語音初始切分單元數為m,假設最少切分單元個數為t,當m0時,取初始切分單元中對應特徵段最長的切分單元,並將該特徵段平均切分為(8-m+1)份,強制切分後的切分單元總數變為8;
步驟107、計算文本匹配分數:將步驟106中得到的切分單元對應特徵序列與0~9十個目標文本的目標模型hmm進行匹配,每個切分單元對應10個匹配打分,假設該打分為word_score(i,j),該變量表示動態密碼中第i個切分單元與數字j的模型的文本匹配分數;
步驟108、聲紋與文本初步認證:
取每個所述切分單元對應的所述切分單元文本匹配分數中m個最高分數對應的文本作為待選文本,若所述待選文本中包含所述切分單元對應的目標文本,則所述切分單元認證通過,計算通過的切分單元的總數,若通過的切分單元總數小於或等於第四閾值,則文本認證不通過,身份認證不通過,判決結束;若通過的切分單元總數大於所述第四閾值,則所述輸入語音的文本認證通過;
判斷所述聲紋匹配分數是否大於第五閾值,如是,則聲紋認證通過,身份認證通過,判決結束;如不是,則將每個所述切分單元與對應目標文本模型的文本打分以及所述聲紋匹配分數進行得分規整,將規整後的打分作為所述判決分類器的輸入進行身份認證。
如圖5所示,其實施方法如下:
步驟108a、每個切分單元各取m個最高得分:由上述步驟106可知,每個切分單元對應有10個得分,各取m(一般為2或3)個最高打分,分別對應m個待匹配文本;
步驟108b、切分單元文本認證:對每個切分單元進行文本認證,若切分單元對應的m個待匹配文本中包含該切分單元對應的目標文本,則該切分單元的文本認證通過,反之,認證不通過;
步驟108c、計算切分單元文本認證通過的總個數w;
步驟108d、測試語音文本認證:假設測試語音切分單元文本認證通過的最小數為p,當w大於p時,則判定該語音文本認證通過,並轉至步驟108e,否則,文本認證不通過,身份認證不通過,判決結束;
步驟108e、測試語音聲紋認證:設置一個較大的聲紋閾值,以保證系統的嚴格性,當聲紋匹配分數大於閾值時,聲紋認證通過,該測試語音身份認證通過,否則,轉至步驟109;
步驟109、得分規整:首先求得大量冒認密碼語音對應目標文本模型的打分均值與方差,在得到測試語音中每個切分單元對應的文本打分後減去冒認得分均值並除以標準差。如圖6所示,其實施方法如下:
步驟109a、求大量冒認文本打分:依次取0~9的單個數字模型hmm,假設取數字l的模型hmml,根據viterbi算法,取大量非l的冒認語音特徵作為模型hmml的輸入,得到大量冒認文本打分;
步驟109b、求均值與標準差:計算每個文本對應的冒認文本打分均值與標準差;
步驟109c、零歸整及歸一化:在步驟107計算文本匹配分數的基礎上,找出每個切分單元與其對應目標文本模型的打分,此時每個切分單元對應一個文本打分。根據零歸整方法,將每個文本打分分別減去對應文本的冒認打分均值並除以標準差,得到規整後的文本匹配分數,將步驟103中得到的聲紋匹配分數與規整後的8個文本匹配分數合併組成一個9維的特徵向量score(得分)。由於該特徵向量中的聲紋匹配分數不論是目標話者還是冒認話者的聲紋打分,其打分一般遠大於文本匹配分數,因此,又對特徵向量增加了 歸一化處理,使得聲紋匹配分數與文本匹配分數均在[0,1]之間。假設該特徵向量的最大值和最小值分別為max_score和min_score,對特徵向量作線性變換,得到一個新的特徵向量new_score=(score-min_score)/(max_score-min_score);
步驟110綜合判決:利用綜合判決分類器對輸入特徵向量new_score進行判決,對於每一個輸入,其輸出為1或0,當輸出為1時表示測試語音判決通過,輸出為0時拒絕測試語音通過。
實施例二:
針對第一種實施方式中步驟104的對於語音特徵初始切分、步驟105的切分單元個數判決,以及步驟106的強制切分,本實施例中採用以下方法進行切分和判決:
步驟201,語音信號初始切分;
本實施例中,按照所述初始切分單元的長度從大到小的順序開始拆分,每次將一個所述初始切分單元平均切分成兩個段,直至切分單元的總個數等於所述目標文本的個數為止;
若強制切分的次數大於等於第二閾值,則強制切分結束;若強制切分的次數小於所述第二閾值,則將當前每個切分的單元分別與每個目標文本hmm進行匹配打分,分別選定最高打分對應的所述目標文本hmm,將所選定的所述目標文本hmm組合成第二複合hmm;
將所述語音特徵作為所述第二複合hmm的輸入進行維特比解碼,得到第二狀態輸出序列,將所述第二狀態輸出序列中為單個目標文本hmm的狀態數的整數倍的狀態對應的位置作為切分點,由該切分點對所述語音特徵分割得到的不同單元即為所述切分單元,若當前的切分單元個數小於第三閾值,則將當前切分後的切分單元作為所述初始切分單元繼續進行強制切分,若當前的切分單元個數大於或等於第三閾值,則強制切分結束,並將上述強制切分後的切分單元作為最終切分單元。如圖8所示,包括如下步驟:
步驟201a、初始分割:計算語音信號包絡,選擇8個極大包絡處附近區域作為初始分割結果;
步驟201b、根據打分對初始分割段判決:將每個分割段對0~9十個數字模型進行打分,每個分割段取最高得分對應的數字,並作為該分割段的判決結果;
步驟201c、複合hmm模型的組合:根據上述步驟201b中的分割判決結果,選擇相應的hmm模型,組合成複合hmm模型,該組合過程可參見第一種實施方式中的步驟104a;
步驟201d、根據viterbi解碼作進一步分割:根據步驟201c輸出的組合模型對輸入信號進行viterbi解碼,根據最佳狀態序列對信號做進一步分割,該分割過程可參見第一種實施方式中的步驟104c。
步驟202、強制切分:將分割段長度大小排序,按大小順序平均分割為兩個,直至分割為8段為止。
步驟203、初始切分判決:若步驟201d的分割段個數小於x(相當於第三閾值,x<8)個,則轉至步驟201b,將步驟202的輸出結果作為步驟201b的輸入,繼續進行分割;若分割段個數大於或等於x,則分割結束。設定一個最大迭代次數d(相當於第二閾值),若該過程迭代次數等於d時,步驟201b的分割段數仍小於x個,則停止迭代,並拒絕該語音;若該過程迭代次數小於d或等於d時分割段數大於等於x,則繼續進行判決,執行第一種實施方式中的步驟107及後續步驟。
圖9為本發明實施例的一種身份認證的裝置的示意圖,本實施例的裝置包括pnn分類器,如圖9所示,本實施例的裝置包括:
聲紋匹配模塊,設置為獲取輸入語音的語音特徵,將所述語音特徵與預存的目標聲紋模型進行匹配,得到聲紋匹配分數;
切分模塊,設置為根據所述語音特徵和預設的目標文本模型對所述輸入語音進行切分,獲取初始切分單元以及初始語音切分單元的個數,如所述初始語音切分單元的個數小於閾值,則判定所述輸入語音為非法語音;如所述初始語音切分單元的個數大於或等於第一閾值,則對所述初始切分單元進行強制切分,使得切分單元的總個數與預設的目標文本的個數相同;
文本匹配模塊,設置為將每個所述切分單元的語音特徵與所有所述目標 文本模型進行匹配,得到每個所述切分單元與每個所述目標文本模型的切分單元文本匹配分數;
認證模塊,設置為根據所述切分單元文本匹配分數、所述聲紋匹配分數和預先訓練的所述pnn分類器進行身份認證。
在一可選實施例中,所述裝置還包括處理模塊,
所述聲紋匹配模塊,是設置為將目標語音與目標聲紋模型進行匹配得到第一聲紋打分,將非目標語音與所述目標聲紋模型進行匹配得到第二聲紋打分;
所述文本匹配模塊,是設置為將所述目標語音與所述目標文本模型進行匹配得到第一文本打分,為將所述非目標語音與所述目標文本模型進行匹配得到第二文本打分;
所述處理模塊,設置為將所述第一文本打分和第一聲紋打分組合成為所述pnn分類器的接受特徵信息,將所述第二文本打分和第二聲紋打分組合成為所述pnn分類器的拒絕特徵信息;
所述pnn分類器,根據所述接受特徵信息和所述拒絕特徵信息進行訓練。
在一可選實施例中,所述處理模塊,還設置為依次選取所述目標文本模型,取非目標文本的語音特徵與對應的所述目標文本模型匹配,得到冒認文本打分,獲取所述目標文本模型對應的冒認文本打分的均值及標準差;將所述第一文本打分和所述第二文本打分分別減去對應的所述冒認文本打分的均值且除以所述標準差,分別得到規整後的文本打分;合併規整後的第一文本打分和所述第一聲紋打分,獲取每一目標文本對應的最大值和最小值;利用該最大值和最小值將規整後的第一文本打分和所述第一聲紋打分進行歸一化,作為所述pnn分類器的接受特徵信息;合併規整後的第二文本打分和所述第二聲紋打分,獲取每一目標文本對應的最大值和最小值;利用該最大值和最小值將規整後的第二文本打分和所述第二聲紋打分進行歸一化,作為所述pnn分類器的拒絕特徵信息。
在一可選實施例中,所述切分模塊,根據所述語音特徵和預設的目標文 本模型對所述輸入語音進行切分,獲取初始切分單元,包括:根據目標密碼中的目標文本序列,將對應的目標文本隱馬爾可夫模型hmm組合成第一複合hmm;將所述語音特徵作為所述第一複合hmm的輸入進行維特比解碼,得到第一狀態輸出序列,將所述第一狀態輸出序列中為單個目標文本hmm的狀態數的整數倍的狀態對應的位置作為初始切分點;依次選取所述相鄰兩個初始切分點作為區間起止點,在所述區間內,以指定幀為單位計算平均能量,尋找平均能量連續指定次增大的點,並將開始增大的點作為新的初始切分點,由所述初始切分點分割成的所述初始切分單元。
在一可選實施例中,所述切分模塊,將對應的目標文本hmm組合成第一複合hmm,包括:所述第一複合hmm的狀態數為單個目標文本hmm的狀態數總和;所述第一複合hmm的每個狀態具有的高斯混合模型參數與所述單個目標文本hmm的每個狀態具有的高斯混合模型參數相同;將所述單個目標文本hmm的狀態轉移矩陣中的最後一個狀態自身轉移概率設為0,轉移到下一個狀態的狀態轉移概率設為1;所述目標文本的最後一個單個目標文本hmm的狀態轉移概率矩陣不作改變;將所述單個目標文本hmm的狀態轉移概率矩陣按照所述目標文本的單個目標文本排列順序合併,得到所述複合hmm的狀態轉移概率矩陣。
在一可選實施例中,所述切分模塊,對所述初始切分單元進行強制切分,使得切分單元的總個數與預設的目標文本的個數相同,包括:選擇特徵段最長的所述初始切分單元進行強制切分,使得強制切分後的所有切分單元的總個數與預設的目標文本的個數相同。
在一可選實施例中,所述切分模塊,對所述初始切分單元進行強制切分,使得切分單元的總個數與預設的目標文本的個數相同,包括:按照所述初始切分單元的長度從大到小的順序開始拆分,每次將一個所述初始切分單元平均切分成兩個段,直至切分單元的總個數等於所述目標文本的個數為止;若強制切分的次數大於等於第二閾值,則強制切分結束;若強制切分的次數小於所述第二閾值,則將當前每個切分的單元分別與每個目標文本hmm進行匹配打分,分別選定最高打分對應的所述目標文本hmm,將所選定的所述目標文本hmm組合成第二複合hmm;將所述語音特徵作為所述第二複合 hmm的輸入進行維特比解碼,得到第二狀態輸出序列,將所述第二狀態輸出序列中為單個目標文本hmm的狀態數的整數倍的狀態對應的位置作為切分點,由該切分點對所述語音特徵分割得到的不同單元即為切分單元,若當前的切分單元個數小於第三閾值,則將當前切分後的切分單元作為所述初始切分單元繼續進行強制切分,若當前的切分單元個數大於或等於第三閾值,強制切分結束,並將上述強制切分後的切分單元作為最終切分單元。
在一可選實施例中,所述文本匹配模塊,將每個所述切分單元的語音特徵與所有所述目標文本模型進行匹配,得到每個所述切分單元與每個所述目標文本模型的切分單元文本匹配分數,包括:將每個所述切分單元的語音特徵作為每個目標文本隱馬爾可夫模型hmm的輸入,將根據維特比算法獲得的輸出概率作為對應的切分單元文本匹配分數。
在一可選實施例中,所述認證模塊,根據所述切分單元文本匹配分數、所述聲紋匹配分數和預先訓練的判決分類器進行身份認證,包括:取每個所述切分單元對應的所述切分單元文本匹配分數中m個最高分數對應的文本作為待選文本,若所述待選文本中包含所述切分單元對應的目標文本,則所述切分單元認證通過,計算通過的切分單元的總數,若通過的切分單元總數小於或等於第四閾值,則文本認證不通過,身份認證不通過,判決結束;若通過的切分單元總數大於所述第四閾值,則所述輸入語音的文本認證通過;判斷所述聲紋匹配分數是否大於第五閾值,如是,則聲紋認證通過,身份認證通過,判決結束;如不是,則將每個所述切分單元與對應目標文本模型的文本打分以及所述聲紋匹配分數進行得分規整,將規整後的打分作為所述pnn分類器的輸入進行身份認證。
本發明實施例還提供了一種計算機可讀存儲介質。可選地,在本實施例中,上述存儲介質可以被設置為存儲由處理器執行的程序代碼,程序代碼的步驟如下:
s1、獲取輸入語音的語音特徵,將所述語音特徵與預存的目標聲紋模型進行匹配,得到聲紋匹配分數;
s2、根據所述語音特徵和預設的目標文本模型對所述輸入語音進行切 分,獲取初始切分單元以及初始語音切分單元的個數,如所述初始語音切分單元的個數小於第一閾值,則判定所述輸入語音為非法語音;如所述初始語音切分單元的個數大於或等於第一閾值,則對所述初始切分單元進行強制切分,使得切分單元的總個數與預設的目標文本的個數相同;
s3、將每個所述切分單元的語音特徵與所有所述目標文本模型進行匹配,得到每個所述切分單元與每個所述目標文本模型的切分單元文本匹配分數;
s4、根據所述切分單元文本匹配分數、所述聲紋匹配分數和預先訓練的概率神經網絡pnn分類器進行身份認證。
可選地,在本實施例中,上述存儲介質可以包括但不限於:u盤、只讀存儲器(read-onlymemory,簡稱為rom)、隨機存取存儲器(randomaccessmemory,簡稱為ram)、移動硬碟、磁碟或者光碟等每種可以存儲程序代碼的介質。
本領域普通技術人員可以理解上述方法中的全部或部分步驟可通過程序來指令相關硬體完成,所述程序可以存儲於計算機可讀存儲介質中,如只讀存儲器、磁碟或光碟等。可選地,上述實施例的全部或部分步驟也可以使用一個或多個集成電路來實現。相應地,上述實施例中的各模塊/單元可以採用硬體的形式實現,也可以採用軟體功能模塊的形式實現。本發明不限制於任何特定形式的硬體和軟體的結合。
以上僅為本發明的優選實施例,當然,本發明還可有其他多種實施例,在不背離本發明精神及其實質的情況下,熟悉本領域的技術人員當可根據本發明作出各種相應的改變和變形,但這些相應的改變和變形都應屬於本發明所附的權利要求的保護範圍。